

Новая нейросеть Qwen Images которая генерирует и модифицирует картинки
Qwen Images — это нейросеть, которая выходит за рамки простого создания изображений по текстовому описанию. Она справляется не только с генерацией новых, но и с тонкой модификацией уже готовых картинок. Можно менять детали, накладывать фильтры, совмещать разные элементы, экспериментировать с настроением и стилем — интерфейс позволяет работать с изображениями на довольно глубоком уровне.

Давайте разберём, какие рабочие задачи способна закрыть нейросеть Qwen.
Модификация картинок в нейросети Qwen Images
Почти все популярные нейросети для обработки картинок — Midjourney, Sora Images и подобные — часто страдают одной типичной проблемой. Жёсткие NSFW-фильтры режут даже те арты и снимки, где ни малейшего нарушения нет. Казалось бы — обработал семейное фото или сделал безобидную иллюстрацию, а получаешь сообщение о блокировке. Такая избыточная цензура здорово раздражает, особенно если занят творчеством или учёбой.
В чём выигрывает Qwen? Её можно поставить на свой собственный сервер. То есть вы лично регулируете, насколько жёсткие будут фильтры. Хотите — добавляйте ограничения, хотите — убирайте максимум "лишнего". Это решение для тех, кому не хочется зависеть от невнятных алгоритмов модерации, когда каждый третий нормальный результат попадает под раздачу.
Среди базовых настроек Qwen нет поддержки NSFW-генерации. Модель исходно не обучали создавать такие изображения. Но если вдруг система усомнится в корректности картинки, она просто мягко "очистит" сомнительные детали. Ни резких банов, ни тотальных блокировок — продолжаешь работать, творить и экспериментировать.
От этого выигрывают прежде всего дизайнеры и иллюстраторы, которым не хочется спотыкаться о случайные запреты. Владельцы сайтов, маркетологи, художники — все, кто привык сам контролировать рабочий процесс, по достоинству оценят Qwen. Полная свобода творчества, никакого неожиданного стоп-сигнала посреди работы. Проверил лично — работать стало намного комфортнее.
Переходим к самому сочному — что умеет Qwen с изображениями.
Свои фотки можно заливать и тут же экспериментировать: обработка, эффекты, стилизация — всё под рукой. Вот мой личный топ возможностей, которые уже доступны, и тех, что тестируются:
Замены одежды + замена окружения, а лицо остаётся вашим. Midjourney и Sora Images до такого не дотянули — специально тестил и сравнивал.
[скоро] Склейка нескольких фото в один кадр, как у Sora Images. Лично жду эту штуку для коллажей и “до-после”.
[скоро] Примерка одежды прямо по снимку: загружаете свой образ и вещи — сервис сам подберёт, что и как сочетается. Для маркетплейсов и продавцов просто находка.
[скоро] Глубинные карты, как в ControlNet, для полного контроля, чтобы результат был предсказуемым.
[скоро] Настройка позы через OpenPose — изменяете позу, двигаете руки, настраиваете композицию до самых мелочей.
Преобразование стиля: по желанию превращаю обычное фото в аниме-персонажа, пиксель-арт или олдскул-иллюстрацию. Всё работает по запросу.
Оживление старых фото одним кликом. Архивные снимки реально преображаются — пробовал на семейных сохранениях.
[бета] Outpaint — дорисовывает края кадра по вашему описанию. Пока в тестах, но круто расширяет возможности.
Свои чёрно-белые фотографии легко превращаю в цветные. Особенно круто для семейных архивов — сам удивился результату.
Восстановление фотографий без перекраивания лица — характер человека полностью узнаваем.
Генерация трёхмерных моделей прямо c картинки — дизайнеры и моделлеры оценят.
[бета] Вырезка одежды с фотки — функция ещё нестабильна, но если её допилят, маркетплейсам будет за что зацепиться.
Удаление водяных знаков в пару кликов — рабочий инструмент для тех, кто с визуалом работает каждый день.
Быстрая смена фона. Например, делаю белый фон для карточек товаров за пару секунд.
Гибкое редактирование по любым промптам — описываете словами, какими хотите видеть изменения, Qwen воплощает пожелания в жизнь.
...и это далеко не всё. Открываются почти безграничные горизонты: только вы решаете, что именно делать с вашими снимками. Достаточно сформулировать, какой результат нужен — и система быстро выдаёт ответ.
Но и это ещё не предел — впереди ещё несколько крутых функций, о которых стоит рассказать:
Когда меняете референс, лицо человека само по себе не поменяется. Только если вы не укажете это явно в промпте. Оригинальное лицо никуда не денется, оно останется.
Умеет не только по-английски, но и по-китайски. При этом фразы разбивает чётко — на блоки, как нужно. Хотите стильную обложку журнала? Легко. Можно задать отдельный заголовок, название журнала, добавить любые информационные вставки — как вам удобно.
Qwen поддерживает работу с LoRA (Low-Rank Adaptation). Это даёт возможность пополнять знания модели с помощью специальных LoRA-модулей. Скачали интересную LoRA на civitai.com — и просто подгрузили её в Yes Ai Bot через Telegram. Всё, ваш искусственный интеллект стал ещё умнее.
Недостатки нейросети Qwen Images
Недостатки нейросети Qwen Images
Qwen — не волшебство, а ИИ с понятными границами возможностей. Все мифы мгновенно развеиваются, когда начинаешь работать с этим инструментом на практике.
Вот с какими трудностями реально сталкивался лично и что замечают пользователи:
Outpaint (дорисовка) иногда шалит: свежедобавленные фрагменты резко выбиваются по стилю или содержанию. Спасти ситуацию можно, но иногда приходится настраивать параметры и даже редактировать вручную. Увы, идеального результата с первого клика не жди.
Qwen довольно прожорлив к «железу». Минимум — видеокарта уровня NVIDIA 3090, комфортно — 4090 или даже 5090. Цены, мягко говоря, немаленькие. Но не всё так грустно: если потянуть апгрейд ПК не по карману, часть функционала работает прямо в Telegram через бота @yes_ai_bot. Для старта хватает обычного смартфона.
Иногда Qwen меняет детали изображения без просьбы: появляется неожиданный фон или новые объекты. Бывало, просишь одно, а в ответ получаешь сюрпризы на картинке. Такие «художественные вольности» сложно контролировать, и они раздражают.
Словарный запас у Qwen скромнее, чем у конкурентов. Сложные или редкие термины часто воспринимаются неправильно. Например, для специфических нишевых проектов или задач возможностей этой нейросети уже не хватает.
Qwen общается только на английском и китайском. На русском, увы, не работает, что для российского рынка — большой минус. Постоянно приходилось переключаться на другой язык, и это далеко не всем удобно.
Как генерировать изображения через Qwen Images
Покажу на примере — будем работать с Telegram-ботом @yes_ai_bot, который умеет использовать нейросеть Qwen Images.
Заходим в Telegram, находим бота @yes_ai_bot
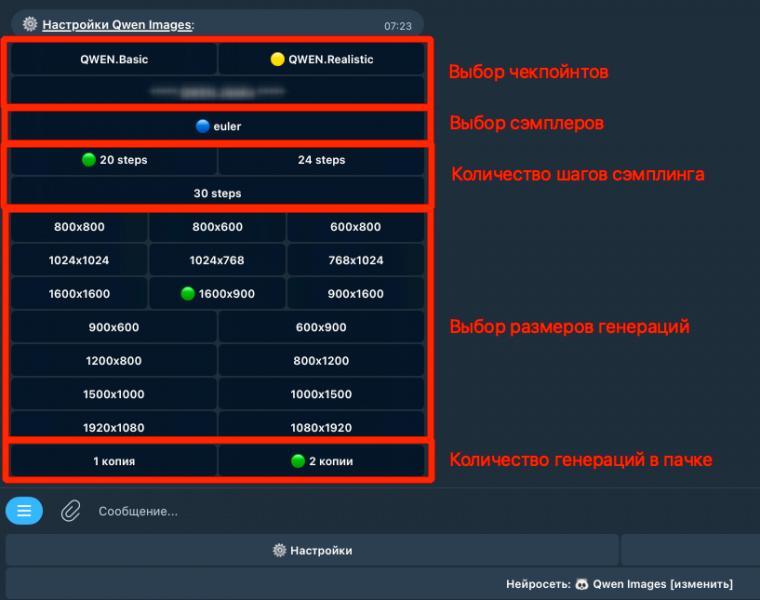
В настройках подбираем параметры под себя: выбираем подходящий чекпойнт (версию модели). Устанавливаем количество шагов генерации — для большинства задач достаточно 20 шагов, этого хватает с головой. По желанию можно задать размер изображения в пикселях и определить, сколько картинок бот сделает за один раз.
Не хочется тратить время на придумывание сложных промтов? В галерее есть уже готовые стили — просто выбирайте тот, что нравится. Удобно, все шаблоны сразу под рукой.
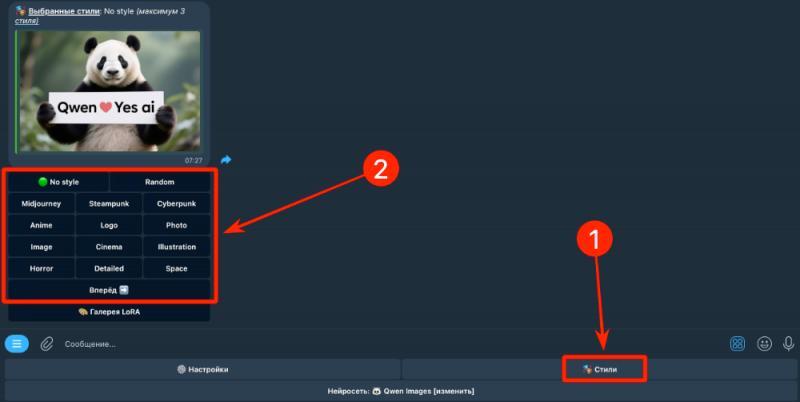
Работать с Yes Ai можно на любом языке. Пишите запрос так, как удобно, хоть по-русски. Сервис переведёт всё на английский сам — не надо думать о правильном синтаксисе или искать переводчик.
Настроить нейросеть Qwen Images можно буквально за пару минут:
Чекпойнт модели. Это основа будущей картинки. Каждый чекпойнт — отдельная стилистика, свой уникальный датасет. Например, если хочется фотореализма, ставьте чекпойнт, который «умеет» фотостиль. Для анимации — другой. Под вашу задачу всегда найдётся подходящий.
Количество шагов генерации. Больше шагов — проработаннее детали, четче результат. Например, быстрая генерация — 8-12 шагов. Для сложной картинки с деталями ставлю 20. Лично для меня это оптимум между скоростью, ценой и качеством.
Формат. Выбирайте нужные пропорции: квадрат 1:1, вертикаль 9:16 для историй, классический 16:9 для заставок и превью. Сразу видно размеры в пикселях — удобно подбирать под соцсети или сайт.
Количество изображений. Можно сгенерировать одну картинку, а можно сразу несколько. Иногда сравниваю два варианта одной идеи — часто выходит совершенно разный стиль и атмосфера.
Затрудняетесь с выбором промпта? Загляните на наш форум. В открытой бесплатной галерее собраны десятки удачных вариантов — листайте, выбирайте, вдохновляйтесь.
Генерация изображений с помощью Qwen Images и LoRA на практике
Чтобы получить иллюстрацию через Qwen Images вместе с LoRA-моделью, действуйте по классической схеме — всё просто и понятно. Главное отличие: в запрос добавляем специальный ключ. Он указывает системе, какую конкретно LoRA-подмодель подключить и насколько сильно её влияние должно проявляться.
Пример промпта для Qwen Images с использованием LoRA:
Панда ест лапшу из миски <lora:1938784:1.1> pixel art in 2dhd octopath traveler style
Разберёмся, как это устроено.
Запись <lora:1938784:1.1> состоит из двух важных частей. Число "1938784" — идентификатор конкретной LoRA-модели с сайта civitai.com. По этому номеру находится именно тот стиль, который вам нужен.
Вторая часть — "1.1" — это, по сути, регулятор силы воздействия выбранной модели на финальную картинку. Чаще всего используются значения от 0.7 до 1.5. Хотите, чтобы влияние было заметнее? Повышайте цифру.
Фразы вроде "pixel art in 2dhd octopath traveler style" — это так называемые ключевые слова. Они подсказывают нейросети, как должен выглядеть ваш итоговый результат, и задают визуальное направление генерации.

Где найти номер LoRA для нужных ключей?
Самый удобный вариант — открыть галерею моделей LoRA в Yes Ai Bot. Это почти хранилище с уже подобранными вариантами, которые пробовали другие пользователи. Нужный ключ можно просто скопировать прямо из списка. Учтите, если в карточке модели прописаны специальные триггер-слова, обязательно добавляйте их к своему промпту. Обычно такие фразы выделяют отдельно, чтобы вы их не пропустили — иначе выбранная LoRA не будет работать так, как надо.
Как загрузить модель Qwen LoRA с Civitai в галерею Yes Ai
В стандартном списке Yes Ai не нашлось нужной нейросети? Решение есть — добавить свежую модель с платформы Civitai. Это огромная база нейросетевых решений со всего мира.
Вот что нужно сделать. Для начала определитесь, какую модель хотите использовать — например, для генерации текстов или изображений. Дальше переходите на https://civitai.com/models.
Чтобы не потеряться среди тысяч вариантов, воспользуйтесь фильтрами: установите «LoRA» и «Qwen». В списке появятся только модели, которые подходят по вашим критериям. Выберите нужную — дальше процесс добавления в галерею Yes Ai займет всего пару минут.
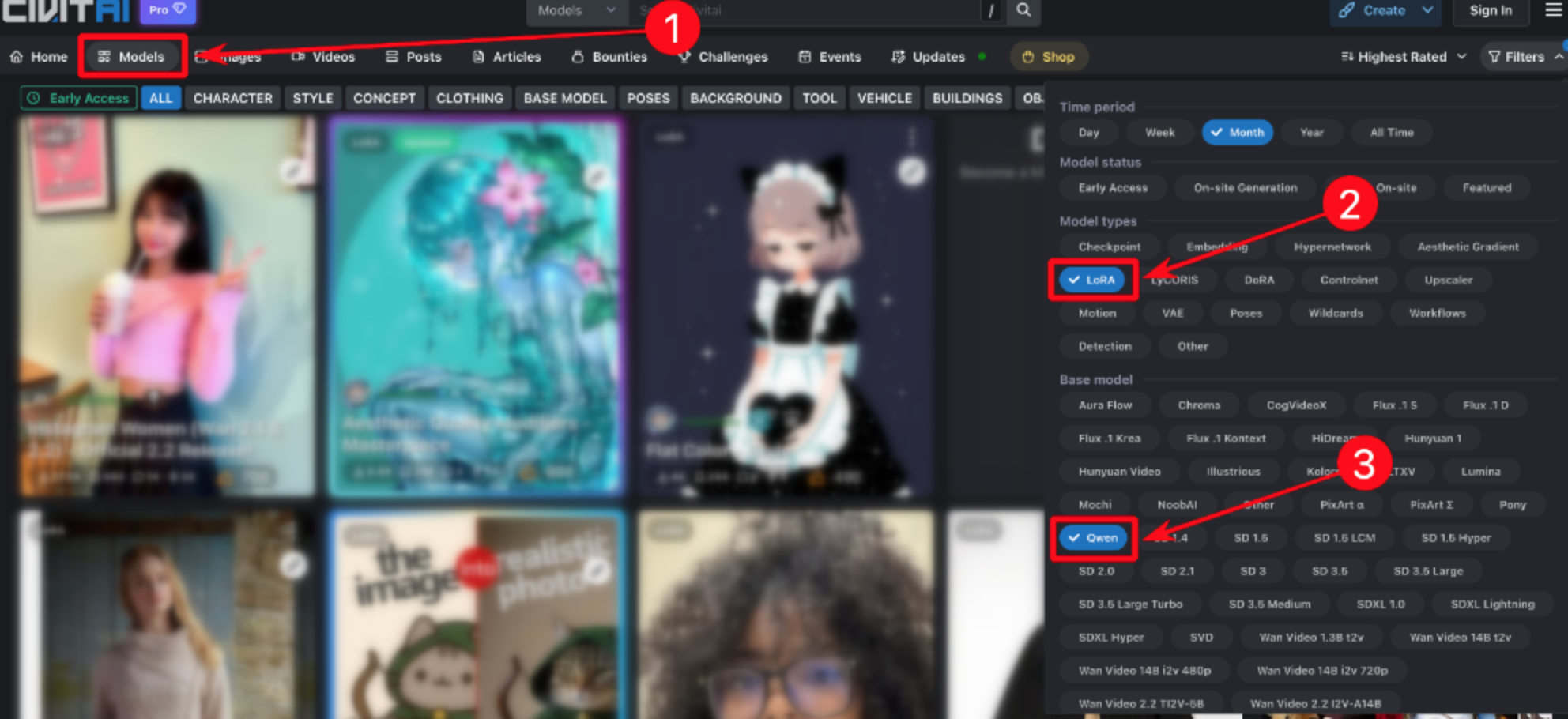
Открываете список моделей — выбираете ту, что подходит по стилю и набору функций. Не ленитесь заглянуть в описания: авторы обычно подробно разбирают, что умеет каждая LoRA-модель на практике. Как только определились, кликаете на карточку, копируете ссылку из браузера, например: https://civitai.com/models/1938784/2dhd-pixel-art-octopath-s...
Сразу отправляете эту ссылку боту Yes Ai в Telegram. Бот всё обработает сам — новая модель появится в вашей галерее минут через пятнадцать, а чаще ещё быстрее. Если берёте что-то на Qwen, обратите внимание: нужны только модели, где явно указано “Base model: Qwen”. До отправки проверьте, что в нижнем меню бота выбрана нужная нейросеть — должна быть надпись “Нейросеть: Qwen Images [изменить]”.
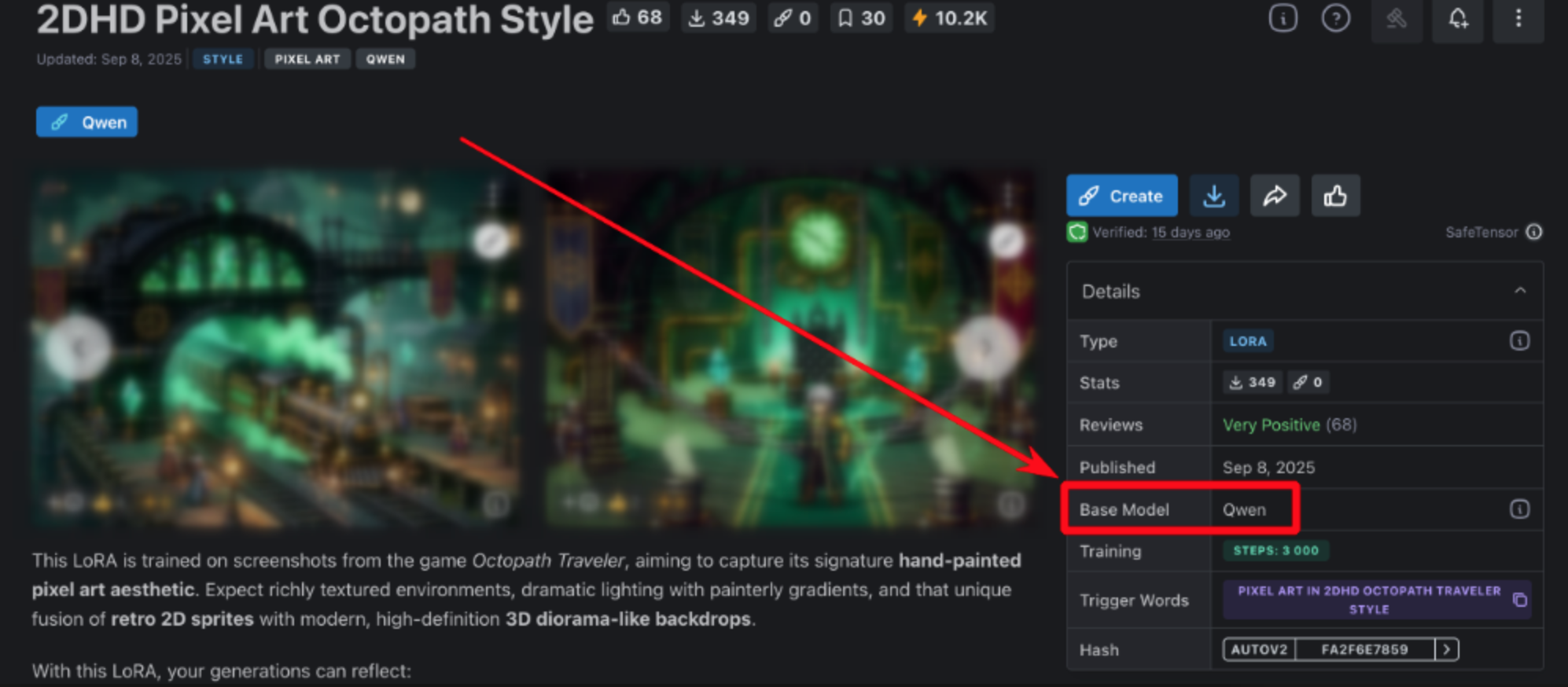
Когда LoRA уже подключена, промпты с соответствующим ключом начинают работать мгновенно. Для примера, вся команда выглядит так: <lora:1938784:1> Здесь 1938784 — это идентификатор выбранной модели, который всегда виден в ссылке при копировании из Civitai.
Однако это только первый шаг. Помимо ключа важны ещё и триггерные слова — их обязательно публикует сам создатель модели. Без них LoRA зачастую вообще не реагирует или выдает странные результаты. Поэтому совет: всегда ищите в описании или профиле автора список этих слов. Обычно они выделяются отдельно — запоминать их не надо, но держать под рукой обязательно.
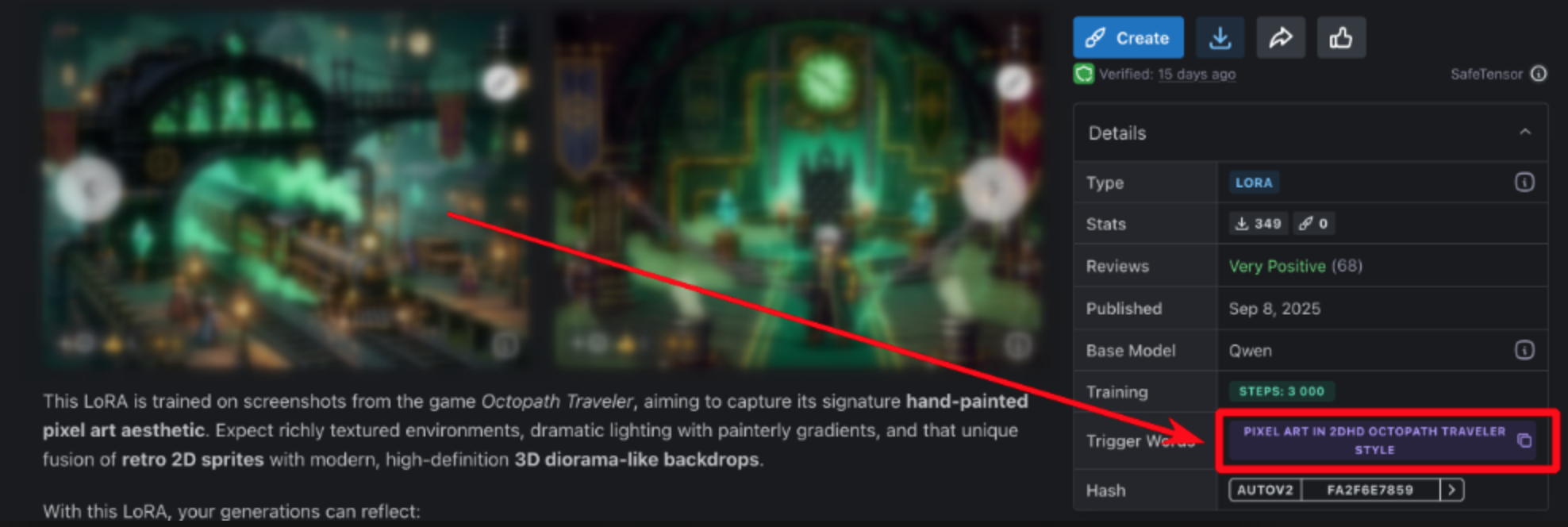
Триггерные слова — это специальные команды, которые вы вставляете в запрос. С их помощью LoRA понимает, что именно от неё хотят. Эти слова — как ключ, который открывает нужные функции нейросети.
Для этой модели есть свой уникальный триггер:
pixel art in 2dhd octopath traveler style
Собираем всё воедино: нужен промт для генератора изображений, чтобы получилась панда за поеданием лапши.
панда кушает лапшу из миски <lora:1938784:1> pixel art in 2dhd octopath traveler style
Многих интересует: можно ли совмещать разные языки внутри одного запроса? Например, написать основную часть промта по-русски, а триггер вставить на английском.
В Yes Ai это не проблема — смешивайте языки как хотите, главное, чтобы суть была понятна. Алгоритмы корректно воспринимают и обрабатывают такой микс.
Другое дело — работа с Qwen на личном ПК. Здесь лучше не рисковать: старайтесь сразу переводить весь промт на английский, чтобы избежать непредсказуемых результатов.
Как выбрать весовой коэффициент для LoRA и зачем он вообще нужен
Весовой коэффициент в LoRA отвечает за то, какую роль выбранная модель сыграет в вашей генерации. Проще говоря: чем выше значение, тем ярче выражены особенности, которые заложены в конкретной LoRA. Слишком высокий коэффициент – рискуете получить сильно перекрученный или неестественный результат. Слишком низкий – эффект модели окажется почти незаметен.
На практике всё просто. Возьмём пример с Yes Ai Bot: вы прописываете идентификатор модели и коэффициент прямо через двоеточие, вот так — <lora:1938784:1.2> Число 1.2 как раз и задаёт “силу” влияния вашей LoRA. Чем ближе это значение к единице или чуть выше, тем отчётливее результат. Обычно большинство пользователей крутится в диапазоне от 0.7 до 1.5. Это своего рода золотая середина – здесь модель уже видна, но картинка сохраняет гармонию.
Но всё индивидуально. Кто-то стабильно использует LoRA с коэффициентом 0.6 для едва заметной стилизации. Встречал заказчиков, которым по душе агрессивные стили — для таких без 2.0 не обходится. Так что, в первую очередь, смотрите на совет автора модели. Часто хорошие LoRA сопровождаются краткими гайдлайнами от тренера.
Зайдите на страницу модели на Civitai — многие создатели честно выкладывают рекомендуемые значения веса LoRA в описании.
Откройте примеры работ на той же странице. Под картинками часто указывают промпты и точный параметр веса, который помог получить такой результат.
Если ни среди советов в описании, ни под тестовыми изображениями не встретился подходящий вариант — выберите вес 1.0 и посмотрите, что получится. Не стесняйтесь играть с настройками: постепенно уменьшайте или прибавляйте значение, пока не увидите подходящий эффект.
По личному опыту: идеальный результат с первого раза — большая редкость. С генеративным AI важны терпение и готовность пробовать разное. Пара лишних итераций — нормальная часть творчества, а не напрасная трата времени.
Хотите быстро подобрать промпты, которые реально работают? На нашем форуме мы собрали специальную галерею — там вы найдёте десятки живых примеров для Qwen Images. Каждое решение проверено на практике. Все нужные настройки тоже указываем. Остаётся только выбрать подходящий вариант и использовать у себя.

Если базовые генерации через промпты и настройку LoRA уже освоили — отлично, двигайтесь дальше! Остались вопросы или хочется поделиться своими наблюдениями? Пишите напрямую в Telegram: https://t.me/yes_ai_talk Не тратьте время на эксперименты в пустую — используйте опыт сообщества.