

Найден способ уверенно распознавать дипфейки?
Современные нейросети умеют создавать настолько правдоподобные изображения, что их порой сложно отличить от реальных фотографий. Такие изображения, называемые дипфейками, могут быть любопытными и забавными, но лишь до тех пор, пока все понимают, что это подделка. Когда же кто-то пытается выдавать дипфейки за чистую монету, они становятся большой проблемой.

С их помощью можно нанести ущерб репутации, повлиять на общественное мнение и даже сфабриковать подложные доказательства для суда. Поэтому, как только появились нейросети, умеющие производить дипфейки, сразу началась разработка алгоритмов, которые были бы способны их распознавать.
Задача осложняется тем, что для создания дипфейков обычно используются генеративно-состязательные нейросети (Generative Adversarial Networks, GAN). Их работа изначально основана на противостоянии двух нейронных сетей, одна из которых генерирует картинки, а другая старается определить, настоящие они или нет. Обе эти сети обучены на больших массивах реальных фотографий. Если изображение выглядит неправдоподобно, вторая нейросеть заставляет первую изменять его до тех пор, пока оно не перестанет идентифицироваться как подделка.
Получается, что дипфейки изначально создаются такими, что существующие системы распознавания не могут уверенно отличить их от реальных фотографий. На сайте thispersondoesnotexist.com вы сами можете оценить, насколько правдоподобно выглядят сгенерированные нейросетью несуществующие люди.
Алгоритмы по распознаванию дипфейков обычно используют свёрточные нейронные сети, которые умеют выделять характерные признаки. Эти нейросети обучают на самих изображениях в явном виде, что требует много времени и ресурсов. Однако коллектив исследователей из Института информационной безопасности им. Хорста Гёрца при Рурском университете в Бохуме предложил более простое и изящное решение этой проблемы. Учёные решили подвергнуть изображения частотному анализу, использовав давно известный метод дискретного косинусного преобразования. Он применяется, например, в алгоритме сжатия JPEG. Изображение в этом случае рассматривается как результат наложения гармонических колебаний различной частоты, взятых с разными коэффициентами. Примерно так:

Эти коэффициенты можно визуализировать в виде прямоугольной тепловой карты, верхний левый угол которой соответствует низкочастотным областям исходного изображения, а нижний правый — высокочастотным. Реальные фотографии в основном состоят из низкочастотных колебаний.

Реальная фотография и её спектрограмма
Если же явные всплески наблюдаются в высокочастотной области, это может свидетельствовать о том, что изображение — подделка. А если они ещё и формируют регулярную структуру — тут как говорится, и к гадалке не ходи.

Дипфейк и его спектрограмма
Чтобы проверить эффективность предложенного подхода, учёные составили тестовую выборку из 10 000 изображений, куда вошли сгенерированные нейросетью StyleGAN портреты несуществующих людей и реальные фотографии из набора Flickr-Faces-HQ (FFHQ). Всё это можно найти на сайте whichfaceisreal.com. Успех был абсолютным: алгоритм распознал все дипфейки до единого!
Более того — выяснилось, что он с большой долей вероятности позволяет определить, с помощью какой именно нейросети было сгенерировано изображение. Дело в том, что каждая из них имеет свой «отпечаток» в частотном диапазоне.
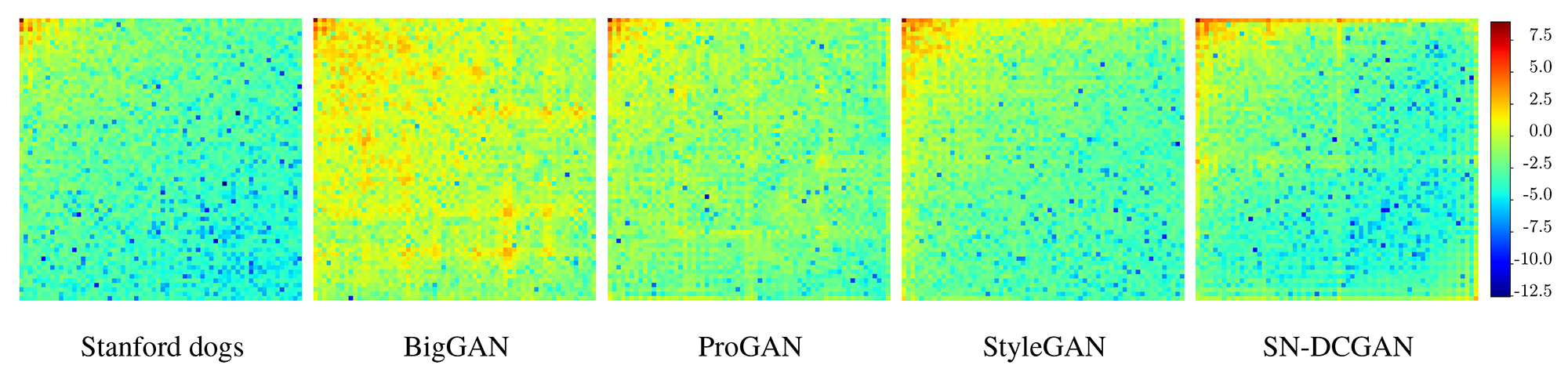
Спектрограммы реальных фотографий из набора Stanford Dogs (слева) и изображений, сгенерированных нейросетями различных архитектур, которые были обучены на этом наборе (четыре справа). Усреднённые значения для 10 000 изображений
Откуда же берутся эти всплески в высокочастотных областях? Оказывается, что они неразрывно связаны с самим принципом действия генеративно-состязательных нейросетей. В основе их работы лежит процесс так называемого апсемплинга, то есть отображения данных из пространства низкой размерности в пространство высокой размерности. Например, сеть StyleGAN, создавшая все дипфейки с людьми из этого поста, формирует в пространстве данных изображение размером 1024 × 1024 пикселя (более миллиона значений) на основе вектора из скрытого пространства, имеющего размерность всего-навсего 100. Если же попытаться обойтись без апсемплинга, то объём вычислений, необходимых для генерации дипфейков, вырастет до астрономических величин.
В данной статье учёные подробно рассмотрели лишь один набор данных и одну архитектуру нейросети. Однако они утверждают, что предложенный метод универсален и будет работать не только для всех существующих сетей типа GAN, но и для тех, что появятся в будущем. Так ли это, станет ясно уже довольно скоро.
P. S. Это очередная новость с семинара «Актуальная наука» в Политехническом музее. Я буду стараться публиковать их каждую неделю.




Искусственный интеллект
5.7K поста11.9K подписчика
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан