
Как я решил сделать мобильное приложение[Part 2]
Исходный код парсера и остальных компонентов приложения положил под систему контроля версий git, в качестве бесплатного хостинга приватных репозиториев я использовал github. В принципе, ничего сложного в настройке нет, создал репозиторий на github и проинициализировал его локально:

После этого развернул локально базу данных mysql в локальном k8s-кластере с помощью minikube + helm(взял 3 версию, до этого использовал 2, из явных плюсов увидел только отсутствие tiller)+ чарт bitnami/mysql(конфигурацию чарта опущу, там все по-умолчанию):



Спроектировал структуру базы данных, получилась не очень красиво, из-за большой вариативности данных, но это можно переделать потом:


Пара заметок по структуре базы данных:
- таблица recipe_parser и некоторые вспомогательные поля нужны для сохранения прогресса парсинга сайта между перезапусками парсера
- выбрал кодировку utf8mb4, потому что в контенте достаточно много emoji, и обычный utf8(трехбайтовый) их не может хранить
За структуру проекта для парсера, я взял golang-standards/project-layout. В принципе для такого мелкого приложения его можно было не использовать, но может кому-то будет полезно знать что есть такая штука, когда будет думать как структурировать проект. Получилось как-то так:
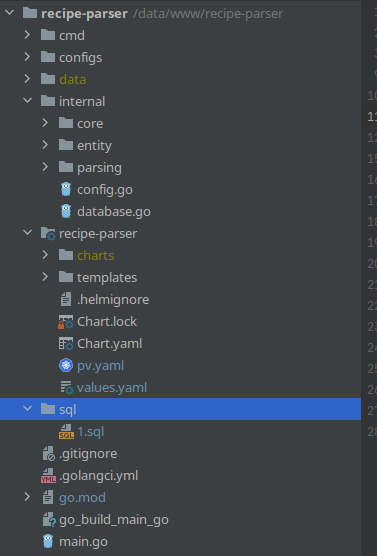
Соответственно:
* recipe-parser - это helm-чарт который я создал выше
* sql - папка с миграциями
* data - это папка с данными базы данных, ее необходимо хранить на хосте, чтоб не потерять данные если мой локальный кластер случайно удалится
* все остальное - код связанный с парсингом, конфиги, команды
Для написания самого парсера я использовал следующие пакеты:
- PuerkitoBio/goquery - для парсинга DOM страниц
- jmoiron/sqlx - для работы с базой данных
- sirupsen/logrus - как логгер
- spf13/cobra - для создания команд
- spf13/viper - для конфигурации приложения(yaml в папке configs)
Сам код парсера не вижу смысла выкладывать(технически он несложный), получились такие этапы:
- спарсить категории/подкатегории и записать в базу
- спарсить ссылки рецептов и записать в базу
- скачать все страницы с рецептами и записать на диск(кстати получилось достаточно много, почти 9gb данных):

- считать с диска страницы, распарсить и записать в базу данных
Везде где можно, я параллелил задачи с помощью горутин и буферизированных каналов для контроля количества потоков. Также на сайте присутствовала защита от ботов, но я ее обошел за счет того, что она работала неправильно. В результате получил на выходе базу данных с ~500 категориями и ~90к готовых рецептов с заголовком, описанием, картинками и шагами приготовления. Еще было бы неплохо выкачать все картинки и закинуть в свое облако(использую space от digital ocean), но это пока можно отложить.
На написание парсера и сам парсинг я потратил примерно три вечера. Конечно все то что я описал можно было не делать, но те базы данных что продаются в интернете гораздо меньше и хуже структурированы чем то что я собрал сам, тем более я получил кучу полезного опыта в процессе. С радостью отвечу на ваши вопросы, некоторые моменты я опустил, чтоб пост не получился сильно большой.
В следующем посте собираюсь написать небольшой бекенд на php (и конечно засунуть все в docker :) , с которым будет работать мобильное приложение.