

Relict Engine
53 поста
53 поста
12 постов
триада WVP (World, View, Projection) так-же перенесены на DSA
Добавлена поддержка нескольких активных сцен (миров)
Добавлен класс камеры
исправлено неопределенное поведение при обновлении трансформации юнита сцены (синхронизация состояний трансформов в начале кадра)
В очередной раз отваливался по рабочим вопросам =/ Но, вроде, вернулся. Чендж лог сегодня очень небольшой по этой-же причине.
Итак, миры и камеры.
Мир определяется рут объектом GameWorld, который хранит все объекты сцены, камеры итд.
Камер у сцен может быть сколь угодно много, но активной одномоментно (во всем движке) может быть только одна (дальше будет сделано исключение для RenderTarget камер, но это отдельно). При этом, сцена без активной камеры продолжит свою работу в фоне. Она продолжит тикать, обновляется, пересчитывается. Просто не будет выводится на экран.
Переключение камер происходит функцией Activate соответствующего Юнита.
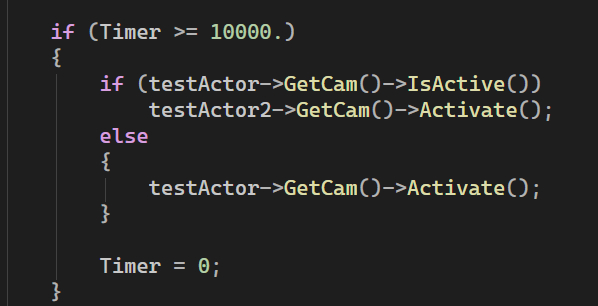
как пример, каждые 10 секунд мы переключаем активную камеру между первым и вторым акторами
При этом, если камера принадлежит другой сцене, то сцена так-же переключится.
Удален юнион UniformValue, как ненужный и не используемый
Заменена функция Set на шаблон с предопределёнными типами для удобства
UniformType удален из движка и используется только для разбора входных динамических параметров материала в RatTools
Замены легаси OpenGL буферы на DSA в коде создания динамических экземпляров (Instancing) материалов
Создание инстанций, кроме инстанции по умолчанию, теперь используют прямое копирование данных на стороне GPU, заместо заполнения буфера через шину
Добавлена заготовка под шейдерный домен Surface на основе физически корректного рендеринга (PBR)
Думается мне, тему инстансов на этом можно закрыть. Оно работает как нужно, параметры определяются, обновляются, читаются и рисуются ровно так, как требуется.
Для закрытии самой темы материалов осталось реализовать только вставки пользовательского кода в скрипт материала. Думаю, завтра/послезавтра уже сделаю. SPIR-V контейнеры отложим в долгий ящик. Сейчас это явно не приоритет.
Следующий этап - класс камеры и юниты источников света (чтобы можно было начать полноценную работу над PBR)
Ассет материала теперь содержит отдельный блок с возможными вводными параметрами шейдера по умолчанию отдельно от юниформов шейдера меатерила
В шейдер введен макет std140 для юниформов
Добавлен отдельный класс в модуле рендера для работы с инстанциями материалов через Uniform Buffer Object (UBO)
Для материалов, имеющих хотя бы один input параметр создается инстанция по умолчанию со значениями юниформов по умолчанию, с запретом на изменение
Добавлено "ленивое" создание инстанций на стороне модуля отрисовки по мере необходимости
Исправлена синхронизация потоков при передаче параметров инстанции материала. Теперь утилизируется uniq_cmd потока отрисовки вместо прямой установки
Переделал инстанции материалов на UBO. Все еще считаю их несколько сырыми и буду их еще какое-то время тестировать и дописывать их код. Кратенько опишу как это работает.
Во первых: UBO требует в шейдере макетной структуры, и поля в ней не могут иметь инициализаторов, поэтому пришлось написать довольно массивный парсер параметров с утилизацией variant и type_identity

glsl именной uniform макет
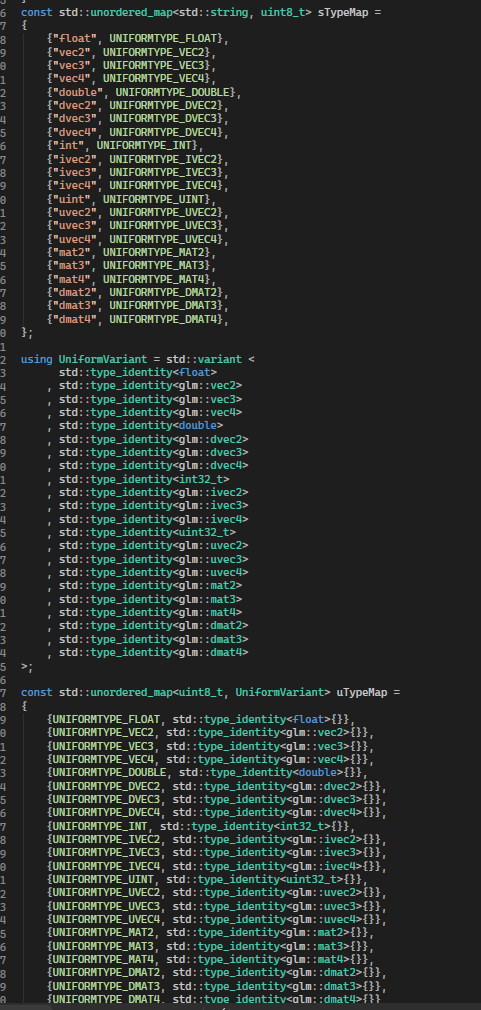
сущности парсера инпутов при импорте материала в движок через RatTools
Во вторых: эта структура требует выравнивая данных, поэтому, уже на стороне движка пришлось делать особую уличную магию перегоняя сырой буфер в выровненный cогласно стандарту
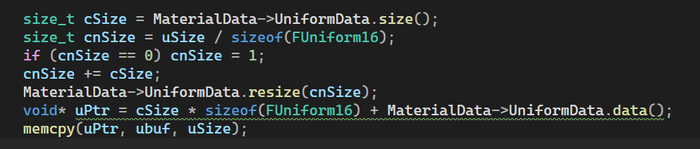
msvc считает что она дофига умная и настойчиво требует cSize обернуть в sizeof()
В третьих: чтобы не пересоздавать UBO буфер каждый раз, пришлось высчитывать офсеты юниформов и хранить их отдельно в виде пары офсет-размер. Таким образом при изменении одного параметра, в GPU отправится только он.
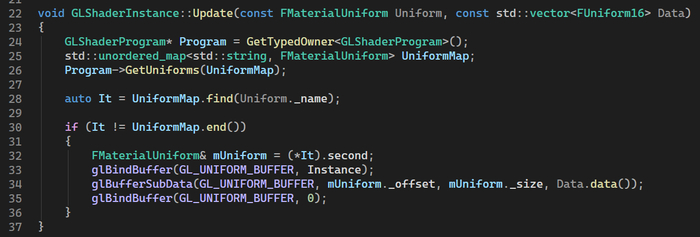
а вот от текстовой метки до конца так и не удалось избавится, благо у unordered_map итерация идет как 0(1)
ну и в четвертых, т.к. действие происходит сразу в двух потоках (игровом и отрисовки), то на выходе получается довольно много операций копирования (ссылки не доживают до исполнения очереди)
В общем снова на очереди вычитка, удаление старого кода, правка нового. Что-то упростить можно, структуры собрать в одном месте, чтобы не были раскиданы по юнитам. Возможно, выбросить нафиг union, ибо от него сейчас пользы никакой уже, но зато сильно меньше удобства при обновлении переменной юниформа, или обертку над ним хотя бы сделать удобства для.

было/стало. SetVector3 выглядит как-то более удобоваримо
Добавлена смена рабочий директории на необходимую (давно надо было сделать, но все забивал)
Добавлена первая итерация материал инстансов (в очень сыром виде, но работает)
Касательно инстанций, значит. Передал несколько класс шейдера. Пока по тупому, в лоб. На выходных надо будет все это просмотреть, вычитать еще раз, и переписать по человечески. А работает это так:
При инициализации контекста дергаются ассеты материалов на загрузку. и передаются в GLShaderProgram
GLShaderProgram это дело компилирует, проверяет и линкует (когда-нибудь потом будет добавлен кэш, но пока рассчитываем на кэш драйвера)
После этого проходится по инпутам, собирая их в 100500 мапов
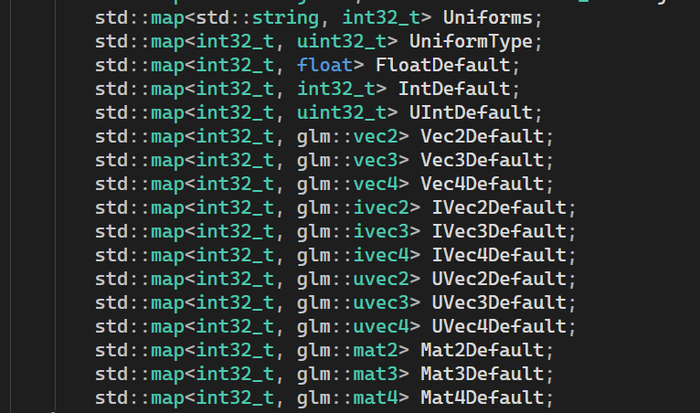
индуский код во всей красе, так еще и не все типы реализованы.
При отрисовке, если на юнит выставлен инстанс, а не сам материал, проверяет в таблице инстанса по текстовой (!) метке наличие установленного параметра.
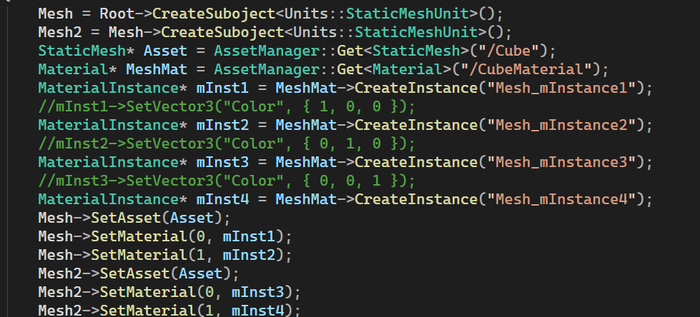
Выставляем инстансы, но не задаем параметры. При инициализации рассчитываем на дефолт юниформа в шейдере (но можно и выставить при желании)
Если текстовая метка присутствует в мапах класса инстанса (там столько-же мапов, по одному на тип), то передает в шейдер значение из него, если нет, то из таблицы дефолта.
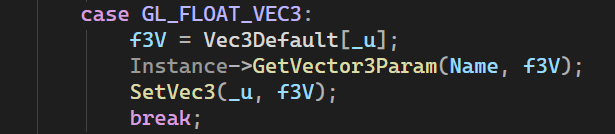
длинный и грустный switch. Я не буду показывать эту портянку
И, разумеется, текстовые метки опрашиваются в каждом кадре (что очень не есть хорошо). Нужно будет сделать какой-нить кэш для быстродоступа к нужным параметрам. Да подумать, как избавится от этих мапов, которые мне прям очень сильно не нравятся.
Но зато даже в таком виде оно работает.
Простенький примерчик:
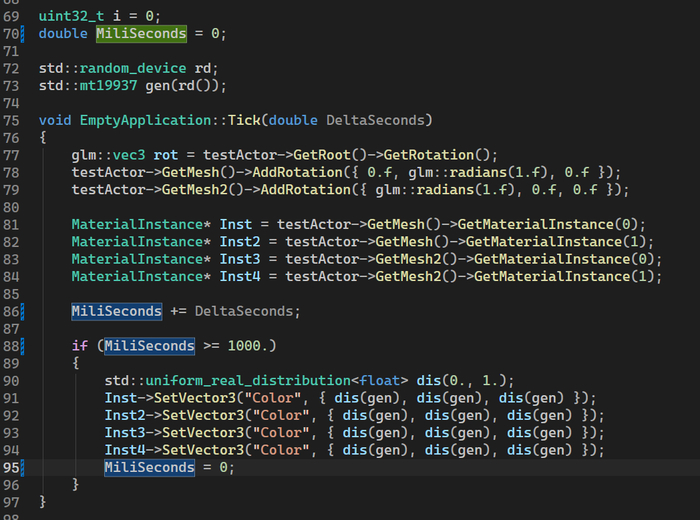
Меняем цвет кубиков раз в секунду
Добавлена заготовка под MaterialInstance
Добавлена обработка ключевого слова input в парсере скрипта материала
Добавлена дополнительная проверка и автоматический выбор параметра max_concurent_taks в случае, если в конфиге параметр равен нулю
Добавлено исключение, в случае, если процессор поддерживает менее 4х потоков
Добавлен программный ограничитель кадров в графическом потоке
Изменена сортировка рендера с сортировки по геометрии на сортировку по шейдерам для уменьшения кол-ва переключения контекста шейдеров OpenGL
Исправлена ошибка при запуске RatTools приводящая к полному запуску движка
Исправлено редкое исключение при обработке очереди AsyncTask разными потоками из-за неучтенного состояния гонки при проверке на пустую очередь
Готовлю движок для внедрения инстансов материалов, чтобы максимально сократить кол-во переключений контекста шейдера (материал == шейдер). Возможно еще проведу оптимизацию по vao - собирая определенные меши в один длинный буфер (сейчас один буфер - один меш + лоды). Однако там есть нюанс с динамической выгрузкой сеток и пересчетом индексов и вообще там не все так очевидно, да и прирост по кадрам не то чтобы прямо большой. Я бы даже сказал не заметный. Т.ч. возможно это того и не стоит, т.к. функция glBindVertexArray всего-лишь перещёлкивает указатель на уже загруженный в GPU буфер. Подумаю, в общем, ибо сейчас это не горит.
Особый класс, который можно создать как вручную, так и загрузив через заранее подготовленный ассет. Содержит перечень переменных со значениями для передачи через uniform шейдера. Привязывается к Материалу(шейдеру) и используется как надстройка над материалом для ускорения процедуры отрисовки.
Добавлен дополнительный интерфейс IThread
Добавлен класс GameThread
RenderThread перенесен из реликта RenderCore в Core
Все семейство классов Thread вынесена из фреймворка RelictClass в обычные классы
Исправлена работа сборщика мусора при удалении объектов с владельцем в другом потоке
Исправлена работа сборщика мусора при закрытие движка
Исправлено завершение потоков семейства Thread в Linux
Мультипоточность отлажена на столько, на сколько это на данном этапе возможно. Движок работает стабильно в обоих целевых ОС. Правда кое-что пришлось таки переделать. В частности Потоки теперь не являются частью фреймворка RelictClass, теперь это самые обычные Сишные классы. Появился дополнительный класс потока GameThread, который по факту не является потоком, но абстракцией над основным потоком приложения. Соответственно изменены и метапараметры RelictClass. Теперь заместо класса потока передается указатель на объект потока. Это добавит в будущем немного сложности, если нам понадобятся пул воркеры, но на данном этапе это сильно упростило жизнь при синхронизации объектов.
Добавлен интерфейс IWorkerThread
Добавлен класс RenderThread
Добавлена обработка очереди сообщений
Добавлен функционал проверки текущего контекста потока в рамках привязанного контекста к мета классу
Добавлено ограничение по минимальному времени тика в главном потоке (по умолчанию 60 раз в сек)
Изменена работа Сборщика мусора для работы с разными контекстами потоков
Изменена работа тика ThreadManager таким образом, чтобы он мог тикать обособленно в каждом отдельном потоке
Изменена работа тикера для работы с разными контекстами потоков для правильной работы флагов ClassInitializer
Исправлен access_violation при удалении RenderObject в случае, если он привязан к уже удаленному VAO
Ну вот мультипоточность и заработала. Есть еще косяки в Сборщике мусора, и возможно еще по ходу дела вылезут, но тем-не-менее я доволен как слон.
Ну и результат на большом fps:
Давайте вернемся немного назад, а именно к посту Relict Engine: ThreadManager и DevLog 20250822, где я говорил о сущностях ThreadManager и AsyncTask. Теперь пришло время несколько расширить этот функционал.
В предыдущем девлоге я упомянул, что нужно развести основной поток и процедуру отрисовки. Собственно этим и займемся. Ведущим потоком у нас все равно будет выступать основной поток приложения (от этого как не крути никуда не деться), а рендер уйдет в отдельный поток со всеми своими объектами.
Основных проблем при работе с воркерами (потоки с бесконечным циклом) в нашем случае будет три:
Т.к. рендерер построен на фреймворке TRelictClass, то необходимо убедится, что экземпляр созданного класса не выходит за рамки контекста потока, для которого он был создан.
Вытекающее из первого: Сборщик мусора должен понимать, в каком потоке находится регулируемый им объект.
Передача данных из главного потока в рендер поток.
Ее предполагается решить, с помощью добавления дополнительной структуры в ClassInitializator
вида:
enum ThreadType : uint8_t
{ THREAD_MAIN = 0,THREAD_RENDER = 1 << 0,
THREAD_CUSTOM = 0xff
};
struct ThreadInitializer
{
ThreadType Thread = THREAD_MAIN;
uint64_t CustomThreadId = 0;
};
Таким образом мы сможем убедится, что создание/удаление экземпляров этого класса будет доступно исключительно в контексте указанного потока. Вызовы же функций, в случае, если они не являются потоко-безопасными, стоит ограничить специальными вызовами проверки контекста.
Как пример:
[Fatal] 2026-05-16 13:34:38.277 GMT+3 - Trying to create new object Relict::Renderer with name Renderer_S in incorrect thread context
Самым простым в данной ситуации решением, и т.к. сборщик мусора работает на событийной модели, будет создание своего собственно экземпляра сборщика для потока. Таким образом мы сможем гарантировать, что сборщик не попытается внезапно удалить объект, который обрабатывается в воркер потоке, и при этом мы сохраним функционал авто очистки мусора независимо от того в каком потоке мы находимся.
Передачу данных предполагается организовать с помощью очереди команд, представляющие из себя лямбда-функции и передающие в поток нужные данные. Так-же, в теории, механизм AsyncTask через делегат OnTaskFinished так-же сможет безопасно передать данные в нужный нам поток (но с нюансами).
Т.к. Relict Engine пишется на 20м стандарте C++, то нам доступны замечательные вещи: jthread и queue из std библиотеки. Таким образом, мы, в принципе, сможем отделаться лишь одной дополнительной сущностью - классом потока, в котором, через queue будет определена очередь команд на исполнение, контекст сборщика мусора и, собственно, цикличная функция обработки этого всего дела. Конечно нужно будет доделать ThreadManager, чуть поменять очередность инициализации движка, и Сборщик мусора (для определения контекста потока из которого его дернули). Мета объект Class оставляем в основном потоке - нам в принципе все равно из какого контекста его дергают, если это не создание или не удаление объекта. Так-же стоит организовать ограничитель частоты цикла потока с выводом параметра ограничения в конфиг.

