


PG_EXPECTO: инцидент PostgreSQL – 95% ожиданий DataFileRead из-за одного запроса
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Утилизация диска vdb достигла 99,9%, операционная скорость и ожидания СУБД резко выросли из-за неоптимального запроса с последовательным сканированием
Запрос, который убил скорость.
Предисловие
В статье разбирается инцидент производительности PostgreSQL. С помощью подхода PG_EXPECTO — сочетания статистического анализа, эпистемологической проверки фактов и процедурного скепсиса — удалось локализовать причину аномального роста ожиданий и падения эффективности дисковой подсистемы. Результатом стал прозрачный отчёт, где каждый вывод имеет статус уверенности: от «подтверждено» до «предположение». Ниже — ключевые выводы и рекомендации, которые могут быть полезны любому администратору PostgreSQL.
Инцидент производительности СУБД
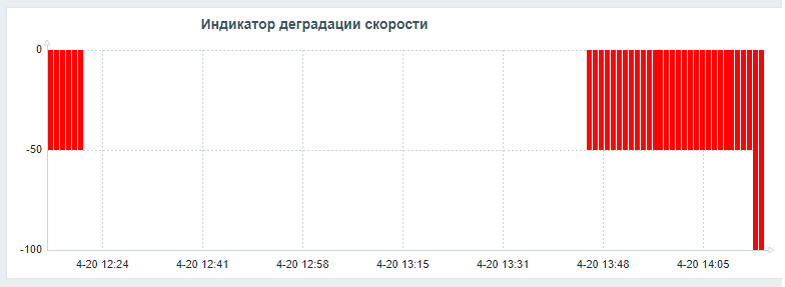
Рис.1 Инцидент производительности СУБД в панели Zabbix
Операционная скорость
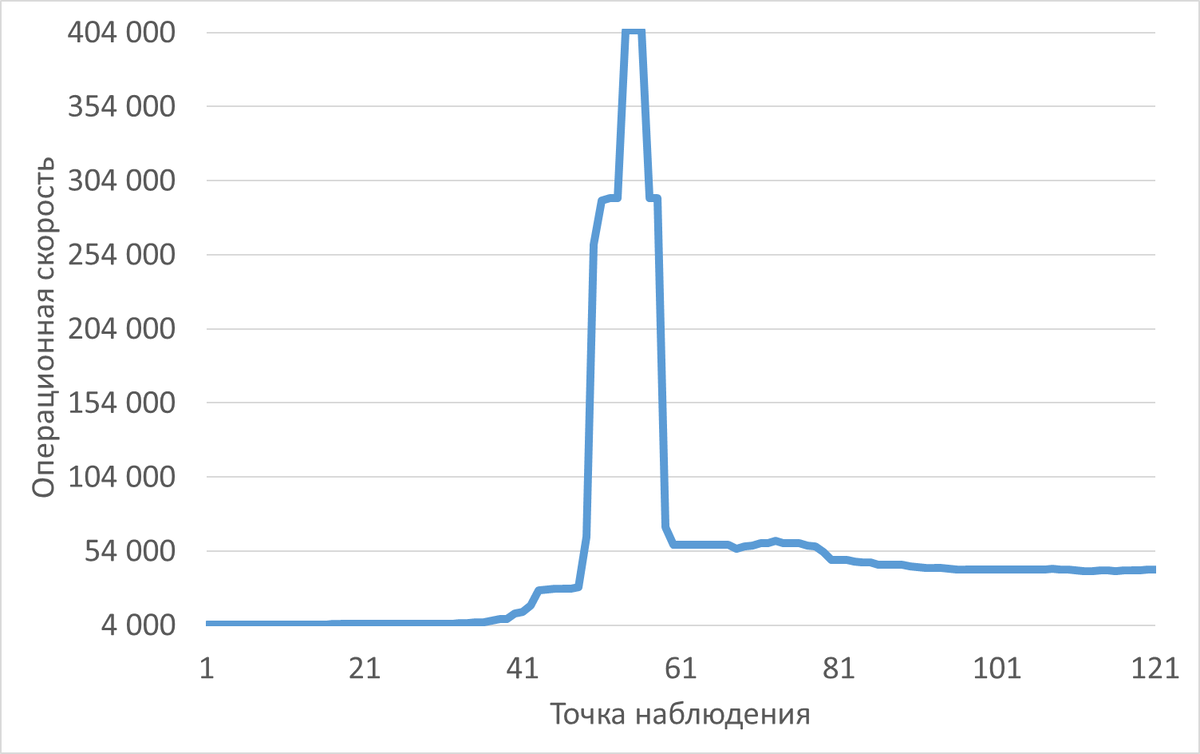
Рис.2 График изменения операционной скорости во время инцидента производительности СУБД
Ожидания СУБД
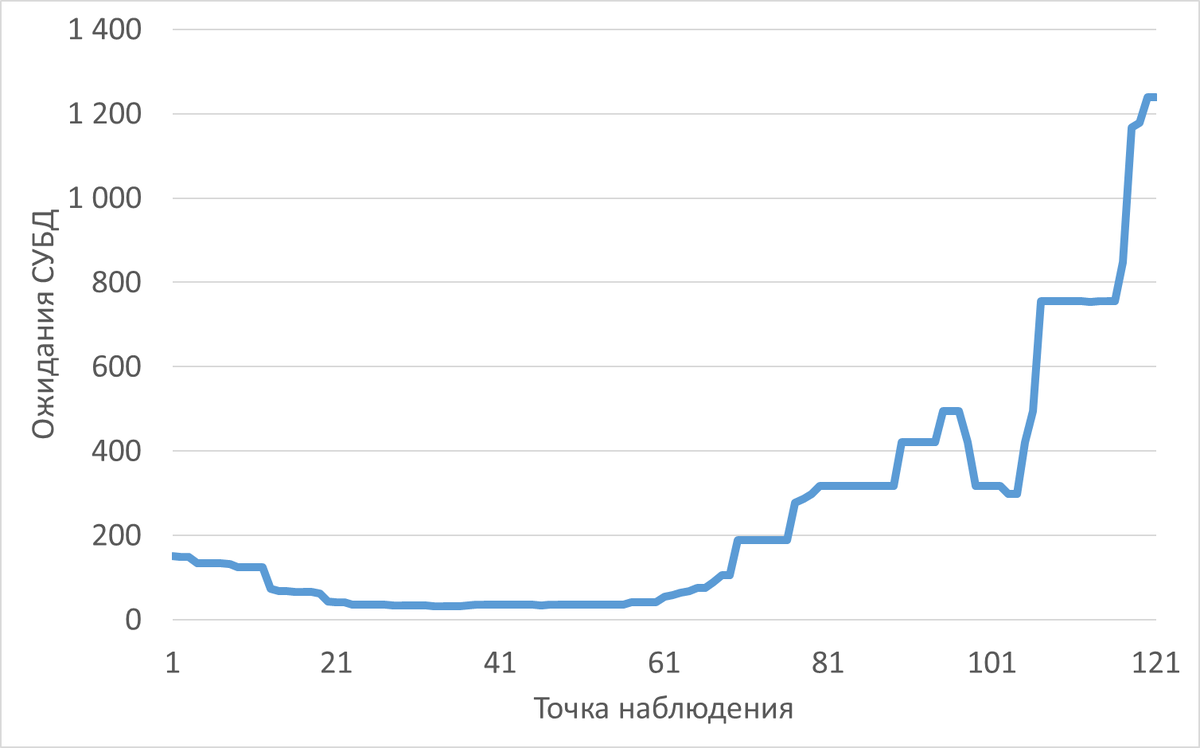
Рис.3 График изменения ожиданий СУБД во время инцидента производительности СУБД
Общая информация
Период анализа: 2026-04-20 12:16 – 14:16
СУБД: PostgreSQL 15.14
ОС/CPU: AstraLinux SE, 16 vCPU (Intel Xeon Skylake)
ОЗУ: 62.8 ГБ
Диски:
vdb (2 ТБ, /data) — данные
vdc (100 ГБ, /wal) — журналы предзаписи
Ключевые настройки PostgreSQL:
shared_buffers = 16 ГБ (Подтверждено)
effective_cache_size = 48 ГБ (Подтверждено)
work_mem = 12 МБ (Подтверждено)
random_page_cost = 1.1 (Подтверждено)
effective_io_concurrency = 300 (Подтверждено)
В тестовый период (12:16–13:16) система работала стабильно с умеренной нагрузкой.
В инцидентный период (13:16–14:16) зафиксирован резкий рост операционной скорости (SPEED) и ожиданий (WAITINGS), а также насыщение дисковой подсистемы vdb.
Ключевые проблемы СУБД и инфраструктуры
1. Проблемный SQL-запрос (Подтверждено)
QueryID: 8811732978066195686
В инцидентный период запрос генерирует 95.3% всех ожиданий типа DataFileRead (Подтверждено статистикой pg_stat_statements).
Ожидания DataFileRead составляют 99.9% от общего числа событий ожидания в инциденте (Подтверждено).
Запрос вызывает интенсивное чтение данных с диска, предположительно — последовательное сканирование большой таблицы или неэффективное использование индексов (Предположение).
2. Насыщение пропускной способности диска с данными (Подтверждено)
Утилизация диска vdb в инцидентный период достигает 99.94% (медиана), в течение 70.5% времени превышает 50% (Подтверждено).
Глубина очереди запросов (aqu_sz) выросла до 2.16 (медиана), в 77% времени превышает 1 (Подтверждено).
Скорость чтения с vdb возросла с 0.85 МБ/с до 230 МБ/с (медиана), что свидетельствует о достижении предела пропускной способности диска (Подтверждено).
Время отклика (r_await) остаётся низким (<1 мс), что характерно для быстрых SSD/NVMe-дисков, упёршихся в лимит пропускной способности виртуализации или контроллера (Вероятно).
3. Рост системных накладных расходов (Подтверждено)
Сильная корреляция между переключениями контекста (cs) и прерываниями (in) (r=0.973, R²=0.95) (Подтверждено).
Корреляция cs и системного времени CPU (sy) (r=0.907, R²=0.82) (Подтверждено).
Эти связи указывают на то, что высокая интенсивность ввода-вывода порождает большое количество прерываний и переключений контекста, увеличивая нагрузку на ядро ОС (Вероятно).
Системное время (sy) выросло с 2% до 4–5%, пользовательское (us) остаётся низким (Подтверждено).
4. Снижение эффективности кэширования чтения (Вероятно)
Корреляция между размером page cache и операциями чтения ослабла в инциденте (R² <0.2) (Подтверждено).
Возможные причины:
Данные читаются однократно и не помещаются в кэш (Предположение).
Рабочий набор данных превышает доступный объём shared_buffers + page cache (Предположение).
Запрос использует последовательное сканирование, которое неэффективно использует кэш (Вероятно).
5. Отсутствие значимых блокировок и других типов ожиданий (Подтверждено)
Единственный значимый тип ожидания — IO. Ожидания на блокировках, LWLock, буферных пинах и IPC отсутствуют или пренебрежимо малы (Подтверждено).
Проблема полностью локализована в подсистеме ввода-вывода и конкретном запросе.
Рекомендации по оптимизации СУБД и инфраструктуры
Оптимизация СУБД (приоритет высокий)
1. Анализ и оптимизация проблемного запроса (Подтверждено необходимо)
Действия:
Получить текст запроса и план выполнения из pg_stat_statements и EXPLAIN (ANALYZE, BUFFERS).
Определить таблицы, участвующие в запросе, и объём читаемых блоков.
Проверить статистику таблиц: выполнить ANALYZE для затронутых таблиц (особенно если данные часто изменяются).
Ожидаемые улучшения:
Создание недостающих индексов для условий WHERE, JOIN, ORDER BY.
Переписывание запроса для уменьшения объёма сканируемых данных (например, использование подзапросов, CTE, ограничение выборки).
В случае необходимости полного сканирования большой таблицы — рассмотреть партиционирование или материализованные представления.
Категория согласно _pg_expecto_instruction.txt:
Проблема, которую можно доказать (Категория 2) — запрос идентифицирован, ожидания подтверждены статистикой.
2. Проверка использования временных файлов и настройка work_mem (Вероятно полезно)
Текущее значение work_mem = 12 МБ. При интенсивных сортировках или хеш-соединениях может быть недостаточно, что приводит к записи временных файлов на диск.
Выполнить запрос: SELECT datname, temp_files, temp_bytes FROM pg_stat_database WHERE datname = current_database();
Если количество и объём временных файлов значительны, увеличить work_mem до 32–64 МБ с осторожностью, так как этот параметр умножается на количество одновременных операций сортировки/хеширования в рамках одного сеанса. Мониторить общее потребление памяти.
3. Проверка актуальности статистики и параметров автовакуума (Предположение)
В отчёте указано, что автовакуум настроен агрессивно (scale_factor=0.01, naptime=1s), но явных признаков bloat нет.
Рекомендуется проверить количество мёртвых кортежей в затронутых таблицах:sqlSELECT schemaname, relname, n_dead_tup, last_autovacuum, last_autoanalyze
FROM pg_stat_user_tables
WHERE n_dead_tup > 1000;При необходимости запустить VACUUM ANALYZE для обновления статистики и очистки мёртвых строк.
4. Оценка эффективности кэширования (Вероятно)
Для проблемного запроса вычислить hit ratio:sqlSELECT queryid, shared_blks_hit, shared_blks_read,
shared_blks_hit::float / NULLIF(shared_blks_hit + shared_blks_read, 0) AS hit_ratio
FROM pg_stat_statements
WHERE queryid = 8811732978066195686;Если hit_ratio < 0.9, данные плохо кэшируются. Возможные решения:
Увеличение shared_buffers не рекомендуется (уже 25% RAM — стандартный предел).
Оптимизация запроса для уменьшения рабочего набора.
Рассмотреть использование расширения pg_prewarm для предварительной загрузки часто используемых данных в кэш.
Оптимизация инфраструктуры
1. Анализ пропускной способности диска vdb (Подтверждено необходимо)
Диск достиг предела в ~240 МБ/с чтения.
Действия:
Проверить тип диска в среде виртуализации (HDD, SSD, NVMe) и установленные лимиты IOPS/пропускной способности.
При использовании облачного хранилища — увеличить лимиты или перейти на том с более высокой производительностью.
Убедиться, что планировщик ввода-вывода Linux соответствует типу диска (для NVMe — none, для SSD — mq-deadline).
Проверить настройки ядра, влияющие на отложенную запись: vm.dirty_ratio, vm.dirty_background_ratio. В инциденте нагрузка на запись невысока, но тюнинг может помочь в будущем.
2. Снижение системных накладных расходов (Вероятно полезно)
Высокая корреляция cs ↔ in и cs ↔ sy указывает на нагрузку от большого количества IO-операций.
Убедиться, что используется effective_io_concurrency = 300 (уже установлено). Для SSD это адекватное значение.
Рассмотреть возможность включения synchronous_commit = off для некритичных транзакций (если допустимо с точки зрения бизнес-логики), чтобы снизить нагрузку на WAL.
Мониторить использование huge_pages в Linux — может уменьшить накладные расходы на управление памятью.
Необходимая дополнительная информация для продолжения анализа и оптимизации производительности
Для точной диагностики и выработки конкретных рекомендаций требуется следующая информация:
Текст проблемного запроса (queryid = 8811732978066195686) из представления pg_stat_statements.
План выполнения запроса с параметрами EXPLAIN (ANALYZE, BUFFERS, TIMING, VERBOSE).
Структура таблиц, задействованных в запросе (определения с индексами и ограничениями).
Статистика по таблицам из pg_stat_user_tables (количество строк, размер, последние vacuum/analyze).
Данные о дисковом вводе-выводе на уровне ОС за инцидентный период (например, логи iostat -x 1).
Информация о виртуальном диске vdb: тип хранилища, установленные лимиты IOPS/пропускной способности, используемый драйвер (virtio, SCSI).
Настройки ядра Linux, связанные с вводом-выводом и памятью (вывод sysctl -a | grep -E "dirty|vm.swappiness|hugepages").
Итоговая оценка: Инцидент вызван одним неоптимальным запросом, который создал нагрузку чтения, превышающую возможности дисковой подсистемы. Оптимизация запроса — первоочередная задача. После её выполнения ожидается возврат показателей к тестовому уровню или улучшение. Дополнительные меры по масштабированию дисковой подсистемы могут потребоваться, если рабочая нагрузка продолжит расти.
Статусы уверенности в выводах:
🟢 Подтверждено — данные из отчёта, статистические метрики.
🟡 Вероятно — логические заключения на основе корреляций, требующие проверки дополнительными инструментами.
🔴 Предположение — гипотезы, которые нуждаются в подтверждении запросом дополнительной информации.
⬛ Неизвестно — информация отсутствует в предоставленном отчёте.
Примечание: в соответствии с инструкцией символы светофоров заменены текстовыми эквивалентами в круглых скобках.
Послесловие
Данный инцидент — наглядное подтверждение того, что даже при исправных настройках инфраструктуры и СУБД один неоптимальный запрос способен полностью насытить диск и вызвать каскад системных накладных расходов. Методология PG_EXPECTO, основанная на явном разделении подтверждённых фактов, вероятных связей и гипотез, позволила не только быстро идентифицировать корневую причину, но и избежать типичных ошибок интерпретации (например, ложного обвинения блокировок или нехватки памяти). Внедрение подобного подхода в регулярную практику анализа производительности делает диагностику прозрачнее, а выводы — проверяемыми и воспроизводимыми.
Postgres DBA
259 постов27 подписчиков
Правила сообщества
Пока действуют стандартные правила Пикабу.