Вышла новая модель для синтеза речи Supertonic 3

Запущена новая сверхлегкая система синтеза речи Supertonic 3 (https://huggingface.co/Supertone/supertonic-3) для полностью локального исполнения на устройстве (ONNX Runtime, без облака) с лицензией OpenRAIL-M и кодом под лицензией MIT.
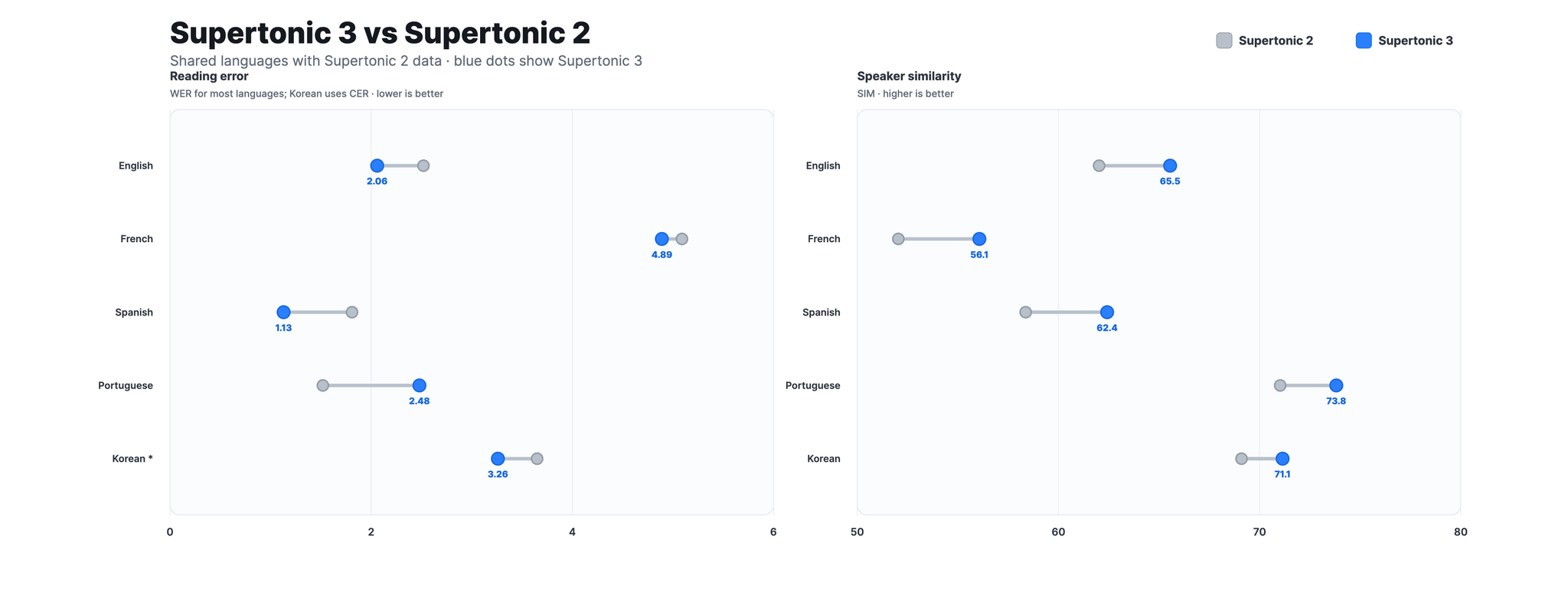
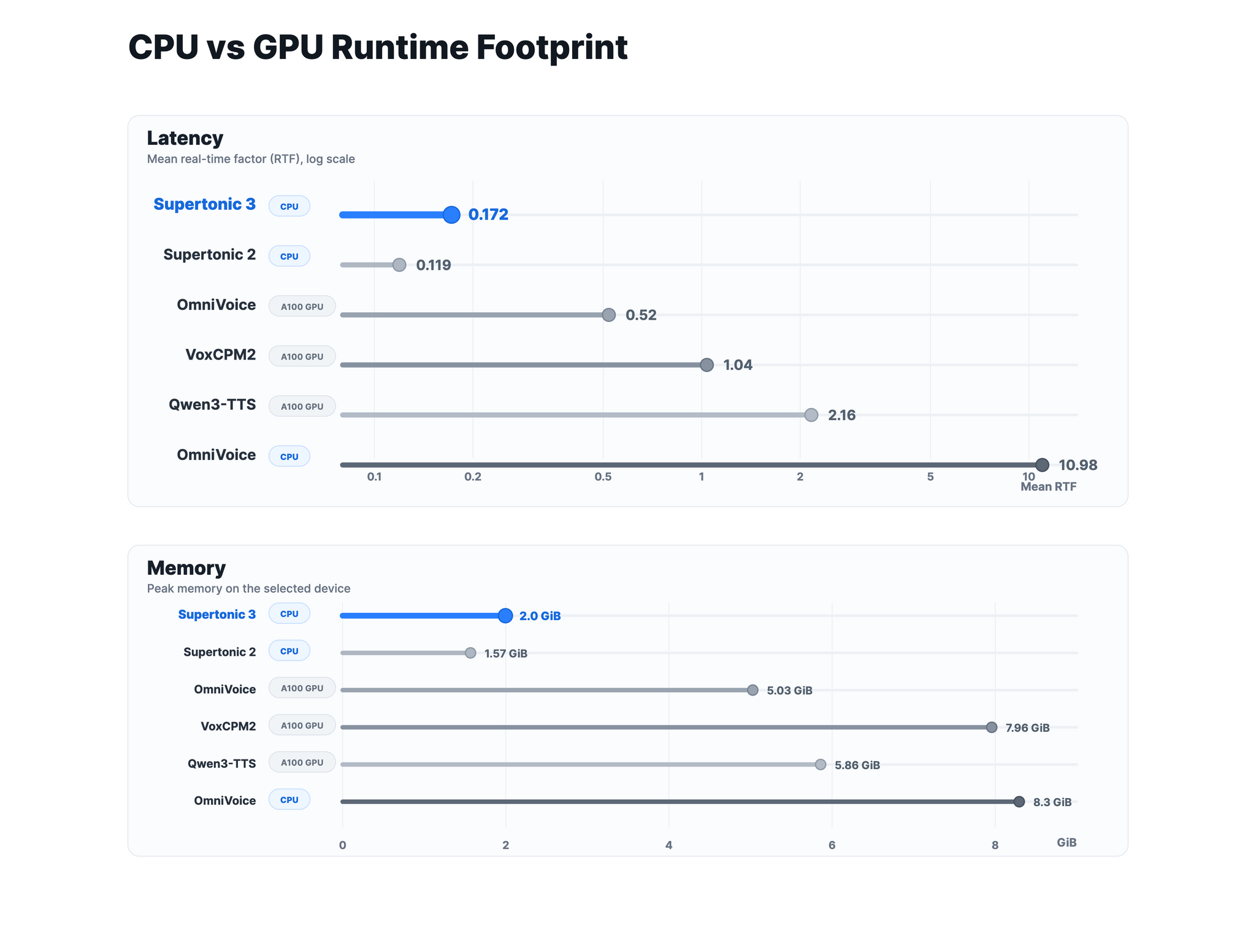
В ней расширили поддержку с 5 до 31 языка (русский, английский, немецкий, французский, испанский, корейский, японский, арабский и другие), уменьшили повторы/пропуски при чтении, повысили схожесть голоса с диктором и добавили поддержку тегов выражения (<laugh>, <breath>, <sigh>). Вдобавок размер модели всего приблизительно 99M параметров, что кратно меньше аналогов (VoxCPM2, Qwen3-TTS и других).
В результате при использовании CPU средняя задержка RTF примерно 0.17, а пиковая потребляемая память около 2 ГБ. При этом точность чтения (WER/CER) на уровне крупных GPU-моделей.