
Продолжение «"Программисты не умеют программировать"»
Просто компилирую почти пустые приложения в Delphi 7 (x86), 11.3, а также Lazarus 2.2.4 (x64). Уровень "Hello, World". Я не менял Uses, оно само туда надобавлялось. Не использовал KOL и прочие навороты.
У Lazarus просто отключал генерацию отладочной информации, у Delphi 11.3 переключал профили Debug/Release (Win32), Delphi 7 (x86) - компилил как есть, на свежеустановленной среде.
Оконное приложение:
vcl, TCaption для вывода "Hello, World". Код примерно такой (Delphi 11.3):
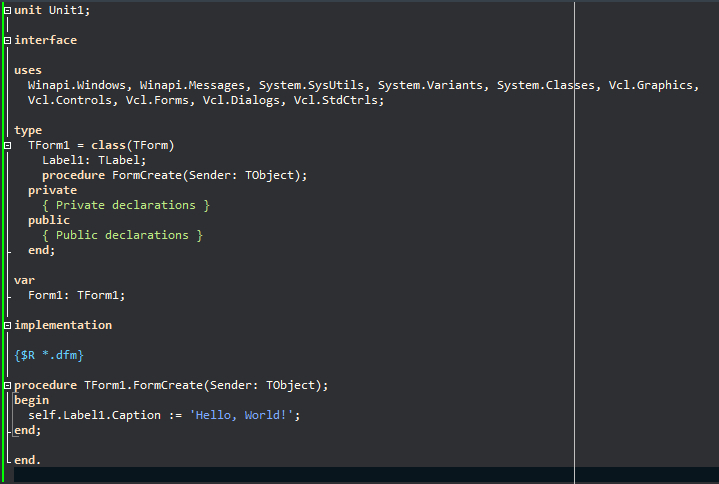
Delphi 11.3
У Lazarus другой список uses:
uses Classes, SysUtils, Forms, Controls, Graphics, Dialogs, StdCtrls;
У Delphi 7 этот список такой:
uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs, StdCtrls;
Консольное приложение:
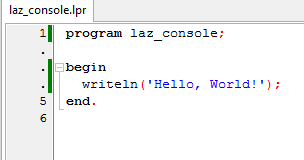
Lazarus
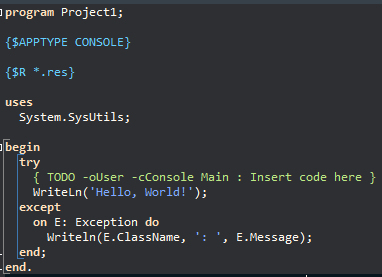
Delphi 11.3
Delphi 7 - как у Lazarus + uses SysUtils.
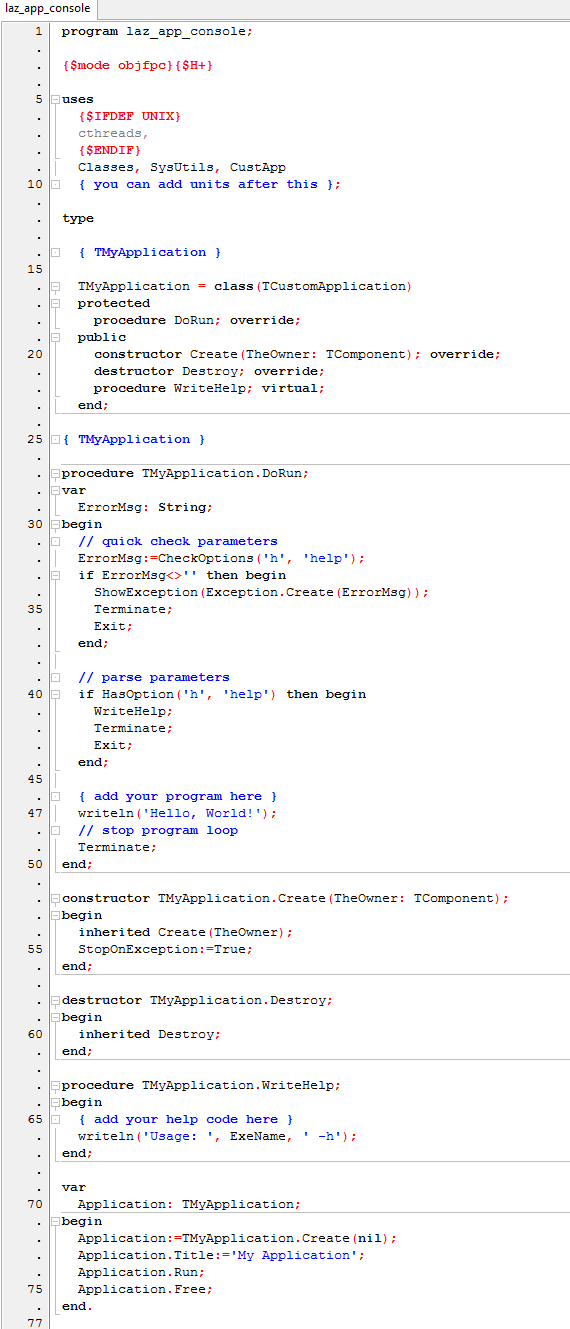
Навороченное консольное приложение Lazarus 2.2.4. Это стандартная заготовка, я добавил только строчку № 47.
По итогу накомпилировал столько приложений:
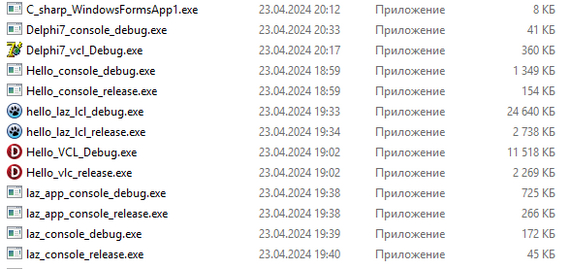
В виде таблички:
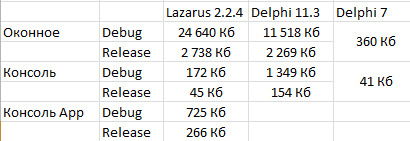
Для Delphi 7 (x86) -- вроде и Debug-версия, но там Debug-файлы генерируются отдельно, т.е. вроде и не Debug.
Решил отдельно замерять по трем компиляторам, даже Delphi 7 откопал, развитие моего комментария: #comment_306393162
Отдельно запустил C# (.NET Framework) с использованием Windows Form и получился такой код:
Все эти Form1 и label1.Text мне что-то смутно напоминают.
Андерс Хейлсберг приложил свою руку и к Delphi, и к C#. При этом C# вдохновлялась Java, а Java вдохновлялась виртуальными машинами:
в 1973 году с участием Вирта был разработан прототип виртуальной машины, исполняющей на любой платформе промежуточный «пи-код», в который предполагалось компилировать все программы
А Никлаус Вирт создал Паскаль, который лег в основу Delphi.