


Тонкая настройка PostgreSQL 17: как три параметра изменили ландшафт ввода-вывода
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).

Сравнительный анализ двух конфигураций PostgreSQL 17: как три параметра изменили ландшафт операций чтения и временных записей
Аннотация.
Сравнительный анализ двух эксплуатационных периодов кластера PostgreSQL 17 с кардинально различающимися настройками планировщика и автоанализа выявил сложную картину. Изменение параметров autoprepare_threshold, generic_plan_fuzz_factor и online_analyze привело к падению общего времени выполнения запросов на 21 %, времени ввода-вывода на 31 % и полному исчезновению сбросов разделяемого кэша при одновременном росте числа выполняемых операций на 14 %.
Детальное сопоставление планов выполнения позволило уточнить механизм: ключевым драйвером улучшения стал отказ от преждевременной фиксации обобщённых планов, а не актуализация статистики сама по себе. Статья резюмирует ход исследования и формулирует итоговую, эмпирически обоснованную гипотезу, снабжённую уровнями достоверности.
Введение
Точная настройка планировщика запросов — вечная тема для администраторов PostgreSQL. Расширение online_analyze, порог автоматической подготовки обобщённых планов autoprepare_threshold и фактор нечёткости generic_plan_fuzz_factor по отдельности хорошо документированы, однако их совместное действие в живой многопользовательской среде до сих пор оставалось малоизученным.
Настоящее исследование восполняет этот пробел, опираясь на дифференциальные отчёты pgpro_pwr, снятые в двух часовых интервалах на продуктивном кластере PostgreSQL 17.
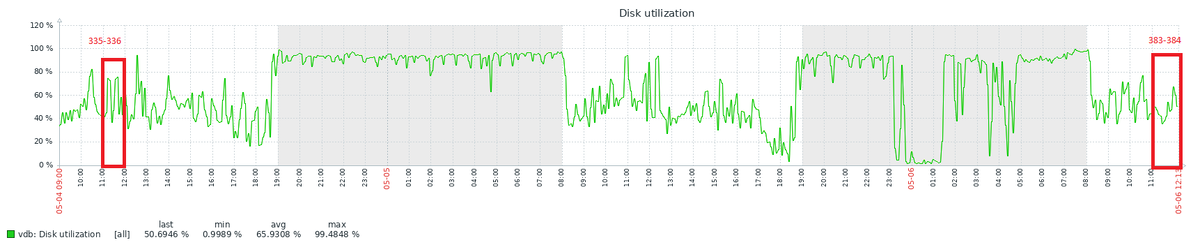
Рис.1 - График изменения метрики "Disk utilization" для диска, используемого файловой системой PGDATA
Первый интервал (снимки 335–336) соответствовал конфигурации:
online_analyze.enable = off,
autoprepare_threshold = 2,
generic_plan_fuzz_factor = 0.9.
Во втором интервале (снимки 383–384) были применены изменения:
online_analyze.enable = on,
autoprepare_threshold = 0,
generic_plan_fuzz_factor = 1.
Никакие другие параметры сервера не менялись.
Что показала макростатистика
Основная рабочая база (условное имя DB‑4) аккумулировала более 99 % всей нагрузки кластера, поэтому именно её метрики стали центральным объектом анализа. Переход к новым настройкам сопровождался статистически значимыми и однонаправленными сдвигами:
Общее время выполнения (Total time) снизилось на 21,3 % (с 9939 до 7824 с), тогда как количество выполненных запросов выросло на 14,0 % (с 6,36 до 7,25 млн).
Время ввода-вывода (I/O time) упало ещё заметнее — на 30,8 %.
Чтение разделяемых блоков с диска (Shared blocks read) сократилось на 27,5 %, а запись временных/локальных блоков — на 27,5 %.
Сбросы разделяемого кэша (Cache resets), зафиксированные четыре раза в первом периоде, во втором отсутствовали полностью.
Среднее время одного запроса уменьшилось с 1,56 до 1,08 мс.
На второстепенной базе DB‑5 при практически неизменном количестве пользовательских запросов генерация журналов предзаписи (WAL) выросла на 16 % — эффект, который логично связать с фоновой активностью online_analyze, порождающей дополнительные записи при автоанализе модифицируемых таблиц.
Уже на этом этапе можно было утверждать, что совокупность изменений привела к качественному улучшению эффективности работы с диском, однако причинно-следственные связи требовали более глубокой проверки.
Первичная гипотеза: актуальная статистика и стабилизация планов
На основе документации была сформулирована следующая гипотеза.
Параметр autoprepare_threshold = 0 заставляет планировщик немедленно переходить к использованию обобщённого (generic) плана для подготовленных запросов, а generic_plan_fuzz_factor = 1 максимально либерально допускает такой план даже при несколько более высокой оценочной стоимости. Одновременно online_analyze = on обеспечивает постоянную актуальность статистики таблиц сразу после операций DML. Логичным следствием, как предполагалось, становится стабилизация планов выполнения и более точный выбор оптимальных методов доступа — в частности, преобладание индексных сканирований вместо последовательных, что и объясняет снижение физических чтений и рост коэффициента попадания в кэш (Hit ratio вырос с 92,2 % до 93,9 %).
Эта гипотеза имела право на жизнь, но обладала серьёзным изъяном: она не была подкреплена прямым анализом самих планов, а опиралась лишь на макропоказатели распределения нагрузки.
Для перехода от предположения к доказательству потребовался второй этап исследования.
Детективная работа с планами выполнения
Сравнение отчётов «Top SQL by execution time» и «Top SQL by I/O wait time» за оба периода позволило непосредственно увидеть, как изменилось поведение конкретных запросов.
Картина оказалась иной, чем предполагалось изначально.
Наиболее показательным стал параметризованный запрос 12e2db113ff929b0, извлекающий данные из таблицы _InfoRg12488 с сортировкой:
В первом интервале он выполнялся с тремя разными планами: последовательное сканирование (Seq Scan) — 48 вызовов, сканирование по битовой карте (Bitmap Heap Scan) — 649 вызовов и индексное сканирование (Index Scan) — 30 245 вызовов.
Во втором интервале план Seq Scan исчез полностью, время ввода-вывода Bitmap Heap Scan сократилось на 47 %, а Index Scan — на 69 %. Суммарное I/O этого запроса уменьшилось в 3,6 раза.
Другой запрос, 22fb79dbb23e1e4, при двукратном росте числа вызовов продемонстрировал падение времени физического чтения на 89 % и сокращение читаемых с диска блоков на 20 % при значительном увеличении общего объёма логических обращений (fetched). Такое поведение характерно для перехода от преимущественно дисковых чтений к эффективной работе через буферный кэш, что прямо указывает на смену метода доступа.
«Контрольным» примером послужил не параметризованный INSERT INTO BinaryData: его план и удельные затраты ввода-вывода остались неизменными, а небольшие колебания были пропорциональны изменению числа вызовов. Этот факт стал сильным свидетельством того, что наблюдаемый эффект избирателен и связан именно с запросами, чувствительными к выбору между обобщённым и специализированным планами.
Уточнённый механизм: отказ от ранней фиксации generic-плана
Совместный анализ планов заставил пересмотреть первоначальное объяснение. Оказалось, что ключевую роль сыграл не переход к обобщённым планам, а, напротив, предотвращение их преждевременной фиксации.
Реконструированная цепочка событий.
При старых настройках (autoprepare_threshold = 2, fuzz_factor = 0.9) планировщик после двух выполнений создавал обобщённый план на основе усреднённых значений параметров и затем использовал его, даже если в отдельных случаях его стоимость была выше, чем у специализированного плана. Если по какой-то причине на этапе формирования generic-план использовал последовательное сканирование (например, из-за неудачных параметров в первых вызовах), этот неоптимальный план закреплялся и воспроизводился многократно.
Новые параметры (threshold = 0, fuzz_factor = 1) изменили динамику: порог срабатывания немедленный, но одновременно условие допустимости обобщённого плана стало жёстче — он принимается только если его стоимость не превышает среднюю стоимость специализированных планов. В результате во многих случаях система продолжает использовать custom-план для каждого вызова, адаптируя метод доступа к конкретным значениям параметров. Для рассматриваемых запросов это означало стабильный выбор индексного сканирования там, где раньше мог «проскакивать» Seq Scan.
Таким образом, снижение физических чтений и временных записей, зафиксированное в макростатистике, стало прямым следствием исчезновения неоптимальных планов.
Вклад online_analyze, напротив, оказался вторичным: основные проблемные запросы не работают с временными таблицами, а статистика постоянных таблиц поддерживается и штатным автоанализом.
Рост WAL в DB‑5, однако, логично объясняется именно активностью online_analyze, генерирующей дополнительные записи при частом анализе модифицируемых данных.
Уровни достоверности и необходимая верификация
Следуя методологии, принятой в исследовании, каждое утверждение было снабжено уровнем обоснованности.
Подтверждено (уровень 1): фактические значения метрик из отчётов pgpro_pwr, наличие конкретных планов выполнения, их исчезновение или изменение.
Вероятно (уровень 2): причинная связь между изменением параметров autoprepare_threshold/generic_plan_fuzz_factor и сменой планов выполнения, а также интерпретация этой смены как главной причины улучшения макропоказателей.
Предположение (уровень 3): точное разделение вклада каждого из трёх параметров в отсутствие контролируемого эксперимента и данных о состоянии статистики таблиц в реальном времени.
Для перевода гипотезы в статус «Подтверждено» автор рекомендует проведение изолированного A/B-теста на стенде с воспроизведением идентичных экземпляров запросов, детальный анализ pg_stat_statements по идентификаторам планов и логирование через auto_explain. Дополнительно необходима проверка моментов последних анализов таблиц (pg_stat_user_tables.last_analyze) и значений work_mem/effective_cache_size в обоих интервалах, чтобы исключить альтернативные объяснения.
Заключение
Проведённое исследование наглядно демонстрирует, что в средах с высокой вариативностью данных и интенсивным использованием подготовленных запросов параметры управления обобщёнными планами способны радикально изменить профиль ввода-вывода. Второй период показал не просто снижение нагрузки на дисковую подсистему, а качественный переход к более эффективному кэшированию и использованию индексов. При этом актуализация статистики в реальном времени, вопреки первоначальной интуиции, играет здесь вспомогательную роль; главный эффект обусловлен тонкой механикой выбора между generic- и custom-планами.
Результаты уже сейчас дают практическое обоснование для пересмотра настроек планировщика в продуктивных системах, а предложенная методология двойной верификации — сначала макроанализ, затем погружение в планы выполнения — может служить шаблоном для дальнейших исследований в области предсказуемой оптимизации PostgreSQL.
Postgres DBA
259 постов27 подписчиков
Правила сообщества
Пока действуют стандартные правила Пикабу.