

Преобразование отсканированных PDF в PDF с возможностью поиска с помощью Python
Отсканированные PDF-файлы по сути представляют собой изображения, помещённые в контейнер PDF. Это означает, что вы можете их просматривать — но не можете искать текст, копировать его или извлекать данные. Если вы когда-либо пытались скопировать содержимое из отсканированного счёта или документа и у вас ничего не получилось, значит, вы столкнулись именно с этим ограничением.
Решение? OCR (оптическое распознавание символов) .
В этом руководстве вы узнаете, как преобразовать отсканированные PDF-файлы в полностью searchable PDF с помощью Python. Мы рассмотрим установку, зависимости, настройку языков и приведём чистый, готовый к использованию пример кода.
Что потребуется
Для выполнения OCR над PDF в Python мы будем использовать два основных компонента:
1. ocrmypdf (Python-библиотека)
Мощная оболочка, объединяющая OCR и обработку PDF в одной команде.
2. OCR-движок Tesseract
Основной OCR-движок, который использует ocrmypdf.
Установка
Шаг 1: Установка ocrmypdf
pip install ocrmypdf
Шаг 2: Установка Tesseract OCR
Windows
Скачайте и установите из официального репозитория Tesseract.
Во время установки обязательно обратите внимание на следующие параметры :
Additional language data (download)
Additional script data (download)
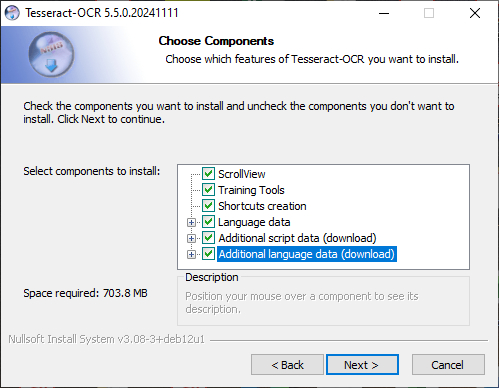
Если вы не отметите эти пункты , по умолчанию будет установлен только английский языковой модуль .
Это одна из самых распространённых ошибок — позже пользователи пытаются запускать OCR для китайского или японского языка и получают ошибки, потому что языковые данные просто не установлены.
macOS (Homebrew)
brew install tesseract
Linux (Ubuntu/Debian)
sudo apt install tesseract-ocr
Настройка Tessdata (важно)
Tesseract должен знать, где расположены файлы языковых данных (.traineddata).
В Windows обычно необходимо вручную задать переменную окружения:
os.environ["TESSDATA_PREFIX"] = r"C:\Program Files\Tesseract-OCR\tessdata"
Если путь указан неверно или отсутствует, OCR завершится ошибкой, связанной с языковыми файлами.
Поддерживаемые языки и использование Enum
Чтобы сделать выбор языка безопаснее и удобнее для разработчиков, в коде используется Enum:
class OcrLanguage(Enum):
"""Поддерживаемые OCR-языки с использованием кодов ISO 639-2."""
ENGLISH = "eng"
SIMPLIFIED_CHINESE = "chi_sim"
TRADITIONAL_CHINESE = "chi_tra"
CHINESE_ENGLISH = "chi_sim+eng"
JAPANESE = "jpn"
KOREAN = "kor"
Зачем использовать Enum?
Исключает опечатки вроде "engg" или "chn"
Поддерживает автодополнение в IDE
Делает код более понятным и самодокументируемым
Как добавить новые языки
Вы можете легко расширить enum OcrLanguage.
Шаг 1: Установите языковые данные
Убедитесь, что соответствующий файл .traineddata находится в папке tessdata.
Примеры:
fra.traineddata → французский
deu.traineddata → немецкий
spa.traineddata → испанский
Шаг 2: Расширьте Enum
class OcrLanguage(Enum):
ENGLISH = "eng"
FRENCH = "fra"
GERMAN = "deu"
SPANISH = "spa"
Шаг 3: Используйте язык
language=OcrLanguage.FRENCH
OCR для нескольких языков
Можно комбинировать несколько языков:
CHINESE_ENGLISH = "chi_sim+eng"
Это особенно полезно для:
двуязычных документов
счетов с несколькими языками
научных статей
Полный пример кода
Ниже приведён полностью рабочий скрипт:
import ocrmypdf
from enum import Enum
import os
# ==============================================
# Указываем каталог данных Tesseract (только Windows)
# ==============================================
os.environ["TESSDATA_PREFIX"] = r"C:\Program Files\Tesseract-OCR\tessdata"
# ==============================================
# Enum языков OCR (без опечаток, удобно выбирать)
# ==============================================
class OcrLanguage(Enum):
"""Поддерживаемые OCR-языки с использованием кодов ISO 639-2."""
ENGLISH = "eng"
SIMPLIFIED_CHINESE = "chi_sim"
TRADITIONAL_CHINESE = "chi_tra"
CHINESE_ENGLISH = "chi_sim+eng"
JAPANESE = "jpn"
KOREAN = "kor"
# ==============================================
# Основная функция конвертации
# ==============================================
def convert_scanned_pdf_to_searchable(
input_pdf_path: str,
output_pdf_path: str,
language: OcrLanguage
):
"""
Преобразует PDF на основе изображений (сканированный PDF)
в PDF с возможностью поиска с помощью OCR.
Args:
input_pdf_path: Путь к исходному сканированному PDF
output_pdf_path: Путь для сохранения searchable PDF
language: OCR-язык, выбранный из enum OcrLanguage
"""
try:
# Выполняем OCR и создаём оптимизированный searchable PDF
ocrmypdf.ocr(
input_file=input_pdf_path,
output_file=output_pdf_path,
language=language.value,
optimize=1,
force_ocr=True
)
print(f"✅ Готово! PDF с поиском сохранён в: {output_pdf_path}")
except Exception as error:
print(f"❌ Ошибка при конвертации: {str(error)}")
# ==============================================
# Запуск конвертера
# ==============================================
if __name__ == "__main__":
# Укажите пути к файлам
INPUT_FILE = "ScannedPDF.pdf"
OUTPUT_FILE = "searchable.pdf"
# Выбор языка через Enum (безопасно и удобно)
convert_scanned_pdf_to_searchable(
input_pdf_path=INPUT_FILE,
output_pdf_path=OUTPUT_FILE,
language=OcrLanguage.ENGLISH
)
Результат:
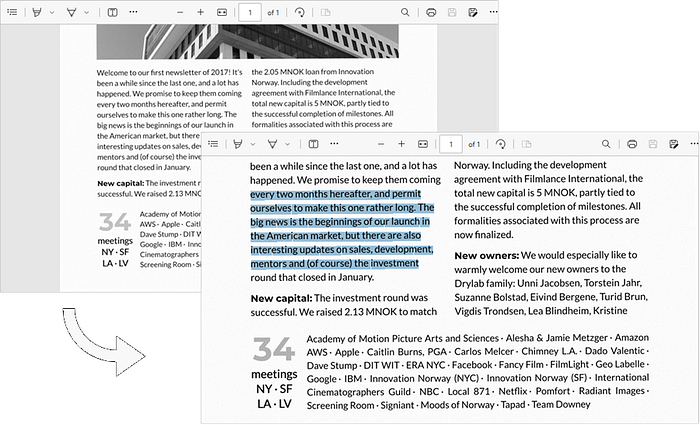
Отсканированный PDF становится доступным для выделения и поиска текста.
Объяснение ключевых параметров
language → определяет язык(и) OCR
optimize=1 → уменьшает размер файла без потери качества
force_ocr=True → принудительно запускает OCR, даже если текст уже обнаружен
Распространённые ошибки
1. Отсутствуют языковые данные
Если вы видите ошибку вида:
Error opening data file...
→ Скорее всего, не установлен языковой пакет.
2. Неверный путь Tessdata
Проверьте переменную:
TESSDATA_PREFIX
3. Низкая точность OCR
Качество OCR сильно зависит от:
разрешения изображения (рекомендуется 300 DPI)
шумов и размытия
чёткости шрифта
Полезные советы
Повышение точности OCR
Выполняйте предварительную обработку PDF (выравнивание, удаление шумов)
Перед OCR переводите изображения в оттенки серого
Используйте корректный DPI
Пакетная обработка
Оберните функцию в цикл:
for file in os.listdir("input_folder"):
if file.endswith(".pdf"):
convert_scanned_pdf_to_searchable(...)
Сохранение исходного внешнего вида
ocrmypdf добавляет скрытый текстовый слой без изменения визуальной структуры документа , поэтому внешний вид исходного PDF полностью сохраняется.
Заключение
Всего несколькими строками Python-кода вы можете превратить бесполезные отсканированные PDF-файлы в полностью searchable, копируемые и индексируемые документы.
Комбинация:
ocrmypdf
Tesseract
структурированного управления языками через Enum
…позволяет создать надёжный и масштабируемый OCR-конвейер, подходящий как для личного использования, так и для корпоративных задач.
Если вам приходится работать с большими объёмами сканированных файлов, этот подход способен сэкономить часы ручной работы — и мгновенно открыть доступ к вашим данным.
Программирование на python
1K постов12K подписчика
Правила сообщества
Публиковать могут пользователи с любым рейтингом. Однако!
Приветствуется:
• уважение к читателям и авторам
• конструктивность комментариев
• простота и информативность повествования
• тег python2 или python3, если актуально
• код публиковать в виде цитаты, либо ссылкой на специализированный сайт
Не рекомендуется:
• допускать оскорбления и провокации
• распространять вредоносное ПО
• просить решить вашу полноценную задачу за вас
• нарушать правила Пикабу