

Оптимизация STM32F103 как ПЛК. Догоняем Mitsubishi FX3, и обгоняем архитектурно2

Кто читает первый раз мой пост. Что у меня за проект: Своими разработками соревнуюсь с брендами в АСУ ТП. Превзойти Codesys
Если коротко, я работаю над собственным аналогом комплекса - Codesys. Программная экосистема для разработки ПЛК на разном железе, под названием 3o|||sheet (читать как “Зошит”). Состоит из трех уровней: Среда разработки IDE (LD/FBD/ текстовые), собственного компилятора, и собственная среда выполнения на стороне железа.
В прошлом посте, сравнивал свой ПЛК с китайскими клонами на базе Mitsubishi FX3 При одинаковом чипе (stm32f103) мой инженерный образец был в три раза медленнее Mitsubishi.
С этим я мириться не стал, и первое что сделал - чуть оптимизировал выборку команд из виртуального ОЗУ.
Внутри рантайма в микроконтроллере. Было:
ic.b[3]= memory[PC];
ic.b[2]= memory[PC+1];
ic.b[1] = memory[PC+2];
ic.b[0]= memory[PC+3];
Во времена тестирования на ПК и микроконтроллерах, чтоб не возиться с “Big Endian/Little Endian” я оставил такой медленный но прямой способ.
Изменил на:
memcopy(&ic, &memory,4);
ic - это регистр инструкции (структура типа Union) , он первым читается из виртуального ОЗУ. К нему применяются различные маски и сдвиги, для извлечения данных (номера регистров, операнды, константы и т.д).
Производительность нашего ПЛК на “ровном месте” увеличилась больше чем на 30%.
Сейчас картина выглядит так по работе с релейной логикой (LD)- Указано время выполнения базовых LD инструкций в микросекундах (меньше - лучше):
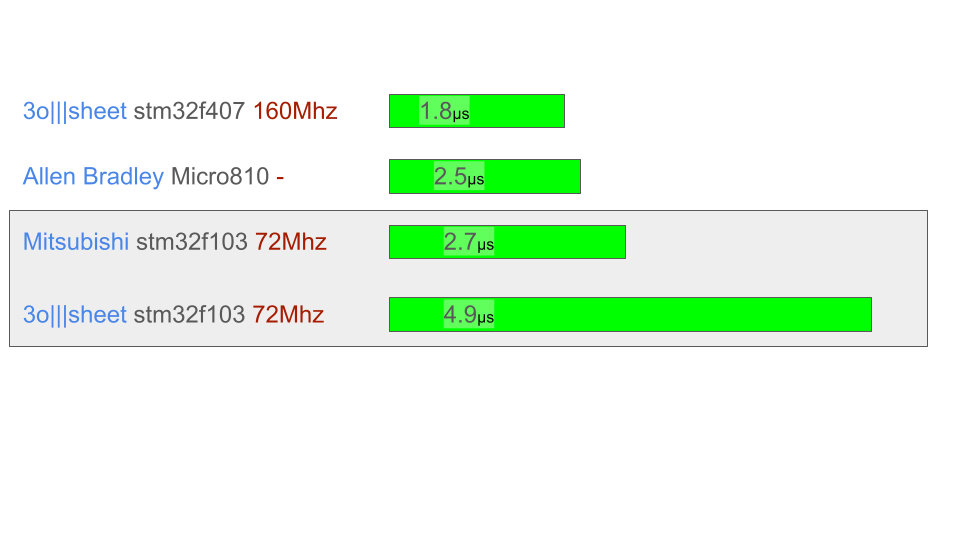
Данные по Allen Bradley Micro810 - взято из документации, какой внутри стоит чип - неизвестно. Данные по китайским клонам по Mitsubishi FX3 - взято из тестов на просторах интернета.
Наш ПЛК на базе собственного 3o|||sheet все еще уступает Mitsubishi FX3 (с китайским клоном и идентичного микроконтроллера stm32f103), но уже не в три раза, как в прошлый раз, а примерно в два раза. Поле для оптимизации у меня еще широкое (та самая работа с декодированием инструкций- маски, сдвиги, и прочее, я молчу уже об оптимизации - конкретно выполнение виртуальных инструкций). Пока я создаю инженерные образцы ПЛК (а не коммерческие) где тестируется в основном- стабильность, а не скорость, хотя периодически бывает интересно что можно выжать по скорости.
Но возможно достичь аналогичного результата клона Mitsubishi FX3 может и не удастся, учитывая универсальность моей архитектуры 3o|||sheet и деревянного ( бюджетного конечно) от Mitsubishi. Но если я оптимизирую производительность до уровня 10-20% разницы с Mitsubishi, буду считать - прекрасным результатом, и вот почему.
Превосходство моей архитектуры:
Mitsubishi FX3 - деревянный и не гибкий, напоминающий Allen Bradley SLC 500). У них “табличная память”. Жестко выделенные области - битовые переменные, целочисленные переменные, таймеры и т.д Адресация, чтение/запись идет быстро - никакого декодирования . В моей архитектуре 3o|||sheet - единое адресное пространство, и любые типы переменных могут располагаться в перемешку, в любой последовательности, с адресным пространством 4 гигабайта:
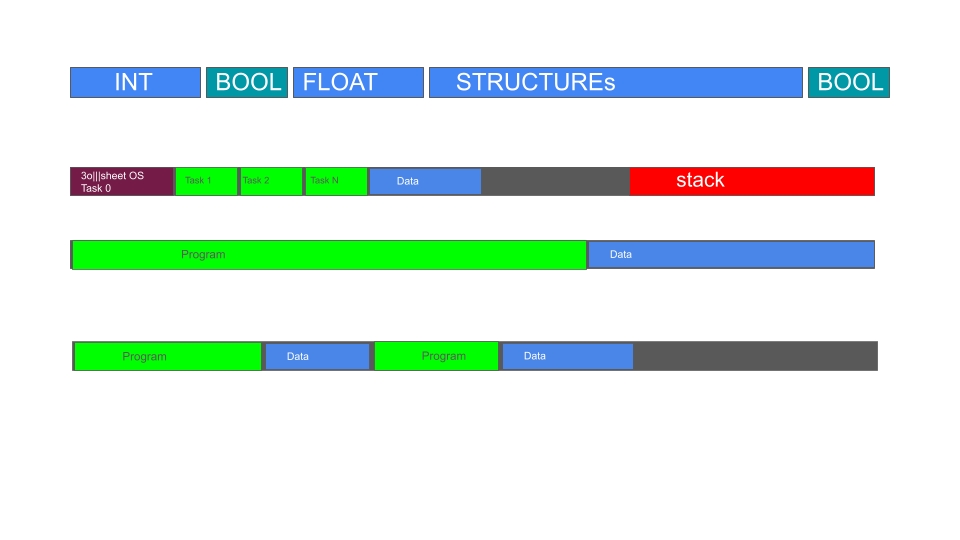
То есть, делить адресное пространство можно - как угодно. Создавать или нет внутри Диспетчер задач или Операционную систему.
Первоначально, я так же создавал ПЛК с системой табличной памяти, они быстро работали, но я пришел к выводу что это тупиковый , устаревший, архитектурный путь .
Но не только я так думаю. Бюджетный современный Allen Bradley может уже исполняться из ST языка ( в отличии от старых бюджетных SLC 500), и что произошло? Новый бюджетный как видим выполняет релейную логику в 2.5 микросекунды на команду, против 1.2 микросекунды у старых SLC 500 ))) данные я прочитал в документации SLC 500. То есть современный ПЛК Allen Bradley стал медленнее в два раза в сравнении с старым Allen Bradley))
Давайте продемонстрирую возможности своего компилятора 3o|||sheet и системы воспроизведения в железе, о том что значит - гибкость системы.
В Первую очередь это - возможность создавать структуры данных любой сложности внутри смешивая данные любых типов (что значит - легкость и читаемость программы, и создание собственных функциональных блоков любой сложности внутри). Так же и воспроизведение программы: можно собирать любую сложную логику - в отдельные функции (что также значительно повышает удобство и написание сложных программ), и вызывать методы внутри друг друга.
Я не буду демонстрировать LD или ST (это у всех ПЛК +- тоже самое, ведь стандарт же), интересней это выглядит внутри микроконтроллера:
func1(){
func2();
}
func2(){
func3();
}
func3(){
func4();
}
func4(){
func5();
}
pause(){
…
}
main()
{
func1();
}
В данном видео примере выводятся строки: чем глубже функция, тем длиннее строка для наглядности
Main ------| переход
func1 ------------| переход
func2 ------------------| переход
func3 ---------------------| переход
func4 ------------------------| переход
func5 ---------------------------| Самая глубокая функция
func5 ---------------------------| возврат
func4 ------------------------| возврат
func3 ---------------------| возврат
func2 ------------------| возврат
func1 ------------| возврат
Main ------| Завершение Main. -> Начало Main.
Глубокие переходы между функциями ( функция внутри вызывает другую функцию, а та следующую и т.д), или рекурсии - на всю память. Единое адресное пространство - чем больше программа - тем меньше данных, и наоборот. Никакой жесткости типа - “память программ 256 кб, память данных 128 кб” и прочее. Никаких жестких списков “целочисленных переменных 256 страниц, булевых 256 страниц, таймеров 64” и т.д. Как в архитектурах типа FX3. Гибкая архитектура подразумевает - есть целое виртуальное ОЗУ - а там распределяйте сколько чего нужно в каких пропорциях - сами.
Так же добавил возможность, обновлять участи кода (полностью их переписывать, на лету, не перезагружая и не останавливая ПЛК)
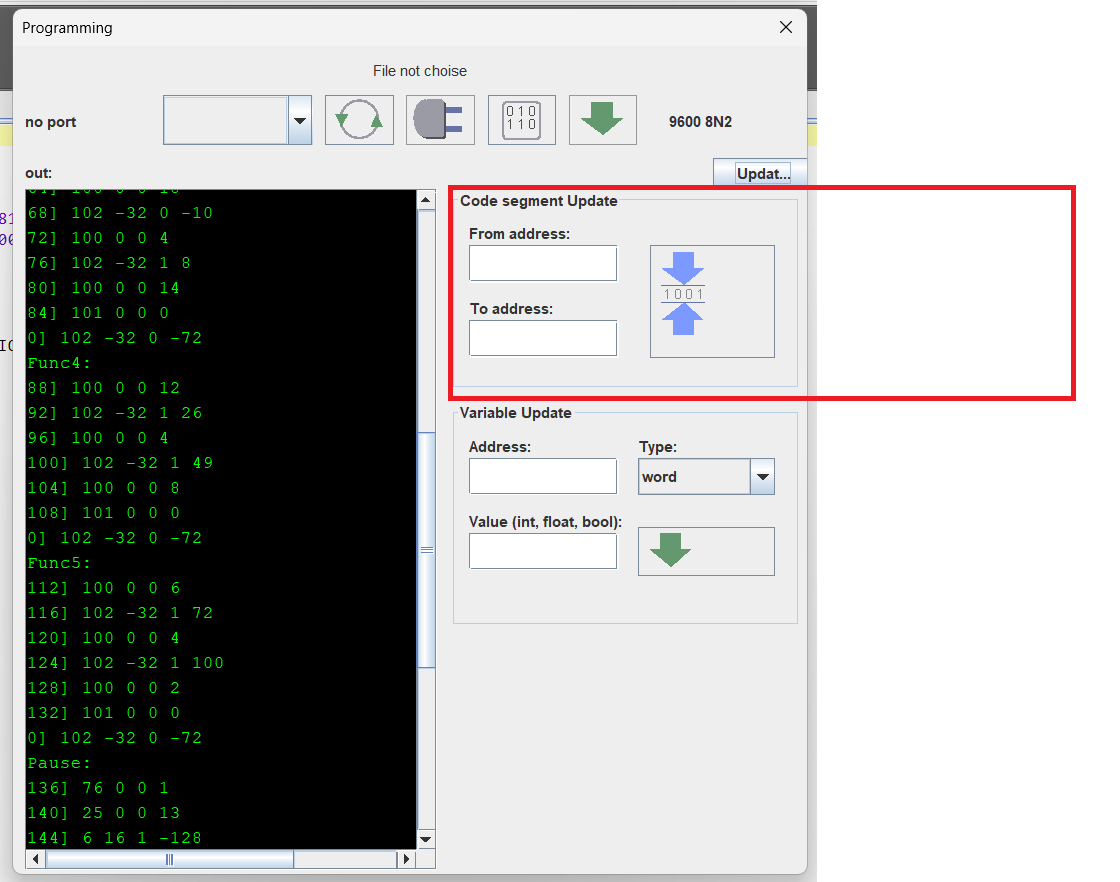
Для обновления кода на лету, надо перекомпилировать проект, и загрузить программу в ПЛК от указанного начала адреса, и до указанного конца. В будущем сделаю удобно - переписать код блока или функции - просто указав по имени.
Разработка своего компилятора - трудный путь, но зато потом все вознаграждается тем что ты вплотную сравниваешься с брендами по функциональности: Вытесняющая многозадачность, обновление кода на лету + свои идеи по безопасности , создавая на слабом железе "микро "виртуалки", где одна может выполнять рискованный код (взаимодействовать с внешними системами) и может слететь, а другая - исполняет критический код, никогда не слетит.
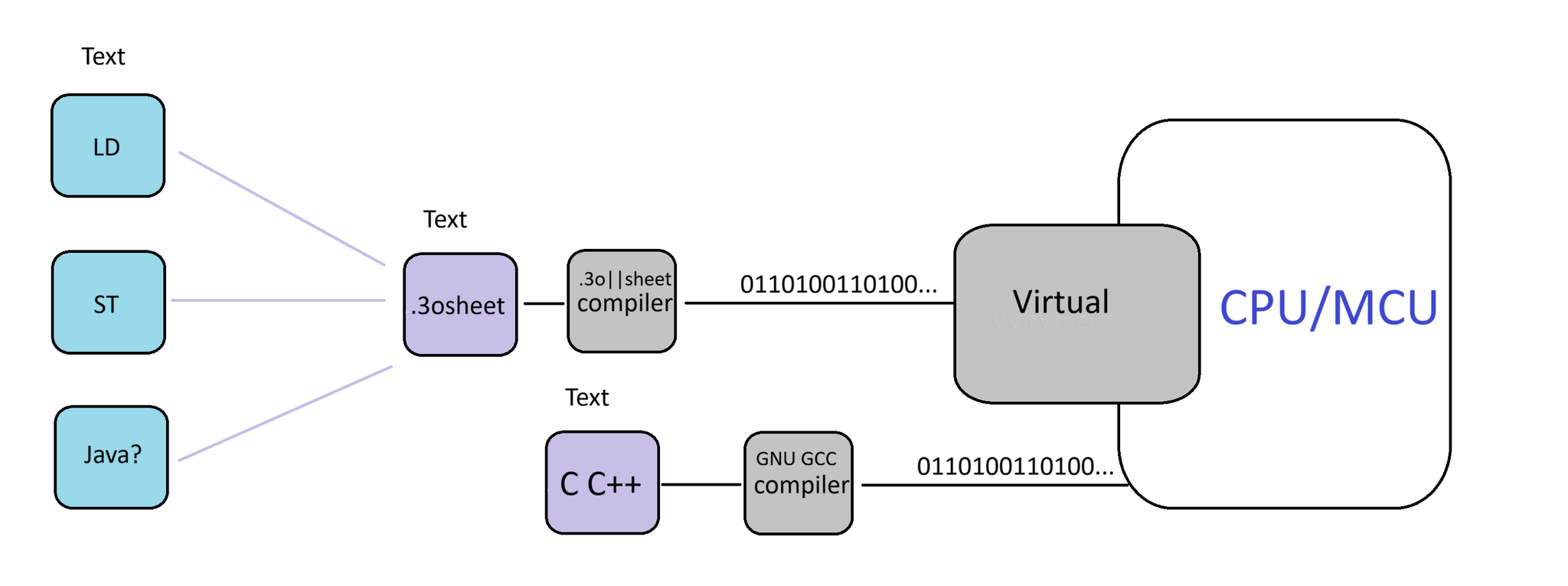
Архитектура. LD ST - текст, переводится в текст .3osheet и .3osheet компилятором своей разработки, переводится в байткод. Сама виртуальная машина написана на СИ. Теоретически, если сделаю транслятор из Java, то получится аналог напоминающий Android.
Ну и на последок,
Сейчас зима, прекрасное время заняться акварельной живописью. Кто то заметил уже, слишком красочная моя среда разработки в сравнении с другими. Я художник (за плечами кроме инженерного - художественный институт). Сейчас возвращаюсь к рисованию опять.


Никак не доедет отладочная плата на RISC V для теста, кому интересно - присоединяйтесь, периодически буду публиковать ход разработки проекта.
Пишите на почту:
Arduino & Pi
1.5K поста20.9K подписчика
Правила сообщества
В нашем сообществе запрещается:
• Добавлять посты не относящиеся к тематике сообщества, либо не несущие какой-либо полезной нагрузки (флуд)
• Задавать очевидные вопросы в виде постов, не воспользовавшись перед этим поиском
• Выкладывать код прямо в посте - используйте для этого сервисы ideone.com, gist.github.com или схожие ресурсы (pastebin запрещен)
• Рассуждать на темы политики
• Нарушать установленные правила Пикабу