Каков метод работы? Все файлы это бинарный код, он несжимаемый бинарный код создаёт значения на сжимаемые те замена. по словарю. по типу 1010101001001010010100101001 на 1111111111000000000000000 через общую постоянную базу данных.
( можете редактирвать ,копировать, присваивать, распространять, и строить свои методы ) ( прошу показать и разослать код математикам, учёным и программистам )
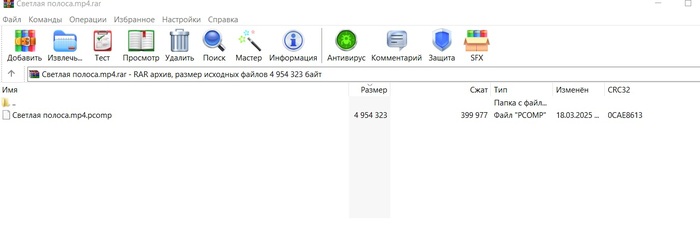
Теперь 4 мб видео это 400 кб ссылок. ( упрощённого кода ) сжатие и расжатие без потерь.
Что говорит ИИ на счёт этого алгоритма по словарю? -
В этом алгоритме словари (и coder, и decoder) заполняются уникальными значениями, полученными из 3-байтовых блоков. Так как 3 байта могут принимать 2563=16 777 216256^3 = 16\,777\,2162563=16777216 возможных комбинаций, максимальное число уникальных значений, которое можно встретить, составляет 16 777 216 (при этом значение 0 обрабатывается отдельно, и для него не создаётся новая запись).
Если представить, что все возможные 3-байтовые комбинации встречаются, то:
В словаре coder окажется до 16 777 215 записей.
Аналогично, decoder будет содержать такое же число записей.
Фактический размер в памяти зависит от накладных расходов Python для хранения каждого элемента словаря. Для 64-битного Python можно ориентировочно принять, что один элемент (ключ+значение и внутренняя структура словаря) может занимать порядка 100 байт (это упрощённая оценка). Тогда один словарь с 16 777 21616\,777\,21616777216 элементами займёт примерно: