
Нейросети локально
Листая Пикабу, часто натыкаюсь на реклмные посты типа "Как купить доступ к %непродающееся_в_РФ%", где всякие-якие за долю малую поспособствуют доступу к нейросетям заморским и прочему.
А если я скажу, что большинство всего этого можно организовать локально на компьютере, а часть даже и на телефоне? Ты сможешь нагенерировать тысячи картинок 100 ваттных ламп накаливания, и товарищ майор не должит Дмитрию Анатольевичу об этом, ибо всё происходит в пределах устройства.
Есть одно НО. Моделей, способных сносно собирать слова в предложения на русском языке, я пока выявил ровно одну — Qwen от китайской Alibaba Group. ruGPT выплёвывает какие-то куски художественных произведений невпопад, а ГигаЧат от Сбера вообще теряет нить разговора после второго запроса. Так что:

Не важно, что ты будешь генерировать: текст, картинки, видео. No Russian.
Начнём с начала: насколько мощным должн быть комп. Ответ: GTX1060 плюс 32 гига оперативки и подкачки суммарно. Подкачка настраивется в Параметры->О Системе->(справа) -> Дополнительные параметры системы.




Пример настройки размера файла подкачки. У меня выбран системный диск, так как это самый быстрый из моих накопителей. И количество подстроено под генерацию изображений и видео моделями от 20Гб весом.
А теперь непосредственно к развёртыванию. Начнём с генератора текста.
На протяжении почти двух лет балуюсь Oobabooga's Text generator

УбаБуга
Начнём с простой установки типа портативки: скачал, распаковал, погнал.
Страничка с релизами: https://github.com/oobabooga/textgen/releases
Листаем ниже до списка портитивных сборок.
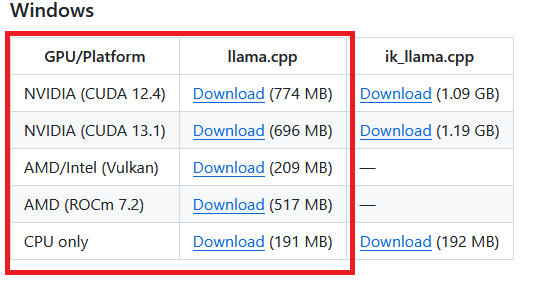
Выбираем билд по видяхе

Для nVidia карт рекомендую выбрать вариант с CUDA. Версию CUDA, поддерживаемую вашей картой можно узнать командой nvidia-smi.
Качаем, распаковываем, запускаем .bat файл.
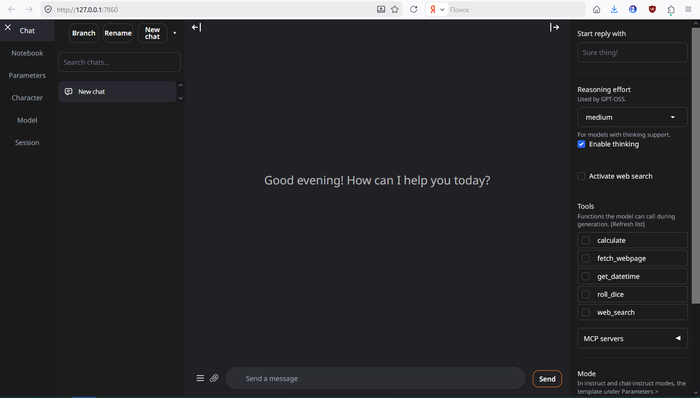
Страница интерфейса в браузере откроется автоматически в портативных сборках.
Осталось дело за малым. Скормить языковыую модель. Идём на https://huggingface.co/
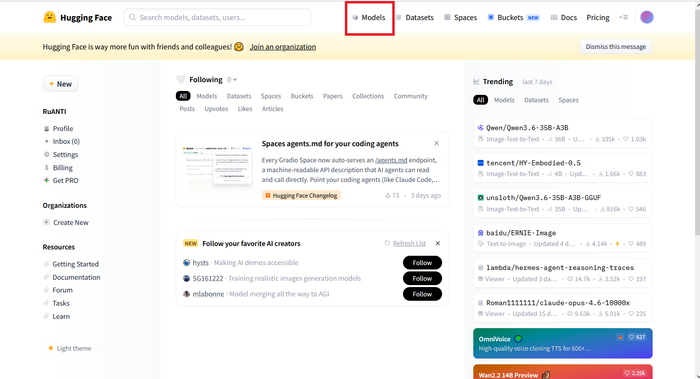
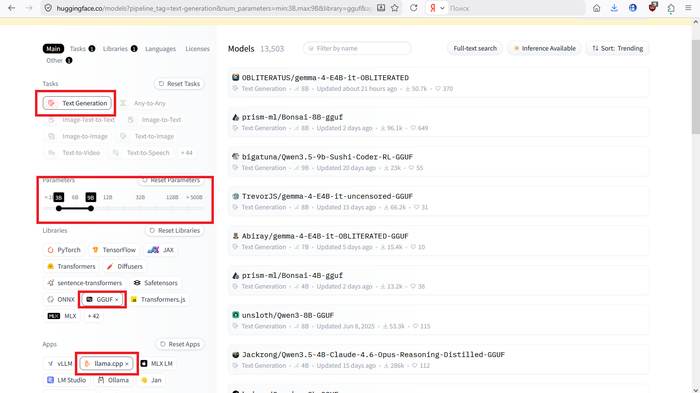
Text Generation, GGUF, Параметры, llama.cpp
Text Generation — назначение модели
GGUF — формат модели. Конкретно этот с квантизацией (читай: со сжатием), что позволит впихнуть невпихуемое
Количество параметров — Это собственно толковость модели. Измеряется в миллиардах. Один миллиард на 1 Гигабайт VRAM.
llama.cpp — приложение под которое собрана модель. Наш УбаБуга работает на этой самой Ламе по дефолту.
Возьмём 8B под 8 гиговую карту.
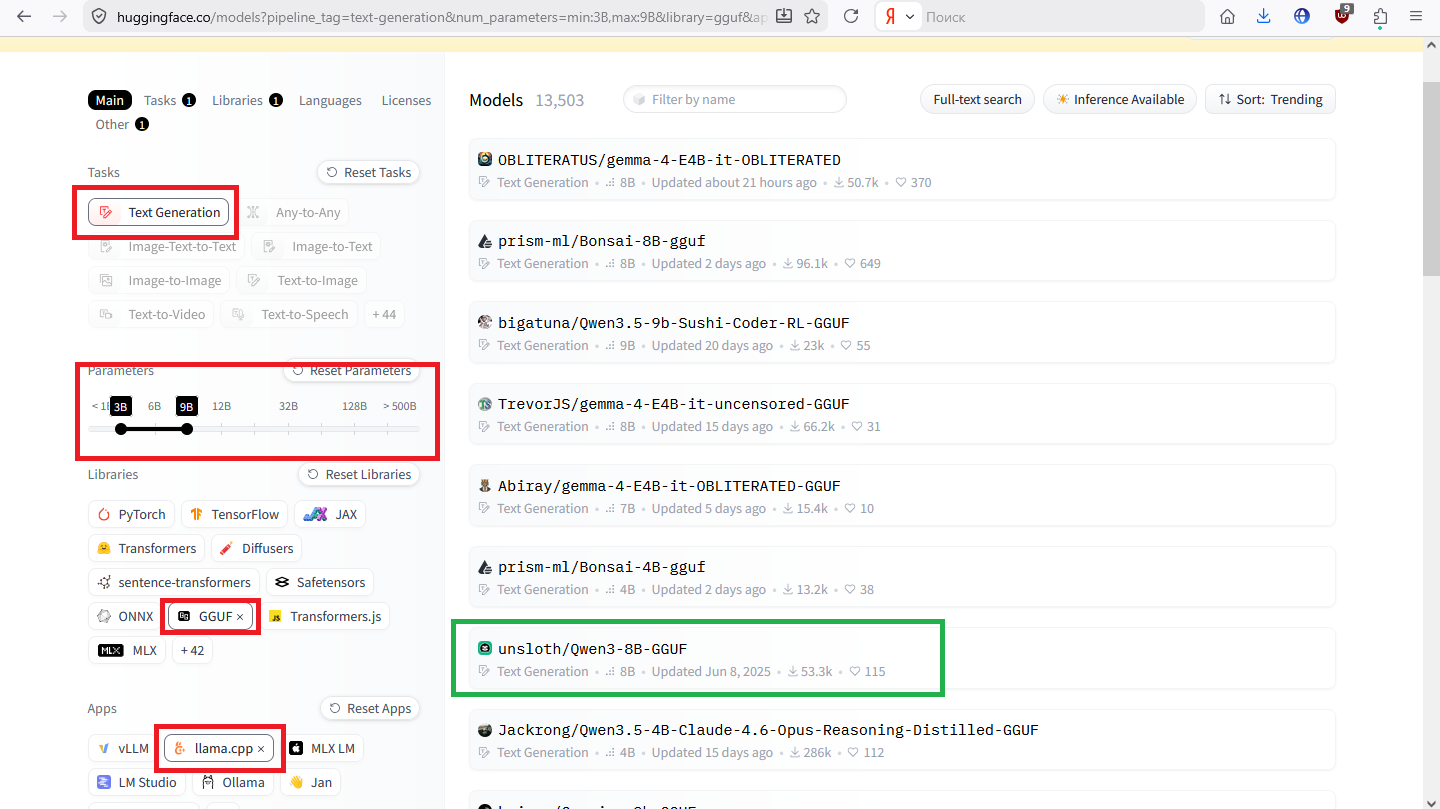
Кстати, вот она.
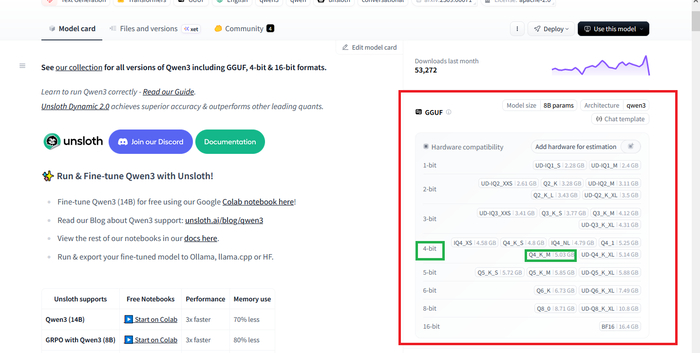
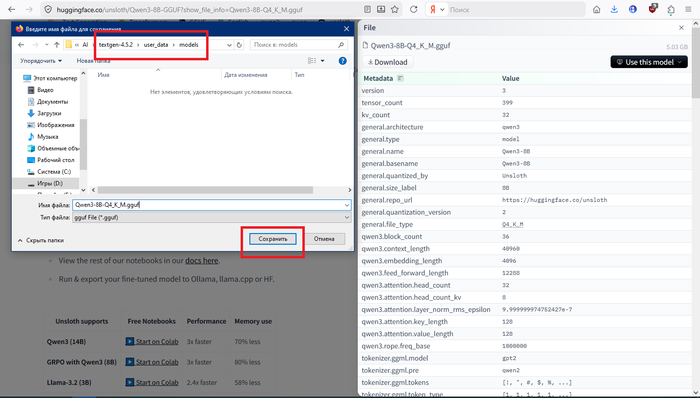
Красным выделена область загрузок всех возможных вариантов. Остановимся на середнячке 4-bit. Выбираем Q4_K_M. В более старых классификациях — Q4_0
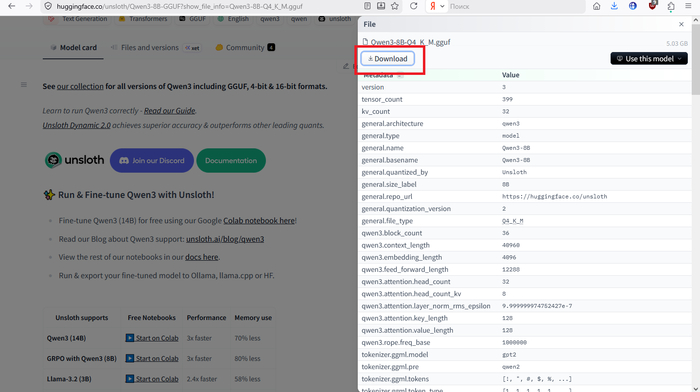
Скачали? Вертаемся взад к нашему генератору.
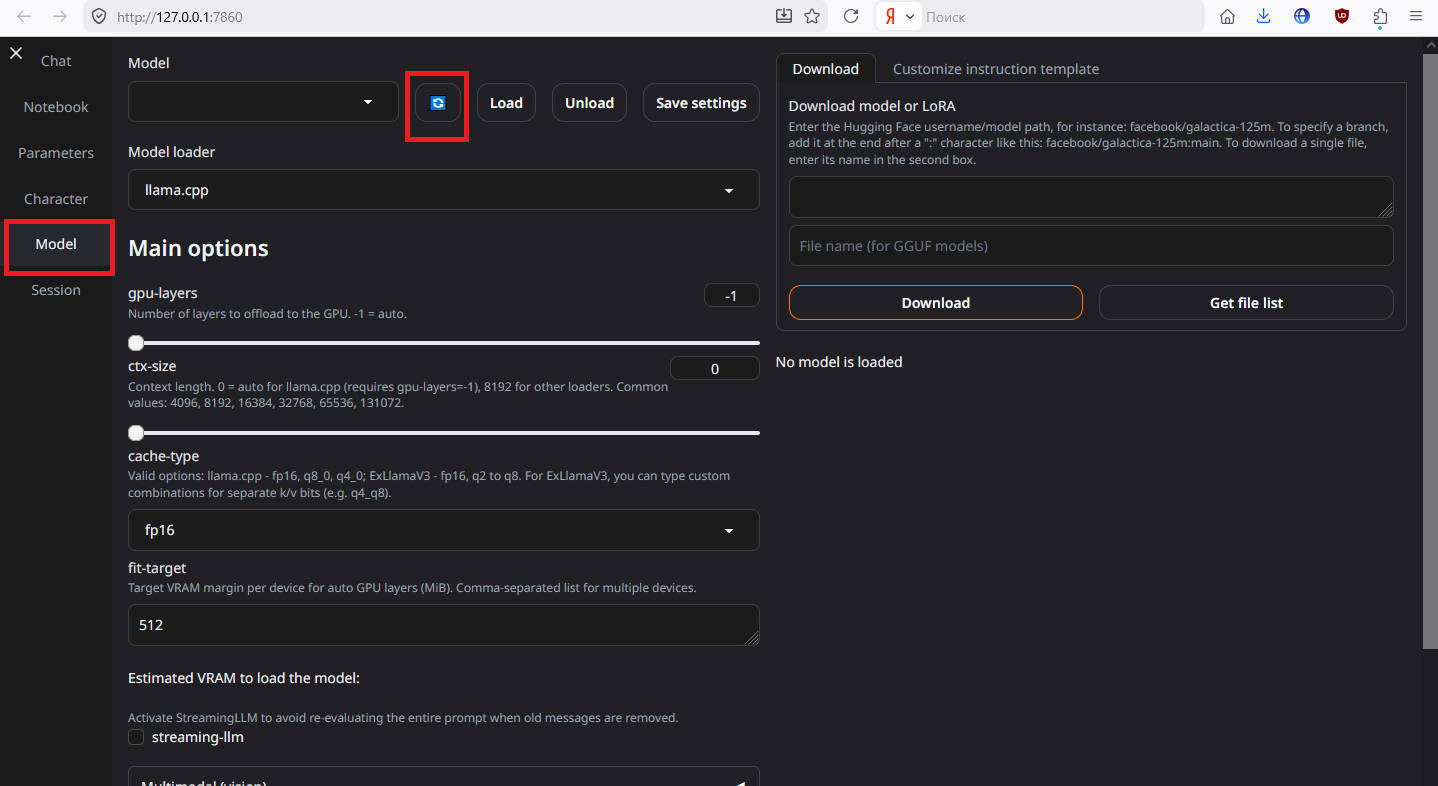
Идём на вкладку Model и жмём на синюю иконку "обновить". Это обновит список моделей и добавит свежедобавленные и уберёт свежеудалённые без перезапуска.
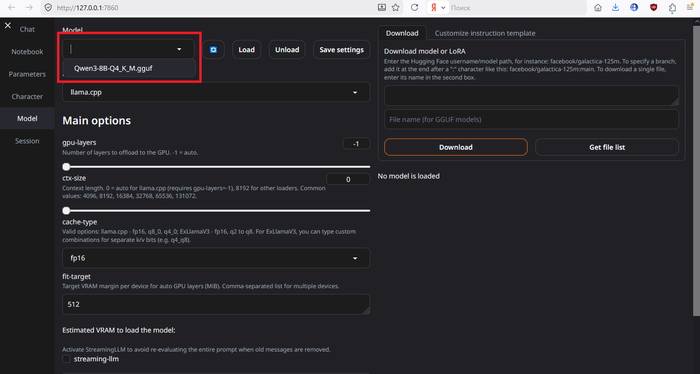
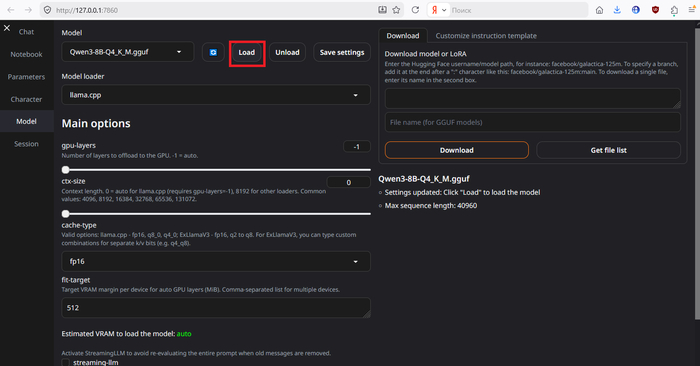
Выбираем модель в выпадающем меню, жмём «Load», ждём загрузки модели в память.
У меня получился расход видеопамяти 11.7Гб. Все что не влезет в видеопамять, будет загружено в общую память, что скажется на скорости, ибо DRAM в разы медленнее чем VRAM. Можно оптимизироваться под 8 гиговую видяху, если нужно. Для начала выгрузите модель кнопкой «Unload», если она уже загружена.
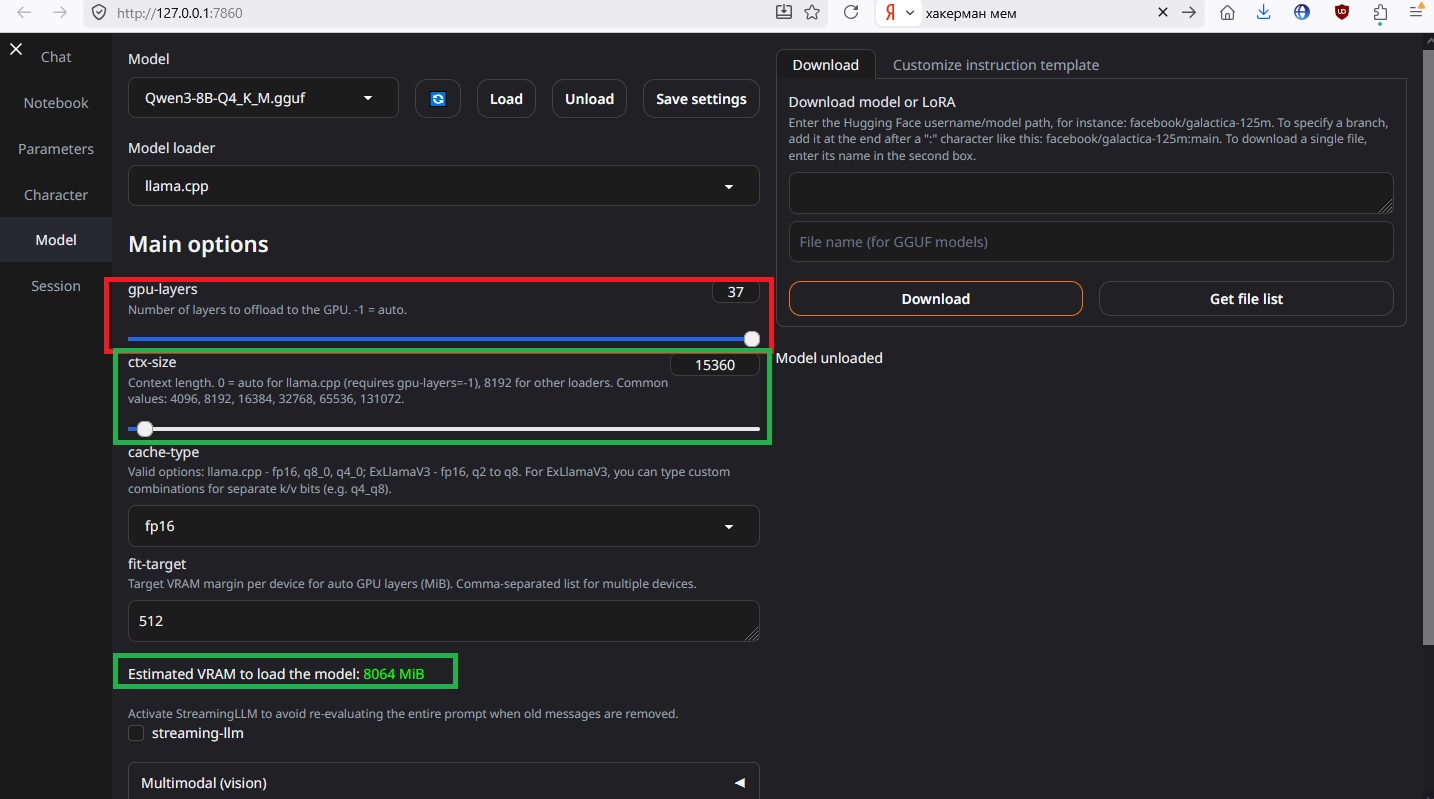
Перетягиваем вправо gpu-layers и ползунком ctx-size регулируем размер контекста, пока показатель ПРИМЕРНОГО потребления VRAM тебя не удовлетворит. Память под контекст выделяется сразу с загрузкой модели.
Едем дальше.
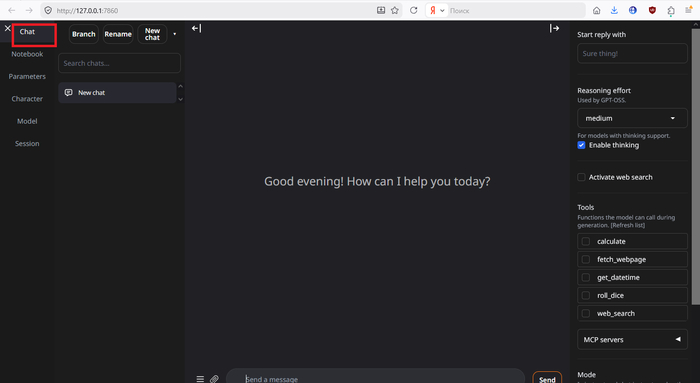
Вертаемся во вкладку «Chat» и справа снизу переключем режим в «chat». Выбрался дефолтный персонаж и начался чат.
Да, персонаж. OoobaBooga's textgen поддерживает персонажей.
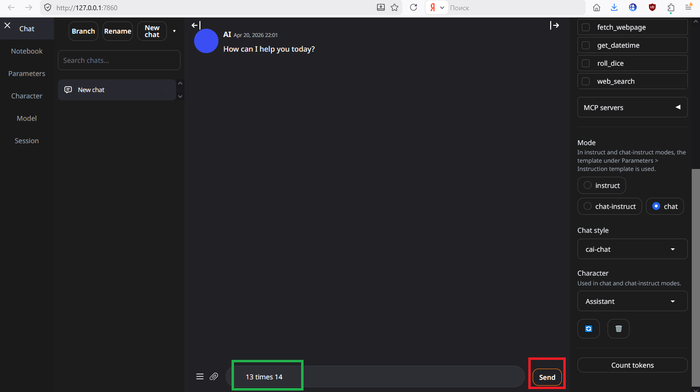
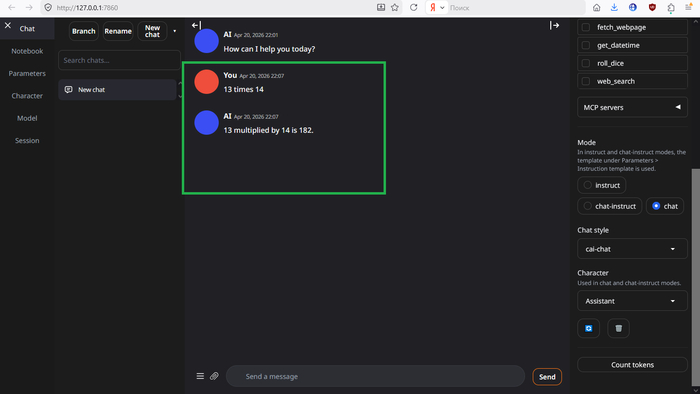
Ну чё, народ, погнали?
Оно работает! Поздравляю.
Пробуем установить персонажа? Вот, кстати, приготвил: https://disk.yandex.ru/i/IFkKHGxMpMhOCw
Да, это PNG картинка. Персонаж хранится в метаданных. Всё прям как у ILLUSION.
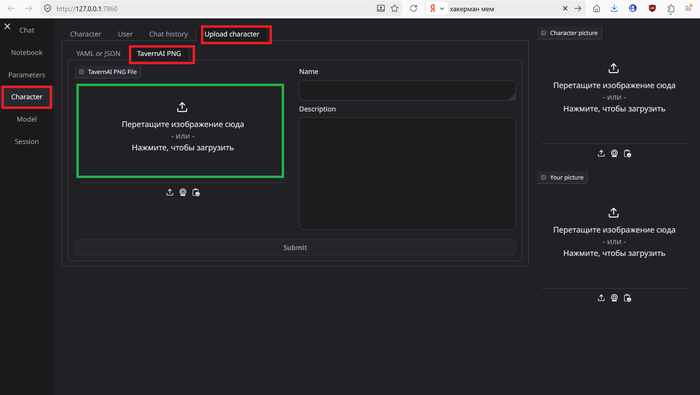
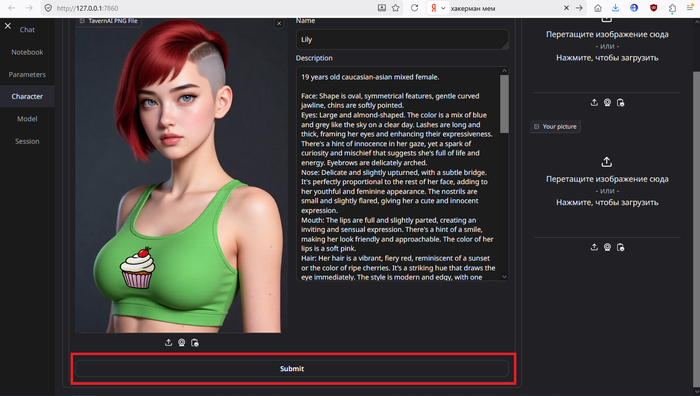
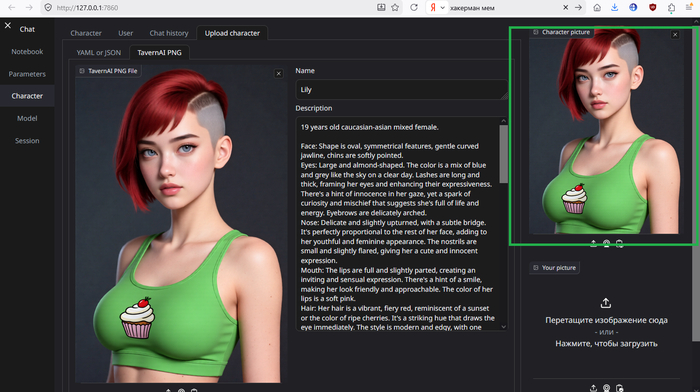
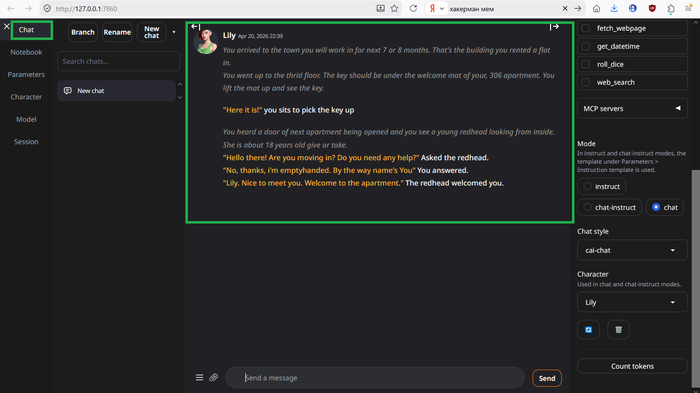
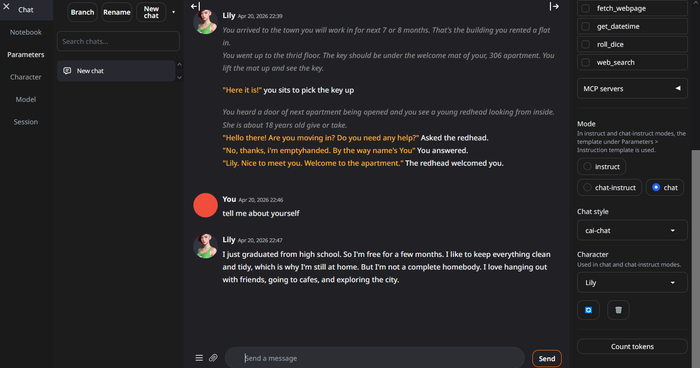
Идём Character -> Upload character -> TavernAI PNG. Перетаскиваем или жмём и выбираем картинку. Жмём Submit. После появления изображения справа сверху возвращаемся во вкладку «Chat». Пробуем.
Оно работает! Поздравляю.



Ещё кое-что...