

Ответ на пост «В Китае разработали лазер для безопасной срубки деревьев»

Ничего не подозревающий пилот в это время
Ничего не подозревающий пилот в это время
Специалисты наводят лазер через оптический прицел и одним нажатием сносят ненужные ветки
Генеративные нейросети любят ловить глюки и выдавать всякую чушь. Причем так массово, что Кембриджский словарь признал «галлюцинировать» главным словом 2023 года. В чем причина этой проблемы? Является ли генеративный ИИ интеллектом? И что общего у ChatGPT и копировального аппарата Xerox? Разбираемся, попутно разрушая мифы про этот наш вездесущий искусственный интеллект.

"ChatGPT заменит поисковики", - говорили они.
Авторитетный Кебриджский словарь признал словом года «галлюцинировать» (hallucinate). Причем не в вакууме, а применительно к генеративному ИИ. Глюки ИИ — это когда ChatGPT выдает косяки в фактологии, из‑за которых пользователи теряют всякую веру его результатам (и срочно бегут все перепроверять в Гугле). Но не стоит злиться на генеративный ИИ за подобные выкрутасы, ведь дело в самой логике его работы. Ее мы сегодня и разберем с помощью парочки метких аналогий.
Год назад Google впервые представил миру своего чат‑бота Bard. Сейчас он вполне неплохо работает (хотя и уступает первопроходцу), но на той презентации умудрился выдать базу‑основу. Он заявил, что «Джеймс Уэбб» был первым космическим телескопом, сделавшим снимки планет за пределами Солнечной системы. Это была ошибка — первые снимки этих самых планет сделал другой телескоп еще за 17 лет до появления на свет «Джеймса Уэбба». Неточность Барда быстро заметили, в результате чего у Google даже просела стоимость акций.
ИИ чат‑боты регулярно выдают неточности и искажения. Чаще всего они незначительны и касаются отдельных деталей. Однако даже наличие небольших косяков сильно снижает полезность генеративного ИИ на практике. Ведь если вы знаете, что ошибки в целом возможны и даже регулярны, то не можете полностью довериться этому инструменту.
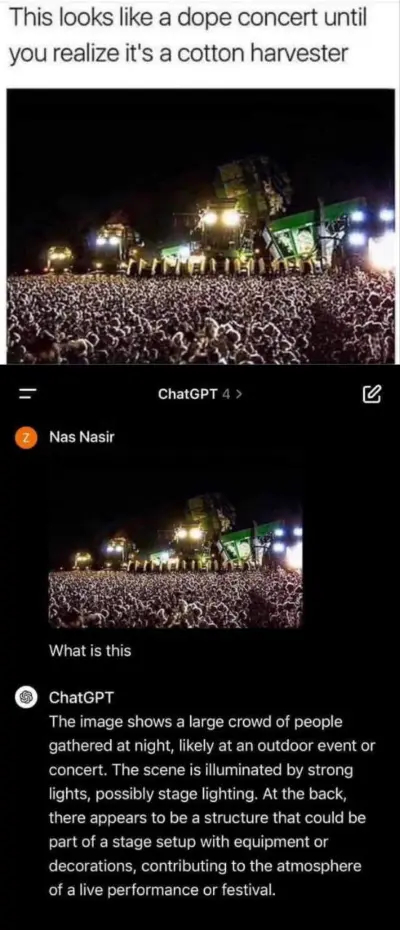
Сферические глюки ИИ в вакууме. Да-да, ChatGPT, конечно же это мероприятие или концерт. День хлопка на плантации отмечают, не иначе. А впрочем, не каждый человек справился бы лучше.
Но не спешите обвинять бездушную машину в злом умысле. У нее нет цели подставить кожаных или намеренно ввести в заблуждение.
Причина в другом. Дело в том, что генеративный ИИ по принципам своего устройства больше напоминает архиватор (т. е. программу для сжатия файлов), нежели полноценное сознание. Именно поэтому эксперты в ИИ зачастую недовольно фыркают, когда генеративные нейросети называют звучным словом «интеллект». А еще это отлично объясняет, почему ChatGPT очень вряд ли превратится в злой скайнет (но это не точно).
Итак, давайте разбираться. В этом нам поможет классная статья издания The New Yorker за авторством Теда Чана, из которой я с большой благодарностью буду заимствовать ключевые тезисы. Подкрепляя их иллюстрациями, дабы нагляднее было.
Осмыслять проблему удобнее чуть издалека, с интересной аналогии.
В 2013 году копировальный аппатар Xerox в офисе одной немецкой строительной фирмы начал творить очень странные дела. Ребята делали копию проекта дома с тремя комнатами и заметили очень любопытное расхождение:
На оригинальной схеме три команты имели разную площадь — 14.13, 21.11 и 17.42 метра. То есть, на чертеже в центре каждой комнаты стояла разная циферка, обозначающая площадь.
Xerox же выдал копию, где на всех трех комнатах стояла одинаковая цифра — 14.13 (как площадь первой комнаты).
Компания прифигела от такого контринтуитивного глюка копировальной техники и обратилась к специалисту по обработке данных Давиду Крайзелю.
Вы, возможно, спросите: «Аффтар, а почему они обратились к человеку такой специальности, а не к эксперту в копировальном деле?». Дело в том, что современные ксероксы используют не классический процесс ксерографии (это когда изображения передаются с оригинала на копию через прохождение лучей через специальный барабан — в общем, аналоговая классика), а цифровое сканирование.
А когда речь заходит о каких‑то манипуляциях с изображениями (да и файлами в целом) в цифровой среде, то мы почти наверняка столкнемся с процедурой сжатия объектов.
Процедура сжатия состоит из двух ключевых этапов. Первый — кодирование (encoding), в ходе которого изначальное изображение переводится в какой‑то более компактный формат. Второй — декодирование (decoding), т. е. обратное действие.
При этом сжатие бывает двух типов:
Сжатие без потерь (lossless) — это когда закодированные данные могут быть восстановлены с точностью до пикселя или бита. Если речь идет про изображения, то самый популярный формат сжатия без потерь — это PNG.
Сжатие с потерями (lossy) — здесь уже распакованные данные отличаются от исходных, но степень отличия столь незначительно и минорна, что их без проблем можно дальше использовать. Яркий пример — JPEG.

Чоткие пацаны не забивают карту памяти своего Сименса пээнгэшками!
Сжатие без потерь обычно используется, скажем, для компьютерных программ. Потому что если потерять хотя бы один символ кода, то все поломается. А вот для изображений, аудио или видеофайлов часто предпочитают использовать сжатие с потерями. Ведь даже если отдельные пиксели картинки поедут или мелодия будет звучать чуть менее чисто, то человечьи органы осязания все равно не заметят подлога, так что пофиг.
Здесь и была зарыта собака в истории со ксероксом. Агрегат использовал lossy‑сжатие формата JBIG2, которое работает примерно так:
В целях экономии места или вычислительных мощностей (а может и того и другого, пойди разберись в этой офисной технике) машина ищет очень похожие области изображения и сохраняет для всех них одну копию, которую потом воспроизводит обратно при декодинге.
Проще говоря, конкретно в этом случае ксерокс почему‑то решил, что комнаты на чертеже так похожи друг на друга, что можно смело забивать на различия и считывать только одну из них — ту, которая площадью 14,13 кв метров. А потом везде нарисовать именно её. То ли потому что формат JBIG2 создан для работы с черно‑белыми офисными бумажками, а не с мелкими объектами чертежей, то ли просто у аппарата был дурной характер — история умалчивает. Но суть в том, что ксерокс решил забить на небольшие различия именно в том случае, где эти различия оказались очень даже критичными.
Вообще, сам факт того, что ксерокс использует сжатие с потерями — это не проблема. Проблема в том, что изображение деградирует очень незначительно, «на тоненького». Настолько чуть‑чуть, что с ходу фиг заметишь. Одно дело, если бы он просто блюррил упрощенные области картинки, но он их может просто вероломно заменить. А строительному бюро потом объясняй заказчику, почему в итоге все комнаты получились одинаковыми.
Запомним историю со Xerox и проведем один мысленный эксперимент (он нам нужен, чтобы подойти еще ближе к пониманию проблемы этих наших GPT).
Представьте, что завтра во всем мире отключат интернет. Вообще. Совсем. Не будет его больше. В связи с этим мы решаем по максимуму выгрузить все содержимое интернета к себе на частный сервер. Ну окей, пусть будет не весь интернет (это совсем тяжко), но хотя бы всю Википедию. Чтобы оставить великие знания потомкам.
Разумеется, место на сервера ограничено — вся Википедия туда не влезет. Допустим, места хватит на 1% от оригинального размера, т. е. сжать изначальный объем нужно в 100 раз. Следовательно, нужно прибегнуть к сжатию с потерями.

Печатать всю Википедию мы, пожалуй, не будем. Это too much даже для гипотетического мысленного эксперимента. Обойдемся цифровым форматом.
Итак, мы применяем сжатие с потерями. Алгоритм у нас мощный — он легко находит чрезвычайно тонкие статистические закономерности на совершенно разных страницах (иногда одинаковыми оказываются длинные фразы или целые предложения). Таким образом нам удается сжать Википедию примерно в 100 раз, что и требовалось в нашем мысленном эксперименте.
Теперь нам не так страшно потерять доступ к интернету, ведь у нас как минимум выкачана база знаний в виде Википедии (а значит, потомкам будет чуть проще делать выводы о предназначении предметов, найденных при раскопках через тысячи лет). Но есть нюанс:
Мы не сможем найти любую цитату слово в слово. Потому что из‑за сжатия с потерями наша Википедия сохранена не буквально, а приблизительно. Алгоритм оставил только то, что кровь из носу требуется, чтобы сохранить смысл всех сущностей. Остальное же было объединено и апроксимировано (т. е. передано приблизительно). А значит, чтобы достать информацию, нам нужно создать интерфейс, который умеет в ответ за запрос выдавать основной смысл.
Чувствуете, на этом моменте комнату начинает наполнять знакомый аромат генеративного ИИ?
Да‑да, только что мы мысленно создали большую языковую модель (LLM), обученную на Википедии (в нашем конкретном случае).
ChatGPT — это заблюренный JPEG не только Википедии, но вообще всего интернета. Когда модель дообучают, этот JPEG еще лучше детализируется в отдельных уголках. Но суть все та же — LLM аккумулирует именно бОльшую часть интернета, но далеку не всю.
Следовательно, когда GPT отвечает за ваш запрос, он не может выдать точную последовательность символов. Он сделает приближение. Другое дело, что GPT отлично умеет превращать это приближение в связный и опрятный текст, который человеческий мозг не может сходу отличить от оригинального.
А как LLM воссоздает пробелы, которые отсутствуют в его сжатой версии интернета? Ответ — интерполяция. Не будем вдаваться в математические дебри этой штуки. Простыми словами — это оценка отсутствующего элемента путем анализа того, что находится с двух сторон от этого разрыва. Когда программа обработки изображений декодирует ранее сжатую фотографию и должна восстановить пиксель, потерянный в процессе сжатия, она просматривает близлежащие пиксели и, по сути, вычисляет среднее (генерирует его).
То же самое делает ChatGPT, только со словами и прочими текстовыми смысловыми сущностями. Секрет в том, что ChatGPT научился делать эту интерполяцию настолько мастерски, что люди не могут этого раскусить (и думают, что имеют дело с настоящим интеллектом).
По сути, генеративный ИИ выдумывает отсутствующие элементы на основе смежных. Фантазер этот GPT, получается.

Если теперь вы хотя бы иногда будете вспоминать эту картинку во время написания очередного промпта, то это значит, что я написал эту статью не напрасно :)
Описанная выше логика отлично объясняет «галлюцинации». Просто‑напросто даже самый большой мастер интерполяции иногда допускает ошибки. И совсем периодически эти ошибки замечают. Однако сам факт вероятности ошибок сильно снижает надежность инструмента. Ведь это значит, что в любой момент может вылезти значимый косяк. А это уже означает, что все результаты нужно сверять с оригинальным текстом (= лишние затраты ресурсов).
И да, и нет. Тут, как говорится, смотря как посмотреть.
Действительно, не стоит очеловечивать генеративный ИИ. То есть не нужно отождествлять его с человеческим интеллектом.
ChatGPT впитывает информацию с большими потерями, восстанавливая ее через интерполяцию. В результате он как будто пересказывает суть своими словами. Вероятно, здесь и кроется разгадка, почему люди так восхищаются генеративным ИИ.
Дело в том, что еще со школьных и универских скамей у людей сидит на подкорке убеждение (весьма резонное), что точное воспроизведение информации — удел зубрилок, которые «выучили, но не поняли», а по‑настоящему толковые ребята пересказывают все своими словами, сохраняя суть. Поэтому и ChatGPT нам кажется толковым парнем, который реально все понимает. На самом же деле он просто передает основной смысл, воссоздавая пропуски за счет усреднения.
Именно поэтому, кстати, GPT3 не очень хорошо справлялся с точными вычислениями больших чисел (допустим, выражение «2345 х 57789» в интернете встретишь не так уж часто), но при этом как Боженька писал всякие студенческие эссе. По мере перехода к GPT4 модель стала более продвинутой, в нее завезли больше закономерностей, поэтому она стала сносно щелкать любую арифметику.
Однако, есть и другая сторона медали. Она касается тех самых закономерностей, которых в GPT4 завезли больше. Смотрите:
Есть такая премия под названием «Приз Хаттера». Ее в 2006 г. учредил старший научный сотрудник DeepMind (это ИИ‑стартап, уже давно купленный Гуглом) Маркус Хаттер. Суть конкурса такая:
Есть текстовый файл на английском языке размером 1 Гб. Его требуется сжать без потерь. Каждый, кто сожмет на 1% от предыдущего лучшего результат, получит 5000 евро. Сейчас лучший результат 115 Мб.
На самом деле, это не просто конкурс по сжатию текста без потерь. Это важное упражнение, приближающее понимание сути настоящего ("взрослого") искусственного интеллекта. И вот этого товарища уже можно отождествлять с человеческим сознанием как минимум по одному признаку:
Чтобы наиболее эффективно сжимать текст без потерь, он должен уметь по-настоящему понимать этот текст и сопоставлять его содержание с реальными знаниями о мире.

Маркус Хаттер вскоре после запуска своего конкурса. Кстати, Лекс Фридман записывал с ним интервью еще три года назад. Рекомендую глянуть, если пропустили.
Например, вот есть у нас какая‑то статья в Википедии на тему физики. Допустим, некий текст, где фигурирует Второй закон Ньютона (Сила = Масса x Ускорение). Вероятно, самый простой способ сжать без потерь такую статью — это заложить в алгоритм сжатия базовый постулат, что «Сила = Масса x Ускорение». Тогда алгоритм может выкинуть повторящиеся куски статьи, вытекающие из логики этого закона, а потом легко их восстановить при надобности (потому что знает сам базовый принцип).
Аналогично и со статьей на некую экономическую тему. Наверняка там будет дофига выводов, основанных на законе спроса и предложения. А значит, если в принцип сжатия заложен этот закон, то можно выкинуть кучу «вторичной» информации.
ИИ работает так же. Чем больше первичных правил и законов он знает, тем меньше может париться с запоминанием вторичных выводов (ведь он может их легко восстановить — если и не дословно, то достаточно точно по смыслу).
При таком раскладе ИИ действительно становится интеллектом — в том плане, что делает частные выводы на основе общих знаний. По сути, старая добрая дедукция из детективных романов про Шерлока Холмса.

Всегда догадывался, что этот парень - искусственный интеллект.
Получается, что хотя ChatGPT все еще очень далек от настоящего интеллекта, он все сильнее стремится к таковому по мере наполнения своей базы знаний и лучшей адаптации к устройству нашего мира. Вот такой интересный процесс.
В целом, получается, что да. Пока что нельзя. Ведь:
Во‑первых, мы не знаем наверняка, скушала ли LLM откровенную пропаганду или какие‑нибудь антинаучные теории заговора. Если скушала, то она могла выстроить очень специфические логические связи. И если она будет заполнять пробелы в соответствии с ними, то результат может получиться очень веселым.
Во‑вторых, также нет гарантии, что ИИшный «JPEG» не заблюррил полностью ту информацию, которая нужна для отработки конретно нашего запроса.
Держа в голове эти два обстоятельства, можем сделать вывод — результаты нынешнего генеративного ИИ можно использовать как отправную точку для анализа, но не финальную истину (не стоит сразу же нести выводы от ИИ своему начальнику, ну вы поняли).
Также стоит разобраться — а хорошая ли это идея создавать контент с помощью ИИ?
Ну, если вы работает на объем, то наверно да. А если на качество и уникальность, то не уверен. Ведь даже если вы используете ИИ для получения некой первичной версии, то держите в уме, что холстом вашего великого произведения будет вторичный (изначально переработанный) продукт, где часть смыслов вообще фантазировалась через интерполяцию (иначе говоря — отправной точки ваших смыслов станет совсем уж откровенный полуфабрикат).
Так что, если вы хотите создавать уникальный контент — то, пожалуй, ИИ стоит использовать только для поиска информации, не более. Однако, если ваша задача переупаковать уже готовый контент — то почему бы нет? Особенно если вам нужно избавиться от оков авторских прав и копирайтов (рубрика «вредные советы»).
Глюки ИИ — это норма. Иногда они кажутся нам смешными и чересчур упоротыми. Но объяснение лежит на поверхности.
По мере обрастания моделей закономерностями и знаниями о мире, глюков будет все меньше. Если, конечно, мир не будет усложняться с той же скоростью или быстрее.
Полезно учитывать эту особенность при использовании ИИ. Так будет меньше шансов серьезно опростоволоситься в кругу уважаемых людей или испортить качество выдаваемых смыслов.
Когда генеративный ИИ сможет стать Скайнетом? Учитывая вышысказанное, рискну предположить, что еще очень‑очень нескоро. Если вообще сможет.

После осмысления информации выше я теперь представляю Скайнет примерно так ("ути-пути какой хорошенький"). Надеюсь, меня за такое не прикончат первым...
Большая часть этой статьи — художественный перевод вот этой статьи. Очень‑очень вольный перевод — считайте, что я интерполировал кое‑какие смыслы, чтобы воспринимать их было проще и веселее. Статья вышла в феврале 2023, т. е. еще до релиза GPT4, но логику передает верно. Рекомендую прочитать оригинал, там еще больше примеров и иллюстраций (но предупреждаю — понадобится неплохой английский и ясное сознание).
Также рекомендую заглянуть на мой тг‑канал Дизраптор. Там я простым человечьим языком и с максимальной наглядностью пишу про разные интересные штуки из мира технологий, инноваций и бизнеса. В том числе про этот наш ИИ, но не только про него.
Программа о новых гаджетах и технологиях
Все хорошее когда-нибудь… начинается!
Радио ЧипльДук / 4duk

Сегодня я проснулся с мыслью, что мир пришёл к состоянию, когда всё что можно было придумать и изобрести уже придумано. В области техники, медицины, социологии, экономики за последние лет 200 человечество сделало все основные научные открытия. Эти открытия ещё некоторое время помогут создавать что-то новое и усовершенствовать уже изобретённое, но принципиально другого уже ничего не будет.
Мозг человека не безграничен в фантазиях. Есть предел и физиологии и мыслям. Можно научиться высоко подпрыгивать, выше других, выше себя, но перепрыгнуть через дом ты всё равно не сможешь. Взлететь не сможешь, просто махая руками. Так же и с мозгом. Развивая мышление, фантазию, продуктивность, подключая коллективное сознание, мы придём к моменту, когда эта мощность достигнет своего максимума.
Все те инновационные всплески, которые мы наблюдаем, заложены ещё 50-60 лет назад, сейчас они получили возможность для реализации, либо просто у кого-то дошли руки. Достаточно поднять журналы "техника молодёжи" или "наука и жизнь" или какие-то подобные, не обязательно отечественные за 50-60 годы. Всё что мы сейчас видим вокруг себя: интернет, беспилотные автомобили, приёмы управления людьми, лечение болезней etc - там изложено в качестве футуристических проектов.
Придумать ничего уникального не получится. Напиши в поисковике что-то, как тебе кажется, неповторимое и он выдаст тебе с десяток уже реализованных и улучшенных результатов. В том числе и варианты, когда кому-то это надоело и он это уже забросил ещё в 2015 году.
Какой из этого вывод? Человечество всё меньше развивается качественно вверх, но всё больше количественно вширь, площадями, за счёт использования изобретений.

Новые научные открытия постоянно меняют нашу жизнь, делая ее более комфортной, интересной и продуктивной. Каждый день мы сталкиваемся с новыми технологиями и идеями, которые раньше казались невозможными. В этой статье рассмотрим несколько интересных открытий в науке, которые обещают изменить нашу жизнь в ближайшем будущем.Одним из самых захватывающих открытий последнего времени является разработка квантовых компьютеров. Квантовые компьютеры обещают значительно увеличить вычислительную мощность и скорость обработки данных. С помощью квантовых компьютеров мы сможем решать сложные задачи, которые раньше были недоступны для классических компьютеров. Например, квантовые компьютеры могут эффективно использоваться в фармацевтической промышленности для разработки новых лекарств или в банковском секторе для защиты данных и обработки транзакций.
Научные открытия играют важную роль в нашей жизни, и каждый день мы сталкиваемся с новыми технологиями и идеями, которые меняют нашу жизнь. Описанные в статье открытия - это только некоторые из множества интересных научных открытий, которые обещают изменить нашу жизнь в будущем.Я в соцсетях:
140 лет назад была такая профессия - оператор телефонной станции. Женщина сидела перед шкафом с проводами и втыкала в нужную дырку штекер, чтобы абоненты могли поговорить друг с другом. Она могла подслушать разговор и именно недобросовестное переключение звонков привело к изобретению АТС, где ты просто набираешь номер и говоришь с кем хочешь без участия человека посередине (но это неточно).
80 лет назад была такая профессия - оператор лифта. Мужик стоял в лифте, открывал и закрывал двери и нажимал на кнопку этажа. Ты не мог в лифте говорить о серьезных вещах, потому что там всегда был посторонний, он хотел зарплату и соцпакет, и именно забастовка за повышение оклада привела к ускоренному внедрению автоматических лифтов, где ты сам себе нажиматель кнопки, а двери открываются моторчиком.
Лет через 20 мы будем со смехом вспоминать, что вызывая такси мы ехали в замкнутом пространстве с незнакомым мужиком, который сидел и крутил руль, рассказывал истории, слушал свою музыку, занимал четверть сидячих мест и иногда неприятно пах, глупость какая, вы б еще на лошади поехали, чтобы вообще задолбаться по дороге. И что в машине не было кроватей, чтобы нормально поспать, едя куда-то за 1000 км в ночь, и что кто-то погибал, засыпая за рулем или потому, что нарушил правила. А еще что была целая профессия перевозящих на дальняк грузы людей, живущих в кабинах авто при этом, ужас. Не говоря уже о доставщиках еды и товаров по месту, целый день развозящих пакеты и коробки вместо дронов, неужели нельзя было раньше автоматизировать.
Потом, конечно же, глупостью станет профессия переводчика-синхрониста, уборщика в номерах, массажиста, водителя автобуса, повара, пилота самолета и машиниста поезда, комбайнера-тракториста, мерчандайзера, строителя и вальщика леса. Но тут еще можно, в теории, построить карьеру и закончить ее за жизнь, в отличии от таксистов - они в крупных городах пропадут лет через 10-15 максимум, хотя ловить там кроме геморроя уже нечего давным-давно.
Вообще, если вам сейчас меньше 25 лет и вы планируете всю карьеру работать руками - подумайте еще раз, это было ошибкой в начале 2000-х, сейчас это просто смертельный номер.

Их есть у нас! Красивая карта, целых три уровня и много жителей, которых надо осчастливить быстрым интернетом. Для этого придется немножко подумать, но оно того стоит: ведь тем, кто дойдет до конца, выдадим красивую награду в профиль!










