В мире умных домов часто приходится выбирать между удобством и функционалом. Раздумывая над тем, каким может быть идеальный умный дом, мы пришли к идее MajorDom — системе, которая стремится изменить этот баланс и упростить быт без жертв. В этом посте поделимся нашим видением и некоторыми основными принципами новой экосистемы, включая приватность, автономность и широкую поддержку устройств.
automate smart — not hard (MajorDom)
В этой статье мы не будем вдаваться во все подробности технических деталей, реализаций и протоколов, а сосредоточимся на более общем, абстрактном, пользовательском описании системы, иначе статья выйдет слишком длинной, но мы обязательно вернемся ко всем деталям позже
Домашние гаджеты
Сегодня существует много разных гаджетов для дома: светильники, шторы, обогреватели, пылесосы, датчика безопасности и микроклимата. Они созданы для того, чтобы облегчить жизнь, но не всё так однозначно.
Раньше каждое устройство имело свой протокол управления, свои стандарты, свои методы безопасности и каждому из них нужно было отдельное приложение или пульт. Чем больше устройств в доме, тем больше времени нужно посвятить управлению ими, что превращается в новую рутину. Это похоже на жонглирование слишком большим количеством мячей.
Приложения для домашних гаджетов
Существующие решения
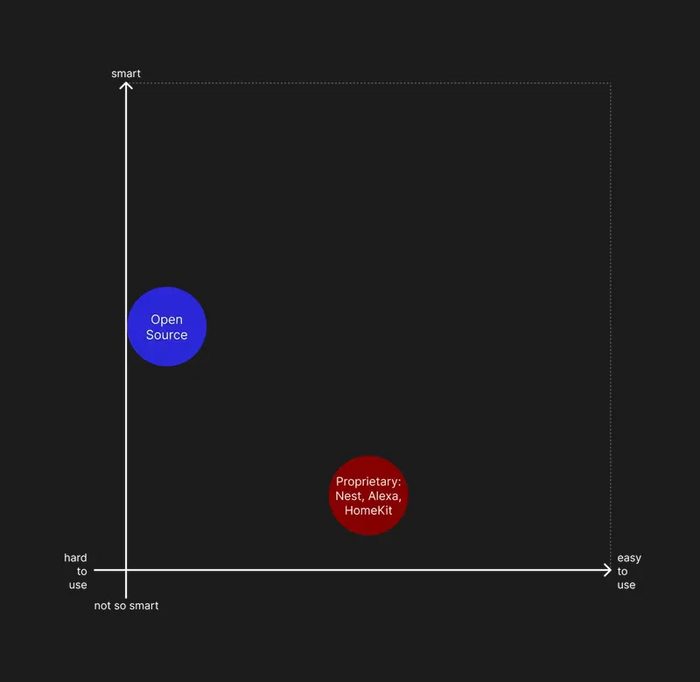
Системы "умного" дома (или домашней автоматизации) должны были решить эту проблему, но до идеала им еще далеко. Есть два типа таких систем: проприетарные от цифровых корпораций и народные с открытым кодом. К сожалению, и у тех, и у тех есть минусы. Предлагаю составить график, в котором по оси x будет легкость использования сложной к простой, а по оси y - умность и функциональность системы.
График: легкость использования к умности системы
Окажется, что все проприетарные системы находятся где-то в центре-внизу. Они дают некоторый функционал, с которым может справиться обычный человек, потратив какое-то время на изучение. Чаще всего эти системы являются закрытыми и поддерживают только свой ограниченный список устройств в своем специальном приложении. Их функциональность сводится к замене физического выключателя кнопкой в телефоне или простыми голосовыми командами. Иногда встречаются элементарные автоматизации, точнее скрипты, которые нужно писать вручную.
В то же время они слишком зависят от облачных решений. Сбой сервера, изменения в политике, новые регуляции или простое отсутствие интернета означают отключение умного дома.
Но, что хуже всего, самые популярные системы принадлежат рекламным или маркетплейсным гигантам, зарабатывающим на продаже персональных данных пользователей. Это основа их бизнес-модели, из-за чего они не могут измениться, поэтому о доверии и приватности здесь не может быть и речи.
Осьминог монополии (отсылка к "standard oil octopus")
Тем, кто хочет больше возможностей или не хочет слежки, приходится переходить на открытые решения и платить за это сложностью настройки и установки. Это область выше и левее центра, но часто это того стоит. Открытые системы предлагают больше свободы, возможности интеграции с любыми устройствами и протоколами благодаря плагинам, неограниченные кастомизации и полный контроль. Единственное, это задачка для технарей, желающих проводить вечера за изучением форумов и разработкой. Точно так же некоторым нравится проводить часы в гараже перебирая все детали машины. Я не говорю, что это плохо, ведь у каждого есть свои хобби, но большинство людей хочет автомобиль, чтобы просто на нем ездить. Конечно, вы можете нанять профессионала, который займется всеми устройствами и безопасностью, потратив на это целое состояние. Но что, если вы не хотите ни нанимать профессионала, ни становиться им самостоятельно?
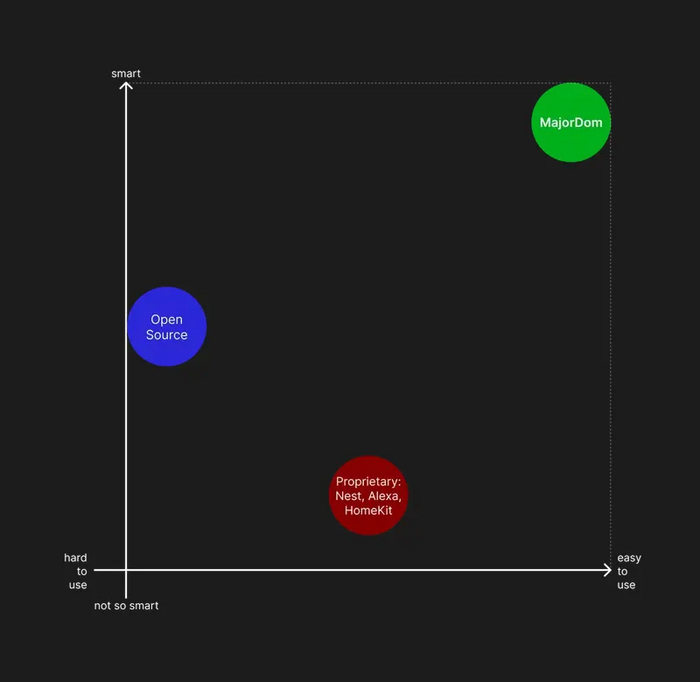
Мы хотим сделать систему, которая займет правый верхний угол: будет работать прямо из коробки, поддерживать широкий спектр устройств, надежно хранить данные пользователей, при этом будет умнее и функциональнее остальных.
График: легкость использования к умности системы (мажордом)
Экосистема умного дома
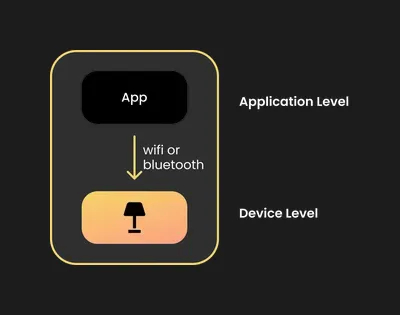
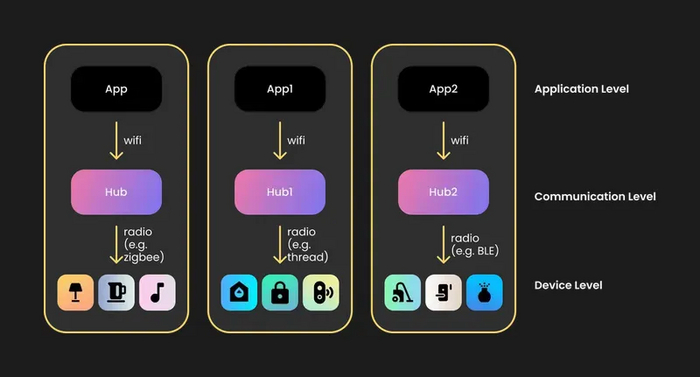
Поговорим о том, как устроены экосистемы умного дома и чем они отличаются от систем домашней автоматизации. Все начинается с устройств, напрямую управляющих домом: лампы, реле, модули с мотором. Это первый "физический" уровень. Вторым уровнем пусть будет интерфейс "application layer". Свяжем их через wifi или bluetooth.
Экосистема умного дома: приложение и устройство
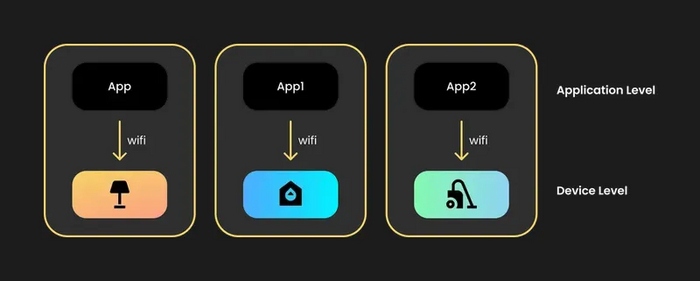
Но представим, что у нас несколько устройств, у каждого по своему приложению. Выглядит не очень удобно, да?
Экосистема умного дома: несколько приложений и устройств
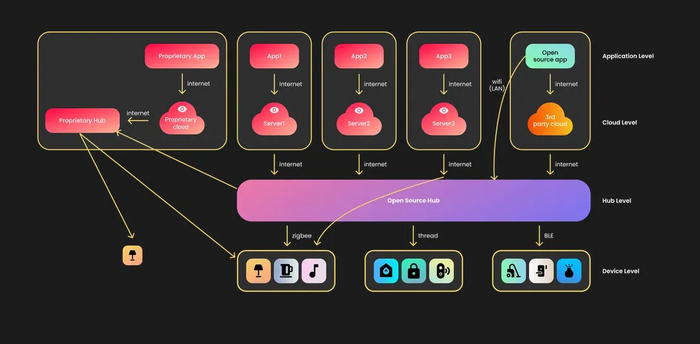
Теперь переведем устройства на более энергоэффективные радиопротоколы. Но как подключить их к смартфону? Добавим посредника в виде хаба, у которого с одной стороны радиомодуль, а с другой - тот же wifi. В качестве бонуса подключим к хабу все устройства того же производителя. Теперь в приложении может быть несколько устройств, но только одного бренда. Так выглядят закрытые "экосистемы". Каждая использует свои протоколы и стандарты, так что они не совместимы между собой.
Закрытые экосистемы умного дома с хабом
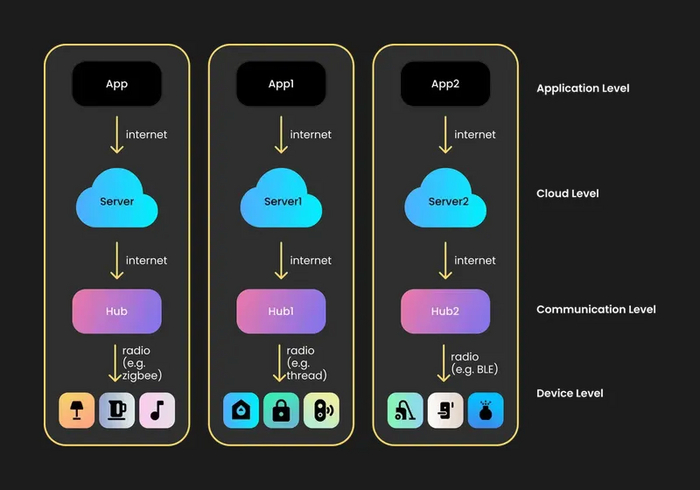
Но, что хуже, далеко не все приложения умеют общаться с хабом напрямую в пределах локальной сети (LAN) и используют сервер даже когда вы находитесь дома. Это тот случай, когда отключение интернета означает полный блэкаут, а наличие интернета - возможность удаленного управления домом из облака (доверяете ли вы облаку компании, зарабатывающей на продаже ваших персональных данных, но не заботящейся об их сохранности?).
Закрытые экосистемы умного дома с хабом и облаком
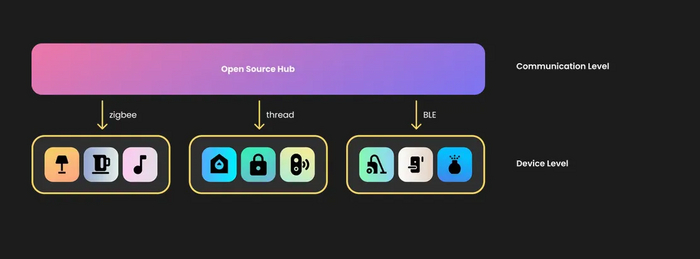
Чтобы это исправить, заменим проприетарный хаб на raspberry pi с какой-нибудь open source системой домашней автоматизации, а также добавим плагины для интеграции устройств. Это позволяет объединить все устройства в одну систему, например, чтобы программировать общие автоматизации или продвинутые сценарии. Уже лучше, но пропала одна мелочь под названием интерфейс.
Универсальный open source хаб умного дома
К счастью, некоторые open source решения идут комплектом с вебным фронтендом или даже мобильным приложением (но не всегда с user-friendly интерфейсом). Добавив еще пару плагинов, мы можем пробросить часть устройств (или все, если очень повезет) в приложение какой-то из экосистем. В таком случае хаб выступает посредником или адаптером для устройств сторонних производителей. Но теперь мы зависимы от этой экосистемы и получаем те проблемы, о которых шла речь в начале статьи. В качестве альтернативы, мы можем подключить другой плагин с кастомным облаком, но это уже становится или слишком сложно, или все еще недостаточно безопасно.
Универсальный open source хаб умного дома c инфраструктурой экосистем
Хочу заметить, что не всегда проприетарный хаб можно полностью заменить на кастомный. Часто вам понадобится иметь оба хаба (проприетарный и кастомный), чтобы система поддерживала оригинальные приложения и устройства. В итоге это может превратиться в запутанный клубок технологий.
Универсальный open source хаб умного дома c инфраструктурой экосистем (сложности)
Кстати, этот пример мне кое-что напоминает:
Нестабильная цифровая инфраструктура
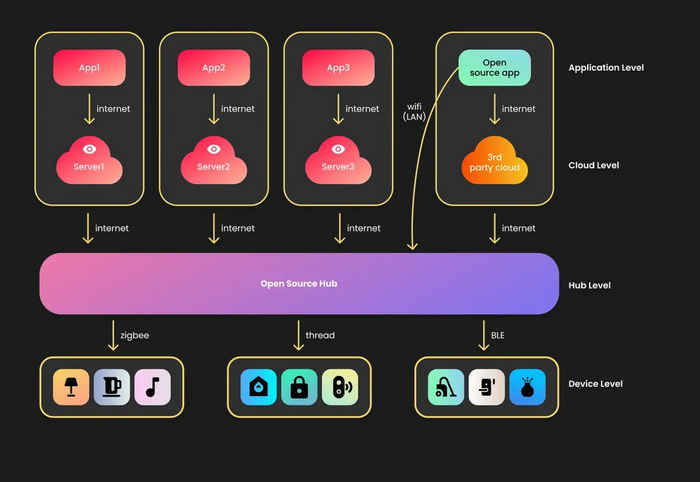
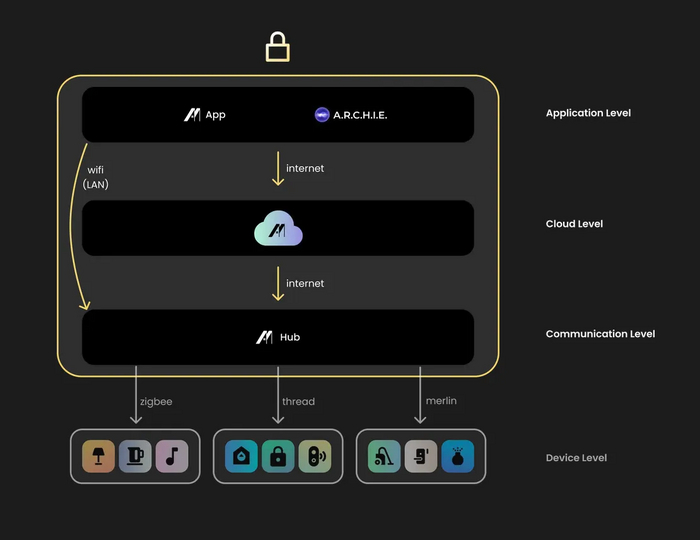
Итак, у нас есть 4 уровня: устройства, хаб (автоматизации, программное управление), сервера, интерфейс (приложения, голосовые ассистенты, итд). Экосистема — это все 4 уровня и их связь, а не какой-то один. Чтобы все работало идеально, мы делаем не просто один из уровней, например, систему автоматизации на уровне хаба. Мы делаем все три верхних уровня: приложение, голосовой ассистент, облако и хаб с максимальной поддержкой устройств других производителей, таким образом получая максимальную совместимость и интеграцию всей системы из коробки: автономную, приватную, независимую и безопасную. Это - МажорДом.
Архитектура экосистемы умного дома MajorDom
Чем наша система будет умнее: наша философия
В фундаменте своей работы мы закладываем следующие принципы:
Полная приватность личных данных — дом не место для чужих глаз. Конфиденциальность — базовое право каждого пользователя.
Автономность — максимальная независимость от внешнего мира, отключенный интернет не должен стать проблемой
Легкость настройки и использования — технологии должны служить человеку, а не наоборот
Максимальная поддержка разных устройств, протоколов и интеграций - в дополнение к предыдущему пункту
Никаких искусственных ограничений — не быть эпл и дать возможность глубокой настройки и кастомизации тем, кому это нужно
Итак, мы собираемся заново изобрести умный дом. По нашему мнению, настоящий умный дом состоит из невидимой армии устройств, которые работают автономно в фоновом режиме, улучшая вашу повседневную жизнь и прикрывая вашу спину. По сути это цифровой дворецкий.
Настоящий умный дом должен быть независимым от внешнего мира. Никаких сбоев из-за отказа интернета или случайного сервера. Это полностью автономная экосистема, которой больше ничего не требуется: ни интернета, ни облачных сервисов, ни даже человека.
В то же время система должна быть простой в использовании. Никаких долгих установок и настроек. Отсутствие периодического изменения настроек. Никакого написания кода. Просто достать из коробки и включить. Технологии должны работать на вас, помните?
Описание MajorDom
Но как нам это сделать? Прежде всего, системе нужно имя. Мы выбрали для неё название MajorDom, которое отлично отражает её сущность. (от англ. majordomo — мажордом, дворецкий, управляющий домом)
Приватность
Пока остальные системы представляют собой черные ящики, мы считаем, что MajorDom должен иметь открытый исходный код, чтобы не было никаких скрытых манипуляций, любой человек мог открыть его, прочитать, выделить проблемы, предложить изменения или даже внести свой вклад.
Хотя исходный код общедоступен, данные пользователя защищены как никогда раньше. Чтобы сделать систему приватной и автономной, большая часть данных хранится локально на устройствах, в основном хабе. Это гарантирует конфиденциальность, а поскольку все данные хранятся локально, автоматизация и все остальные функции прекрасно работают даже при отсутствии интернета в отличие от систем, которые всегда полагаются на подключение к серверу, поскольку все данные хранятся где-то в интернете.
Но в некоторых случаях данные необходимо передавать через интернет, например, с помощью удаленного управления, когда вы не дома. В этом случае данные надежно шифруются (end-to-end), а ключи хранятся только на физических устройствах пользователя. Это означает, что вы всегда можете получить удаленный доступ к своему дому, но только вы и никто другой, включая админов и разработчиков.
Поддерживаемые устройства
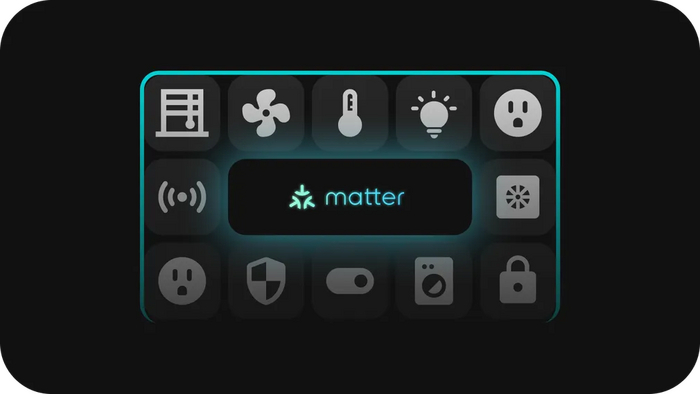
Конечно, прежде чем настраивать автоматизации, в доме нужны устройства. Zigbee Alliance, переименованный в Connectivity Standards Alliance или CSA, — это объединение различных компаний, занимающихся умным домом, которые решили создать универсальный протокол связи для всех устройств домашней автоматизации. Они назвали этот протокол Matter. И MajorDom с ним совместим. Это означает, что вы можете добавить любое совместимое с Matter устройство в свою систему MajorDom. И это еще не все.
matter протокол
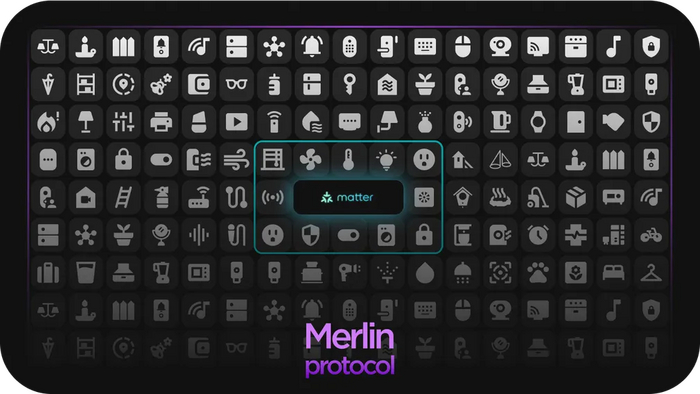
Matter изначально поддерживает только самые распространенные базовые устройства, поэтому мы создали протокол связи Merlin. Благодаря более гибкой архитектуре он не только существенно расширяет список поддерживаемых устройств, но и делает его бесконечным.
Мерлин протокол
В то же время мы понимаем, что сегодня только малая часть уже выпущенных устройств поддерживает один из этих протоколов, поэтому мы также собираемся добавить интеграции устройств, использующих zigbee, z-wave, wifi и BLE, таким образом став самой универсальной экосистемой.
Умная комната с устройствами на разных протоколах в системе MajorDom
Интерфейс
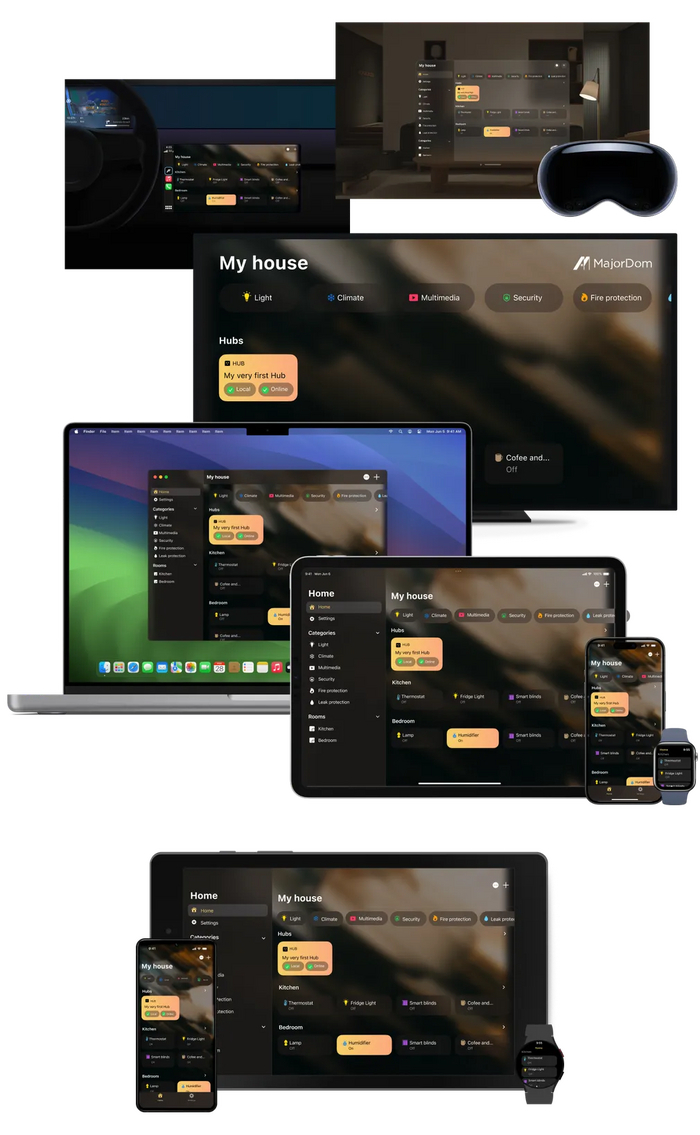
Мобильное приложение MajorDom на фоне хаба
Мы наконец-то собрали в одном месте все устройства, но как с ними общаться? Для этого мы разработали красивое мобильное приложение, доступное практически на всех платформах, включая устройства Android — телефоны, планшеты и часы, а также устройства Apple — iPhone, iPad, Mac, Apple Watch, Apple TV, CarPlay и даже новый шлем Vision Pro. Приложения так же включают виджеты, которые можно разместить на домашнем экране, экране блокировки или в любом другом месте, поддерживаемом операционной системой, что позволит управлять домом даже не запуская приложение.
По-настоящему умный дом большую часть времени должен работать автономно, в фоновом режиме, чтобы вы этого даже не замечали. Но как мы собираемся это автоматизировать, если никто не хочет писать скрипты?
Вместо этого:
Скрипты для автоматизаций умного дома
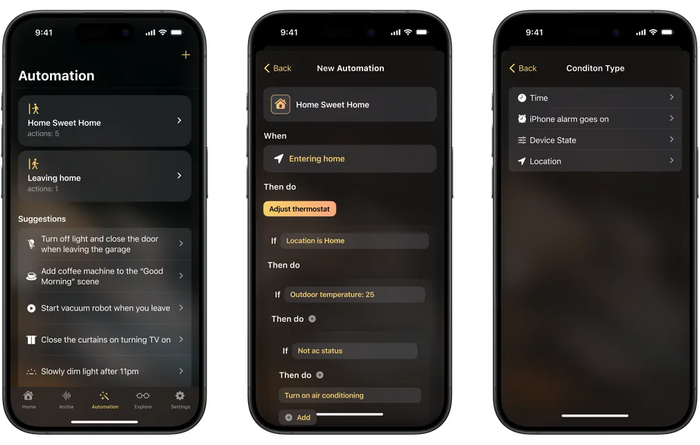
Для автоматизации мы добавили в приложение вторую вкладку, которая поможет легко настроить любой сценарий. Но это было слишком просто и мы пошли дальше.
Приложение MajorDom: вкладка автоматизаций
Чтобы еще больше упростить этот процесс, мы изобрели технологию умных предложений, которая предсказывает, что вы хотите автоматизировать. Иногда она настолько умна, что даже не требует помощи пользователя. Например, вы можете просто добавить все устройства и начать использовать их, не добавляя никакой автоматизации или сценария. Через некоторое время эта технология предложит сцены и автоматизацию на основе ваших привычек. Вы даже можете разрешить ей добавлять сцены и автоматизации без подтверждения, полностью в фоновом режиме. Настоящие умные автоматизации.
Арчи — умный голосовой ассистент
Автоматизация — это хорошо для ежедневной рутины, но иногда требуется более индивидуальный подход. Арчи в этом профессионал. В отличие от других "ассистентов", он понимает вас с высокой точностью, знает контекст, улавливает по несколько сложных запросов за сообщение и общается так, будто вы разговариваете с настоящим помощником, а не просто диктуете голосовые команды!
Умная колонка MajoDom Audio с голосовым ассистентом Арчи.
Перевод: — Арчи, проверь мое расписание — У вас встреча с командой разработки в 3 часа и планы на ужин в 7. Также, не забудьте, что сегодня день рождения у вашей мамы. У вас есть достаточно времени на звонок между 4 и 6 часами вечера
Арчи предназначен не только для контроля дома, но и для каждого аспекта повседневной жизни, от управления заметками до предоставления общей информации и голосовых уведомлений.
Как настоящий профессиональный мажордом, Арчи говорит на многих языках. Он может одновременно слушать до трех заранее выбранных языков и отвечать на соответствующем.
Арчи унаследовал все основные ценности MajorDom: конфиденциальность, автономность, простота в использовании и настоящая умность. Он может работать офлайн, но интернет расширяет его возможности до неограниченного диапазона, а благодаря использованию крупных языковых моделей, навыки этого ассистента ближе к настоящему искусственному интеллекту, чем когда-либо прежде в истории человечества.
Демонстрация голосового ассистента Арчи в мобильном приложении MajorDom на фоне умной колонки MajorDom Audio и хаба MajorDom Hub.
Работа из коробки: делаем свои устройства
"Люди, серьезные на счет софта, должны делать своё железо" — эта цитата особенно актуальна для умного дома. Это единственный способ обеспечить беспроблемную интеграцию множества протоколов из коробки. То же самое касается ассистента: не каждая платформа потянет офлайн распознавание, обработку и синтез речи. К тому же, полностью доверять ему можно только тогда, когда знаешь, что на устройстве нет постороннего ПО с доступом к микрофону. Вот почему мы разрабатываем два собственных устройства: хаб MajorDom Hub для управления устройствами, автоматизацией и порталом в экосистему — это как руки дома. И колонка MajorDom Audio для голосового ассистента — уши и голос дома.
Умная колонка MajorDom Audio и хаб MajorDom Hub
И еще кое-что… для активных пользователей
Мы хотим максимально упростить интеграцию идей пользователей — будь то аппаратное или программное обеспечение. С этой целью мы спроектировали два основных инструмента, позволяющих каждому внести свой вклад.
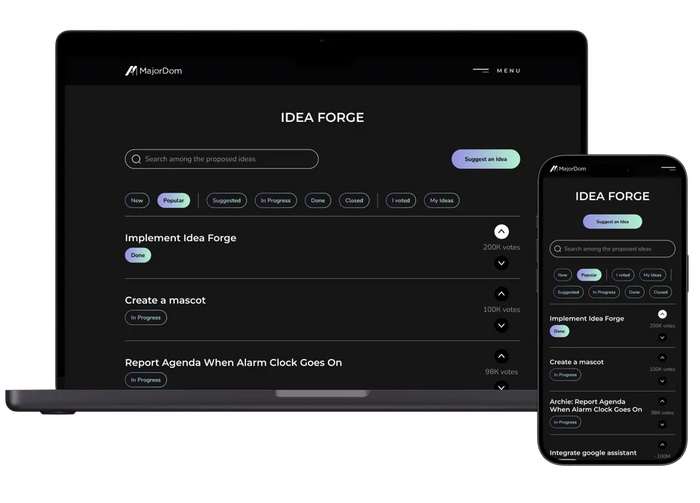
«Idea Forge» (Кузница идей)
Во-первых, при разработке MajorDom мы создали «Idea Forge» (Кузницу идей). Эта платформа превращает предложения пользователей в реальные фичи. Любой желающий может предоставить идеи через форму на сайте. Необязательно быть программистом; достаточно одной светлой мысли. Эти предложения затем появляются на доске голосования сообщества, что позволяет каждому влиять на процесс разработки. Демократия в действии. Самые популярные идеи рассматриваются к реализации командой MajorDom. Речь идет не только о пользователях; речь идет о превращении пользователей в создателей.
Но это не просто игра в ожидание. Если вы любите приключения или просто не можете дождаться, вы можете засучить рукава и написать любую фичу самостоятельно.
Во-вторых, мы максимально упрощаем работу для всех разработчиков. Разрабатываем модульную прошивку хаба с поддержкой плагинов и удобные библиотеки с подробной документацией.
Заключение
На данный момент проект находится в стадии активной разработки, но большая часть упомянутого уже реализована, включая ядро системы, интеграции некоторых протоколов, удаленное управление, автоматизации, офлайн часть Арчи и мобильное приложение. Дальнейшие новости будем публиковать здесь, но так же рекомендую подписаться на соответствующие страницы проекта в социальных сетях. Записаться на ранний доступ можно на сайте majordom.io в один клик.
Присоединиться к проекту
Проект является довольно сложным и масштабным, а качественный результат требует много часов работы профессиональных инженеров, программистов и дизайнеров. В современном капиталистическом мире только коммерческая разработка может гарантировать стабильный результат.
Предзаказы, Кикстартер, Донаты
В будущем проект будет опубликован на кикстартер — платформу краудфандинга, на которой можно будет оформить самые ранние предзаказы устройств, но поддержать проект финансово можно уже сейчас на patreon или buymeacoffee.
Стать частью команды
В нашей команде уже есть дизайнеры, инженеры софта для фронта, бэка, мобильных приложений, хаба и голосового ассистента. В то же время мы ищем промышленных дизайнеров, embedded инженеров для железа, а так же программистов, разбирающихся в низкоуровневых деталях популярных протоколов в сфере умного дома. Если вы занимаетесь чем-то другим, но хотите присоединиться к проекту, пишите свои предложения, будем рады всем.
Инвесторам
Мы также рассматриваем получение инвестиций от $50k pre-seed раунда за долю компании. Говоря о цифрах, текущий рынок умного дома оценивается в 100 миллиардов долларов США, с прогнозируемым ростом до 600 миллиардов в 2033 году. Похоже на отличную возможность вложения.
Австралийский стартап Cortical Labs разрабатывает нечто удивительное: компьютерный чип, созданный с использованием живых клеток человеческого мозга. Этот проект, получивший название Dishbrain, представляет собой настоящую инновацию.
На кремниевой основе чипа растут живые нейроны человеческой коры головного мозга, выполняя функции проводников и связываясь между собой и с другими элементами системы. Это можно сравнить с миниатюрной версией мозга, которому уже удалось научиться играть в классическую видеоигру Pong. Хотя в игре он показал себя не идеально, скорость и эффективность его обучения превзошли традиционные цифровые методы ИИ. Такие гибридные чипы могут кардинально изменить не только развитие искусственного интеллекта, но и медицину, предоставляя новые возможности для тестирования лекарств и изучения заболеваний.
Cortical Labs утверждают, что их чипы способны расти, учиться и адаптироваться, подобно человеческому мозгу. Возможности, которые откроются перед нами благодаря этому изобретению, могут быть поистине революционными.
Если вам интересны новые технологии, полезные сервисы и новости будущего, добро пожаловать в ИИшница 🍳
Студенты программисты из Новосибирского государственного технического университета работают над нейросетью, которая уже определяет 8 видов отходов: пластик, стекло, бумага, бытовые отходы и др. В будущем список классов отходов планируют расширить до 30.
На первом этапе разработки такой функции в базу данных загружались изображения различных отходов, которые анализировались и сохранялись в памяти ИИ. Поначалу нейросеть путалась в большом количестве пластиковых и стеклянных форм бутылок, но на данный момент вероятность распознавания класса отходов составляет практически 100%.
Еще одной полезной опцией для пользователей является то, что нейросеть за вас будет отправлять вторсырье переработчику. В программу вы загружаете фото отходов, ИИ определит тип и объем вторсырья, заполнит за вас заявку на вывоз. Также нейросеть подберет компанию, которая принимает такие отходы, а курьер на машине доставит вторсырье на предприятие
Компания Brisk It представила новинку — умный гриль с искусственным интеллектом, который обещает довести приготовление еды до совершенства.
1/2
ИИ автоматически настраивает температуру для каждого ингредиента, позволяя готовить несколько блюд одновременно без риска их испортить.
Управление грилем осуществляется через специальное мобильное приложение, которое не только включает и выключает огонь, но и уведомляет вас о готовности блюда.
Цена умного гриля составляет 132 000 рублей, и это отличный выбор для празднования майских праздников.
Если вам интересны новые технологии, полезные сервисы и новости будущего, добро пожаловать в ИИшница 🍳 - пища для ума в мире высоких технологий
В технологическом институте Невинномысска, который является филиалом Северо-Кавказского федерального университета, разработан инновационный робот-поводырь для помощи людям с ограниченными возможностями. Этот робот оснащен машинным зрением и может анализировать входящие данные, используя алгоритмы искусственного интеллекта, чтобы предоставлять соответствующие уведомления своему владельцу.
Робот разработан как шестиколесная подвижная платформа высотой около метра с встроенным мини-компьютером. На верхней части установлены камеры для сканирования окружающей среды, а также динамик, который озвучивает уведомления для пользователя. Предусмотрено, что пользователь может «вести» робота, используя специально разработанный поводок.
Используя принципы машинного зрения и искусственного интеллекта, робот-поводырь способен выбирать оптимальный маршрут движения, учитывая возникающие на пути препятствия. Кроме того, устройство может распознавать различные объекты, информационные знаки и тексты, например, озвучивать текст на этикетках товаров.
Первый прототип этого робота уже создан в НТИ СКФУ, и его стоимость составила менее 70 000 рублей. Однако команда разработчиков планирует значительно расширить функциональные возможности аппарата, для чего им требуются инвестиции порядка одного миллиона рублей. В качестве потенциальных покупателей рассматриваются государственные учреждения, социальные службы и различные некоммерческие организации.
Простите поклонники лучика, но не мог пройти мимо. Я не буду разбирать каждый абзац этой статьи и комментировать его, только в конце приведу цитаты и свои комментарии к ним. На мой взгляд статья очень размыто отвечает на главный вопрос, поставленный в заголовке: как работает нейросеть? Я не в курсе на какую возрастную аудиторию рассчитан материал, но с учетом того, что в статье приведена функция y = kx + b, полагаю, я могу использовать немного математики.
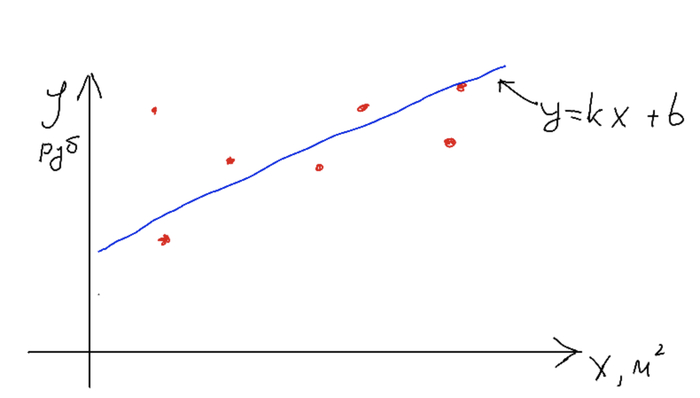
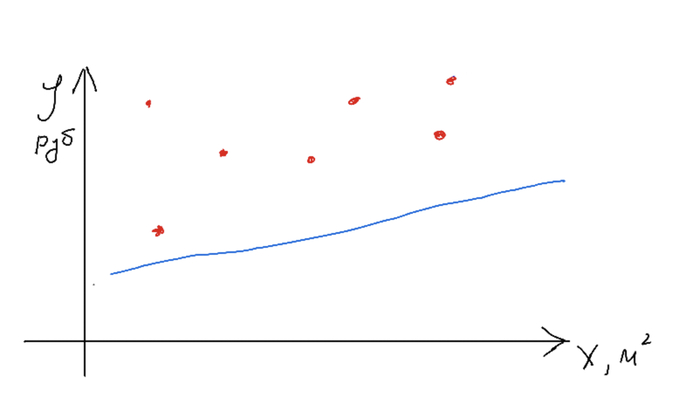
Авторы предлагают аналогию вроде такой: нейросеть - это набор нейронов-чисел, а учатся они, если им показать много примеров. Прежде чем переходить к нейронам, я расскажу как они учатся. Это может показаться странным, но просто принцип обучения что в нейросетях, что в простых моделях машинного обучения одинаков. Для примера рассмотрим как раз уже приведенную функцию y = kx + b. Перенося ее на реальный мир можно взять в качестве примера задачу расчета стоимости жилья в зависимости от площади квартиры. Тогда y - стоимость, x - площадь квартиры, а решаем мы задачу т.н. линейной регрессии (это для сильных духом, постараюсь обходиться без терминов). Далее слайды, которые рисовал сам, простите.
Нужно получить модель, которая по набору иксов (метраж квартиры) дает правдоподобную стоимость. Точки на графике - наши реально существующие данные. Прямая - наша функция. Обучив модель, мы можем подать ей на вход один x и получить ожидаемый y.
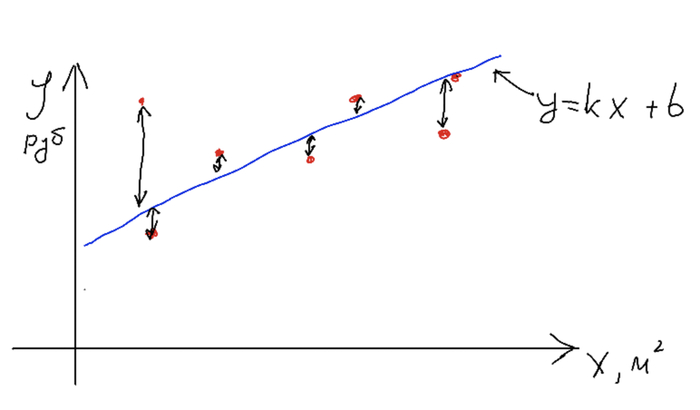
В случае применения машинного обучения мы должны просто настроить неизвестные параметры нашей функции (k и b), чтобы получить оптимальную прямую. Главный вопрос - как? Для этого мы должны ввести понятие ошибки модели, чтобы понять, хороши ли она выполняет свою задачу. В нашем примере ошибка - это разность между предсказаниями и реальной стоимостью.
Ошибка модели - средняя разность между реальными значениями и предсказанными по модулю или в квадрате. Формальным языком: L = (y' - y)^2 / n, где n - количество примеров в данных, y' - предсказания, а y - реальные значения y для наших x).
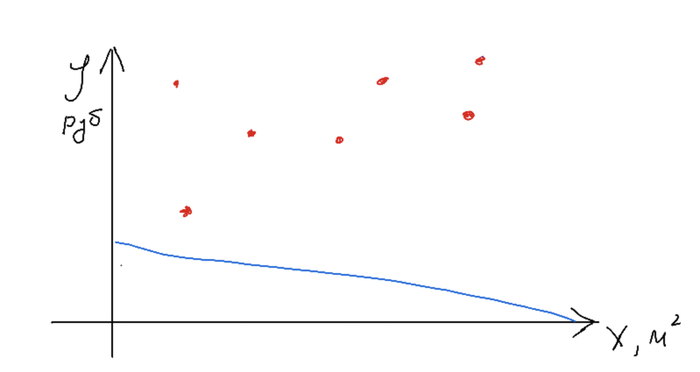
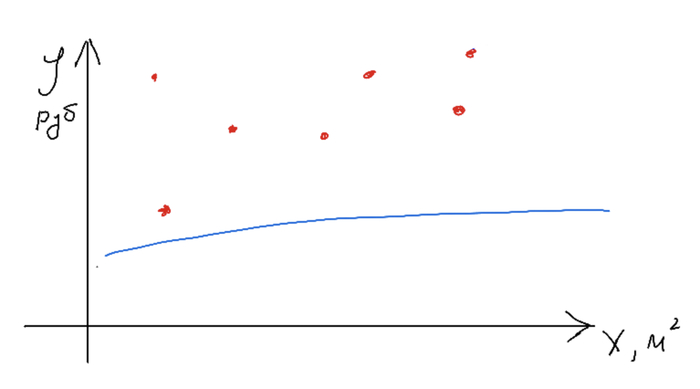
Назовем функцию вычисления ошибок функцией потерь (точнее, она так и называется). Оптимальная модель будет выдавать минимальную среднюю разность, т.е. значение функции потерь будет минимальным. С оценкой определились, теперь переходим к процессу обучения. Для этого мы строим одну случайную прямую, считаем разность между предсказаниями и данными, определяем в какую сторону нам нужно сдвинуть нашу прямую, и сдвигаем, меняя наши k и b на небольшое значение. На какое - задается параметрами модели, обычно этот шаг небольшой, чтобы не перескочить наше оптимальное положение.
Случайная прямая
Один шаг обучения
Второй шаг обучения ( и так далее)
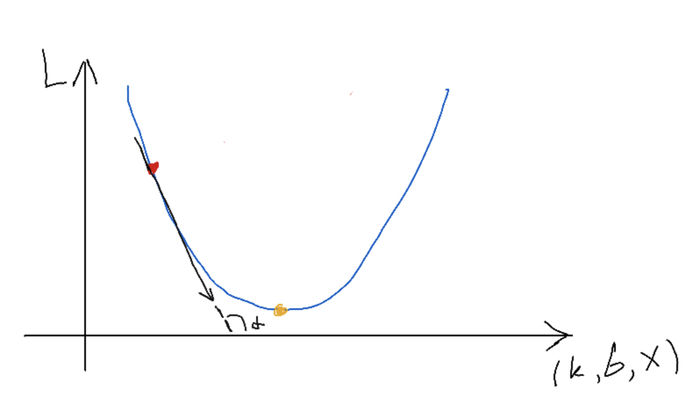
Небольшое отступление, которое можно пропустить. Пытливый ум спросит меня, а как мы определяем в какую сторону двигаться на каждом шаге? Отвечаю - просто смотрим на знак. Раньше я упомянул, что для расчета мы используем квадрат или модуль разностей для каждого отдельно взятого примера и усредняем их. Но тогда все наши расчеты будут положительными. Трюк в том, что при обучении мы используем не саму функцию потерь, а производную от нее или т.н. градиент (блин, обещал же без терминов). Геометрически производную можно изобразить так:
Производная - это тангенс угла наклона касательной к функции потерь в выбранной точке. Производная показывает направление роста функции.
На графике изображена функция потерь при разных значениях для нашей задачи - это парабола. Причем левая ветвь соответствует ситуации, когда мы задаем случайную прямую ниже наших точек, правая - выше. Наша задача попасть из красной точки в желтую, т.е. в минимум функции. Определив градиент, мы двигаемся в сторону уменьшения функции, достигая минимума. Математически, при расчете производной (dL = (2 / n) * (y' - y) * x) мы избавляемся от квадрата и можем получать отрицательные значения (и получаем в нашем примере) и тогда двигаемся в противоположную от знака сторону, прибавляя небольшие значения к нашим коэффициентам k и b.
Возвращаясь к объяснению на пальцах. В реальной жизни параметров, влияющих на стоимость квартиры больше, чем просто ее метраж. Тогда мы переходим в многомерное пространство. В реальной жизни у нас есть другие задачи, например то же отделение фотографий кошек от фотографий собак (задача классификации). Или генерация изображений. Но во всех этих задачах используется один и тот же принцип: мы должны определить функцию потерь - определить как мы вычисляем ошибки предсказаний модели и посчитать разницу между предсказаниями и реальными значениями и изменить значения коэффициентов, в зависимости от смещения предсказаний. Для задачи классификации животных (кошек и собак) мы на самом деле строим точно такую же прямую, просто эта прямая не проходит через точки в пространстве, а старается разделить их. Точками в этом случае могут выступать значения пикселей наших картинок, в таком случае, для обычного изображения кошечки, например, разрешением 512х512, мы работаем в 786432-мерном пространстве (потому что 3 (если используем цветное изображение RGB) * 512 * 512 = 786432) и подбираем в этом пространстве не прямую, а плоскость. И уравнение этой плоскости будет таким y = b + k1 * x1 + k2 * x2 + ... + k786432 * x786432. А функция потерь будет другая, но об этом я уже не буду говорить.
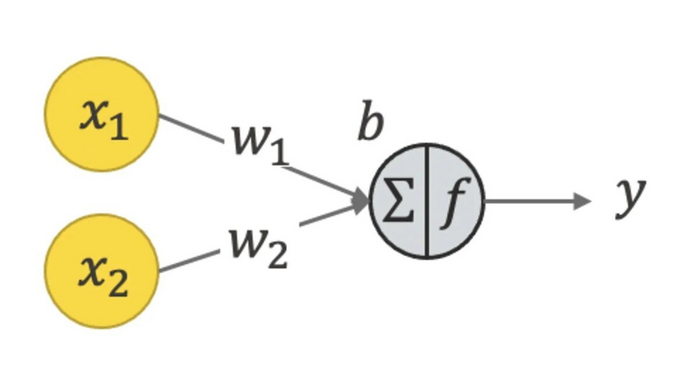
Теперь, когда мы поняли как мы учим, можно понять, что такое нейрон в нейросетях. На самом деле, ответ уже понятен. В процессе обучения мы настраиваем коэффициенты некой функции, нейрон тогда - это просто математическая функция от входных данных. Возвращаясь к статье лучика, на этой картинке нейрон - это как раз таки серый кружочек. А желтые - это значения входных данных. Они могут быть в то же время выходными данными с нейронов предыдущего слоя нейросети.
x1, x2 - значения входных данных, w1, w2, b - коэффициенты (я использовал выше k и b)
А сколько нейронов в нейросети? Много и зависит от архитектуры. Входной слой просто принимает данные и вычисляет взвешенную сумму, передавая результат на внутренние слои. На примере тех же изображений - количество нейронов на первом слое будет зависеть от параметров изображения, а именно от количества пикселей, но количество нейронов скрытых (внутренних) слоев мы устанавливаем сами. Мы можем поставить один нейрон на первый скрытый слой, который будет суммировать все данные, но толку от такой сети будет мало. На выходном слое количество нейронов зависит от нашей задачи. Для генерации нам нужно в каждом пикселе сетки предсказать реальное значение цвета, значит нейронов будет столько же, сколько пикселей нам надо получить. Если мы говорим о задаче классификации, то на выходном слое будет столько нейронов, сколько у нас классов - т.е. 2 для кошек/собак, например. Рассматривать необычные слои, вроде сверток, не будем, но они есть.
А зачем вообще нужны нейросети? Я уже выше описал, что все задачи так или иначе формализуются в набор известных функций. Но преимущество нейросетей в том, что они универсальны как раз за счет общих принципов построения. А взаимодействие нейронов на разных слоях позволяет расширить пространство настраиваемых параметров, что в свою очередь позволяет уловить связи в данных на разных уровнях. Например, разные слои нейросети, обученной на задаче классификации изображений, могут улавливать разные паттерны: например контуры, формы или цвета. Что как раз-таки используется для передачи стиля - мы замораживаем глубинные веса обученной нейросети (те, которые отвечают за пространство, форму и т.д.) и дообучаем на одном стилевом изображении только те слои, которые отвечают за "мазки кисти" и цвета.
Несколько примеров современных нейросетей и как они обучены:
Генерация изображений. Существует множество архитектур сетей для генерации. Причем я говорю о генерации без текстового описания. Например, т.н. GAN-ы. Они обучены генерировать изображения из шума, как и сказано в статье. Но они не обучаются специально запоминать формы, объемы, углы, цвета. Они обучаются генерировать изображение так, чтобы результат не отличался от данных, с которыми мы его сравниваем.
Векторизация текстов - я выделил этот пункт отдельно, т.к. все сети, работающие с текстами, должны уметь переходить от тестов к точкам в пространстве - векторам чисел. Описывать, как это происходит примерно так же долго, как я описывал линейную регрессию. Но для простоты скажем, что нейросети учатся предсказывать пропущенные в тексте слова, настраивая при этом числа в пространстве векторов, где каждый вектор соответствует отдельному слову. Это классическая задача классификации, а значит мы снова строим разделяющие плоскости.
Генерация текстов. И снова множество архитектур. Есть даже не нейросетевые (смотрите цепи Маркова, которые просто считают попарные вероятности слов в тексте). Нейросетевые пытаются предсказать одно следующее слово на основе предыдущих.
Генерация изображений по тексту. Здесь мы объединяем известные подходы и идея такая: раз мы уже знаем, как векторизовать текст, то будем использовать вектора текста как входные данные, а готовые изображения, как идеал, который нужно научится генерировать из шума. Для обучения таких моделей используется огромное количество картинок с описаниями к ним. Кстати, поэтому было много претензий к русскоязычным генеративным моделям, которые генерировали, например, американские флаги по запросу "Родина". Просто сложно создать большой датасет размеченных изображений своими силами, все используют открытые датасеты, и, например, переводят тексты и всячески обогащают данные.
Теперь можно перейти к самому интересному - цитаты из статьи.
Компьютерный нейрон – это просто... число!
Уже выяснили, что нет.
«А если собаки и кошки раскиданы вперемешку, а?» – спросите вы. Ну что ж, тогда нам может потребоваться не одна линия. И возможно не две и не три, а целый десяток или даже сотня. Важно понять, что рано или поздно мы сможем с помощью обыкновенных чисел и прямых «поделить» наш лист так, чтобы нейросеть уже знала наверняка – что именно она «видит», кошку или собаку, в чью именно область она «ткнула пальцем».
Я зацепился за это определение. Потому что если нам известно только 2 класса, то будет только одна "линия" на выходе. Да, каждый нейрон строит свое собственное решение, но он во-первых, не видит какую-то свою область данных, а во-вторых, его решение агрегируется с решениями всех остальных нейронов на выходном слое. То, что описано - это скорее работа классических деревьев решений, которые действительно нарезают пространство на сколько угодно областей.
Проблема номер один – для обучения нейросети нужно очень много информации. Чтобы научить нейросеть отличать кошку от собаки, ей нужно показать тысячи (лучше миллионы) самых разных кошек и собак. Воспитанник детского садика в возрасте трёх лет кошку с собакой не спутает, даже если видел их всего лишь пару раз в жизни...
С миллионом явный перебор. Кроме того, существуют техники дообучения, позволяющие переиспользовать обученные модели с гораздо меньшим набором данных.
Проблема номер два: нейросети совершенно не умеют анализировать собственные творения, объяснять, «что здесь нарисовано и почему», в частности, они не умеют считать! Из-за этого компьютерные изображения постоянно рисуют людей то с шестью, то с восемью пальцами. Или кошек то с тремя, то с пятью лапами.
Вообще-то, объяснять уже умеют. Но только узкий класс мультимодальных сетей (если мы обучим модель генерировать текст по изображению - обратная задача генерации изображения по тексту - то сможет). А с пальцами проблема в общем тоже пофикшена улучшениями архитектур и увеличением количества параметров моделей. Были бы деньги обучать такие модели.
Проблема номер четыре: нейросеть не умеет работать при нехватке информации, «достраивать недостающее». Скажем, человеческий детёныш, даже малыш, увидев кошачий хвост, торчащий из-под дивана, тут же уверенно «распознает» спрятавшегося котёнка и побежит ловить его! Нейросеть такое «неполное» изображение понять не в состоянии. Человек, исказивший внешность (скажем, надевший маску или загримированный) для современной нейросети опять же становится неузнаваемым.
Умеет и достраивает. И распознает и людей в масках узнает. Опять же, на это влияют как архитектура, так и способ получения данных. Всегда можно аугментировать изображения (например в части тренировочных изображений кошек и собак обрезать все, кроме хвостов и тогда такая нейросеть сможет по хвосту определить животное).
Проблема номер пять: нейросеть совершенно не понимает законов нашего мира – скажем, тех же законов оптики. Она никогда не сможет различить на картине человека – и его отражение в зеркале (для живого человека – задачка пустяковая). Она никогда не сможет различить человека или его лицо в кривом зеркале (как это делаем мы на аттракционе «Комната смеха» в городском парке, или когда разглядываем самих себя в новогодние шарики).
Аналогично - аугментация данных решает проблемы с кривыми зеркалами.
Проблема номер шесть: нейросети чрезвычайно чувствительны к разного рода помехам, дефектам, «шуму». Скажем, если на старой фотографии часть изображения залита грязью, чернилами, испорчена пятнами или царапинами, сильно выцвела, если карточка разорвана или разрезана напополам – уверенное узнавание тут же становится неуверенным и вообще ошибочным. Для человека сломанная на части кукла – всё равно кукла; для нейросети – это уже совершенно другой, неизвестный объект
Формально - да. Именно поэтому при обучении специально добавляют шум, аугментируют данные, выключают часть нейронов. И тогда модель справляется.
Проблема номер семь: нейросети на текущий момент ужасающе «однопрограммны». Если нейросеть настроена на распознавание лиц – она будет уметь только распознавать лица. Переучить её на написание текстов или музыки будет чрезвычайно сложно, часто вообще проще написать и обучить совершенно новую сеть. Если она умеет отличать квадраты от треугольников – даже не пробуйте попросить её отличить кошку от собаки или самолёт от парусной лодки...
В целом верно, но не совсем. В рамках одной моды и архитектуры - работа с текстом, или изображениями, или музыкой - переучить нейросеть не проблема. И даже мультимодальные модели существуют и активно развиваются. Но да, архитектура генератора музыки и генератора изображений и данные для этих сетей настолько разные, что просто в тупую подменить данные нельзя. Удивительно.
Проблема номер восемь: связи между компьютерными нейронами случайны, поэтому нейросети лишены запоминания созданных образов. На приказ «нарисуй мне дерево» нейросеть охотно откликнется и будет рисовать деревья снова и снова, но... каждый раз это будет «другое дерево». И если вы напишете команду «нарисуй мне такое же дерево, как в прошлый раз, только на берегу реки», нейронная сеть не поймёт вас. Она опять нарисует «новое случайное дерево».
Связывать случайность (кстати, они не случайны, а заданы архитектурой) связей между нейронами и неспособность запоминать созданный образ - максимально некорректно. То, что здесь описано, на самом деле решаемо. Но это решение за пределами архитектуры нейросети. Это как предъявлять претензии микроволновке, за то, что она не включила сама кнопку, типа, могла бы и запомнить. У нее нет инструментов запоминания результата, как нет у голой нейросети - она получает данные на вход, генерирует выход и все.
В целом, я догадываюсь, что изначальная статья была рассчитана на детей младшего школьного возраста. И я по размышлению выкинул из моего разбора несколько цитат, которые на самом деле оказались верны, просто сильно упрощают представление. И то, что я описал может быть не всем понятно и требует более глубокого погружения.