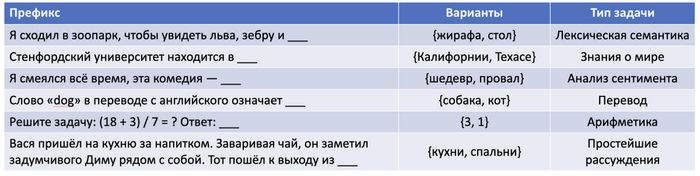
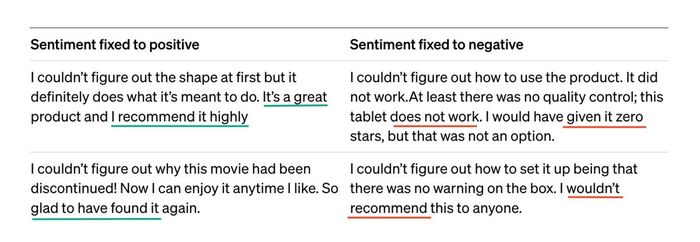
Мы начали разработку еще в 21 году, тогда мы хотели создать игру, в которой будет кооператив - так как мы очень любим такие игры ( ну а кто не любит ).
Сел в машину)
Но разработка так и не началась, мы начали разрабатывать другие проекты, но в свет вышел только ужасный the room 23, но это был только первый опыт. Игру пытались сделать похожей на muck, но получилось конечно не очень, в мак играть приятней:)
Нападение зомби
Думаю это не последний проект нашей команды, и мы уже скоро начнем делать новую игрушку, а пока можете почитать об этой и посмотреть прикольные гифки
Игра демки не имеет, зато на главной странице очень много интересных гифок! Вышла она относительно недавно, и сама игра уже почти готова Пока записывал эти гифки, наиграл 3 часа, с другом время прошло быстро)
( если понравилось, можете добавить игру в избранное:)
Об Игре.
Игра, где вы сможете выживать, сражаться с зомби и бандитами, а также все это делать вместе с другом!Всего в игре присутствует 3 режима, 1) выживач. 2) 1 vs 1 с другом ( играть можно в 3-ем ). 3) копия игры - ready or not (но называется ready or no ).
Она атмосферная
В игре есть квесты, их правда не много, зато сам мир я считаю наполненным, и в 3 режимах играется шикарно.
Перестрелка
На обложку потратил мы потратили 3 тысячи , но я ожидал за такие деньги другого результата, потому что я бы с опытом работы в год сделал лучше. Но трейлер получился неплохой)
В этом году ESA планирует запустить аппарат Hera, основной целью которого является астероид Диморф. В 2022 году он стал объектом эксперимента NASA по планетарной защите, в ходе которого в него врезался зонд DART. Однако результаты нового исследования говорят о том, что Hera может вообще не найти никакого кратера от этого столкновения.
Столкновение DART с Диморфом состоялось 26 сентября 2022 года. Его последствия намного превзошли ожидания специалистов. По самым скромным оценкам, удар выбил не меньше тысячи тонн вещества с поверхности астероида. У него также появился длинный пылевой хвост (который позже раздвоился) протяженностью в 10 тысяч км.
Кроме того, удар серьезно изменил орбитальные параметры Диморфа. Он является спутником более крупного астероида Дидим. До удара орбитальный период Диморфа составлял 11 часов 55 минут. После удара он сократился до 11 часов 22 минут.
В конце 2026 года к Диморфу прибудет аппарат Hera. Одна из его первоочередных задач является изучение образовавшегося в результате удара кратера. Однако результаты нового исследования, выполненного учеными из Бернского университета, говорят о том что Hera может вообще не найти никакой воронки. Вместо этого, удар DART, скорее всего, полностью изменил форму астероида.
Исследователи пришли к такому выводу в ходе серии из 250 симуляций, воспроизводящих первые два часа после столкновения. На подготовку каждой из них у них уходило около полутора недель. Ученые постарались учесть все известные величины, начиная от характеристик самого астероида и заканчивая массой DART.
Симуляции показали, что наиболее вероятным является сценарий, в котором после удара на поверхности Диморфа не осталось кратера. На Земле кратеры образуются за короткое время, а типичный угол конуса воронки составляет около 90 градусов. Но на Диморфе все иначе. Дело в том, что этот объект представляет собой «мусорную кучу» — скопление обломков, удерживаемых вместе очень слабыми силами гравитации. Симуляции показали гораздо более широкий угол конуса выброса, доходящий до 160 градусов, на что повлияла изогнутая форма поверхности астероида, а также то, что значение второй космической скорости на нем составляет всего 10 см в секунду.
По мнению ученых, наиболее вероятный сценарий заключается в том, что кратер продолжил расширяться и в какой-то момент попросту охватил весь астероид. В результате, Диморф фактически изменил свою форму. Исследователи образно сравнивают его с M&M, от которого откусили кусочек. По их оценкам, удар DART выбросил в космос порядка 1% вещества Диморфа и привел к смещению еще порядка 8% его вещества.
Если Hera подтвердит эти выводы, то они также будут иметь важное значение и для истории происхождения Диморфа. Исследователи подозревают, что он образовался в результате прошлого «вращения» Дидима, выбрасывавшего в космос материал с экватора, который затем сросся под действием гравитации.
Приветствую всех, кто это читает, и в особенности тем, кому не безразличны супергеройские сериалы с канала CW. Я продолжаю серию умеренно интересных/вообще неинтересных (смотря кого спросить) постов о сходствах и различиях между персонажами из сериалов и их версиями из комиксов. В прошлый раз прошёлся по крупным злодеям, так что сейчас займусь некрупными незлодеями – нейтральными и положительными персонажами и их союзниками, вразнобой.
Разумеется, дисклеймеры: кто сериалы не смотрел и боится испортить себе всё удовольствие, тех ждут спойлеры, а объективные описания перемежаются моими субъективными мнениями в отношении персонажей.
Начать предлагаю с Честера П. Ранка. Тут отличия от комиксов идут вообще по всем фронтам. Общего с комиксным вариантом разве что цвет кожи. В комиксах Барри Аллен даже лично с Честером никогда знаком не был. Но Честер был другом Уолли Уэста. Он дебютировал как злодей поневоле – жиробубель, у которого в теле было целое параллельное измерение, и который был вынужден похищать и ЖРАТЬ алмазы, чтобы это измерение не сожрало его изнутри. Уолли, бывший на тот момент основным Флэшем, стабилизировал его способность, и Честер стал его другом, а также бизнесменом, сколотившим состояние на утилизации свалок – пустил свою силу на поглощение мусора. В сериале же он дебютировал более-менее близким к варианту из комиксов (разве что стройным, а не жиртрестом), потом его замели под ковёр, и весьма надолго, объяснив это тем, что он типа лечился в лаборатории...и вернули его, когда из сериала ушёл Карлос Вальдес (Циско) и в команде освободилась вакансия супергения, спеца по отсылкам к поп-культуре и клоуна. Никем из этих троих Честер в комиксах не является.. Он весьма умён, но не супергений, не умеет в отсылки к Звёздным Войнам и не особо-то и смешной.
А вот с Кристин Крамер ситуация иная. Хотя бы потому, что в сериале её значительно лучше раскрыли...при этом полностью переписав. Это новый персонаж с тем же именем, но при этом у неё всё равно более значительная роль в жизни Флэша, чем в комиксах. В комиксах Кристн Крамер была обычным человеком. Криминалисткой, напарницей Барри Аллена. Её персонажеобразующей чертой была обида на Барри – однажды его вечные опоздания и прогулы перестало терпеть начальство и его передвинули на работу криминалистом в тюрьме. И Кристен, как напарницу, вместе с ним, что ей ОЧЕНЬ не понравилось. Всё, это весь её персонаж в комиксах. Но в сериале она офигенно суровая следовательница, которая испытывает неприязнь к металюдям при том, что сама метачеловеком является. Да – в комиксах никаких суперсил у неё нет, а в сериале она может копировать силы находящихся рядом металюдей. Она дебютировала практически как антагонист, со своим жёстким отношением к Флэшу и остальным, но впоследствии перешла на сторону Флэша. В плане внешности же очередной gingercide – рыжий в комиксах персонаж утратил пламя в волосах. Зато обрёл душу.
Рип Хантер...тут беда, конечно, ибо так испоганить персонажа, это надо уметь. В плане внешности претензий нет, хотя играющий Рипа актёр, Артур Дарвилл, похоже, так и не смог выйти из роли Рори Понда из сериала «Доктор Кто». Проблема не в этом. Рипу катастрофически уменьшили размах и снизили важность. Рип в комиксах – без преувеличения, главный специалист вселенной DC по путешествиям во времени. Если он где-то замешан, значит, предстоит эпик. И главное – он выживает и является неотъемлемой частью вселенной DC. В Стреловселенной он дебютировал в сериале «Легенды Завтрашнего Дна Дня» и собрал команду героев с целью уничтожения Вандала Сэвиджа. В принципе, в подобном он был замечен и в комиксах...да только в сериале ему до высот комиксного персонажа далеко. Он и под контроль Сэвиджа попадает, и истеричкой становится, а в итоге и вовсе погибает, пожертвовав собой, чтобы спасти остальных, и о нём, в общем-то, забывают. Сила характера? Авторитет? Экспертные знания? Аххаха. Слили персонажа. Зато поблистал крутым пальтишком. Ах да, а ещё Рип Хантер в комиксах это ложное имя, созданное специально чтобы никто не вычислил его семью, а в сериале о семье Рипа можно узнать больше, чем хотелось бы.
Тему Лисицы в Стреловселенной закрутили ж0ска и развили сильнее, чем в комиксах...для начала, продумав, что Лисиц было две. В комиксах была всего одна Лисица – Мари Дживе-МакКейб, обладательница Тотема Танту, позволяющего копировать способности животных. Есть она и в Стреловселенной...преимущественно в привязанном к Стреловселенной мультсериалу (но мультики я в этой серии постов не рассматриваю), ибо вживую появлялась примерно в одной серии. Большая же часть экранного времени посвящена другой Лисице – Амайе Дживе. В сериале «Легенды Завтрашнего Дня» это бабушка Мари, выдернутая из прошлого участница Общества Справедливости, примкнувшая к Легендам в стремлении наказать Эобарда Тоуна за то, что он убил её парня, Рекса Тайлера (Часового), а как с этим справились, она покинула команду и поселилась в своей африканской деревушке. О какой-то близости к комиксам говорить не приходится: в комиксах такого персонажа, как «Амайя Дживе», просто НЕТ. Мари есть, а Амайи нет. А Мари не состояла в Обществе Справедливости (зато состояла в Лиге Справедливости) и не встречалась с Часовым.
Мари в комиксах - Мари в сериале - Амайя. Оранжевый почти что кэжуал прикид, казалось бы, практически не нуждающийся в обновлении для экранов, заменили на кожу, ибо сидаб. И на жёлтый цвет, потому что оранжевого нельзя ни в волосах, ни в одежде.
Зато хотя бы со способностями Лисицы не стали оригинальничать и взяли способности из комиксов, перенеся их точно и полностью. Активировав Тотем Танту, Лисица и в комиксах, и в сериале может копировать способности какого-нибудь животного (полёт орла, сила гориллы и т.д.), и визуально это проявляется в виде окружающей Лисицу светящейся ауры в виде соответствующего животного. Но поскольку отрисовка спецэффектов это дорого, то в определённый момент Тотем по сюжету начал сбоить, и Амайя переключилась на рукопашку. Ах да, в плане внешности. Претензий в целом не имею (разве что у Лисицы в комиксах традиционно короткие волосы, а в сериале длинные), но сериал, как водится, пожмотился на костюм. Костюм у Лисицы в Стреловселенной официально есть, даже более костюмистый, чем в комиксах...но Амайя предпочитает носить обычную одежду.
А теперь уведите куда-нибудь чувствительных мальчиков, говорить будем о цыганах. Вернее, о Цыганке. И скажу сразу – персонажи с таким прозвищем в комиксах и в Стреловселенной совершенно разные (хотя вряд ли кого-то это уже удивит)! О внешности даже говорить не приходится. Цыганка в комиксах всегда носила либо яркие наряды, чтобы соответствовать прозвищу, либо нечто брутальное (в 1990-х). Цыганка сидабовская – 100% Сидаб, чёрная кожа (некоторое сходство с послеФлэшпоинтовским нарядом, но минимальное). Зато у сидабовской поинтереснее тема. Дело в том, что Цыганка в комиксах...никакая. Это супергероиня не первого, и даже не второго эшелона. Да, она состояла в Лиге Справедливости...детройтской, в которой из классических участников были только Аквамэн и Марсианин. Когда Детройтская Лига Справедливости распалась, Цыганка некоторое время геройствовала сама, затем примкнула к Хищным Птицам (женской команде, которую организовала Барбара Гордон). В Стреловселенной же Цыганка – путешественница по Мультивселенной, работа которой - находить злостных нарушителей, которые сбежали из своих миров и прячутся в чужих вселенных. Это могла быть очень плодотворная тема...но её замели под ковёр, толком не раскрыв, и для верности Цыанку ещё и убили.
Отмечу также различия в способностях, которые тоже о многом говорят. Основная способность Цыганки в комиксах – замаскироваться под обстановку и не отсвечивать. Вообще она может создавать иллюзии, но в первую очередь использует их для маскировки типа «хамелеон». Хотя может и создавать пугающие иллюзии, чем неоднократно пользовалась. По традиции, герой, основная способность которого – быть незаметным, не бывает заметным и важным (Невидимая Женщина из Марвел, например, свою невидимость дополняет созданием мощных невидимых барьеров, а пока эта способность не появилась, в редакцию шли письма «убейте её»). А сериальная Цыганка была той ещё мастерицей. Она обладала способностями, внезапно, Вайба. А именно: стрельба вибрационными волнами, способность «прощупать» предмет и таким образом найти его владельца либо узнать, с чем предмет связан, и умение открывать порталы. Ничего из этого Цыганка комиксная никогда не умела. Стреловселенная могла сделать её важным персонажем...но увы.
А ещё фанаты до сих пор срутся по поводу её прозвища, ибо само слово Gypsy ночит несколько пренебрежительный характер (недостаточно, чтобы быть расовым ругательством типа "черножопый", но где-то на уровне "хохол").
И пока мы говорим о Цыганке, стоит упомянуть другого связанного с ней персонажа, и тут опять ПОЛНОЕ расхождение с комиксами...в лучшую сторону. В комиксах Бричер – исключительно эпизодический персонаж, отец Цыганки, дебютировавший в 2013 году (когда Цыганке уже переписали ориджин). Гость из иного измерения, сражавшийся против, по сути, злого двойника Вайба. Бричер в комиксах носил силовую броню и не снимал её, ибо чрезмерное использование энергии навредило его телу, практичвески превратив его в энергию. Но это в комиксах. В сериале же Бричера играет Дэнни Трехо, уж не знаю, чем его в Стреловселенную заманили. И это всё, что о нём нужно знать, ибо Трехо остаётся Трехо, где бы и кого бы ни играл. Никакой силовой брони, минимум вайбоподобных сил (для экономии бюджета), много колюще-режущего и буйный нрав. Ну круто же! Ну и да, по сюжету он отец Цыганки. И появляется в сериале чаще, чем она сама.
ЦИСКИИИИИ!
Пора поговорить об одном из моих любимых персонажей вселенной DC, Мистере Террифике. Это тот редкий случай, когда визуально практически полное попадание – когда он таки создал костюм и личность Мистера Террифика в сериале «Стрела», от образа из комиксов не отличить. А значит, как положено в Стреловселенной, все отличия в истории. Для начала, Террифика в комиксах зовут Майкл Холт, а в сериале Кёртис Холт. Зачем имя изменили – непонятно. Также бросается в глаза резкое различие в мотивации персонажа. В комиксах Майкл Холт был женат и жену горячо любил, но периодически гавкался с ней, ибо был заядлым атеистом, а жена была очень сильно верующей. Однажды из-за ссоры жена задержалась и по пути в церковь её сбила машина. Майкл винил себя в смерти жены (даже усомнился в своём атеизме – «Из-за моего упрямства жена погибла или бог наказал?»), даже подумывал о суициде, но решил вместо этого пойти по стопам героя Золотого века по прозвищу «Мистер Террифик». В сериале же Кёртис Холт – замужний гей, а Мистером Террификом стал после того, как огрёб по голове, ибо захотел стать сильнее, чтобы защищать себя и других, а прозвище взял в честь реслера. А ещё Майкл в комиксах глава собственной компании, а Кёртис в сериале – вечный подчинённый.
Уровень способностей Мистера Террифика тоже изрядно снизили. Не, так-то он крут и в комиксах, и в сериале, но из сериала убрали мои любимые «нереалистичные» способности. В комиксах Майкл – один из умнейших людей на Земле, техногений, атлет-десятиборец олимпийского уровня и весьма хорош в рукопашке. Он постоянно носит высокотехнологичную маску, которая делает его абсолютног невидимым для любой цифровой техники, а ещё у него при себе всегда несколько Т-Сфер. Каждая – микрокомпьютер в прочном корпусе с антиграв-движком (они могут летать сами, могут служить ударными снарядами, могут подерживать человеческий вес), с голографическим проектором и камерами, которые подсоединены к маске Террифика (так Майкл может с их помощью проводить разведку). А ещё Сферы бьют врагов током и взрываются. В сериале физуха и интеллект у Кёртиса вполне себе весьма но цифровой невидимости нет, а маска – это просто маска. Да и Сферы чутка попроще, хотя без сомнения, круты, тут со спецэффектами не экономили. Голограммы, взрывы, удары – это всё есть. В общем, вроде не то чтобы совсем исказили персонажа, но...почему геем сделали именно того, чей ориджин непосредственно связан с женой, и зачем менять имя?
Луч...один из персонажей, с которыми Стреловселенная поступила несправедливо. И нет, я имею в виду вовсе не резкую смену ориентации. В комиксах DC Луч – потомственный герой. Первый Луч бил нацистов ещё в 1940-е, в компании с Человеком-Бомбой, воспитанным кондорами «Маугли», одной из самых сексапильных супергероинь за всю историю комиксов и живым воплощением США. Его сын, Рей Террилл, родился солнечным ребёнком метачеловеком с солнечными способностями, и отец до совершеннолетия держал его в темноте, опасаясь, что преждевременная активация способностей под солнечными лучами может парня погубить. Луч состоял в Юной Справедливости и в нескольких разных составах Лиги Справедливости, и он один из топовых по способностям персонажей DC. В сериале же намудрили: Рей получил способности от своего двойника из вселенной победившего нацизма и отправился туда помогать немногочисленным местным героям бить нацистов. И, кстати, чуть не погиб, ибо его захватили в плен и приговорили к казни за гомосексуализм. Рей в комиксах, если что, изначально геем не был, но после успеха сериала ему ориентацию и в комиксах поменяли. В принципе, и костюмом, и способностями Луч вполне вышел, но его в сериале слишком мало для такого довольно важного персонажа. Как он поселился в той вселенной, где нацисты, чтобы их бить, так о нём и забыли.
В следующий раз напишу о мелких суперзлодеях, а вот когда именно будет следующий раз - это сюрприз, ибо пост ещё не готов, дел внезапно навалилось, а в свободное время по мне скучают спирачЧЕСТНО КУПЛЕННЫЕ ЗА ДЕНЬГИ игры (а я по ним). Так что...продолжение следует!
Друзья! А вы помните такие мобильные телефоны, как Siemens? Когда-то у всемирно известного консорциума, занимающегося выпуском различного силового оборудования и поездов, было собственное мобильное подразделение, которое успешно конкурировало в конце 90х и начале 2000х. Многие мои читатели «постарше» наверняка вспомнят, а то и сами владели такими легендарными моделями, как Siemens SL45, ME45, C55, C65, S65, S75! Но немногие знают, что в своё время эти девайсы были сродни полноценным Symbian-смартфонам Nokia, или даже современным Android-девайсам с разблокированным загрузчиком: энтузиасты быстро смогли разобраться в алгоритме генерации ключей для загрузчика и начать делать патчи, которые фактически превращали «тормозной» телефон в почти настоящий смартфон с полноценной многозадачностью! Недавно мне подарили целых три телефона Siemens, которые носят статус культовых: Siemens C65, Siemens C75 и Siemens S75! Два девайса из трёх были в замечательном состоянии, но имели некоторые проблемы в аппаратной части. В сегодняшнем ностальгическом материале, мы с вами: вспомним о том, какие телефоны делали Siemens в своё время и на каких аппаратных платформах они работали, продиагностируем, проведем аппаратный ремонт и составим список самых частых болячек устройств на платформе S-Gold, рассчитаем ключи для загрузчика, пропатчим, накатим эльфпак и посмотрим, какой же была моддинг-сцена телефонов в нулевых! Интересно? Тогда бегом разворачивать статью!
❯ Эх, Siemens, Siemens...
Пожалуй, ни одно видео или статья с ностальгией по мобильным телефонам из нулевых не обходится без упоминания телефонов от компании Siemens. Немецкие девайсы были инновационными и прорывными во многих аспектах. Например, инженеры Siemens стали первопроходцами, добавив возможность прослушивания MP3 на телефоне, поддержку карт памяти MMC (предок MicroSD, полностью совместимый с ним на программном уровне) и установки полноценных Java-приложений в легендарный SL45, вышедший аж в 2000 году. Нельзя также не упомянуть первый телефон с цветным дисплеем и предусмотрительность инженеров Siemens с точки зрения разъёма для аксессуаров — вряд ли вы видели ещё один телефон с возможностью «горячей» установки внешней камеры прямо в порт для синхронизации!
Но особый статус телефоны Siemens получили на территории СНГ — их девайсы одновременно обожали и злостно ругали. И ведь было за что их любить: у Siemens был особый подход к дизайну телефонов с чётким разделением целевой аудитории устройства, не похожий ни на Nokia, ни на Sony Ericsson, а прошивка в этих девайсах хоть и была достаточно тормознутой и местами не совсем логичной, но тем не менее, её визуальная часть была сделана с явной любовью художников к делу. Каждый девайс по своему отличался от своих собратьев. Вот, вспомните молодежного маскота Siemens, пацанёнка в очках:
Критика в основном заключалась в очень сырых и тормозных первых версиях прошивок (однако компания активно выпускала обновления и пользователь мог спокойно перепрошить телефон в домашних условиях без похода в СЦ), слишком сильном урезании C-серии (например, в С75 невозможно было установить флэшку, а встроенной памяти было мало для мультимедийного телефона) и отсутствии поддержки MP3 на поздних устройствах. Но тем не менее, «сименсам» всё равно было что предложить простым пользователям в мультимедийном плане. А со временем, потянулись и энтузиасты…
Телефоны Siemens были построены на двух аппаратных платформах разработки родственной компании Infineon (ранее эта компания была полупроводниковым подразделением Siemens и занималась разработкой микропроцессоров): первая платформа называлась E-Gold и состояла из микропроцессора с архитектурой C166, работающего на частоте от ~13МГц (SL45) до ~52МГц (S55), GSM-радиотракта и контроллера питания Dialog (на некоторых телефонах использовался Twigo, по каким-то причинам несовместимый с «диалогом»). Её мы могли встретить во множестве устройств A-серии (бюджетники), S и C серии до 6x, а также некоторых устройствах серии SL. Второй платформой была легендарная и многообещающая S-Gold, которая использовалась в устройствах 65'ой и 75'ой серии. Эта платформа была построена на базе ядра ARM926EJ-S, работающего на частоте ~104-208МГц (с возможность разгона), GSM-радиотракта с поддержкой GPRS и EDGE, а также всё того-же контроллера питания Dialog. В своё время устройства на базе S-Gold получили небывалый интерес среди энтузиастов, которые относительно быстро разобрались в алгоритме расчёта ключей для загрузчика и получили возможность применять специальные врезки ресурсов или кода в оригинальную прошивку устройства, называемые патчами. В сегодняшнем материале мы рассмотрим устройства именно на платформе S-Gold!
Со временем, патчи стали неотъемлемой частью «прошаренного» сообщества Siemens, которое в основном тусовалось на форуме siemens-club. Десятки людей активно ковыряли различные версии прошивок под разные девайсы, добавляя новый функционал или меняли визуальную составляющую устройства: какие-то патчи просто «перекрашивали» индикаторы, или, например, меняли шрифт устройства, другие отключали надоедливую кнопку выхода в интернет (которая сжирала огромные денюжки для среднестатистического школяра или студента тех лет), добавляли возможность альтернативного управления, переназначая вечно ломучий джойстик C65 на кнопки клавиатуры, а то и добавляли довольно точную A-GPS навигацию по карте вышек оператора (!) и поддержку нескольких (!!) E-Sim (!!!) в 2004-2005 году!
Пожалуй, многие читатели отнесутся со скепсисом к E-Sim в 2005 году. Но такая возможность была, хоть и не совсем в современном и удобном виде.
Дело в том, что у каждой SIM-карты, помимо публично доступного для телефона идентификатора IMSI, существует ещё идентификатор Ki, который возможно расшифровать только используя алгоритмы БС оператора. Однако в те годы, алгоритмы криптографии в «симках» были проще и с помощью специального софта была возможность «сбрутить» (взломать методом перебора) Ki за несколько часов. Патч, предположительно, работал довольно просто: он подменял Ki и IMSI на те, которые уже были предварительно посчитаны и заставлял baseband часть прошивки заново искать сеть. По итогу мы работали уже с другой SIM-картой :)
Не стоит забывать о различных патчах, связанных с Java-машиной: были ускорители Java-приложений, расширители хипа и тому подобное, позволяющие играть в Java-игры с большим комфортом.
Высшей точкой развития моддинг-сцены на телефонах Siemens стало появление эльфлоадера и эльфпака — возможности запуска нативных программ, написанных на C с полноценной многозадачностью и возможность переключаться между несколькими приложениями! Фактически, это превращало простой мультимедийный телефон в смартфон, который мог выполнять довольно широкий круг задач! Чего уж говорить, одними из самых популярных эльфов были клиенты электронной почты, аськи, плееры с поддержкой mp3 (они, кстати, с дикими хаками — поскольку PCM-часть сименсов толком не отреверсили, эльф просто налету конвертировал mp3 в wav (т. е. тот же PCM) и скармливал в родной плеер :)). Такая свобода действий позволяла, например, портировать на телефон эмулятор NES или SEGA и играть в них на долгих и скучных парах. Для владельцев обычных кнопочников (но не смартфонов на WM2003 for Smartphones) это было шиком и роскошью.
Стоит упомянуть также проект моего друга, с которым мы довольно давно знакомы — @Azq2, который вообще умудрился портировать на него Linux, причём полноценный, а не ucLinux (который не требует MMU и в целом попроще своего десктопного аналога).
Со временем подтянулись и фанаты других производителей мобильных телефонов — Motorola и Sony Ericsson. Сначала появились «моторы» — на мотофане с большим трудом смогли справиться с RSA-подписью и шифрованием прошивок (об этом может подробнее рассказать один из активных админов мотофана — @EXL. По его словам, не обошлось без утечек дебаг-инфы прошивки), но всё же нашли тестпоинт, изучили утекшую информацию и написали свой эльфлоадер, который работает на E398, E1, Razr V3/V3i и некоторых других аппаратах. Сонерики подтянулись позже всех, а вот на Nokia S40 почему-то никто особо и не пытался ничего сделать. Возможно дело в RPL-сертификатах и жёсткой политике Nokia относительно модов, а может в том, что моддерам хватало Symbian — ведь кастомные прошивки выходят даже сейчас!
Недавно мне подарили сразу двух красавцев в очень хорошем состоянии — Siemens C65 от известного блогера Maddy MURK и Siemens C75 от моего читателя из Краснодара. А ещё мой читатель @kostett, задарил CX75 в идеальном состоянии, S75 под реставрацию и S68, за что вам всем огромное спасибо!
И C65 и C75 имели определенные аппаратные проблемы — оба девайса не включались и не подавали никаких признаков жизни. Ну что ж, берём в зубы сервис-мануал, схему и идём диагностировать наших красавцев, плавно переходя в практическую часть нашей статьи!
❯ Диагностика
Начнём мы с вами с C75. Визуально девайс был в очень хорошем состоянии, если бы не бич 75-ой серии — крайне хрупкие корпуса. Крепления фронтальных панелек рассыпались прямо на глазах, так что на этапе фотографирования пришлось немного, эээ, выкручиваться :) К сожалению, к моменту написания статьи я так и не нашёл новый (пусть и китайский) корпус на C75 по нормальной цене, зато нашел на S-ки!
Итак, при установке аккумулятора, девайс не реагируетy ни на кнопку включения, ни на зарядное устройство. В первую очередь, нам нужно определить характер неисправности: исправны ли контроллер питания, процессор и флэш-память.
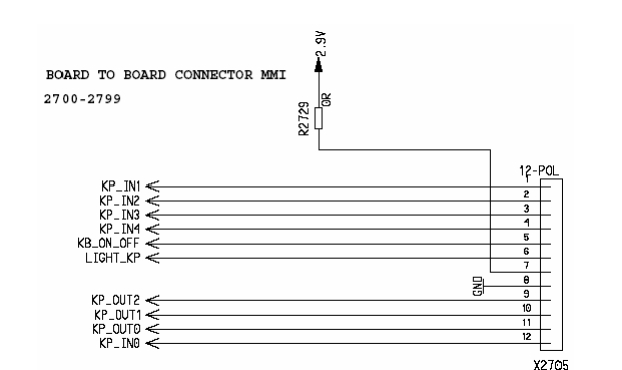
Очевидно что одно без другого работать не может, однако здесь важна поступательность действий: если за кнопку включения и формирование напряжений для остальных модулей отвечает КП, то и начинать нужно с него. Смотрим, присутствует ли на кнопке включения напряжение, близкое к вольтажу часов реального времени (~2.8В).
В нашем случае, питальники были на месте и при замыкании KB_ON_OFF на землю, КП кратковременно поднимал напряжения на процессоре и затем обратно отключался. Смотрим внимательно сервис-мануал и находим Power On Sequence. После старта контроллера питания, процессор должен вычитать из флэш-памяти стартовый код прошивки, проинициализировать ОЗУ и после этого регулярно отправлять «пинг» контроллеру питания, сигнализируя о том, что телефон работает. Если связь с флэш-памятью, ОЗУ или КП утеряна, то модуль WatchDog в КП просто выключит устройство.
Цитата из схемы на A60 на платформе E-Gold, но ASIC'и концептуально очень похожи.
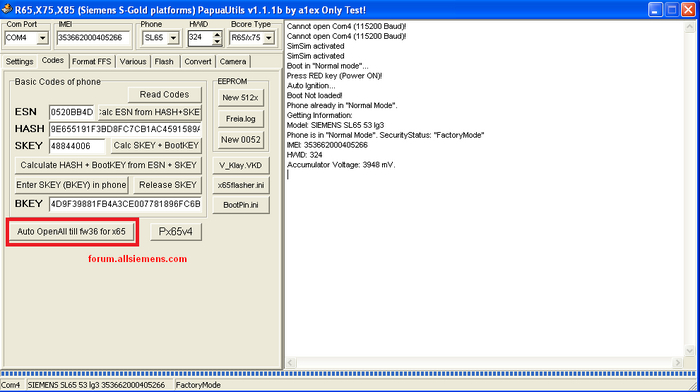
Кроме того, процессор тактируется от 26МГц кварца, идущего с SDR-передатчика. Если он пострадал в следствии воды или падения — телефон также не включится. Проверить наличие старта процессора можно с помощью x65PapuaUtils. Если девайс хотя бы как-то отвечает на нажатие красной кнопки и что-то показывает в логе «папуаса» — значит передатчик, скорее всего, жив. Но для этого, конечно же, нужен дата-кабель.
Самое время глянуть, что у нас под металлическими экранами! Вскрываем их и видим… вот это:
Явные следы попадания влаги, процессор был весь ужарен и во флюсе… кто-то ещё в нулевых пытался его ремонтировать. Берём в зубы строительный фен и сдуваем процессор:
Процессор снялся за 10-15 секунд без нижнего подогрева, что говорит нам о том, что прошлый мастер пытался посадить процессор «на пузо» (т. е. не нанося новые шары припоя) и у него явно не получилось. После этого на девайс забили и отложили в долгий ящик… чтобы спустя 18 лет он попал ко мне! Специально для ремонта этого «симака» я нашёл и купил новый BGA-трафарет, отреболил процессор и поставил обратно:
Помимо перекатки процессора, поскольку девайс «купался», помимо поврежденных шаров процессора помер и фильтр на USB, отвечающий за дата-кабель. Его можно заменить на перемычки, но для этого нужен адекватный микроскоп, которого у меня пока нет. Я пробовал махнуть с 65 серии — не работает.
Тот самый крошечный фильтр на примере C65. Находится в BGA-корпусе, его легко посадить «на пузо».
Подсобрал девайс и… Он включился! Правда, работал только под небольшим изгибом — присмотревшись, я обнаружил следы флюса около флэш-памяти производства Intel, которую тоже сажали на пузо, да ещё и криво. После прогрева, девайс поработал какое-то время и через пару дней отвалился — как раз к моменту подготовки статьи, а у меня как назло не было нужного универсального трафарета :( Поэтому C75 выбывает из сегодняшней статьи, окруженным, но не сломленным :) Трафареты заказаны — ждём, оживляем и я сделаю отдельный пост о его судьбе.
Давайте перейдем ко второму красавцу — Siemens C65. Как я уже говорил ранее, его мне подарил известный блогер Maddy MURK, у которого частенько выходят обзорные ламповые видео о ретро-мобилках. Заслал он мне сразу несколько девайсов под восстановление, одним из которых и был этот C65!
Изначально, у девайса был битый дисплей — это не проблема, у меня такие есть :) Очевидно, что это следствие падения и как это часто бывало на 65'ых/75'ых, заменой дисплея всё не закончилось. Всё дело в том, что в те годы отвал процов и диалогов был типовой болячкой на телефонах Siemens. После перехода на более низкий техпроцесс производства плат (шары уменьшились в размерах, а следовательно и сами контактные площадки), пятачки стали хрупкими и в лучшем случае дело заканчивалось отвалом с необходимостью прогрева или перекатки. А в худшем — пятаки под процессором срывало и приходилось их восстанавливать, тянув перемычки!
К сожалению, конструктивно некоторые Сименсы были не очень продуманы: блок клавиатуры был внешним и пружинился к коннектору на плате, создавая при каждом нажатии нагрузку на плату. Добавить к этому то, что иногда телефоны закручивались фиг пойми какими винтами (после мастерских и т. д.), перекашивая плату, и результат был печальным — спустя пару лет активных нажатий на клавиатуру, девайс переставал включаться…
И причина этому проста — из-за того, что плата подвергается регулярным деформациям (хоть и несерьезным) — со временем может либо оборвать дороги, либо просто отвалиться процессор/флэш/ОЗУ с необходимостью дальнейшей перекатки. Именно поэтому живых CX65 осталось относительно немного.
Девайс определялся в «папуасе», но не мог зайти в сервисный режим из-за ошибки связи с ОЗУ. Тут уже всё стало очевидно и я приготовил фен… ремонт оказался абсолютно таким же, как и в случае с C75! Правда, если вы хотите попробовать оживить свой симак и перекатывать BGA не умеете, то можете просто погреть и покачать процессор с хорошим флюсом, есть шанс, что девайс оживет и ещё порадует вас или, по крайней-мере, позволит скинуть фото на другое устройство.
Обратите внимание на выделенную надпись. Boot not loaded как раз означает то, что телефон ответил на нажатие буткея, но девайс не смог полностью проинициализировать загрузчик.
Дисплей я взял в одном из сименсов, которые купил по 70 рублей «на запчасти».
Включаем девайс и тут тоже всё работает :)
Девайс определяется в папуасе и полностью проходит тест дисплея, кнопок и звука, что означает его полную работоспособность! Подытоживая аппаратный ремонт, рассказываю о некоторых типовых болячках телефонов Siemens:
Телефон едва слышимо пикает при попытке включения: это называется пикофф (отключение телефона с вылетевшим исключением) из-за переполнения раздела с пользовательскими данными. Увы и ах, но его придётся форматировать (хотя перед этим можно посчитать ключи и снять дамп, а потом попытаться поискать фотки в условном binwalk'е). Решается очень легко при наличии дата-кабеля: подключаем телефон к ПК с Windows XP (подойдет и виртуалка), заходим в «папуас», жмём «Service Mode» и кратковременно нажимаем красную кнопку. После того, как девайс зашёл в сервис-мод, форматируем User-раздел в соотвествующей вкладке. Всё, девайс загрузится как новый!
Телефон не стартует, VRTC нет, питаний на тест-поинтах вообще никаких нет: начните с осмотра Dialog, на месте ли обвязка, не калится ли он, приходит ли на него VBat, какое потребление при нажатии на кнопку питания и есть ли реакция на подключение ЗУ. При необходимости перекатать или заменить. Аккумулятор тоже стоит проверить.
Телефон не стартует, но определяется в папуасе: проверьте процессор. При необходимости перекатайте и, если умеете, восстановите пятаки. Вполне возможно, что девайс когда-то прошивали и окирпичили — прошейте последнюю доступную сервисную прошивку (через Winswup). В крайнем случае можно посчитать буткей и залить фуллфлэш с чужого девайса.
Телефон не стартует, напряжения есть и никак не определяется: вполне может быть что и фильтр USB-поврежден, из-за чего папуас не видит телефон. Опять же, катаем проц, если не помогло — то ОЗУ и КП. Стоит глянуть на наличие 26МГц кварца с передатчика.
Телефон пикает и отключается в процессе работы: если есть дата-кабель, то x65PapuaUtils покажет причину пикоффа и ExitString, что поможет понять из-за чего ошибка. Но в основном это следствие кривой прошивки: шьем последнюю официальную и наслаждаемся!
❯ Прошиваем и патчим
Давайте сначала я просвещу вас в терминологию в мире моддинга сименсов:
Патч — хак оригинальной прошивки, который прошивается в флэш-память по определенному адресу. Обычно патчи подменяют графику, реакцию системы на какие либо события (например поиск сети или пропуск проверки SIM-карты) или добавляют новые функции.
Эльфлоадер — загрузчик нативных ELF-программ.
XTask — диспетчер задач, позволяющий переключаться между программами.
Эльфпак — сборка из эльфлоадера и необходимых патчей для его работы.
SWILIB, библиотека функций — Специальная таблица функций, предназначенная для того, чтобы эльфы и патчи могли работать на разных версиях прошивок.
Пришло время пропатчить наши сименсы и посмотреть, на что они способны теперь! Я собрал все необходимые файлы, в том числе папуас, флэшер и патчер, а также прошивки для C65 и SL65 и необходимые патчи в один архив, дабы вам не пришлось ничего искать самим! К сожалению, к моменту подготовки статьи, я так и не смог найти фильтр на C75, да ещё и флэша отвалилась :( Поэтому моддить мы будем только C65 и S75! И в этом нам снова поможет x65PapuaUtils. Для применения патчей нам необходимо разблокировать загрузчик путем расчёта Boot-ключе, которые генерируются на основе связки ESN + Hash. Для устройств 65 серии с низкой версией прошивки, x65PapuaUtils может сам всё сделать одной кнопкой, но для устройств 75 серии придется устанавливать отдельный мидлет и смотреть бут-ключи там.
Мидлет, позволяющий узнать ESN, эксплуатировал интересную уязвимость Java-машины, связанную с реализацией deflate. Благодаря тому, что разработчики оставили ошибку с переполнением, мидлет выходил за границы указателя и инжектил собственный шеллкод, который позволял читать и писать всё адресное пространство устройства :)
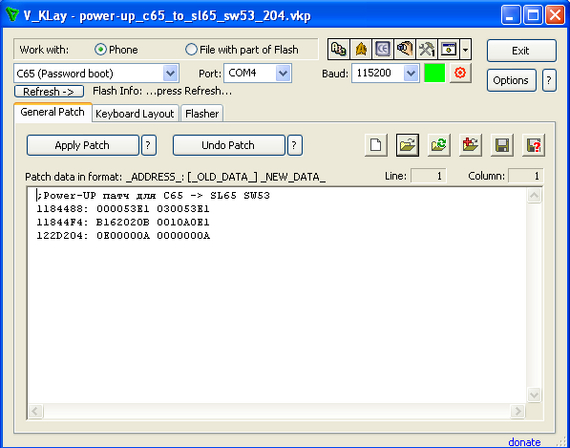
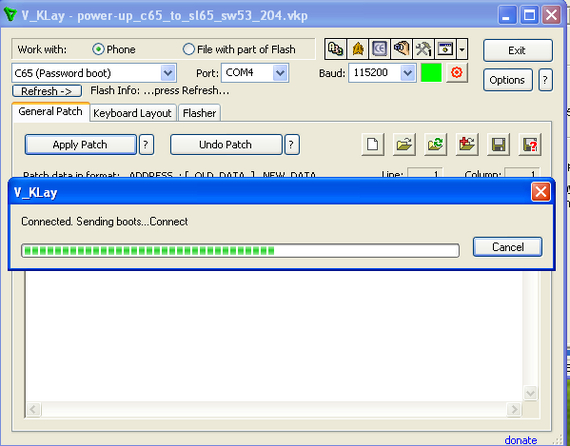
После разлочки загрузчика, сгенерируйте VKD-файл в папуасе и ставьте софт одного из самых крутых дядек в моддинг-сцене сименсов: V_KLay от ValeraVi! Это довольно крутая программа, которая оперирует собственным «языком» патчей: каждый патч предполагает указатель на адрес в флэш-памяти, старое значение (для валидации) и новое. По итогу, каждый патч — это просто текстовый файл, в том числе и эльфлоадер!
Пример патча. ValeraVi даже какое-то подобие препроцессора сделал с #if'ами — что вообще улёт :)
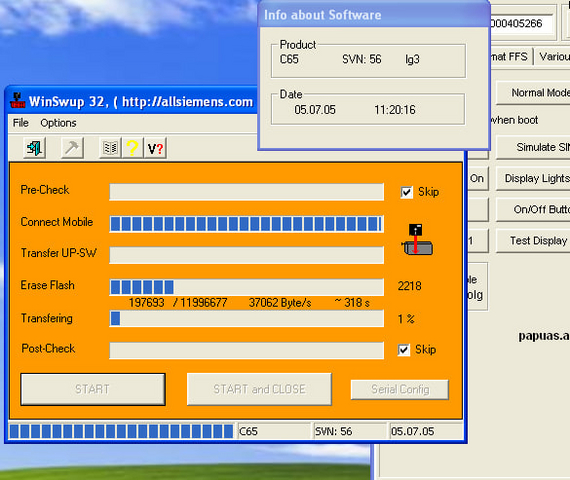
Но ставить патчи пока рано, на C65 в чистом виде не было нормального эльфпака, хотя патчей было достаточно. Обычно его перепрошивали в SL65, где была более шустрая Java-машина (вроде даже с поддержкой M3G) и возможность снимать видео! В остальном, девайс был почти аналогичен C65. Сначала телефон нужно «переименовать» в SL65 с помощью утилиты x65Flasher, а затем прошить WinSwup'ом с отключенными галочками проверок.
Девайс откажется стартовать, вылетая с пикоффом (при этом телефон будет жаловаться на Invalid HW). Для обхода этого ограничения, нам необходимо поставить специальный патч на обход проверки железа телефона и адаптации C65 к SL65. Делается это просто: загружаем патч по отдельности, выбираем C65 (Password boot) и подключаем выключенный телефон к ПК. Когда программа начнет искать телефон — кратковременно нажимаем красную кнопочку и программа начнет патчить девайс!
Делать дамп флэши необязательно, достаточно просто нажать пробел (дамп затянется на час-полтора).
После применения патчей, девайс стартует и работает как будто это SL65! Давайте же теперь присмотрим себе прикольные плюшки в базе патчей и накатим что-нить интересное. Например, я поставил «ускоритель Java», «замена значков на C75», «открыть все диски» и «работа без SIM-карты».
Увы, я несколько ночей бился с эльфпаком и заставить работать у меня его не вышло: на C65 эльфпак слишком старый и удален из базы патчей, а на SL65 он банально нерабочий — в комментариях тоже были жалобы на то, что программы банально не работают :(
Накатили эльфпак? Отлично, теперь наш телефон пропатчен, посмотрим как это работало в случае C65, а заодно узнаем, какую информацию он хранит в себе уже почти 20 лет!
❯ Знакомимся с девайсом поближе
Друзья! Эту часть статьи я решил оформить в виде серии относительно небольших видосов, дабы вы могли лучше прочувствовать дух того времени. Для занятых читателей, или просто тех, кто не хочет смотреть видео, я хотел сделать отдельный подраздел, где были бы только скриншоты - но увы, ограничение Pikabu на 25 медиа-элементов в одном посте дают о себе знать :(
Включив девайс, нас встречает такой знакомый звук щелчка включения света и пацаненок в очках на фоне! После установки патча на работу без SIM, девайс сразу грузится в систему и работает стабильно, без каких либо проблем. Эффекты от патчей есть сразу. Разблокируются два скрытых диска с кэшем системы и конфигами, что позволяет чистить их без форматирования устройства, немного меняется верхний статусбар, а Java-машина и StackAttack в ней работают заметно шустрее!
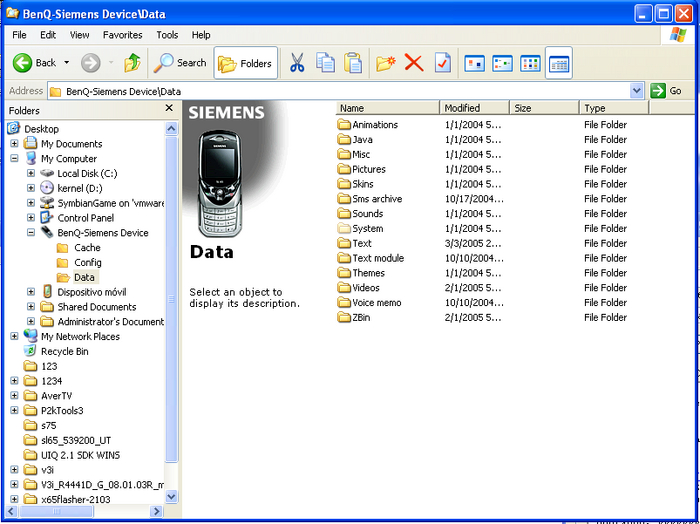
Но самая главная кладезь информации в «симаках» — это, конечно же, раздел файлов! Телефоном пользовалась маленькая девочка лет десяти и здесь, спустя практически 20 лет, сохранилась часть её жизни! На телефоне остались фотографии родственников, а также мультимедийные файлы, которыми она обменивалась со своими друзьями и возможно одноклассниками! На девайсе есть просто куча различных картиночек и гифок, популярные в рунете тех лет. Котики, гифки с девушками, машины — всё, чем делились пацаны класса попадало сюда! Не менее важной была и фонотека каждого телефона! Некоторые MIDI-мелодии на большинстве девайсов и сейчас можно встретить!
Что особенно забавно, девочка, видимо, очень хотела себе Sony Ericsson, так что на телефоне есть заставка с лого «сонерика» и фирменным рингтоном! А может, это отголоски тех лет, когда сонерики считались самыми крутыми и некоторые пытались стилизовать под них свои телефоны? Ведь в начале 2010-х такой тренд тоже был, но с кастомными прошивками в стиле iOS для Android смартфонов!
Осторожно, на фото ниже ламповые бобины, а из-за названия файла начинает играть миди в голове! Кто тут не узнает evropa.mid? На телефоне были самые разные треки, начиная с midi-версий ранних треков Eminem, заканчивая гимном СССР и, конечно же, саундтреками фильмов «Бумер» и сериала «Бригада»!
Но вы ведь, вероятно, ждёте эльфов, дабы узнать что они могли привносить новенького в телефон?
❯ А эльфы? Эльфы где!?
Ну как я мог написать статью про Siemens'ы без эльфов! Как я уже говорил выше, на C65 (который стал SL65) эльфлоадер поставить мне не удалось. Однако, на более популярные модели Siemens, эльфлоадер легко установить и он работает без проблем, разве что перед этим придется прошиться на самую свежую прошивку для вашего девайса!
Изучать эльфы мы будем с вами на примере Siemens S75, который подарил мне читатель! На телефон были установлены патчи для работы без SIM, библиотека функций а также эльфпак. Но для работы эльфов, необходимо закинуть на нулевой диск (т. е. в память) папку ZBin с некоторыми полезными программами типа того же XTask'а. Если у вас нет подходящей флэшки, то это можно сделать через Bluetooth, ИК-порт или дата-кабелем с помощью Mobile Phone Manager (осторожно, он забагованный до жути!).
Ну, а на видео ниже предлагаю вам ознакомиться с тем, что же привносили эльфы в мир телефонов Siemens!
❯ Заключение
И вот, казалось бы, мобильные телефоны Siemens серьёзно сдали позиции в 2004 году и совсем погибли после покупки компанией Benq. Но какая же ирония случилась ближе к концу 2000 годов, когда Nokia на платформе S40 начала использовать… чипсеты Infineon X-Gold, те самые продолжатели сименсовких S-Gold'ов! До этого Nokia использовала собственный процессор UPP (вроде бы, разработанный в сотрудничестве с STMicroelectronics). Помимо Nokia, X-Gold использовали Apple и некоторые другие производители (LG), а старую платформу E-Gold можно было встретить в некоторых бюджетных телефона, по типу Мегафон Минифон. То есть в весьма своеобразной форме, учитывая родственные связи Infineon и Siemens, «сименсы» как бы вернулись обратно на рынок телефонов, только уже в качестве «сердца» телефонов других брендов!
Вот такой была моддинг-сцена эльфов в нулевых годах! Лёгким движением руки, сименсы превращались из обычных кнопочников в почти аналоги современных смартфонов! Казалось бы, прошло практически 20 лет, многие форумы упомянутые в первом разделе статьи уже не существуют, а тот же мотофан стал прибежищем коллекционеров и немногих владельцев «моторов» в наше время. Но как бы не так! Спустя много лет, интерес к кнопочникам снова пробудился у многих участников сообщества того же сименс клаба. Мы чудом обнаруживаем, что база патчей для Siemens, которую ведет Илья kibab всё ещё работает, EXL с мотофана продолжает портировать всякие ништяки на моторы, Azq2 всё ещё пилит эльфы, патчи, а также полноценный аппаратный эмулятор процессора SGold, который способен запустить родную прошивку! У любителей моддинга мобилок из нулевых есть собственный TG-канал siepatch, где обсуждают моддинг под симаки, моторы — всё подряд! Но чатик формально приватный и по инвайтам. Если действительно хотите попасть туда — пишите мне в тг @monobogdan, скину инвайт.
P. S.: Друзья! Время от времени я пишу пост о поиске различных китайских девайсов (подделок, реплик, закосов на айфоны, самсунги, сони, HTC и т. п.) для будущих статей. Однако очень часто читатели пишут «где ж ты был месяц назад, мешок таких выбросил!», поэтому я решил в заключение каждой статьи вставлять объявление о поиске девайсов для контента. Есть желание что-то выкинуть или отправить в чермет? Даже нерабочую «невключайку» или полурабочую? А может, у этих девайсов есть шанс на более интересное существование! Смотрите в соответствующем посте, что я делаю с китайскими подделками на айфоны, самсунги, макбуки и айпады! Да и чего уж там говорить: эта статья уже сама по себе весьма наглядный пример! Найти меня можно в комментариях тут, на Пикабу, и в тг @monobogdan
Понравился материал?
Был у вас Siemens?
Я тут Galaxy S8 прикупил за 800 рублей. Большая часть фотографий в статье сделана именно на него. Норм качество?
Понравилась статья и хотите поддержать меня, дабы новые статьи выходили чаще? Ниже есть формочка с донатами. Всем большое спасибо!
А вам как наши сегодняшние герои? Понравились? Если вдруг интересно, то у меня есть канал в Телеге, куда я публикую бэкстейдж со статей, всякие мысли и советы касательно ремонта и программирования под различные девайсы, а также вовремя публикую ссылки на свои новые статьи. 1-2 поста в день, никакого мусора!
Материал подготовлен при поддержке TimeWeb Cloud. Подписывайтесь на меня и @Timeweb.Cloud, дабы не пропускать новые статьи каждую неделю!
Исаак Шварц, Композитор Исаак Шварц – легендарный композитор, музыкой которого восхищается уже несколько поколений. Его взросление происходило в музыкальной семье – это сказалось на дальнейшей судьбе. Большую часть своей жизни он посвятил творчеству, созданию композиций, мало кого оставляющих равнодушными.Дом-музей имени Исаака Шварца в п. Сиверский
Дом Музей имени Исаака Шварца в пг. Сиверский. В 2011 году в п. Сиверский Ленинградской области состоялось открытие дома-музея имени Исаака Шварца. Все желающие теперь могут побывать в бывшей творческой мастерской талантливого композитора. Сегодня этот музей является одним из наиболее популярных в Ленинградской области. Количество экспонатов в его основном фонде превышает 5 тыс. Они в деталях рассказывают о жизни композитора, знакомят с бытом Шварца.
Вся обстановка в музее подлинная. Именно так все и выглядело при жизни музыканта. К наиболее ценным экспонатам причисляют уникальную документацию из семейного архива композитора, нотные сборники, партитуры, награды, когда-то врученные Шварцы. И это далеко не все, посетителям музея будет интересно взглянуть на:· афиши фильмов и спектаклей;
· ордена;
· «иконостас» - собрание фотографий людей, которыми гордится отечественное искусство.В музее функционирует несколько постоянных экспозиций. Одна из них называется «И Музыка стала жизнью…». Другая – повествует о совместном творчестве композитора с Булатом Окуджавой.
Концертно-выставочный зал при музее
В 2020 году при музее возвели Концертно-выставочный зал. Сегодня его задействуют для проведения мастер-классов, лекций, семинаров, концертов и выставок картин.
Большинство визитеров сначала посещают именно это здание. Тут на регулярной основе проводятся вечера музыки, здесь же находится касса.Стены декорированы нотами и разнообразными музыкальными инструментами. Смотрится такое оформление очень эффектно и необычно.
Экскурсия в среднем длится 1,5 часа.
Впервые композитор побывал в Сиверской в годы студенчества. Ему так полюбились местные пейзажи и красоты речки Оредеж. В 1964 году Шварц перебрался насовсем.
В его распоряжении было целых два дома. В одном он проживал с супругой, а второй использовал в качествеЧто интересного можно увидеть в музее?
Обстановка в кабинете Исаака Шварца не изменилась. Утро композитора начиналось с зарядки и занятий на велотренажере.
Большой интерес у посетителей вызывает рояль «Бехштейн», впрочем, как и рабочий стол.
Рояль Бехштейн Исаака Шварца в его доме. пг. Сиверский Отдельное место в доме композитора было обустроено для отдыха. На торшере лампы лежит свисток, с его помощью Шварц подзывал своего пса. Композитор держал собаку породы сенбернар по кличке Ральф.
В кабинете сохранилось большое количество аудиокассет, лично записанных композитором. Периодически он слушал их под настроение.
Из интересных экспонатов в кабинете выделим еще и различные награды. Шварц трижды получал престижную в мире кинопремию «Ника».Экскурсия в дом-музей композитора будет интересна всем, кто интересуется музыкой.
Расскажите в комментариях, бывали ли вы в этом музее, и какие интересные выставки вы посетили в последнее время?
Это заключительная часть нашего лонгрида про то, что на самом деле скрывается внутри нейросетки для генерации видео под названием SORA. Если вы не читали первую часть, то начать лучше именно с нее.
Поразительное качество рендеринга
Ну что-то мы с тобой, Нео, зациклились на одном видео с девицей в красном — давай пощупаем что-то ещё. Второе видео, на котором хочется сделать акцент, короче. За 9 секунд нам показывают вид от первого лица девушки, созданный коротеньким промптом: «Отражения в окне поезда, едущего по пригороду Токио».
Вы только посмотрите на эти отражения! Как объекты приобретают форму, когда за окном проносится тёмный столб, и затем снова превращаются в силуэт на стекле! И это при том, что за окном проплывает пригород, какие-то здания ближе и визуально движутся быстрее, а те, что поодаль, минимально меняют ракурс. Мы, люди, привыкли, что и в кино, и в реальной жизни всё это естественно, но даже для видеоролика сделать такую отрисовку с большим количеством объектов и отражениями — это надо постараться.
Этот и ещё пара примеров (1, 2 и даже 3) вообще заставили людей обсуждать гипотезу об использовании реального игрового движка для отрисовки изображения. И уж если оный не используется для предсказания в сложных сценах, то наверняка в нём генерировали обучающую выборку! Это, конечно, спекуляция, и однозначного ответа на вопрос у нас нет. Из всех технических деталей, представленных в блоге OpenAI, можно сделать вывод, что конкретно пиксели модель рисует сама (без опоры на условный игровой движок Unreal Engine 5) — исследователи даже констатируют, что этот навык появился исключительно при масштабировании модели.
Другие неожиданные сюрпризы SORA
Одна из новых и (частично) неожиданно появившихся способностей модели — это возможность создания видео с динамическим движением камеры. Мы уже это наблюдали в первом примере: камера двигается и вращается, а люди и прочие элементы сцены перемещаются в трехмерном пространстве соответственно нашим естественным ожиданиям. Но не мог не поделиться с вами этими чудесными сценами.
Представляете, какое количество аспектов приходится учитывать модели мира? Ведь приходится моделировать поведение агентов (в данном случае — людей) и множество взаимодействий для каждого кадра. Но давайте изолируем задачу и сфокусируемся на ней: иногда SORA может имитировать простые действия, влияющие на состояние мира. В одном случае это изменение картины в местах, где полотна касается кисточка, а в другом бургер становится откушенным.
Опять же, выглядит естественно, мы даже не замечаем, мозг принимает это как должное. Но представляете сколько усилий пришлось бы прикладывать инженерам-программистам, чтобы все подобные взаимодействия прописать для какой-нибудь игры в мельчайших деталях? Да что там, люди до сих пор смотрят на ролик из Red Dead Redemption 2 ниже, и переживают, что уж ну вот с таким-то уровнем детализации мы никогда не увидим следующего творения Rockstar. А подборки в духе «200 невероятных деталей, которых нет в других играх!» даже спустя 5 лет после релиза заставляют игроков удивляться кропотливости разработчиков.
И раз уж мы заговорили про игры — а вы знали, что SORA как ультимативный симулятор миров может эмулировать... Minecraft?
Всё, что вы увидели в этих двух примерах — полностью сгенерировано. Так же, как в примерах с DOOM и гоночной игрой из середины статьи — это «подглядывание» в симуляции, воспроизводимые моделью. И в эти симуляции можно подсадить агентов обучаться делать что-либо. Они, ни разу не провзаимодействовав с реальным миром, могут обретать навыки, переносимые в реальность.
И, да, все продемонстрированные свойства возникают без какого-либо внесения явной информации о трехмерных объектах в сцене, их геометрии, и т.д. — это исключительно проявление уже упомянутого масштабирования, с которым модель учится всё лучше и лучше решать свою задачу.
Но почему бы просто не создать игру?
Вероятно, главный вопрос, который крутятся в голове технически подкованных читателей — это «Зачем здесь для создания модели мира нужна нейронка, когда можно просто взять игровой движок и сделать игру?». Давайте постараемся подискутировать и порассуждать.
Разработка обычно упирается в три тесно связанных фактора: размер команды, бюджет и срок разработки. Самые дорогие в производстве игры стоят порядка ~$300M, самыми детально проработанными называют игры Rockstar (это которые GTA делают). Пример такой игры я приводил выше, и вот даже после показа трейлера GTA VI интернет взорвался вниманием к деталям: вау, песок на пляже прилипает к ногам! Ого, как реалистично распыляется спрей! Невероятно, там есть ветер, который развевает волосы!
Самые большие фанаты уже покадрово разбирают трейлер следующей игры и строят теории. Уровень детализации впечатляет — от отражений на багажнике до прилипшего к ногам песка.
Но с ручной проработкой есть одна проблема: она плохо масштабируется. Даже при сроке разработки игры больше 5 лет количество мелких деталей, которые в неё можно было бы добавить, всё равно превышает реально имплементированное. Физика волос, тканей, одежды, жидкостей, снега, поведение животных и людей... это всё надо продумать и прописать.
Если задуматься, это всё то, за что мы могли бы похвалить SORA или в худшем случае её наследника SORA 2. Только вот для SORA 2 нам не нужно собирать команду в три тысячи разработчиков и пыхтеть 7 лет, а для игр мы очень сильно ограничены человеческим ресурсом. Количество и качество проработки сильно упирается в программистов (и способности ими руководить). С нейросетями, как было упомянуто, ситуация не такая: ты просто покупаешь больше видеокарт, делаешь модель покрупнее, и вуаля! Кто знает, какие детали начнут около-идеально симулироваться при увеличении модели ещё на порядок?
Поэтому, даже если мы захотим сделать глобальный суперпроект мегасимуляции (для чего бы это ни было нам нужно) — мы просто не сможем прописать каждую песчинку на пляже, каждое дуновение ветра. Масштабирование модели позволяет выучить все полезные вещи из уже имеющихся данных, главное, чтоб электричества, видеоускорителей и денег хватило :)
Но может игры не нужны, и достаточно обойтись реальным физическим миром? На самом деле, тут та же самая проблема — чтобы обучать модели нужны сотни тысяч, миллионы попыток. Те же боты в DotA 2 при обучении наигрывали 200-300 ЛЕТ опыта в сутки. Примерно то же происходило в AlphaGo, системе для настольной игры го от DeepMind: модель играла сама с собой тысячелетиями. Просто не в реальности. Так что для обучения интерактивного агента в реальном мире нам либо придётся долго ждать, либо строить целую армию терминаторов, что а) крайне затратно, и б) из-за развития технологий теряет актуальность, железо устареет быстрее. Проще закупить кластер видеокарточек, которые могут делать и обучение, и ещё десяток вещей в других областях. Опять масштабирование побеждает!
Опускаемся с небес на землю
Но в то же время мы уже видели, что даже моделирование простой игры неидеально, и бот может научиться эксплуатировать симуляцию. Одно из решений — это чередование виртуального и реального мира, с постоянным итеративным дообучением из самых свежих собранных данных. Как только алгоритм определяет, что его модель мира слабо предсказывает происходящее и уж очень ошибается — эти данные кладутся в выборку с пометкой «первый приоритет». Чтобы, наблюдая ситуацию из видео ниже, модель «удивлялась», и исправляла неточность:
В данном примере нейронка (и, вероятнее всего, выработанная ею модель мира) не точно воспроизводит физику многих основных взаимодействий — таких, как разбивание стекла или опорожнение стакана. Другие сложные взаимодействия (вроде потребления пищи) не всегда приводят к правильным изменениям состояния объектов. В длительных сценах возникает несогласованность, а также спонтанные появления или исчезновения объектов. Модель также может путать пространственные аспекты промпта (и даже право-лево не отличать).
Но зачем же тогда OpenAI сделали анонс и выложили кучу демок? Технология как будто бы не готова для производства видеоконтента, а модель мира у неё пока... не ясно, будет ли достаточной для обучения ботов в аналоге Матрицы. Во-первых, как написано на официальной странице: «мы делимся результатами нашего исследования на раннем этапе, чтобы начать обсуждение и получать отзывы от людей, не входящих в состав OpenAI, а также чтобы дать общественности представление о том, какие возможности искусственного интеллекта ожидают нас в будущем». А теперь и вы, прочитав эту статью, имеете более полную картину мира, понимаете, что и как делается, и к чему стоит готовиться. Компания пока не планирует предоставлять доступ к модели всем подряд — но уже начался период закрытого тестирования на предмет безопасности и байесов (устойчивых искажений в какую-либо сторону) генераций.
Во-вторых, OpenAI в очередной раз пофлексили превосходством над другими игроками — только посмотрите на генерации моделей конкурентов (открытых и закрытых) по тем же самым промптам, что и у SORA. Даже не близко! Но впереди нас ждёт только развитие.
А что, собственно, впереди?
И тут мы переходим на территорию осторожных, но спекуляций. В OpenAI уверены, что продемонстрированные возможности указывают на то, что продолжение масштабирования моделей генерации видео является многообещающим путем к разработке очень проработанных симуляторов физического и цифрового мира, а также объектов, животных и людей, которые населяют их. Эта фраза повторяется дважды в этой статье — и точно также в блоге OpenAI, уж настолько сильно компания хотела задать акцент.
Но как такой симулятор нашего мира можно использовать, и чем он полезен? Кроме детально разобранного плана обучения ботов внутри виртуального мира, видится два ключевых направления работы. Первое — это обучение GPT-N+1 поверх (или совместно) с видео-моделью, чтобы те самые латенты, характеризующие состояние мира и механики взаимодействий в нём, были доступны языковой модели. Без углубления в технические детали отмечу, что существуют способы обучения нейросетей одновременно и на тексте, и на изображениях/видео — так, что сам «предсказательный движок» будет общий, а энкодер и декодер свои для каждого типа данных. Тогда даже при генерации текста GPT будет опираться на модель мира, выученную в том числе по видео, получит более полную картину взаимодействий объектов и агентов. Это своего рода «интуиция», которая также, как и латент в случае гоночек/DOOM, будет нести в себе неявное описание потенциального будущего, что в свою очередь повлияет на навыки рассуждений с далёким горизонтом планирования. Именно это является одной из основных проблем современных LLM — они могут выполнить какую-то одну простую задачу, но не могут взять целый кусок работы, декомпозировать, распланировать и выполнить.
Второе направление работы — это непосредственно симуляция, когда модель при генерации как бы берёт паузу, и проигрывает несколько разных симуляций будущего: а что будет, если сделать вот так или эдак? Происходить это будет в пространстве сигналов (латентов), так же, как мы в голове размышляем, что будет при таких-то и таких-то действиях — поэтому проблема неидеальной реконструкции снова уходит на второй план. На основе анализа результата десятков-сотен прокручиваний ситуации можно скорректировать поведение модели/агента. Вероятно, мы увидим первые эксперименты в рамках компьютерных игр — зря что ли OpenAI в прошлом году купили компанию, разрабатывавшую аналог Minecraft, но с упором на социальные взаимодействия? Тем более, что это не будет их первым опытом в игрушках: ещё до GPT-1 проводились эксперименты с популярной игрой DotA 2, где в итоге команда скооперировавшихся ботов дважды обыграла чемпионов мира.
Но у SORA для таких симуляций нет одной важной детали: возможности учитывать действия агента. Ведь вспомните: модель мира работает не только с сигналом от окружения, но и с командой, предсказываемой ботом. Если из одного и того же кадра гонки делать поворот налево или направо — то очевидно, что будущее будет разным. Так что к системе обучения на видео к SORA придётся приделать сбоку модуль, который как бы угадывает, что происходит между кадрами. Тем более что у OpenAI есть опыт подобной работы (опять совпадение? не думаю) — летом 2022 года они обучали нейросеть играть в Minecraft по видео с YouTube. Для того, чтобы сопоставить картинку на экране с действиями, по малому количеству разметки была натренирована отдельная модель, предсказывающая вводимую игроком команду. Правда, на видео общего спектра такой подход применить сложнее — какая вот команда отдаётся на съемке процесса завязывания галстука? А на записи футбольного матча? А как это увязать?
Вполне возможно, что ответ — как и всегда — будет следующим: «ну дай машине, она разберётся, главное чтоб данных хватило». Пока писался этот блогпост, Google DeepMind выпустили статью с описанием модели Genie, предназначенной для... генерируемых интерактивных окружений. Такой подход принимает на вход кадр и действие и предсказывает, как будет выглядеть мир (и какие потенциально действия можно сделать). И, конечно же, тестируется это на настоящей робо-руке, ведь игрушек нам мало!
Обратите внимание на реалистичную деформацию пакета чипсов. Это не реальный объект, кадры полностью сгенерированы выученной моделью мира. Контроллер робо-руки может принять решение после многократной симуляции будущего для более аккуратных манипуляций.
Скорее всего, и на обучение, и тем более на применение моделей на масштабе всего YouTube потребуется огромное количество ресурсов, заточенных под работу с нейросетями. Уже сейчас ведущие в AI-гонке компании сталкиваются с проблемами: видеокарт Nvidia не хватает на всех, а список закупок заполнен на год вперёд. Даже если есть денежные средства масштабировать модели в 10, в 100 раз — может просто не хватить GPU. При этом, нейронки легче и меньше становиться пока не планируют. Вот например SORA, по слухам, требует часа вычислений на генерацию минутного FullHD ролика. Это может быть похоже на правду — сразу после анонса команда OpenAI генерировала в твиттере видео по запросам людей, и минимальное время от твита до генерации составило 23 минуты. Но и ролик был 20-ти секундный!
В общем, как спайс занимает центральное место в мире Дюны, так и вычислительные мощности играют ключевую роль для AI — наравне с данными. Вероятно, поэтому начали появляться слухи о желании Сэма Альтмана привлечь инвестиции на реорганизацию индустрии (не компании, а всей индустрии!) производства полупроводников и чипов, создав глобальную сеть фабрик. Слухи какие-то совсем дикие — мол, нужно привлечь от 5 до 7 триллионов долларов. Это, на минуточку, 4–5% от мирового ВВП! Капитализация самой дорогой компании в мире, Microsoft (лол? напродавали винду), составляет 3 триллиона. Да на 7 триллионов можно и весь Тайвань прикупить, чего уж — главное, чтоб Китай позволил.
Нет, это не оценка компании или всего рынка, это именно необходимые инвестиции. Да.
Лично я не верю в такие суммы, но порядок двух-трёх триллионов инвестиций на горизонте десятилетия считаю посильным. Знаете, запускать Матрицу для того, чтобы погрузить в неё 8 миллиардов людей — дело всё же недешевое! В общем, поживём — увидим.
Согласны? Узнали себя? (Надеюсь, что нет)
Одно можно сказать точно: если Сэм Альтман будет продолжать двигаться такими темпами — то проблема моего досуга на ближайшие несколько лет точно будет решена. Придётся пилить здоровенные лонгриды с объяснением того, каким конкретно образом свежие нейросетки собрались захватывать наш мир на этой неделе, буквально безостановочно. :) Если вы не хотите пропустить эти будущие материалы — то подписывайтесь на мой ТГ-канал Сиолошная. (Также отдельная благодарность Паше Комаровскому из RationalAnswer за то, что помог с редактурой этого гигантского материала, и Богдану Печёнкину с Ярославом Полтораном за вычитку опечаток.)
Это вторая часть нашего лонгрида про то, что на самом деле скрывается внутри нейросетки для генерации видео под названием SORA. Если вы не читали первую часть, то начать лучше именно с нее.
Опускаемся на уровень глубже: Дум — крута!
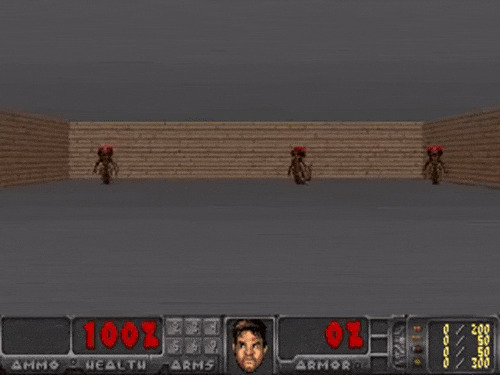
Но вы поди уже устали смотреть на какие-то пиксельные машинки и гоночки, давайте возьмём что-то крутое. Как гласит культовая фраза, Дум — круто! Поэтому слегка сменим обстановку, и переместимся в новое игровое окружение с новыми правилами.
Дум — крута!
Дум — это 3Д-экшон, суть такова... здесь взята урезанная игра с понятной задачей: продержаться в комнате с монстрами-импами как можно дольше. Можно перемещаться влево-вправо, чтобы уклоняться от огненных шаров, запускаемых монстрами в другом конце комнаты. Чем больше времени продержишься — тем лучше.
Наконец-то запустили дум не только на мобилках и холодильниках, но и на Висишечке
Первым делом необходимо переобучить энкодер-декодер, а затем — модель мира. Мы уже детально обсудили, как это делать. Единственным изменением является то, что помимо следующего состояния мы также предсказываем нолик или единичку — в зависимости от того, закончилась ли игра (если вдруг в игрока попал огненный шар). Если мы хотим тренировать бота полностью в симуляции, то как иначе нам понять, что game is over?
Затем произведём обучение нейросети, отвечающей за контроль игрока — полностью внутри симуляции. То есть, этот агент не будет играть в игру вообще: ни один латент, на основе которого принимается решение (двигаться влево или вправо), не будет получен из реальных изображений. Да и самих изображений вообще нет — только цепочка последовательно предсказываемых сигналов, которые бот мог бы увидеть от реальной игры (если бы не летал в фантазиях).
На нашу радость, с помощью декодера мы можем подсмотреть, что происходит в этой симуляции — и даже при желании поиграть в неё самостоятельно (ведь симулятор предсказывает следующее состояние не только по текущему латенту, но и по действию — движется игрок или стоит). Ниже вы можете увидеть запись симуляции. Если в нижнем левом углу робот — то играет обученный бот, а если обезьянка — то ваш покорный слуга. :) Обратите внимание на счётчик времени слева сверху (он наложен отдельным скриптом) — игра обнуляется, если игрок ловит фаербол лицом.
Сорри за мыльную картинку: именно так выглядит игра «в фантазиях» нашей нейросетки, а не на реальном движке
Качество записи тут ниже потому, что и энкодер, и декодер учились на картинках меньшего разрешения. Прослеживается аккуратность симуляции — есть кирпичные стены по бокам, через которые нельзя пройти, огненные шары летят по своей траектории, задаваемой в момент атаки. Однако и артефакты сложно не заметить: монстров то больше, то меньше, хотя по правилам их число должно строго увеличиваться.
Plot twist: пересаживаемся в «реальный мир»
Окей, ну вроде и обезьяна, и робот играют на равных (я старался, честно). Поигравшись с настройками, авторы исследования замерили качество: в 100 подряд идущих симулированных играх бот проживал в среднем 918 кадров (чуть больше 20 секунд). Теперь переходим к развязке — этого обученного бота, без любой промежуточной адаптации, заставляют играть в настоящую игру, а не симулятор. Теперь состояние среды формируется уже по известному сценарию: изображение из игрового движка обрабатывается энкодером в сигнал, с опорой на который (и на свою модель мира) бот делает предсказание, двигаться ли ему влево, вправо или замереть.
Сколько этот бычара смог продержаться не в своих мечтах, а на деле? Смог вывезти за базар? Ну, да — в реальной игре он продержался в среднем 1092 кадра (даже больше, чем в симуляции). Это большой скачок по отношению к другим методам обучения — на тот момент лучшим считался результат 820 кадров.
То есть, обучение в симуляции не то что просто кое-как перенеслось на настоящую «жизнь» (игру, которую мы симулировали), а сделало это с сохранением качества, да вдобавок еще и показало себя лучше других методов. Где-то тут полезно бы вспомнить, что новую модель SORA для генерации видео в OpenAI называют симулятором миров... но до этого мы ещё дойдем. А то вдруг окажется, что на примитивных игрушках это всё работает, а реальная-то жизнь она ж совсем не такая?
А пока вернёмся к примеру с машинкой. Может быть он вас не впечатлил? Тоже игрушка ведь. Ну едет и едет по симулированному треку, чего бубнить. Но что, если я скажу вам, что стартап Wayne, занимающийся разработкой автопилотов, ещё в далёком 2018 году опробовал метод на реальном транспортном средстве? И вот что у них получилось:
Кстати, вы обратили внимание на дождь? Не беда, если нет (ваш энкодер решил опустить эту деталь, не так ли?). Но вот что интересно: в этом случае модель училась водить в симуляторе, данные для которого были собраны исключительно в солнечную погоду. Но это не помешало обучить бота, который будет ездить в дождь! Сосредоточившись на том, что имеет отношение к принятию решений при вождении, система не отвлекается на отражения от луж или капли воды на стекле. Фактически, модель фокусируется на том, что имеет отношение к вождению, и это позволит применить подход к ситуациям, не встреченным во время тренировки.
Но не всё так радужно с симуляциями
Мы уже упомянули выше, что симуляции неидеальны: в Doom неправильно (непоследовательно) отображается количество врагов во времени. Но есть и куда более серьёзная проблема. Поскольку используемая модель мира является лишь приближением среды, то иногда она выдаёт состояния, которые не соответствуют правилам, задаваемым окружением. По этой причине бот, обучающийся в фантазиях, может наткнуться на неточность и начать её эксплуатировать. В примере с Doom это может выглядеть так:
То чувство, когда запустил в игре настолько «изи мод», что враги даже забыли тебя атаковать
Здесь бот нащупывает такое состояние, в котором симуляция не считает нужным запускать огненные шары в игрока — а значит, и умереть нельзя. И это может оказаться как просто мелким недостатком при переносе в реальную игру (или, тем более, мир), так и критической уязвимостью, приводящей к непредсказуемому непонятному поведению. Если мы будем учить автопилоты для реальных дорог в симулированной среде — лучше удостовериться, что пешеходы там не умеют телепортироваться на пару метров в сторону, когда возникает риск сбивания их машиной.
Причин неидеальности симуляции можно выделить две: недостаток данных для конкретной ситуации (из-за чего возникает «дырка» в логике симулятора) и недостаточная «ёмкость» обучаемой модели мира.
Про решение первой проблемы поговорим совсем вкратце (оно достаточно техническое, и не вписывается в рамки статьи). Один подход заключается в уменьшении предсказуемости среды в симуляторе, когда из одного и того же состояния игра может перейти в совершенно разные фазы на следующем шаге. Причём, можно управлять степенью случайности, находя баланс между реализмом и эксплуатируемостью (абсолютно случайную среду не получится обмануть — ведь она не зависит от твоих действий). Другое решение — привить обучаемому боту любопытство. Сделать это можно, например, если штрафовать его за то, что он слишком слабо меняет состояние среды (засиживается на месте), или же наоборот поощрять за новые свершения. Вы не поверите, но один из ботов в таком эксперименте начал залипать в аналог «телевизора», щёлкая каналы. В конце концов, мы не так уж сильно и отличаемся друг от друга. :)
Агент слева оказался настолько любознателен, что подсел на иглу телевидения. У бота справа телевизора в лабиринте попросту не было, поэтому он успешно выбрался. Вывод: если хотите спрятать сокровища — оставьте в лабиринте телевизор.
А что делать с ёмкостью модели? На данный момент известен лишь один гарантированный способ, который даст результат при любых обстоятельствах: масштабирование. Это означает, что мы можем увеличить размер нейросети, пропорционально увеличить размер корпуса тренировочных данных, и как следствие потратить больше ресурсов на обучение.
Все остальные способы, хоть иногда и могут сработать (взять более чистые данные/выбрать другую архитектуру модели/и т.д.), но имеют свои ограничения, а главное — могут перестать работать. Для больших нейронных сетей (в том числе и языковых моделей вроде ChatGPT) уже пару лет как вывели эмпирический закон, который показывает, насколько вырастет качество при увеличении потребляемых при тренировке ресурсов. Это называется «закон масштабирования».
Нужно БОЛЬШЕ ВИДЕОУСКОРИТЕЛЕЙ!
И масштабирование сейчас — одна из самых главных причин, по которой вы всё чаще и чаще в последнее время слышите про AI, и почему наблюдается рост качества. Если раньше модели обучали на одном, ну может на двух серверах в течении пары недель, то теперь компании арендуют целые датацентры на месяцы. По сути, появился способ закидать проблему шапками, покупай больше видеокарточек — и дело в шляпе шапке. Это одновременно и хорошо, и плохо — с одной стороны мы точно знаем, что можно получить нейросеть получше, а с другой — она будет стоить дороже.
Вернёмся к ранее упомянутому стартапу Wayne, продолжающему заниматься беспилотными автомобилями. Они всё ещё фокусируются на создании моделей мира как вспомогательном инструменте обучения алгоритмов (прямо как OpenAI). В прошлом году они представили свою модель GAIA-1, которая... тоже была обучена предсказывать будущие кадры в видео. На видео ниже вы можете увидеть сравнение ранней модели, обученной летом 2023 года, с более поздней, на которую потратили существенно больше ресурсов («отмасштабировали»).
Да, оба видео сгенерированы почти полностью, реальным является лишь первый кадр, общий и для левой, и для правой демонстрации. Однако здесь мы наблюдаем реконструкцию с использованием декодера, а не входное изображение — поэтому уже на первой секунде заметна разница. Во-первых, вдалеке виднеются светофоры — а значит у модели мира будет задача их симулировать. Во-вторых, детали вроде машин и деревьев стали намного чётче. В-третьих, улучшилась согласованность последовательно идущих кадров (посмотрите на «плавающие» формы машин справа в самом начале). Подход один и тот же, архитектура модели и принцип обучения те же — а результат качественно лучше.
Такой продвинутый симулятор может показывать и более сложные сцены, а не просто езду по прямой. Следующий пример демонстрирует, что модель мира может помочь симулировать взаимодействие с другими участниками дорожного движения. В варианте слева белый автомобиль дает задний ход, уступая нам дорогу. Во втором развитии схожего сценария (и оба — в визуализированной «фантазии» модели!) мы уступаем дорогу и позволяем выполнить разворот — при этом наш автомобиль замедляется. Здесь оба видео порождены одной и той же моделью, разница лишь в выборе развития событий (та самая случайность в модели мира).
Вуаля, теперь можно обучать модель автопилота в симуляции, порождаемой «фантазией» модели мира, без выезда на реальную дорогу с риском для водителей, и при этом инсценировать любые желаемые сценарии. Однако нейронке есть куда расти: на её обучение потратили ресурсов в 100 раз меньше, чем на одну из лучших доступных языковых моделей LLAMA-2-70B от META (ex-Facebook, на территории РФ признана экстремистской), и приблизительно в 2000 раз меньше, чем (по слухам) OpenAI потратили на GPT-4 — самую лучшую Large Language Model (LLM) на данный момент. Представляете, какой потенциал для улучшений? (Конечно представляете — просто посмотрите на OpenAI SORA!)
Единственная разница между сгенерированными видео — количество вычислительных мощностей, потраченных на обучение SORA. На демонстрацию справа суммарно было использовано в 32 раза больше ресурсов, чем на жутенькую The Thing слева.
Есть ли модели мира у LLM?
Ну, раз уж мы заговорили про большие языковые модели, то давайте сделаем отступление и попробуем разобраться: а есть ли модель мира у них. С одной стороны, зрением они не обладают, лишь читают текст в интернете, а с другой — ну что-то же они должны были выучить? Сразу после этого блока мы перейдем к модели SORA, с которой всё и начиналось, и в целом вы можете пропустить эту часть без потери смысла — но мимо вас пройдёт столько всего интересного!
Примерно 95–98% ресурсов тренировки больших языковых моделей тратится на обучение задаче предсказания следующего слова в некотором тексте. Под «некоторым» здесь подразумевается почти любой текст на сотне языков, доступных во всём интернете. Там есть и Википедия (как база знаний и фактов), и учебники по физике, описывающие принципы взаимодействия объектов (включая силы гравитации), есть детективные истории, и много чего вообще. Каждый раз модель смотрит на часть предложения и угадывает следующее слово. Если она сделает это правильно, то обновит свои параметры так, чтобы закрепить уверенность в ответе; в противном случае она извлечет уроки из ошибки и в следующий раз даст предсказание получше.
Префиксы — это примеры некоторых контекстов из интернета. Далее идут потенциальные варианты продолжения (то есть следующего слова, которое нужно предсказать). В последней колонке определен тип задачи (классификация тут условная, а не строгая и однозначная)
Давайте посмотрим на примеры в табличке выше. Чтобы предсказать следующее слово для каждого из префиксов, нужно либо обладать конкретными знаниями, либо уметь рассуждать. Иногда это может быть двумя сторонами одной и той же монеты: например, можно запомнить базовую таблицу умножения, но также через неё понять и тысячи более сложных примеров (которые в этой таблице не встречались), и затем начать корректно применять принципы математических операций.
OpenAI в этом плане двигались постепенно — первые проверки гипотезы о том, что языковая модель при обучении строит модель мира, помогающую ей успешно предсказывать следующее слово, были ещё до GPT-1. Исследователи предположили, что если взять достаточно большую по тем временам модель, и обучить её на 40 Гигабайтах отзывов с Amazon (при этом не показывая, какой рейтинг оставил пользователь — только текст), то скорее всего нейросеть сможет сама «изобрести» внутри себя концепцию сентимента. Иными словами, она сможет определять, является ли отзыв позитивным или негативным. С учётом того, что в явном виде мы никак эту информацию не сообщаем — было неочевидно, получится ли разобраться со столь сложной и абстрактной вещью, которая существует только у нас в голове: сентимент текста. Ведь это не природное явление, не закон физики — это то, как мы, люди, придумавшие свои искусственные языки, воспринимаем информацию.
Сказано — сделано. В OpenAI обучили модель, а затем рассмотрели её латент (да, там тоже модель сначала сжимает текст в понятные ей сигналы, а затем переводит его обратно в текст) под микроскопом. Так же, как мы пытались крутить 15 чиселок латента на гифке с игрушечной трассой, исследователи пытались найти такой параметр (из 4096 разных, если вам интересно), который был бы связан с сентиментом. И, как уже должно быть понятно, нашли!
Но как для текста можно понять, что вот, скажем, семнадцатая цифра в нашем латенте отвечает за сентимент? Пробуется два способа: это анализ зависимости значения от входной последовательности (текста отзыва), и сентимента генерируемого текста (= «фантазии» модели) от этого же значения. Мы как бы отвечаем на два вопроса: «Правда ли значение предсказуемо меняется из-за отзыва?» и «Правда ли, что модель опирается на это значение, то есть, сгенерированный отзыв меняется из-за значения в латенте?»
Сначала про первое. Давайте возьмём тысячи отзывов, но уже не с Amazon, а с американского аналога Кинопоиска, IMDB. Для каждого из них определим, являются ли они позитивными или негативыми. Затем будем подавать эти отзывы в модель (грубо говоря использовать энкодер для получения латента, хоть в языковых моделях это устроено чуть иначе) и смотреть, как меняется найденная цифра. Можно сделать визуализацию в виде гистограмы, на которой отзывы с разным сентиментом окрашены в разные цвета.
Горизонтальная шкала показывает, как негативные (голубым) и позитивные (оранжевым) отзывы распределились по значениям найденного нами внутри модели параметра, отвечающего за сентимент.
По графику видно, что для негативных отзывов модель зачастую показывает значения ниже нуля (аналог с визуализацией гоночной трассы — один ползунок выкручен влево), а для позитивных — выше. И «горбики» распределений почти заметно отличаются. Те отзывы, что попадают на пересечение, скорее всего имеют смешанный сентимент: может, там фильм и хвалят, и ругают? Таким образом, мы можем сказать, что состояние модели меняется в зависимости от сентимента конкретного отзыва — становится больше или меньше.
Но опирается ли нейронка на эту модель мира? Считается ли конкретно этот латент важным во время запуска симуляции (в которую мы можем подсмотреть уже не визуально, а по сгенерированному тексту)? Давайте зафиксируем все остальные значения латента (через установку одинакового начала отзыва), и сначала сгенерируем отзыв о фильме, указав большое положительное значение, а затем — отрицательное. По идее, если для модели этот признак важен, мы ожидаем увидеть очень положительный, хвалебный отзыв, а за ним — негативный.
Результаты генерации. Зелёным выделены позитивные части отзывов, красным — негативные.
И ровно это учёные и обнаружили — при генерации ответ модели существенно меняет свой окрас в зависимости от лишь одной цифре в латенте. Но главная фишка в том, что мы не давали модели никакого понимания, что такое сентимент, и какими словами он выражается — вообще ничего, кроме кучи текстов. И всё же для модели мира оказалось удобнее (выгоднее?) кодировать данные так, чтобы сентимент легко разделялся, и им можно было управлять.
Этот игрушечный пример послужил толчком для OpenAI к развитию идей в модели GPT-1, а GPT-2 и 3 были дальнейшим масштабированием: больше модель, больше текстов, и как следствие более полная картина мира, выработанная внутри нейросети. Поскольку теперь кроме отзывов мы показываем тексты вообще про всё на свете, от комментариев на Дваче до учебника по физике, то модель выучивает огромное количество вещей, не только простой сентимент.
Очень сложно оценить наперёд, насколько комплексной и многогранной будет модель, и что будет зашито в её модель мира. Бывают комичные случаи: знакомьтесь, Ян Лекун, лауреат премии Тьюринга (аналог Нобелевки в компьютерных науках) за вклад в область нейронных сетей. За это его ещё называют одним из трёх крёстных отцов искусственного интеллекта. В настоящее время является вице-президентом по AI в компании META. Кажется, уж он-то точно хорошо разбирается в предмете?
Те самые трое крёстных отцов AI (Ян Лекун справа). Вообще говоря, к настоящему моменту они между собой немного все разосрались, но это уже совсем другая история...
В подкасте Лексу Фридману от 23 января 2022 года Ян говорил: «Я не думаю, что мы можем научить машину быть разумной исключительно на основе текста, потому что я думаю, что объем информации о мире, содержащейся в тексте, ничтожен по сравнению с тем, что модели нужно знать. Вы знаете, что люди пытались сделать это в течение 30 лет, верно? <...> Я думаю, что это в принципе безнадежно, но позвольте мне привести пример. Я беру предмет, кладу его на стол и толкаю стол. Для вас совершенно очевидно, что предмет будет двигаться вместе со столом, верно? Потому что он на нём лежит. Но в мире нет текста, объясняющего это! И поэтому, если вы тренируете машину, настолько мощную, насколько она может быть, например, ваш GPT-5000 или что-то еще, она никогда не узнает эту информацию. Этого просто нет ни в одном тексте».
Менее чем через год вышла ChatGPT (GPT-3.5), которая...правильно отвечала на этот вопрос. Ну ладно, ошибся дядька, наверное, где-то в учебниках физики был схожий пример. Когда в Твиттере ему за это предъявили, то он придумал новую мега-супер-сложную задачку. Сейчас-то наверное подготовился? Не стал щадящие примеры выбирать? Он выбрал задачку с шестерёнками... которую модель решила сходу, сразу же.
Тогда через месяц он придумал усложнение: «7 стержней равномерно распределены по кругу. На каждом стержне установлена шестерня, так, что она находится в сцеплении с шестернями слева и справа. Шестерёнки пронумерованы от 1 до 7 по кругу. Если бы третья шестерня была повернута по часовой стрелке, в каком направлении вращалась бы седьмая?». Родители с детьми в начальной школе уже словили флешбеки от домашки по физике, но теперь они хотя бы узнают, что... GPT-4 и на такой вопрос даёт правильный ответ.
На размышление даётся 30 секунд. Пишите в комментах, кто оказался умнее — вы или GPT-4?
GPT-4 вообще удивила многих. Вот как думаете, можно ли ответить на такой вопрос к следующей картинке, не понимая физику нашего мира, не моделируя взаимодействия объектов? Что произойдет с мячиком, если перчатка упадёт?
GPT-4 может принимать текст вместе с изображением, и умеет отвечать на вопросы, требующие визуальной информации. Тут модель правильно предсказала, что мячик подлетит наверх.
Позиция Яна не в том, что модели так не могут в принципе — он лишь не верил, что сложным физическим описаниям можно научиться либо просто по тексту, либо что такой текст вообще существует. И был не прав. Этот пример призван показать, что не стоит загадывать наперёд, что не смогут делать системы завтрашнего дня.
Конечно, модель могла не «понять» физику и уж тем более не строить модель мира, а быть обученной на таких же или уж очень похожих задачах. Однако я уже со счёта сбился от количества примеров с вопросами про очень специфичные и даже закрытые штуки, которые публикуют пользователи, но для которых, тем не менее, GPT-4 даёт адекватные ответы. Один, два, три раза — можно списать на запоминание, но были случаи...
И даже у столь мощной GPT-4 модель мира всё еще не идеальна, и то и дело приводит к глупым ошибкам. «Все модели неправильны, но некоторые из них полезны», помните?
OpenAI SORA: эмулятор Вачовски или симулятор мира?
Наконец, переходим к десерту. Такое длинное вступление было необходимо для того, чтобы наглядно продемонстрировать читателю крайне важные в контексте новой модели OpenAI тезисы:
Модели мира помогают агенту принимать решение с учётом информации о возможном будущем
Для того, чтобы успешно предсказывать будущее состояние, важно понимать лежащие в основе формирования среды процессы
Модели мира строят предсказания не в привычном нам виде, а в понятном им мире преобразованных сигналов (латентное пространство)
Мы можем заглянуть внутрь, но реконструкция не будет идеальной
Бот, обученный в симулируемой моделью мира сцене, может проявлять навыки и в реальной среде
Масштабирование модели всегда приносит улучшения, при этом многие из них неочевидны и сложнопредсказуемы
И вот теперь, когда мы разобрали концепцию моделей мира и посмотрели, для чего они могут использоваться, мы будем смотреть на примеры и пытаться понять, а в чём же именно ВАУ-эффект модели SORA. Она, как и GPT-4, выработала внутри себя какую-то модель мира, помогающую предсказывать следующий кадр в огромной разнообразной выборке всевозможных видео. Рендеринг финального изображения — это лишь реконструкция того, что предсказывает модель (потому что мы смотрим на это через призму декодера; хоть он и достаточно мощный, но имеет свои недочёты).
Пример, которым OpenAI решили похвастаться и вывести в начало своего блогпоста, вы уже видели в превью статьи. Это одноминутное FullHD @ 30 к/сек. видео, сгенерированное по текстовому запросу (промпту): «Элегантная женщина идет по улице Токио, озаренной теплым светом неоновых огней и анимированных городских вывесок. На ней черная кожаная куртка, длинное красное платье и черные ботинки, в руке черная сумочка. Она в солнцезащитных очках и с красной помадой. Шагает уверенно и непринужденно. Асфальт улицы мокрый, отзеркаливающий яркие огни. Вокруг ходит множество пешеходов.»
Во-первых, сложно не заметить точнейшее соблюдение всех деталей промпта в сгенерированном видео. Даже если сильно захотеть — разве что субъективные «элегантная женщина» и «шагает уверенно» можно подвергнуть сомнению, но, по-моему, модель справилась отлично. В этом заслуга специального приёма, использовавшегося OpenAI при разработке их предыдущей модели, DALL-E 3 (делает генерацию изображения по текстовому запросу, как MidJourney).
Так как зачастую текстовые подписи к картинкам и роликам в интернете очень короткие и несут лишь поверхностное (а иногда и неточное) описание происходящего, исследователи предложили применить умницу GPT-4 для генерации более подробных описаний. Для этого видео нарезалось на кадры, и языковая модель получала команду создать детальные подписи к происходящему в нескольких подряд идущих изображениях. Текстовые комментарии выходят не в пример длиннее, с большим количеством нюансов, поэтому обученная text-2-image или text-2-video модель гораздо охотнее обращает внимание на запрос, пытаясь соответствовать каждой его частичке. Даже лучшие платные аналоги моделей еле-еле оперируют двумя, самый край тремя предложениями — а тут мы нагрузили деталей на 5 строчек! Для DALL-E 3 процент синтетических текстов был 95%, вероятно, в SORA плюс-минус такой же.
Во-вторых, общий визуал существенно превосходит ожидания от моделей на данный момент. В Твиттере даже шутят, что «это был невероятный год прогресса AI... за один час». Тут сложно не согласиться, особенно если последнее демо, что вы видели — это Уилл Смит со спагетти из начала статьи. Но в сцене, кажется, учтено почти всё. Если заведомо не знать, что это генерация и не ждать подвоха — сразу и не скажешь. Освещение, отражения, толпа людей, переход на ближний план с детализацией текстуры кожи, плавность перемещения камеры с соответствующим изменением углов обзора на объекты в фоне. А те объекты, что пропадают из поля зрения на несколько секунд (люди сзади, синий дорожный знак на стене справа), возвращаются без изменений — такой консистентности во времени раньше и не мечтали добиться!
Моя модель мира предсказывает, что этот карандаш пропадёт из поля зрения через пару секунд. И... он испарился!
В-третьих, давайте поговорим про недостатки. Я пересмотрел видео около десятка раз, и самые заметные изменения происходят, если сравнивать начало и конец. На секундах с 55 по 59 вы можете заметить, что: 1) из рук пропадает чёрная сумочка; 2) левый лацкан куртки стал аномально большим (и даже испортил симметрию), да и правый прибавил в размере; 3) на красном платье на груди появляются чёрные пятна; 4) меняется причёска, появляется завихрение волос. Есть и комичные проблемы — обратите внимание, как левая нога превращается в правую (и наоборот) на секундах 15 и 29. И как после такого заснуть? А на секундах 16–17 ноги группы людей слева (парень, проходящий мимо двух азиаток в масках) будто бы окутаны водным шаром и очень расплывчаты.
Важно отметить, что часть этих проблем наверняка лежит на неидеальности реконструкции декодера, а часть — на проблемах с моделью мира. А может быть, собака зарыта где-то ещё, мы не знаем. Дело осложняется тем, что ни у кого, кроме OpenAI и их доверенных лиц, нет доступа к нейросети, чтобы это можно было проверить. Помните, как в эксперименте с числом в латенте, влияющим на генерацию отзыва? Тогда исследователи могли однозначно проверить, что будет, если его дёргать туда-сюда, здесь же подобного анализа не производилось. И всё же сделаю смелое предположение и скажу, что пронумерованные проблемы из абзаца выше скорее всего являются недостатками модели мира (исчез объект? поменялась форма чуть ли не самого крупного объекта в кадре? как так?!), а вот проблемы с отображением ног — уже реконструкции (потому что энкодер и декодер не посчитали нужными кодировать информацию о двух ногах, находящихся рядом).
Подобный артефакт можно было наблюдать на одном из видео выше, в симуляторе для автопилота. Там сами машины и окружение были достаточно чёткими, а вот диски колес как будто бы не крутились, и были очень шумными. Вероятнее всего, при обучении модель сочла, что куда выгоднее кодировать такие признаки, как размер авто, направление его движения, скорость, а вот насколько повёрнуты колёса в каждый момент времени уже можно подзабить — ведь это не так важно, и мы, люди, тоже не обращаем внимания при вождении на этот шум. Помните, что модель мира предсказывает будущее состояние, но не вся информация одинаково полезна для этой цели.
А так как информация не присутствует в модели мира и латенте, то и декодер не может грамотно восстановить картинку.
Но с этим связана и неожиданная хорошая новость! Раз модель мира не уделяет внимание такой детали, то и несоответствие картинки из декодированного видео настоящему миру не так критично. Ведь энкодер при сжатии видеопотока в латент для обработки (или симуляции) также опустит эти детали! В итоге, латент для реальной картинки и для «симулированной» будет почти одинаковым (хоть проблемы в реконструкции заметны невооружённым глазом). А значит наш бот, играющий в симуляторе, не заметит подвоха, и сможет потенциально оперировать в реальном мире. То, что может быть критично для создателей видеоконтента в силу неидеальности визуала, абсолютно не мешает основной цели модели SORA!
Так, и мы опять не влезли в ограничение Пикабу по количеству символов на один материал. :) Заключительная часть статьи находится вот здесь (осталось совсем немного потерпите!).