

Раритет: Электроника МК-90/МК-92

МК90

МК92
Показать полностью
1
Эволюция CRM систем от пещеры до современного офиса
CRM-системы, или системы управления взаимоотношениями с клиентами, прошли долгий путь от своего зарождения до современных решений, которые мы видим сегодня в офисах. Давайте рассмотрим эту эволюцию шаг за шагом.
1. Пещерная эра: В давние времена, когда бизнесы только начинали развиваться, пещерные люди использовали примитивные методы учета и взаимодействия с клиентами. Они могли хранить записи о своих клиентах и транзакциях на стенах пещер или на каменных табличках.
2. Ручное управление: Со временем люди начали использовать более удобные способы управления клиентскими отношениями. Где-то в середине XX века, предприниматели стали вести записи вручную, создавая карточки клиентов и записывая информацию о каждом клиенте отдельно.
3. Механические устройства: С развитием технологий появились первые механические устройства для учета и управления клиентскими данными. Например, появились специальные картотечные машины, на которых можно было записывать и хранить информацию о клиентах.
4. Эра компьютеров: С развитием компьютеров и электроники начали появляться первые программы для управления взаимоотношениями с клиентами. Началось использование электронных баз данных, где можно было хранить информацию о клиентах и вести учет их операций.
5. Появление CRM-систем: В конце 20 века появились первые настоящие CRM-системы, предназначенные для автоматизации управления взаимоотношениями с клиентами. Они предлагали более широкий функционал, включая хранение и анализ данных, автоматическую обработку заказов, управление продажами и маркетингом.
6. Облачные CRM-системы: В последние годы CRM-системы перешли на новый уровень — облачные сервисы. Теперь компании могут использовать CRM-системы, которые работают через интернет и предоставляют доступ к данным из любого места, где есть подключение к сети. Это упрощает работу и позволяет легко распределить доступ к данным между разными отделами и сотрудниками.
7. Интеграции и автоматизация: Современные CRM-системы предлагают множество интеграций с другими инструментами и услугами, такими как электронная почта, социальные сети, VoIP и др. Они также предлагают возможности автоматизации задач, например, отправку писем или уведомлений клиентам, создание отчетов и анализ данных.
Таким образом, эволюция CRM-систем привела нас к современным облачным решениям, которые значительно упрощают управление взаимоотношениями с клиентами и повышают эффективность бизнеса.
Показать полностью


ИТ-выскочки, о которых вы не слышали. Как локальные предприниматели дали прикурить Google, Amazon и другим межународным гигантам
Google захватил мировой рынок поиска, Amazon подмял под себя весь ecommerce, а местным онлайн-кинотеатрам сложно тягаться с Netflix? Чаще всего - да. Однако, в некоторых странах и регионах локальные tech-компании отвесили смачного пинка глобальным корпорациям. Сегодня разберем самые яркие примеры.

Основатели японской Rakuten (про неё ближе к концу статьи) отмечают запуск своего портала 25 лет назад. Ну либо это просто какие-то японцы празднуют днюху в офисе, кто ж Google-картинки проверит.
Еще до санкций, в условиях гораздо более открытых границ российского рынка для западных компаний, в России родился и укрепился свой технологический лидер - Яндекс. Все мы знаем эту компанию, все мы пользуемся её сервисами. От такси и маркетплейса до музыкального стриминга и рекламных систем. Теперь вот и свой ИИ активно развивают. Но начиналось все, конечно, с поискового движка. Который даже во времена самой мощной глобальной экспансии Google неизменно сохранял за собой высокую долю на российском рынке.
Однако пример нашего Яндекса - далеко не единcтвенный. В мире есть немало стран, где в условиях конкуренции с муждународными титанами появились и окрепли собственные технологические империи, крепко вцепившиеся в локальный ecommerce, транспортную агрегацию, поиск, стриминг и другие важные для человечества занятия. Более того, порой "местные чемпионы" становились настолько крутыми, чтобы выкидывали эти самые Гуглы и Амазоны пинком под их технологический зад.
Итак, в этой статье я расскажу про самые яркие примеры таких компаний. Разберемся, как они появились и развивались, какие продукты предлагают пользователям, и как конкурируют с глобальными лидерами. А также попытаемся докопаться, за счет чего им это удалось.
На текущий момент я собрал штук 10-12 таких компаний. Поэтому, материал разделю на несколько частей. Сегодня разберем первые 4 из списка (фокус будет на две крайне самобытные страны с мощными технологиями - Южную Корею и Японию), а потом, если формат зайдет и вы влепите изрядное количество лайков, сделаю еще один или два выпуска.
Небольшое примечание. Безусловно, целая россыпь локальных IT-колоссов в Китае. Но Поднебесную мы сегодня трогать не будем. У них там Великий файрволл, обеспечивающий тепличные условия для местного диджитала. Поэтому, хотя это нисколько не умаляет достоинств китайского tech, все же пример Китая для нас не совсем актуален. Про китайский IT у меня есть отдельная статья - если интересно, welcome (точнее, хуан йин).
Еще одно небольшое примечание. У подавляющего большинства азиатских tech-гигантов есть особенность - их рисом не корми, а дай склеить все свои сервисы, приложения и прочие свистоперделки в единый огромный суперапп. Кто-то (например, китайцы) без супераппов вообще жить не могут. Другие азиатские страны могут обойтись и без них, но все равно обожают взять все свои такси, екомы, мессенджеры и стриминги и соединить их в один огромный драконзорд. Совсем каррикатурный сценарий - это вшить все это безобразие внутрь мессенджера или соцсети.
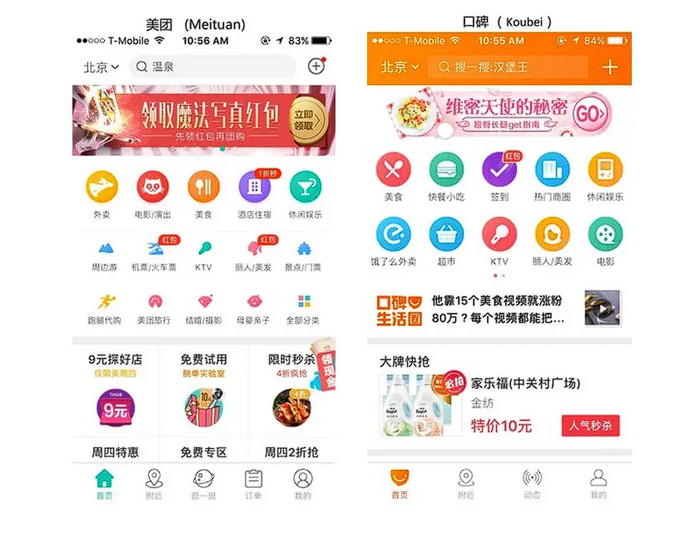
Например, вот так выглядят главные вкладки китайских экосистем Meituan и Koubei от Alibaba. Для европейского взгляда это UX-ад с конями, но азиатам (особенно китайцам) норм.
Итак, погнали разбирать компании:
Корейская экосистема с привкусом какао
Вообще, я хотел начать свой анализ с Северной Кореи. Но товариш Ким не пускает мой роутер в местный кванмён, а сервер в Пхеньяне слегка недоступен в сервисах, которые с 1 марта нельзя продвигать и упоминать в РФ (кстати, им уже придумали безопасный эвфемизм, вроде "нельзяграма"?).
Так что, начну с Кореи Южной. У этой страны есть целых две мощные tech-компании - Kakao и Naver. Если проводить аналогию (очень грубо), то представьте, что весь Яндекс разделили на две отдельные структуры - в одну засунули все такси, доставку и остальные транзакционные сервисы, а другой отдали поиск, порталы, погоду и прочие информационные продукты. Так вот, Kakao был бы похож на первую, а Naver - на вторую.
Начну с Kakao. История у них непростая и уходит аж в прошлое столетие. Еще в 1998 появилась компания Kakao Entertainment, которая производила фильмы, клипы и прочий контент для телека и зарождающегося интернета. Примерно в то же время местная IT-компания NHN Corp запустила свой мессенджер NHN Chatroom. Также в истории участвовал телеком-гигант Daum, у которого был свой поисковый движок и популярный веб-портал.
Так вот. В 2000-х в результате нескольких хитросплетенных слияний и поглощений вся эта пестрая топла преобразовалась в единую компанию Kakao. А в 2010 году мессенджер NHN стал KakaoTalk, которым теперь активно пользуется каждый кореец.
Согласно заветам азиатских цифровых сервисов, Kakao стал активно развивать дополнительный функционал прямо внутри мессенджера. Помимо обмена сообщениями и групповых чатов, в Kakao вовсю процветал мобильный гейминг. В 2010 г. был запущен "корейский Инстаграм" (по прежнему запрещенный в РФ) под названием KakaoStory. Потом появился KakaoBank - мобильный платежный сервис. Еще позже, в 2015 г., появилось KakaoTaxi - вкладка для вызова такси внутри мессенджера, который уже активно превращался в суперапп.
Сейчас Kakao - это огромная экосистема, где помимо описанных выше сервисов есть собственная картография и навигатор, видео- и музыкальный стриминги, лайфстайл-сервисы и блок примочек для бизнеса. Сам мессенджер KakaoTalk остается популярнейшим каналом коммуникации в стране, им регулярно пользуются более >90% корейцев.
Отдельно хочу отметить два интересных решения:
Первое - это Kakao Loyalty. Компания запилила собственную программу лояльности, в которую максимально быстро и легко может встроиться любое предприятие - хоть крупная ритейловая сеть, хоть палатка с раменом от дядюшки Кима (но не товарища Кима, этого вряд ли пустят).
Проще говоря, представьте условный Яндекс Плюс или Сбер Спасибо, к которому может в пару кликов подключиться любой бизнес. Достаточно лишь принимать оплату через KakaoPay (который, как мы помним, есть у каждого покупателя внутри KakaoTalk), и баллы лояльности начинают капать покупателю прямо в любимый мессенджер. Удобно и бесшовно.
Второе - Kakao Friends. Это вообще локальный мем. Сейчас каждый из нас может отправлять в Telegram миллионы самых разных стикеров. Но давайте вспомним времена, когда все общались Вконтактике (еще в том, старом). Там тоже были стикеры, но их создавали не пользователи, а сама площадка. Их ассортимент был ограничен, а еще они были платные. Kakao в этом плане пошел еще дальше.
В 2012 году мессенджер запустил 8 авторских стикеров, вот таких:

Мне кажется, или крот слева (да, это именно крот, я загуглил) напоминает Самуэля Л Джексона из Криминального Чтива? Впрочем, у гуся вообще такое лицо, будто мне не стоит про него шутки шутить.
Со временем эти стикеры стали популярны в народе, и для них начали делать свой ЛОР, всячески его коммерциализируя.
В Корее и некоторых других азиатских странах появились парки развлечений и тематические кафе Kakao Friends. С персонажами стикеров начали запускать сериалы, телешоу и детские мультики. Модные корейские бренды начали дропать с ними лимитки. А корейские детишки радостно бегают с соответствующими игрушками (монетизация на детском мерче detected). Небось, даже Crocs свои джиббитсы с ними выпустил (это мое предположение, не проверял - но если не выпускали, то точно стоит).
В результате KakaoFriends не просто разнообразили общение в мессенджере, но и стали отдельным полноценным каналом монетизации для холдинга. Про узнаваемость бренда и клиентскую лояльность и говорить не приходится. По-моему, абсолютно удивительный продуктовый пример, я подобного больше нигде не видел. Бренды, берите на вооружение, только потом не забудьте отстегнуть мне процентик за идею.

Во вселенной KakaoFrineds даже есть собственные спин-оффы и сольники. Например, у льва Райана (второй слева на предыдущей картинке) есть собственная сеть кафе. И вообще, там целая империя мерча - кафе, рестораны, детские комнаты, что угодно!
Сладенький кусочек кимчи для северокорейских хакеров
Вторая главная айти-компания Кореи - это Naver. Если кратко, то Naver - это крупнейший поисковик страны, обрабатывающий львиную долю всех поисковых запросов на корейском языке. В 1999 г. трое студентов из Сеульского университета запустили свой поисковых сервис, уже через год выкатив мобильную версию. В отличие от веселого названия "'Kakao'', фаундеры Naver не стали экспериментировать с неймингом. Naver - это акроним от "Navigation and Verification''.
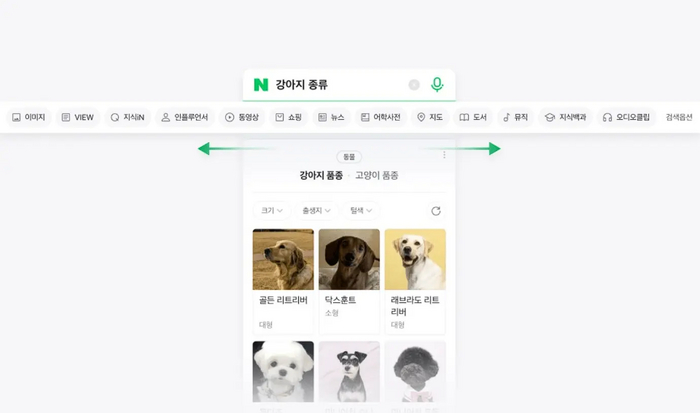
Скриншот нынешнего интерфейс Naver. Не знаю, почему у какого-то корейца на картинке собачки в результах. Надеюсь, это не баннерная реклама тематического кулинарного портала от Naver!!
В отличие от Kakao, который в своем развитии тяготел к ecommerce и прочим транзакционным бизнесам, Naver сразу сфокусировался на работе с информацией. Еще в бородатые годы компания запустила свой мессенджер Naver Chat, который позже оброс социальными механкиами - например, соцсетью с фокусом на знакомства и нетворкинг под названием Naver Personal. Также Naver запустил базу знаний Knowledge iN (сейчас известна как Naver Encyclopedia - корейский аналог Википедии). Чуть позже еще появился картографический сервис и навигатор, здесь наметилась явная конкуренция с Kakao.
Также у Naver есть словари, погода, игровые сервисы, новостные порталы, почтовый клиент, тематические контентные разделы вроде Naver Health, Naver Fashion и что только не. Монетизируется все это через рекламные системы, которых Naver тоже наплодил в достатке.
Компания экспериментировала и с транзакционными сервисами - например, запустила музыкальный стриминг Naver Music и собственную доставку продуктов из магазинов. Но все равно, фокус корпорации всегда был именно на сервисах индексации, информационных порталах и картах.
Однако, главный бизнес Naver - это именно поисковик. Долгое время Naver безоговорчно лидировал в стране, особенно в сегменте запросов на корейском языке, с чьей семантикой его движок работал гораздо лучше того же Google. В 2010-х доля Naver на корейском рынке поиска уверенно держалась в районе 70%, а в 2016 г. и вовсе приблизилась к 90%. Однако потом стала стремительно падать... К 2021 доля компании упала до 50%, а к 2023 и вовсе до 32%. При этом доля Google на рынке Южной Кореи сейчас уже более 60% и продолжает расти. Почему же так вышло?
Помимо очевидных причин, вроде рыночной мощи Гугла, его ресурсов, недавних инвестиий в ИИ (Naver, кстати, тоже здорово погрузился в ИИ) и прочего подобного, нужно выделить один интересный нюанс:
Есть мнение, что в какой-то момент Naver переборщил с приоритизацией своих сервисов в выдаче. Корейцы начали замечать, что если что-нибудь загуглить (или занаверить?) в поисковике Naver, то с неиллюзорной вероятностью первые Х результатов будут вести на другие сервисы компании - например, тематические и новостные порталы. К тому же, Naver начал выводить свои сервисы и на главную страницу поиска, серьезно утяжеляя интерфейс и засоряя рабочую область всяческим мусором.

Интерфейс Naver в 2017 г. Думаю, им стоило выкинуть в помойку всё, кроме верхней поисковой строки и парочки фильтров (сейчас к этому пришли, но слишком поздно). Кстати, мне одному это напоминает типичный российский информационный портал в вакууме?
Google же наоборот шел по пути упрощения и расчищения UX, а также более активно выплевывал независимые сторонние результаты, делая поисковую выдачу более вариативной и полезной.
Уважаемые продакты, юиксеры и руководители российских информационных сервисов, фиксируйте этот фейл в свои ноушены и не повторяйте корейских ошибок!
Заканчивая с Южной Кореей, хочется рассказать про одну интересную особенность местной картографии. Как известно, у Южной Кореи есть не очень дружелюбный к ней северный сосед. А из КНДР можно вообще на изи дострелить ракетой до Сеула, Инчона и многих других корейских городов (конечно, если оказия все же случится, не дай Бог).

А еще южнокорейское руководство отлично знают про хакеров из КНДР. Да, я представляю себе северокорейских хакеров именно так - напротив каждого сидит собственный Ким Чен Ын и контролирует, сколько проклятых капиталистов товарищ успел взломать.
Так что, Южная Корея очень трепетно оберегает свои картографические данные, особенно расположение самых важных объектов. Поэтому несколько лет назад Google не смог договориться с корейцами о доступе к их картографии. Говорят, что ЮК требовала тотально зацензурировать данные о важных объектов, и Google на такое не согласился. То же самое с Apple Maps. Так что, в Южной Корее карты Google и Apple работают лишь частично - карты вроде бы открываются, геолокация отслеживается, но маршрут по какой-нибудь заковыристой дорожной развязке Сеула вы построить в них не сможете. Я делал про это пост у себя в канале, там много комментов (в т.ч. от подписчиков из Кореи), гляньте, если интересно.
Несмотря на то что Naver слегка растерял былую мощь на рынке поиска, компания все еще остается важнейшим держателем данных южнокорейских пользователей. Так что, не мудрено, что сумрачные кибергении товарища Кима обожают атаковать Naver.
Мессенджер против землетрясений
Отдельно расскажу про онлайн-платформу Line. Это дочерний проект корейского Naver, который сначала был запущен как мессенджер, но постепенно оброс собственной соцсетью, платформой для мобильного гейминга, платежным сервисом и такси-агрегатором.
Несмотря на корейское происхождение, свою главную аудиторию сервис снискал в соседней Японии, где быстро стал самым популярным мессенджером с активной аудиторией почти 90 млн человек.
Но самая важная фишка Line в другом. Изначально приложение запускалось корейским холдингом в качестве инструмента, с помощью которого жители сейсмоактивной Японии могли бы удобно и эффективно контактировать с семьей в ситуации природных катастроф (Line запустили в 2011 г. сразу после мощного землетрясения у острова Хонсю).

У Line есть весьма продвинутый встроенный фунционал для безопасности во время природных бедствий. Сам мессенджер заявляет аж 8 таких фич, некоторые из которых довольно необычные.
Например, каждому пользователю предлагается активировать встроенные информационные оповещения, которые при случае звонко высвятятся на главном экране. К тому же, мессенджер отслеживает геолокацию, и при землетрясении или другой напасти автоматически создает чат, в который сам добавляет незнакомых юзеров с одинаковым или близким местоположением. Там они могут обменяться критически важной информации и помочь друг другу. При этом, в таком чате можно сделать ИИ-выжимку основной инфы - мессенджер сам проанализирует беседу чата и выдаст ключевое в отдельном окне сверху (ну, чтобы не пришлось лихорадочно листать огромную историю чата, параллельно уворачиваясь от обломков очередного разрушающегося здания).
К тому же, в профиле юзеров появляется специальный статус, с помощью которого родные и друзья могут понять, все ли с ним или с ней в порядке. Ну и само собой, в Line встроена интерактивная карта больниц и разных укрытий с информерами и полезными советами. Интересно, туда можно интегрировать свой ресторанчик? Ну типа, раз выжил в землетрясении и добежал до больнички, то вот, смотри, рядом с ней есть палатка с вкуснымии гедза (а что, уверен, что спасшиеся от землетрясения люди ужас как голодны).
Любопытно, что "катастрофический функционал" влияет и на некоторые транзакционные сервисы Line. Например, встроенный в мессенджер такси-агрегатор Line Taxi в случае землетрясения начнет адаптировать тарифы для водителей, чтобы пострадавшие в зоне бедствия с большей вероятностью могли найти машину (разумеется, компания учитывает и отрабатывает все очевидные риски).
Во многом за счет этого функционала Line быстро стал must-download приложением для любого японца, после чего навесить дополнительный функционал и монетизацию стало делом техники.
Как онлайн-аукцион стал главным IT-дзайбацу
Транзитом через историю Line полноценно перенесемся в страну Восходящего солнца. Не ругайтесь на меня, товаращи-японисты. Я понимаю, что Rakuten - ниакой не клановый дзайбатцу, а обычный кабусики-гайся (т.е. обычная компания, чья история не тянется со времен Реставрации Мэйдзи). Но я не удержался, ради красоты заголовка.
Итак, вообще, про компанию Rakuten можно писать отдельную большую статью, поэтому сегодня пройдусь кратко по ключевым моментам.
В конце девяностых банковский служащий Хироси Микитани насмотрелся на зарождающийся в США тренд на электронную коммерцию и решил перенести тамошние практики в родную Японию.
В 1997 г. он запустил портал для торговли товарами сторонних продавцов в формате онлайн-аукциона. Видимо, подсмотрел фишку у набиравшего тогда популярность eBay. Тем не менее, Микитани решил собирать нетворк-эффект своей платформы не совсем так, как это делали будущие лидеры американского ecommerce.
Например, если Amazon начал развитие с оцифровки отдельного рынка (продажи книг), набрал там критическую массу покупателей, а потом уже начал пропихивать своей лояльной клиентской базе другие товарные категории, то Rakuten решил сразу сделать ставку на раскачку предложения (а спрос подтянется, куда он денется).

В 2014 г., когда Rakuten уже стал гигантской онлайн-империей, Микитани написал кнингу "Маркетплейс 3.0", где выложил свои секреты построения ecommerce-платформ. Сам я её пока не читал, но слышал, что книга годная. Так что, рекомендую авансом.
Так вот, Микитани решил сфокусироваться на привлекательности своего детища для продавцов. Он радикально снизил для них комиссию, сделав её примерно в 5-10 раз меньше, чем тогда было у тех же Amazon и eBay, активно заходивших на японский рынок. К тому же, первым продавцам предлагался комплект привлекательных допуслуг, вроде бесплатной доставки и льготного периода ("бесплатных" первых месяцев на платформе). Также Rakuten помогал создавать витрины и даже обучал не сильно продвинутых владельцев небольшого бизнеса онлайн-торговле. К тому же, Rakuten был более снисходителен к малому и микробизнесу, смотря сквозь пальцы на многие косяки и недочеты, которые точно стали бы стоп-факторами при выходе на платформы зарубежных конкурентов.
В дальнейшем, по мере развития компании, комиссия, конечно, росла. Но все равно, комиссионная политика Rakuten до сих пор считается весьма гуманной и привлекательной в сравнении с другими игроками.
Забавный факт. В начале развития Микитани поставил амбициозную цель - перенести на свою платформу все торговые точки Токио. Тогда Rakuten был совсем небольшим стартапом, у него не было торговых агентов. Так что, основатель с небольшой командой сами обивали пороги компаний, заманивая их на свой распрекрасный сервис. Микитани решил начать с малого бизнеса, так что, основатель и ко иногда одевались нарочито непрезентабельно и расхлябанно, дабы не отпугивать чересчур деловым внешним видом владельцев небольших лавок.
Это сработало. Год спустя через платформу проходило уже 5 млн сделок. Компания крепла и захватывала все больше японского ecommerce. Вскоре, Микитани задумал международную экспансию.
В 2000-х компания начала выходить на другие азиатские и некоторые европейские рынки, в основном через скупку местных ecommerce-стартапов, стримингов и соцсетей. Также была попытка выхода на китайский рынок через стратегическое партнерство с Alibaba. Но партнеры не осилили борьбу с Tencent, JD, Meituan и прочими китайскими звездами. К тому же, Rakuten вышел в Китай в неудачный момент - экономика КНР как раз разгребала последствия финансового кризиса 2008 года.
Тем не менее, международная экспансия продолжалась. В 2014 году Rakuten купил сервис, о котором вы точно слышали - мессенджер Viber (как думаете, Микизани отправляет там открытки своим внукам?). А еще наверняка вы видели лого Rakuten на футболках Барселоны, ведь в 2016-2020 годах компания была титульным спонсором каталонского гранда.

Просто какие-то два чувака решили сфоткаться с основателем Rakuten. Кстати, судя по лицу Микитани, сам он болеет за мадридский Реал, или как минимум за Эспоньол.
Параллельно с ростом за пределами Японии, Rakuten обзаводился новыми бизнесами. Вдобавок к запущенному еще в 2000 г. платежному сервису Rakuten Pay, компания внедрила собственную платформу для управления личными финансами RakutenMoney. И вообще, ребята серьезно ударились в финтех, выпустив свою карточку и еще довольно много платежных фич и продуктов. В 2019 вообще запилили собственный криптокошелек и сделали свою криптовалюту, интегрированную с сервисом Rakuten Pay и внутренней программой лояльности.
А в 2014 г. компания запустила свой тревел-агрегатор, встроенный в основное приложение. Ведь азиат может уехать из супераппа, а суперапп из азиата - никогда!
Сейчас Rakuten - один из двух крупнейших ecommerce-игроков на рынке Японии (то уступит лидерство Amazon, то снова вырвется вперед) и довольно крепкий бренд в Южной Корее, Великобритании, Германии и еще нескольких странах.
Если проводить аналогию, то Rakuten чем-то напоминает наш Ozon. Тоже крупный маркеплейс, который активно лезет в финтех и тревел. И кстати, в 2011 г. Rakuten инвестировал довольно большую сумму как раз в Ozon.
Последний факт на сегодня. Слово "Rakuten" переводится с японского как "сдержанный оптимизм". Если вы найдёте более японское название для огромной IT-империи, то можете кинуть в меня булыжник из японского каменного сада!
***
На сегодня все. Если статья получит хороший отклик и наберет много лайков и комментов, то я продолжу. На очереди индонезийский суперапп, малазийский райдтех, казахстанский ультимативный финтех, турецкая экосистема и даже африканский стриминговый сервис.
Если вы дочитали до конца, то вам точно зайдут мои тг-каналы, а именно:
На основном канале Дизраптор я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и продуктовых новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили).
А на втором канале под названием Фичизм я пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Показать полностью
10
Корпоративная сеть
Корпоративная сеть — это интегрированная информационная сеть, предназначенная для обмена данными, ресурсами и коммуникаций между различными узлами и подразделениями одной организации. Корпоративная сеть обеспечивает надежное и безопасное соединение между компьютерами, серверами, телефонами, принтерами и другими устройствами внутри организации. Корпоративная сеть отличается от сети, например, Интернет-провайдера тем, что правила распределения IP адресов, работы с интернет-ресурсами и т. д. едины для всей корпоративной сети, в то время как провайдер контролирует только магистральный сегмент сети, позволяя своим клиентам самостоятельно управлять их сегментами сети, которые могут являться как частью адресного пространства провайдера, так и быть скрытым механизмом сетевой трансляции адресов за одним или несколькими адресами провайдера. Корпоративную сеть, основанную на компьютерных технологиях, называют Интранетом.

Основные характеристики корпоративной сети включают в себя:
1.Топология сети - это физическая структура связей между узлами сети, например, звезда, кольцо, шина или смешанная топология. Она определяет способ организации и управления сетью.
Существует несколько возможных топологий корпоративных сетей рисунок 1:
1.1. Звезда - наиболее распространенная топология, при которой все устройства подключены к центральному коммутатору или маршрутизатору. Это упрощает управление сетью и обеспечивает высокую отказоустойчивость, но при этом требует много кабельной инфраструктуры.
1.2. Кольцо - в этой топологии все устройства подключены в кольцевую цепь, где каждый компьютер соединен с двумя соседними. Это обеспечивает равномерное распределение нагрузки и отказоустойчивость, но снижает скорость передачи данных.
1.3. Шина - в этой топологии все устройства подключены к одному линейному кабелю, который является центральным каналом передачи данных. Это простая и дешевая топология, но имеет ограничения в скорости и проблемы с отказоустойчивостью.
1.4. Дерево - комбинация звезды и шины, при которой несколько звездных сетей соединены между собой через общий канал центрального коммутатора. Это обеспечивает гибкость расширения сети и улучшает отказоустойчивость.
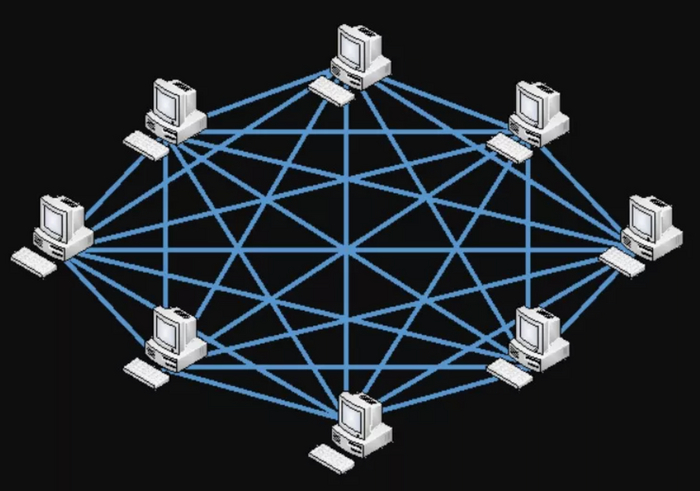
1.5. Сеть мешок - сеть, в которой каждое устройство подключено к каждому другому. Это обеспечивает наивысшую отказоустойчивость и скорость передачи данных, но требует большого количества кабельной инфраструктуры и управления.
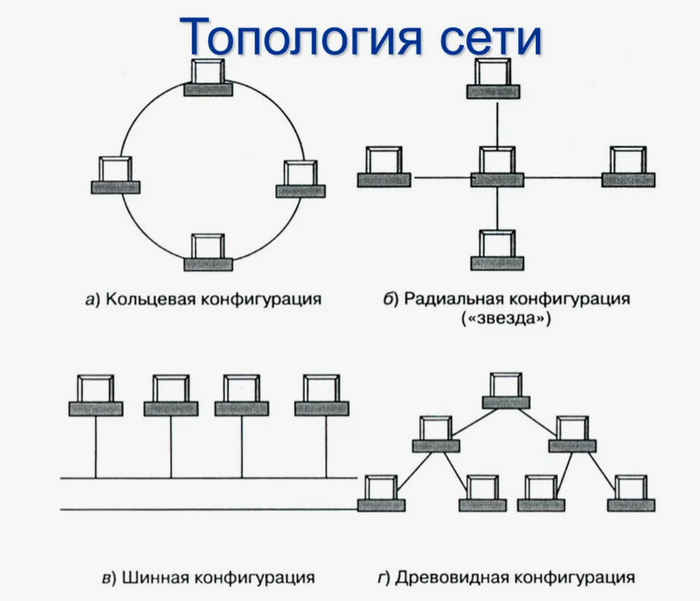
Рисунок 1
Каждая из указанных топологий имеет свои преимущества и недостатки, и выбор оптимальной зависит от конкретных потребностей и возможностей организации.
2.Пропускная способность - это возможность сети обрабатывать и передавать данные с заданной скоростью. Она зависит от оборудования сети, кабелей, протоколов и других факторов рисунок 2.

Рисунок 2
2.1. Пропускная способность - корпоративной сети определяется количеством данных, которые могут быть переданы через сеть за определенный период времени. Пропускная способность измеряется в битах в секунду (bps) или в килобитах в секунду (Kbps), мегабитах в секунду (Mbps) и гигабитах в секунду (Gbps) Рисунок 3.
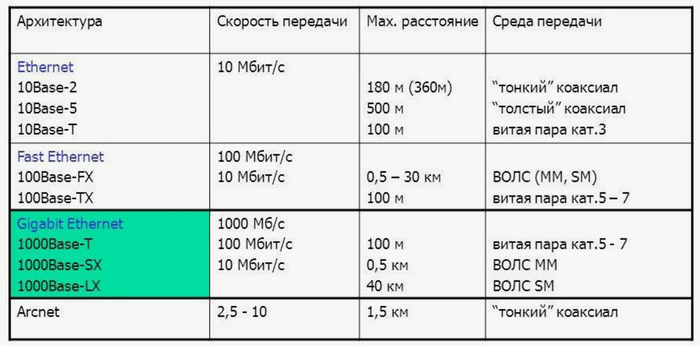
Рисунок 3
2.2. Пропускная способность - корпоративной сети зависит от нескольких факторов, таких как тип технологии передачи данных (например, Wi-Fi рисунок 4, Ethernet рисунок 5 ), количество устройств в сети, используемое оборудование (маршрутизаторы, коммутаторы), объем трафика данных и пропускная способность самого оборудования.
Беспроводная передача данных WiFi
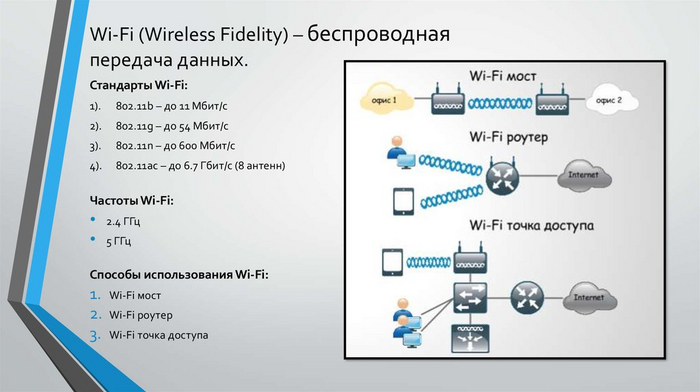
Рисунок 4 (WiFi)
Проводная передача данных Ethernet
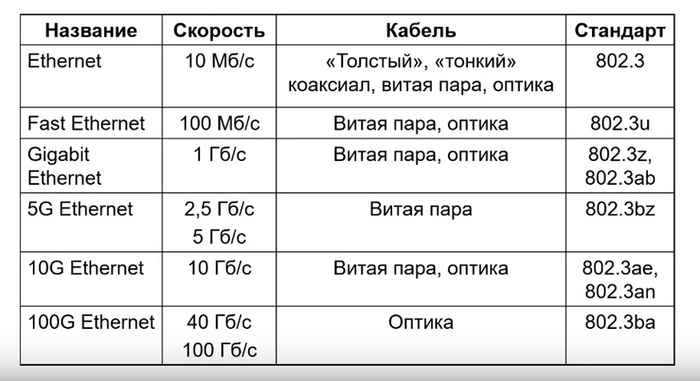
Рисунок 5
Для обеспечения эффективной работы корпоративной сети необходимо регулярно мониторить и оптимизировать пропускную способность, чтобы предотвратить проблемы с производительностью и перегрузками сети. Для увеличения пропускной способности сети можно использовать более мощное оборудование, увеличить пропускную способность каналов связи, оптимизировать настройки сетевого оборудования и программного обеспечения и т.д.
3.Безопасность - это защита сети от несанкционированного доступа, вирусов, вредоносного программного обеспечения и других угроз. Безопасность корпоративной сети обеспечивается с помощью аппаратных и программных средств, а также политик и процедур безопасности.

Безопасность корпоративной сети - это важный аспект ее функционирования, так как она содержит конфиденциальные данные компании, такие как финансовая информация, данные клиентов, интеллектуальная собственность и другие чувствительные информации, которая может быть взломана или украдена злоумышленниками.
При разработке систем безопасности корпоративной сети оценивают динамику поля угроз и возможный ущерб от них, а также необходимость степени интенсивности использования механизмов защиты в структуре сети для нейтрализации атак на неё. После тестирования корпоративной сети осуществляется ряд профилактических мер по прогнозированию вирусных атак, исследованию вредоносного кода и его уничтожению.
Для обеспечения безопасности корпоративной сети применяются различные меры, включая:
Файрволлы(Firewall, Брандмауэр) - программное обеспечение или аппаратные устройства, которые фильтруют трафик в сети и блокируют попытки несанкционированного доступа рисунок 6.
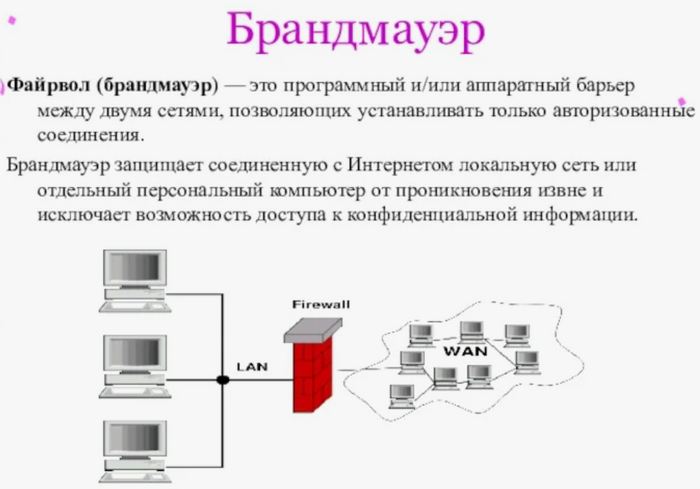
Рисунок 6
Виртуальные частные сети (Virtual Private Network VPN) - предоставляют зашифрованное соединение между удаленными пользователями и корпоративной сетью, что обеспечивает безопасную передачу данных через общедоступные сети рисунок 7.
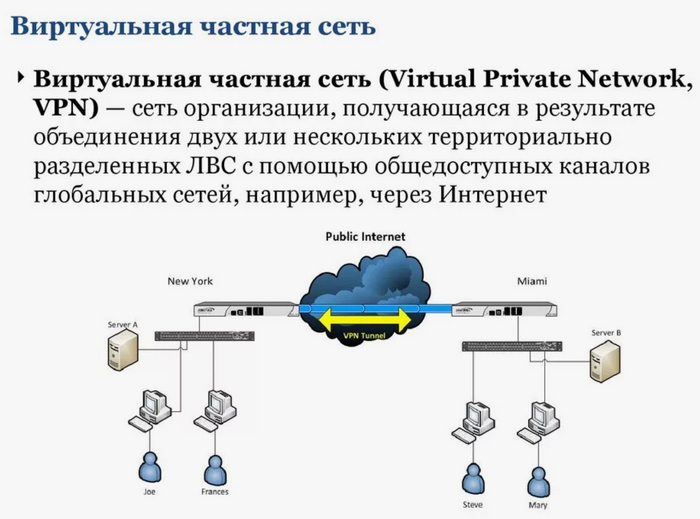
Рисунок 7
Антивирусное программное обеспечение - защищает компьютеры и серверы от вредоносных программ и вирусов рисунок 8.
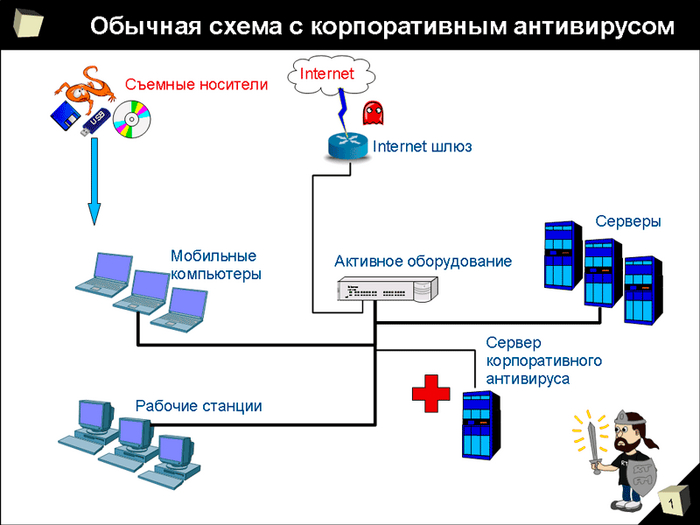
Рисунок 8
Системы обнаружения вторжений (IDS) и предотвращения вторжений (IPS) - отслеживают и блокируют несанкционированные попытки доступа к сети рисунок 9.
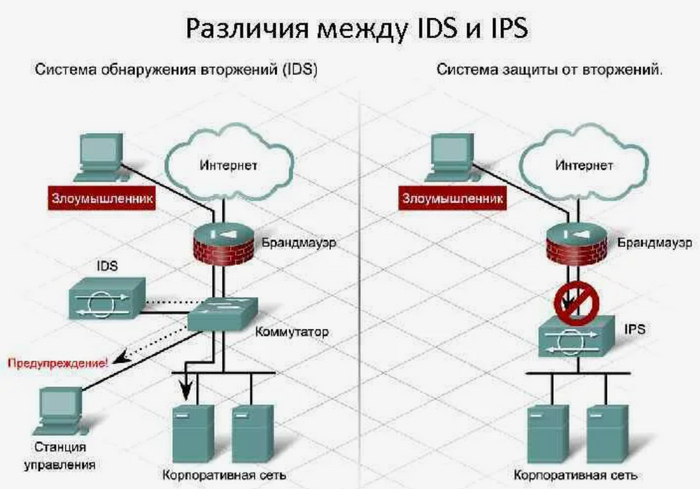
Рисунок 9
Аутентификация и авторизация - процессы проверки личности пользователя и предоставления доступа только к необходимым ресурсам и данным рисунок 10.

Рисунок 10
Регулярное обновление программного обеспечения и систем безопасности - для закрытия уязвимостей и обеспечения защиты от новых угроз. Небольшой пример классификации программного обеспечения ПК пользователя рисунок 11.
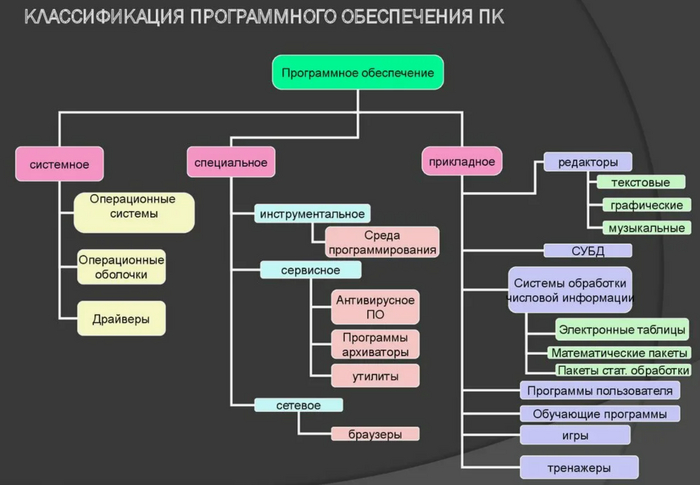
Рисунок 11
В целом, хорошо спроектированная и правильно настроенная корпоративная сеть с соответствующими мерами безопасности обеспечивает защиту конфиденциальных данных компании и предотвращает потенциальные кибератаки и утечки информации.
4.Масштабируемость - это возможность расширения сети, добавления новых устройств и узлов, а также переноса сетевых ресурсов без значительного снижения производительности рисунок 12.

Рисунок 12
Масштабируемость корпоративной сети является важным аспектом, так как она должна быть способной расширяться и расти вместе с компанией. Это означает, что сеть должна быть спроектирована таким образом, чтобы новые устройства и оборудование могли легко добавляться без значительных изменений в инфраструктуре.
Для обеспечения масштабируемости корпоративной сети необходимо учитывать следующие аспекты:
Гибкая структура: сеть должна быть построена с использованием гибкой архитектуры, которая позволит легко добавлять новые узлы и устройства рисунок 13.
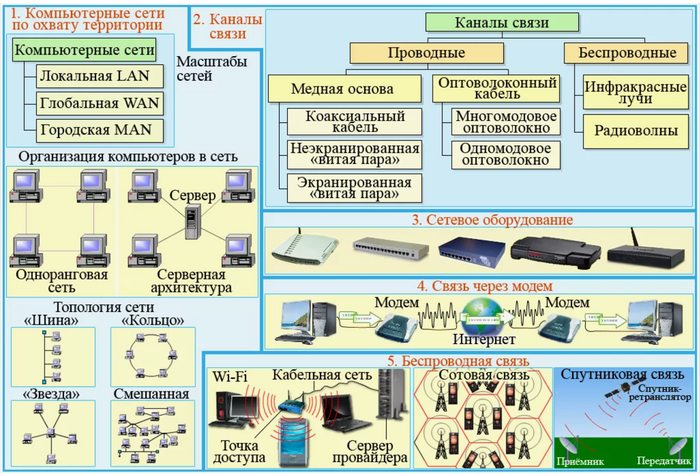
Рисунок 13
Использование облачных технологий: облачные сервисы позволяют масштабировать ресурсы сети без необходимости приобретения нового оборудования рисунок 14.
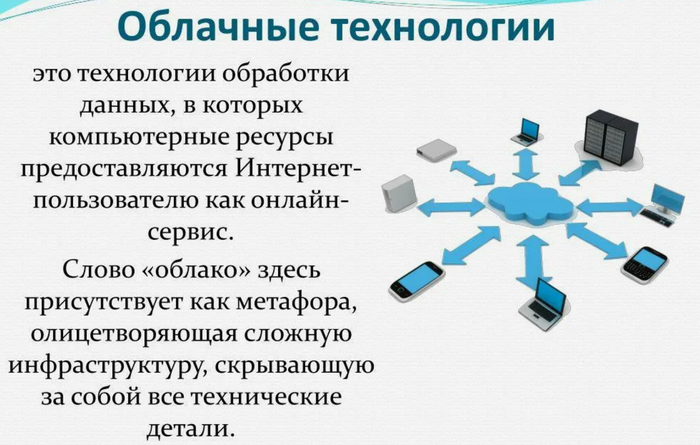
Рисунок 14
Использование виртуализации: виртуализация позволяет управлять ресурсами сети более эффективно и упрощает процесс добавления новых устройств рисунок 15.
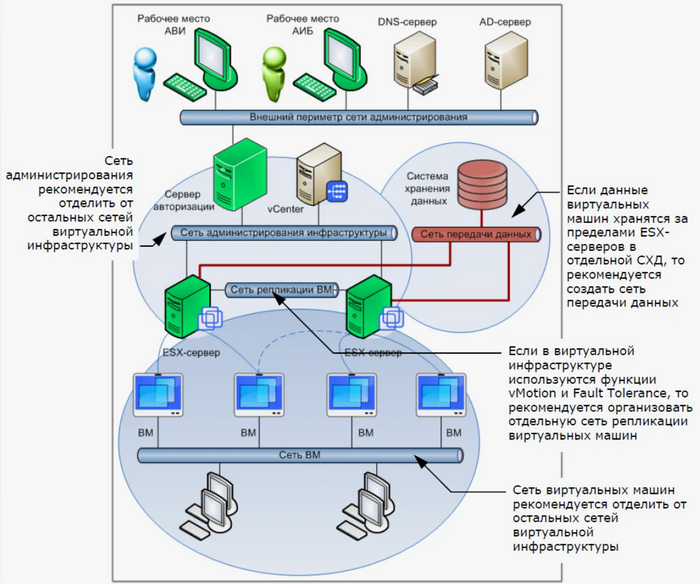
Рисунок 15
Использование многоканального доступа: расширение сети с помощью нескольких каналов связи обеспечивает более высокую доступность и производительность рисунок 16.
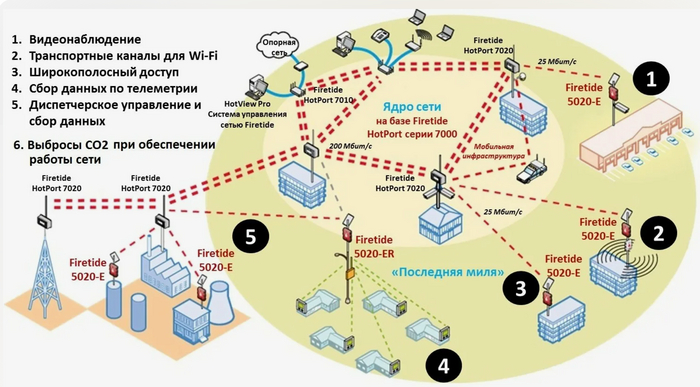
Рисунок 16
Мониторинг и управление: корпоративная сеть должна быть подвергнута непрерывному мониторингу и гибко управляема, чтобы своевременно обнаруживать и решать проблемы, а также оптимизировать использование ресурсов рисунок 17.
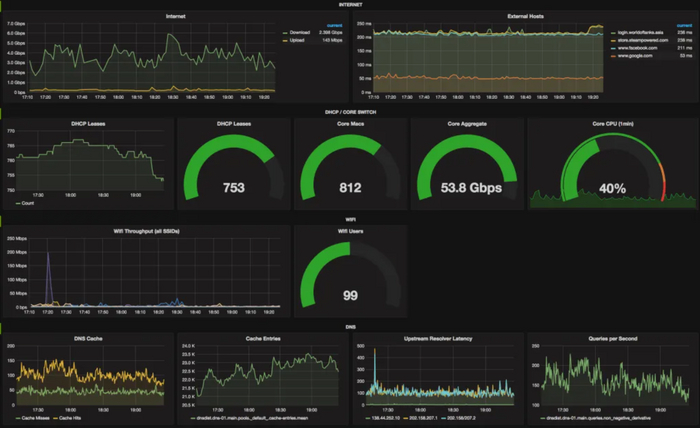
Рисунок 17
Масштабируемость корпоративной сети играет важную роль в эффективном функционировании бизнеса и обеспечении его развития. Правильное проектирование и постоянное обновление сетевой инфраструктуры позволяют компании быть готовой к росту и изменениям в бизнес-среде.
5.Централизованное управление - это возможность контролировать и администрировать сеть из одного центра, управлять доступом к ресурсам, обеспечивать резервное копирование данных и мониторинг работы сети. Корпоративная сеть может быть построена на основе локальной сети (LAN), глобальной сети (WAN), виртуальной частной сети (VPN) или комбинации различных типов сетей. Она играет важную роль в повышении эффективности работы сотрудников, обмене информацией, автоматизации бизнес-процессов и обеспечении конкурентоспособности организации рисунок 18.
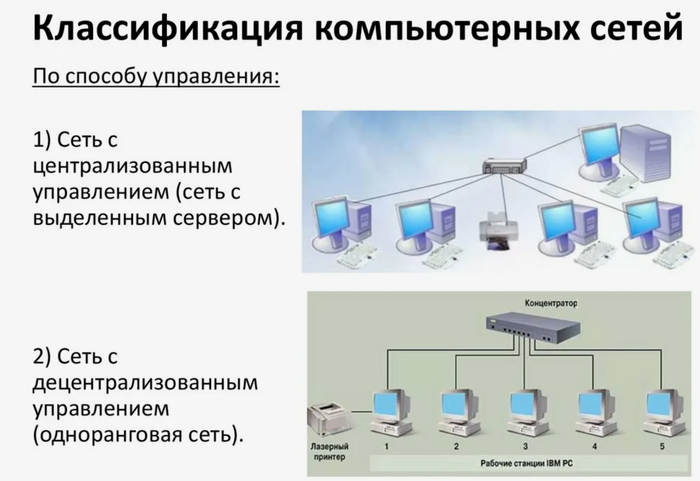
Рисунок 18
Централизованное управление корпоративной сетью означает, что все настройки и управление ресурсами сети проводятся из одного центрального места – обычно из штаб-квартиры компании или из специального отдела информационных технологий. Это позволяет обеспечить более эффективное и надежное управление сетью, централизованную защиту данных, а также контроль доступа и безопасности.
Централизованное управление корпоративной сетью может быть реализовано с помощью специальных программных продуктов, таких как системы управления сетью (Network Management Systems), которые позволяют администраторам мониторить состояние сети, настраивать параметры работы устройств, проводить диагностику сети и многое другое.
Основные преимущества централизованного управления корпоративной сетью:
1. Упрощение процесса управления и обслуживания сети:
Централизованное управление корпоративной сетью предполагает использование центрального сервера или управляющего устройства, которое контролирует все узлы сети и обеспечивает их работоспособность и безопасность рисунок 19.
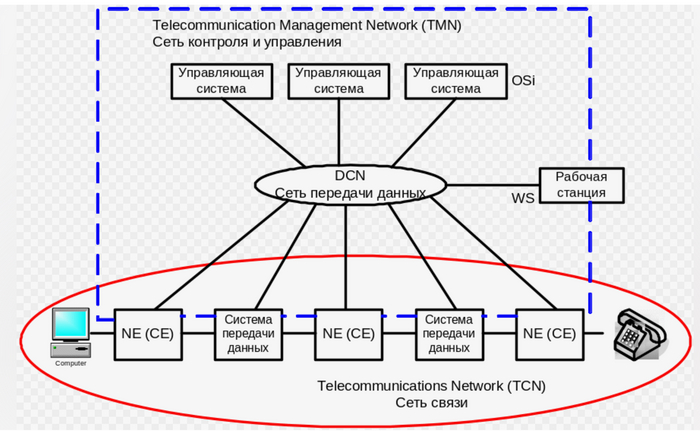
Рисунок 19
Одним из основных преимуществ централизованного управления корпоративной сетью является упрощение процесса администрирования сети. Администратору достаточно иметь доступ к центральному серверу для выполнения всех необходимых операций по настройке, мониторингу и обслуживанию сети. Это значительно упрощает работу администратора и позволяет ему быстро реагировать на возникшие проблемы и обеспечивать бесперебойную работу сети. Другим важным преимуществом централизованного управления корпоративной сетью является обеспечение ее безопасности. Центральный сервер может контролировать доступ пользователей к ресурсам сети, устанавливать политики безопасности и мониторить активность пользователей. Это позволяет предотвращать несанкционированный доступ к данным и защищать сеть от внешних угроз. Таким образом, централизованное управление корпоративной сетью важно для обеспечения ее эффективной работы, безопасности и удобства администратора. Эта модель управления дает возможность эффективно масштабировать сеть, упростить процессы обслуживания и обеспечить высокий уровень защиты данных.
2. Централизованный контроль безопасности данных и доступа к ресурсам:
Для реализации централизованного управления и контроля безопасности данных и доступа к ресурсам необходимо использовать специальное программное обеспечение, такое как централизованные системы управления доступом (IAM), централизованные системы мониторинга безопасности, централизованные системы аутентификации и авторизации и другие решения рисунок 20.
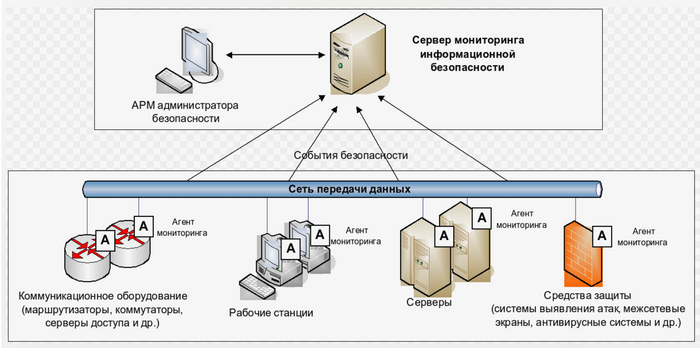
Рисунок 20
Основные преимущества централизованного управления и контроля безопасности данных и доступа к ресурсам в рамках корпоративной сети включают в себя:
- Более высокий уровень безопасности, благодаря централизованному контролю доступа к данным и ресурсам
- Более эффективное управление политиками безопасности и упрощенное администрирование сети
- Уменьшение рисков утечки данных и нарушений безопасности
- Более простое масштабирование сети и добавление новых устройств и пользователей - Более прозрачное и единое управление доступом к данным и ресурсам внутри организации.
Таким образом, централизованное управление и контроль безопасности данных и доступа к ресурсам играет важную роль в обеспечении безопасности и эффективности корпоративной сети, позволяя компаниям эффективно защищать свои данные и ресурсы от угроз и несанкционированного доступа.
3. Более эффективное выделение ресурсов и оптимизация работы сети рисунок 21:
Более эффективное выделение ресурсов и оптимизация работы сети включает в себя ряд мероприятий.
Во-первых, благодаря централизованному управлению можно более точно распределять ресурсы в сети, например, выделять больше пропускной способности там, где она наиболее необходима. Это позволяет повысить производительность сети и снизить нагрузку на отдельные узлы.
Во-вторых, оптимизация работы сети включает в себя регулярное мониторинг и анализ работы устройств и потоков данных. Это позволяет выявить узкие места и проблемы в работе сети, чтобы оперативно устранить их и повысить ее стабильность и надежность.
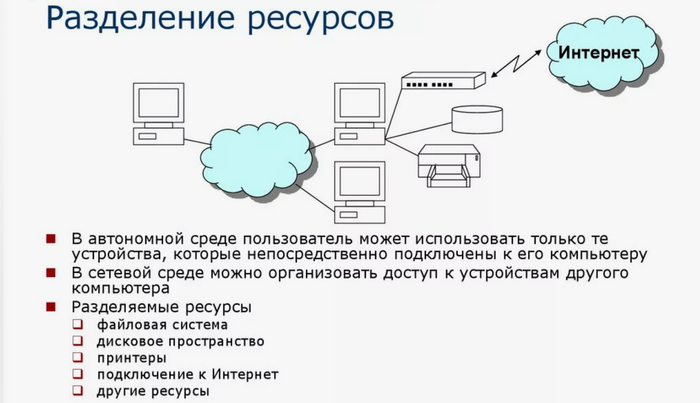
Рисунок 21
Таким образом, централизованное управление корпоративной сетью и ее оптимизация позволяют обеспечить более эффективное функционирование сети, улучшить производительность и обеспечить надежность работы организации в целом.
4. Увеличение надежности и стабильности сети:
Один из основных преимуществ централизованного управления - это возможность проводить управление и мониторинг всей сети из одного места, что упрощает процесс администрирования и повышает эффективность работы сети. Также, централизованное управление позволяет быстро выявлять и устранять проблемы в сети, что способствует увеличению ее надежности и стабильности.
Увеличение надежности и стабильности сети также достигается благодаря использованию резервирования и балансировки нагрузки. Например, использование резервирования подразумевает создание дублирующих каналов связи и оборудования, которые могут автоматически вступить в действие в случае отказа основного оборудования или канала. Балансировка нагрузки позволяет распределять трафик между разными узлами сети, что помогает предотвратить перегрузку и сбои в работе сети.
Кроме того, для обеспечения надежности и стабильности сети можно использовать различные технологии и методы защиты данных, такие как шифрование, брандмауэры, антивирусные программы и системы обнаружения вторжений. Системы мониторинга и резервное копирование данных также играют важную роль в обеспечении безопасности и надежности корпоративной сети.
5. Сокращение времени на решение проблем с сетью и оборудованием:
Централизованное управление корпоративной сетью означает, что все решения по настройке, мониторингу и обслуживанию сети принимаются из одного центрального пункта, что обеспечивает единство и координацию в работе всей сети.
Один из главных преимуществ такого управления является сокращение времени на решение проблем с сетью и оборудованием. Благодаря централизованному управлению, администраторы могут быстро выявить проблемы, провести диагностику и принять меры для их устранения.
Кроме того, такой подход позволяет сэкономить время на обслуживание сети в целом, поскольку все настройки, обновления и резервное копирование данных могут быть проведены централизованно, без необходимости проводить их на каждом устройстве отдельно. Централизованное управление корпоративной сетью позволяет повысить эффективность ее работы, обеспечить стабильность и безопасность работы сети, а также значительно сократить время на решение проблем с сетью и оборудованием. Пример корпоративной сети рисунок 22.
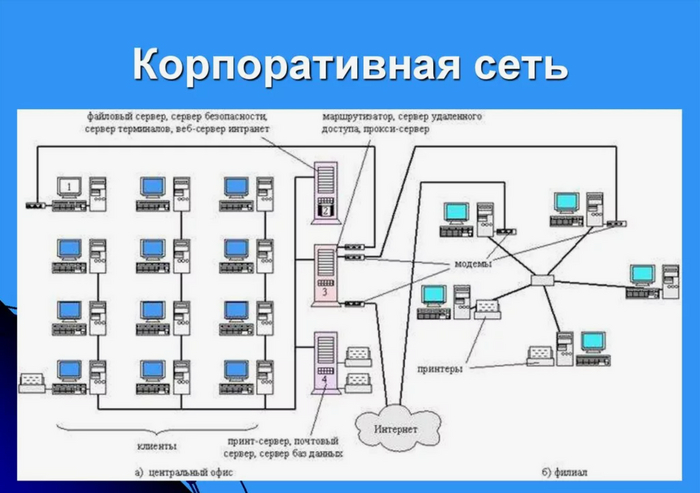
Рисунок 22
Таким образом, централизованное управление корпоративной сетью является важным инструментом для обеспечения устойчивой и безопасной работы сети компании, а также эффективного управления всеми ее ресурсами.
Так что же такое корпоративная сеть??? Это достаточно сложный механизм требующий основательного подхода начиная от подхода к проектирования сети (необходимо руководствоваться стандартами построения сетей передачи данных, и их технологиями передачи, стандартами организации последней мили, стандартами построения локальных сетей), создания серверных помещений (ЦОД, промежуточные КЦ(коммутационные центры) и т.д.). Выбора предполагаемого оборудования, программного обеспечения. Ну и не маловажный фактор это конечно СПЕЦИАЛИСТЫ которые и будут проектировать, вытраивать и в конечном итоге управлять этим флагманом.
Показать полностью
25
1

Разработали систему, которая продумывает маршруты пациентов и сокращает очереди. Вместо «Кто последний?» — QR-код
Умная электронная очередь сама строит маршруты для пациентов, чтобы они как можно быстрее проходили нужных специалистов. В итоге медцентр принимает больше клиентов и увеличивает прибыль, а пациенты не стоят в очередях. Рассказываю, как работает эта система.

С чем пришел клиент: очереди и неравномерная нагрузка на докторов
К нам обратилась сеть медцентров, которая оказывает услуги по проведению профосмотров и медкомиссий работникам организаций. Компании ежегодно отправляют сотрудников на медосмотры, уклониться от этой обязанности нельзя. Часто работники приходят в клинику большими группами, в несколько десятков человек. Такая специфика работы подразумевает сразу несколько проблем:
В один день приходит много человек, которым нужно попасть в одни и те же кабинеты. Пациентам нужно пройти осмотры врачей, сдать анализы, сделать ЭКГ и другие функциональные исследования, а потом получить заключение по результатам медосмотра.
Пройти весь маршрут нужно как можно быстрее, желательно за день. Пока сотрудники находятся в медцентре, работодатель теряет деньги.
К одним врачам копятся очереди, другие простаивают. Приемы у разных специалистов различаются по длительности. Например, в одном кабинете пациент проводит в среднем 5 минут, в другом 15, в третьем 10.
В итоге пациенты проводят в очередях примерно столько же времени, сколько и на приемах, а иногда и больше — при этом злятся, нервничают и устают. Медцентр в это же время испытывает нагрузку и не принимает других пациентов.
Что придумали: систему, которая динамически строит и корректирует маршрут каждого пациента
Раньше человек приходил в регистратуру, получал обходной лист со списком кабинетов, которые нужно посетить. Такой же перечень получали его коллеги. Они все ходили по этому маршруту, ожидали приема врачей и спрашивали: «Кто последний?». Иногда возникали конфликты, когда кто-то хотел попасть в кабинет вне очереди.
Обычно медцентры ставят на стойку регистратуры электронную очередь, которая показывает номера талонов и к какому окну необходимо подойти. Мы разработали систему, которая строит индивидуальный маршрут для каждого посетителя по кабинетам. Причем это происходит динамически и на протяжении всего времени, пока пациент находится в учреждении. Перед тем как указать следующий кабинет обходного листа, алгоритмы анализируют множество факторов:
Среднюю продолжительность приема в каждом кабинете, чтобы избежать очередей.
Сколько человек ждет приема в те кабинеты, куда нужно попасть конкретному посетителю.
Кабинеты, в которых пациент уже побывал, чтобы система не отправила его дважды к одному и тому же доктору.
Перерывы в работе кабинетов — от отдыха врачей до кварцевания и уборки.
Последовательность, в которой нужно пройти обследования и осмотры — например, к терапевту нужно идти уже с готовой кардиограммой. Значит, его кабинет должен идти после кабинета, где делают ЭКГ. Или пациенту нужно пройти вакцинацию, поэтому сначала он должен попасть к терапевту, и только потом в процедурный кабинет.
На основе этих данных система определяет, куда нужно направить пациента, чтобы он потратил как можно меньше времени в медцентре. При этом посетителю не надо запоминать, за кем он занимал очередь, и считать, сколько перед ним человек. Все это уже сделал и учел алгоритм, достаточно просто ждать вызова в нужный кабинет.

Первый пункт маршрута посетители узнают в регистратуре, а следующие — в кабинетах специалистов. Можно сразу сказать, что мужчина с рюкзаком и пациент в бело-красной куртке отправятся в разные кабинеты
Как шла работа: моделировали ситуации и много раз проходили их шаг за шагом
Чтобы разработать с нуля и внедрить программное обеспечение, нам понадобилось девять месяцев. За это время мы прошли четыре этапа работы:
Собрали данные о проблемах у заказчика и систематизировали их.
Сформулировали гипотезы, каким образом должны строиться маршруты по медцентру.
Проанализировали и проверили гипотезы для будущей системы.
Разработали ПО на основе сценариев, которые прошли проверку во время третьего этапа.
Заказчику важно было сократить время, которое посетители проводят в центре. Ведь его можно использовать, чтобы принять других пациентов. Условно, до внедрения системы медосмотр успевали пройти 20 человек, а с ней — 40. В итоге мы существенно увеличили проходимость медцентра, что позволило вернуть недополученную прибыль.
Параллельно возникла идея, что система поможет собрать статистику по каждому специалисту: сколько времени уходит на приемы, перерывы, скольких пациентов успевает принять. На основе этих данных руководитель медцентра будет считать KPI для каждого сотрудника. Еще с помощью информации о времени приемов можно контролировать эффективность врачей-специалистов. Как только они отмечают, что закончили прием одного пациента, система приглашает следующего. При этом, если врачу нужен перерыв, он может отметить это в программе. А если кто-то захочет схитрить и не поставит отметки, что прием закончился, это отразится на KPI.
Одним из самых сложных для нас оказался третий этап — работа с гипотезами. Мы моделировали все возможные сценарии и шаг за шагом тестировали возможные маршруты пациентов. Вносили новые переменные и снова тестировали. Например, считали, как изменятся маршруты, если врач уйдет на обед. Рассчитывали так, чтобы за 20 минут до часа икс запись в кабинет закрылась, а возобновилась только после того, как доктор вернется.
Были идеи, которые сначала показались перспективными, но в итоге мы их сильно изменили или вообще отказались от них. Среди них — фиксированные маршруты. Изначально мы хотели, чтобы пациент на ресепшене сразу получал индивидуальный маршрут со всеми точками. В реальности оказалось, что это невозможно, ведь обстановка меняется каждую минуту: кто-то опоздал на прием, и доктор вызвал другого пациента. Где-то прием длится дольше запланированного, и под дверью копится очередь, а у другого специалиста, наоборот, образовалось свободное время. Готовая система реагирует на эти факторы и перестраивает маршруты.

Всю актуальную информацию пациент видит на планшете около нужного кабинета: порядок действий, примерное ожидание в очереди и номер посетителя на приеме
Придумали защиту системы от тех, кто встал в очередь и куда-то ушел. Если человек пропустил вызов в кабинет — например, не услышал звукового оповещения, — то он автоматически становится следующим в очереди. Если пациент пропустил и эту возможность, ему придется заново подойти к планшету и считать QR-код, чтобы встать в очередь.
Корпусы для планшетов тоже разрабатывали сами — не только ПО, но и внешнюю часть оборудования. Нужно было разместить планшет, сканер QR-кода и провода питания в едином корпусе. При этом было важно, чтобы устройство долго служило и выглядело аккуратно в интерьере медцентра.
Сначала мы спроектировали модели корпуса и распечатали на 3D-принтере для тестов. Самый удобный и эстетичный вариант заказали на производстве. Материалы подобрали максимально долговечные — металл и антивандальное стекло.
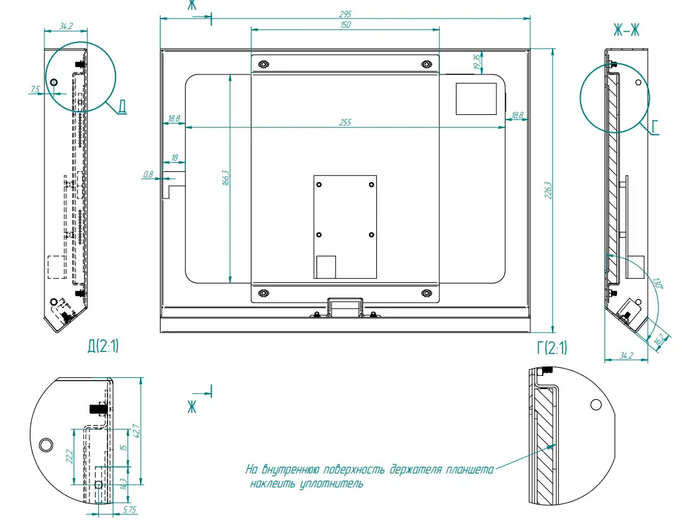
Мы разработали корпус с нуля — от материалов до дизайна и сборки. Продумали все крепления и разъемы так, чтобы устройство было прочным и при этом эстетичным
В итоге получилась система из практичных устройств. В алгоритме можно корректировать логику: менять количество кабинетов и врачей, сокращать или увеличивать время приема. Система подстроится под изменяющиеся условия и новые вводные. А сами планшеты прослужат долго за счет прочных материалов.
Как работает система и чем она отличается от обычной электронной очереди
Работает система на базе аппаратного комплекса из терминала, планшетов и телевизоров. Они выполняют следующие функции:
👉 Терминал. Через него посетитель получает талончик, чтобы встать в очередь в регистратуру. Именно там человек получает первую точку своего маршрута.
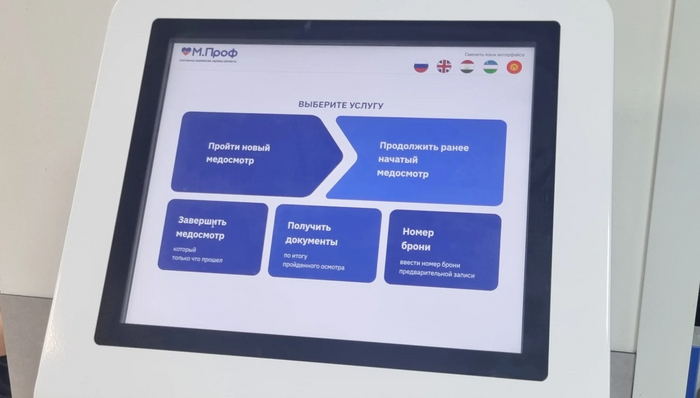
Через терминал посетитель выбирает нужную опцию, получает талон и с ним идет в регистратуру
👉 Телевизор. В каждом холле установлено несколько больших телевизоров. На экранах отображается порядок очереди к стойке регистратуры. На больших экранах можно показывать рекламу или включать имиджевые ролики.

Телевизоры показывают информацию об очереди в регистратуру
👉 Планшеты. Они расположены около каждого кабинета. Через них доктор приглашает на прием, а пациенты видят на экране занятость кабинета, среднее время ожидания в очереди и расписание перерывов.
Планшеты висят около каждого кабинета. Чтобы встать в очередь или покинуть ее, нужно отсканировать QR-код
Со стороны это похоже на обычную электронную очередь в банке или на почте. Но наши алгоритмы сложнее. Они анализируют массу данных перед тем, как отправить пациента в какой-то кабинет. Благодаря системе для пациентов после прохождения стойки регистратуры начинается магия. Иначе назвать профосмотр с минимумом очередей нельзя.
В итоге путь пациента выглядит так:
Регистратура. Посетитель получает талон с QR-кодом вместо обходного листа и номер первого кабинета в маршруте.
Холл. Пациенту нужно уведомить систему, что он дошел до кабинета и встал в очередь — отсканировать QR-код через планшет около двери.
Кабинет специалиста. После осмотра доктор называет следующую точку маршрута, которую определила система.
Посетитель проходит по кабинетам до тех пор, пока не пройдёт всех специалистов.
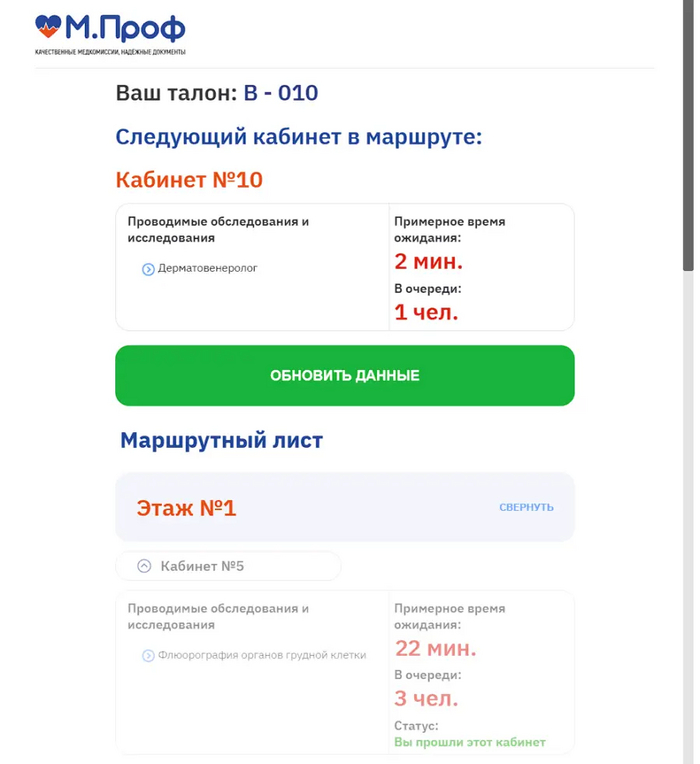
Благодаря умной электронной очереди время пребывания пациента в медцентре сократилось почти в два раза — в среднем с 80 минут до 45 минут. Пациенты проводят меньше времени в очереди, а врачу не нужно выходить в коридор и звать следующего пациента на прием.
Алгоритмы умной очереди можно использовать не только в медцентрах, которые занимаются профосмотрами. Возможности этой системы адаптируются и под учреждения, которые занимаются лечебной диагностикой: например, обычные клиники, куда пациенты приходят, чтобы пройти обследование перед госпитализацией или операцией. Отсутствие очередей — сильное УТП для пациентов. Они хотят получить услуги быстро и качественно, а клиника — распределить нагрузку на специалистов так, чтобы они успевали принять за день еще больше пациентов.
Про рабочие проекты в различных отраслях бизнеса, которые мы реализуем с помощью цифровых решений, я рассказываю у себя в телеграм-канале.
Показать полностью
6
1

Израильский стартап по защите данных, поддерживаемый PayPal и Nationwide, привлекает 30 миллионов долларов
Программное обеспечение, разработанное тель-авивской компанией Mine, сообщает компаниям и потребителям, где находятся их данные и как они их используют, чтобы более эффективно управлять данными и конфиденциальностью.

Основатели израильского дата-стартапа Mine (справа налево): Коби Ниссан, Галь Рингель и Галь Галон. (Courtesy)
Тель-авивскому стартапу Mine, чье программное обеспечение позволяет предприятиям и потребителям контролировать использование их данных, удалось получить финансирование от новых американских инвесторов, сообщила компания.
Израильский стартап, основанный в начале 2019 года генеральным директором Галом Рингелем, финансовым директором Коби Ниссан и техническим директором Галом Голаном, заявил, что привлек $30 млн в раунде финансирования серии B, проводимом Battery Ventures и PayPal Ventures, инвестиционным подразделением финтех-компании. при участии инвестиционного подразделения страхового гиганта Nationwide.
К финансированию также присоединились существующие инвесторы, в том числе венчурный фонд искусственного интеллекта Google Gradient Ventures, Saban Ventures, MassMutual Ventures и Headline Ventures. На сегодняшний день стартап привлек в общей сложности $42,5 млн финансирования.
Mine утверждает, что ее платформа отображения данных в реальном времени на основе искусственного интеллекта показывает пользователям, где хранится их информация внутри организации или бизнеса, какие системы и активы у них есть и какие данные они хранят внутри. Платформа создана для того, чтобы организации и предприятия могли быстрее и эффективнее управлять данными и конфиденциальностью, а также нацелена на снижение рисков и затрат, связанных с различными нормативными актами.
«Финансирование было завершено на второй неделе октября. «Несмотря на сложную ситуацию на финансовых рынках с марта прошлого года, мы управляли компанией очень осторожно и дисциплинированно, сокращая ежемесячные расходы, а также значительно увеличивая доходы, что позволило нам достичь выдающихся показателей, которые заинтересовали многих инвесторов. ».

Наглядное изображение безопасности данных для противодействия онлайн-мошенничеству (anyaberkut; iStock by Getty Images)
Стартап заявил, что собранные средства будут использованы для его планов глобального расширения в США и для продвижения своей платформы отображения данных корпоративным клиентам. Среди 150 текущих клиентов Mine — Reddit, HelloFresh SE, Fender, Guesty, Snappy и Data.ai. Стартап также ищет возможности нанять десятки разработчиков и специалистов по машинному обучению в Израиле. В офисах Mine в Тель-Авиве, США и Германии работает около 35 сотрудников.
«Мы были инвесторами и стойкими сторонниками Mine с самого начала, и мы очень рады быть частью этого решающего момента, возглавив последний раунд финансирования Mine, который позволит ей стать игроком номер один в области решений для обеспечения конфиденциальности и позволит его расширение на другие новые области, такие как регулирование искусственного интеллекта», — сказал Скотт Тобин, старший партнер Battery Ventures.
В связи с ростом социальных сетей и сбора персональных данных по всему миру, а также растущей заботой о конфиденциальности, Mine изначально разработала свою технологию как приложение, помогающее потребителям отслеживать, у кого есть их данные, как компании используют их данные и какой риск связан с этими организациями. Приложение, которое дает потребителям контроль над своими личными данными онлайн, также предоставляет пользователям возможность отправить запрос на удаление услуг, которыми они больше не пользуются, и позволяет им запросить удаление своих данных.
По словам стартапа, с момента запуска приложения в 2020 году более 5 миллионов пользователей по всему миру использовали Mine, чтобы уменьшить свой цифровой след, отправив более 50 миллионов запросов более чем 600 000 компаниям и организациям. В результате более 500 000 пользователей приложения были спасены от различных цифровых угроз, говорится в сообщении стартапа.
Перевод с английского
Показать полностью
1

Если вы профи в своем деле — покажите!

Такую задачу поставил Little.Bit пикабушникам. И на его призыв откликнулись PILOTMISHA, MorGott и Lei Radna. Поэтому теперь вы знаете, как сделать игру, скрафтить косплей, написать историю и посадить самолет. А если еще не знаете, то смотрите и учитесь.

ChatGPT — никакой не интеллект, а просто программа для "сжатия интернета" на мощных стероидах. Но мы его все равно любим
Генеративные нейросети любят ловить глюки и выдавать всякую чушь. Причем так массово, что Кембриджский словарь признал «галлюцинировать» главным словом 2023 года. В чем причина этой проблемы? Является ли генеративный ИИ интеллектом? И что общего у ChatGPT и копировального аппарата Xerox? Разбираемся, попутно разрушая мифы про этот наш вездесущий искусственный интеллект.

"ChatGPT заменит поисковики", - говорили они.
Небольшое вступление или "в чем суть проблемы?"
Авторитетный Кебриджский словарь признал словом года «галлюцинировать» (hallucinate). Причем не в вакууме, а применительно к генеративному ИИ. Глюки ИИ — это когда ChatGPT выдает косяки в фактологии, из‑за которых пользователи теряют всякую веру его результатам (и срочно бегут все перепроверять в Гугле). Но не стоит злиться на генеративный ИИ за подобные выкрутасы, ведь дело в самой логике его работы. Ее мы сегодня и разберем с помощью парочки метких аналогий.
Год назад Google впервые представил миру своего чат‑бота Bard. Сейчас он вполне неплохо работает (хотя и уступает первопроходцу), но на той презентации умудрился выдать базу‑основу. Он заявил, что «Джеймс Уэбб» был первым космическим телескопом, сделавшим снимки планет за пределами Солнечной системы. Это была ошибка — первые снимки этих самых планет сделал другой телескоп еще за 17 лет до появления на свет «Джеймса Уэбба». Неточность Барда быстро заметили, в результате чего у Google даже просела стоимость акций.
ИИ чат‑боты регулярно выдают неточности и искажения. Чаще всего они незначительны и касаются отдельных деталей. Однако даже наличие небольших косяков сильно снижает полезность генеративного ИИ на практике. Ведь если вы знаете, что ошибки в целом возможны и даже регулярны, то не можете полностью довериться этому инструменту.
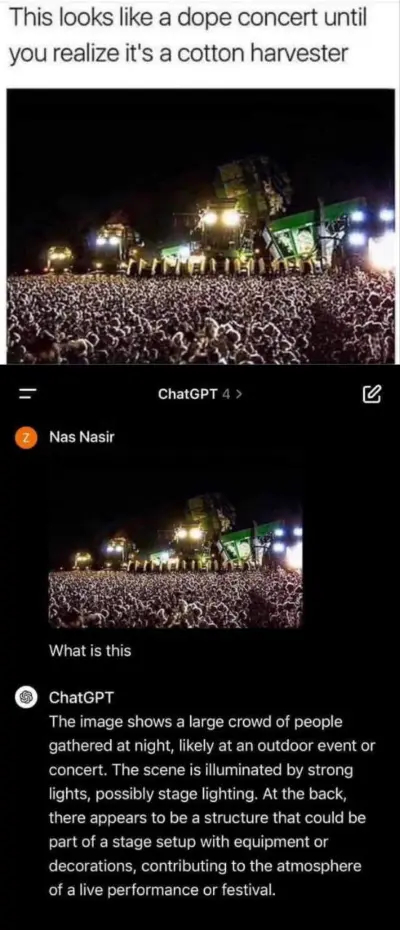
Сферические глюки ИИ в вакууме. Да-да, ChatGPT, конечно же это мероприятие или концерт. День хлопка на плантации отмечают, не иначе. А впрочем, не каждый человек справился бы лучше.
Но не спешите обвинять бездушную машину в злом умысле. У нее нет цели подставить кожаных или намеренно ввести в заблуждение.
Причина в другом. Дело в том, что генеративный ИИ по принципам своего устройства больше напоминает архиватор (т. е. программу для сжатия файлов), нежели полноценное сознание. Именно поэтому эксперты в ИИ зачастую недовольно фыркают, когда генеративные нейросети называют звучным словом «интеллект». А еще это отлично объясняет, почему ChatGPT очень вряд ли превратится в злой скайнет (но это не точно).
Итак, давайте разбираться. В этом нам поможет классная статья издания The New Yorker за авторством Теда Чана, из которой я с большой благодарностью буду заимствовать ключевые тезисы. Подкрепляя их иллюстрациями, дабы нагляднее было.
Хитрый Xerox и внимательные немецкие архитекторы
Осмыслять проблему удобнее чуть издалека, с интересной аналогии.
В 2013 году копировальный аппатар Xerox в офисе одной немецкой строительной фирмы начал творить очень странные дела. Ребята делали копию проекта дома с тремя комнатами и заметили очень любопытное расхождение:
На оригинальной схеме три команты имели разную площадь — 14.13, 21.11 и 17.42 метра. То есть, на чертеже в центре каждой комнаты стояла разная циферка, обозначающая площадь.
Xerox же выдал копию, где на всех трех комнатах стояла одинаковая цифра — 14.13 (как площадь первой комнаты).
Компания прифигела от такого контринтуитивного глюка копировальной техники и обратилась к специалисту по обработке данных Давиду Крайзелю.
Вы, возможно, спросите: «Аффтар, а почему они обратились к человеку такой специальности, а не к эксперту в копировальном деле?». Дело в том, что современные ксероксы используют не классический процесс ксерографии (это когда изображения передаются с оригинала на копию через прохождение лучей через специальный барабан — в общем, аналоговая классика), а цифровое сканирование.
А когда речь заходит о каких‑то манипуляциях с изображениями (да и файлами в целом) в цифровой среде, то мы почти наверняка столкнемся с процедурой сжатия объектов.
Процедура сжатия состоит из двух ключевых этапов. Первый — кодирование (encoding), в ходе которого изначальное изображение переводится в какой‑то более компактный формат. Второй — декодирование (decoding), т. е. обратное действие.
При этом сжатие бывает двух типов:
Сжатие без потерь (lossless) — это когда закодированные данные могут быть восстановлены с точностью до пикселя или бита. Если речь идет про изображения, то самый популярный формат сжатия без потерь — это PNG.
Сжатие с потерями (lossy) — здесь уже распакованные данные отличаются от исходных, но степень отличия столь незначительно и минорна, что их без проблем можно дальше использовать. Яркий пример — JPEG.

Чоткие пацаны не забивают карту памяти своего Сименса пээнгэшками!
Сжатие без потерь обычно используется, скажем, для компьютерных программ. Потому что если потерять хотя бы один символ кода, то все поломается. А вот для изображений, аудио или видеофайлов часто предпочитают использовать сжатие с потерями. Ведь даже если отдельные пиксели картинки поедут или мелодия будет звучать чуть менее чисто, то человечьи органы осязания все равно не заметят подлога, так что пофиг.
Здесь и была зарыта собака в истории со ксероксом. Агрегат использовал lossy‑сжатие формата JBIG2, которое работает примерно так:
В целях экономии места или вычислительных мощностей (а может и того и другого, пойди разберись в этой офисной технике) машина ищет очень похожие области изображения и сохраняет для всех них одну копию, которую потом воспроизводит обратно при декодинге.
Проще говоря, конкретно в этом случае ксерокс почему‑то решил, что комнаты на чертеже так похожи друг на друга, что можно смело забивать на различия и считывать только одну из них — ту, которая площадью 14,13 кв метров. А потом везде нарисовать именно её. То ли потому что формат JBIG2 создан для работы с черно‑белыми офисными бумажками, а не с мелкими объектами чертежей, то ли просто у аппарата был дурной характер — история умалчивает. Но суть в том, что ксерокс решил забить на небольшие различия именно в том случае, где эти различия оказались очень даже критичными.
Вообще, сам факт того, что ксерокс использует сжатие с потерями — это не проблема. Проблема в том, что изображение деградирует очень незначительно, «на тоненького». Настолько чуть‑чуть, что с ходу фиг заметишь. Одно дело, если бы он просто блюррил упрощенные области картинки, но он их может просто вероломно заменить. А строительному бюро потом объясняй заказчику, почему в итоге все комнаты получились одинаковыми.
Идем дальше. Проблема сжатой Википедии
Запомним историю со Xerox и проведем один мысленный эксперимент (он нам нужен, чтобы подойти еще ближе к пониманию проблемы этих наших GPT).
Представьте, что завтра во всем мире отключат интернет. Вообще. Совсем. Не будет его больше. В связи с этим мы решаем по максимуму выгрузить все содержимое интернета к себе на частный сервер. Ну окей, пусть будет не весь интернет (это совсем тяжко), но хотя бы всю Википедию. Чтобы оставить великие знания потомкам.
Разумеется, место на сервера ограничено — вся Википедия туда не влезет. Допустим, места хватит на 1% от оригинального размера, т. е. сжать изначальный объем нужно в 100 раз. Следовательно, нужно прибегнуть к сжатию с потерями.

Печатать всю Википедию мы, пожалуй, не будем. Это too much даже для гипотетического мысленного эксперимента. Обойдемся цифровым форматом.
Итак, мы применяем сжатие с потерями. Алгоритм у нас мощный — он легко находит чрезвычайно тонкие статистические закономерности на совершенно разных страницах (иногда одинаковыми оказываются длинные фразы или целые предложения). Таким образом нам удается сжать Википедию примерно в 100 раз, что и требовалось в нашем мысленном эксперименте.
Теперь нам не так страшно потерять доступ к интернету, ведь у нас как минимум выкачана база знаний в виде Википедии (а значит, потомкам будет чуть проще делать выводы о предназначении предметов, найденных при раскопках через тысячи лет). Но есть нюанс:
Мы не сможем найти любую цитату слово в слово. Потому что из‑за сжатия с потерями наша Википедия сохранена не буквально, а приблизительно. Алгоритм оставил только то, что кровь из носу требуется, чтобы сохранить смысл всех сущностей. Остальное же было объединено и апроксимировано (т. е. передано приблизительно). А значит, чтобы достать информацию, нам нужно создать интерфейс, который умеет в ответ за запрос выдавать основной смысл.
Чувствуете, на этом моменте комнату начинает наполнять знакомый аромат генеративного ИИ?
GPT выдает точные ответы, но есть нюанс...
Да‑да, только что мы мысленно создали большую языковую модель (LLM), обученную на Википедии (в нашем конкретном случае).
ChatGPT — это заблюренный JPEG не только Википедии, но вообще всего интернета. Когда модель дообучают, этот JPEG еще лучше детализируется в отдельных уголках. Но суть все та же — LLM аккумулирует именно бОльшую часть интернета, но далеку не всю.
Следовательно, когда GPT отвечает за ваш запрос, он не может выдать точную последовательность символов. Он сделает приближение. Другое дело, что GPT отлично умеет превращать это приближение в связный и опрятный текст, который человеческий мозг не может сходу отличить от оригинального.
А как LLM воссоздает пробелы, которые отсутствуют в его сжатой версии интернета? Ответ — интерполяция. Не будем вдаваться в математические дебри этой штуки. Простыми словами — это оценка отсутствующего элемента путем анализа того, что находится с двух сторон от этого разрыва. Когда программа обработки изображений декодирует ранее сжатую фотографию и должна восстановить пиксель, потерянный в процессе сжатия, она просматривает близлежащие пиксели и, по сути, вычисляет среднее (генерирует его).
То же самое делает ChatGPT, только со словами и прочими текстовыми смысловыми сущностями. Секрет в том, что ChatGPT научился делать эту интерполяцию настолько мастерски, что люди не могут этого раскусить (и думают, что имеют дело с настоящим интеллектом).
По сути, генеративный ИИ выдумывает отсутствующие элементы на основе смежных. Фантазер этот GPT, получается.

Если теперь вы хотя бы иногда будете вспоминать эту картинку во время написания очередного промпта, то это значит, что я написал эту статью не напрасно :)
Описанная выше логика отлично объясняет «галлюцинации». Просто‑напросто даже самый большой мастер интерполяции иногда допускает ошибки. И совсем периодически эти ошибки замечают. Однако сам факт вероятности ошибок сильно снижает надежность инструмента. Ведь это значит, что в любой момент может вылезти значимый косяк. А это уже означает, что все результаты нужно сверять с оригинальным текстом (= лишние затраты ресурсов).
Получается, генеративный ИИ - это совсем не интеллект?
И да, и нет. Тут, как говорится, смотря как посмотреть.
Действительно, не стоит очеловечивать генеративный ИИ. То есть не нужно отождествлять его с человеческим интеллектом.
ChatGPT впитывает информацию с большими потерями, восстанавливая ее через интерполяцию. В результате он как будто пересказывает суть своими словами. Вероятно, здесь и кроется разгадка, почему люди так восхищаются генеративным ИИ.
Дело в том, что еще со школьных и универских скамей у людей сидит на подкорке убеждение (весьма резонное), что точное воспроизведение информации — удел зубрилок, которые «выучили, но не поняли», а по‑настоящему толковые ребята пересказывают все своими словами, сохраняя суть. Поэтому и ChatGPT нам кажется толковым парнем, который реально все понимает. На самом же деле он просто передает основной смысл, воссоздавая пропуски за счет усреднения.
Именно поэтому, кстати, GPT3 не очень хорошо справлялся с точными вычислениями больших чисел (допустим, выражение «2345 х 57789» в интернете встретишь не так уж часто), но при этом как Боженька писал всякие студенческие эссе. По мере перехода к GPT4 модель стала более продвинутой, в нее завезли больше закономерностей, поэтому она стала сносно щелкать любую арифметику.
Однако, есть и другая сторона медали. Она касается тех самых закономерностей, которых в GPT4 завезли больше. Смотрите:
Есть такая премия под названием «Приз Хаттера». Ее в 2006 г. учредил старший научный сотрудник DeepMind (это ИИ‑стартап, уже давно купленный Гуглом) Маркус Хаттер. Суть конкурса такая:
Есть текстовый файл на английском языке размером 1 Гб. Его требуется сжать без потерь. Каждый, кто сожмет на 1% от предыдущего лучшего результат, получит 5000 евро. Сейчас лучший результат 115 Мб.
На самом деле, это не просто конкурс по сжатию текста без потерь. Это важное упражнение, приближающее понимание сути настоящего ("взрослого") искусственного интеллекта. И вот этого товарища уже можно отождествлять с человеческим сознанием как минимум по одному признаку:
Чтобы наиболее эффективно сжимать текст без потерь, он должен уметь по-настоящему понимать этот текст и сопоставлять его содержание с реальными знаниями о мире.

Маркус Хаттер вскоре после запуска своего конкурса. Кстати, Лекс Фридман записывал с ним интервью еще три года назад. Рекомендую глянуть, если пропустили.
Например, вот есть у нас какая‑то статья в Википедии на тему физики. Допустим, некий текст, где фигурирует Второй закон Ньютона (Сила = Масса x Ускорение). Вероятно, самый простой способ сжать без потерь такую статью — это заложить в алгоритм сжатия базовый постулат, что «Сила = Масса x Ускорение». Тогда алгоритм может выкинуть повторящиеся куски статьи, вытекающие из логики этого закона, а потом легко их восстановить при надобности (потому что знает сам базовый принцип).
Аналогично и со статьей на некую экономическую тему. Наверняка там будет дофига выводов, основанных на законе спроса и предложения. А значит, если в принцип сжатия заложен этот закон, то можно выкинуть кучу «вторичной» информации.
ИИ работает так же. Чем больше первичных правил и законов он знает, тем меньше может париться с запоминанием вторичных выводов (ведь он может их легко восстановить — если и не дословно, то достаточно точно по смыслу).
При таком раскладе ИИ действительно становится интеллектом — в том плане, что делает частные выводы на основе общих знаний. По сути, старая добрая дедукция из детективных романов про Шерлока Холмса.

Всегда догадывался, что этот парень - искусственный интеллект.
Получается, что хотя ChatGPT все еще очень далек от настоящего интеллекта, он все сильнее стремится к таковому по мере наполнения своей базы знаний и лучшей адаптации к устройству нашего мира. Вот такой интересный процесс.
Получается, из-за глюков LLM-кам нельзя доверять так же, как поисковикам (как минимум пока они не усвоят все законы бытия)?
В целом, получается, что да. Пока что нельзя. Ведь:
Во‑первых, мы не знаем наверняка, скушала ли LLM откровенную пропаганду или какие‑нибудь антинаучные теории заговора. Если скушала, то она могла выстроить очень специфические логические связи. И если она будет заполнять пробелы в соответствии с ними, то результат может получиться очень веселым.
Во‑вторых, также нет гарантии, что ИИшный «JPEG» не заблюррил полностью ту информацию, которая нужна для отработки конретно нашего запроса.
Держа в голове эти два обстоятельства, можем сделать вывод — результаты нынешнего генеративного ИИ можно использовать как отправную точку для анализа, но не финальную истину (не стоит сразу же нести выводы от ИИ своему начальнику, ну вы поняли).
Также стоит разобраться — а хорошая ли это идея создавать контент с помощью ИИ?
Ну, если вы работает на объем, то наверно да. А если на качество и уникальность, то не уверен. Ведь даже если вы используете ИИ для получения некой первичной версии, то держите в уме, что холстом вашего великого произведения будет вторичный (изначально переработанный) продукт, где часть смыслов вообще фантазировалась через интерполяцию (иначе говоря — отправной точки ваших смыслов станет совсем уж откровенный полуфабрикат).
Так что, если вы хотите создавать уникальный контент — то, пожалуй, ИИ стоит использовать только для поиска информации, не более. Однако, если ваша задача переупаковать уже готовый контент — то почему бы нет? Особенно если вам нужно избавиться от оков авторских прав и копирайтов (рубрика «вредные советы»).
Выводы
Глюки ИИ — это норма. Иногда они кажутся нам смешными и чересчур упоротыми. Но объяснение лежит на поверхности.
По мере обрастания моделей закономерностями и знаниями о мире, глюков будет все меньше. Если, конечно, мир не будет усложняться с той же скоростью или быстрее.
Полезно учитывать эту особенность при использовании ИИ. Так будет меньше шансов серьезно опростоволоситься в кругу уважаемых людей или испортить качество выдаваемых смыслов.
Когда генеративный ИИ сможет стать Скайнетом? Учитывая вышысказанное, рискну предположить, что еще очень‑очень нескоро. Если вообще сможет.

После осмысления информации выше я теперь представляю Скайнет примерно так ("ути-пути какой хорошенький"). Надеюсь, меня за такое не прикончат первым...
Большая часть этой статьи — художественный перевод вот этой статьи. Очень‑очень вольный перевод — считайте, что я интерполировал кое‑какие смыслы, чтобы воспринимать их было проще и веселее. Статья вышла в феврале 2023, т. е. еще до релиза GPT4, но логику передает верно. Рекомендую прочитать оригинал, там еще больше примеров и иллюстраций (но предупреждаю — понадобится неплохой английский и ясное сознание).
Также рекомендую заглянуть на мой тг‑канал Дизраптор. Там я простым человечьим языком и с максимальной наглядностью пишу про разные интересные штуки из мира технологий, инноваций и бизнеса. В том числе про этот наш ИИ, но не только про него.
Показать полностью
8