Как за 3 месяца сделать систему, которая экономит 5.7 млн в год
Привет, Пикабу! Меня зовут Игорь, я в IT с 2013 года. Последние 2 года пилю автоматизацию с AI.
Короче, к нам пришёл клиент — колл-центр недвижимости. Говорит: "Тратим полтинник в месяц (500 тысяч рублей) на то, чтобы 5 человек вручную чистили персоналку из записей звонков. Можно автоматизировать?"
Сделали за 3 месяца. Теперь экономят 5.7 млн в год. Вот как.
Проблема: передать записи нельзя, штраф 6 млн
Представь: у тебя колл-центр. Записываешь тысячи разговоров в день. Хочешь обучить AI на этих записях, чтобы контролировать качество работы операторов.
Но в разговорах куча персоналки:
ФИО клиентов ("Меня зовут Иван Петров")
Телефоны ("+7 915 234-56-78")
Адреса ("Проспект Мира, дом 127, квартира 45")
Паспортные данные, ИНН, СНИЛС
Передать эти записи подрядчику (ML-команде, аналитикам) без анонимизации — утечка персональных данных.
Штраф по ФЗ-152: До 6 млн рублей + блокировка сайта.
В Европе ещё веселее (GDPR): до €20 млн или 4% годового оборота — что больше.
Как обычно решают: нанять людей
Наняли 5 человек. Платят по 100к в месяц каждому. Итого: 500 тысяч в месяц улетает.
Что они делают: Вручную читают транскрипты звонков, заменяют имена на [ИМЯ], телефоны на [ТЕЛЕФОН], и так далее.
Производительность: 20-30 документов в день на человека. Всей командой — 100-150 документов в день.
Проблемы:
Медленно: У клиента 1000+ документов в день, не успевают
Дорого: 500к/мес = 6 млн/год на зарплаты
Ошибки: Человек устал, пропустил номер телефона → утечка ПД → штраф 6 млн
Вопрос: можно ли это автоматизировать?
Наше решение: ChamelOn
Мы сделали систему ChamelOn — автоматическая анонимизация персональных данных.
Время разработки: 3 месяца от ТЗ до production (работающей версии).
Что получилось:
Жрёт 50-60 документов в секунду (против 20-30 в день вручную)
Точность 92-96% (98%+ для телефонов и email)
Стоимость: только сервер (~20к/мес)
Экономия: 480 тысяч в месяц = 5.7 млн в год
Для сравнения:
Человек: 20-30 документов в день
ChamelOn: 50-60 документов в секунду
Разница — в тысячи раз.
Как оно работает (для чайников)
Что детектируем
ChamelOn ищет 9+ типов персональных данных:
ФИО: "Иван Петров", "Мария Сидорова"
Телефоны: "+7 915 234-56-78", "8-916-123-45-67"
Email: "user@example.com"
Адреса: "Проспект Мира, дом 127"
Города: "Москва", "Санкт-Петербург"
Паспорта: "Серия 4518, номер 234567"
ИНН: "771234567890"
СНИЛС: "123-456-789 01"
Telegram: "@username"
Как анонимизируем (4 способа)
1. Редактирование (полное удаление):
Было: "Меня зовут Иван Петров, телефон +7 915 234-56-78"
Стало: "Меня зовут [ИМЯ1], телефон [ТЕЛЕФОН1]"
2. Маскирование (частичное скрытие):
Было: "Иван Петров, +7 915 234-56-78"
Стало: "И*** П*****, +7 9** ***-**-78"
3. Псевдонимизация (замена на фейковые данные):
Было: "Иван Петров, +7 915 234-56-78"
Стало: "Алексей Смирнов, +7 916 987-65-43"
4. Обобщение (замена на категорию):
Было: "Иван Петров, +7 915 234-56-78"
Стало: "мужское имя, мобильный номер"
Технологии
Ну вот тут совсем кратко (без занудства):
Backend: Node.js (бекенд)
Frontend: React (веб-интерфейс)
Детекция:
Regex паттерны (ищут номера/email)
ML модели (Natasha NER для русских имен)
Словари (60 тысяч фамилий, 28 тысяч имен)
Короче, комбинация правил + машинное обучение.
Где мы налажали (косяки разработки)
Теперь самое интересное. Первая версия работала отлично... на тестовых данных. А когда клиент дал реальные записи — началось веселье.
Косяк #1: Разорванные телефоны
Проблема: Клиенты диктуют номер телефона не целиком, а по кускам. Паузы в речи. Повторы. Переспросы.
Пример из реальных записей:
Оператор: "У вас WhatsApp есть на этом номере?"
Клиент: "Вы 7868 звоните, да?"
Оператор: "Нет, я звоню 963-824-487, а на какой номер мне позвонить?"
Клиент: "Лучше 914-218-7868, там WhatsApp."
Оператор: "7868. Алексей, да?"
Видишь? Полный номер — +7 914 218-7868. Но он разбит на три части: "7868", "914-218-7868", "7868".
Базовый regex такое не ловит. Он ищет номер целиком, а тут куски по всему тексту.
Что сделали: Написали Context-aware Phone Detector — анализирует контекст вокруг чисел. Если видит слова "номер", "позвонить", "WhatsApp" рядом с числами — собирает их вместе.
Результат: Точность для разорванных номеров выросла с 40-50% до 85-90%.
Первую неделю детектор ловил всякую хрень типа "Проспект Мира 127" как номер телефона. Пришлось добавлять фильтры.
Косяк #2: Ошибки распознавания речи
Проблема: Клиент использует ASR (автоматическое распознавание речи), чтобы превращать звонки в текст. ASR делает ошибки — особенно с именами и городами.
Примеры из жизни:
"Меня зовут Юлия" → "Меня зовут Юля зовут" (дубль слова)
"Наталья Усанина" → "Наталья Усаниной" (опечатка)
"В Макеевку" (город) → "В Матеевке" (ASR не знает города)
Наш детектор ищет "Юлия" в словаре имён — находит. А "Юля зовут" — не находит, потому что это не имя, а косяк транскрибации.
Что сделали: Добавили Fuzzy Matching (нечёткий поиск) + обработку склонений. Теперь детектор понимает: "Усанина" и "Усаниной" — это одна фамилия в разных падежах.
Результат: Пропущенные ПД снизились с 8-10% до 5-7%.
Косяк #3: Контекстная зависимость
Проблема: Одно слово может быть персоналкой или НЕ персоналкой — зависит от контекста.
Пример 1: "Мира" (топоним или имя?)
Контекст А:
"Один на проспекте Мира, дом 127"
"Мира" тут — это проспект, не имя. Пропускаем.
Контекст Б:
"Меня зовут Мира"
"Мира" тут — это имя. Детектируем как [ИМЯ].
Первую неделю детектор анонимизировал "проспект Мира" везде. Получалось: "проспект [ИМЯ], дом 127". Бред.
Что сделали: Добавили фильтрацию адресных контекстов. Если рядом со словом "Мира" есть "проспект", "улица", "дом" — это топоним, пропускаем.
Результат: Ложные срабатывания упали с 12-14% до 5-7%.
Другие применения (где ещё полезно)
ChamelOn делали для колл-центра, но применимо и в других местах.
1. Медицина: исследования без раскрытия личности
Ситуация: Нужно провести научное исследование на данных пациентов.
Проблема: Этический комитет не одобрит, если истории болезни содержат ФИО, адреса, паспорта.
Решение: Анонимизировать истории болезни — оставить симптомы, диагнозы, но удалить личность.
Результат: Публикуешь исследование без риска судебных исков.
2. HR: анонимные резюме против предвзятости
Ситуация: Рекрутер смотрит резюме. Видит ФИО, возраст, фото.
Проблема: Эта информация влияет на решение. ФИО "Магомед" → пропускают. Возраст 50+ → пропускают. Фото "не того вида" → пропускают.
Решение: Анонимные резюме — убрать ФИО, возраст, фото. Оценивать только скиллы.
Результат: Увеличение разнообразия нанимаемых на 15-20%.
3. DevOps: копировать production базу в test без утечки
Ситуация: Нужно скопировать production базу данных в staging для тестирования.
Проблема: В production есть реальные клиенты с реальными данными. Копировать как есть — утечка ПД.
Решение: Анонимизировать дамп БД перед копированием.
Результат: Тестируешь на реальных данных без риска штрафов.
4. Юристы: публиковать кейсы без палева
Ситуация: Юридическая фирма хочет опубликовать кейс для маркетинга.
Проблема: Документы полны конфиденциальных данных клиентов.
Решение: Анонимизировать документы перед публикацией.
Результат: Показываешь свою работу без судебных исков.
Лайфхак: Как законно использовать западные сервисы с российскими ПД
Ну вот тут самое интересное. Многие российские компании хотят использовать западные AI-сервисы (OpenAI, Claude, Google Cloud), но упираются в проблему: нельзя передавать персональные данные россиян на зарубежные серверы без специальных условий.
Что говорит закон (ФЗ-152)
Статья 12: Персональные данные граждан РФ должны обрабатываться на серверах в России.
Исключение: Можно передать на зарубежные серверы, если:
Есть согласие субъекта персональных данных
ИЛИ данные обезличены (анонимизированы)
Штраф за нарушение: До 6 млн рублей + блокировка.
Проблема на практике
Ситуация: Ты хочешь использовать OpenAI API для анализа клиентских заявок, обучения чат-бота, классификации обращений.
Но в заявках персоналка: ФИО, телефоны, email, адреса доставки.
Вопрос: Как отправить это в OpenAI, не нарушая закон?
Решение: Анонимизация перед отправкой
Схема:
1. Клиентская заявка (с персоналкой)
2. ChamelOn анонимизирует (на твоём российском сервере)
3. Анонимизированные данные отправляются в OpenAI/Claude
4. AI обрабатывает, возвращает результат
Реальные use cases
Use Case #1: Обучение чат-бота на клиентских диалогах
Проблема: У тебя 10,000 диалогов с клиентами. Хочешь обучить чат-бота (fine-tuning OpenAI), но в диалогах куча персоналки.
Решение:
Прогоняешь диалоги через ChamelOn → анонимизируешь
Отправляешь анонимизированные диалоги в OpenAI для обучения
Обученная модель не знает реальных ФИО/телефонов, только метки
Результат: Ты используешь OpenAI легально, не нарушая ФЗ-152.
Use Case #2: Транскрибация звонков через Google Cloud Speech-to-Text
Проблема: Google Cloud Speech-to-Text работает отлично (лучше российских аналогов), но записи звонков содержат персоналку.
Решение:
Вырезаешь фрагменты с персоналкой (ФИО, телефоны) ДО отправки в Google
ИЛИ отправляешь как есть, но потом анонимизируешь транскрипт на своём сервере
Результат: Google обрабатывает аудио без персоналки, ты получаешь транскрипт и чистишь его локально.
Use Case #3: Аналитика клиентских отзывов через Claude API
Проблема: Хочешь анализировать отзывы клиентов на тональность/проблемы через Claude, но в отзывах ФИО, телефоны, email.
Решение:
Анонимизируешь отзывы через ChamelOn
Отправляешь в Claude API
Получаешь аналитику: "70% отзывов негативные из-за долгой доставки"
Результат: Claude обрабатывает отзывы без персоналки, ты получаешь инсайты легально.
Важные нюансы
1. Анонимизация != Псевдонимизация для закона
ФЗ-152 считает:
Анонимизация (обезличивание) — данные НЕЛЬЗЯ восстановить → можно передавать
Псевдонимизация — данные МОЖНО восстановить по ключу → всё ещё ПД, нельзя передавать без согласия
Для OpenAI/Claude используй: Redaction ([ИМЯ], [ТЕЛЕФОН]) или Generalization ("мужское имя", "мобильный номер").
НЕ используй для зарубежных серверов: Псевдонимизацию (замена на фейковые данные), если хранишь маппинг для восстановления.
2. Согласие субъекта (альтернатива)
Если нужно передавать данные как есть (без анонимизации), можешь запросить согласие:
"Я согласен на передачу моих персональных данных на серверы OpenAI (США) для целей обработки заявки."
Но это геморрой:
Нужно собирать согласия со всех клиентов
Клиенты могут отказаться
Юридическая волокита
Проще анонимизировать и не париться.
3. Хранение данных
Важно: Анонимизация происходит на твоём сервере (в России). Только анонимизированные данные уходят за границу.
Нельзя: Отправить сырые данные в OpenAI, а потом сказать "мы их анонимизировали там". Роскомнадзор пошлёт.
Итоги: Западные сервисы + ФЗ-152 = Возможно
Схема работы:
Персональные данные → твой российский сервер (ChamelOn анонимизирует)
Анонимизированные данные → OpenAI/Claude/Google Cloud (обрабатывают)
Результат → возвращается тебе, деанонимизация (если нужно) на твоём сервере
Легально: Да, потому что западные серверы НЕ получают персональные данные (только метки).
Эффективно: Да, потому что используешь лучшие AI-модели мира.
Дёшево: Да, потому что анонимизация стоит копейки (20к/мес на сервер против 500к/мес на ручную работу).
Короче: Анонимизация — это не только про защиту от штрафов. Это про возможность использовать крутые западные AI-сервисы, не нарушая российский закон.
Почему не используем LLM (большие AI-модели)?
Вопрос: Почему ChamelOn не использует ChatGPT/Claude для детекции персоналки?
Ответ: Потому что это медленно и дорого.
Сравнение:5. Деанонимизация (если нужно восстановить связь)
Пример:
До анонимизации (на твоём сервере):
"Добрый день! Меня зовут Иван Петров, телефон +7 915 234-56-78. Хочу заказать доставку по адресу: Москва, проспект Мира, дом 127."
После анонимизации (отправляешь в OpenAI):
"Добрый день! Меня зовут [ИМЯ1], телефон [ТЕЛЕФОН1]. Хочу заказать доставку по адресу: [ГОРОД1], [АДРЕС1]."
OpenAI видит: Нет персональных данных, только метки [ИМЯ1], [ТЕЛЕФОН1].
Классифицирует: "Заявка на доставку, город: столица, тон: вежливый".
Возвращает тебе: Результат классификации.
Если нужно восстановить: У тебя есть маппинг [ИМЯ1] = Иван Петров, [ТЕЛЕФОН1] = +7 915 234-56-78 (хранится на твоём сервере).
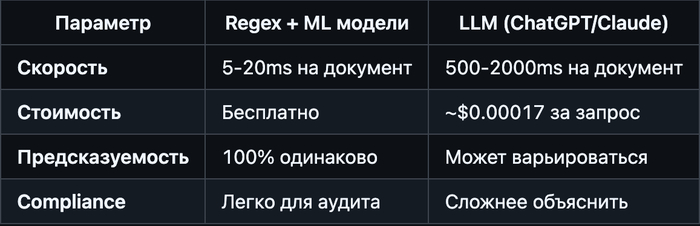
В 25-100 раз медленнее. Для 1000 документов в день это критично.
НО: Планируем добавить LLM для валидации (не для основной работы).
Идея:
Stage 1: Regex + ML ищут персоналку (быстро, 5-20ms)
Stage 2: LLM проверяет результат, находит пропущенное (медленно, но опционально)
Stage 3: Админ смотрит предложения LLM, подтверждает или отклоняет
Пример:
Оригинал: "Звонила Татьяна, сказала приехать на Кутузовский"
Stage 1 (Regex): "Звонила [ИМЯ], сказала приехать на Кутузовский"
(Пропущен "Кутузовский" — проспект, адрес)
Stage 2 (LLM): "Нашёл пропущенное: Кутузовский (адрес, уверенность 85%)"
Stage 3 (Человек): Админ подтверждает → добавляется в чёрный список
Следующий раз: "Звонила [ИМЯ], сказала приехать на [АДРЕС]"
(Теперь анонимизируется автоматически!)
Стоимость LLM интеграции: ~$1.70/месяц (~170 рублей) для 10,000 запросов.
Экономия на ручной работе: ~21,000 рублей.
ROI: 21,000 / 170 = 123x возврат.
Релиз планируем на Q1 2026.
Итоги: автоматизация vs ручная работа
Ручная анонимизация:
Стоимость: 500 тысяч рублей/мес
Производительность: 20-30 документов/день на человека
Риск: Пропустил ПД → штраф 6 млн
ChamelOn:
Стоимость: 20 тысяч рублей/мес (только сервер)
Производительность: 50-60 документов/сек
Точность: 92-96%
Экономия: 5.7 млн рублей/год
Время разработки: 3 месяца от ТЗ до production.
Compliance: ChamelOn помогает соблюдать GDPR (Европа), ФЗ-152 (Россия), HIPAA (США, медицина).
Масштабируемость: От 10 до 10,000 документов в день без изменений архитектуры.
Дисклеймер: Ожидаемая критика
Я понимаю, что пост вызовет критику. "Зачем автоматизация, если есть ручная работа?", "AI делает ошибки, лучше доверять людям", "Это замена специалистов".
Моё мнение: Эта критика больше про страх смешанный с высокомерием, чем про технические аргументы.
Страх: "Если AI может анонимизировать данные, что будет с моей работой?"
Высокомерие: "Только люди могут правильно обрабатывать данные, AI — это игрушка."
Реальность: AI не заменяет хороших специалистов. Он их усиливает. ChamelOn не про замену людей — это про автоматизацию рутины, ускорение процессов и снижение человеческих ошибок.
Факты:
Ручная анонимизация: 20-30 документов/день, риск пропустить ПД
ChamelOn: 50-60 документов/сек, 95% точность, полный аудит
Не согласен? Отлично. Напиши мне в Telegram, обсудим технические детали. Предпочитаю технические аргументы эмоциональным реакциям.
P.S. У меня есть телеграм-канал, где я пишу про разработку, всякое айтишное, а иногда бизнесовое. Давления никакого — просто если вдруг интересно: t.me/maslennikovigor
Игорь Масленников AI Dev Team | DNA IT В IT с 2013 года