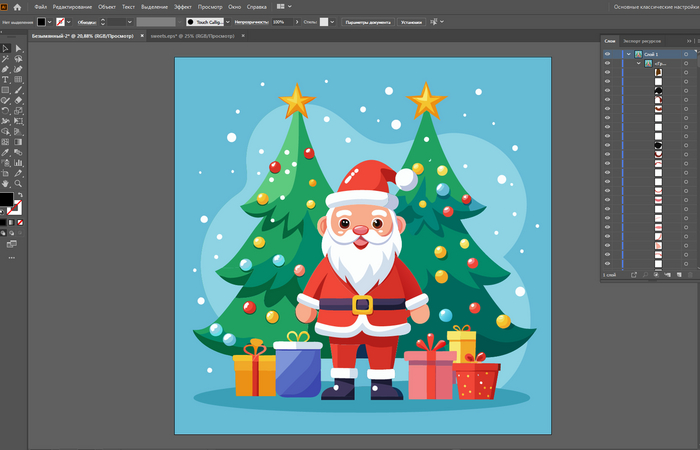
Как же все-таки классно, что появляются новые возможности, которые значительно ускоряют работу художников, дизайнеров. Сегодня хочу поделиться с вами, где и как можно создать с нуля векторную иллюстрацию и выгрузить ее в SVG-формате для дальнейшей отправки на сток, например. Все очень просто, поэтому справится любой новичок без какого-либо опыта.
Платформа Рекрафт позволяет делать не только растровые, но и векторные изображения. Причем она не просто воссоздает векторный стиль визуально, но и позволяет вывести файл сразу в SVGформате. И еще большой плюс, бесплатно здесь можно работать сколько угодно.
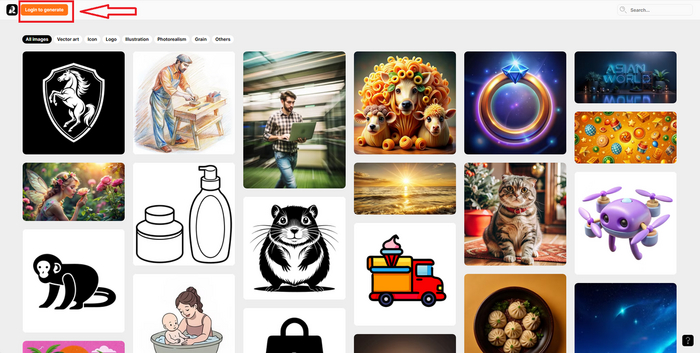
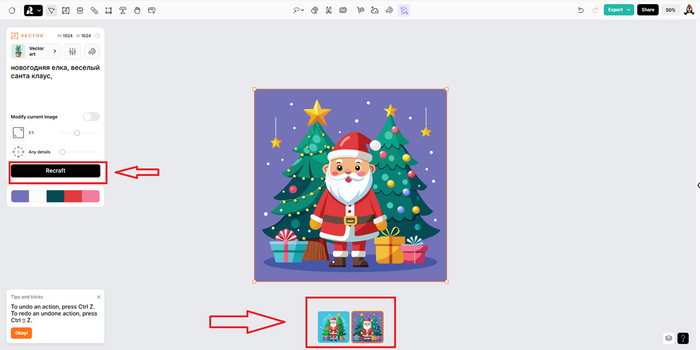
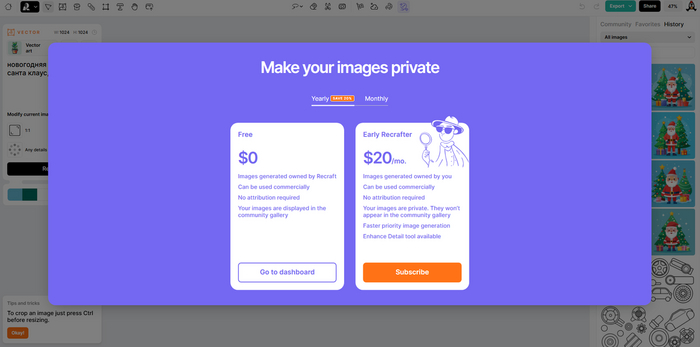
Первое, что мы видим, когда заходим на платформу, на картинке ниже. Проходим обычную регистрацию через гугл аккаунт.
Дальше видим это, создаем новые проект:
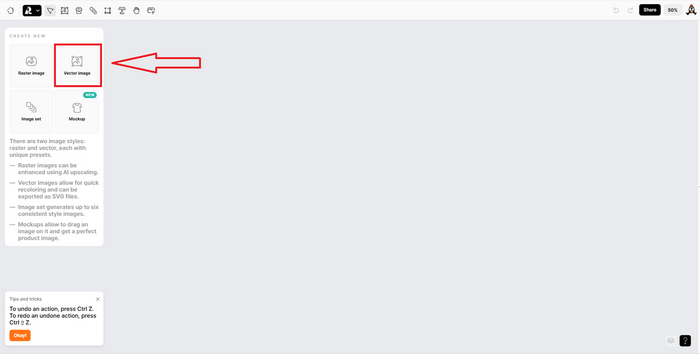
Теперь нам дается выбор, с каким изображением дальше работаем. Видим 4 варианта: растровые картинки (здесь фотореализм, иллюстрации), векторные (иконки, логотипы, рисунки от руки), набор векторных изображений и мокап продукта (то, как картинка будет выглядеть на каком-либо предмете). Сегодня я делаю новогоднюю векторную иллюстрацию. Иду туда.
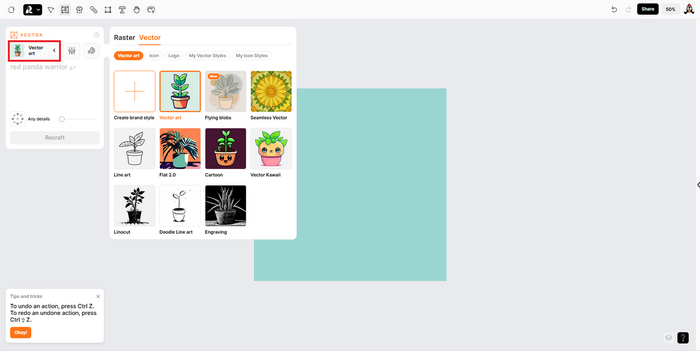
Предлагается несколько вариантов стилей, я выбираю векторный рисунок. Рядом расположены настройки, где вы можете прописать негативный запрос. Еще правее вы видите значок палитры, там можно настроить цветовую гамму и фон. А ниже под этим всем большое поле для промта, выбор соотношения сторон и уровень детализации. Все понятно наглядно и интуитивно. Запрос здесь можно писать на русском языке, что значительно облегчает задачу.
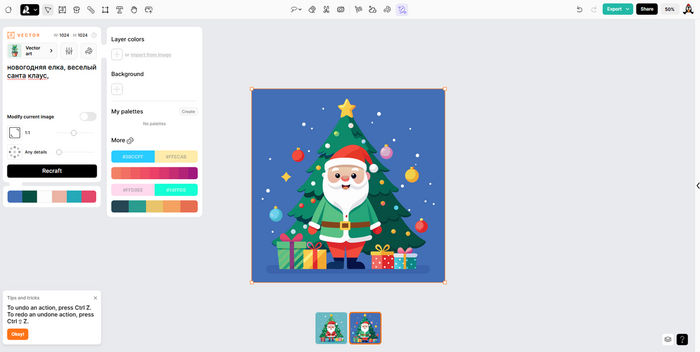
Проставили нужные настройки, жмем кнопку Recraft, которая находится под промтом. Ждем несколько секунд, после чего сервис выдает вам 2 готовых арта.
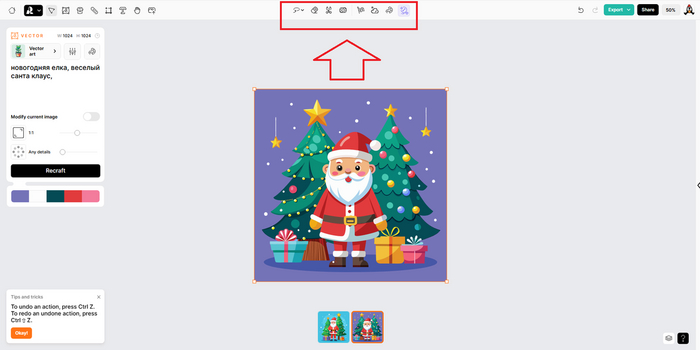
Над картинкой есть инструменты, позволяющие улучшить изображение при необходимости. Здесь можно перерисовать или стереть часть изображения, удалить или заменить фон, перекрасить картинку или увеличить разрешение. Правда не все функции доступны бесплатно. Впрочем, апскейл изображения можно бесплатно сделать ТУТ.
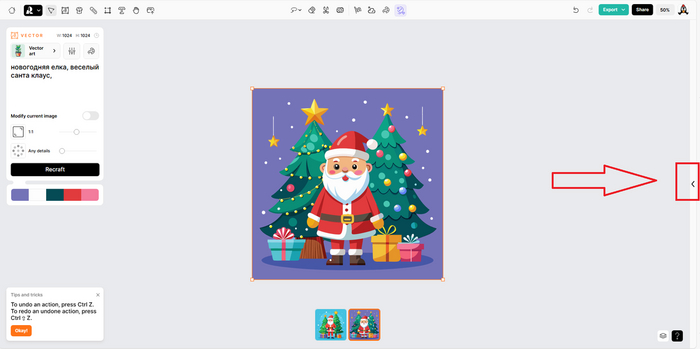
Чтобы войти в историю ваших генераций, нужно открыть панель на стрелочку слева и выбрать вкладку History. Здесь же во вкладке Community можно ознакомиться с работами других пользователей.
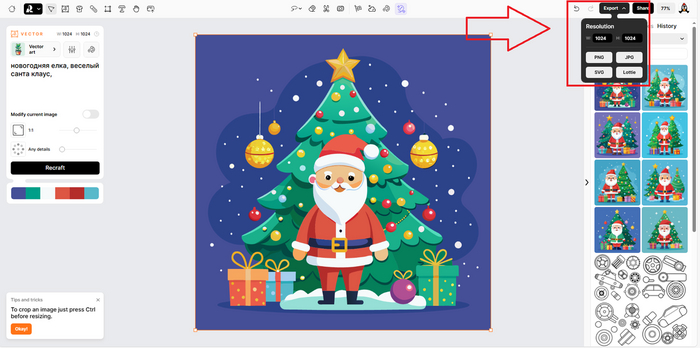
Картинка готова, экспортируем ее себе на устройство. Для скачивания доступно несколько форматов, включая векторный SVG.
Выбираем нужный формат. Для загрузки на сток мне нужен EPS. Для дальнейшей работы можно пойти в Адоб Иллюстратор, доправить по-быстрому если требуется более детально, подогнать до нужного размера и сохранить так же в EPS или любом другом формате. Рекрафт позволяет использовать изображения в коммерческих целях даже в бесплатном тарифе.
Ну вот и все. Новогодняя иллюстрация отправилась на сток.
Ставь обратную реакцию, если статья оказалась полезной для тебя и залетай ко мне в Тг-канал, где ежедневно ты будешь получать новые ссылки на полезные нейронки, интересные промты и инфу о нейроартах.
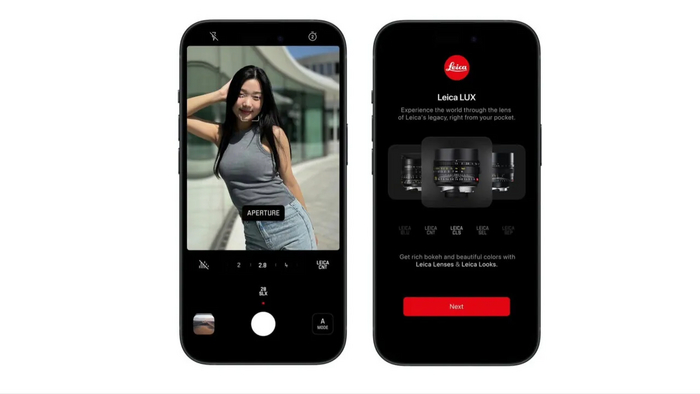
Leica представила новое приложение для iPhone, что означает, что теперь пользователи этого устройства смогут пользоваться технологиями Leica.
Xiaomi до сих пор была единственной компанией с официальным брендингом Leica, но теперь у владельцев iPhone появится возможность испытать нечто похожее.
Приложение LUX от Leica создано для того, чтобы имитировать ощущения от использования объективов Leica. Это достигается благодаря сочетанию программных решений и искусственного интеллекта.
Приложение предлагает 11 различных цветовых профилей, которые соответствуют современным камерам Leica, а также классическим моделям. В нем предусмотрен полностью автоматический режим камеры, аналогичный встроенной камере Apple, а также режим диафрагмы, который с помощью искусственного интеллекта имитирует стиль, боке и диафрагму таких объективов, как Summilux-M 35mm f/1.4 ASPH.
Хотя приложение Leica бесплатное, в нем доступно лишь пять цветовых профилей и одна имитация объектива. Чтобы разблокировать все профили, объективы и другие более продвинутые функции, потребуется заплатить $6.99 в месяц или $69.99 в год.
Добавление функций Leica в iPhone — значительное событие для поклонников этого бренда. Ранее единственным способом получить технологии Leica на мобильном устройстве было приобрести смартфон Xiaomi. Вопрос лишь в том, насколько хорошо эти функции работают на практике.
Хотя приложение для iOS неплохо справляется с задачей имитации, быстрый обзор снимков, сделанных с его помощью, показывает незначительные проблемы, такие как артефакты изображения и зазубренные края. Возможно, эти недостатки будут устранены в будущих обновлениях, но без более тесного сотрудничества с Apple всегда будут некоторые ограничения. Тем не менее, это наиболее близкий к оригиналу опыт использования Leica на iPhone.
На данный момент Leica Lux доступно только для пользователей iPhone через App Store, но в будущем, возможно, появится и версия для Android. Надеемся на это.
Не так давно компания Google представила свою лучшую нейросеть - Gemini.
Gemini - прямой конкурент ChatGPT. Это не просто конкурент, Gemini через некоторое время будет плотно интегрирован в Android и займёт место голосового ассистента, а также возьмёт на себя множество рутинных операций.
Сейчас он представлен в первой итерации, и для его работы необходимо подключение к интернету.
Но пройдёт всего один-два года, телефоны получат новые чипы с интегрированными NPU.
NPU (Neural Processing Unit) в телефонах - это специализированный процессор или ускоритель, предназначенный для ускорения работы алгоритмов искусственного интеллекта и машинного обучения на мобильных устройствах.
И возможности Gemini сильно расширятся.
И если бы не всем известные события, мы бы тоже получили Gemini, но для нас его искусственно ограничили.
Но, ограничивать сильно не старались, лишь выполнили формальное требование уважаемых людей.
Поэтому обойти ограничение легко, достаточно выполнить всего три действия на телефоне.
Ниже я покажу, как установить Gemini и пользоваться им каждый день без ограничений, и даже VPN устанавливать не придётся.
Как установить Gemini на Xiaomi без VPN
Текстовая версия инструкции. Показываю на примере Xiaomi. Если у вас телефон другого вендора делайте поправки на название функций и их расположение:
Откройте общие настройки телефона, найдите пункт меню "Другие способы подключения".
Найдите строку "Частный DNS-сервер".
Выберите вариант "Имя хоста провайдера DNS".
Впишите следующий адрес: "comss.dns.controld.com" (Кстати, этот DNS позволит пользоваться и ChatGPT без VPN, а также уберёт большую часть рекламы с телефона). Этот адрес должен использоваться всегда, его убирать не надо, иначе Gemini работать не будет.
Теперь вернитесь в главное меню телефона, найдите "Расширенные настройки".
Далее "Язык и ввод".
Выберите английский язык для смартфона (English Unites States). После установки Gemini и проверки его работоспособности можно вернуть русский язык.
Снова вернитесь в общие настройки, найдите пункт "Google".
Теперь выберите меню "Настройки для приложений Google".
Далее "Поиск, Ассистент и голосовое управление".
Теперь "Google Ассистент".
Далее "Языки".
Добавьте английский язык "English (Unites States)".
Выберите самую новую версию, на момент написания это версия от 22 апреля и нажмите на иконку "Стрелка вниз".
На новой странице найдите раздел "Download Google Gemini" и в правом столбце снова нажмите на иконку "Стрелка вниз".
Чуть пролистайте страницу вниз, увидите большую голубую кнопку "Download APK", нажмите на неё, начнётся загрузка установочного файла.
После завершения загрузки запустите файловый менеджер, в случае с Xiaomi это "Проводник".
Перейдите в раздел "APK", вы увидите установочный файл приложения, запустите установку. Если появится предупреждение о том, что для установки необходимо дать права, сделайте это.
НЕ ЗАПУСКАЙТЕ приложение сразу после установки. В начале надо проверить, что все настройки вы сделали правильно, для этого В БРАУЗЕРЕ откройте сайт gemini.google.com. Если вы видите приветствие с кнопкой "Начать чат с Gemini", значит, всё сделали правильно. Теперь можно запустить приложение Gemini и пользоваться им без ограничений.
Если вы видите сообщение о том, что в вашей стране запуск Gemini ещё не произведён, значит, скорее всего, вы допустили ошибку в установке DNS. Вернитесь к этому пункту и выполните его ещё раз.
Запустите Gemini, проверьте, что он работает. Если так, то можно вернуть русский язык в телефон.
Надеюсь, теперь ваше погружение в мир современных нейросетей станет более глубоким и интересным.
Если по необычайному стечению обстоятельств вам стало любопытно, есть ли ещё подобные лайфхаки для смартфонов Xiaomi - добро пожаловать на MetaMi.
Для тех, кто не хочет смотреть видео, текстовая инструкция:
Перейдите на сайт yoursearch.ai с мобильного браузера, или на ПК
Найдите плитку с надписью "Yoursearch Telegram" и нажмите на неё
Запустится приложение Telegram, где появится бот поискового сервиса
Нажмите на кнопку "Старт"
Введите любой поисковый запрос и подождите несколько секунд
Удобно то, что поиск вы осуществляете из мессенджера, и оттуда же потом легко поделиться результатом с собеседником: просто переслать, или скопировать нужную часть ответа.
Пользуйтесь интеллектуальным поиском, хватит терять время на ручную модерацию десятков сайтов.
Если по необычайному стечению обстоятельств вам стало любопытно, есть ли ещё подобные лайфхаки для смартфонов Xiaomi - добро пожаловать на MetaMi.
Всё больше в жизнь проникают нейросети, как в виде чат-ботов, так и в виде алгоритмов, которые работают в привычных нам приложениях.
Не всегда мы можем повлиять на то, как используются данные, которые обрабатываются нейросетями.
Некоторые работают локально, но очень много людей используют облачные сервисы, основанные на Ai.
Особенность нейросетей заключается в том, что для того, чтобы они оставались конкурентоспособными их должны постоянно тренировать и дообучать. Иначе они очень быстро отстанут от конкурентов.
Легче всего брать данные для дообучения из результатов беседы нейросети с людьми.
Уверен, не все люди горят желанием отдавать свои личные данные крупным корпорациям, да ещё бесплатно.
Ладно ещё, если вы спрашивали у ChatGPT какой-то рецепт блюда, или как заменить масло в двигателе автомобиля. Но не забывайте, что ChatGPT способен анализировать фото, видео и текстовые документы. Поэтому эту нейросеть часто используют в компаниях для работы, "скармливая" Ai информацию, которая вообще не должна быть общедоступной.
Для того, чтобы данные пользователя не использовались для дальнейшего обучения ChatGPT, а также для гарантированного их удаления с серверов, есть два режима у этого чат-бота. И я покажу, как их включить.
Как включить режим инкогнито при работе с ChatGPT
Для тех, кто не хочет смотреть видео, оставлю текстовую инструкцию:
Откройте интерфейс ChatGPT в браузере
Нажмите на название "ChatGPT" в верхней части экрана
Появится меню, в котором увидите переключатель "Временный чат". Включив его вы добьётесь двух целей: беседа будет гарантированна удалена через 30 дней и данные не будут использованы для обучения алгоритмов.
Есть ещё один метод: войдите в настройки аккаунта, найдите вкладку "Элементы управления данными" и в нём отключите пункт "Улучшить модель для всех". Эта опция отвечает за разрешение использовать данных, которые вы предоставили ChatGPT для анализа, а также вашу беседу с ботом для дальнейшего обучения.
Надеюсь, вам были полезны эти знания. Теперь вы можете быть спокойны - ChatGPT не будут использовать вашу информацию для дообучения бота.
Конечно, это всё по заявлению компании OpenAI. Как дела обстоят на самом деле мы не знаем.
Если по необычайному стечению обстоятельств вам стало любопытно, есть ли ещё подобные лайфхаки для смартфонов Xiaomi - добро пожаловать на MetaMi.
Нейросеть способна быть полноценным репетитором и говорить на разных языках,что вызвало резкое снижение акций компании. Эксперты считают,что OpenAI фактически убила несколько языковых профессий.
Похоже, теперь совёнку Дуо придётся самому искать репетитора.
Для всех поклонников футбола Hisense подготовил крутой конкурс в соцсетях. Попытайте удачу, чтобы получить классный мерч и технику от глобального партнера чемпионата.
А если не любите полагаться на случай и сразу отправляетесь за техникой Hisense, не прячьте далеко чек. Загрузите на сайт и получите подписку на Wink на 3 месяца в подарок.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
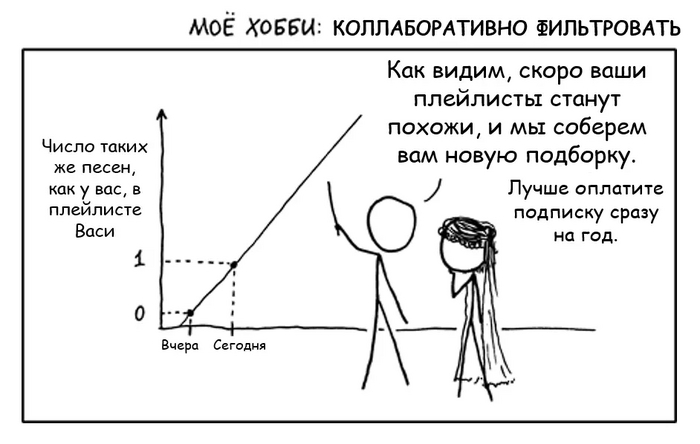
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.