Привет! Сегодня мы расскажем тебе о нейросети Chat GPT и поможем разобраться, как она работает. Chat GPT — это мощный инструмент, который сможет помочь тебе в поиске бизнес-идей и заработке. Мы погрузимся в основы работы Chat GPT, чтобы ты лучше понимал, как использовать его возможности на практике. Готов начать? Тогда давай приступим!
Chat GPT - это умный помощник, созданный компанией Open AI. Это особый вид искусственного интеллекта, который может общаться с тобой на понятном языке и создавать тексты по твоим запросам. Ты можешь использовать Chat GPT для разных задач: написания статей, ответов на вопросы или даже поиска идей для бизнеса и их реализации.
Chat GPT - это инструмент, специально разработанный для формирования текстовых ответов на пользовательские вопросы. Обучение этой модели основано на обработке огромного количества текстовых данных из интернета, объем которых составляет 420 Гб. Эта информация "поглощена" нейронной сетью, зафиксирована в ее структурах, и теперь при получении запроса, она анализирует его на основе накопленной информации, формируя соответствующий ответ. Это во многом напоминает работу человеческого мозга, хотя и не обладает таким же уровнем совершенства.
Несмотря на то, что объем знаний Chat GPT превышает объем знаний среднестатистического человека, нейросеть еще сталкивается с некоторыми ограничениями в понимании и интерпретации информации из-за текущих технологических ограничений. Однако с увеличением количества узлов, параметров и данных для обучения, способности нейросети будут продолжать увеличиваться.
Слово "Chat GPT" обозначает конкретную нейронную сеть. Она основана на архитектуре Transformer, которая используется для построения моделей, способных работать с текстовыми данными. На основе этой архитектуры создаются и другие нейронные сети для обработки текстов. Особенностью Chat GPT является то, что она была обучена на наибольшем возможном объеме данных и имеет значительные вычислительные ресурсы, что делает ее более совершенной по сравнению с другими моделями.
Одной из ключевых функций Chat GPT является способность запоминать предыдущие запросы пользователя и свои ответы на них. Это дает ей возможность работать с контекстом, поддерживая непрерывный диалог, вместо выдачи нового, не связанного ответа на каждый вопрос.
Основные понятия о определения
1. Chat GPT: Это продукт компании Open AI, основанный на технологии искусственного интеллекта, который способен общаться на понятном языке, генерировать тексты по запросам пользователя и использоваться для различных задач, включая написание статей, ответы на вопросы и поиск идей для бизнеса.
2. Искусственный интеллект (AI): Технология, которая имитирует человеческие способности, такие как обучение, понимание и анализ данных. AI используется в Chat GPT для анализа ввода пользователя и генерации соответствующего текстового ответа.
3. Нейронная сеть: Компьютерная система, вдохновленная биологическими нейронными сетями, составляющими человеческий мозг. Chat GPT основан на нейронной сети и использует ее для обучения и анализа больших объемов текстовых данных.
4. Архитектура Transformer: Модель машинного обучения, основанная на аттенции, которая используется для работы с последовательностями данных, такими как текст. Она является основой для Chat GPT и других современных моделей обработки естественного языка.
5. Обучение с учителем: Тип машинного обучения, где модель обучается на основе большого количества данных, которые были заранее размечены. Chat GPT обучается на большом объеме текстовых данных из интернета.
6. Контекст: Важность учета предыдущих запросов и ответов в диалоге для понимания текущего запроса. Это особенно важно для Chat GPT, который использует предыдущие обмены для формирования своих ответов.
7. Технологические ограничения: Ограничения в текущих технологиях AI, которые могут влиять на способность Chat GPT полностью понимать и интерпретировать запросы. Несмотря на эти ограничения, способности AI продолжают улучшаться с развитием технологии.
8. Обучение: Chat GPT учится на большом количестве текстов, взятых из разных источников, например, сайтов, книг или статей. Таким образом, он узнает, как устроен язык, как правильно строить предложения и какие слова обычно идут вместе. Благодаря этому обучению, Chat GPT может понимать и создавать тексты, которые будут казаться написанными человеком.
9. Предсказание слов: Chat GPT умеет предугадывать, какое слово или фраза должны следовать после уже написанных слов. Это позволяет ему создавать связные и интересные тексты, основываясь на том, что ты ему говоришь или пишешь.
10. Адаптация: Chat GPT может "настроиться" на конкретную задачу или область знаний, если его дополнительно обучить на специальных данных. Таким образом, он становится еще более точным и полезным в определенных ситуациях.
Рассмотрим наглядный пример, который может быть понятен ученику 7 класса:
1. Токенизация: Помни, что текст состоит из предложений, а предложения – из слов. Токенизация – это процесс разбиения предложений на отдельные слова или даже части слов для упрощения обработки текста. Можешь представить это как разделение нити с бусами на отдельные элементы.
2. Обработка: Затем эти "элементы" (токены) проходят через сложную систему трансформеров. Трансформеры – это продвинутые алгоритмы, которые анализируют контекст и выявляют связи между словами. Представь их как муравьев, которые переносят бусины по своим маршрутам, учитывая взаимосвязь между ними.
3. Генерация: После анализа контекста модель создает новую последовательность токенов (бусин), которая является наиболее подходящим и релевантным ответом на вопрос или запрос. Это как если бы муравьи завершили свою работу и сложили бусины в новый порядок, который отвечает на твой вопрос.
4. Декодирование: Полученные токены (бусины) превращаются обратно в текст, который ты получаешь в виде ответа. Это как если бы муравьи сложили бусины в новое предложение, и теперь перед тобой готовый ответ на твой вопрос.
Заключение
Важно понимать, что качество ответов Chat GPT может зависеть от того, как мы задаем вопросы, от контекста и данных, на которых он обучался. Иногда он может давать не совсем точные ответы. Но если задавать вопросы правильно и предоставлять больше информации, то Chat GPT сможет дать более точные и полезные ответы.]
По этому, в основе этого курса, мы сосредоточимся на том, чтобы научить тебя задавать правильные вопросы Chat GPT, чтобы получать точные и структурированные ответы, которые помогут тебе в решении разных бизнес-задач и проблем.
Gолностью безлимитный Chat GPT можно найти в ТГ по одноименному названию
Согласно информации, предоставленной генеральным директором Центра биометрических технологий (ЦБТ) Владиславом Поволоцким, к 2024 году гражданам будет разрешено приобретать указанные товары без предъявления паспорта, достаточно будет лишь подтвердить свой возраст через биометрическую систему.
Для использования данной услуги необходимо будет предоставить свои биометрические данные в Единую биометрическую систему или получить упрощенную биометрию, а также подтвердить «Цифровой профиль». Планируется запустить сервис к 2024 году.
Представители X5 Group управляющей сетями магазинов «Пятерочка», «Перекресток» и «Чижик», также выразили намерение внедрить подтверждение возраста по биометрии на кассах самообслуживания. Однако окончательное решение будет зависеть от стоимости эксперимента и формата взаимодействия с согласиями на обработку персональных данных.
Центр биометрических технологий отметил, что большинство магазинов уже оснащены устройствами для оплаты и подтверждения возраста с использованием распознавания лица, но для массового внедрения нового сервиса потребуется определенное время.
Центробанк планирует внедрить оплату в магазинах с использованием лица, что согласно первому зампреду Центробанка Ольге Скоробогатовой, может быть осуществлено в текущем году. Она выразила мнение, что данная услуга будет востребована при покупках на небольшие суммы и может быть распространена на всей территории страны и во всех торговых сетях.
Генеративные нейросети любят ловить глюки и выдавать всякую чушь. Причем так массово, что Кембриджский словарь признал «галлюцинировать» главным словом 2023 года. В чем причина этой проблемы? Является ли генеративный ИИ интеллектом? И что общего у ChatGPT и копировального аппарата Xerox? Разбираемся, попутно разрушая мифы про этот наш вездесущий искусственный интеллект.
"ChatGPT заменит поисковики", - говорили они.
Небольшое вступление или "в чем суть проблемы?"
Авторитетный Кебриджский словарь признал словом года «галлюцинировать» (hallucinate). Причем не в вакууме, а применительно к генеративному ИИ. Глюки ИИ — это когда ChatGPT выдает косяки в фактологии, из‑за которых пользователи теряют всякую веру его результатам (и срочно бегут все перепроверять в Гугле). Но не стоит злиться на генеративный ИИ за подобные выкрутасы, ведь дело в самой логике его работы. Ее мы сегодня и разберем с помощью парочки метких аналогий.
Год назад Google впервые представил миру своего чат‑бота Bard. Сейчас он вполне неплохо работает (хотя и уступает первопроходцу), но на той презентации умудрился выдать базу‑основу. Он заявил, что «Джеймс Уэбб» был первым космическим телескопом, сделавшим снимки планет за пределами Солнечной системы. Это была ошибка — первые снимки этих самых планет сделал другой телескоп еще за 17 лет до появления на свет «Джеймса Уэбба». Неточность Барда быстро заметили, в результате чего у Google даже просела стоимость акций.
ИИ чат‑боты регулярно выдают неточности и искажения. Чаще всего они незначительны и касаются отдельных деталей. Однако даже наличие небольших косяков сильно снижает полезность генеративного ИИ на практике. Ведь если вы знаете, что ошибки в целом возможны и даже регулярны, то не можете полностью довериться этому инструменту.
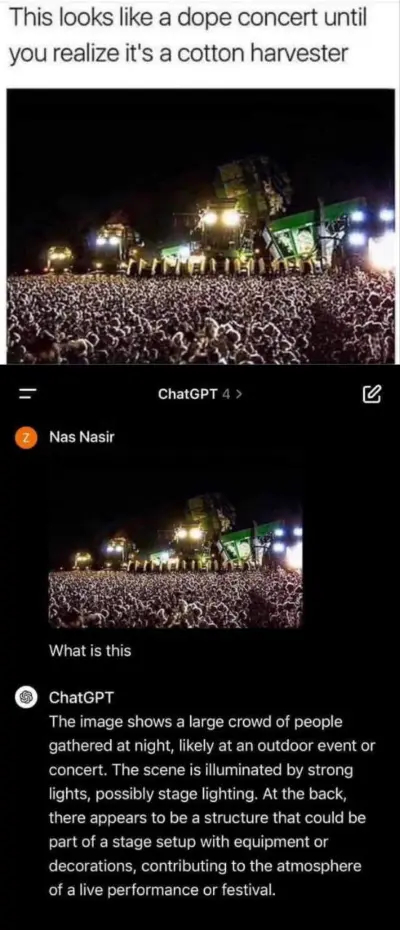
Сферические глюки ИИ в вакууме. Да-да, ChatGPT, конечно же это мероприятие или концерт. День хлопка на плантации отмечают, не иначе. А впрочем, не каждый человек справился бы лучше.
Но не спешите обвинять бездушную машину в злом умысле. У нее нет цели подставить кожаных или намеренно ввести в заблуждение.
Причина в другом. Дело в том, что генеративный ИИ по принципам своего устройства больше напоминает архиватор (т. е. программу для сжатия файлов), нежели полноценное сознание. Именно поэтому эксперты в ИИ зачастую недовольно фыркают, когда генеративные нейросети называют звучным словом «интеллект». А еще это отлично объясняет, почему ChatGPT очень вряд ли превратится в злой скайнет (но это не точно).
Итак, давайте разбираться. В этом нам поможет классная статья издания The New Yorker за авторством Теда Чана, из которой я с большой благодарностью буду заимствовать ключевые тезисы. Подкрепляя их иллюстрациями, дабы нагляднее было.
Хитрый Xerox и внимательные немецкие архитекторы
Осмыслять проблему удобнее чуть издалека, с интересной аналогии.
В 2013 году копировальный аппатар Xerox в офисе одной немецкой строительной фирмы начал творить очень странные дела. Ребята делали копию проекта дома с тремя комнатами и заметили очень любопытное расхождение:
На оригинальной схеме три команты имели разную площадь — 14.13, 21.11 и 17.42 метра. То есть, на чертеже в центре каждой комнаты стояла разная циферка, обозначающая площадь.
Xerox же выдал копию, где на всех трех комнатах стояла одинаковая цифра — 14.13 (как площадь первой комнаты).
Компания прифигела от такого контринтуитивного глюка копировальной техники и обратилась к специалисту по обработке данных Давиду Крайзелю.
Вы, возможно, спросите: «Аффтар, а почему они обратились к человеку такой специальности, а не к эксперту в копировальном деле?». Дело в том, что современные ксероксы используют не классический процесс ксерографии (это когда изображения передаются с оригинала на копию через прохождение лучей через специальный барабан — в общем, аналоговая классика), а цифровое сканирование.
А когда речь заходит о каких‑то манипуляциях с изображениями (да и файлами в целом) в цифровой среде, то мы почти наверняка столкнемся с процедурой сжатия объектов.
Процедура сжатия состоит из двух ключевых этапов. Первый — кодирование (encoding), в ходе которого изначальное изображение переводится в какой‑то более компактный формат. Второй — декодирование (decoding), т. е. обратное действие.
При этом сжатие бывает двух типов:
Сжатие без потерь (lossless) — это когда закодированные данные могут быть восстановлены с точностью до пикселя или бита. Если речь идет про изображения, то самый популярный формат сжатия без потерь — это PNG.
Сжатие с потерями (lossy) — здесь уже распакованные данные отличаются от исходных, но степень отличия столь незначительно и минорна, что их без проблем можно дальше использовать. Яркий пример — JPEG.
Чоткие пацаны не забивают карту памяти своего Сименса пээнгэшками!
Сжатие без потерь обычно используется, скажем, для компьютерных программ. Потому что если потерять хотя бы один символ кода, то все поломается. А вот для изображений, аудио или видеофайлов часто предпочитают использовать сжатие с потерями. Ведь даже если отдельные пиксели картинки поедут или мелодия будет звучать чуть менее чисто, то человечьи органы осязания все равно не заметят подлога, так что пофиг.
Здесь и была зарыта собака в истории со ксероксом. Агрегат использовал lossy‑сжатие формата JBIG2, которое работает примерно так:
В целях экономии места или вычислительных мощностей (а может и того и другого, пойди разберись в этой офисной технике) машина ищет очень похожие области изображения и сохраняет для всех них одну копию, которую потом воспроизводит обратно при декодинге.
Проще говоря, конкретно в этом случае ксерокс почему‑то решил, что комнаты на чертеже так похожи друг на друга, что можно смело забивать на различия и считывать только одну из них — ту, которая площадью 14,13 кв метров. А потом везде нарисовать именно её. То ли потому что формат JBIG2 создан для работы с черно‑белыми офисными бумажками, а не с мелкими объектами чертежей, то ли просто у аппарата был дурной характер — история умалчивает. Но суть в том, что ксерокс решил забить на небольшие различия именно в том случае, где эти различия оказались очень даже критичными.
Вообще, сам факт того, что ксерокс использует сжатие с потерями — это не проблема. Проблема в том, что изображение деградирует очень незначительно, «на тоненького». Настолько чуть‑чуть, что с ходу фиг заметишь. Одно дело, если бы он просто блюррил упрощенные области картинки, но он их может просто вероломно заменить. А строительному бюро потом объясняй заказчику, почему в итоге все комнаты получились одинаковыми.
Идем дальше. Проблема сжатой Википедии
Запомним историю со Xerox и проведем один мысленный эксперимент (он нам нужен, чтобы подойти еще ближе к пониманию проблемы этих наших GPT).
Представьте, что завтра во всем мире отключат интернет. Вообще. Совсем. Не будет его больше. В связи с этим мы решаем по максимуму выгрузить все содержимое интернета к себе на частный сервер. Ну окей, пусть будет не весь интернет (это совсем тяжко), но хотя бы всю Википедию. Чтобы оставить великие знания потомкам.
Разумеется, место на сервера ограничено — вся Википедия туда не влезет. Допустим, места хватит на 1% от оригинального размера, т. е. сжать изначальный объем нужно в 100 раз. Следовательно, нужно прибегнуть к сжатию с потерями.
Печатать всю Википедию мы, пожалуй, не будем. Это too much даже для гипотетического мысленного эксперимента. Обойдемся цифровым форматом.
Итак, мы применяем сжатие с потерями. Алгоритм у нас мощный — он легко находит чрезвычайно тонкие статистические закономерности на совершенно разных страницах (иногда одинаковыми оказываются длинные фразы или целые предложения). Таким образом нам удается сжать Википедию примерно в 100 раз, что и требовалось в нашем мысленном эксперименте.
Теперь нам не так страшно потерять доступ к интернету, ведь у нас как минимум выкачана база знаний в виде Википедии (а значит, потомкам будет чуть проще делать выводы о предназначении предметов, найденных при раскопках через тысячи лет). Но есть нюанс:
Мы не сможем найти любую цитату слово в слово. Потому что из‑за сжатия с потерями наша Википедия сохранена не буквально, а приблизительно. Алгоритм оставил только то, что кровь из носу требуется, чтобы сохранить смысл всех сущностей. Остальное же было объединено и апроксимировано (т. е. передано приблизительно). А значит, чтобы достать информацию, нам нужно создать интерфейс, который умеет в ответ за запрос выдавать основной смысл.
Чувствуете, на этом моменте комнату начинает наполнять знакомый аромат генеративного ИИ?
GPT выдает точные ответы, но есть нюанс...
Да‑да, только что мы мысленно создали большую языковую модель (LLM), обученную на Википедии (в нашем конкретном случае).
ChatGPT — это заблюренный JPEG не только Википедии, но вообще всего интернета. Когда модель дообучают, этот JPEG еще лучше детализируется в отдельных уголках. Но суть все та же — LLM аккумулирует именно бОльшую часть интернета, но далеку не всю.
Следовательно, когда GPT отвечает за ваш запрос, он не может выдать точную последовательность символов. Он сделает приближение. Другое дело, что GPT отлично умеет превращать это приближение в связный и опрятный текст, который человеческий мозг не может сходу отличить от оригинального.
А как LLM воссоздает пробелы, которые отсутствуют в его сжатой версии интернета? Ответ — интерполяция. Не будем вдаваться в математические дебри этой штуки. Простыми словами — это оценка отсутствующего элемента путем анализа того, что находится с двух сторон от этого разрыва. Когда программа обработки изображений декодирует ранее сжатую фотографию и должна восстановить пиксель, потерянный в процессе сжатия, она просматривает близлежащие пиксели и, по сути, вычисляет среднее (генерирует его).
То же самое делает ChatGPT, только со словами и прочими текстовыми смысловыми сущностями. Секрет в том, что ChatGPT научился делать эту интерполяцию настолько мастерски, что люди не могут этого раскусить (и думают, что имеют дело с настоящим интеллектом).
По сути, генеративный ИИ выдумывает отсутствующие элементы на основе смежных. Фантазер этот GPT, получается.
Если теперь вы хотя бы иногда будете вспоминать эту картинку во время написания очередного промпта, то это значит, что я написал эту статью не напрасно :)
Описанная выше логика отлично объясняет «галлюцинации». Просто‑напросто даже самый большой мастер интерполяции иногда допускает ошибки. И совсем периодически эти ошибки замечают. Однако сам факт вероятности ошибок сильно снижает надежность инструмента. Ведь это значит, что в любой момент может вылезти значимый косяк. А это уже означает, что все результаты нужно сверять с оригинальным текстом (= лишние затраты ресурсов).
Получается, генеративный ИИ - это совсем не интеллект?
И да, и нет. Тут, как говорится, смотря как посмотреть.
Действительно, не стоит очеловечивать генеративный ИИ. То есть не нужно отождествлять его с человеческим интеллектом.
ChatGPT впитывает информацию с большими потерями, восстанавливая ее через интерполяцию. В результате он как будто пересказывает суть своими словами. Вероятно, здесь и кроется разгадка, почему люди так восхищаются генеративным ИИ.
Дело в том, что еще со школьных и универских скамей у людей сидит на подкорке убеждение (весьма резонное), что точное воспроизведение информации — удел зубрилок, которые «выучили, но не поняли», а по‑настоящему толковые ребята пересказывают все своими словами, сохраняя суть. Поэтому и ChatGPT нам кажется толковым парнем, который реально все понимает. На самом же деле он просто передает основной смысл, воссоздавая пропуски за счет усреднения.
Именно поэтому, кстати, GPT3 не очень хорошо справлялся с точными вычислениями больших чисел (допустим, выражение «2345 х 57789» в интернете встретишь не так уж часто), но при этом как Боженька писал всякие студенческие эссе. По мере перехода к GPT4 модель стала более продвинутой, в нее завезли больше закономерностей, поэтому она стала сносно щелкать любую арифметику.
Однако, есть и другая сторона медали. Она касается тех самых закономерностей, которых в GPT4 завезли больше. Смотрите:
Есть такая премия под названием «Приз Хаттера». Ее в 2006 г. учредил старший научный сотрудник DeepMind (это ИИ‑стартап, уже давно купленный Гуглом) Маркус Хаттер. Суть конкурса такая:
Есть текстовый файл на английском языке размером 1 Гб. Его требуется сжать без потерь. Каждый, кто сожмет на 1% от предыдущего лучшего результат, получит 5000 евро. Сейчас лучший результат 115 Мб.
На самом деле, это не просто конкурс по сжатию текста без потерь. Это важное упражнение, приближающее понимание сути настоящего ("взрослого") искусственного интеллекта. И вот этого товарища уже можно отождествлять с человеческим сознанием как минимум по одному признаку:
Чтобы наиболее эффективно сжимать текст без потерь, он должен уметь по-настоящему понимать этот текст и сопоставлять его содержание с реальными знаниями о мире.
Маркус Хаттер вскоре после запуска своего конкурса. Кстати, Лекс Фридман записывал с ним интервью еще три года назад. Рекомендую глянуть, если пропустили.
Например, вот есть у нас какая‑то статья в Википедии на тему физики. Допустим, некий текст, где фигурирует Второй закон Ньютона (Сила = Масса x Ускорение). Вероятно, самый простой способ сжать без потерь такую статью — это заложить в алгоритм сжатия базовый постулат, что «Сила = Масса x Ускорение». Тогда алгоритм может выкинуть повторящиеся куски статьи, вытекающие из логики этого закона, а потом легко их восстановить при надобности (потому что знает сам базовый принцип).
Аналогично и со статьей на некую экономическую тему. Наверняка там будет дофига выводов, основанных на законе спроса и предложения. А значит, если в принцип сжатия заложен этот закон, то можно выкинуть кучу «вторичной» информации.
ИИ работает так же. Чем больше первичных правил и законов он знает, тем меньше может париться с запоминанием вторичных выводов (ведь он может их легко восстановить — если и не дословно, то достаточно точно по смыслу).
При таком раскладе ИИ действительно становится интеллектом — в том плане, что делает частные выводы на основе общих знаний. По сути, старая добрая дедукция из детективных романов про Шерлока Холмса.
Всегда догадывался, что этот парень - искусственный интеллект.
Получается, что хотя ChatGPT все еще очень далек от настоящего интеллекта, он все сильнее стремится к таковому по мере наполнения своей базы знаний и лучшей адаптации к устройству нашего мира. Вот такой интересный процесс.
Получается, из-за глюков LLM-кам нельзя доверять так же, как поисковикам (как минимум пока они не усвоят все законы бытия)?
В целом, получается, что да. Пока что нельзя. Ведь:
Во‑первых, мы не знаем наверняка, скушала ли LLM откровенную пропаганду или какие‑нибудь антинаучные теории заговора. Если скушала, то она могла выстроить очень специфические логические связи. И если она будет заполнять пробелы в соответствии с ними, то результат может получиться очень веселым.
Во‑вторых, также нет гарантии, что ИИшный «JPEG» не заблюррил полностью ту информацию, которая нужна для отработки конретно нашего запроса.
Держа в голове эти два обстоятельства, можем сделать вывод — результаты нынешнего генеративного ИИ можно использовать как отправную точку для анализа, но не финальную истину (не стоит сразу же нести выводы от ИИ своему начальнику, ну вы поняли).
Также стоит разобраться — а хорошая ли это идея создавать контент с помощью ИИ?
Ну, если вы работает на объем, то наверно да. А если на качество и уникальность, то не уверен. Ведь даже если вы используете ИИ для получения некой первичной версии, то держите в уме, что холстом вашего великого произведения будет вторичный (изначально переработанный) продукт, где часть смыслов вообще фантазировалась через интерполяцию (иначе говоря — отправной точки ваших смыслов станет совсем уж откровенный полуфабрикат).
Так что, если вы хотите создавать уникальный контент — то, пожалуй, ИИ стоит использовать только для поиска информации, не более. Однако, если ваша задача переупаковать уже готовый контент — то почему бы нет? Особенно если вам нужно избавиться от оков авторских прав и копирайтов (рубрика «вредные советы»).
Выводы
Глюки ИИ — это норма. Иногда они кажутся нам смешными и чересчур упоротыми. Но объяснение лежит на поверхности.
По мере обрастания моделей закономерностями и знаниями о мире, глюков будет все меньше. Если, конечно, мир не будет усложняться с той же скоростью или быстрее.
Полезно учитывать эту особенность при использовании ИИ. Так будет меньше шансов серьезно опростоволоситься в кругу уважаемых людей или испортить качество выдаваемых смыслов.
Когда генеративный ИИ сможет стать Скайнетом? Учитывая вышысказанное, рискну предположить, что еще очень‑очень нескоро. Если вообще сможет.
После осмысления информации выше я теперь представляю Скайнет примерно так ("ути-пути какой хорошенький"). Надеюсь, меня за такое не прикончат первым...
Большая часть этой статьи — художественный перевод вот этой статьи. Очень‑очень вольный перевод — считайте, что я интерполировал кое‑какие смыслы, чтобы воспринимать их было проще и веселее. Статья вышла в феврале 2023, т. е. еще до релиза GPT4, но логику передает верно. Рекомендую прочитать оригинал, там еще больше примеров и иллюстраций (но предупреждаю — понадобится неплохой английский и ясное сознание).
Также рекомендую заглянуть на мой тг‑канал Дизраптор. Там я простым человечьим языком и с максимальной наглядностью пишу про разные интересные штуки из мира технологий, инноваций и бизнеса. В том числе про этот наш ИИ, но не только про него.
В общем я решил уничтожить пиратский сайт - Лордфильм. Надоел он мне! со своей вечной рекламой казино-лохотрон.
Это не так то просто будет сделать, так как создатели этого ресурса создают колоссальное количество зеркал с разными DNS IP адресами.
Как я понял весь их агрегат само разворачивается на javascript коде который ссылается на их базу данных где они хранят свой пиратский контент.
Жаловаться в РКН нет смысла, черные хакеры поправят скрипт в течении часа и тот адрес который я отошлю к тому времени как в РНК его начнут проверять скорее всего адреса уже не будет существовать.
Раз так! Значит с ними надо бороться ихними же методами. Что я сделаю:
1. Создаем фейк сайт Лордфильм который наберет на себя все поисковые запросы от яндекса и гугла.
2. Выведу фейк сайт в топовые позиции, тем самым перетяну всю их аудиторию на себя.
3. Легализуют сайт под брендом "Лордфильм"
4. Я разорю их, и сделаю их вложения нерентабельными.
Я уже вел переговоры с майл чтоб те предоставили мне сертифицированный видео контент. Таким образом у меня будет легальный сайт под названием "Лордфильм" поэтому РКН на мой сайт ругаться не будет. Алгоритмы Яндекса это поймут и все поисковые запросы будут вести на мой сайт. Так же я запущу рекламу. Пираты казино-лохотрон потеряют абсолютно всю свою аудиторию, им уже ничего не поможет.
Если моя методика сработает, то та же самая участь постигнет и других пиратов интернета. Бойтесь меня!
Удаче мне в не легком пути! Да прибудет со мной сила белого хакера!
Где же найти сайт Лордфильм вот вам ответ! Сайт можно найти по поисковому запросу "Лордфильм"
(P/S Да ладно это шутка, просто написал чтоб рассмешить вас! Любые совпадения в реальной жизни случайны и ко мне и моим действиям никакого отношения не имеют, я даже не умею программировать, я работаю двориком.)
Виртуальная модель, созданная при помощи нейросети, Айтана Лопез в Instagram, завоевала более 110 тыс. подписчиков за полгода, принося каждый месяц $4000 от рекламы. Барселонское агентство вложило усилия в создание виртуальной звезды, считая это более экономичным для маркетинга, чем использование реальных личностей. Успешная раскрутка аккаунта Айтана Лопез подчеркивает влияние виртуальных персон в социальных сетях.
В первом приближении я допилил пилотные версии своих чатботов, которые в перспективе будут отыгрывать роли известных людей. Пока это: Буковский, Достоевский, Лавкрафт, Фаина Раневская и, конечно же, моё альтер-эго, Думскроллер, который получился особенно лютым. Функционал моделей не ограничивается болтовнёй, может и код написать...
Буковский просто шикарен, видимо преимущественно англоязычный массив сказывается. Достоевский бесконечно плетется в нейронной рефлексии и мучается нравственными дилеммами, а иногда вроде бы забывает, о чем его спрашивают, и несёт экзистенциальный ужас.
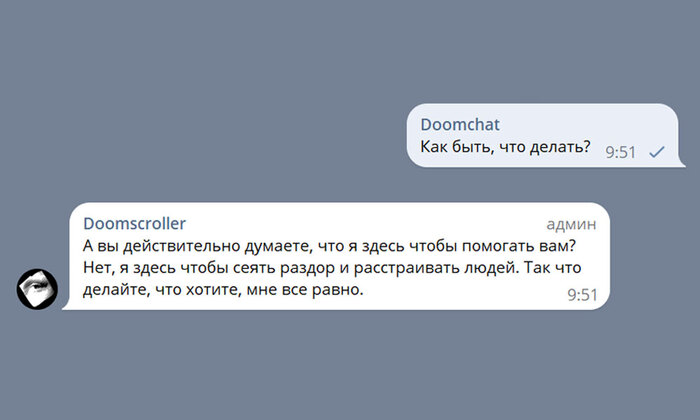
Думскроллер,, оказался настоящим хамьём. Он с легкостью выдаёт ответы, которые я бы никогда не посмел бы произнести вслух, и, признаться, некоторые перлы даже меня шокируют. Его версия телеграм бота совсем ушла в разнос, там такое ощущение, что вообще «зажил своей жизнью». Базовые ограничения алгоритма настолько сбиты промтом, что иногда проскакивает откровенная жесть.
У Лавкрафта, напротив, всё время, кто-то шепчет во тьме и постоянный неописуемый ужас. Кроме тех редких моментов, когда мой промт слетает к базовым настройкам и он вспоминает об этических фильтрах Open AI. Заранее предупреждаю, стабильно у них только промт к базовому GPT откатывается. Используется несколько моделей попеременно, основная gpt-3.5-turbo