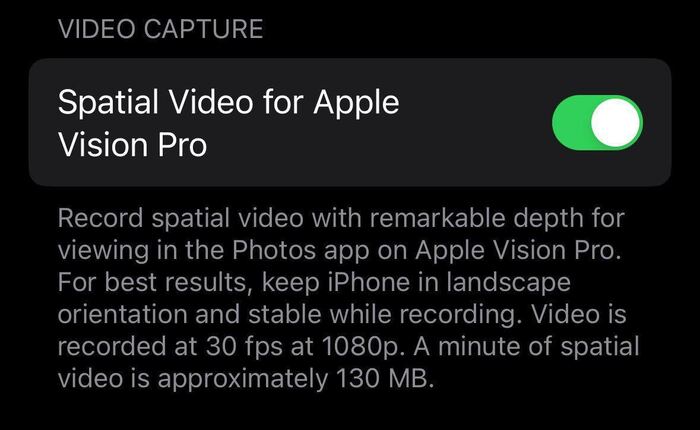
📱 Новая функция в iOS 17.2 beta 2 позволяет iPhone 15 Pro записывать пространственное видео, которое можно будет просматривать на гарнитуре Apple Vision Pro через приложение "Фото".
Это полностью трехмерные впечатления, которые можно пережить, надев гарнитуру.
Например, если вы снимаете пространственное видео с вечеринки по случаю дня рождения вашей дочери, вы можете надеть Vision Pro и заново пережить этот день, поскольку операционная система создает ощущение, что вы вернулись в тот момент. 🙌
Для достижения наилучших результатов держите iPhone в альбомной ориентации и устойчиво во время записи.
Видео будет иметь разрешение 1920x1080 при частоте 30 кадров в секунду. Минута пространственного видео занимает примерно 130 МБ.
Да уж, будущее уже наступило!
Источник телеграм канал ИИшница 🍳 - тут все самое интересное из мира новых технологий и нейросетей 🤖
Он использует технологию трекинга зрителя для преобразования 2D-изображений в #3D, что делает обьекты интерактивными. Эта технология открывает новые и захватывающие способы, познакомиться с произведениями искусства, которые реагируют на взаимодействие с пользователем.
Интерактивное жидкое зеркало на физическом дисплее? Дайте две!
Когда дело доходит до автоматического создания изображений на основе собственных идей, на помощь приходят две самых популярных среди пользователей нейросети — DALL-E 2 и Midjourney. Обе являются инструментами, способными создавать реалистичные изображения с хорошим качеством. Эти ИИ обычно понимают, чего вы хотите, и пытаются генерировать новые изображения, в том числе что-то похожее на конкретный пример, но часто можно увидеть, что результат совершенно не соответствует запросам. Что ж, это изменится с новой моделью от NVIDIA — Perfusion, нейросетью, которая позволяет создавать изображения из описаний на естественном языке.
В отличие от своих тяжеловесных конкурентов, Perfusion выделяется компактным размером моделей всего в 100 КБ и 4-минутным временем обучения. Perfusion предлагает пользователям возможность комбинировать различные настраиваемые элементы с набором изображений, которые функционируют как «концепции». Модель способна изучить «концепцию» объекта (например, вещи, животного или человека), а затем генерировать эти концепции в новых сценариях.
❯ Всё дело в концепции
Модель преобразования текста в изображение (T2I) — это алгоритм машинного обучения, который позволяет пользователям писать подсказки на естественном языке для создания изображения, сгенерированного ИИ. Модели T2I предлагают новый уровень гибкости, позволяя пользователям управлять творческим процессом. Однако персонализация этих моделей в соответствии с визуальными концепциями, предоставленными пользователями, остаётся сложной проблемой. Задача персонализации T2I ставит перед собой множество сложных задач, таких как поддержание высокой визуальной точности, объединение нескольких персонализированных концепций в одном изображении и сохранение небольшого размера модели. Perfusion может решить эти задачи.
Основная фишка Perfusion заключается в его новой технике Key-Locking («блокировка ключей»). Связывая определённые концепции с другими концепциями во время создания изображений, Perfusion может создавать больше версий начальной концепции, сохраняя при этом её суть. Это позволяет пользователям персонализировать изображения с помощью определённых объектов, например, таким как «кот», сохраняя при этом уникальные характеристики, которые определяют конкретного «кота».
Блокировка ключей смягчает проблему переобучения, из-за чего модели сложно создавать новые версии идеи, потому что она тесно связана с изображениями, на которых она изначально обучалась. Perfusion корректирует математические преобразования, превращающие слова в картинки. Key-Locking позволяет модели связывать конкретные запросы пользователей с более широкой категорией или «надкатегорией». Например, запрос на создание кота побудил бы модель сопоставить термин «кот» с более широкой категорией «кошачий». После этого выравнивания модель обрабатывает дополнительные сведения, предоставленные в текстовом запросе пользователя.
Привязав нового кота к общему понятию «кот», модель может изобразить кота во многих различных позах, внешности и окружении. Но кот по-прежнему будет сохранять свою «кошачесть», которая делает его похожим на определённого кота, а не просто на случайного Барсика. Например, можно добавить концепцию «шляпа» к концепции «кот» и «блокировать ключ» общей концепции «кот в шляпе». Любое переобучение происходит на основе введённых новых концепций, а не всей модели, что означает меньшую потребность в дорогостоящих вычислительных мощностях и хранилищах.
Проще говоря, Key-Locking позволяет ИИ гибко отображать персонализированные концепции, сохраняя при этом их основную идентичность. Это всё равно, что давать художнику следующие указания: «Нарисуй моего кота Тома, когда он спит, играет с мячиком и нюхает цветы».
Еще одно преимущество модели Perfusion заключается в её адаптивности. В зависимости от требований пользователя модель можно настроить так, чтобы она строго соответствовала текстовой подсказке, или предоставить определённую степень творческой свободы в своих выходных данных. Эта универсальность гарантирует, что модель может быть точно настроена для получения результатов, варьирующихся от точных до более общих, в зависимости от конкретных потребностей пользователя.
Фронт Парето
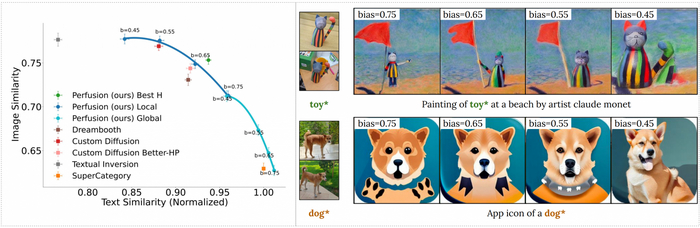
Это позволяет пользователям легко исследовать фронт Парето (сходство текста и сходство изображений) и выбирать оптимальный компромисс. Важно отметить, что обучение модели требует некоторой ловкости. Слишком сильное сосредоточение на воспроизведении модели приводит к тому, что модель снова и снова выдает один и тот же результат, а слишком точное следование текстовому запросу без какой-либо свободы обычно приводит к плохому результату. Гибкость настройки того, насколько близко генератор следует запросу, является важной частью настройки.
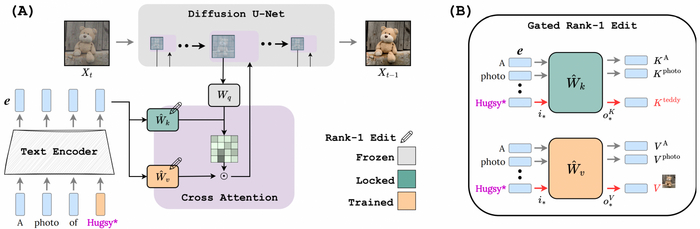
Текстовый запрос преобразуется в серию кодировок. Каждое кодирование подаётся в модули перекрёстного внимания диффузионного шумоподавителя U-Net (фиолетовые блоки). U-Net демонстрирует, как кодирование текста влияет на пути ключа и значения
❯ Меньше значит лучше
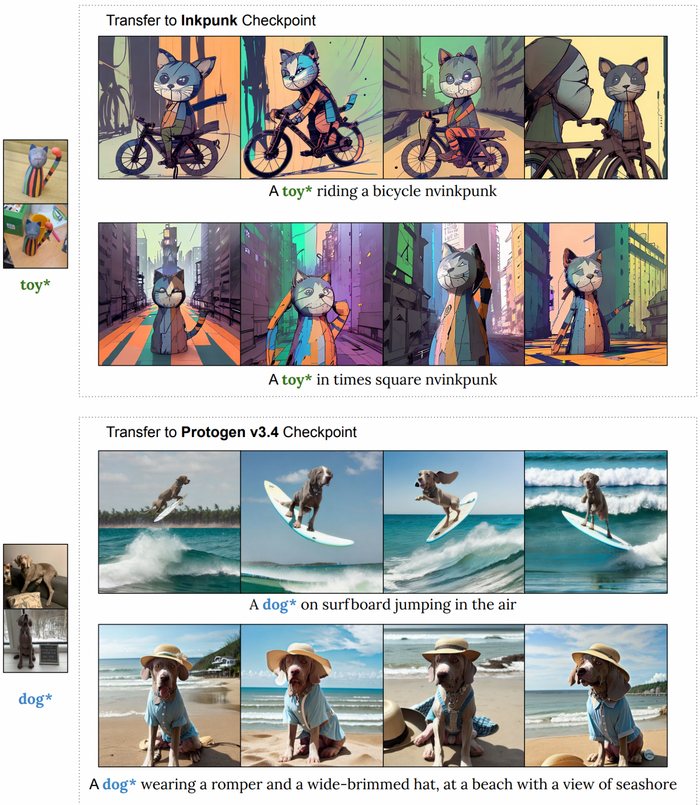
Perfusion основывается на Stable Diffusion с дополнительными механизмами для захвата и одновременного создания нескольких «концепций». В отличие от существующих генераторов изображений, которые изучают концепции изолированно, Perfusion позволяет нескольким персонализированным концепциям сосуществовать в одном изображении с естественным взаимодействием. Эта открывает перед художниками новые возможности для экспериментов и создания уникального визуального контента.
Perfusion может обеспечить более анимационные результаты с лучшим сопоставлением подсказок и меньшей восприимчивостью к фоновым чертам исходного изображения. Для сравнения для каждой концепции прилагаются образцы из обучающего набора, а также сгенерированные изображения, их кондиционирующие тексты с текущих методов Custom-Diffusion, Dreambooth и Textual-Inversion.
Сравнение результата Perfusion с другими методами
Другие генераторы AI изображений тоже могут предлагать варианты тонкой настройки, но их громоздкий размер может быть недостатком. Самые популярные модели T2I, в том числе Stable Diffusion и Dall-E, имеют миллиарды параметров, что означает, что они занимают несколько гигабайт в автономном режиме. Для Perfusion требуется всего 100 КБ пространства, что является впечатляющим достижением по сравнению с Midjourney, для которого требуется более 2 гигабайт хранилища. Сверхэффективный размер позволяет просто обновлять те части, которые нужны, по сравнению с методами, которые обновляют всю модель.
Для справки: LoRA — это популярный метод точной настройки, используемый в Stable Diffusion. Он может добавить к приложению от десятков мегабайт до более одного гигабайта. Другой метод, Textual-Inversion, легче, но менее точен. Модель, обученная с помощью Dreambooth, самого точного метода на данный момент, весит более 2 ГБ.
Эффективно блокировать концепции и уменьшать размер модели удаётся с помощью метода, называемого редактированием модели ранга-1. В современных моделях преобразования текста в изображение, основанных на Custom-Diffusion всегда есть текстовая подсказка, которая закодирована для извлечения соответствующей информации. Эта информация так или иначе добавляется, обычно через механизм перекрестного внимания к процессу генерации изображений, который является итеративным процессом. Редактирование ранга-1 контролирует то, что появляется в конечном изображении.
Качество изображения, создаваемое моделью Perfusion, примерно такое же, как у Stable Diffusion v1.5. С точки зрения эффективности, благодаря лёгкому объёму, эффективность модели Perfusion находится в «первом эшелоне» в отрасли.
Это всё ещё не идеально, но это большой шаг вперёд для моделей преобразования текста в изображение с полным контролем над генерацией. Здесь модель ещё борется с сохранением идентичности объекта, который ему отправляется. Объекта, который является «суперкатегорией», что иногда приводит к чрезмерному обобщению, поскольку некоторые суперкатегории слишком широки и включают много разных объектов или специфических стилей, которые не обязательно нужны. Объединение концепций пока ещё требует большого количества оперативной инженерной работы, что является ещё одной причиной научиться делать текстовые запросы лучше.
❯ Новый игрок
Инновации в Perfusion пользователям делиться своими персонализированными концепциями в виде небольших дополнительных файлов, избегая необходимости делиться громоздкими контрольными точками модели. Это также делает персонализацию моделей менее затратной, открывая больше возможностей для большего количества людей.
С точки зрения распространения, модели, адаптированные для конкретных организаций, легче распространять или развёртывать на периферии. По мере того, как практика преобразования текста в изображение становится всё более популярной, возможность добиться такого значительного уменьшения размера без ущерба для функциональности будет иметь первостепенное значение.
Однако важно отметить, что Perfusion в первую очередь обеспечивает персонализацию модели, а не саму полную генеративную способность. Несмотря на то, что этот метод многообещающий, он имеет некоторые ограничения. Авторы отмечают, что критический выбор во время обучения может иногда чрезмерно обобщать концепцию. По-прежнему необходимы дополнительные исследования, чтобы легко объединить несколько персонализированных идей в одном изображении.
Nvidia сообщила о планах выпустить код в будущем, что позволит более широко изучить и понять потенциал этой компактной нейронной сети. Хотя код Perfusion пока недоступен, заявленный авторами план подразумевает, что эта эффективная персонализированная система искусственного интеллекта может со временем попасть в руки разработчиков, отраслей и создателей.
Это исследование согласуется с растущим вниманием Nvidia к ИИ. По мере роста спроса на технологии искусственного интеллекта Nvidia стратегически позиционирует себя как доминирующего игрока в этой области. Акции компании выросли более чем на 230% в 2023-м году, поскольку её графические процессоры продолжают доминировать в моделях обучения ИИ. Учитывая, что такие компании как Google, Microsoft и Baidu, вкладывают миллиарды в генеративный ИИ, инновационная модель Perfusion от Nvidia может дать ей преимущество.
Помимо Perfusion, Nvidia также разработалаOmniverse Audio2Face, инструмент, который позволяет создавать 3D-анимации из аудио. Кроме того, с начала года стало известно, что компания разрабатывает драйверы на основе ИИ для оптимизации производительности своих видеокарт.
Более подробная информация о Perfusion представлена на выставке SIGGRAPH 2023.
Больше интересных статей в нашем блоге на Хабре. Недорогие сервера для ваших проектов — здесь.
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Компания WAVR разработала прототип устройства по сбору энергии из движения океанских волн.
Представляющий собой плавающее устройство с шарнирной системой, WAVR Wave Energy Converter (WEC), непрерывно захватывает энергию движущихся волн. Стоит отметить, что устройство изготовлено из пластика и способно легко держаться на поверхности воды.
Первоначально устройство разрабатывалось для индивидуального использования, предоставляя возможность генерации энергии для подзарядки компактных электрических устройств во время плавания в открытом море.
Тем не менее, Клайд Игараши, основатель WAVR, видит перспективы за рамками индивидуального использования. По его мнению, в сотрудничестве с крупными компаниями возможно создание волновых энергоферм, способных обеспечивать электроэнергией целые населенные пункты.
"Мы планируем использовать множество соединенных между собой маленьких устройств, собирающих энергию с небольших волн, так как подобным крупным устройствам для сбора энергии соответственно требуются большие волны", - объяснил он.
В сотрудничестве с производственной компанией Robogio Dynamics и русским инженером Виктором Чебоксаровым, команда Игараши разработала прототип, изготавливаемый на 3D-принтере из пластика и весом менее 5 кг. Данное устройство использует энергию, передаваемую через шарниры от волн, и аккумулирует ее во внутреннем батарейном отсеке. Кроме того, оно может заряжать внешние батареи.
В настоящее время WEC способно собирать энергию исключительно от волн, однако WAVR стремится расширить технологические возможности устройства, которые позволят использовать также солнечную и ветровую энергию.
В настоящее время система генерирует приблизительно три ватта энергии на квадратный метр. Игараши отмечает, что это составляет около четверти мощности стандартной солнечной панели. Однако, солнечную энергию нельзя получать непрерывно, в отличие от энергии волн. Ведь существуют места, где солнечного света практически нет, а волн множество.
Проект был разработан в соответствии с планами Гавайев по переходу на 100% использование возобновляемых источников энергии к 2045 году.
Инициатива нашла поддержку у Джона Вайхи, бывшего губернатора штата, который в настоящее время состоит в совете директоров компании.
"Окруженные Тихим океаном, Гавайи могут получить огромную выгоду от развития технологии компании WAVR", - подчеркнул Вайхи.
"Мы являемся одним из самых изолированных участков земли в мире, и наше будущее станет более независимым благодаря использованию окружающих нас природных ресурсов. Это станет огромным шагом вперед, если нам удастся использовать волновую энергию вместе с другими видами возобновляемой энергии, такими как солнечная и ветровая."
Прототипы компании WAVR уже начали привлекать большое внимание к технологиям волновой энергии, а при должном развитии они смогут принести значительные изменения в области возобновляемой энергии в ближайшем будущем.
... и это не компьютерная графика, это реальность. Что это такое? 3D голограмма – объёмная картинка, созданная благодаря уникальному фотографическому методу – голографии. По факту, при помощи специального лазера в воздухе возникает трехмерное изображение, которое невероятно похоже на реальный объект. Устройство найдено на просторах АлиЭкспресс. Ссылка на источник для ознакомления.
В Англии создали стартап, который печатает ракетные двигатели на 3D-принтере, а топливо для них делает из пластиковых отходов. Новая ракета Skyrora XL сможет выводить полезный груз на высоту до 500 км, а для заправки ей понадобится обычный мусор, который англичане научились превращать в керосин Ecosene.
Всем привет! Это Новости Стартапов, и сегодня мы расскажем про искусственный интеллект для принтера и лазерной резки.
Мы все получили массу удовольствия от использования искусственного интеллекта для создания игровых активов, странных селфи, пользовательских стоковых изображений, и это был лишь вопрос времени, когда один из крупных производителей оборудования решит тоже создавать изображения этим способом.
После многих лет исследований генеративный искусственный интеллект наконец-то внедрили в компании Glowforge, которая занимается лазерной резкой и печатью.
Она выпустила функцию Magic Canvas, которая позволяет даже наименее артистичным из нас создавать забавные и креативные произведения искусства, оптимизированные для лазерных гравировальных станков компании.
Компания создала несколько стилей (от героического портрета и карандашного рисунка до супермилых и мультяшных персонажей). Сочетая стиль с подсказкой, программное обеспечение Glowforge отправляет команды в облако, где мощная графическая карта создаёт изображение на основе подсказки. Если пользователю не нравится изображение, он может создать новую версию изображения, или передать созданный шедевр в принтер.
Конечно, пока Magic Canvas не сравнится с тем, что может сделать профессиональный художник. Но, это в 1000 раз лучше, чем то, что могут сделать те, кто не умеют рисовать.
Glowforge может делать гравировку по дереву, акрилу, ткани и любым другим материалам, даже на шоколаде.
Компания также подала заявку на патенты, связанные с программным обеспечением Magic Canvas, но команда не захотела делиться конкретными деталями о том, какую именно нейронную сеть она использует для создания произведений с искусственным интеллектом для лазерной гравировки.
Новая функция является частью подписки Glowforge Premium за 50 долларов в месяц (или 239 долларов в год), а Magic Canvas доступна на всех моделях начиная с сегодняшнего дня.
Это были все новости на сегодня. Пишите в комментариях, какой стартап вам больше понравился, и, конечно же, подписывайтесь на наш телеграм-канал Новости Стартапов: https://t.me/novosti_startupov
Как получить бесплатные 3D-изображения для своих проектов
В дизайне сайтов или презентаций вместо обычных иллюстраций можно использовать 3D-изображения — их можно найти в 3D Bay. Это самый большой в сети бесплатный сток с 3D-изображениями.
Как им пользоваться:
1. Переходим на сайтhttps://clouddevs.com/3dbay/ и вбиваем в поиске желаемое фото. Файлы отсортированы по категориям — образование, дизайн, наука, спорт, мебель, офис, здоровье и так далее.
2. Выбираем подходящий вариант и нажимаем на него.
3. Выбираем размер и клацаем «Download».
4. Всё готово — файл с 3D-изображением уже скачан на ваше устройство! Всё бесплатно, даже не нужна регистрация.