Есть стереотип, что тестостерон — это брутальность, мышцы и волосатость. Частично так, но роль тестостерона в нашем организме гораздо больше, чем просто набор мышц и потенция. Нам важно контролировать его уровень, но можно ли это сделать естественным путём?
На связи RISE: сообщество про ноотропы и личную продуктивность. В этой статье вы узнаете насколько важен тестостерон, и какие есть проверенные способы повышения.
ТЕСТОСТЕРОН
Тестостерон - это стероидный гормон, который организм вырабатывает в основном в яичках и яичниках. Надпочечники также производят небольшое количество. В период полового созревания у мальчиков тестостерон влияет на формирование костной и мышечной ткани, обусловливает развитие вторичных половых признаков, половое созревание и нормальную половую функцию у мужчин.
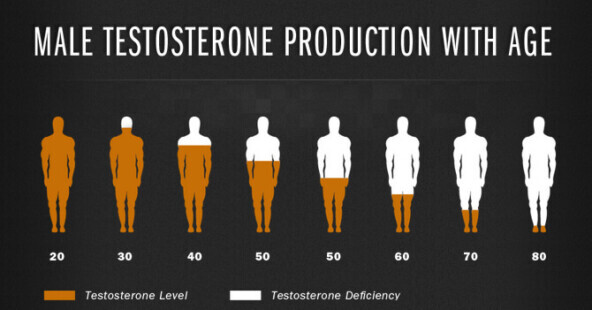
После 30 лет увы, у мужчин уровень тестостерона начинает неуклонно стремиться вниз.
У женщин тоже вырабатывается тестостерон, но в меньших количествах. Он играет одну из главных ролей в развитии фолликула в яичниках, в основном у них доминирует гормон эстроген.
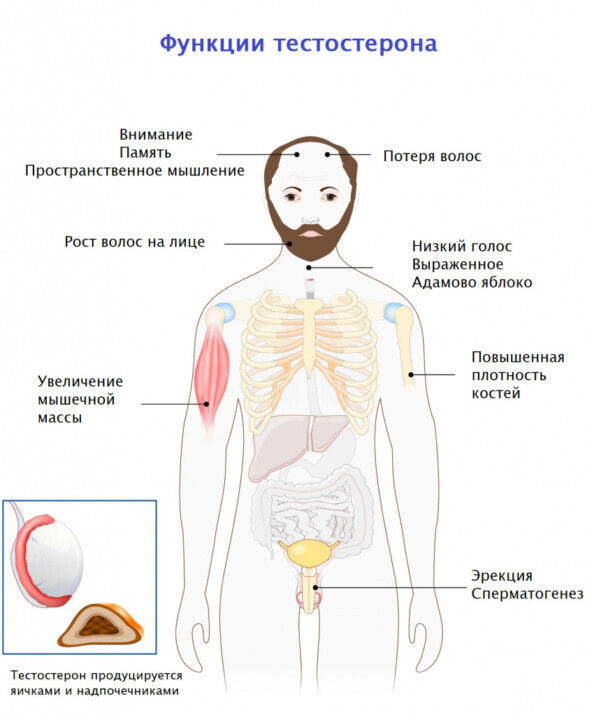
Роль тестостерона в организме
Тестостерон чаще всего связан с половым влечением, набором мышечной массы и на то, как откладывается жир в организме. Он увеличивает количество нейромедиаторов, которые способствуют росту мышечных тканей.
Помимо вышеперечисленного, у него гораздо больше функций.
У мужчин тестостерон играет следующую роль:
Как понять, что у вас низкий тестостерон?
Также уровень тестостерона снижается и у женщин в возрасте 45+ и это тоже неприятные последствия:
Бывает и такое, что тестостерон зашкаливает, чаще всего это проявляется у спортсменов, которые гонят тест для мышечной массы или при гормональном сбое. Увы, это не повод для радости, помним, что во всём важен баланс.
Как понять, что у вас высокий тестостерон?
Излишняя нервозность и вспыльчивость
Нарушение сна
Быстрые смены настроения от эйфории до агрессии
Проблемы с мочеполовой системой
У женщин повышенный тестостерон может проявляться в виде:
В любом случае даже внешние признаки не служат 100% гарантией, лучший вариант — это сдача анализов на свободный/общий тестостерон.
Контролировать тестостерон важно в обе стороны, особенно для мужчин.
Почему тестостерон падает?
Вообще снижение тестостерона — это глобальная проблема. Есть множество исследований, которые демонстрируют, что средний уровень тестостерона у мужчин снижается на 1% каждый год, плюс-минус и снижается сила хвата.
Кроме возраста есть и другие факторы, которые влияют на снижение тестостерона. Давайте рассмотрим их подробно.
1. ОЖИРЕНИЕ И МАЛОПОДВИЖНЫЙ ОБРАЗ ЖИЗНИ
Наиболее частая причина снижение тестостерона — это ожирение, казалось бы именно из-за низкого тестостерона увеличивается % жира. Но тут есть и обратная связь - избыточный вес выводит из равновесия гормональную ось организма и его реакцию на инсулин, повышается уровень липопротеинов в крови, повышается холестерин, что приводит к снижению тестостерона.
Проблема современности в том, что большинство из нас слишком много ест и слишком мало двигается. Зачем выходить на улицу, плясать на кухне, готовя еду, если есть доставка на дом? Есть исследование, где прослеживается прямая связь снижения тестостерона и тем, чем мы питаемся.
Люди, которые едят булки, молочку, сахар, фаст-фуд и редко готовят дома, с большей вероятностью имеют нездоровый состав тела (например, увеличение висцерального жира и снижение массы скелетных мышц) и низкий уровень общего тестостерона. Цифровая индустрия все дела…
Ну и добавим к этому “сидячие” профессии, коих сейчас большинство и получаем статичное снижения тестостерона ежегодно.
2. ВНЕШНИЕ ТОКСИНЫ
Ежегодное мировое производство пластмасс с 70-х годов выросло с 50до 300 миллионов тонн. Да, где-то плачет Грета Тунберг, но это реально дох...много
Многие виды пластмассы содержат химические вещества, нарушающие работу эндокринной системы, а конкретнее — бисфенол А.
Бисфенол — это гормоноподобное вещество, которое маскируется под эстроген, и понижает уровень тестостерона, кроме того у БФА ещё много неприятных воздействий на организм.
Пластик повсюду: в пищевых контейнерах, бутылках, в подкладке алюминиевых банок.
Количество выделяемого БФА повышается в несколько раз при нагревании. Так что в следующий раз подумайте сто раз, прежде чем греть в микроволновке еду в контейнере.
Если контакт с пластиком можно более или менее избежать, то овощи практически все обрабатываются пестицидами, как вариант покупать овощи у знакомой бабы Маши или выращивать самому. Больше всего пестицидов скапливается во всех видах капусты, в остром и болгарском перцах, клубнике и яблоках.
Было также произведено исследование на мужчинах, в котором пестициды снижали уровень тестостерона и подвижность сперматозоидов.Мойте продукты перед тем, как их съесть, желательно замачивать в воде на 10-15 минут, особенно в зимний сезон.
3. СТРЕСС
Краткосрочный стресс может привести к резкому повышению уровня тестостерона, например погружение в ледяную воду и это иногда полезно.
Но долгосрочный психический и физиологический стресс приводит к снижению тестостерона.
Тут всё по цепочке. Стресс заставляет надпочечники выделять гормон кортизол, избыточная секреция кортизола влияет на биохимические процессы организма, в том числе и на снижение выработки тестостерона.
4. Алкоголь
Про вред алкоголя и так многие знают, добавлю лишь что свежие исследования 22 и 23 года показывают, что алкоголь нарушает выработку тестостерона и в целом влияет на гормональную систему.
При редком и кратном употреблении у здорового взрослого мужчины, который выпил пинту виски (473 мл) за один день, в краткосрочный период повышается концентрация и выброс тестостерона, но через 72 часа развивается низкий уровень общего тестостерона, и этот уровень падает до уровня алкоголика.
Это неполный список причин снижения тестостерона, различные эндокринные заболевания, генетика, усиленная терапия, операции и травмы, всё это тоже снижает уровень тестостерона, но тут доверимся врачам.
Как повысить уровень тестостерона?
Физические нагрузки
Физические упражнения - один из наиболее эффективных способов повысить и держать тестостерон в норме.
Одно из исследований 2015 года с участием мужчин с ожирением показало, что увеличение физической активности более полезно, чем ограничение калорий.
Также влияние на уровень тестостерона может варьироваться в зависимости от нескольких факторов, включая тип упражнений и интенсивность тренировок. Но тут стоит отметить, что даже упражнения с отягощениями, которые могут вызвать значительные резкие изменения концентрации тестостерона не работают после 15-16 недель. Если в тренировки нет интенсивности, тестостерон будет расти только в моменте, но в перспективе меньше.
Например, если сравнить упражнение по разгибанию рук на бицепс в статике и динамичные упражнения без груза с собственным телом, второе будет давать больше прироста тестостерона.
Высокоинтенсивные интервальные тренировки более эффективны. В любом случае любая тренировка повышает уровень тестостерона в той или иной степени, главное — чтобы она приносила вам удовольствие.
ЕДА
Тут всё по классике — употребление достаточно количества БЖУ, особенно белка помогает поддерживать здоровый уровень тестостерона и способствует потере жира. Кроме того, постоянные диеты или переедание могут привести к снижению уровню тестостерона.
Потребление здоровых жиров также поддерживает уровень тестостерона и гормональный баланс. Есть также подборка исследований, которые показывают, что диета с низким содержанием жиров может снизить уровень тестостерона.
Поэтому не бойтесь есть жирную пищу, употребляйте больше белков, овощей. Соблюдение сбалансированной диеты напрямую влияет на работу гормональной системы.
Здоровый сон и снижение стресса
Хороший сон и снижение стресса важны также, как диета и физические упражнения. По сути это тоже кирпичики из которых состоит наша база, основа для синтеза тестостерона.
Качество сна оказывает серьёзное влияние на уровень тестостерона. Интересное исследование с участием 2295 мальчиков-подростков и мужчин показало, что нарушение сна снижает уровень тестостерона.
Как наладить сон и нормализовать циркадные ритмы писал тут.
Добавки для повышения тестостерона
Ашваганда
В исследовании 2019 года изучалось влияние ашваганды на уровень гормонов у мужчин в возрасте 40-70 лет с избыточным весом и лёгкой усталостью. Одна группа получала плацебо, другие ашваганду. У тех, кто принимал ашваганду, уровень тестостерона вырос на 15% больше, чем в группе плацебо.
Также исследования 2015 года показало, что ашваганда повышала уровень тестостерона у мужчин в течении 8-недельного периода.
D - аспарагиновая кислота (DAA)
D-аспарагиновая кислота относится к алифатическим аминокислотам. Она присутствует в организме и помогает функционировать нервной системе. DAA является нейромедиатором – переносит нервные импульсы между клетками мозга.
DAA помогает высвобождаться гормонам, в частности тестостерону.Есть исследование, где средний исходный уровень тестостерона у испытуемых мужчин находился в пределах 25% нижнего клинического диапазона (3–10 нг/мл), а добавление DAA в течение 12 дней повышало уровень тестостерона примерно до 50% клинического диапазона.
Большинство исследований показывают, что DAA может действовать на клетки Лейдинга в семенниках, которые выделяют тестостерон, либо изменять поведение гипоталамуса или гипофиза, давая команду производить тестостерон.DAA принимают курсами, чтобы был эффект и не возникало толерантности.
Витамин D3
Исследования 2020 года показали связь между уровнем витамина D и тестостероном. У мужчин с дефицитом витамина уровень тестостерона был ниже, чем у мужчин без дефицита.
Кроме тогда, есть ещё одно исследование, что витамин D эффективен при лечении эректильной дисфункции.
Пажитник
В исследовании 2015 года принимали участие 80 женщин в возрасте от 20 до 49 лет, им давали концентрат пажитника по 600 миллиграммов или плацебо каждый день 8 недель. Экстракт привёл к значительному повышению уровня тестостерона и сексуального влечение по сравнению с плацебо.
Кстати, пажитник используют в грузинской кухне или часто добавляют в выпечку, можно использовать как афродизиак, главное не переборщить))
Пажитник получил довольно веские доказательства эффективности и на мужчинах. В обзоре 2020 года с учётом мета-анализа, было выявлено, что экстракт пажитника существенно влияет на уровень тестостерона у мужчин.
ДГЭА (дегидроэпиандростерон)
Вырабатываемый надпочечниками естественным путем — стероидный гормон, превращающийся в организме в тестостерон и другие половые гормоны.
Исследования, указывают что ДГЭА лучше работает на мужчин после 50, когда уровень собственного ДГЭА плохо вырабатывается, как и синтез свободного тестостерона, также стоит учитывать что ДГЭА может фактически увеличить уровень эстрогена, поскольку ДГЭА преобразуется в организме как в тестостерон, так и в эстроген.
Магний
Магний — это база не только для нашей ЦНС, но и для выработки тестостерона. Магний расходуется в бешеных количествах на все процессы, протекающие в организме. Достаточное количество магния в организме может привести к значительному повышению уровня тестостерона, а дефицит этого минерала к обратному результату.
Исследование, проведенное в 2011 году с выборкой из 455 мужчин в возрасте 65 лет и старше показало, что потребление магния положительно влияет на секрецию анаболических гормонов и увеличивает содержание свободного и общего тестостерона в крови.
Исследование 2011 года с участием трех групп мужчин с четырьмя различными интервалами: один отдыхал перед приемом добавок; один отдыхает после приема добавок; другой – с утомлением (физ нагрузка 90–120 минут в день) перед приемом магния и четвертый с утомлением (физ нагрузка 90–120 минут в день) после приема добавки.
В итоге выяснилось, что уровень тестостерона повышался как у мужчин, занимавшихся физическими нагрузками или фитнес-тренировками, так и у тех, кто находился в неактивном состоянии. Однако повышение уровня тестостерона было более значительным у спортсменов чем у тех, кто вел малоподвижный образ жизни.
Ну и напоследок, добавки магния + цинк могут еще больше увеличить выработку тестостерона. Возьмите на заметку.
Вывод:
Тестостерон — гормон, который жизненно необходим для здоровой и счастливой жизни, другое дело, что его нужно контролировать.
В последнее время всё больше набирает популярность заместительная гормональная терапия, как женская так и мужская, это конечно вариант, но побочек там целый ворох. Поэтому держите свои гормоны под контролем: принимайте добавки, высыпайтесь, занимайтесь физ. нагрузками, соблюдайте баланс во всём, берегите здоровье смолоду.
RISE — самый большой канал по биохакингу в РФ. Сейчас в Телеграм канале можно забрать крутой гайд по антистрессу для наших подписчиков бесплатно.