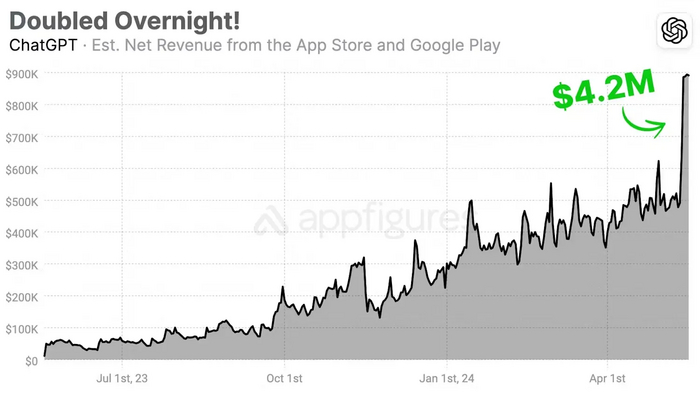
Запуск новой модели GPT-4o от OpenAI привел к значительному росту доходов мобильного приложения ChatGPT, что привлекло внимание бизнес-сообщества. Модель GPT-4o, представленная 13 мая, может обрабатывать текст, речь и видео, обеспечивая мгновенную реакцию и множество голосовых опций. Хотя модель доступна бесплатно на веб-платформе, мобильные пользователи вынуждены переходить на платную подписку ChatGPT Plus за $19,99 в месяц для получения новых функций.
Стратегия и результаты
Эта стратегия увеличила спрос на подписки, вызвав рекордный скачок доходов OpenAI на мобильных устройствах. В первый день запуска GPT-4o доходы мобильного приложения ChatGPT выросли на 22% и достигли $900,000, что почти вдвое больше среднего дневного дохода приложения в $491,000. С 13 по 17 мая приложение заработало $4,2 миллиона чистого дохода на App Store и Google Play, что стало крупнейшим скачком доходов за всю историю приложения.
Интерес к новым технологиям
Данные показывают высокий потребительский интерес к новым технологиям ИИ, несмотря на высокую стоимость подписки. Большая часть новых доходов пришлась на App Store (81%), а крупнейшим рынком стали США, обеспечив $1,8 миллиона дохода. Другие крупные рынки включают Германию, Великобританию, Японию, Францию, Канаду, Корею, Бразилию, Австралию и Турцию.
Прогнозы
Рост доходов не замедляется и, по прогнозам, продолжит увеличиваться.
Нейросеть способна быть полноценным репетитором и говорить на разных языках,что вызвало резкое снижение акций компании. Эксперты считают,что OpenAI фактически убила несколько языковых профессий.
Похоже, теперь совёнку Дуо придётся самому искать репетитора.
Когда мы слышим словосочетание "Большой IT" (Bigtech), то в голове всплывают логотипы Amazon, Google и прочих Netflix со Spotify. Однако в странах Юго-Восточной Азии есть успешные tech-игроки с сотнями миллионов пользователей и целой россыпью необычных сервисов и продуктовых решений. Сегодня я о них расскажу.
В этом цикле статей я разбираю самые крутые и мощные технологические компании за пределами так называемого "золотого миллиарда". И еще Китай не трогаю - это отдельная большая история, тянет на собственный цикл (возможно, напишу позже). В первой части я разбирал IT-лидеров Японии и Южной Кореи, а сегодня речь пойдет про Юго-Восточную Азию - Индонезию, Таиланд, Малайзию, Сингапур, Вьетнам и так далее.
Итак, начнем:
Скутеры для всего или первый единорог Индонезии
Если вы хоть раз летали погреться на тайском, вьетнамском или, скажем, балийском солнышке, то наверняка заметили, насколько в Юго-Восточной Азии любят скутеры. Лично у меня одно из самых ярких впечатлений от поездки на Пхукет - это как местные везут на мопеде семью с ребенком, клетку с курицей, а еще огромную доску для серфа. И им норм.
Safe enough.
Логично, что при такой популярности скутеров в этом регионе развился и соответствующий извоз. Если мы возьмем, например, Индонезию, то там уже много лет все катаются на мототакси, которое местные называют "ojek".
Так вот, 15 лет назад один индонезийский предприниматель подумал "Во всем мире уберизируется такси, а чем наши родные оджеки хуже?". Так появился стартап Gojek. Сейчас это огромный райдтех и экосистема, но началось все как раз с упорядочивания скутерного хаоса.
Бизнес оджеков походил на базар на колесах. Большую часть времени оджеки тратили на поиск пассажиров, а у клиентов знатно подгорало от того, что поиск свободного скутера занимает дольше времени, чем сама дорога. Так что, идея оказалась очень актуальной.
Изначально Gojek был всего лишь колл-центром, который распределял заказы. Однако, в 2014-2015 годах на рынок Индонезии начал заползать Uber и некоторые региональные игроки (про одного из них поговорим отдельно ниже), так что, Gojek получил первое внимание инвесторов. В тот момент пришло осознание, что модель колл-центра изживает себя. Нужен был агрегатор в приложении, который и решили пилить на первые привлеченные инвестиции.
Основатель Gojek Nadiem Makarim - довольно интересный персонаж. Начал консультантом McKinsey (коллега по цеху, получается), потом разорвал местный tech, а в 2019 специально под него придумали роль "технологического министра" (как-то так) в Правительстве.
За первый же год приложение набрало аж 30 млн скачиваний. Вообще, рынок Индонезии был настолько огромным и лакомым, что Gojek получил оценку 1,5 млрд долларов (т.е. стал единорогом) еще в рамках первого инвестиционного раунда в 2014 году. Однако, путь компании только начинался.
Gojek стал усиленно расти. Каждый год увеличивался парк скутеров и число обслуживаемых заказов. Параллельно компания меняла позиционирование - от "Убера для оджеков" компания перешла к модели "цифрового сервиса на все случаи жизни". Почти сразу после основания у Gojek появился сервис доставки еды и посылок - что логично, учитывая, как удобно и быстро можно доставлять негабарит на скутерах. В 2016 г. у Gojek уже был огромный скутеропарк (так вообще говорят?), так что было логично запустить их краткосрочную аренду - назовем её "скутершеринг". Позже добавили и полноценный каршеринг, а следом и автомобильный такси-агрегатор.
Потом компания и вовсе пошла во все тяжкие. Gojek оцифровал буквально все сегменты и ниши, до которых смог дотянуться своей цифровой индонейзийской лапой:
Доставка готовой еды GoFood, доставка непродовольственных товаров GoShop и GoMart. Лекарства привозит GoMed. Курьерская доставка через GoSend и GoBox. Агрегатор клининга GoClean. Библиотека развлекательного контента с умным подбором через Gotix, GoPlay, GoGames. Запись на всякие массажи и бьюти-процедуры через GoMassage...
Разумеется, все это дело приправили собственным платежным сервисом GoPay (запущен в 2020 году). Он умеет переводить деньги, генерировать и сканировать платежные QR-коды и делать оплату коммуналки, штрафов и прочих счетов. Позже к нему прикрутили рассрочки, займы, страховки, платформу для инвестирования, сформировав комплексный оффер в финтехе.
У Gojek есть и совсем удивительные услуги, которые я не встречал даже у самых заковыристых азиатских супераппов - например, у компании есть агрегатор услуг по уходу за домашними животными, а в пандемию компания сдавала в аренду медицинских масок (надеюсь, эта аренда не была многоразовой).
В 2018 г. произошло важное объединение - Gojek купил крупную индонезийскую ecommerce-площадку Tokopedia (это еще один индонезийский единорог), за счет чего экосистема усилила онлайн-торговлю.
Сейчас экосистема Gojek выглядит так. 3 юнита дополняют и усиливают друг друга.
Нужно отметить, что в отличие от многих азиатских tech-лидеров, Gojek - это не совсем суперапп. Напомню, суперапп - это когда компания делает зонтичный интерфейс для пользователя в одном месте и запускает площадку для внутренних мини-приложений, а эти мини-приложения уже клепают сторонние разработчики (ну, в основном). Gojek же - это именно экосистема цифровых сервисов, разработанных самой компанией.
Сейчас у Gojek более 100 млн активных пользователей в Индонезии и нескольких соседних странах, а около 80% местных предпринимателей непременно работают через него (как основной канал или один из). А всего-то надо было навести порядок в чехарде азиатских скутеров.
Gojek нередко приписывает себе титут крупнейшего цифрового сервис Юго-Восточной Азии, но...
... с этим не согласны их конкуренты из соседней Малайзии...
... Или из Сингапура, попробуй там разбери.
Появление Grab на свет чуть более прозаично, чем у их индонезийских коллег. В 2012 г. двое сингапурско-малазийских выпускников Гарварда запустили местный аналог Uber под названием MyTeksi. Стартовали в Малайзии, где долгое время сервис так и назывался, а с 2013 года стали расширяться на соседние страны - сначала в Сингапуре и Таиланде, а позже и Вьетнаме, Индонезии и на Филиппинах.
Grab решил фокусироваться на on-demand мобильности, так что в других сегментах первые годы был не очень активен (хотя сейчас ситуация меняется). Зато в райдтехе они очень быстро развернулись на полную катушку.
Начали расширение с GrabCar. Как объясняет сама компания, это не агрегатор-такси, а сервис для краткосрочной аренды частных авто с водителем. Для клиента ключевых отличия ровно два. Во-первых, если Grab Taxi агрегирует машины из местных таксопарков, которые везут в основном по счетчику, то в GrabCar водители-частники везут по фиксированному прайсу (у нас всё такси так работает, а у них вот нет). Во-вторых, в GrabCar фокус на более премиальных авто (видать, с кондиционером) и более скилловых водителях. То есть, в этом плане слегка напоминает наш Wheely. Для компании же отличий целая куча - начиная с уровня вовлечения во всю цепочкой, заканчивая регуляторкой и прочими нюансами.
Еще чуть позже Grab запустить ультра-мега-лакшери извоз под брендом GrabCar+. Возможно, в машинах по этому тарифу даже есть кожаные сидения!!
В 2014 г. компания оцифровала тех самых оджеков на мопедах под брендом GrabBike (получается, повторно оцифровала, вслед за Gojek). Потом добавила собственный каршеринг. В 2017 г. компания предложила детский тариф GrabFamily - он идет как отдельный сервис, но по сути это просто тариф. В том же году руководство Grab решило, что хватит плодить родственные сущности, и объединило почти весь свой транспорт в единый суперапп JustGrab. В связи с объединением появились и новые фичи - например, запуск единого поиска по всем машинкам с фикс тарифом, а там уж что быстрее найдется - будь то такси или частник из GrabCar.
Также с годами появился сервис поиска попутчиков GrabHitch (что-то вроде BlaBlaCar), бронирование мест в автобусах, доставка продуктов, еды и прочей всякой всячины. Позже доставку докрутили до полноценного ecommerce-сервиса под брендом GrabShop. Ну и собственный платежный сервис запилили - куда же без него, это ж азиаты.
Несколько интересностей про Grab:
В ковид компания запустила отдельный сервис для удобного и быстрого перемещения медработников между домом, больницей и пациентами. Сервис назвали GrabCare. Правда, работал он только в Сингапуре, но все равно круто.
Grab еще в 2016 г. сделал в приложении чат между водителем и пассажиром. Более того, поскольку компания сразу целилась в страны, во многих из которых было по несколько локальных языков, то в чат почти сразу прикрутили лайв-перводчики. В этом плане Grab обскакал свой оригинал, ведь в приложении Uber чат с водителем возник только в 2017 г. В Яндекс Такси еще годом позже.
Не обошлось и без скандалов. В 2022 г. курьеры и водители Grab во Вьетнаме проводили массовый протест против политики компании. По их мнению, из-за повышения цен на топливо быть курьером или таксистом стало гораздо менее выгодно, а компания слишком аморфно реагировала на эту ситуацию. Grab решили отрегировать повышением цен для клиентов (что, вообще говоря, логично), но эффект вышел так себе - грэбберы просто столкнулись со снижением заказов. В ситуацию даже вмешивались власти, в итоге ситуацию разрулили путем подкрутки условий и комиссий.
Вероятно, на этом фото недовольный вьетнамский курьер Grab пытается понять "а хули тут так мало??!"
В 2019 г. Grab стал первым декакорном (т.е. стартапом стоимостью более 10 млрд долларов) из Юго-Восточной Азии. После этого сервис продолжил бурное развитие. Ковид и пандемийные реалии дали дополнительного пинка доставке еды, товаров и прочим сервисам "последней мили". В 2021 Grab стал публичной компанией через SPAC. Сейчас у сервиса около 180 миллионов пользователей и очень прочные корни в большинстве стран региона. Однако, популярность различных его сервисов может варьироваться по странам.
Местный Wildberries, подвинувший Amazon
Прямо сейчас Shopee - самая посещаемая ecommerce-площадка Индонезии и крепкий игрок в Малайзии, Вьетнаме, Таиланде, на Филиппинах и Тайване, а еще (внезапно) в Бразилии.
Компанию основал сингапурский бизнесмен Форрест Ли. Вообще, ему принадлежит целый холдинг Sea Ltd., помимо Shopee включающий гейминговую компанию Garena (это разработчик мобильных игр и эксклюзивный дистрибьютор многих ПК и консольных хитов регионе, тоже достойный кандидат на разбор), платежные сервисы и чего только не. Многие годы компания соревнуется с тем же Grab на вершине списка самых дорогих компаний Сингапура. А сам Форрест в некоторые годы возглавлял местный список Forbes.
Фаундер Shopee Форрес Ли. Компании по ловле креветок у него нет, но зато есть крупнейшая торговая платформа в ЮВА. Тоже неплохо.
Но да ладно, вернемся к Shopee. Компания запустилась в 2015 г. в Сингапуре, а экспортироваться в соседние крупные страны стала в последующие пару лет. Сначала это был C2C-маркетплейс, примерно как наш Авито, но потом они прикрутили B2С продажи, и профессиональные крупные селлеры стали перетягивать оборот на себя.
Отдельно стоит отметить, что Shopee укреплялся на новых рынках в тот период, когда в регион активно выходили мощнейшие игроки. Во-первых, в 2017 г. в ЮВА объявился Amazon. Во-вторых, в 2016 г. Джек Ма купил сингапурскую платформу Lazada, после чего стал сжигать мегатонны юаней на конкурентную борьбу. Lazada, кстати, тоже достойна разбора в этой статье, но за ней стоят китайские владельцы и ресурсы, поэтому не совсем наш сабж.
Однако, Shopee смог победить их в Индонезии, да и на других рынках сохранил очень неплохую долю. Так как им это удалось?
Во-первых, Shopee быстрее конкурентов смог понять главные боли своих целевых рынков. По порядку:
Боль первая - не очень высокий уровень благосостояния (простите за эвфемизм) местного населения. Из-за этого нужно было фокусироваться на мобилках, причем так, чтобы сервис нормально работал на любой самой нищебродской лопате. Для этого Shopee с самого начала использовал подход mobile-first.
Mobile-first - это когда любой интерфейс, процесс или фичу пилят сразу для смартфона (мобильного бразуера или приложения). А уже позже все это дело адаптируется для десктопного формата.
Вот тут COO Shopee неплохо объясняет, что это означает на практике.
Боль вторая - низкая технологическая грамотность населения, помноженная на повальную бедность. Данная гремучая смесь приводила к крайне низкому уровню доверия к онлайн-торговле. Что логично, когда плохо шаришь за технологии в целом, а еще любое кидалово может стать фатальным для скромного семейного бюджета. Решение Shopee - собственный сервис эксроу-депонирования Shopee Guarantee. Здесь помогли финтех-компетенции материнской компании Sea Ltd.\
Эскроу - это способ оплаты, когда некая третья сторона сначала размещает (депонирует) средства покупателя у себя и передает их продавцу только когда покупка успешно совершена. Например, когда покупатель получил товар и оповестил об этом сервис, нажав соответствующую кнопку в приложении.
Проще говоря, сервис выступал финансовым гарантом сделки. Кстати, есть мнение, что с помощью похожего финта в Китае в свое время укрепился Alibaba.
Боль третья - слабая логистическая инфраструктура. Здесь Shopee использовать гибридный подход. Во-первых, он активно подключал множество локальных логистических партнеров, при этом всячески усиливая их и дополняя собственными логистическими центрами. Там, где с логистикой было совсем печально, компания выстраивала инфраструктуру с нуля. При этом, чтобы сделать доставку доступнее и привлечь побольше логистических партнеров, Shopee активно субсидировала и предлагала бесплатную или льготную доставку.
Помимо лечения глубинных болей, Shopee неплохо отрабатывала и потребительскую специфику местных рынков. Например, запилила вкладку со скидками и спецпредложениями (по сути, непрерывный канал с трансляцией скидок), а также добавил отдельный раздел с продажами через лайвстримы. Последнее - это отдельный фетиш азиатской торговли, про него я много писал у себя на канале (раз, два, три).
Вот соответствующие фичи Shopee наглядно. В середине - трансляция скидок, справа - лайвстримы. А слева зафигачили гигантский приветственный купон, чтобы у юзера не было шансов не сконвертиться.
Сейчас у Shopee около 400 млн юзеров (одни источники говорят про 300 млн, другие про 500 млн, так что я округлил), которые делают около 215 уникальных заходов на сервис в месяц. Примерно половина из них - индонезийцы, остальные - жители других стран ЮВА.
Также интересен выход компании в Бразилию. Shopee начал заходить на этот рынок в 2020 г., а в начале 2021 г. стал самым скачиваемым шоппинговым приложением в стране. Ключ к бразильскому успеху - геймификация привлечения. Shopee запустил несколько мини-игр в приложении, победители которых получали скидочные и подарочные купоны. И здесь явно не обошлось без геймдев-юнита материнской компании. Вообще, Форрест Ли очень круто добивается синергий между своими бизнесами, нашим строителям экосистем точно стоит исследовать его подход.
Кстати, заметили, что в статье шла речь аж о трех огромных трансазиатских компаниях с базой в Сингапуре? Дедушка Ли Куан Ю явно что-то знал.
На сегодня всё. Хотите такую же статью про Японию и Корею? Тогда вам сюда.
Если вы дочитали до конца, то вам наверняка зайдут мои тг-каналы, а именно:
На основном канале Дизраптор я простым человечьим языком разбираю разные интересные штуки из мира бизнеса, инноваций и технологий (а еще анонсирую все свои статьи).
А на втором канале под названием Фичизм я пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
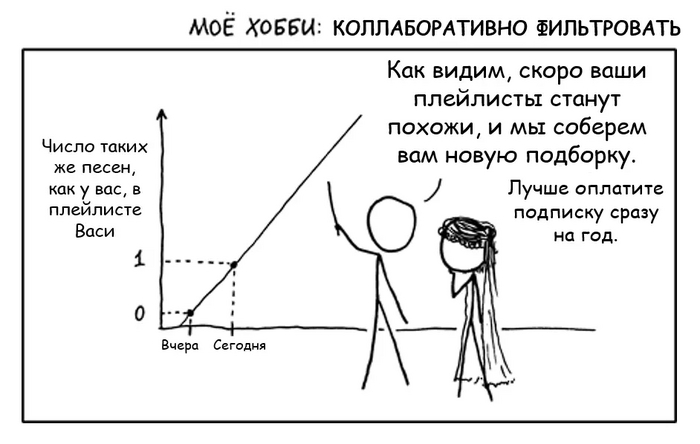
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Известный российский банк "Тинькофф" представил в App Store новое приложение, которое получило название "Т-помощь". Приложение якобы оказывает юридические консультации, однако внутри полностью идентично старому приложению банка.
Информацию о новом приложении банк дает при попытке входа в старое приложение "Тинькофф", где появляется уведомление о том, что приложение устарело.
В involta.media добавили, что скачать новое приложение стоит как можно быстрее, поскольку их быстро удаляют из-за санкций.
NightCafe - это сервис, который использует различные модели Stable Diffusion, включая мощную SDXL, и позволяет пользователям создавать уникальные иллюстрации. Вы можете опробовать сервис на их сайте.
Простота освоения сервиса оценивается на уровне 3, что означает, что он потребует некоторой привыкания, но в целом достаточно понятен для использования.
Качество генерации моделей также оценивается на уровне 3, что означает, что они создают достаточно качественные иллюстрации, но могут быть некоторые ограничения или недостаточно реалистичные детали.
Фан-эффект сервиса также оценивается на уровне 3, что означает, что он может предложить интересные возможности для создания уникальных картин.
Сервис доступен на английском языке, что может быть удобно для англоязычных пользователей.
В бесплатной версии вы можете создавать до пяти картин в день, а в платной версии, они предлагают возможность обучить нейросеть в собственном стиле. Стоимость подписки начинается от 4,79 $ (442 ₽) в месяц.
NightCafe предлагает возможность использовать различные модели Stable Diffusion и обучать сеть в своем стиле, чтобы создавать уникальные иллюстрации. Он является интересным инструментом для профессиональных дизайнеров и творческих людей, которые хотят выразить свою индивидуальность в создании картин.
Вы можете создать свою картинку при помощи нашего телеграмм бота "ТУТ"
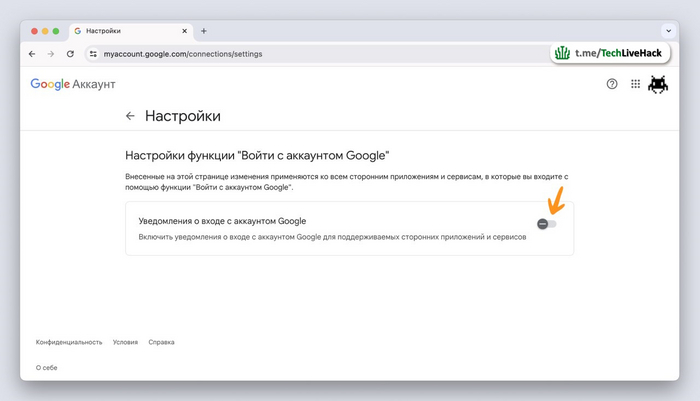
Многие пользователи сталкиваются с предложением войти на сайты через учетную запись Google. Google предоставит приложению ваше имя, адрес электронной почты и фото профиля для создания аккаунта.
Если вы предпочитаете не видеть эти всплывающие окна, то опцию можно отключить:
Пользователи сервисов Яндекса смогут осуществить вход на сервис по биометрическим данным. Теперь в Яндекс ID можно войти по отпечатку пальца.
Также Яндекс добавил возможность входа по распознованию лица, ранее данная функция была внедрена в Сбер.
Для этого Яндекс интегрировал веб-стандарт WebAuthn. В компании отметили, что биометрия пользователей остается в памяти устройства, дальше ее никуда не передают.
В involta.media добавили, что подключить возможность входа по биометрии можно в личном кабинете.