Teachable Machine - быстрый и простой способ создания моделей машинного обучения для ваших сайтов, приложений от Google.
Без специальных знаний или программирования, прямо в браузере. Бесплатно.
Даже школьник сможет с помощью веб-камеры и микрофона на своем ПК без написания кода обучать нейронные сети и экспортировать их в сторонние приложения, носители или на веб-сайты.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
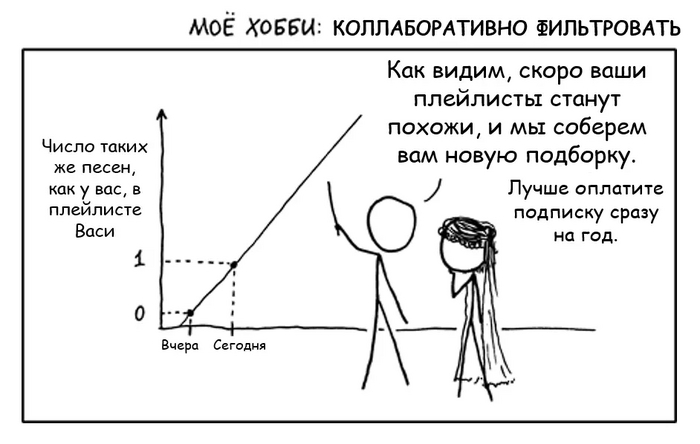
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Брехня. Человек, понимающий, что говорит, никогда бы такой бред не сочинил. Очень дорого заставлять индусов эффективно, честно и быстро решать такую задачу. Это я говорю как человек, ставивший подобные задачи индусам и другим удалённым "асессорам". Они работают медленно и норовят обмануть работодателя. Перекрестный контроль работает не так хорошо, как может показаться: ленивые асессоры хитры и изворотливы.
Сделать систему автоматического распознавания, даже с некоторой погрешностью, проще, чем заставить индусов дешево рассматривать видюшки с камер в реальном времени с той же погрешностью. Потому что данные для обучения можно размечать неспешно, перепроверять подозрительную разметку задним числом, контролировать процесс будут кровно заинтересованные амазоновские инженеры, а не копеечные бригадиры в Хайдерабаде, которым плевать на результат и которые параллельно работают операторами колл-центра, продают карри и дрочат.
В новостях про закрытие этих амазоновских магазинах ничего про индусов не говорится.
Мы наконец-то отсняли видео с разбором аргументов "за" и "против" опасности систем ИИ. Запустили ИИ в симуляции города и обсудили реальную систему, работавшую в своё время на территории Москвы. Пишите, что думаете по теме, и на какую тему хотели бы увидеть следующее видео!
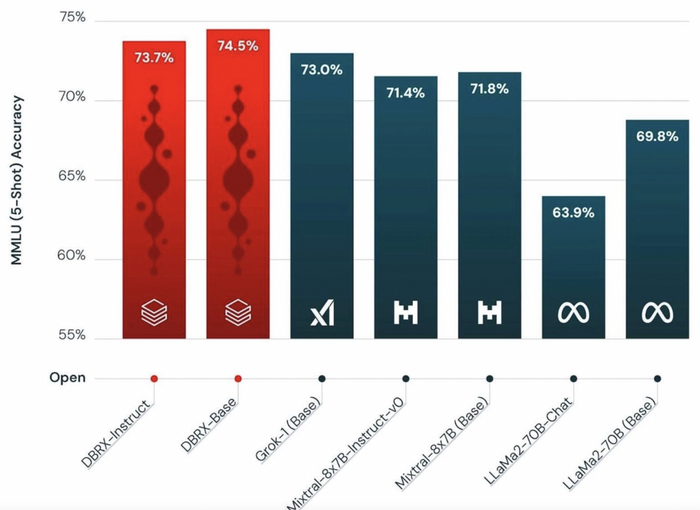
Компания Databricks только что представила DBRX, новую модель большого языка с открытым исходным кодом (LM) с ошеломляющими 132 миллиардами параметров.
Модель превосходит все открытые модели на большинстве бенчмарков.
Вот что вам нужно знать 👇
DBRX - это новая бесплатная модель искусственного интеллекта с 132 миллиардами параметров.
Может обрабатывать до 32 000 токенов одновременно.
Конференция продолжается, и на ней представлены захватывающие анонсы для сферы искусственного интеллекта
Приготовьтесь ознакомиться с последними новинками в области искусственного интеллекта, представленными на GTC 2024, ведущей конференции для разработчиков, бизнес-лидеров и исследователей этой области. На этом мероприятии были представлены содержательные вебинары, образовательные сессии и передовые демонстрационные материалы, а также многое другое. Мы собираемся рассказать о всех ключевых моментах и инновациях, представленных на этой конференции в этом году.
NVIDIA представляет сетевые коммутаторы серии X800, обладающие непревзойденной сквозной пропускной способностью 800 Гбит / с и передовыми сетевыми решениями для инфраструктур искусственного интеллекта.
Microsoft и NVIDIA расширяют сотрудничество, в рамках которого искусственный интеллект и технологии Omniverse от NVIDIA интегрируются в Microsoft Azure, Azure AI и Microsoft 365.
NVIDIA представляет Omniverse Cloud API, графической платформы NVIDIA Blackwell GPU в инфраструктуру AWS, расширяющей возможности искусственного интеллекта.
DRIVE Thor от NVIDIA преобразует транспорт, централизованный автомобильный компьютер,предназначенный для автопарков следующего поколения, от электромобилей до автономных грузовиков и роботакси.
NVIDIA анонсирует проект GR00T для человекоподобных роботов
NVIDIA представляет проект GR00T, базовую модель для человекоподобных роботов, а также компьютер Jetson Thor и обновления платформы Isaac Robotics. GR00T помогает роботам понимать естественный язык и имитировать движения человека, повышая их адаптивность и возможности взаимодействия. Компьютер Jetson Thor может похвастаться усовершенствованным SoC, оптимизированным для повышения производительности и безопасности, что упрощает интеграцию для решения сложных задач.
Project GR00T
Сотрудничество с ведущими компаниями-производителями роботов направлено на продвижение робототехники на основе искусственного интеллекта для различных приложений. Основные обновления платформы Isaac включают Isaac Lab для моделирования и OSMO для управления данными, облегчающие обучение роботов. Манипулятор Isaac повышает ловкость и возможности искусственного интеллекта для манипуляторов-роботов, в то время как Isaac Perceptor обеспечивает трехмерное окружающее зрение для автономных мобильных роботов, что способствует производству и выполнению работ. Эти инновации обещают произвести революцию в робототехнике и внедренном искусственном интеллекте с потенциальными последствиями для различных отраслей промышленности.
NVIDIA представляет суперкомпьютер с искусственным интеллектом DGX SuperPod
Компания NVIDIA представила DGX SuperPod, передовой суперкомпьютер нового поколения для искусственного интеллекта, оснащенный новейшими суперчипами GB200 Grace Blackwell. Эти чипы идеально подходят для выполнения масштабных генеративных задач искусственного интеллекта. СуперПод имеет уникальную архитектуру с жидкостным охлаждением в стойке, обладает мощностью искусственного интеллекта в 11,5 exaflops и обеспечивает 240 терабайт памяти, которую можно масштабировать с помощью дополнительных стоек. Каждая система GB200 оснащена 36 процессорами Grace и 72 графическими процессорами Blackwell, что обеспечивает до 30 раз более высокую производительность для моделей с большими языковыми возможностями.
Архитектура объединяет NVIDIA BlueField-3 DPU и Quantum-X800 InfiniBand для увеличения пропускной способности и проведения внутрисетевых вычислений. Возможности прогнозного управления обеспечивают бесперебойную работу за счет обнаружения и устранения потенциальных проблем. Кроме того, NVIDIA представляет систему DGX B200, разработанную для различных задач искусственного интеллекта на базе архитектуры Blackwell, обеспечивающую производительность искусственного интеллекта на уровне 144 петафлопс и расширенные сетевые возможности. Обе системы поставляются с корпоративным программным обеспечением NVIDIA для искусственного интеллекта и экспертной поддержкой. Они будут доступны у глобальных партнеров NVIDIA позже в этом году.
NVIDIA представляет сетевые коммутаторы серии X800
NVIDIA представляет сетевые коммутаторы серии X800: Quantum-X800 InfiniBand и Spectrum-X800 Ethernet, обладающие непревзойденной сквозной пропускной способностью 800 Гбит/с, что имеет важное значение для обработки искусственного интеллекта и вычислительных нагрузок. Эти коммутаторы значительно ускоряют работу приложений искусственного интеллекта, облачных вычислений и HPC, особенно в ЦОД, использующих новые продукты на базе архитектуры Blackwell. Microsoft Azure, Oracle Cloud Infrastructure и Coreweave являются первыми компаниями, которые внедряют эти передовые сетевые решения, подчеркивая важность надежных сетей для масштабирования инфраструктуры искусственного интеллекта.
Quantum-X800
Платформа Quantum-X800 устанавливает новый стандарт с пятью кратно большей пропускной способностью и девятью кратно большими вычислительными возможностями внутри сети по сравнению с предыдущим поколением, в то время как Spectrum-X800 оптимизирует производительность сети для облаков искусственного интеллекта и предприятий, обеспечивая изоляцию производительности в многопользовательских средах. NVIDIA предоставляет комплексную поддержку программного обеспечения, включая библиотеку коллективных коммуникаций, что повышает программируемость сети и эффективность работы. Quantum-X800 и Spectrum-X800 будут доступны у различных поставщиков инфраструктуры по всему миру в следующем году, включая Dell Technologies, Lenovo и Hewlett Packard Enterprise.
Microsoft и NVIDIA расширяют сотрудничество
На GTC Microsoft и NVIDIA объявили о расширении сотрудничества и интеграции технологий искусственного интеллекта и Omniverse от NVIDIA в Microsoft Azure, Azure AI и Microsoft 365. Это включает внедрение NVIDIA Grace Blackwell GB200 и Quantum-X800 InfiniBand в Azure для передовых моделей искусственного интеллекта. Партнерство также охватывает здравоохранение, где Azure и NVIDIA DGX Cloud используются для стимулирования инноваций. В Microsoft Azure будут размещены облачные API NVIDIA Omniverse, обеспечивающие взаимодействие с данными и визуализацию.
Сервер логического вывода Triton поддерживает прогнозы искусственного интеллекта в Microsoft Copilot для повышения производительности в Microsoft 365. Кроме того, в Azure AI появятся микросервисы NVIDIA NIM inference, ускоряющие развертывание искусственного интеллекта за счет оптимизированного вывода данных для различных моделей.
NVIDIA представляет Omniverse Cloud API
NVIDIA представляет на GTC универсальные облачные API, расширяющие возможности своей промышленной цифровой платформы-близнеца для бесшовной интеграции в существующие программные приложения. Крупные игроки отрасли, такие как Siemens, Ansys и Cadence, используют эти API для рендеринга в реальном времени, модификации данных и совместной работы в цифровых двойных экосистемах. Siemens интегрирует облачные API Omniverse в свою платформу Xcelerator, Ansys использует их для взаимодействия данных при моделировании автономных транспортных средств, а Cadence внедряет их в свою платформу Reality Digital Twin для оптимизации центров обработки данных.
Другие партнеры, такие как Trimble, Hexagon и Rockwell Automation, используют облачные API Omniverse Cloud API для революционизации проектирования и автоматизации. Кроме того, API ускоряют автономную разработку компьютеров, позволяя проводить обучение и тестирование с использованием полного стека с помощью высокоточного моделирования датчиков. Благодаря внедрению в различных отраслях, включая WPP, медиа.Monks, как и Continental, Omniverse преобразует цифровизацию, расширяя масштабы и оптимизируя производственные рабочие
AWS и NVIDIA объявили о сотрудничестве в области генеративного искусственного интеллекта.
AWS и NVIDIA объявили о партнерстве, которое включает интеграцию новой графической платформы NVIDIA Blackwell GPU в инфраструктуру AWS. Это сотрудничество предлагает суперчипы GB200 Grace Blackwell и графические процессоры B100 Tensor Core, что расширяет возможности генеративного искусственного интеллекта. За счет объединения многоузловых систем NVIDIA с системой Nitro от AWS и сетевым адаптером Elastic Fabric Adapter (EFA), партнерство создает возможность для выполнения вывода на многотриллионных языковых моделях в реальном времени с несколькими параметрами в масштабе.
Адам Селипски, генеральный директор AWS, подчеркнул важность этого сотрудничества для развития вычислений с искусственным интеллектом. Платформа Blackwell, оснащенная GB200 NVL72 и поддерживаемая функциями AWS для работы с сетями и виртуализации, позволяет реализовывать мощные вычисления на языковых моделях в реальном времени.
AWS планирует предоставить инстансы EC2 с графическими процессорами B100 для ускорения генеративного обучения ИИ и вывода данных. Кроме того, облачные инстансы NVIDIA DGX на AWS будут поддерживать разработку передовых моделей ИИ. Меры безопасности, такие как шифрование и AWS Nitro Enclaves, обеспечивают защиту данных клиентов и весовых коэффициентов моделей.
Проект Ceiba, совместная инициатива по созданию мощного суперкомпьютера с искусственным интеллектом исключительно на AWS, направлена на продвижение различных приложений с искусственным интеллектом. Кроме того, AWS и NVIDIA сотрудничают в расширении возможностей автоматизированного поиска лекарств и запуске микросервисов с генеративным ИИ в здравоохранении, демонстрируя свою приверженность продвижению ИИ во всех отраслях.
NVIDIA запускает климатическую платформу Earth-2
NVIDIA представляет Earth-2, облачную платформу, которая направлена на компенсацию экономических потерь, вызванных экстремальными погодными условиями, связанными с изменением климата, стоимостью 140 миллиардов долларов. Earth-2 использует микросервисы NVIDIA CUDA-X и предлагает облачные API в NVIDIA DGX Cloud для моделирования погоды и климата в высоком разрешении. Благодаря использованию генеративного ИИ CorrDiff, эти симуляции позволяют создавать изображения с разрешением в 12,5 раза выше, в 1000 раз быстрее и в 3000 раз более энергоэффективно, чем текущие модели.
Центральное метеорологическое управление Тайваня планирует использовать Earth-2 для более точных прогнозов тайфунов с целью минимизации потерь за счет заблаговременной эвакуации. Кроме того, Earth-2 интегрирует NVIDIA Omniverse, что позволяет визуализировать воздействие погоды в режиме реального времени. Метеорологическая компания намерена использовать API Earth-2 для улучшения своих сервисов Weatherverse. Среди первых пользователей платформы – компании для анализа погоды, такие как Spire и Meteomatics, а также стартапы, занимающиеся разработкой климатических технологий. Earth-2 использует облачную платформу NVIDIA DGX Cloud для ускорения работы с полным стеком, обеспечивая моделирование с безупречной скоростью и масштабированием.
NVIDIA Healthcare представляет микросервисы с генеративным искусственным интеллектом
NVIDIA представляет на GTC более двух десятков медицинских микросервисов, расширяя возможности глобальных медицинских предприятий благодаря инновациям в области искусственного интеллекта, доступным на любой облачной платформе. Эти микросервисы, включая NVIDIA NIM, ускоряют поиск лекарств, медицинскую визуализацию и геномный анализ благодаря оптимизированным моделям искусственного интеллекта и рабочим процессам. Среди известных приложений – интеграция микросервисов NVIDIA BioNeMo в платформу молекулярного проектирования Cadence для разработки лекарств и развертывание медицинских агентов с генеративным искусственным интеллектом для решения конкретных задач от Hippocratic AI.
Abridge использует искусственный интеллект для создания клинических заметок, в то время как Flywheel преобразует модели в микросервисы, улучшая медицинскую визуализацию и управление данными. Эти инновации призваны революционизировать уход за пациентами и исследования в области здравоохранения, удовлетворяя важнейшие потребности отрасли и улучшая результаты. Разработчики могут получить доступ к этим микросервисам и развернуть их с помощью NVIDIA AI Enterprise 5.0 в различных сертифицированных системах и облачных платформах, способствуя широкому внедрению и интеграции в экосистеме здравоохранения.
DRIVE Thor от NVIDIA преобразует транспорт
На конференции GTC компания NVIDIA представляет централизованный автомобильный компьютер DRIVE Thor, спроектированный для использования в автопарках следующего поколения, включая электромобили, автономные грузовики и роботаксы. Используя приложения искусственного интеллекта, DRIVE Thor обещает многофункциональные кабины и безопасное автономное вождение на одной централизованной платформе. Ведущие транспортные компании, такие как BYD, Hyper и XPENG, уже внедряют DRIVE Thor для своих автопарков следующего поколения электромобилей. Кроме того, компании Nuro, Plus, Waabi и WeRide применяют его в решениях для автономного вождения грузовиков и роботакси 4-го уровня. Благодаря новой архитектуре NVIDIA Blackwell, DRIVE Thor гарантирует производительность в 1000 терафлопс, обеспечивая безопасную автономную работу.
DRIVE Thor
Oracle и NVIDIA предлагают суверенные решения в области искусственного интеллекта
Oracle и NVIDIA объединяют усилия с целью предоставления суверенных решений в области искусственного интеллекта по всему миру, помогая правительствам и предприятиям развертывать фабрики искусственного интеллекта с операционным контролем для поддержки цифрового суверенитета. Используя распределенное облако Oracle и инфраструктуру искусственного интеллекта, а также программное обеспечение NVIDIA для ускоренных вычислений и генеративного искусственного интеллекта, это сотрудничество обеспечивает возможность выполнять операции с искусственным интеллектом на местном или локальном уровне. Такие решения способствуют экономическому росту, при этом обеспечивая суверенитет данных. Ключевые предложения включают корпоративный искусственный интеллект Oracle и платформу искусственного интеллекта NVIDIA с полным стеком, которые могут быть развернуты в различных облачных регионах для миграции, модернизации и внедрения инноваций в области информационных технологий.
Организации, такие как Avaloq, TEAM IM и e & UAE, уже внедрили эти решения для цифровой трансформации и расширения возможностей искусственного интеллекта, сохраняя при этом контроль над данными. Кроме того, Oracle планирует интегрировать вычислительную платформу NVIDIA Grace Blackwell в свои OCI Supercluster и OCI Compute для повышения производительности моделей искусственного интеллекта и энергоэффективности. Сотрудничество также распространяется на NVIDIA DGX Cloud на OCI, предоставляя доступ к NVIDIA Grace Blackwell для решения энергоэффективных задач искусственного интеллекта. Таким образом, эти суверенные решения для искусственного интеллекта доступны организациям, позволяя им использовать искусственный интеллект, сохраняя при этом суверенитет данных.
Google Cloud и NVIDIA масштабируют разработку искусственного интеллекта
Google Cloud и NVIDIA углубили свое партнерство для поддержки сообщества машинного обучения (ML), упрощая разработку, масштабирование и управление генеративными приложениями искусственного интеллекта. Google объявила о внедрении новой вычислительной платформы NVIDIA Grace Blackwell с искусственным интеллектом и доступности облачного сервиса NVIDIA DGX в Google Cloud. Кроме того, Google будет использовать облачную платформу DGX на базе NVIDIA H100, которая теперь обычно доступна на виртуальных машинах Google Cloud A3.
Google Cloud & NVIDIA
SAP и NVIDIA ускоряют внедрение генеративного искусственного интеллекта
SAP SE и NVIDIA объявили о расширенном партнерстве, нацеленном на ускорение внедрения генеративного искусственного интеллекта на предприятиях и преобразование данных в облачных решениях SAP. Сотрудничество направлено на интеграцию масштабируемых возможностей генерации искусственного интеллекта для конкретного бизнеса в портфолио SAP, включая Joule Copilot, с использованием SAP Generative AI Hub.
SAP & NVIDIA
Целью этой инициативы является помощь клиентам в масштабном использовании искусственного интеллекта и углублении их понимания данных. Ключевые моменты включают создание дополнительных возможностей генерации искусственного интеллекта в SAP Business Technology Platform (SAP BTP) с использованием сервиса Foundry от NVIDIA, инновационные варианты использования с облачными решениями SAP и объединение источников данных искусственного интеллекта с SAP Datasphere. Кроме того, SAP планирует использовать корпоративное программное обеспечение NVIDIA AI для генерации искусственного интеллекта производственного уровня в своих облачных решениях. Ожидается, что эти разработки станут доступны к концу 2024 года. Чтобы получить дополнительную информацию, зрители могут посмотреть повтор основного выступления Дженсена Хуанга на GTC.
NVIDIA представляет исследовательскую облачную платформу 6G
NVIDIA представляет исследовательскую облачную платформу 6G, цель которой состоит в изменении беспроводных технологий с помощью инноваций, основанных на искусственном интеллекте. Платформа, одобренная лидерами отрасли, такими как Ansys, Samsung и Keysight, предоставляет исследователям набор инструментов для продвижения разработок в области 6G. Ключевые элементы включают Aerial Omniverse Digital Twin для моделирования, Aerial с ускорением CUDA RAN для настраиваемого тестирования сети и Sionna Neural Radio Framework для интеграции с искусственным интеллектом.
Платформа способствует конвергенции 6G и искусственного интеллекта, обещая преобразовательные возможности подключения и интеллектуальные системы. Тестированию и моделированию, которые имеют решающее значение для эволюции 6G, уделяется значительное внимание благодаря вкладам ведущих поставщиков. Исследователи могут получить доступ к платформе через программу для разработчиков NVIDIA 6G, способствующую сотрудничеству и инновациям в области беспроводных технологий.
NVIDIA вносит свой вклад в японский суперкомпьютер ABCI-Q
Компания NVIDIA объявляет, что японский суперкомпьютер ABCI-Q, созданный для продвижения национальной инициативы в области квантовых вычислений, будет использовать платформы NVIDIA для ускоренных и квантовых вычислений. ABCI-Q, оснащенный более чем 2000 графическими процессорами с тензорным ядром NVIDIA H100 и работающий на CUDA-Q, гибридной платформе квантовых вычислений с открытым исходным кодом, будет способствовать высокоточному квантовому моделированию в различных отраслях промышленности. Интегрированный с NVIDIA Quantum-2 InfiniBand, он обеспечивает масштабируемую производительность для решения самых сложных задач в области квантовых вычислений.
Ожидается, что ABCI-Q будет запущен в начале следующего года. Цель ABCI-Q заключается в продвижении исследований в области квантовых технологий и их практических применений в соответствии со стратегией Японии по изучению потенциала квантовых вычислений в области искусственного интеллекта, энергетики и биологии. Система будет поддерживать моделирование квантовых схем, квантовое машинное обучение, гибридные системы классического и квантового типа, а также разработку алгоритмов.
Компания NVIDIA запустила облачный сервис NVIDIA Quantum Cloud, предназначенный для расширения возможностей исследователей и разработчиков в области квантовых вычислений в таких научных областях, как химия, биология и материаловедение. Построенный на платформе квантовых вычислений CUDA-Q, он позволяет пользователям создавать и тестировать новые квантовые алгоритмы и приложения в облаке, включая симуляторы и инструменты для гибридного квантово-классического программирования.
Ключевые функции включают генеративный квантовый собственный преобразователь, интеграцию Classiq и QC Ware Promethium для решения сложных задач квантовой химии. У NVIDIA более 160 партнеров, интегрирующих Quantum Cloud в свои предложения, включая поставщиков облачных услуг, таких как Google Cloud и Microsoft Azure, а также ведущие квантовые компании. Ранний доступ к NVIDIA Quantum Cloud доступен для новаторов в области квантовых вычислений.
Автор этих рвущих жёппы тезисов просто решил забайтить народ за эти самые жопы.
На самом деле это довольно капитанские и бессмысленные в большинстве своём утверждения. Ну кроме тех, которые чушь.
По порядку:
"Без кода" - чей-то чужой код.
Так и есть. Но что автор тезиса хотел сказать этим? Дело в том, что чем меньше кода решают одну и ту же проблему, тем лучше. Код - это нагрузка. За ним нужно ухаживать как за грядкой. Если вы можете решить свои продовольственные вопросы получая всё с маленькой грядки, то это во всех смыслах лучше, чем ухаживать ха огромным огородом ради того же самого набора продуктов. В случае, если этот огород ещё и не ваш, а продукты вы получаете, то это вообще идеально! Все довольны.
"Облако" - чужие сервера
Тут то же самое, что и с пунктом выше. Держать свой датацентр и свои сервера - это тот ещё геморрой. Это удел параноиков (по долгу службы или по личным предпочтениям). Если вам нужны не сервера, а результат их работы, то зачастую лучше сконцентрироваться но собственных бизнес-задачах и не пытаться автономно обеспечить себя всем.
Представьте, если бы компании не останавливались на развертывании своих датацентров, а заморачивались еще и собственным производством микрочипов, чистого кремния, добычей и очисткой металлов, производством всего спектра оборудования для производства всего спектра оборудования... Если кто-то до сих пор держит свои датацентры, то это всего лишь вопрос недоработки. Например нет нужных стандартов, нездоровый рынок в плане монополии и т.д.
"Машинное обучение" - статистика на стероидах
Ага. Но так и что же? Вы так говорите, как будто это что-то плохое.
"Искусственный интеллект" - большой объём "условных операторов" "Что Если"
А вот тут как раз чушь для хайпа или от непонимания.
ИИ (в том виде, в котором этот термин употребляется сейчас в применении к нынешним технологиям) - это не куча "ифов". Это упрощенная модель мозга, которую именно что обучили на огромном массиве данных. Как уложились данные в этой модели мозга и как получается результат нам не сильно понятнее, чем как это присходит в голове крысы, решающей задачи поиска в лабиринте. Нынешние нейронные сети, если не впадать в бессмысленное утрирование, это продукт фазового перехода сложности и объёма данных. Разница между набором условий в классическом алгоритме и нейронной сетью как между инфузорией туфелькой и смышлёным камариком, который на своих нейронах умеет в навигацию, сенсоры, адаптивность и прочее...
Подите реализуйте такого же камарика на условиях. Не имитацию, а именно функциональный аналог. А потом будете говорить что нейросеть - это ифы.
"Блокчейн" - неэффективная база данных, безопасность которой обеспечена всеобщим недоверием.
Когда заходит речь об эффективности, нужно говорить и о критериях оценки оной. Эффективность - это понятие не простое. Вот пушка не эффективна для охоты на воробья, а по испанскому галеону прошлых веков она вполне годится стрелять. Эффективность нужно рассматривать в конкретном применении. Для того, для чего придумали Блокчейн, он очень эффективен. А именно он эффективен для хранения и верификации цепочек транзакций в среде без доверия. Просто нет альтернатив.
"Биг дата" огромный объём данных с которым никто не знает что делать.
Тоже, знаете ли... Если вы не знаете, то это не значит, что никто не знает. Да, постоянно находятся новые применения, и это везде так. Иногда бигдату имеет смысл собирать на будущее.
"Умный дом" - дом, который знает о твоей диете больше тебя.
Вообще бред какой-то. Правильно в наших реалиях так: Умный дом - это штука, которая создаёт проблем больше, чем решает, и вопреки предназначению постоянно раздражает пользователей неочевидным поведением в вопросах, в которых привычна простота.
Я тоже большой поклонник вот этой всей херни с умным домом, но это не значит, что рядом с такими энтузиастами как я приятно и комфортно жить. Особенно когда я в командировке без связи, а свет почему-то включается в спальне в 3 часа ночи каждые десять минут.
"Виртуальная реальность" - модный способ игнорировать окружающую действительность.
Это скорее про социальные сети. Виртуальная реальность - это как ИИ (до недавних пор). Мы сраные десятилятия "вот вот" придём к этой самой виртуальной реальности, а на деле получаем 3д-телевизоры на полтора раза поиграться, гугл-в-глас - очки о которых все забыли уже, тошнотворные задержки и невозможность нормально "ходить"=). Всё это впереди, но когда - это пока не понятно. Не наступил момент фазового перехода, как с нейросетями сейчас происходит.
Если с нейросетью уже можно пообщаться получив много пользы, то провести с пользой время в VR пока есть ГОРАЗДО меньше возможностей.
"Квантовые вычисления" - технология смысл которой даже разработчики полностью не понимают.
Ну да, но там всё не так сложно, если не лезть вглубь и не пытаться что-то с помощью этого сделать. =) Очередная научная свистоперделка для обывателей, которая выльется в реальные полезные технологии ещё когда-нибудь потом в будущем. А пока нужно иметь большую головчу и гору энтузиазма, чтобы копаться и разбираться вэ том. Жаль, что процент таких людей не велик.
"Интернет вещей" - способ сделать так, чтобы даже твой тостер можно было взломать через интернет.
Ну тут, если сцедить яд, то примерно так и есть=). Однако это тенденция и она есть. Со временем это выльется в красивую незаметную магию технологий будущего. Будущего, в котором вам не надо будет задумываться о связи, о настройках этой связи, о совместимости... Будет магическое мышление без особого понимания как оно там внутри устроено. Сейчас так многие ездят на машине не особо вдаваясь как там у нее работает трансмиссия и ДВС. Многие играют и работают на компьютерах не вникая как там алгоритмы перемалывают для этого гигабиты. В какой-то момент такая же магия придёт и в локальную бытовую автоматизацию рутинных вещей. Свет будет гореть там, где он нужен, а там где не нужен - не будет. И в 80% случаев этого будет достаточно, а для остальных 20% можно будет сделать магический пасс рукой в сторону лампочки, и она засветится. Может быть нужно будет ещё произнести "Люминос максима".
То же и про тостер. Тосты просто будут готовы когда они вам нужны, но если тостер не угадал пока, или не "привык" ещё к вам, то можно будет махнуть ему рукой в специфическом жесте, и он всё поймёт как надо.
Взломы всего этого тоже, кстати, обещают быть в будущем эпическими и интересными. Жду будущего всегда с интересом и нетерпением, но, надо сказать, что и вокруг нас уже полно этого самого "будущего". Надо уметь видеть.