Подойдет даже если никогда не делал сайты. Можно заработать, имея интернет и ПК/ноут.
Сегодня поговорим про то, как делать денюжки в нише сайтостроения как ты уже понял из заголовка, бояться не стоит конкуренции или того, что придется идти на биржи фриланса с копипастными портфолио, чтобы вечность сидеть ждать заказы - нет.
В общем разберем с тобой "небольшую подработку", которая даст возможность к своему основному виду деятельности делать +- от 5 до 40к₽ в неделю, зависит от вовлеченности и усердия.
Не обращай внимания на разброс цифр, ведь у каждого свои обстоятельства и возможности, я указал примерные данные, просто для понимания ситуации.
Что будет необходимо для работы?
Антидетект браузер (можно использовать любой, у которого есть бесплатный доступ "пробник" или определенное количество, например 10 у Incogniton). Еще есть Indigo и Multiaccount.
Прокси, чтобы рандомизировать свое местоположение, и не вызывать подозрений с одного и того же железа у Авито;
Доска объявлений: Авито (преимущественно), если вы в другом регионе то OLX или Kaspi.
Рабочая почта под каждый профиль.
Виртуальная или живая симка, если есть лишние.
Конструктор сайтов Tilda, с бесплатными рандомными доменами и простыми минималистичными бесплатными шаблонами.
Теперь к самому процессу:
Заходим с созданного нового аккаунта на доску объявлений, для поиска - частного мастера. Важно именно частного для начала, а затем уже и с фирмами работать.
*первым делом всегда нужно нарабатывать репутацию и первые отзывы.
Создавать сайты особо долго и упорно учиться не нужно - быстрее и лучше использовать заготовленные шаблоны, меняя данные мастеров.
Далее читаем объявление, и если там нет какой-то агрессии, или кучи противоречий, то можно брать в работу и смело начинать через личку (применяя СИ разумеется) обрабатывать.
Для начала пишете цепляющий вопрос, уже издалека создающий потребность: "Здравствуйте, у вас есть сайт?". ты подогреешь интерес, может интересуешься прайсом на услуги и т.д., поэтому в 75% случаев отобранные тобой адекватные люди пойдут на контакт.
Если не отвечают прочитав вопрос (игнор), то переспрашиваешь 1 раз, "Олег, вы не ответили, есть ли у вас сайт?". Если не идет ответа снова - идешь дальше, не зацикливаешься.
Работаем с предложением, если ответили "нет сайта" следующим образом:
Делаем скрины фотографий мастера (на фото он должен быть), обрезаем водный знак авито, и начинаем создавать под него простую страничку с его данными с объявления.
Контакты, описание, ссылку на профиль (на него же в Авито), и сохраняешь готовый шаблон. Копируешь ссылку на него, домен рандомный, не красивый, но все это мелочи.
Идешь в переписку, и скидываешь ему ссылку прям туда, и далее кидаешь сообщение со своим УТП.
Итак, твой прайс минимум 500₽, а максимум 1500₽ (в зависимости от региона и количества работы - смотришь отзывы его), рекомендую в пределах 600-1100₽ за сам сайт.
Далее уже допы: зарегистрировать домен, прикрутить его к сайту, добавить/подправить информацию, и передать полностью со всеми потрохами.
Все делается в течении 30-50 минут, если не отвлекаться, и сразу продать максимум всего, если человеку все не до сайта было, и думал что дорого, но знал всегда, что он нужен, хотя бы как Визитная Карточка для своих клиентов.
*из переписки Авито человек в 90% случаев переходит на него, и видит свою актуальную информацию. Уже готовый продукт, который - бери и пользуйся, да еще и за копейки. Для мастера 500-1000 это мелочь, так как те же плиточники успевают даже видеоблоги в шортсах вести и делать дополнительные реальные мани.
Поэтому не переживай из-за первых отказов на первых порах, и оттачиваешь свой навык убеждения и продаж в первые недели работы.
Доп. заказы с биржи фриланса:
У Кворка есть определенный лимит на отправку приветственного сообщения-отклика на работу, так называемое "cover letter". Вот их параллельно и используй, отправляя их из месяца в месяц, потихоньку придет первый заказ, затем первый отзыв, а потом уже и оттуда полноценно через несколько месяцев будут падать заявки, так как аккаунт прокачается и будет получать показы от самой биржи + сарафан.
С набором инструментов выше, ты сможешь создавать до 50 сайтов. На шаблонах оставляешь свой контакт, чтобы даже если не актуально на момент твоего предложения, то он сможет к тебе обратиться позже, чтобы выкупить и разобраться.
Такое нормально, так как мастера часто загружены работой и им некогда справить нужду или нормально поесть.
Также хочу отметить, что ты всегда можешь быть дальновиднее, и развить навык еще лучше, овладеть кучей функций, разобраться глубже, и делать сайты как элемент контента для shorts и вести блог как ремесленник, такое смотрят (формат "как создает сайт", "реальный заказ на фрилансе", "переписки с заказчиками - тупняк 2" и т.д.).
Кроме того, блоги приносят не только известность с рекламодателями (сервисы, плагины и партнерки), но и реальные заказы для компаний или продуктов.
Поэтому подумай и о будущем, а не только о штамповке простоты в массы.
Перед тем как писать мастерам - разберись с функционалом на Тильде, и научись копировать свои шаблоны и менять разные блоки, вставлять картинки. Это обязательно нужно делать в первую очередь. Если самому стремно - загляни на ютубчик ;)
Использовать конструкторы, CMS или ИИ - дело твое.
У знакомой взломали аккаунт в телеграм. Синтезировали аудиосообщение о просьбе 20 тысяч. Очень похожий голос (нейросеть на основе голосовых очевидно). Кто-то повёлся. Я - нет, т.к. всегда перезваниваю на обычный номер в таких случаях.
В итоге написано в теходдержку телеграма, заменена симка с сохранением номера. Атака длилась час примерно и прекратилась то ли после обращения в поддержку (ответа пока нет на почту), то ли после замены симки. Телефон не терялся.
Приходила смс от магазина куда она когда-то ходила. Она прошла по ссылке. Говорит, что открылся сайт, посмотрела и закрыла. Через небольшой промежуток времени началась атака.
В телеграм она могла зайти, но её тут же "выбрасывало" - поэтому завершить "чужую" сессию не получалось.
По её описанию, если всё так как она говорит - мне кажется по ссылке "что-то" незаметно поставилось. Какая-то программа. Она позволила вскрыть телеграмм. Потом программа удалила смс (т.к. на текущий момент смс отсутствует, а она его не удаляла. Была именно смс). Удалилась ли сама программа - не знаю. И как она так поставилась, что разрешения на установку не спрашивала, тоже вопрос (по умолчанию программы только от официального магазина же ставятся). Неплохая такая программа, похоже.
Вопрос - непонятно, отследил бы её антивирус или нет (если бы стоял)?
Рекомендации во избежание взлома : поставить 2х шаговую верификацию в настройках (облачный пароль). Плюс passcodelock на чаты. Ну и завершить все ненужные сеансы профилактически.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
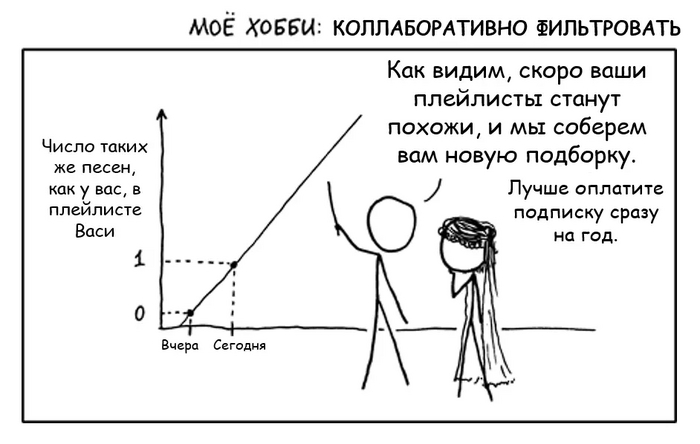
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Сегодня расскажу про несколько популярных прибыльных направлений в заработке, которые ты вполне можешь освоить с полного нуля.
Важно сосредоточиться на том, что количество источников дохода может быть несколько, а лучше чтоб они вообще были полупассивными (или пассивными), и занимали не более 3-5 часов в сутки, принося профит каждый божий день.
Так организовать свой доход можно и даже нужно, но главное это знания. Без них не получится ни выбрать что-то стоящее, ни автоматизировать, ни запустить.
Не так давно, на этом самом канале, мы говорили про ИИ
, который может быть помощником в создании контента.
Тут важно учитывать важную составляющую - монтаж, если алгоритм видит что тут дело рук одной только нейросети, то разумеется такой контент не пройдет, но никто не говорил, что сценарий и вообще в целом содержание можно как-то отследить кто писал.
Поэтому можно также быстро делать контент и ручками через монтажные проги типа capcut. Будет все также быстро, а функционал по автоматическому добавлению субтитров (анализ речи и преобразование ее в текст на видео) есть уже даже в адоб премьер про, афтер эффектс, капкут.
И так ближе к делу
Первый способ: Онлайн услуги. Фриланс.
Что сюда входит из наиболее популярных направлений?
Создание чат-ботов;
Монтаж шортс видео;
Создание обложек для шортс видео;
Монтаж широкоформатных длинных (классических) видео для ютуба, ВК видео и/или Рутюба;
Создание обложек к видео для длинных роликов;
Написание сценариев (с помощью ИИ разумеется) к роликам;
Настройка любого вида рекламы (Директ, Контекст, Таргет, Тизеры и т.д.);
Создание сайтов тоже может быть, тут главное нишу найти, и делать на объемах.
Это единственный проверенный и надежный способ заработка, где вы получаете ровно столько, сколько обговорили и сделали. Времязатраты могут быть колоссальны как и рост по экспаненте сложности проектов.
Советы:
Выбирайте из всего, что нагуглите именно то, что вам самим интересно, чтобы на дистанции не перегореть.
Найдите обучения в базах различных Пиратских бухт и Шервудов максимальное количество информации и изучайте, далее уже бегом к практике.
Будьте готовы делать первые заказы бесплатно, чтобы наработать клиентскую базу, портфолио и отзывы. Взаимодействия с клиентами также отрабатываете.
Базовому монтажу можно научиться за 1 день :)
Где искать заказчиков?
Личных подход: это создание персонализированного предложения инфлюенсеру, компании или бизнесу, изучив деятельность и проанализировав имеющееся в оформлении или наполнении. Тут только добиваться долго и упорно, но контракты на несколько лет того стоят.
Можно и нужно писать блогерам, но максимально по делу, а не с просьбами взять на работу, потому что вы классный и он тоже крутой и вам суждено быть вместе
Классические биржи фриланса, при чем все, которые есть.
Биржи-маркетплейсы, типа файвер или кворк - оформляете карточку со своими предложениями и услугами.
Совет: выбирайте сами с кем работать, особенно в первом варианте, основывайтесь на личных ощущениях, отзывается ли та или иная деятельность, и готовы ли вы для них делать что-то.
Спойлер: с первого раза может не получиться. Не расстраиваемся и не отчаиваемся.
Миллионы не заработать на линейном доходе, где потраченное время = определенная сумма.
2. Партнерские программы (ПП)
Второй и приличнейший (идеальный для старта) способ заработка после работы на фрилансе и регулярным общением с заказчиками.
Здесь все просто. Получаем % от продаж за рекомендации товаров или услуг, работая как напрямую с компаниями, так и через посредников, которыми являются сами партнерские программы.
Вы некоторые из них должны знать: Admitad, Rafinad, Workle, Elama, Яндекс Маркет. Бывают и встроенные партнерские программы у различных сервисов, то есть у каждого своя, даже у той же Robokassa и Prodamus, Timeweb отличная партнерка, и выплаты до 40%.
Жир одним словом, особенно если учесть, что вложений не нужно, можно начать вообще без ничего.
Как продвигать эти партнёрские ссылки?
Можно писать статьи, и подключать конечно нейронки в помощь, главное следить, чтобы смысл не потерялся, и ключевые слова были внутри "зашиты".
Дзен, VCru, 9111 и прочие будут готовы вас принять.
Важно: в статьях лучше оставлять ссылки на видео, а не напрямую ссылку, так как модерацию не пройдет и могут еще последовать санкции. Лучше по чуть-чуть долго, чем много и один раз :)
3. Видеоконтент
Рилсы, Тикток, ВК Клипы, Яппи, Шортсы, Длинные для ютуба и для вк с рутюбом - где угодно.
Навык создания видеоконтента, где и съемку нужно знать и сценарии и монтаж, и разбираться в трендах, понимать как работают алгоритмы и что зайдет что не зайдет - очень востребован и ценится.
В самом ютубе есть всё - с чего начать свой канал, какую тематику выбрать, как постепенно научиться монтировать, и как развивать его дальше в долгую - всё вообще доступно, как говориться: "научись правильно гуглить".
Что можно получить с 1 видео?
Оплата ютубом за просмотры (монетизация с нюансами, но она есть);
Партнерки, если даете в видео полезность или просто вставили как интеграцию;
Реклама. Интеграции в виде построллов или преролллов (в конце или в начале видео), оплачивают напрямую на расчетный счет или обычный банковский по номеру карты или телефона;
Свои услуги или товары (мерч например), который косвенно упоминаете в своем же видео.
Главные плюсы: обилие вариантов монетизации приобретенных навыков и возможность 1 единицу контента распространять по всем имеющимся площадкам как автор, получая больше охвата.
Заморочиться нужно да, но потолка в доходе нет. Стоит того, чтобы вникать, и намного интереснее чем фриланс.
4. Дропшиппинг - продажа чужого товара за %
Отличный вариант для тех, кто не считает себя творческой личностью, и не хочется рисовать обложки или тыкать постоянно в ПК мышкой, монтируя ролик или печатать посты/статьи на заказ.
Тут все более понятно. Продал 1000 ед. по своей цене по 250 условно, заказчику (или производителю) обошлось в закупке по 100 - заработали все.
Нюанс в том, что % не всегда щедрый, и тут необходимо тщательно найти тех, с кем будете сотрудничать, кто щедро насыпет за труд, и перспективы роста покажет.
5. Нейронки
Один из самых свежих способов заработка, особенно для тех, кто не имеет стартового капитала.
Самое главное что нужно понять - как с их помощью можно заработать. Какие есть сейчас доступные и качественные, и как все организовать так, чтобы они выполняли 85% работы, при чем без отклонений от ТЗ.
ChatGPT пишет сценарии и тексты, а может и код написать :)
Глюки, английский интерфейс и впн конечно могут убить желание работать с ними, но все же отбрасывать в сторону на совсем не стоит.
Более подробно: как заработать на искусственном интеллекте - я разобрал в своем ТГ канале
Сайт генерирующий планы обучения на любую сферу знаний. Позволит выучить любой навык. Достаточно ввести навык, который хотите изучить и нажать на него. В результате сайт выдаст целый план обучения.
В плане будет не только база, но и продвинутые навыки. К примеру, вы можете узнать как выучить какой-либо язык или узнать как сделать искусственный интеллект.
После выхода обновлений компания оставила нас без подробностей, но теперь они появились.
Если коротко, то обработка изображений могла приводить к исполнению произвольного кода. Через подобные дыры хакеры могут встраивать вредоносные коды в само изображение, в итоге попадая в вашу систему и воруя данные.
Уязвимости связаны с CoreMedia и WebRTC. Их обнаружил Ник Гэллоуэй из команды Google Project Zero, которая ищет уязвимости нулевого дня.
Проблему устранили с помощью улучшенной проверки ввода.
Советую обновить свои яблочные устройства до последней версии.
Я хочу начать с того, что если вы ждете ответа в конце, вы будете разочарованны. Его просто не существует. Я весь 2005 год проработал стажером на Nickelodeon Studios, чтобы повысить свой уровень в мультипликации. Естественно, бо’льшую часть практики мне не оплачивали, но я получал льготы в образовании. Для взрослых это может и не значить ничего особенного, но любой подросток того времени наизнанку вывернулся бы ради такого. С тех пор, как я начал работать непосредственно с редакторами и аниматорами, я получил прямой доступ к еще не вышедшим эпизодам. В это время как раз был закончен полнометражный фильм по Спанчбобу. На него ушла вся креативность, поэтому новый сезон вышел позже, чем планировалось. В действительности же задержка произошла по более печальным причинам. Была проблема с первыми сериями, и она затормозила всё и вся на несколько месяцев. Я и два других стажера были в редакторской студии вместе с ведущими аниматорами и звуковыми редакторами и собирались работать над последней редакцией серии. Мы получили, как нам казалось, копию эпизода «Боязнь крабсбургера» (“Fear of a Krabby Patty”) и собрались вокруг экрана, чтобы посмотреть его. Пока серия не приняла окончательный вид, аниматоры часто вставляют в неё забавные надписи, что-то вроде профессиональной шутки. Например, обычные надписи заменяются на непристойные, вроде «Как секс не работает» (“How sex doesn’t work”) вместо «Рок двустворчатых» («Rock-a-by-Bivalve») в серии, где Спачнбоб и Патрик усыновляют морской гребешок. Ничего особо смешного, просто приколы на работе. Поэтому, когда мы увидели название «Самоубийство Сквидварда», мы решили, что это не более чем подобная шутка. Один из стажеров издал смешок. Как всегда, играла веселая музыка. Сюжет начинался с упражнений Сквидварда на кларнете, как обычно, со множеством фальшивых нот. Снаружи слышится смех Спанчбоба, Сквидвард перестает упражняться и вопит ему, чтобы тот вёл себя потише, потому что этой ночью концерт и ему нужно тренироваться. Спанчбоб соглашается и вместе с Патриком идет проведать Сэнди. Появляется экран с пузырьками, и мы видим окончание концерта Сквидварда. С этого момента начинается что-то подозрительное. Пока Сквидвард играет, некоторые кадры повторяются, в отличие от звука (в этом месте звук синхронизирован с анимацией, так что это необычно), но когда он перестает играть, звук заканчивается так, будто скачков и не было. Слышен легкий гул публики, затем она начинает освистывать его. Не так как обычно в мультиках, в освистывании можно ясно различить ненависть (? malace). Мы видим Сквидварда крупным планом, он явно боится. Кадр переключается на публику со Спанчбобом в центре, он тоже освистывает Сквидварда, что на него не похоже. Хотя это не самое странное. Странно то, что у всех слишком реалистичные глаза. Очень детально вырисованные. Не фото настоящих человеческих глаз, но нечто более реальное, чем компьютерное изображение (CGI). Зрачки были красными. Мы озадаченно посмотрели друг на друга, но, так как мы не сценаристы, то не задавались вопросом о том, можно ли это смотреть детям. Кадр переключается на Сквидварда, который сидит на краю кровати и выглядит очень несчастным. Из окна-иллюминатора видно ночное небо, так что после концерта прошло немного времени. Тревожит в этом месте отсутствие звука. Его буквально нет. Не слышно даже фонового шума динамиков, будто они выключены, хотя индикатор показывал, что они исправно работают. Сквидвард просто сидел там, моргая, в тишине примерно полминуты, потом начал тихо всхлипывать. Он закрыл руками (щупальцами) глаза и тихо плакал еще целую минуту, и в это время фоновый звук очень медленно нарастал от неслышного до едва слышного. Звук напоминал лёгкий лесной ветерок. Картинка стала медленно приближаться к лицу Сквидварда. Говоря «медленно», я имею в виду, что кадры с разницей появления меньше чем в 10 секунд были неотличимы друг от друга. Всхлипы становятся громче, в них слышно больше боли и злости. Экран на пару секунд немного вздрагивает, будто закручивается вокруг центра, потом возвращается в нормальное состояние. Звук лесного ветерка медленно становится громче и настойчивее, как если бы где-то вот-вот разразится шторм. Он становится жутким, а всхлипы Сквидварда звучат так реально, что кажется, что они доносятся не из динамиков, а так, будто вместо динамиков дыры, и звук доносится с другой стороны. Какого бы хорошего качества звук ни производился в студии, для создания звука такого качества в ней просто не было оборудования. За звуками ветра всхлипов было очень слабо слышно что-то похожее на смех. Он появлялся странными отрывками и ни разу не длился больше секунды, так что было сложно уловить его (мы просмотрели этот эпизод дважды, так что простите, если всё это звучит слишком странно, но у меня было время поразмыслить над этим). Через 30 секунд экран затемнился, сильно вздрогнул, что-то вспыхнуло, как если бы один кадр был удален. Ведущий мультипликационный редактор нажал паузу и прокрутил покадрово. То, что ты увидели, было ужасно. Это было фото ребёнка не старше 6 лет. Его лицо было в крови и синяках, один глаз лопнул и свисал с запрокинутого лица. Мальчик был раздет до нижнего белья, его живот был грубо разрезан, и внутренности лежали рядом с ним. Он сам лежал на каком-то тротуаре, скорее всего, на улице. Самым жутким было то, что на фото была видна тень фотографа. Не было пометок криминалистов, по ракурсу съемки было понятно, что снимок был сделан не простым очевидцем. Похоже, фотограф был причастен к смерти ребёнка. Конечно, мы были шокированы, но не прекратили просмотр, надеясь, что это была просто жестокая шутка. Экран показал Сквидварда вполовину роста, всхлипывающего громче, чем раньше. Из его глаз по лицу текла кровь. Она тоже была сделана слишком реалистично, казалось, до нее можно дотронуться и почувствовать на пальцах. Ветер превратился в лесной ураган, слышен был даже треск веток. Смех, глубоким баритоном, длился дольше и появлялся чаще. Примерно через 20 секунд экран опять дернулся, проскочил один кадр. Редактору не хотелось перематывать назад, как и всем нам, но он знал, что должен был это сделать. На этот раз появилось фото маленькой девочки, не старше первого ребёнка. Она лежала на животе, рядом в луже крови лежали её заколки. Её левый глаз тоже лопнул и вывалился, на ней не было ничего, кроме трусиков. Её внутренности были вынуты через грубый разрез на спине и лежали на ней. Тело опять было на улице, была видна тень фотографа, по форме и размеру очень похожая на предыдущую. Я подавил рвотный позыв, один стажер, единственная девушка в комнате, выбежала. Серия продолжилась. Примерно через пять секунд после фото Сквидвард замолчал, затихли все звуки, как это было в начале этой части серии. Он опустил щупальца, его глаза сейчас были слишком реалистичными, как у других персонажей в начале серии. Они были налиты кровью, пульсировали и кровоточили. Он просто смотрел на экран, будто наблюдал за зрителем. Где-то через 10 секунд он начал всхлипывать, уже не закрывая глаза щупальцами. Звук был пронзительным и громким, самым страшным в нем были всхлипы, смешанные с криками. Слезы и кровь ручьем лились по его лицу. Вернулся звук ветра и глубокий смех,появилось еще одно фото и в этот раз оно показывалось добрых пять кадров. Редактор остановил на четвертом и прокрутил назад. Сейчас на снимке был мальчик, примерно того же возраста, но сама сцена была другой. Внутренности были вынуты из живота и накручены на большую ладонь, правый глаз лопнул и свисал вниз, по нему тонкой струйкой текла кровь. Мультипликатор переключил на следующий кадр. Сложно поверить, но он отличался от предыдущего, хотя мы не могли понять, чем. То же самое и со следующим. Мультипликатор переключил на первый кадр и прокрутил все 5 быстрее, и я не выдержал. Меня стошнило на пол, у мультипликационного и звукового редакторов перехватило дыхание. Пять кадров не были пятью разными фотографиями, похоже, это были кадры из видео. Мы видели, как рука медленно поднимает внутренности, как глаза ребёнка фокусируются на них, на последних двух кадрах мальчик даже начинает моргать. Ведущий звуковой редактор сказал нам остановить видео, потому что ему нужно позвонить разработчику, чтобы тот приехал и посмотрел на это. Мистер Хилленбург (mr. Hillenburg) приехал примерно через 15 минут. Он был озадачен тем, что его вызвали сюда, так что редактор просто снял видео с паузы. Когда эти несколько кадров закончились, все крики и звуки опять прекратились. Лицо Сквидварда было взято крупным планом, он просто смотрел на зрителя примерно три секунды. Кадр быстро исчез, тот же глубокий голос произнес «СДЕЛАЙ ЭТО», и мы увидели в руках Сквидварда дробовик. Он немедленно вложил ружье себе в рот и спустил курок. Реалистичная кровь и мозги разбрызгиваются по стене и кровати за ним, и он с силой летит назад. Последние 5 секунд эпизода его тело лежит на своей стороне кровати (в оригинале bod, видимо, опечатка), один глаз свисает с того, что осталось от головы, на пол и безучастно смотрит вниз. Эпизод заканчивается. Мистер Хилленбург, само собой, срывается на нас. Он требует объяснить, что за чертовщина происходит. Большинство людей к этому моменту уже покинули комнату, так что только немногие из нас остались посмотреть эпизод во второй раз. После повторного просмотра весь эпизод в точности запечатлелся в моей памяти и послужил причиной моих страшных ночных кошмаров. Я жалею о том, что остался. Единственное предположение, которое мы могли выдвинуть, заключалось в том, что кто-то отредактировал файл на пути от художественной студии до этого помещения. Мы вызвали технического редактора, чтобы он выяснил, когда это произошло. Анализ файла показал, что был отредактирован новый материал. Тем не менее временная отметка показывала время всего на 24 секунды раньше, чем то, когда мы начали смотреть видео. Всё использовавшееся оборудование, включая технику и программное обеспечение, было иностранным, возможно, временная отметка сбилась и показывала неправильное время, но все остальное было исправно. До сих пор ни мы, ни кто-либо другой не знает, что произошло. Было проведено расследование касательно природы фотографий, но оно ни к чему не привело. Дети не были опознаны, в данных и на фото не было ни косвенных, ни прямых улик. До этого я никогда не верил в необъяснимые явления, но сейчас, если случится что, чего я не смогу объяснить, я подумаю дважды, прежде чем списать всё на случайность. Само видео вы можете найти на просторах интернета.
Когда то и у эмигрантов из Узбекистана были свои форумы.Самым основным был fromuz.com- он давно мертв почему-то.Хотя проект был очень прибыльным.Я не понимаю мотивов владельца но уже как случилось так и случилось.
Там тоже были литературные произведения , стихи , очерки и рекомендации. Конечно львиную часть обьема держали срачи на разные темы , как и на Пикабу но что-то теплое, родное держало людей на ресурсе. Вживую люди собирались сотнями и в разных городах отчаянно гуляли.