Supertone Shift позволяет пользователям мгновенно преобразовывать свой голос в голос выбранного персонажа в режиме реального времени.
Время задержки минимальное - 47 миллисекунд, что обеспечивает плавное и естественное взаимодействие в реальном времени. Хороший инструмент для создания разнообразного и уникального контента.
Плюсы и минусы:
Плюсы:
Использовать можно абсолютно бесплатно до 26 июня, затем планируется его полноценный запуск
Программа устанавливается на компьютер, доступны версии как для Windows, так и для MacOS
Сервис способен изменять ваш голос в реальном времени в таких приложениях, как Zoom, Telegram, Discord, FaceTime.
Вы даже можете записывать аудиосообщения в Telegram, используя измененный голос, что добавит пикантности вашим разговорам.
Минусы:
На начальном этапе доступно только 10 тестовых голосов, но вы легко сможете подобрать нужный тембр.
Хорошая возможность для анонимных владельцев каналов и групп пообщаться с аудиторией, например. Так же сервис придется по душе подкастерам, стримерам, пранкерам, VTubers, геймерам. В общем, универсальный инструмент для любого, кто заинтересован в инновационном использовании голоса в цифровых медиа и развлечениях.
Надеюсь, статья была для вас полезной, если вы хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни, то добро пожаловать в мой телеграм канал НейроProfit, где я рассказываю, как можно использовать нейросети для бизнеса.
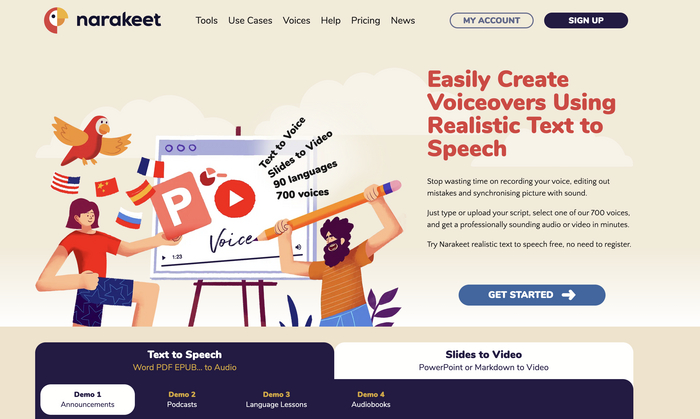
Narakeet - удобный сервис с русским языком в наличии, где можно напечатать, надиктовать или вставить файл и сервис бесплатно озвучит. Правда тут есть свои ограничения, о них чуть позже.
Какие типы файлов можно загрузить:
обычный текст (.txt), MS Word (.docx и .doc), MS Excel (.xlsx и .xls), PDF, EPUB, RTF, открытый документ (.odt, .ods) и субтитры (.srt). , .vtt) файлы.
Что крутого:
100 языков и диалектов, в каждом из которых доступно до 20 голосов озвучки, включая русский
можно использовать бесплатно
можно настроить громкость голоса и скорость
можно выбрать формат, в котором предпочтительней скачать m4a, mp3, вав, IVR WAV
помимо этого, можно настроить, в каком видео предпочтительней скачать - одним аудиофайлом, аудио и субтитры, или zip архивом с аудио для каждой сцены
можно не только вставить текст файлом, напечатать, можно и просто надиктовать в режиме реального времени
быстрая скорость обработки
Какие есть ограничения:
Без учетной записи вы можете загружать файлы размером до 10 МБ, содержащие до 1 КБ текста повествования. Платный тариф начинается от 6 $ и дает 30 минут по цене 0,20 $ за минуту кредитов, которые можно потратить на создание аудио/видео файлов в любое время. Так же, платный тариф дает право на коммерческое использование голоса.
В целом, хороший сервис, Elevenlabs он конечно не заменит, но дает очень приближенный функционал, если у вас файл до 10 МБ, который нужно озвучить не для коммерческого использования, сервис будет полезен.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
Всем привет! В сегодняшней статье посмотрим на новую нейросеть под названием Udio. По результатам, кажется, она превосходит последнюю версию Suno.
Взглянем детально на функционал и её способности, ну и покажу, как можно дорабатывать результаты из Udio так, чтобы получались неплохие(!) коммерческие треки, которые можно будет выпустить на площадках. Да, вы всё верно прочитали: вся музыка, сгенерированная в Udio, полностью принадлежит вам, а уж тем более после доработки. Если вы всегда мечтали создать свой трек, не вставая с кресла или кровати, то это оно вот самое. Приступим.
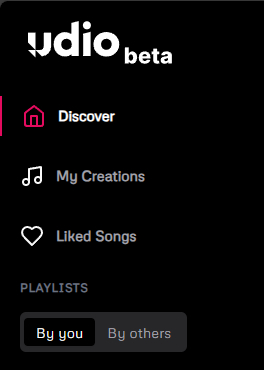
Всего на сайте три доступных вкладки:
Discover — или так называемая главная страница. Здесь самые залайканные работы пользователей за определенный период
My Creations — в этой вкладке хранятся ваши сакральные наработки
Liked Songs — соответственно, лайкнутые работы
Так же доступны и плейлисты. Давайте перейдём к самому главному - генерации музыки.
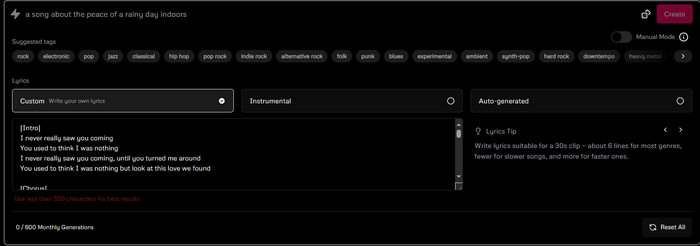
Чтобы приступить к созданию трека, жмём сверху слева розовую "Create". Далее видим следующее окно.
Сразу видим следующее: в месяц доступно 600 генераций(что достаточно много) и рекомендация по количеству символов: не более 350 для лучших результатов. Ну и Udio сам генерирует вам обложку к треку, причём очень неплохо.
Так же разработчики сделали шпаргалку, чтобы правильно написать текст к песне и рулить промптом. Детально останавливаться не будем, скажу лишь, что рекомендуется использовать разделители аранжировки, а именно припев, куплет, бридж и всё такое. Если, конечно, музыка со словами. Так же доступны несколько языков, эмоции, дикторские голоса, инструменты и пол вокалиста, читка или пение, всё это и много чего ещё можно регулировать. Удивительно.
Ну и помимо текста есть основной промпт трека
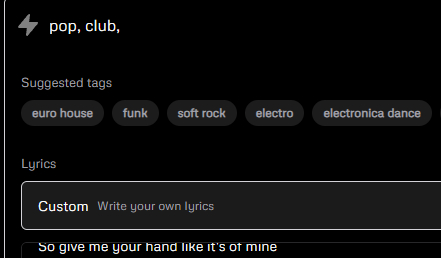
Тут есть куча тегов с жанрами музыки и автоматический поиск, вводите и сразу видите результаты. Давайте попробуем создать лиричный синт-поп ретровейв трек с красивым женским вокалом, текст взял из одного похожего по стилю трека.
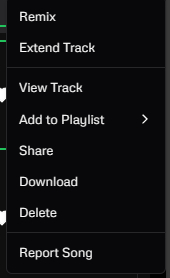
Ещё замечу, что Udio создает 30-секундные демки, которые вы можете по выбору сделать полноценными по длительности(Extend Track), а так же скачать демку, удалить её, сделать ремикс или зарепортить. Чтобы доделать трек до полноценного, здесь есть редактор, который добавили буквально на днях.
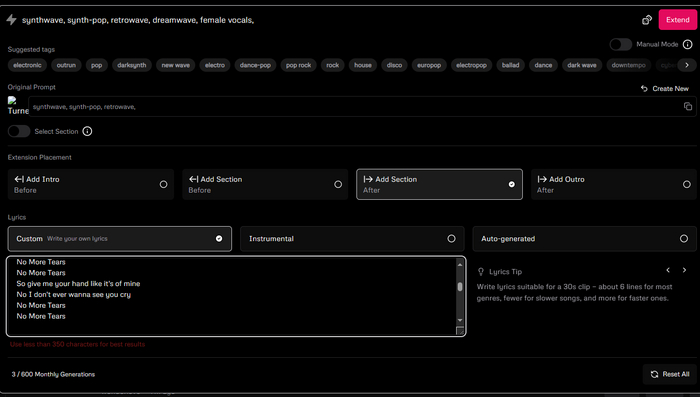
Итак, у меня получилось несколько вариантов, но мне приглянулся один, там почти не слышно голоса из-за затяжного интро, но мне с первых нот понравилось. Далее я нажимаю Extend, чтобы сделать полноценную версию
Здесь мы видим редактор Udio. Тут можно добавить части трека, такие как интро, аутро и т.п. И само собой текст. Дублирую его и генерирую ещё раз.
Немного подождав, вот какой результат получился, а точнее два:
На самом деле, мне этого уже достаточно, и можно закидывать всё это в DAW и далее дособирать, но я покажу функционал до конца, доделаем вокальную часть, и если будет много плюсов, покажу, как доделать профэссионално
Мне очень нравится две вещи: что создаётся по два отрывка, и можно выбрать, который лучше. И второе, что можно добавлять инструментальные аутро и интро, и что в целом редактор удобный. Мне не нравится, что я не могу выбрать темп трека, это пока единственное, что меня огорчило, потому что темп очень сильно решает, будет ли трек танцевальным, или медленным и текучим, а ещё скорее всего темп может повлиять и на настроение, которое задаст нейронка. Но есть костыли, можно добавить темп в текст песни.
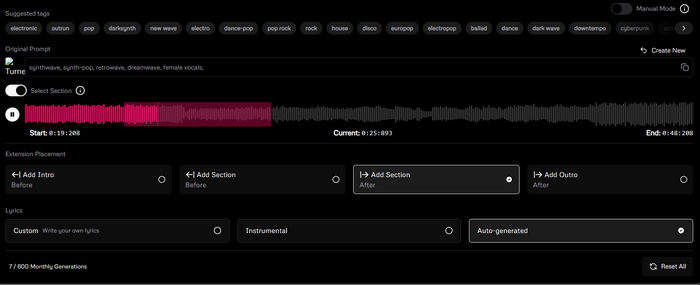
В этом окне так же есть очень немаловажная функция, это Select Section
Выбираем любой кусок, неудобно, что нет разделения по тактам, чтобы выбрать отрезок ровно, надеюсь, что это добавят в будущем. Так же выбираем, добавить часть до или после выбранного отрезка, и нажимаем Extend. Теперь нейронка будет отталкиваться от выбранного вами отрезка
Только что закончилась генерация, и чёрт возьми, это очень крутое аутро. Это нереально крутое и вайбовое аутро с саксом, просто послушайте. Трек вышел на 2:10
Интерфейс довольно простой и понятный, что тоже мне понравилось.
В общем, очень крутая штука, в ней действительно можно убить часы и получить невероятные эмоции.
Давайте сделаем костыльныйонлайн мастеринг, это лучше, чем ничего. Если будет много плюсов, то покажу, как делать некостыльный
Так же есть несколько режимов, но советую выбирать инструментальный. Всё же лучше чем ничего. Такое уже не стыдно выложить и на цифровые площадки по типу Яндекс.Музыки.
Приглашаем вас делиться своими работами в нашем сообществе Нейро-Музыкана Пикабу.
Если вам интересна тематика генерации музыки, добро пожаловать в Нейро-Звук🔉. Ну и загляните в моё сообщество музыкантов в Telegram, если вам понравилась статья, до новых встреч!
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.
Вот такие прикольные клипы я получила из песен, которые сгенерировала в Suno и Udio:
Здесь мне песня напомнила любую песню Тейлор Свифт, поэтому я просто сгенерировала клип для Тейлор Свифт)
Noisee — бесплатная нейросеть, которая создаст музыкальный клип на основе трека.
Можно использовать ссылку на песню из Suno, Youtube, Udio, Stable Audio и Soundcloud. Можно так же загрузить свой mp3-файл. Работает пока только через платформу Discord.
Для примера, я сгенерировала треки в Suno и Udio, и затем вставила ссылку на каждый в Noisee, прописала, что должно быть в клипе, при желании можно добавить референсы в виде изображений. Нейросеть довольно быстро генерирует.
Заодно сами сможете сравнить, кто из генераторов музыки лучше справился с изначальной текстовой подсказкой.
Что крутого в нейросети Noisee?
Если в видео что-то не понравилось, его можно отредактировать. Просто нажимаете Edit и вас переносит на сайт Noisee, где можно ПОКАДРОВО отредактировать, изменить автоматически сгенерированный промпт для КАЖДОЙ картинки.
Ограничения:
Использовать можно 3 раза за 3 часа
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? В своем телеграм канале НейроProfit я рассказываю, как можно использовать нейросети для бизнеса
Пост для людей от 30 лет и старше . Для тех кто может быть узнает себя . Не для инженеров . Не для буквоедов . Не для душных людей - сегодня душнить буду я . Не для тех у кого нет времени . Очень длинный и подробный . Пролистывайте пожалуйста не тратьте своё драгоценное время . Рассказываю свою жизнь и ощущения не с точки зрения инженерии , а с точки зрения собственного ощущения и эмоций .
... стал постарше начал работать . купил себе с 5и зарплат - первые Hi-Fi компаненты . CD-DA плеер , винилку , усилок 2х канальный 8и Ом ный . 2 на 100 вт и фронта 3х полосные с вуферами бумажными 30 см 200 вт с сильным запасом . всё Pioneer . В магазине класс А . в комиссионном отделе б/у без гарантии .
И вот это был первый раз когда я полноценно кайфанул от качества звука . Прям эмоции . Звучало бомбезно . Наслаждался долго . Всякие извращения практиковал типа : инструментал только слушал , подставки резиновые покупал под колонки , чтобы о пол вибраций не было , фильтр сетевой с землей под японскую вилку где наоборот не воткнешь вилку . Комнату завешивал ковролином студийным . Расставлял по-разному :, колонки выше , ниже . разносил ... Пока в армию не забрали . Пока служил - батя замотал всё в ломбард и деньги пропил . И деку мляяя .😭
Далее был у меня CD-DA плеер Marantz , рес Marantz модель не помню . Помню что 7.2 . Не потому что комната большая у меня была , а потому что в семиканальных ресах больше нюансов по настройке частотного диапазона звука , реверберации , и усилок мощнее . Комплект деревянной акустики 7.0 Marantz . И два одноименных активных саба . Соединено через коаксиал 30 см спецом короткий медный с позолоченными тюльпанами . Расставил . Выставлял по эквалайзеру каждый канал в отдельности , задержку звука тылов в соответствии с размером комнаты , морочился в общем . Кайфанул .
Потом был опыт с винилкой и ламповым усилком и 3х полосными колонками всё DENON непременно из дерева (массив) с шёлковым твиттером , с бумажными мидами и вуферами ... кайфанул . Новый уровень .
Дохера в общем денег по тупому в эту болезнь инвестировал ... доходило до того что хотел заказать из штатов б/у усилок HI END класса ... благо нашёл бабу . Она дурь эту из меня выбила ... под каблук загнала ... всё мое это хозяйство на АвNто продала и гейм овер ...
Далее уже слушал только в магазинах по случаю . в Hi-Fi отделах передружился с продаванами . Приходил и с особо больными болтал часами про аудиофилию . Новые года там праздновал (магазин работал с 25 декабря по 13 января круглосуточно) . Долбоёбов не было кроме нас . Магаз пустой . В ночь играли на плойке на самой большой диагонали что была в магазине 105 дюймов ... топовый усилок киловаттный жарили до красна . Балдежь .
... далее произошло то , после чего я чуть не двинулся сознанием ... понять это головой не могу до сих пор ... в общем у нас магазин уценки открыли DOMO там всякий хлам кривой , возвратный продавали с 80% скидкой . Моей задачей было купить что то маленькое , дешевое чтобы жена не учуяла что я денег с зарплаты зажал и чтобы не жалко было в гараж поставить на мороз и сырость . Перерыл я весь аудио отдел . Мой выбор пал на уёбаный ширпотребный домашний театр Pioneer 5.1 маленький , дешманский , легкий 1000 китайских PMPO шек . Вот такой .👇
Остальное там было ещё большая хуета . На безрыбе и рак щука . Купил за пятак . Нашару прям . Из косяков был витриной , пролюбили пульт от него , просрали фишки (клеммники) от колонок к башке . (Пустяки) . Притащил в гараж , вскрыл , провода колонок напаял прям на плату на похуй даже с клеммами не морочился . В параметры тем более не заглядывал . Пульт китай универсальный за 200 руб библиотека на 10 000 устройств . Разумеется никакого DVD , MP3 не совал в него . Только CD-DA .
включаю и охуеваю ! Верха довольно приятны , утонченные , не резкие , всё слышу , кайф , цифровой сигнальный проц хороший (как я это понимал ? когда вручную не мог выставить звук лучше чем предустановка- их две, выбрал басистее . Значит проц ок .) я прям рад ! Но Басы ну прям говно ... не беда . Метнулся в уценку . Нашел активный саб Sony дерево , 12 дюймов . Косяк - "не включается" . Думал динамик этот врежу в корпус родного пассивного саба , либо этот саб сделаю пассивным напрямую динамик соединю . Окрыл - сгорел пред по скачку напряжения . Отлично . Заменил пред - 5 руб . Работает . Подключил к линейному выходу (на активный саб даже не было выхода), но усилок и динамик активного саба срежут верха и будет норм . Включил басы гуд !
ходил в выходные в гараж за картошкой ... на 3 часа ... слушал ... прям ничего так ...
думал как это дешманская балалайка может звучать то ? Там фронта и тылы из пластика !!! Усилок килограмма два без теплоотвода с кулером . Потребление 200 вт . Смех .
как от мороза отрыгнул у меня этот пионер полез копать его подробнее . В общем секрет в том что он построен на низком сопротивлении 4 Ом . Хотя компанентные пионеры обычно 8 0м . считается что аудиофильный звук 2.0 стерео . И человек будет дубасить пол киловатта на одних злых фронтах и якобы не было в то время за дешево таких сплавов чтобы построить полукиловаттные колонки сопротивлением 2 Ом или 4 Ом , просто обмотку динамика такую суперпроводимую не создать менее 6-8 Ом . киловатт на 2-4 ом это прерогатива Hi End . И делать усилок на меньшем сопротивлении нет смысла ... наёбывали они в аудиофильских журналах😁 ... хотя это чистый маркетинг . Yamaha делала всё 6 Ом , Pioneer 8 ом чтобы тупо колонки их же бренда брали к усилку . Пидары .
эта же игрушечная пионерка типа для фильмов , моща не надо , вот вам усилочек слабый на низком сопротивлении и колоночки погремушки пластиковые , смотри киношку . Но инженеры Pioneer не привыкли делать совсем дерьмо . Процессор отличный раскладывает как надо . Фронта / тылы хоть и из пластика но 2х полосные . Твиттер бумажный . Широкополосника два бумажных с магнитом хорошим в каждой колонке . Корпус зашумлен . Стык корпуса проклеен и прорезинен . Опа нихуя какая пиздатая дешёвка . То есть весь этот сарай давал хорошие верха и эффекты на CD-DA . Но саб родной пассивный ну прям дерьмо 6 дюймов . Это минус .
а что мощи нет и басы слабые всё компенсирует активный соневский саб из дерева .
блять так даже обидно что я за червонец собрал звук примерно того доармейского пионера ... в голове не укладывается до сих пор ...
Далее был ещё один разрыв шаблона . 2021 год. Баба моя открыла летнее кафе . Говорит на тебе 20 к . Иди блютуз колонку возьми чтобы играла фоном ... ага ага ...
Повинуюсь . Поглядел что есть . На JBL PARTYBOX 1000 нехватает он тогда был полтос , щас 120 к где то .
хули делать . Надо слушать всё подрят . Слушаю значит перебором с айфона бабы всё подрят . Не улыбается ничего . Хуета . Прям говно . Либо одни верха . Либо одни басы . Вместо вуферов широкополосники . Диапазон дай боже 100 гц - 15кгц
и встретил я значит первый раз в жизни Samsung Sound Tower T70 . Тогда он был 23 косаря по акции . Щас в районе полтоса . Вот такой
Никогда не думал что буду слушать вообще звук Samsung блять . Моно блять .
коннекчусь что ВАЖНО с айфона бабы моей . Музыку слушаю через Apple music это как для братьев андроидников пояснить приложухи "ЗВУК" то есть аудиофайлы для воспроизведения на HI-FI аппаратуре . Бл... звучит ... ! Ёб твою ... звучит !!!
Гуглю значит за эту звуковую башню . Пишут мля . Материал корпуса ПЛАСТИК , МЕТАЛЛ . бренд Samsung , производство Китай ! Я чуть крышей не поплыл ... КАААААК СЦУКА ВЫ ИГРАЕТЕ ??? Крыша сползает .
Лезу в YouTube кто ты сука звуковая башня ??? Разбор полностью . Вскрыли . Материал ФАНЕРА толстая акустическая . Металл имеется ввиду профиля этой башни . Чем фанера скреплена . Пластик имеется ввиду облицовка . Начинка Harman . То есть китайский JBL купил технологии и инженеров поглотив HARMAN , а следом Samsung выкупил JBL с потрохами . Можете погуглить . Даже в фирменных магазинах Samsung не спроста стоят колонки JBL/HARMAN.
Честные Три полосы . Два твиттера , два ширика . Вуфер дюймов 12 на глаз , он в нижней части как и у JBL PARTYBOX глазами его не видно . От самсунга пульт наверное и дизайн башни .
Думаю ну в моно я не хочу . Хочу двух TWS братишек ! Сконнектил , разнес , включил . Да ёб же ш твою мааать как хорошо ... за 46 косарей !!!! Мляяя !
Одобрил у жены 46 кэсов . (Не сказал что их будет стереопара) . Сказал дешевле 46 к ненути ... хуй вам . Поворчала . Перевела ещё 26 к . Купил . До сих пор не сдохли . Самсунги мля !
Далее был ну вообще какой то беспредел и так нельзя прступать с людьми кто видел в глаза Hi-Fi хоть раз в жизни ...
В 2019 году не имея бвбок (моя ж всё тратит) я купил себе ультробюджетник Samsung Galaxy A50 6/128гб . по случаю . За две сотки . Пизда одна с моей работы его уронила на пол новенький сильно . Разбила . Треснула стекло дисплейного модуля одна трещина снизу на рамке черной . Матрица потухла . Не включается . Гуглим новый модуль 6500 руб китай не ориг олед . Сказала выкину . Я говорю выкинь мне . Она купи мне пачку парламента - отдам со всеми проводами . Сказано - сделано .
Принес . Нагрел . Вскрыл крышку . Развинтил . Ахуууеть . Не включается отстегнулся коннектор аккума от удара , нет изображения отсоединился шлейф от системной платы к дисплейному модулю . Да ладно ???? . Собираю . Молюсь . Включаю . Включается . Матрица ок . Не разбилась . Сенсор ок . Стекло печаль . Но кинул сверху защитное стекло с черной рамкой и прикрыл трещину от попадания воды внутрь дисплейного модуля - что для светодиодной матрицы - смерть . (Через 5 лет пишу с него сейчас) .
Смартфон не игровой , черепаха на Эксинусе . Но прочный . И что примечательно хоть и через bluetooth звук говно , через miniJack звук для бомж сегмента просто ебейший . Без всяких предусилителей . Проц стоит Dolby Atmos . если зарыться хорошо - можно поднять параметры . например в режиме музыка он мне не вкатил - там верха и низы без середины , а в режиме фильм - ярко выраженная середина всё слышно . При этом басы не слишком теряются . Есть настройка по каждой полосе под определенную гарнитуру . Чтобы раскрыть на всём диапазоне .
А щас прям будете ржать надо мной и закидаете ванючими носками ...
2021 год . так как я без музыки , когда не у бабы на работе в кафе ... в метро на работу ехать скууучно . Зашёл по дороге от дома к метро по пути в Ашан . В уши . В кармане пятихат . Карта у бабы моей . Шоб ниче не покупаааал .
Гляжу нет нихуя ... акция проводные уши JBL бомж версии T100. 500 руб перечеркнуто новая цена 250 руб . Вот такая залупа 👇
Мелкие , проводули ниточки , даже не гарнитура . ну думаю давай Harman удиви меня второй раз ...
подключил к бомж самсунгу , настроился по частотному диапазону этих ушей . Ввалил . Ебиииическая сила ... как HARMAN это делает ??? Питания нет , так как работают от miniJack , пассивные , фильтров внутри быть не может . двум динамикам там не поместиться . Нет места . Откуда блять звуууук ??? А ??? Harman ты как это сделал ??? А ??? Теку крышей ...
в моем понимании звук это минимум 3 полосы . Вч динамик . Сч динамик . Нч динамик . До них фильтра чтобы на каждый динамик подать именно ту частоту . Правильно рассчитанный корпус по размерам . Правильного размера фазоинвертор для дыхания ... и всё это зашумлено и герметично по корпусу . И только тогда широкий диапазон . Хороший усилок . Хороший источник звука . И хороший носитель звука . Если что то из этого не так - всё по пизде ! В миниатюре думал так же всё работает .
Тут я слушаю на дешманском андроиде, цифру ,через приложуху "ЗВУК", на ушах внутриканалках с тонкими проводулями . Из понтов только входное отверсие для зачерпывания воздуха . Ни фильтров , ни шумодава , нихуя . По звуку : утонченный верх , хорошая середина , басс различается по глубине , диапазон ок - 50 гц точно чувствую . И мне нравится . Бляяяя . Как !?
теперь почему пост с задержкой в дохуя лет . Колупнуть их целыми рука не поднялась . Три года убивал в мороз , дождь . Сегодня оборвал провод зацепившись рукой . Наконец то . Открыл . Внутри НИХУЯ . Ни платы , ни второго динамика . Пусто . Получается широкополосный динамик и всё .... хороший сплав проводов и обмоточки динамичков .
Я СТОКА БАБОК УБИЛ В HI-FI ....🤦♂️🤦♂️🤦♂️🤦♂️
для справки в младших моделях портативных колонок JBL/HARMAN до 2020 года везде один динамик . С хорошим ходом . Похожий на вуфер , но который воспоизводит и верха . Как то . А что по бокам это резинки под названием пассивный излучатель , первое назначение чтобы не дребезжал корпус от давления когда она вдыхает и выдыхает ОНИ НЕ ЗВУЧАТ САМИ в привычном понимании просто колебают воздух . Как фазоинвертор закрытого типа .
В более дорогих моделях серии PARTYBOX 2 или даже 3 полосы там всё понятно откуда что берётся .
а теперь мой обещанный вопрос знатокам . КАК МОЖНО ФИЗИЧЕСКИ РЕАЛИЗОВАТЬ ЗВУК В ДИАПАЗОНЕ 50 ГЦ - 20 КГЦ ОДНИМ ДИНАМИКОМ . Как он может одновременно генерировать такие колебания ?
Сервис Munute может свести песню, выровняет звук, уберёт лишние шумы.
Нейросеть обучена на десятках тысяч коммерчески успешных песен. Бесплатно дают обработать 3 песни, затем подписка от $13 в месяц.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
⚠️Иску́сственный интелле́кт (ИИ) — свойство искусственных интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека, наука и технология создания интеллектуальных машин, особенно интеллектуальных компьютерных программ.
1/3
⚠️Суперкомпьютер (СверхЭВМ, СуперЭВМ, сверхвычислитель) — специализированная вычислительная машина, значительно превосходящая по своим техническим параметрам и скорости вычислений компьютеры общего пользования.
1/3
СУПЕРКОМПЬЮТЕР
⚠️Виртуальная реальность ( VR, искусственная действительность) — созданный техническими средствами мир, передаваемый человеку через его ощущения: зрение, слух, осязание и другие. Виртуальная реальность имитирует как воздействие, так и реакции на воздействие. Для создания убедительного комплекса ощущений реальности компьютерный синтез свойств и реакций виртуальной реальности производится в реальном времени.
1/3
ВИРТУАЛЬНАЯ РЕАЛЬНОСТЬ
⚠️Портал — разрыв в пространстве-времени, искусственного или естественного происхождения, позволяющий материи мгновенно перемещаться между двумя точками пространства или времени. Также во многих произведениях жанра фэнтези портал представляет собой искусственно создаваемый проход, «коридор» или «окно» из одного места в другое (или даже из одного мира в другой).
Прошлое — часть линии времени, состоящая из событий, которые уже произошли.
1/3
ПРОШЛОЕ
⚠️Документальная фотография — ветвь фотоискусства, направление фотографии, художественная программа которого ориентирована на изображение достоверного. Центральная идея документальной фотографии — обращение к реальным событиям. В некоторых случаях документальная фотография формируется как обращение или призыв и подразумевает создание фотографического документа.
⚠️Архив - это совокупность архивных документов, а также архивное учреждение или структурное подразделение учреждения, организации и предприятия, осуществляющее прием и хранение архивных документов в интересах пользователей.
Будущее — гипотетический отрезок линии времени, множество событий, которые ещё не произошли, но могут произойти.
БУДУЩЕЕ
⚠️Создание мира, миропостроение — это процесс построения воображаемого мира, иногда связанного с целой вымышленной вселенной. Получившийся мир можно назвать сконструированным гипотетическим миром.
⚠️Миропостроение может быть спроектировано сверху вниз, снизу вверх или при комбинации этих подходов. Официальное руководство построения мира обозначают эти термины как «снаружи внутрь» и «изнутри наружу» соответственно. В нисходящем подходе дизайнер сначала создает общее описание мира, определяя общие характеристики: жителей мира, уровень технологий, основные географические особенности, климат и история. Оттуда они развивают остальной мир с возрастающей детализацией. Этот подход может включать создание основ мира, за которыми следуют такие уровни, как континенты, цивилизации, нации, города и поселки. Мир, построенный сверху вниз, имеет тенденцию быть хорошо интегрированным, с соответствующими компонентами, подходящими друг другу. Однако может потребоваться значительная работа, прежде чем будет завершено достаточно подробностей, чтобы сеттинг стал полезным, например, в качестве сеттинга для истории.
⚠️Возможно, самое основное соображение в построении мира — то, в какой степени вымышленный мир будет основан на физике реального мира в сравнении с магией. В то время как магия является более распространенным элементом фэнтезийных сеттингов, научно-фантастические миры могут содержать их магические или технологические эквиваленты.
Термин «worldbuilding» был впервые использован в «Эдинбургском обзоре» в декабре 1920 года и появился в статье Артура Стэнли Эддингтона «Пространство-время и гравитация: обзор общей теории относительности», чтобы описать процесс придумывания гипотетических миров с различными физическими законами.
⚠️ Возможно через несколько десятилетий, технологии продвинутся вперёд и произойдет новый этап в развитии возможности перемещения во времени...
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
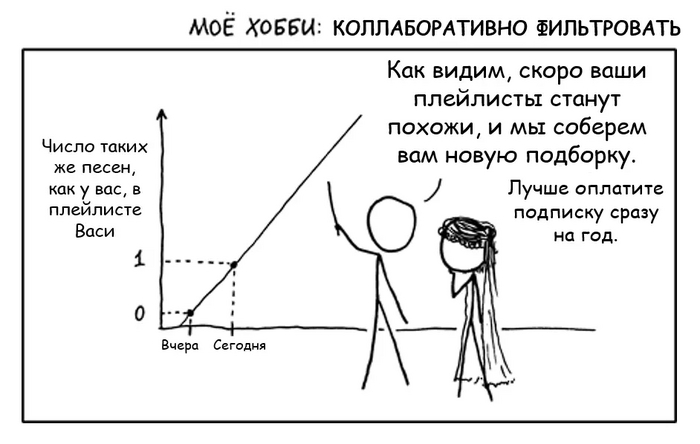
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.