
Утильсбор!1
Пару лет спустя:
Пару лет спустя:
Будущее туманно, — говорил мудрец.
Особенно то будущее, где ты обещал себе начать бегать с понедельника.

(с) Маркус Аврелиус
Автор: Денис Аветисян
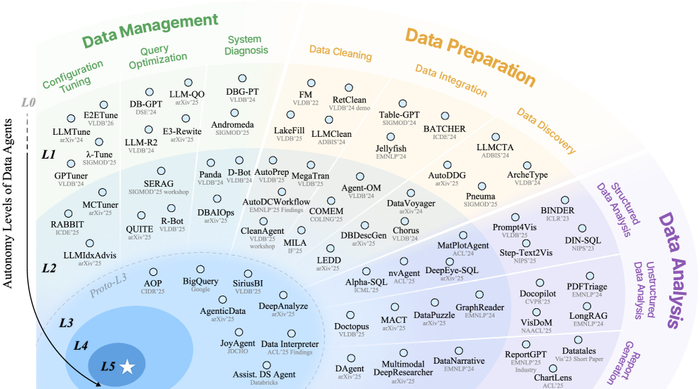
Различные агенты данных демонстрируют разный уровень сложности и функциональности, отражая иерархическую структуру, в которой каждый уровень опирается на предыдущий для достижения общей цели.
В эпоху экспоненциального роста данных, традиционные методы обработки захлебываются в море разнородных и постоянно увеличивающихся объемов информации, хранящихся в Data Lakes. В этой ситуации возникает фундаментальное противоречие: стремление к автоматизации анализа данных с помощью Data Agents сталкивается с проблемой их неоднозначной классификации и отсутствием четких критериев оценки, что порождает сомнения в их реальной эффективности. В ‘A Survey of Data Agents: Emerging Paradigm or Overstated Hype?’, авторы решаются спросить: действительно ли мы стоим на пороге новой эры интеллектуального управления данными, или же вокруг Data Agents раздувается неоправданная шумиха, скрывающая глубокие технологические ограничения и препятствия на пути к их широкому применению?
Современная инфраструктура данных все больше полагается на озера данных – обширные хранилища необработанных данных, представляющих собой, по сути, цифровые архивы. Однако, традиционные методы обработки данных все чаще оказываются неспособными справиться с масштабом, разнородностью и сложностью этих озер, что создает серьезное препятствие для эффективного анализа. Кажется парадоксальным, но чем больше данных мы собираем, тем сложнее становится извлечь из них значимые знания. Это напоминает закон энтропии – хаос нарастает быстрее, чем порядок.
Возникает критическое узкое место: раскрытие ценности, скрытой в этих активах, требует парадигмального сдвига в управлении данными и их подготовке. Недостаточно просто хранить информацию – необходимо уметь ее быстро и эффективно обрабатывать, очищать, интегрировать и анализировать. В противном случае, озеро данных превращается в болото, где знания тонут в избытке информации. И здесь, как и во многих других областях, время играет решающую роль. Любое улучшение, любая оптимизация, стареет быстрее, чем ожидается, требуя постоянного обновления и адаптации.
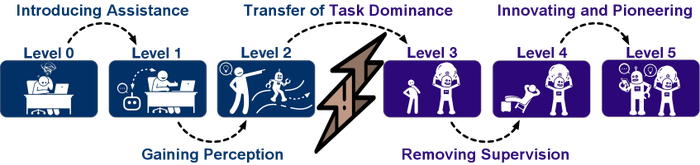
Исследование показывает, что эволюционные скачки происходят между уровнями агентов данных, демонстрируя прогресс в их развитии.
В этой связи, необходимо признать, что простым увеличением вычислительных мощностей проблему не решить. Подобный подход лишь временно замедляет наступление энтропии, но не отменяет ее. Настоящий прогресс требует принципиально новых подходов к управлению данными, основанных на автоматизации, интеллектуальном анализе и адаптивности. Необходимо создать системы, способные самостоятельно обнаруживать аномалии, очищать данные, интегрировать разнородные источники и генерировать полезные знания. В противном случае, мы обречены на вечное догоняние, пытаясь удержать ускользающий поток информации. И здесь, как ни странно, откат – это не всегда поражение, а иногда – необходимое путешествие назад по стрелке времени, позволяющее переосмыслить подходы и избежать тупиковых решений.
Задача не в том, чтобы просто хранить больше данных, а в том, чтобы извлекать из них больше смысла. И это – вызов, который требует не только технических инноваций, но и философского переосмысления нашей роли в эпоху информации.
В эпоху, когда данные становятся новой нефтью, а скорость их генерации неуклонно растет, возникает необходимость в интеллектуальных системах, способных не только собирать и хранить информацию, но и автономно преобразовывать ее в ценные знания. Именно здесь на арену выходят Агенты Данных – архитектуры, основанные на возможностях больших языковых моделей (LLM), призванные преодолеть разрыв между необработанными данными и практически значимой аналитикой.
Эти агенты – не просто автоматизированные скрипты или наборы правил. Они обладают способностью к пониманию структуры данных, выявлению релевантных преобразований и выполнению конвейеров подготовки данных с минимальным вмешательством человека. Вспомним, что версионирование – это форма памяти, а в контексте данных – возможность отслеживать изменения и возвращаться к предыдущим состояниям, что критически важно для обеспечения надежности и воспроизводимости анализа.
В основе работы Агентов Данных лежит способность LLM к пониманию семантики данных. Они могут анализировать схемы баз данных, распознавать типы данных и взаимосвязи между ними, а также выявлять аномалии и несоответствия. Эта способность позволяет им автоматически генерировать запросы к базам данных, преобразовывать данные из одного формата в другой и выполнять сложные аналитические операции.
Однако, для достижения максимальной эффективности, Агентам Данных необходимы инструменты для оптимизации их работы. Здесь на помощь приходят фреймворки, такие как AFlow, которые позволяют автоматизировать и оптимизировать агентские рабочие процессы, обеспечивая масштабируемость и эффективность обработки данных. Стрела времени всегда указывает на необходимость рефакторинга, и в контексте рабочих процессов это означает постоянную оптимизацию и улучшение производительности.
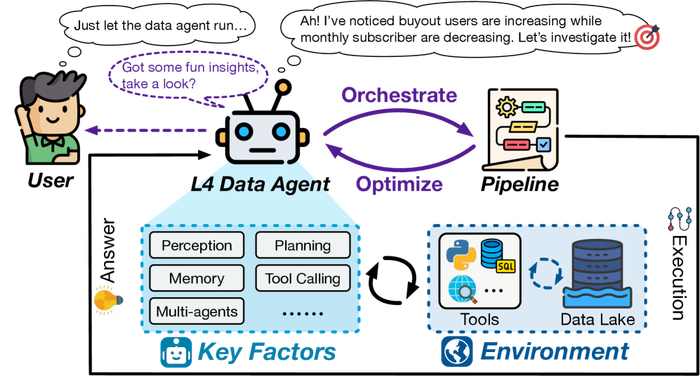
Агенты данных уровня 4 демонстрируют высокую степень автономии, позволяя им самостоятельно выполнять задачи.
В конечном итоге, Агенты Данных представляют собой эволюцию в подходе к обработке данных. Они не просто автоматизируют рутинные задачи, но и позволяют организациям извлекать больше ценности из своих данных, быстрее и эффективнее. Их способность к автономной работе и адаптации к изменяющимся условиям делает их незаменимым инструментом в эпоху, когда данные становятся ключевым фактором конкурентоспособности.
Исследователи полагают, что будущее Агентов Данных связано с развитием их способности к обучению и адаптации к новым типам данных и задачам. В конечном итоге, они должны стать интеллектуальными партнерами аналитиков, способными самостоятельно решать сложные проблемы и предлагать инновационные решения.
В эволюции систем, подобно живым организмам, каждый этап отмечен адаптацией и усложнением. Изначально, вспомогательные агенты данных уровня 1, обеспечивают поддержку, облегчая выполнение задач для пользователей. Они подобны опытным подмастерьям, ускоряющим рутинные операции, но не способным к самостоятельному творчеству.
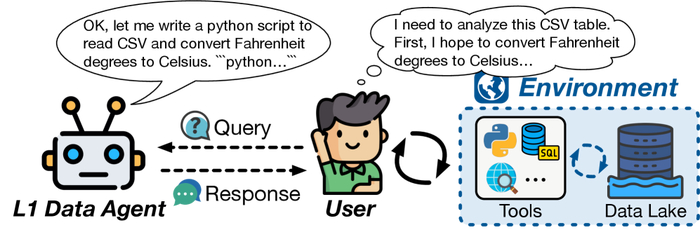
Агенты данных уровня 1 обеспечивают поддержку, облегчая выполнение задач для пользователей.
Однако, требования к этим системам растут, и возникает необходимость в инструментах, способных к более сложным преобразованиям. Здесь на сцену выходят системы, подобные AutoPrep, которые улучшают способность к рассуждению и вызову инструментов для подготовки данных, отвечающих на вопросы на естественном языке. Это подобно обучению ученика не просто выполнять указания, а понимать суть задачи и самостоятельно находить оптимальное решение.
Потребность в автоматизации обслуживания и оптимизации баз данных приводит к появлению систем, таких как GaussMaster. Этот многоагентный помощник, подобно опытному инженеру, предлагает рекомендации по индексации и оптимизации управления данными, предотвращая накопление технического долга и обеспечивая стабильную работу системы во времени.
Взаимодействие с базами данных часто требует специфических знаний и навыков. Инструменты, такие как nvAgent и Alpha-SQL, упрощают этот процесс, позволяя пользователям взаимодействовать с данными и создавать визуализации, используя естественный язык. Это подобно переводу сложного технического языка на понятный человеческому.
Для управления сложными данными, хранящимися в озерах данных, необходимы комплексные инструменты. iDataLake представляет собой такую систему, обеспечивающую связывание данных, оркестровку конвейеров и выполнение аналитических задач. Это подобно строительству моста между разрозненными источниками данных, обеспечивающего плавный поток информации.
Каждый из этих инструментов — лишь часть сложной системы, которая постоянно развивается. Как и любой организм, эти системы нуждаются в постоянном уходе и адаптации, чтобы оставаться жизнеспособными и эффективными во времени. Именно эта непрерывная эволюция и делает их поистине ценными.
Развитие интеллектуальных систем обработки данных неуклонно ведёт к созданию агентов, способных автономно решать всё более сложные задачи. Однако, для осмысленного анализа и сравнения различных подходов, необходима чёткая система классификации, отражающая степень их независимости и интеллектуальных возможностей. Именно такую систему и представляет предложенная иерархическая таксономия агентов данных, охватывающая уровни от L0 до L5.
Эта таксономия, вдохновлённая стандартом SAE J3016, используемым в автомобильной промышленности для классификации систем автоматического вождения, определяет постепенное увеличение степени автономности. Подобно тому, как автомобили эволюционируют от простых систем помощи водителю до полностью автономных транспортных средств, агенты данных продвигаются от ручного управления к полному самоопределению.
Агенты уровня L0 предлагают лишь базовую помощь, требуя постоянного вмешательства человека. С каждым последующим уровнем, возрастает степень автоматизации и самостоятельности. Агенты уровня L1 способны выполнять отдельные задачи, но нуждаются в чётких инструкциях и контроле. Уровни L2 и L3 характеризуются всё большей способностью к самоорганизации и решению комплексных проблем, требуя лишь надзора со стороны человека. И, наконец, агенты уровня L4 и L5 представляют собой полностью автономные системы, способные к творческому решению задач и даже к созданию новых знаний.
Эта иерархия, подобно эволюционному древу, демонстрирует путь к созданию действительно интеллектуальных систем обработки данных. Каждая архитектура проживает свою жизнь, и мы лишь свидетели её развития. Важно понимать, что улучшения стареют быстрее, чем мы успеваем их понять. Поэтому, чёткое понимание этой прогрессии имеет решающее значение для эффективного развёртывания и управления агентами данных, позволяя адаптировать их возможности к конкретным бизнес-потребностям.
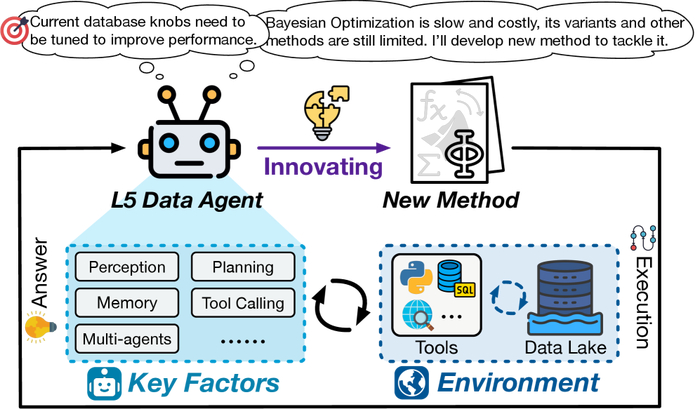
Агенты данных уровня 5 достигают полной автономии, способствуя выполнению задач без вмешательства человека.
В конечном счёте, задача состоит не просто в создании более умных систем, но и в понимании принципов, лежащих в основе их эволюции. Каждая ступень развития, каждый переход от ручного управления к автономному функционированию, является ценным уроком, который помогает нам создавать более надёжные, эффективные и интеллектуальные системы обработки данных.
Исследование, представленное авторами, подчеркивает эволюцию систем управления данными, от ручного вмешательства к полной автономии. Этот процесс неразрывно связан с понятием времени, ведь каждая ступень развития требует адаптации и исправления ошибок. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — создать его». Эта фраза прекрасно иллюстрирует подход, который демонстрируют исследователи, стремясь не просто описать текущее состояние data agents, но и наметить путь к их дальнейшему развитию. Автономные системы, как и любые сложные структуры, не избавлены от ошибок, но именно способность к самообучению и адаптации определяет их долгосрочную жизнеспособность и зрелость.
Исследование, предложенное авторами, выстраивает иерархию, словно карту увядания систем. Каждый уровень автономии – это лишь отсрочка неизбежного. Попытка классифицировать "агентов данных" – благородная, но, возможно, запоздалая. Ведь сама идея полной автоматизации управления данными таит в себе парадокс: стремясь к идеалу беспристрастности, мы создаем системы, неспособные к осмысленному диалогу с прошлым. Каждая ошибка – сигнал времени, а рефакторинг – это не просто улучшение кода, а диалог с тем, что уже устарело.
Очевидно, что ключевым препятствием остается не техническая сложность, а онтологическая неопределенность. Что есть "данные"? Что есть "интеллект"? И самое главное – для чего все это нужно? Авторы справедливо отмечают вызовы, но упускают из виду, что сама погоня за "автономностью" может привести к созданию систем, лишенных критического мышления и способности к адаптации в условиях непредвиденных обстоятельств.
Вместо того чтобы стремиться к созданию "идеального агента", исследователям стоит сосредоточиться на разработке инструментов, позволяющих человеку эффективно взаимодействовать с данными. Иначе, мы рискуем создать системы, которые, подобно стареющим часам, будут продолжать тикать, но уже не будут показывать время.
Оригинал статьи: denisavetisyan.com
Связаться с автором: https://www.linkedin.com/in/avetisyan/

Проект Autonomys, ранее известный как Subspace, постепенно выходит из тени и начинает напоминать не просто экспериментальную сеть, а серьёзную инфраструктуру, которая претендует на роль «блокчейна будущего». В сентябре команда подвела итоги первого месяца после запуска токена AI3 и активации второй фазы сети.
Главное, что стоит знать: сеть теперь полноценно работает. Три основных уровня — консенсус, исполнение (Auto EVM) и ликвидность — уже запущены. То есть сеть умеет обрабатывать транзакции, взаимодействовать с приложениями и обеспечивать движение токенов.
Токен AI3 прошёл листинг на нескольких биржах, а ликвидность держится стабильно. В то же время началась программа стейкинга под названием Guardians of Growth. Участники уже застейкали около 28 миллионов токенов — это примерно четверть доступного предложения. Для молодой сети это внушительный показатель вовлечённости.
Ещё одно заметное событие — появление моста Hyperlane, который позволяет оборачивать AI3 в формат wAI3 и использовать его в экосистемах Ethereum и USDT. Добавили и мультиподпись SAFE, чтобы повысить безопасность хранения активов.
В технической части разработчики сделали акцент на переходе от тестовой сети Taurus к новой — Chronos. На ней проверяются устойчивость и масштабируемость, а также готовится запуск программы Game of Domains, после которой сеть сможет стать полностью открытой для независимых операторов.
Но главная идея, которая отличает Autonomys от большинства других проектов, — это ставка на пост-квантовую безопасность. Команда утверждает, что современные криптографические алгоритмы (включая те, что используются в Bitcoin и Ethereum) в будущем могут стать уязвимыми для квантовых компьютеров. Autonomys хочет внедрить методы защиты заранее, до того, как угроза станет реальной.
Кроме того, проект активно интегрируется с ИИ-технологиями. Один из примеров — сотрудничество с Gaia Network, где узлы смогут хранить данные в цепи AI3, а ИИ-агенты получать к ним доступ через специальный фреймворк Auto Agents. Иными словами, речь идёт о создании инфраструктуры для автономных ИИ-приложений, работающих напрямую в блокчейне.
Внутри сообщества тоже кипит жизнь: проводятся конкурсы документации, программы поддержки фермеров, карты распределения узлов по миру. Это помогает улучшить документацию, вовлечь разработчиков и сделать сеть более децентрализованной.
Если коротко, то Autonomys сейчас на этапе, когда всё уже запущено, но массовое применение только начинается. Проект интересен прежде всего своей ориентацией на долгосрочную устойчивость и технологическую глубину — редкость в мире, где большинство блокчейнов живут от хайпа до хайпа.
Так что пока кто-то спорит, какой мем-коин «улетит на Луну», команда Autonomys спокойно строит сеть, которая, по их словам, должна пережить даже квантовые компьютеры.

Пожалуй, каждый уже высказался про ИИ. Стоит ли бояться его, кого он заменит и так далее. А в моём TG-чате и вовсе на фоне этого настоящие баталии происходят.
Позвольте я выскажу своё мнение (пост довольно большой), а мы с вами подискутируем в комментариях, если у вас есть на это желание. Вообще для нашего удобства стоит отметить, что развитие Интернета происходило в четыре больших этапа:
1. Создание самого Интернета, когда люди уже могли заходить на различные веб-сайты.
2. Создание поисковиков по типу Google, когда людям стала доступна любая информация на различных источниках.
3. Создание социальных сетей и мессенджеров, когда людям стало проще коммуницировать и появилась возможность зарабатывать в Интернете на блогах и т.д.
4. Создание первых общедоступных ИИ моделей, когда люди могут генерировать контент и получать уже "разжёванную" информацию без поиска источников, как это было с поисковиками.
Первый этап (создание Интернета и сайтов) значительно сократил телефонистов-операторов, поскольку потенциальный клиент мог узнать всю информацию на веб-сайте, но первый этап создал профессии веб-программистов, верстальщиков сайтов и так далее.
Второй этап (появление Google и поисковиков) значительно сократил сотрудников библиотек (когда я был в начальных классах, то у нас в библиотеке работало 5 человек, когда появились поисковики - в библиотеке у нас стало работать 2 человека), но второй этап создал профессию трафик-менеджера, цель которого - выводить компанию и её рекламу на первые страницы выдачи.
Третий этап (появление социальных сетей и мессенджеров) значительно сократил сотрудников почты и телеграфистов, ведь пропала нужда в долгих и неудобных письмах и телеграммах, но третий этап создал профессию SMM-специалиста, который отвечает за развитие бизнеса в социальных сетях.
И тут мы подбираемся к текущему четвёртому этапу - созданию ИИ. Это уже просто каток, который прошёлся по профессиям. Он уже значительно сократил творческие профессии и джунов-программистов, сократил операторов, а кто-то использует ИИ даже в качестве психологов, но четвёртый этап уже создал профессию специалиста по внедрению ИИ и по работе с нейросетями.
Какой мы можем сделать вывод из этого? Что множество профессий всегда по тем или иным причинам сокращаются, но не все из них уничтожаются (как, например, кучеры или люди-будильники).
Мы до сих пор имеем операторов, библиотекарей, сотрудников почты, хоть и в меньшем количестве, чем раньше.
Что мы можем предпринять? Подстраиваться и адаптироваться. Не нужно противиться прогрессу, потому что прогресс - это огромная махина, которая вас снесёт, если вы будете ей противиться.
Вам нужно с прогрессом сотрудничать. Если вы человек творческой профессии, то используйте ИИ для облегчения своей работы, но дорабатывайте работу по необходимости вручную.
Если вы джун-программист, то используйте ИИ как помощника в написании простого кода и для его анализа, чтобы быстрее продвинуться в программировании.
Но тут важный момент. ИИ нужно использовать как помощника (!), а не полную замену. Это ключевой момент. Помощника тоже нужно проверять на наличие неудачных решений. И чем быстрее вы "подружитесь" с прогрессом и заставите его работать на своё благо, тем лучше будет для вас.
В конце концов, когда появились первые автомобили, то кучеры воротили носом - мол, нам это не надо. Итог? Профессия сначала сократилась, потом - померла.
Что мог сделать бедный кучер в той ситуации? Не воротить носом, а использовать свои навыки навигации и знания города, и пересесть на автомобиль и заняться перевозкой людей на автомобиле (такси ещё тогда в привычном понимании не было, а был извоз).
Поэтому используйте ИИ как помощника, и возможно, что вы не останетесь без работы. Я говорю "возможно", потому что прогресс в любом случае лишит людей работы, но создаст новые профессии. А ваша задача - подстроиться под окружающую действительность, и тогда шансы сохранить профессию у вас сохранятся.
А если сохранить работу не удастся, то новый этап создаст новые профессии. И тут выбор за вами - приложить усилия и обучиться новой профессии, или надеяться просто на лучшее...
Правильно заданный вопрос - половина ответа на вопрос "что делать?"
Будущего, а не средняя зарплата в переводе на рубли.
Проблема не решаема в лоб - большинство ВСЕГДА будет получать зарплату чуть ниже средней, иное просто невозможно в сколько-нибудь естественной ситуации.
Но можно сделать эту около-среднюю зарплату сверхстабильной через неестественность ситуации, ценой полного застоя стабилизации всего общества. То есть возвращение к советскому типу плановой экономики, причем не по Брежневу, а по Сталину Андропову.
Второй возможный путь это сознательное уменьшение населения и жизнь как арабских нефтемонархиях. Те самые 25 миллионов Тетчер начнут рожать просто от нечего делать четобы получить увеличение клановой пайки. Не много, но для стабилизации численности на этих 25 миллионах пока нефть не кончится или китайцы не начнут продавать ТЯ реакторы за копейки хватит.
Третий - война. Можно даже не побеждать, главное поддержание состояния осажденной крепости в надежде что через пару поколений спад рождаемости из-за изоляции и закручивания гаек сменится подъемом из-за них же.
В Европе исламизация и просто неадекватное правление. Гетто, миллионы отбросов из-за границы.
А вот здесь проблема в лоб вполне решаема. Национал-социализм как раз про это. Разумное (на самом деле нет) правление включая евгенические программы, инородцев в печь. Главное, чтобы от такой жизни начался орднунг, а не очередной дранг нах остен.
В США похоже но по-своему и потихоньку ход к гражданскому конфликту
И у них проблема в лоб решаема. Потому что хотя негры в беге лидируют, в стрельбе белые все еще впереди.
Отлично подойдет всем, кому приходится по долгу службы руководить людьми и принимать важные стратегические решения. Даже если у вас на работе есть только вы)
Маркетинговые войны, Джек Траут
Основы стратегического маркетинга
Игры в которые играют люди, Эрик Берн
Психология человеческих взаимоотношений. Управлять командой сразу становится проще
Психология влияния, Роберт Чалдини
Как влиять на людей, чтобы они принимали решения, которые вам нужны)) Согласитесь, важный навык не только в бизнесе))
Корпорация гениев, Эд Кэтмелл
Книга от президента Pixar, идеально для тех, кто работает с творческой командой.
Цель: процесс непрерывного улучшения. Элияху Голдрат
Ответит на вопрос : как стать самым конкурентноспособным на рынке.
И еще, вне списка: Финансист. Титан. Стоик, Теодор Драйзер.
Читали что-то из списка? Пишите в комментариях!
Также, в моём тг-канале опубликован список топ-100 книг художественной литературы, из которой, в зависимости от запроса, можно взять больше, чем из специализированной.
Всем доброе утро, мы начинаем день с новостей из Китая!

Огневое испытание Zhuque-3.
Китайская компания LandSpace продвигает разработку двухступенчатой многоразовой ракеты Zhuque-3 (ZQ-3), вдохновленной Starship и Super Heavy от SpaceX. В январе 2024 года прошел первый тест вертикального взлета и посадки (VTVL) на аппарате VTVL-1 в центре Цзюцюань (JSLC). К сентябрю второй VTVL-тест продлил зависание до 200+ секунд (против 60 ранее), а в июне последовали статические огневые испытания прототипа.

Zhuque-3 в сборочном цехе.
22 октября в зоне Dongfeng (JSLC) провели очередное статическое огневое испытание: ракету полностью заправили, но она осталась неподвижной во время работы двигателей. Это "генеральная репетиция" приближает к первым орбитальным запускам в Q4 2025 года. LandSpace планирует вертикальную интеграцию, осмотр и обслуживание перед первым восстановлением первой ступени в 2025-м, с повторным использованием прототипа.

Транспортировка на стартовую площадку.
Название Zhuque-3 отсылает к "Красной птице" — символу огня в китайской мифологии. Ракета из нержавеющей стали, с топливом LCH4/LOX, девятью двигателями Tianque-12A, высотой 65,9 м и массой 550 000 кг. Грузоподъемность: 11 800 кг (одноразово) или 8 000 кг (многоразово) — близко к Falcon 9 (22 800 кг на LEO).
В перспективе — Zhuque-3E: 76,2 м, девять TQ-12B, до 21 000 кг (расширяемо) или 18 300 кг (извлекаемо), для конкуренции с Falcon. Идея многоразовости анонсирована в 2021-м на "Национальном космическом дне" в Нанкине. Это шаг Китая к лидерству в космосе!








