
Эволюция данных: от ручного управления к автономным агентам
Автор: Денис Аветисян
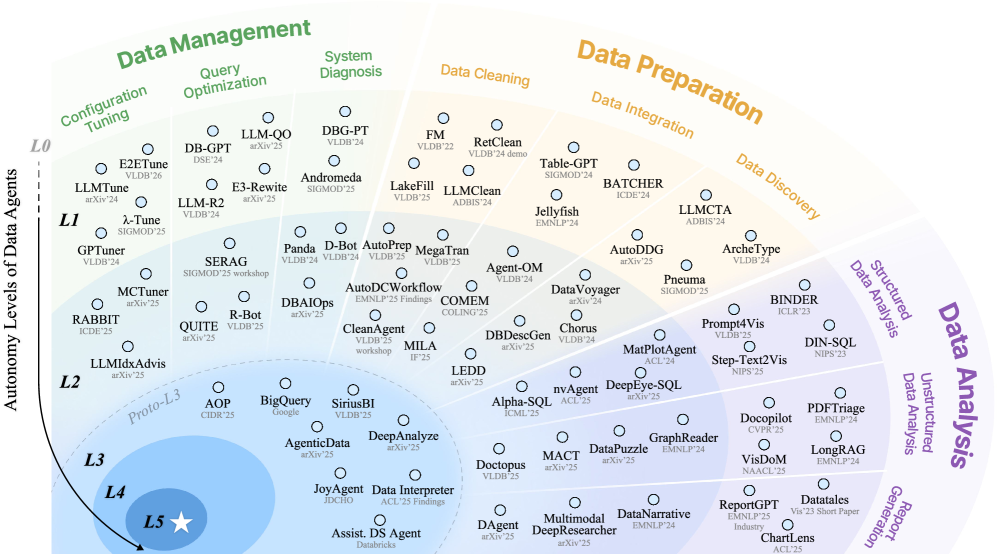
Различные агенты данных демонстрируют разный уровень сложности и функциональности, отражая иерархическую структуру, в которой каждый уровень опирается на предыдущий для достижения общей цели.
В эпоху экспоненциального роста данных, традиционные методы обработки захлебываются в море разнородных и постоянно увеличивающихся объемов информации, хранящихся в Data Lakes. В этой ситуации возникает фундаментальное противоречие: стремление к автоматизации анализа данных с помощью Data Agents сталкивается с проблемой их неоднозначной классификации и отсутствием четких критериев оценки, что порождает сомнения в их реальной эффективности. В ‘A Survey of Data Agents: Emerging Paradigm or Overstated Hype?’, авторы решаются спросить: действительно ли мы стоим на пороге новой эры интеллектуального управления данными, или же вокруг Data Agents раздувается неоправданная шумиха, скрывающая глубокие технологические ограничения и препятствия на пути к их широкому применению?
От Эха к Знанию: Преодоление Энтропии в Океанах Данных
Современная инфраструктура данных все больше полагается на озера данных – обширные хранилища необработанных данных, представляющих собой, по сути, цифровые архивы. Однако, традиционные методы обработки данных все чаще оказываются неспособными справиться с масштабом, разнородностью и сложностью этих озер, что создает серьезное препятствие для эффективного анализа. Кажется парадоксальным, но чем больше данных мы собираем, тем сложнее становится извлечь из них значимые знания. Это напоминает закон энтропии – хаос нарастает быстрее, чем порядок.
Возникает критическое узкое место: раскрытие ценности, скрытой в этих активах, требует парадигмального сдвига в управлении данными и их подготовке. Недостаточно просто хранить информацию – необходимо уметь ее быстро и эффективно обрабатывать, очищать, интегрировать и анализировать. В противном случае, озеро данных превращается в болото, где знания тонут в избытке информации. И здесь, как и во многих других областях, время играет решающую роль. Любое улучшение, любая оптимизация, стареет быстрее, чем ожидается, требуя постоянного обновления и адаптации.
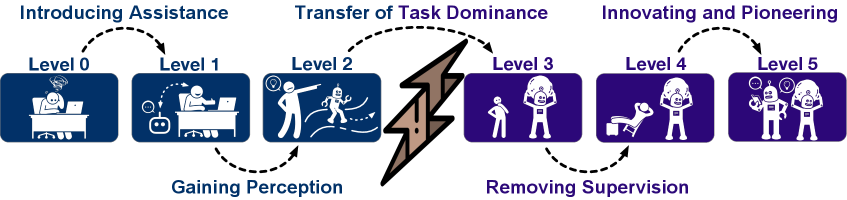
Исследование показывает, что эволюционные скачки происходят между уровнями агентов данных, демонстрируя прогресс в их развитии.
В этой связи, необходимо признать, что простым увеличением вычислительных мощностей проблему не решить. Подобный подход лишь временно замедляет наступление энтропии, но не отменяет ее. Настоящий прогресс требует принципиально новых подходов к управлению данными, основанных на автоматизации, интеллектуальном анализе и адаптивности. Необходимо создать системы, способные самостоятельно обнаруживать аномалии, очищать данные, интегрировать разнородные источники и генерировать полезные знания. В противном случае, мы обречены на вечное догоняние, пытаясь удержать ускользающий поток информации. И здесь, как ни странно, откат – это не всегда поражение, а иногда – необходимое путешествие назад по стрелке времени, позволяющее переосмыслить подходы и избежать тупиковых решений.
Задача не в том, чтобы просто хранить больше данных, а в том, чтобы извлекать из них больше смысла. И это – вызов, который требует не только технических инноваций, но и философского переосмысления нашей роли в эпоху информации.
Агенты Данных: Автономные Рабочие Процессы в Симфонии Информации
В эпоху, когда данные становятся новой нефтью, а скорость их генерации неуклонно растет, возникает необходимость в интеллектуальных системах, способных не только собирать и хранить информацию, но и автономно преобразовывать ее в ценные знания. Именно здесь на арену выходят Агенты Данных – архитектуры, основанные на возможностях больших языковых моделей (LLM), призванные преодолеть разрыв между необработанными данными и практически значимой аналитикой.
Эти агенты – не просто автоматизированные скрипты или наборы правил. Они обладают способностью к пониманию структуры данных, выявлению релевантных преобразований и выполнению конвейеров подготовки данных с минимальным вмешательством человека. Вспомним, что версионирование – это форма памяти, а в контексте данных – возможность отслеживать изменения и возвращаться к предыдущим состояниям, что критически важно для обеспечения надежности и воспроизводимости анализа.
В основе работы Агентов Данных лежит способность LLM к пониманию семантики данных. Они могут анализировать схемы баз данных, распознавать типы данных и взаимосвязи между ними, а также выявлять аномалии и несоответствия. Эта способность позволяет им автоматически генерировать запросы к базам данных, преобразовывать данные из одного формата в другой и выполнять сложные аналитические операции.
Однако, для достижения максимальной эффективности, Агентам Данных необходимы инструменты для оптимизации их работы. Здесь на помощь приходят фреймворки, такие как AFlow, которые позволяют автоматизировать и оптимизировать агентские рабочие процессы, обеспечивая масштабируемость и эффективность обработки данных. Стрела времени всегда указывает на необходимость рефакторинга, и в контексте рабочих процессов это означает постоянную оптимизацию и улучшение производительности.
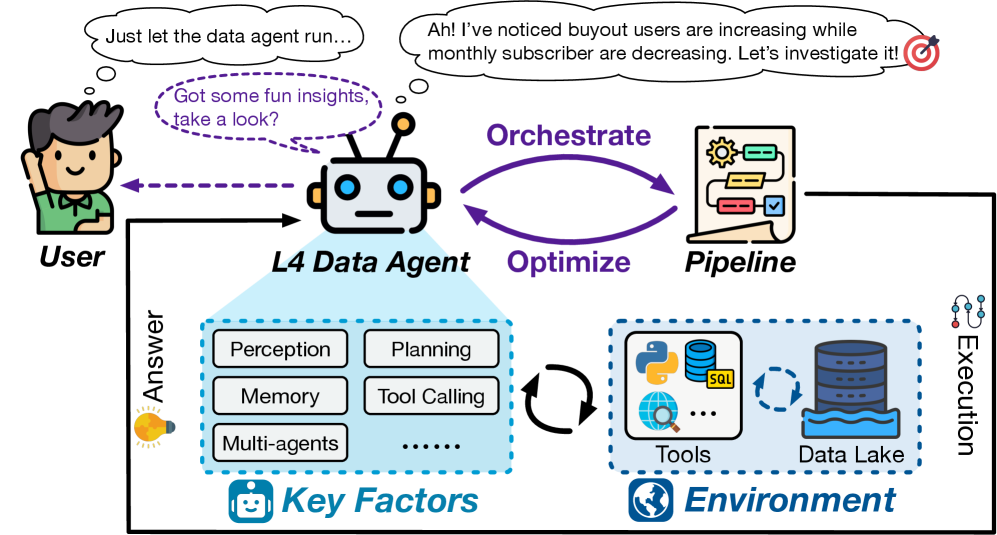
Агенты данных уровня 4 демонстрируют высокую степень автономии, позволяя им самостоятельно выполнять задачи.
В конечном итоге, Агенты Данных представляют собой эволюцию в подходе к обработке данных. Они не просто автоматизируют рутинные задачи, но и позволяют организациям извлекать больше ценности из своих данных, быстрее и эффективнее. Их способность к автономной работе и адаптации к изменяющимся условиям делает их незаменимым инструментом в эпоху, когда данные становятся ключевым фактором конкурентоспособности.
Исследователи полагают, что будущее Агентов Данных связано с развитием их способности к обучению и адаптации к новым типам данных и задачам. В конечном итоге, они должны стать интеллектуальными партнерами аналитиков, способными самостоятельно решать сложные проблемы и предлагать инновационные решения.
Специализированные Инструменты: Каждая Шестерня в Механизме Автономности
В эволюции систем, подобно живым организмам, каждый этап отмечен адаптацией и усложнением. Изначально, вспомогательные агенты данных уровня 1, обеспечивают поддержку, облегчая выполнение задач для пользователей. Они подобны опытным подмастерьям, ускоряющим рутинные операции, но не способным к самостоятельному творчеству.

Агенты данных уровня 1 обеспечивают поддержку, облегчая выполнение задач для пользователей.
Однако, требования к этим системам растут, и возникает необходимость в инструментах, способных к более сложным преобразованиям. Здесь на сцену выходят системы, подобные AutoPrep, которые улучшают способность к рассуждению и вызову инструментов для подготовки данных, отвечающих на вопросы на естественном языке. Это подобно обучению ученика не просто выполнять указания, а понимать суть задачи и самостоятельно находить оптимальное решение.
Потребность в автоматизации обслуживания и оптимизации баз данных приводит к появлению систем, таких как GaussMaster. Этот многоагентный помощник, подобно опытному инженеру, предлагает рекомендации по индексации и оптимизации управления данными, предотвращая накопление технического долга и обеспечивая стабильную работу системы во времени.
Взаимодействие с базами данных часто требует специфических знаний и навыков. Инструменты, такие как nvAgent и Alpha-SQL, упрощают этот процесс, позволяя пользователям взаимодействовать с данными и создавать визуализации, используя естественный язык. Это подобно переводу сложного технического языка на понятный человеческому.
Для управления сложными данными, хранящимися в озерах данных, необходимы комплексные инструменты. iDataLake представляет собой такую систему, обеспечивающую связывание данных, оркестровку конвейеров и выполнение аналитических задач. Это подобно строительству моста между разрозненными источниками данных, обеспечивающего плавный поток информации.
Каждый из этих инструментов — лишь часть сложной системы, которая постоянно развивается. Как и любой организм, эти системы нуждаются в постоянном уходе и адаптации, чтобы оставаться жизнеспособными и эффективными во времени. Именно эта непрерывная эволюция и делает их поистине ценными.
Иерархия Автономии: Уровни Интеллекта Агентов Данных
Развитие интеллектуальных систем обработки данных неуклонно ведёт к созданию агентов, способных автономно решать всё более сложные задачи. Однако, для осмысленного анализа и сравнения различных подходов, необходима чёткая система классификации, отражающая степень их независимости и интеллектуальных возможностей. Именно такую систему и представляет предложенная иерархическая таксономия агентов данных, охватывающая уровни от L0 до L5.
Эта таксономия, вдохновлённая стандартом SAE J3016, используемым в автомобильной промышленности для классификации систем автоматического вождения, определяет постепенное увеличение степени автономности. Подобно тому, как автомобили эволюционируют от простых систем помощи водителю до полностью автономных транспортных средств, агенты данных продвигаются от ручного управления к полному самоопределению.
Агенты уровня L0 предлагают лишь базовую помощь, требуя постоянного вмешательства человека. С каждым последующим уровнем, возрастает степень автоматизации и самостоятельности. Агенты уровня L1 способны выполнять отдельные задачи, но нуждаются в чётких инструкциях и контроле. Уровни L2 и L3 характеризуются всё большей способностью к самоорганизации и решению комплексных проблем, требуя лишь надзора со стороны человека. И, наконец, агенты уровня L4 и L5 представляют собой полностью автономные системы, способные к творческому решению задач и даже к созданию новых знаний.
Эта иерархия, подобно эволюционному древу, демонстрирует путь к созданию действительно интеллектуальных систем обработки данных. Каждая архитектура проживает свою жизнь, и мы лишь свидетели её развития. Важно понимать, что улучшения стареют быстрее, чем мы успеваем их понять. Поэтому, чёткое понимание этой прогрессии имеет решающее значение для эффективного развёртывания и управления агентами данных, позволяя адаптировать их возможности к конкретным бизнес-потребностям.
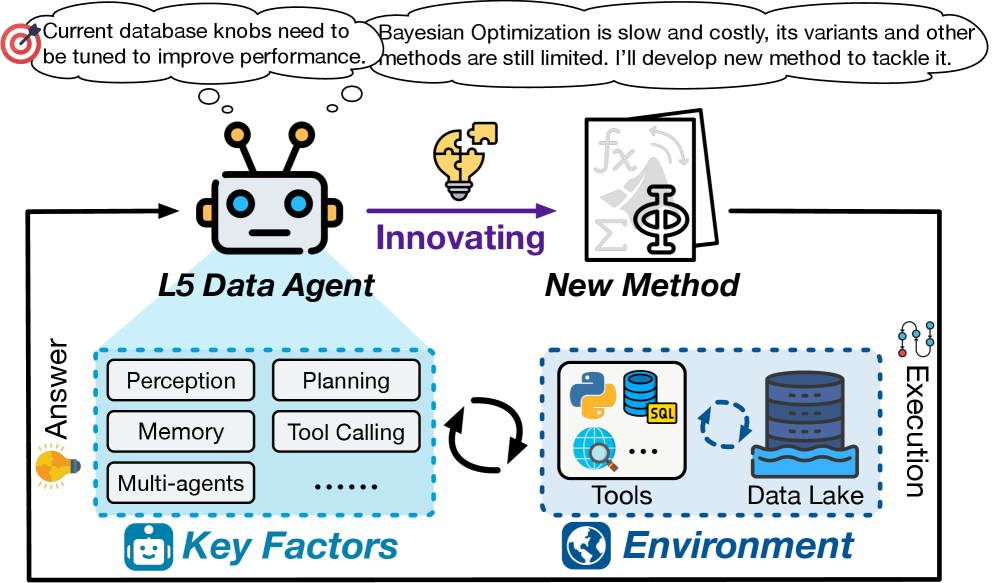
Агенты данных уровня 5 достигают полной автономии, способствуя выполнению задач без вмешательства человека.
В конечном счёте, задача состоит не просто в создании более умных систем, но и в понимании принципов, лежащих в основе их эволюции. Каждая ступень развития, каждый переход от ручного управления к автономному функционированию, является ценным уроком, который помогает нам создавать более надёжные, эффективные и интеллектуальные системы обработки данных.
Исследование, представленное авторами, подчеркивает эволюцию систем управления данными, от ручного вмешательства к полной автономии. Этот процесс неразрывно связан с понятием времени, ведь каждая ступень развития требует адаптации и исправления ошибок. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — создать его». Эта фраза прекрасно иллюстрирует подход, который демонстрируют исследователи, стремясь не просто описать текущее состояние data agents, но и наметить путь к их дальнейшему развитию. Автономные системы, как и любые сложные структуры, не избавлены от ошибок, но именно способность к самообучению и адаптации определяет их долгосрочную жизнеспособность и зрелость.
Что впереди?
Исследование, предложенное авторами, выстраивает иерархию, словно карту увядания систем. Каждый уровень автономии – это лишь отсрочка неизбежного. Попытка классифицировать "агентов данных" – благородная, но, возможно, запоздалая. Ведь сама идея полной автоматизации управления данными таит в себе парадокс: стремясь к идеалу беспристрастности, мы создаем системы, неспособные к осмысленному диалогу с прошлым. Каждая ошибка – сигнал времени, а рефакторинг – это не просто улучшение кода, а диалог с тем, что уже устарело.
Очевидно, что ключевым препятствием остается не техническая сложность, а онтологическая неопределенность. Что есть "данные"? Что есть "интеллект"? И самое главное – для чего все это нужно? Авторы справедливо отмечают вызовы, но упускают из виду, что сама погоня за "автономностью" может привести к созданию систем, лишенных критического мышления и способности к адаптации в условиях непредвиденных обстоятельств.
Вместо того чтобы стремиться к созданию "идеального агента", исследователям стоит сосредоточиться на разработке инструментов, позволяющих человеку эффективно взаимодействовать с данными. Иначе, мы рискуем создать системы, которые, подобно стареющим часам, будут продолжать тикать, но уже не будут показывать время.
Оригинал статьи: denisavetisyan.com
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Лига Новых Технологий
1.9K поста16.9K подписчиков
Правила сообщества
Главное правило, это вести себя как цивилизованный человек!
Но теперь есть еще дополнительные правила!
1. Нельзя раскручивать свой сайт, любую другую соц сеть или мессенджер, указывая их как источник. Если данная разработка принадлежит вам, тогда можно.
2. Нельзя изменять заглавие или текст поста, как указано в источнике, таким образом чтобы разжигать конфликт.
3. Постите, пожалуйста, полный текст с источника, а не превью и ссылка.