Многих пользователей интересует, может ли Дипсик генерировать изображения и чем вообще эта нейросеть отличается от привычных нам ChatGPT и других ИИ-сервисов. Deepseek (в русском сегменте чаще пишут «Дипсик») — это современная модель искусственного интеллекта, запущенная в 2023 году в Китае как отдельное направление хедж-фонда High-Flyer (основатель и генеральный директор — Лян Вэньфэн). Она разрабатывалась как продвинутая языковая система, способная анализировать запросы, писать тексты, помогать в решении задач и проводить сложные вычисления.
Со временем набор ее функций значительно расширился, и сегодня Deepseek рассматривается как одна из самых быстро развивающихся нейросетей в Азии. Разработчики делают акцент на открытой архитектуре, самостоятельном обучении модели и стремлении объединить языковые и графические технологии в одном интеллектуальном комплексе.
Умеет ли Дипсик генерировать изображения?
Нет, Deepseek сам по себе не рисует картинки, как это делают Midjourney или DALL·E. Однако нейросеть может работать с визуальной информацией косвенно и оказаться полезной, когда дело касается изображений.
Основные возможности Deepseek в работе с изображениями:
1. Описывает изображение текстом
передаете, что изображено (или загружаете картинку в интерфейсе, который это поддерживает) — модель формулирует связное, подробное описание.
2. Анализирует изображение
кто/что находится на картинке;
какие предметы на переднем и заднем плане;
какие надписи, логотипы, элементы интерфейса есть на изображении.
3. Анализирует композицию и стиль
общий жанр (иллюстрация, фото, инфографика);
примерный художественный стиль;
что в кадре отвлекает, что, наоборот, привлекает внимание.
4. Помогает придумывать промпты для других ИИ-генераторов
превращает ваше «хочу красивую обложку к статье» в детальный промпт;
адаптирует промпт под конкретный сервис (Midjourney, DALL·E, Stable Diffusion и т.п.).
5. Сопоставляет текстовую информацию с визуальной
проверяет, соответствует ли картинка описанию или ТЗ;
подсказывает, чего не хватает, чтобы визуал лучше отражал текст.
ТОП-10 нейросетей, которые умеют генерировать картинки
Midjourney — нейросеть для художественной генерации изображений по текстовому запросу, особенно сильная в стильных, атмосферных и концепт-артах.
Nano Banana — высокоскоростная модель Google Gemini 2.5 Flash для генерации и детального редактирования фотореалистичных изображений с сохранением консистентности персонажей.
Dall-E — модель от OpenAI, которая по текстовому описанию создает иллюстрации, умеет дорисовывать и редактировать фрагменты уже существующих изображений.
Stable Diffusion — открытая диффузионная модель, позволяющая генерировать и локально донастраивать изображения, а также использовать image-to-image, инпейтинг и аутпейтинг.
ChatGPT — универсальная модель GPT-4o с возможностью создавать изображения по тексту и комбинировать визуальный и текстовый контент.
Qwen — модель от Alibaba, которая по тексту создает детализированные изображения и поддерживает точное редактирование и сложный текст на картинках.
Runway — сервис для креаторов, где можно генерировать и редактировать не только изображения, но и видео (text-to-image, text-to-video и другие режимы).
Flux — нейросеть с точным контролем над стилем и деталями изображения, которая через LoRA-надстройки и тонкую настройку позволяют получать стилизованные и высококачественные изображения под конкретные задачи.
Kolors — нейросеть, сфокусированная на реалистичных, кинематографичных изображениях и динамичных сценах, часто используемая для промо-картинок и визуальных концептов.
SDXL — улучшенная версия Stable Diffusion, создающая более детализированные и фотореалистичные изображения, лучше справляющаяся с текстом и сложными сценами.
Это веб-интерфейс к нейросети Midjourney на русском языке, который позволяет генерировать изображения по текстовому описанию прямо в браузере. Сервис позиционируется как способ пользоваться Midjourney без Discord и знания английского, за вас все делает русскоязычный интерфейс. Доступ к Midjourney идет через единую подписку Study24.ai, а внутри кабинета вы просто выбираете нужный инструмент и задаете промпт.
Русский интерфейс и подсказки — не нужен английский.
Все запускается из браузера.
Единая подписка дает доступ не только к Midjourney, но и к другим нейросетям (GPT, DALL·E и др.).
Есть пробный период, можно сначала «пощупать» сервис.
Это онлайн-доступ к модели Nano Banana, которая умеет мгновенно генерировать и редактировать изображения по текстовому описанию. На стороне Google это продвинутая модель семейства Gemini 2.5 Flash Image, специализирующаяся на text-to-image и image-to-image, а Study24 дает к ней удобный русскоязычный интерфейс «в один клик». Через браузер можно создавать совершенно новые картинки, перерабатывать загруженные фото, менять фон, стиль, одежду, добавлять объекты и т.д.
Модель особенно сильна в фотореализме и сохранении «узнаваемости» персонажей при множественных правках.
Основан на Google Gemini 2.5 Flash Image — современная модель с поддержкой и генерации, и редактирования изображений.
Единая подписка дает доступ не только к Nano Banana, но и к другим нейросетям (GPT, DALL·E, DeepSeek и т.д.).
Быстрая генерация и редактирование, удобная для рабочих креативных сценариев (дизайн, маркетинг, соцсети).
Для активной работы и больших объемов генераций потребуется платный тариф — бесплатный план ограничен.
Как и у базовой модели Nano Banana, возможны сложности с очень мелкими деталями и сложными сценами (мелкий текст, крошечные объекты и т.п.).
Онлайн-генератор изображений на русском языке, который дает доступ к фирменной модели DALL·E 3 от OpenAI через простой веб-интерфейс. Пользователь вводит текстовое описание, а нейросеть превращает его в картинку — иллюстрацию, обложку, логотип или любой другой визуал по запросу.Сервис работает внутри агрегатора Study24: из одного личного кабинета можно пользоваться DALL·E 3, ChatGPT, Midjourney и другими нейросетями без переключения между сайтами.
Доступ к мощной модели DALL·E 3 от OpenAI в русскоязычном интерфейсе.
Одна подписка сразу на несколько нейросетей (DALL·E 3, Midjourney, GPT-модели и др.) в одном кабинете.
Работа с локальными тарифами в рублях.
Есть бесплатный старт через тариф FREE с приветственными токенами.
Это онлайн-доступ к популярной нейросети Stable Diffusion для генерации изображений по текстовым промптам или загруженным фотографиям. Сервис работает прямо в браузере, понимает русский язык и позволяет за секунды получать арты, обложки, стилизованные фото и другие визуалы. В интерфейсе можно выбрать нужную версию модели (например, Stable Diffusion XL или Stable Diffusion 3/3.5), настроить стиль, разрешение и количество вариантов, а затем сразу скачать результат в хорошем качестве.Оплата устроена по принципу «pay-as-you-go» — платите только за успешно сгенерированные картинки, без обязательной подписки.
Оплата только за генерацию, без абонентской подписки и скрытых платежей.
Поддержка генерации по тексту и по фото, с настройкой стиля, разрешения и количества вариантов.
Несколько версий Stable Diffusion (XL, 3/3.5) с разным качеством и ценой за изображение.
GPTunneL — крупный AI-хаб: в одном аккаунте доступны и другие нейросети (GPT-модели, Flux, Midjourney, DALL·E и т.д.).
Это русскоязычный веб-чат с моделью GPT-5, заточенный под учебу, работу и повседневные задачи. Платформа выступает агрегатором десятков нейросетей, где GPT-5 используется как основной «мозг» для диалогов, написания текстов, решения задач, программирования и генерации идей. Работать можно прямо в браузере или мобильной версии, без сложной настройки, с оплатой в рублях.
Единый агрегатор: в одном аккаунте доступны GPT-5, Nano Banana, Veo 3, FLUX, DALL·E, Midjourney и другие популярные модели.
Заточен под учебу и работу: есть готовые режимы для решения задач, написания рефератов/докладов, дипломов, презентаций и генерации видео.
Локальные тарифы в рублях и невысокий порог входа: минимальный платный план начинается с небольших сумм, плюс есть бесплатные лимиты.
Можно начать с ChatGPT 5-mini и DeepSeek на фримиум-тарифе, а затем перейти на полный GPT-5, не меняя платформу.
Нейросеть для генерации изображений по текстовому описанию, которая особенно хорошо работает с текстом внутри картинки: логотипы, надписи на вывесках, постерах, одежде и другим.Модель умеет органично «встраивать» текст в сцену, так что надписи выглядят частью изображения, а не просто наклейкой сверху.Поддерживается широкий спектр стилей — от фотореализма до акварели и иконографики, есть возможность персонализации и дообучения под фирменный стиль бренда.Сервис доступен через платформу GenAPI: вы подключаете модель по API и платите только за фактические генерации.
Отличная работа с текстом внутри изображения: логотипы, таблички, надписи читаются и выглядят естественно.
Поддержка множества художественных стилей и возможность дообучения под фирменный стиль бренда.
Быстрая генерация (в среднем около 15–23 секунд на картинку).
Гибкая модель оплаты: платите только за сгенерированные мегапиксели, без подписок и долгих обязательств.
Удобно подключать к своим продуктам через единое API вместе с другими моделями GenAPI.
Мощная нейросеть для генерации изображений в кинематографичном стиле: реалистичные лица, мягкий свет и атмосферные сцены, похожие на стоп-кадры из фильма. Сервис особенно полезен для обложек, сторителлинга, презентаций и проектов, связанных с видео и визуальными историями. Работать с моделью можно как через веб-интерфейс GenAPI, так и через API: вы отправляете текстовый запрос (опционально добавляете референс-картинку), а в ответ получаете готовое изображение. Модель поддерживает нестандартные форматы (16:9, 9:16 и др.), умеет «запоминать» персонажа по одной фотографии и имеет режим Turbo для быстрых и дешевых черновых набросков.
Кинематографичная картинка «из коробки»: мягкий свет, продуманная композиция и проработанные текстуры, минимум доработки в редакторе.
Умение держать узнаваемого персонажа по одной референс-фотографии — удобно для комиксов, серийных иллюстраций и рекламных кампаний.
Режим Turbo для быстрых и более дешевых черновиков, когда нужно перебрать много вариантов.
Поддержка широких и вертикальных форматов (16:9, 9:16 и др.) — удобно для превью, сторис и презентаций.
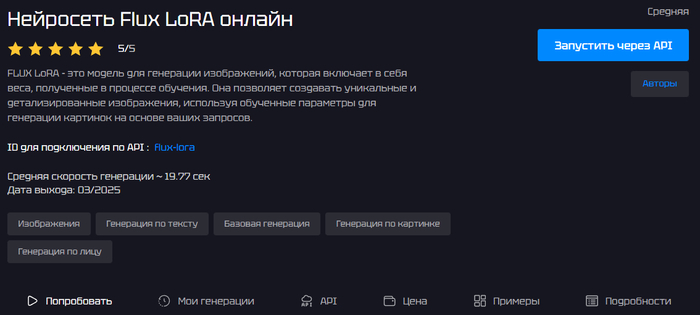
Версия модели FLUX.1 [dev] от Black Forest Labs с поддержкой LoRA-адаптеров, предназначенная для генерации детализированных изображений и тонкой персонализации стиля. Модель позволяет использовать обученные LoRA (например, через отдельный инструмент FLUX LoRA Portrait Trainer), чтобы «прикрутить» к генерации нужный бренд-стиль, конкретные лица, архитектуру или авторские художественные приемы. В интерфейсе GenAPI доступна настройка разрешения, числа шагов и силы LoRA, а средняя скорость генерации — около 15–16 секунд на изображение.
Поддержка LoRA-адаптеров — можно точно подгонять стиль под бренд, персонажей, архитектуру, жанры.
Высокое качество изображения: FLUX.1 [dev] хорошо держит реалистичность, детали, руки и текст.
Гибкая настройка параметров (разрешение, шаги генерации, сила LoRA) прямо из интерфейса GenAPI или по API.
Относительно быстрая генерация (в среднем ~15,8 секунды на картинку).
Легко встроить в рабочие процессы через единое API GenAPI, не занимаясь инфраструктурой и GPU.
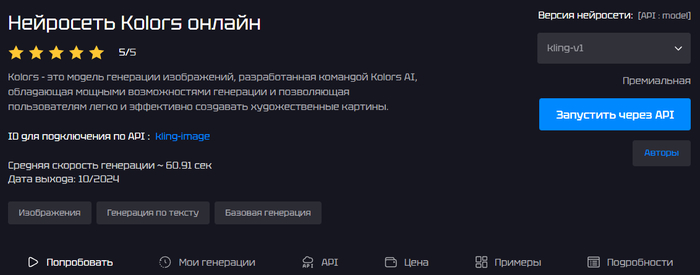
Нейросеть для генерации изображений, разработанная командой Kolors AI (создатели KlingAI), которая позволяет по текстовому запросу получать детализированные художественные картинки. Пользователь вводит промпт, выбирает формат и размер изображения, при необходимости добавляет референс — модель берет его за основу и дорисовывает сцену в нужном стиле. Средняя скорость генерации — около 25 секунд на картинку, а подключение возможно как через веб-интерфейс, так и по API (ID модели: kling-image).
Премиальная модель от создателей KlingAI, заточенная под художественные изображения.
Простая работа: текстовый запрос + выбор формата, размера и количества картинок, опционально — референс.
Нет подписок — оплачиваете только сгенерированные изображения, низкая цена в рублях.
Полностью русскоязычный интерфейс, оплату можно провести любой российской картой или через СБП.
Средняя скорость генерации ~25 секунд, что удобно для рабочих креативных задач.
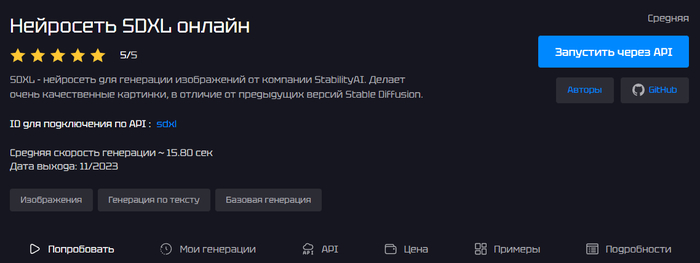
Онлайн-доступ к улучшенной версии Stable Diffusion от Stability AI, которая создает изображения по текстовому запросу и работает заметно качественнее ранних моделей Stable Diffusion. Модель дает более яркие и точные цвета, аккуратные тени и свет, лучше справляется с текстом на картинке и тонкой настройкой стилей, а также умеет дорисовывать недостающие части изображения и сильно перерабатывать исходное фото. GenAPI автоматически переводит русские промпты на английский (через опцию translate_input), так что можно писать запросы по-русски и получать хороший результат.Средняя скорость генерации — около 20–21 секунды на изображение, при этом модель доступна через веб-интерфейс и по API с ID sdxl.
Высокое качество картинки: детальная проработка света, теней, фактур и цветов по сравнению с ранними версиями Stable Diffusion.
Хорошая работа с текстом на изображении и поддержка negative_prompt для явного указания, чего вы не хотите видеть на картинке.
Автоперевод русских промптов через translate_input — можно писать описания на русском языке.
Поддержка разных типов входных данных: генерация с нуля по тексту, доработка и преобразование уже существующих изображений.
Открытый исходный код SDXL и отсутствие жестких творческих ограничений по стилям и сюжетам.
Deepseek: кому подходит нейросеть и как использовать ее возможности
Если коротко, Deepseek — это «мозговый помощник» на базе нейросети, который берет на себя рутину с текстами, кодом и задачами, а вам оставляет принятие решений. Сгенерировать картинку Дипсик не может, однако отлично работает с информацией, идеями и сложными запросами.
Что умеет именно Дипсик
Тексты
пишет статьи, посты, письма, сценарии, описания товаров;
умеет подстраиваться под тон, стиль и целевую аудиторию;
сокращает, перефразирует, улучшает готовые тексты.
Код и технические задачи
генерирует фрагменты кода и объясняет, как они работают;
помогает искать и исправлять ошибки;
подсказывает алгоритмы, структуры данных, архитектурные решения.
Аналитика и обучение
делает краткие выжимки из длинных документов;
сравнивает варианты, выделяет плюсы и минусы;
объясняет сложные темы простым языком, с примерами.
Работа с идеями
генерирует концепции, названия, слоганы, рубрики;
помогает придумать промпты для других нейросетей (например, генераторов изображений);
предлагает планы статей, сценариев, обучающих материалов.
Кому подходит Дипсик
Маркетологам, SMM и контент-мейкерам — для контент-планов, текстов, креативов и правок.
Разработчикам и технарям — для подсказок по коду, разбору ошибок и прототипирования.
Студентам и авторам — для конспектов, рефератов, структурирования учебных материалов.
Предпринимателям и менеджерам — для писем, коммерческих предложений, кратких аналитических записок.
Всем, кто много работает с текстом и информацией — от блогеров до продуктовых команд.
Какие задачи он помогает решать
В этой статье я дал ответ на популярный вопрос «может ли Дипсик генерировать изображения». Deepseek в первую очередь создан как мощный текстовый и аналитический ИИ-ассистент, который работает с кодом, задачами, документами и идеями, а не как полноценный графический генератор. При этом он отлично дополняет любые сервисы, умеющие рисовать: помогает сформулировать точные промпты, проанализировать получившиеся картинки и превратить визуал во внятный текст.
Если у вас есть опыт работы с Дипсиком, обязательно поделитесь им в комментариях. Напишите, как вы используете нейросети для работы с изображениями и какими сервисами дополняете Deepseek.