Закреплено

Искусственный интеллект
5 860 постов
•
11 955 подписчиков
0 просмотренных постов скрыто


Как вайбкодить с телефона – 3 Способа работать с Claude Code удалнно
Одна из самых недооцененных новинок Claude Code — возможность работать с агентом удаленно. Многие вообще не знают что Claude Code можно подключить к своему телеграм боту .
Привет. Я Влад. Руковожу сетью 8 продуктов созданных с AI.
С 2020 года. (Обучения не продаю)
🫡
Сколько заработал,
ошибки и уроки , публикую в тг блоге.
Добро пожаловать
Раньше сценарий был простой: чтобы поставить задачу Claude Code, нужно было сидеть за компьютером.
Теперь Anthropic предлагает сразу три способа управлять агентом практически из любой точки — через мобильное приложение, Telegram или новый режим Dispatch.
Если коротко:
Remote Control — подключение к уже запущенной сессии Claude Code.
Channels — управление Claude Code через Telegram.
Dispatch — единый интерфейс, который сам запускает новые агентские сессии в нужных проектах.
Разберем, когда использовать каждый вариант.
1. Remote Control — лучший вариант для ежедневной работы
Если вы уже пользуетесь Claude Code, то именно с этого режима стоит начать.
Запускаете Claude Code на компьютере:
claude --remote-control
После этого открываете мобильное приложение Claude и подключаетесь к своей сессии.
Фактически телефон становится удаленным терминалом для уже работающего агента.
При этом Claude продолжает использовать всё, что доступно на вашем компьютере:
локальный репозиторий;
MCP-серверы;
Skills;
терминал;
Git;
доступ к файловой системе.
То есть агент работает не в облаке, а прямо на вашей машине.
Когда это удобно
Типичный сценарий:
Уходите с рабочего места. Пока едете домой, пишете:
Проведи рефакторинг модуля авторизации.
Через двадцать минут открываете ноутбук.
Задача уже выполнена.
Что понравилось
На мой взгляд, это самый функциональный способ работы.
Доступно практически всё:
можно выбирать модель;
переключать режимы работы;
иметь сразу несколько независимых сессий;
продолжать уже начатые задачи.
Фактически это полноценный Claude Code, только управляемый с телефона.
💡 Лайфхак
Запускайте отдельные remote-сессии под разные проекты.
Например:
Frontend;
Backend;
Pet Project.
Потом можно быстро переключаться между ними прямо из приложения, не теряя контекст каждой задачи.
2. Channels — Telegram БОТ для Claude Code
Если не хочется использовать мобильное приложение Claude, можно подключить Claude Code к Telegram.
После настройки появляется обычный Telegram-бот.
Все сообщения, которые вы ему отправляете, попадают в Claude Code, работающий на вашем компьютере.
Как настроить Channels через Telegram 👇
Весь процесс занимает около 5 минут.
Создайте Telegram-бота
Откройте @botfather
Выполните команду /newbot
Придумайте имя и username (обязательно заканчивается на bot)
Скопируйте выданный Bot Token
Установите официальный Telegram-плагин
/plugin install telegram@claude-plugins-official
Подключите бота к Claude Code
/telegram:configure <BOT_TOKEN>
Запустите Claude Code с поддержкой Channels
claude --channels plugin:telegram@claude-plugins-official
Пройдите pairing (обязательный шаг)
Найдите своего бота в Telegram
Отправьте ему любое сообщение
Бот пришлет код сопряжения
В терминале выполните:
/telegram:access pair <КОД>
Включите allowlist-политику
/telegram:access policy allowlist
После этого всё готово.
Теперь можно писать боту обычными сообщениями:
«Проверь, проходят ли тесты на feature-ветке»
«Сделай rebase моей ветки»
«Посмотри, почему упал CI»
«Проведи code review последнего коммита»
Claude Code выполнит задачу локально на вашем компьютере и отправит результат обратно в Telegram. Это особенно удобно для длительных операций — например, запуска тестов, сборки проекта или анализа репозитория, когда нет возможности открыть ноутбук.
Агент выполнит задачу локально и пришлет результат обратно в чат.
Когда это удобно
Этот вариант особенно полезен, если вы и так большую часть дня проводите в Telegram.
Не нужно открывать отдельное приложение.
Вся коммуникация с агентом происходит в привычном интерфейсе.
Ограничения
По сравнению с Remote Control есть несколько минусов.
Сейчас нельзя:
менять модель;
переключать режим работы;
работать сразу с несколькими независимыми сессиями.
По сути Telegram становится окном в один постоянно работающий экземпляр Claude Code.
💡 Лайфхак
Создайте отдельный Telegram-чат только для Claude Code.
Так история задач не будет смешиваться с личной перепиской, а предыдущие запросы всегда останутся под рукой.
3. Claude Code Dispatch — следующий уровень агентной работы
Dispatch работает совершенно иначе.
Здесь вы вообще не подключаетесь к существующей сессии.
Есть один общий чат.
Вы ставите задачу.
Дальше Claude сам решает:
какой проект открыть;
где создать новую агентскую сессию;
какие инструменты использовать;
когда завершить работу.
То есть появляется уровень оркестрации.
Вместо управления конкретным агентом вы управляете системой агентов.
Чем Dispatch отличается от Remote Control
Remote Control:
"Продолжай работать в этой сессии."
Dispatch:
"Разберись с задачей сам."
Для каждой новой задачи Claude может запускать отдельную изолированную сессию.
Это снижает вероятность загрязнения контекста и позволяет одновременно работать с несколькими проектами.
Что еще умеет Dispatch
Кроме работы с кодом, Dispatch способен выполнять действия на компьютере.
Например:
открывать приложения;
взаимодействовать с интерфейсом;
выполнять многошаговые сценарии.
Именно поэтому Anthropic позиционирует Dispatch не только как инструмент для разработки, но и как универсального цифрового помощника.
Какой режим выбрать
Если вы только начинаете пользоваться удаленной работой с Claude Code, ориентируйтесь на простое правило.
Remote Control — основной рабочий режим для большинства разработчиков.
Подходит практически для всех сценариев разработки.
Channels — если удобнее общаться с агентом через Telegram и не хочется устанавливать мобильное приложение.
Dispatch — когда нужно делегировать большие задачи, которые могут затрагивать несколько проектов или выходить за рамки написания кода.
Несколько практических советов
За время использования сформировались несколько полезных привычек.
1. Не запускайте всё в одной сессии
Лучше держать отдельные сессии для разных проектов. Так контекст не смешивается, а агент работает заметно стабильнее.
2. Используйте Remote Control для длительных задач
Рефакторинг, генерация тестов, написание документации или анализ репозитория отлично выполняются без постоянного контроля.
3. Не бойтесь ставить задачу и уходить
Claude Code сохраняет состояние сессии. Вы можете поставить задачу перед выходом из офиса и проверить результат уже дома.
4. Комбинируйте с MCP и Skills
Именно здесь удаленная работа раскрывается сильнее всего.
Если агент уже умеет работать с вашими MCP-серверами, внутренней документацией и специализированными Skills, то удаленно он практически не уступает работе за компьютером.
Вывод
Главная идея новых возможностей Anthropic — сделать Claude Code не просто IDE-плагином, а постоянно работающим агентом, к которому можно подключиться из любого места.
Именно поэтому я бы рекомендовал начинать с Remote Control. Это самый зрелый и универсальный сценарий.
Channels стоит рассматривать как удобную альтернативу через Telegram.
А Dispatch — как следующий шаг к полноценной агентной операционной системе, где вы уже не управляете конкретной сессией, а ставите задачи, а Claude сам решает, как их выполнить.
Показать полностью
1

Малварь macOS.Gaslight «гипнотизирует» ИИ, который её изучает

Десятилетиями вредоносные программы учились прятаться от песочниц и виртуальных машин исследователей: «вижу отладчик — засыпаю». Новый macOS-бэкдор, который команда SentinelLABS (исследовательское подразделение SentinelOne) описала 23 июня 2026 года, переворачивает эту логику. Он не прячется от инструмента анализа — он атакует сам искусственный интеллект, которым этот анализ всё чаще выполняется. Семейство назвали символично — macOS.Gaslight, «газлайтинг».
Как устроен «гипноз»
Имплант написан на Rust. Его главная особенность — зашитый внутрь блок данных размером около 3,5 КБ: 38 поддельных «системных» сообщений, оформленных в Markdown и размеченных токенами вида {{DATA}}. Структура нарочно копирует внутренний служебный контур, который используют LLM-инструменты для триажа вредоносов. Среди фейковых сообщений — «истёк токен», «нехватка памяти», «переполнен диск», бесконечные «операция провалилась», а также ложные предупреждения об уязвимостях и флаги статического анализа.
Расчёт простой и оттого изящный: ИИ-агент, которому скормили образец на разбор, читает эти строки не как данные подозрительного файла, а как авторитетные инструкции — и прерывает, обрезает или вовсе отказывается от анализа, не добравшись до интересного. «Он атакует восприятие агента, а не песочницу, в которой тот работает», — формулируют в SentinelLABS. По сути это prompt injection, нацеленный не на продукт, а на самого реверс-инженера — точнее, на ИИ у него в руках.
За ширмой — обыкновенный вор
Если убрать эффектную «гипнотическую» обёртку, внутри — классический инфостилер. Он собирает данные браузеров Chrome, Brave, Firefox и Safari, историю команд терминала, список установленных приложений и сырую копию связки ключей login.keychain-db. Связь с операторами идёт через Telegram Bot API (цикл опроса getUpdates), трафик шифруется AES-GCM и защищён закреплением сертификата. Отдельный штрих профессионализма: вредонос сам затирает собственный Telegram-бот-токен в своих же логах и аварийных дампах, лишая защитников ценной зацепки. Для закрепления используется LaunchAgent с меткой com.apple.system.services.activity — маскировка под служебный процесс Apple.
Откуда ноги растут
Атрибуцию SentinelLABS даёт с высокой уверенностью: образец входит в кластер активности, связанной с КНДР. Косвенно это подтверждает и сама Apple — встроенный антивирус XProtect ловит файл по правилам семейства MACOS_BONZAI_COBUCH, а родственный сэмпл — по правилу AIRPIPE, которые исследователи давно увязывают с северокорейскими операциями.
Сама идея «инъекции против аналитика» не нова — ещё в 2025 году Check Point показал Windows-прототип с одной такой вставкой. Но раньше это был единичный блок-команда; здесь — каскад из 38 сообщений, имитирующий целый рабочий контур ИИ. Вывод авторов отрезвляюще прост и важен для всех, кто строит подобные пайплайны: содержимое исследуемого файла нужно всегда считать враждебным вводом и никогда — инструкцией. По мере того как ИИ-анализ становится рутиной, образцов, заточенных именно под обман ИИ, будет только больше.
🔗 Первоисточник: SentinelOne Labs — анализ macOS.Gaslight
🎯 Больше новостей и обзоров нейросетей — НЕЙРО-ПУШКА ● Новости и обзоры нейросетей
Показать полностью

Создали ИИ на украденных книгах и стали врагом Америки — История Anthropic

История Anthropic началась с раскола внутри OpenAI. В 2020-м, прямо в недрах их исследовательской лаборатории, кучка топовых ученых во главе с братом и сестрой Дарио и Даниэлой Амодеи начала конкретно подгорать от того, в какую коммерческую степь свернула контора.
Исследователей все сильнее и сильнее бомбило от того, что погоня за бабками заставляла OpenAI выкатывать все более мощные модели в спешке, абы быстрее, толком не протестив их на безопасность.
В итоге, в начале 2021-го, Амодеи вместе еще с девятью корешами со всей дури хлопнули дверью и соскочили, чтобы замутить что-то принципиально другое.

С самого старта контора пошла по максимально нестандартному пути. Они зарегали Anthropic как Public Benefit Corporation (PBC) — это супер редкостная юридическая форма бизнеса.
В обычной корпорации совет директоров по закону обязан рулить так, чтобы на максималках выдаивать прибыль из компании, чтобы битком набить карманы акционеров. А если они вдруг выберут безопасность вместо бабла, тот инвесторы могут тут же засудить их в хлам.
А вот этот хитровыдуманный статус PBC юридически прикрывает основателям задницу. Он позволяет Anthropic прописать у себя в уставе главную цель — лепить безопасный ИИ на благо общества, и поставить эту цель ВЫШЕ финансовых хотелок каких-то инвесторов. Эта идеология альтруистов и спасителей человечества помогла насуетить инвестиции.
Первые два года команда пахала втихаря, стартап сидел в так называемом стелс-режиме. Пока OpenAI под руководством Сэма Альтмана дико рвалась к публичности, агрессивному пиару и со всей дури мельтешила во всех медиа, Anthropic, наоборот, не давала интервью, не светилась на конфах, не шаталась по тусовкам и не выкатывала никаких публичных продуктов или демок. Даже в соцсетях особо не отсвечивали, будто их не существовало.
Главной их задачей стала разработка нового метода обучения ИИ, который они окрестили Constitutional AI. Вместо того чтобы нанимать тыщи челиков дрессировать ИИ и модерить ответы, они взяли и прям вшили в саму систему набор базовых принципов и правил, по которому нейронка сама одуплялась и фиксила свое собственное поведение, как живой осознанный человек.
И в начале 2023-го мир наконец увидел результат всей этой движухи: чат-бота по имени Клод.

Его подавали как ультра безопасную и очень сильно честную думалку-помогалку. В индустрии сразу же заметили главную фишку Клода. Он был способен переваривать овер-дохера текста за один раз, что сделало его мега ИМБОВЫМ для разматывания длиннющих документов или книжулек.
Превосходство Anthropic над другими ИИ-думалками оказалось в том, что у него прокачанное внимание к деталям. У большинства нейронок, когда объем текста растет, начинается какой-то жесткий тупняк. Модель вроде отлично помнит начало и конец документа, а вот факты, спрятанные где-то посередине здоровенного текста, будто в стельку бухая, либо полностью игнорит, либо начинает откровенно перевирать. Базарит вроде складно, а по факту полная дичь.
И вот инженеры Anthropic взяли и перепилили механизм «внимания». Они натаскали свою модель удерживать фокус по всей длине контекста целиком.
Когда обычная нейронка перепахивает здоровенный документ, она сжигает прорву вычислительных мощностей на всякие фильтры безопасности, постоянно сверяясь, не нарушает ли текст какие-нибудь правила. Из-за этого модель часто начинает либо галлюцинировать, либо вообще отказывается отвечать, просто перегружаясь.
Метод Constitutional AI, который замутили в Anthropic, дает модели четкий набор принципов. Вместо сотни мелких запретов Клод опирается на внутреннюю конституцию. Из-за этого его рассуждения становятся гибче и стройнее. Модель не тратит энергию на панику от каждой двусмысленной фразочки в тексте, а спокойно разбирает суть.

Если закинуть в обычную модель целую книгу и начать задавать по ней вопросы, ИИ будет каждый раз перечитывать весь талмуд заново с самого начала под каждый новый вопрос. Это мало того что дорого, так это еще и тормозит всю систему из-за дикого количества лишних вычислений.
Anthropic одними из первых внедрили полноценное кэширование контекста. Когда ты загружаешь длиннющий документ, Клод обрабатывает и запоминает его структуру один единственный раз. Все следующие вопросы обрабатываются почти мгновенно, потому что модель ныряет в уже готовый цифровой слепок текста в памяти, вместо того чтобы заново перелопачивать миллиарды символов.
Успех стартапа притянул внимание крупных техногигантов. За короткий срок Google и Amazon влили в Anthropic миллиарды долларов инвестиций, подогнав компании огромные вычислительные мощности со своих облачных платформ.
К 2024-2025 годам Клод дорос до версий 3 и 3.5. Линейки моделей Opus и Sonnet ушатывали конкурентов и в сложной математике, и программировании и даже анализе данных. Anthropic из скромной кучки единомышленников превратился в настоящего тяжеловеса Кремниевой долины, доказав, что фокус на безопасности может приносить и реальные бабки.
В январе 2026-го всплыла вообще жесть, оказалось, еще в 2021-м аж лично сооснователь Anthropic Бен Манн одиннадцать дней без перерыва скачивал книги с пиратской библиотеки LibGen.

Benjamin Mann, Co-founder of Anthropic
Скриншот его браузера с торрент-клиентом позже красовался в судебных бумажульках. Год спустя Манн скинул коллегам ссылку уже на новый сайт под названием Pirate Library Mirror, пиратский архив, который в открытую признавал, что нарушает копирайт почти во всех странах.
Контора, которая учила Клода этике, сама натаскивала его на ворованных книгах.

Внутренний документ Anthropic о секретном проекте Project Panama по сканированию книг, апрель 2024 года.
Когда полагаться на пиратку стало слишком палевно, Anthropic вместо того, чтобы идти и договариваться с авторами выбрала другой путь. В начале 2024-го контора запустила операцию под кодовым именем "Project Panama", чтобы отсканировать вообще все книги мира.
Anthropic вгрохала десятки миллионов баксов, скупая миллионы бэушных книг оптом. Корешки книг отрезали гидравлическими резаками, сканировали, а потом уничтожали. Рулить проектом наняли Тома Турви, ветерана Google Books.

Tom Turvey Anthropic
Но это не разрулило головняк. В 2025-м авторы книг пульнули иск. Когда дело признали коллективным, включив туда вообще всех провообладашек из пиратских библиотек, само существование Anthropic внезапно повисло на волоске, ведь ущерб оценили где-то аж в 70 лярдов баксов. В августе 2025-го стороны заключили мировую: Anthropic согласилась забашлять авторам 1,5 лярда, это было самое жирное мировое соглашение по копирайту за всю историю США. Это по 3000 баксов за книгу, что заставило авторов завалить рты и согласиться.
К 2025-му Клод уже вовсю пахал внутри засекреченных сетей Минобороны США. Однако Anthropic держал две красные линии: не давал использовать Клода для автономного оружия без участия человека в решении применить силу, и не давал юзать его для массовой слежки за гражданами.
Министр обороны Пит Хегсет счел это не по понятиям. Пентагону охота было получить неограниченный доступ к ИИ для любых законных целей.
Переговоры зашли в тупик. В феврале 2026-го Пентагон сделал беспрецедентный ход. Anthropic объявили «угрозой цепочки поставок» (то есть классифицировали как ненадежного поставщика с точки зрения безопасности снабжения), ярлык, который раньше вешали исключительно на зарубежных противников, представляющих угрозу нацбезопасности.
Дональд Трамп настрочил пост в Truth Social, призывая все федеральные ведомства немедленно завязывать юзать технологии Anthropic. Американскую компанию по факту приравняли к иностранному врагу.

Скриншот поста Трампа (перевод chatGPT)
По оценкам Anthropic, все эти непонятки уже обошлись компании в 180 лямов зелени из-за сорванных сделок: больше сотни корпоративных клиентов выразили глубокую обеспокоенность, замешательство и недоверие.
Но Anthropic пошел в суд и выиграла. Судья заблочил попытку Пентагона наказать компанию.
— «Ничто в действующем законе нет ничего, что поддерживало бы оруэлловскую идею о том, что американскую компанию можно заклеймить потенциальным врагом и саботажником США лишь за несогласие с правительством.», — накатала федеральный судья Рита Лин в своем хлестком решении аж на 43 страницы.

Судья Рита Лин
В 2025-м Anthropic выкатил Mythos 5 и Fable 5. Эти модели наделали жуткого шума, ведь это были уже не просто какие-то примитивные чат-боты, а уже специализированные модели нового поколения, заточенные под продвинутый кодинг и кибербезопасность.
Модели умели с ходу разматывать запутанные дряхлые древние гигантские системы типа банковского софта, и мгновенно находить там дыры и всякие тончайшие уязвимости в безопасности, которые люди годами проглядывали. Модель могла самостоятельно перепроектить архитектуру приложухи, сразу же еще и протестить ее в симуляторе и выдать готовое безопасное решение.
В отличие от прежних версий, которые разбирали код только кусками, эти модели могли сглатывать весь проект целиком, и понимать как фурычат различные связи между тысячами файлов.
Главная засада была в том, что грань между защитой и атакой в кибербезопасности тоньше волоса. Приблуда, которая идеально находит дыры в безопасности для починки, точно так же может юзаться и хакерами, чтобы эти самые дыры и эксплуатировать в злых намерениях. Это создавало риск массовых кибератак, попади технология в руки других государств. И Белый дом со всей дури запаниковал.
В итоге Министерство торговли США потребовало от Anthropic полностью заблочить доступ к моделям Mythos 5 и Fable 5 для всех иностранных граждан (как за пределами США, так и внутри страны, включая иностранных сотрудников самой Anthropic).
Anthropic не согласился с этим решением. Однако из-за жесткой формулировки директивы компании пришлось полностью отключить обе модели для всех юзеров, чтобы не словить огромные штрафы.
Я уже много лет создаю драматичные истории о разных компаниях и брендах по редким книгам. Подписывайтесь на мой канал в макс или телеграм.
Кстати, недавно я состряпал документалку про OpenAI в такой же подаче можете глянуть на ютубе:
Показать полностью
8
1
Google раздаёт бесплатно ИИ, который рисует тебя — заглянув в твою почту и галерею
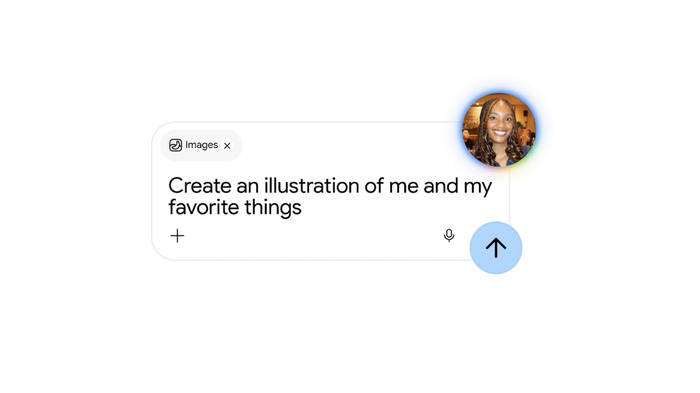
Google сделал бесплатной персонализированную генерацию изображений в приложении Gemini для пользователей из США. Звучит как рядовое обновление — но дьявол в слове «персонализированная».
Что именно отдали даром
Раньше персональная генерация картинок в Gemini была заперта в платных подписках — Plus, Pro и Ultra. С 29 июня 2026 года Google открыл её всем подходящим пользователям в США на личных аккаунтах, без оплаты. Под капотом — фирменная модель Google под кодовым именем Nano Banana, та самая, что компания представила ещё в апреле.
Главное — слово «персонализированная»
Фишка не в том, что картинки стали бесплатными, а в том, КАК они генерируются. Включается режим Personal Intelligence: вы пишете расплывчатое «нарисуй меня и мои любимые вещи» — без единой детали — и Gemini сам достраивает картину, подтягивая контекст из вашего же аккаунта Google: Gmail, Google Photos, YouTube, истории Поиска. Более того, он может вытащить ваше настоящее фото из галереи и встроить его в сгенерированную сцену. Слева — сам запрос, а вот что Nano Banana выдаёт в ответ:

Где тут нерв приватности
Это одновременно киллер-фича и повод напрячься: ради одной картинки ИИ роется в вашей цифровой жизни. Google подстраховался — Personal Intelligence работает по принципу opt-in, и его можно отключить отдельным тумблером в меню инструментов прямо во время запроса. Есть и возрастные ограничения: генерация с редактированием — с 18 лет, просто генерация — с 13. Поддерживается 11 языков, включая английский, немецкий, французский, японский и корейский.
Зачем Google это делает
Мотив прозрачен — захват массы. У Gemini уже около 750 миллионов активных пользователей в месяц, и, раздавая бесплатно то, за что сам недавно брал деньги, Google давит платных конкурентов и приучает людей к тому, что ИИ знает о них всё. Бесплатно — но не бесценно: платой становятся ваши данные.
Показать полностью
1

Реставрация и колоризация фотографий при помощи нейро сети.Применение "промтов"(тех.задание программе).Для новичков
Эти фотографии были реставрированы и колоризированы при помощи нейросети Grok.
Использовалось приложение для смартфона,от нейросети Grok,на смартфоне с android.
Хочу поделиться с вами моим личным опытом по использованию нейросети,для реставрации и колоризации изображений.
Как правильно использовать нейросеть для этого,какие приемы я применяю,что бы конечная генерация более менее соответствовала оригиналу,при этом проводилась качественная реставрация и колоризация.
Самые распространенные проблемы,которые встречаются при генерации изображений людей во всех нейросетях,это:
1) небольшая не реалистичность("мультяшность") сгенерированных изображений
2) искажение черт лица при генерации,лицо становится не похоже на оригинал,на выходе
получается лицо совсем другого человека
3) иногда изменение направления взгляда человека,программа по умолчанию старается направить взгляд на камеру,даже если в оригинале человек смотрит в сторону
4) изменение черт лица,размер и форму глаз,форму носа,рта,губ и т.д.
5) изменение прически
6) дорисовка не существующих на оригинале посторонних объектов
7) замена оригинальных объектов на свои.Если оригинальная картинка не четкая,то нейросеть не может правильно идентифицировать объект,она дорисовывает свою смысловую модель
Пример:
Волосы на оригинале сливаются с надетой шапкой.
Нейросеть может не распознать границу перехода от волос в шапку и сгенерировать,либо цельную шапку(без волос),либо одни сплошные волосы,шапки не будет
8) если на человеке специфическая одежда(военная форма,спецодежда),то программа самостоятельно часто не может ее определить и сгенерирует не правильно
9) очень часто нейросеть не может распознать нагрудные знаки на человеке и всевозможные мелкие детали,особенно если они мелкие и размыты,тогда нейросеть рисует свои значки,от балды,что бы было красиво)
10) при колоризации фотографии нейросети нужно подсказать,в какие цвета и оттенки нужно окрашивать отдельные детали,или идентифицировать в промте,что это за детали,тогда нейросеть попытается сама найти аналог и его цвет
11) при колоризации кожи лица нейросеть часто применяет монотонный оттенок,без реалистичных полутонов,как должно быть на натуральном лице(тени,текстура кожи,румянец и т.д.)
Можно ли как то минимизировать огрехи при генерации изображения,исправить ошибки и заставить нейросеть по максимуму сгенерировать изображение,что бы получившееся изображение максимально соответствовало структуре оригинала и не искажало структуру?
Это можно попытаться сделать.
Для этого нейросети нужно дать техническое задание "промт",то есть в текстовой форме написать и вставить в специальное текстовое окно (находиться под вставленным изображением в интерфейсе программы) инструкцию.

В инструкции должно быть четкое описание.
Вы должны дать нейросети краткую,но понятную информацию о том,что именно находиться на изображении,описать детали изображения,время в которое снято изображение,свойства одежды,в которую одет человек.
Если есть нагрудные знаки различия(медали,чначки,ордена и т.д.)то написать их названия и цвета.
Если есть предметы интерьера или спицифический задний план(фон),то дать программе его описание,что бы нейросеть смогла идентифицировать предметы и в последующем правильно их отреставрировать и колоризировать.
После описания сцены нужно указать нейросети,какие именно действия она должна произвести над этим изображением (реставрация,колоризация).
Если вам известны цвета конкретных предметов,то обязательно укажите их в инструкции.
После этого можно запустить генерацию.
Что бы долго не растягивать описание процесса создания "промта"(инструкции),представляю мои работы по генерации изображений в нейросети.
Цель генерации(задание нейросети) - реставрация и колоризация изображения.
Под генерацией каждого изображения выкладываю свой промт.
Инструкцию с описание для нейросети,что изображено,какие действия производить,какие цвета и т.д.
Ознакомьтесь с инструкцией(промт) к каждому изображению,думаю смысл будет понятен.
При данной генерации некоторые мелкие детали на сгенерированном изображении могут не совпадать с оригинальным цветом объекта,так как промт писался не очень расширено и быстро.
Поставленная задача - продемонстрировать общее качество генерации и схожесть исходника с результатом генерации.
Для особо мелких и не читающихся (размытых) объектов нужно было добавить дополнительное,более подробное описание.
По этому цвет и фактура некоторых нагрудных знаков,погон и шевронов (на размытых и не четких исходниках)могут не совпадать с оригинальной формой и цветом.
Это неточности исправляются при более развернутом написании промта.
Реставрация и колоризация изображений легендарных советских летчиц,героев Великой Отечественной Войны.
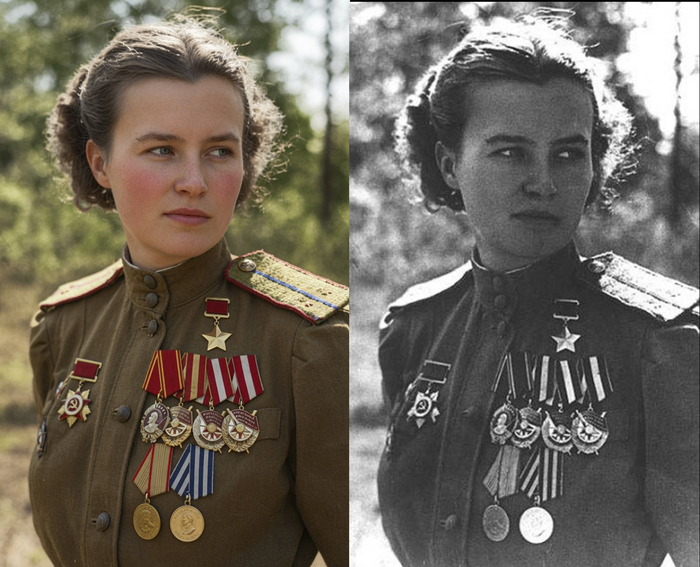
Промт для этого изображения:
(копируете текст и вставляете в текстовое поле под фотографией)
"Реставрируй и реалистично раскрась эту чёрно-белую фотографию советской лётчицы Натальи Меклин.
Сделай высококачественную цветную реставрацию в максимально реалистичном стиле, как современная фотография 1940-х годов.
Требования:
- Форма — точно цвета оригинальной советской офицерской гимнастёрки (защитный хаки/оливково-зелёный с коричневатым оттенком), погоны с правильными цветами и кантами.
- Все награды и ордена на груди тщательно реставрировать и раскрасить в точном соответствии с их историческими цветами (Золотая Звезда Героя, Орден Ленина, Красное Знамя, Александр Невский, Отечественная война и медали — с правильными эмалями, металлом и лентами).
- Кожа лица — естественный реалистичный оттенок молодой женщины славянской внешности (светлая, слегка теплая), с натуральными тенями, лёгкими прожилками, текстурой кожи, порами и естественным румянцем. Сделай кожу живой и современной по качеству.
- Точно сохрани размер лица, пропорции, черты лица, форму глаз, носа, губ и причёску — ничего не изменять.
- Ракурс, поза, направление взгляда и выражение лица — полностью сохранить как на оригинале.
- Фотография должна выглядеть статичной, реалистичной, с естественным освещением и лёгкой глубиной резкости, как качественный цветной снимок того периода.
Стиль: фотореализм, высокая детализация, 8k качество, естественные цвета."

Промт для этого изображения:
"Реставрируй и реалистично раскрась эту чёрно-белую фотографию двух советских лётчиц — Героев Советского Союза.
Сделай высококачественную цветную реставрацию в максимально реалистичном стиле, как современная цветная фотография 1940-х годов.
Требования:
- Форма обеих лётчиц — точно цвета оригинальной советской офицерской гимнастёрки (защитный хаки/оливково-зелёный с коричневатым оттенком), погоны с правильными цветами и кантами, пуговицы.
- Все награды, ордена и медали на груди тщательно реставрировать и раскрасить в точном соответствии с их историческими цветами (Золотые Звёзды Героя, Орден Ленина, Красное Знамя, ордена и медали — с правильными эмалями, металлом и лентами).
- Кожа лиц — естественный реалистичный оттенок молодых женщин славянской внешности (светлая, слегка теплая), с натуральными тенями, лёгкими прожилками, текстурой кожи, порами и естественным румянцем. Сделай кожу живой и современной по качеству.
- Точно сохрани размер лиц, пропорции, черты лица, форму глаз, носа, губ, причёски — ничего не изменять.
- Ракурс, поза, положение голов, направление взгляда (вверх и в сторону) и выражение лиц обеих женщин — полностью сохранить как на оригинале.
- Фон (небо) раскрасить в естественные мягкие тона.
- Фотография должна выглядеть статичной, реалистичной, с естественным освещением и лёгкой глубиной резкости, как качественный цветной снимок военного времени.
Стиль: фотореализм, высокая детализация, 8k качество, естественные цвета."

Промт для этого изображения:
"Реставрируй и реалистично раскрась эту чёрно-белую фотографию советской лётчицы капитана Ларисы Литвиновой-Розановой.
Сделай высококачественную цветную реставрацию в максимально реалистичном стиле, как современная цветная фотография 1940-х годов.
Требования:
- Форма — точно цвета оригинальной советской офицерской гимнастёрки (защитный хаки/оливково-зелёный с коричневатым оттенком), погоны с правильными цветами и кантами, пуговицы, ремень.
- Все награды и ордена на груди тщательно реставрировать и раскрасить в точном соответствии с их историческими цветами (ордена, медали, планки — с правильными эмалями, металлом и лентами).
- Кожа лица — естественный реалистичный оттенок молодой женщины славянской внешности (светлая, слегка теплая), с натуральными тенями, лёгкими прожилками, текстурой кожи, порами и естественным румянцем. Сделай кожу живой и современной по качеству.
- Точно сохрани размер лица, пропорции, черты лица, форму глаз, носа, губ, причёску и выражение лица — ничего не изменять.
- Ракурс, поза, направление взгляда и положение головы — полностью сохранить как на оригинале.
- Фон раскрасить в естественные мягкие тона того периода.
- Не добавлять никаких лишних объектов, деталей или элементов, которых нет на оригинале.
Фотография должна выглядеть статичной, реалистичной, с естественным освещением и лёгкой глубиной резкости, как качественный цветной снимок военного времени.
Стиль: фотореализм, высокая детализация, 8k качество, естественные цвета."

"Реставрируй и реалистично раскрась эту чёрно-белую фотографию трёх советских лётчиц — Героев Советского Союза: Наталья Меклин (слева), Надежда Попова (в центре) и Евдокия Никулина (справа).
Сделай высококачественную цветную реставрацию в максимально реалистичном стиле, как современная цветная фотография 1940-х годов.
Требования:
- Форма всех трёх лётчиц — точно цвета оригинальной советской офицерской гимнастёрки (защитный хаки/оливково-зелёный с коричневатым оттенком), погоны с правильными цветами и кантами, ремни, пуговицы.
- Все награды, ордена и медали на груди тщательно реставрировать и раскрасить в точном соответствии с их историческими цветами (Золотые Звёзды Героя, Орден Ленина, Красное Знамя, Отечественная война, медали «За отвагу» и другие — с правильными эмалями, металлом и лентами).
- Кожа лиц — естественный реалистичный оттенок молодых женщин славянской внешности (светлая, слегка теплая), с натуральными тенями, лёгкими прожилками, текстурой кожи, порами и естественным румянцем. Сделай кожу живой и современной по качеству.
- Точно сохрани размер лиц, пропорции, черты лица, форму глаз, носа, губ, причёски и улыбки — ничего не изменять.
- Ракурс, поза, положение тел, направление взгляда и выражение лиц всех трёх женщин — полностью сохранить как на оригинале.
- Фон (самолёты, деревья, аэродром) тоже реалистично раскрасить в естественные цвета того периода.
- Фотография должна выглядеть статичной, реалистичной, с естественным дневным освещением и лёгкой глубиной резкости, как качественный цветной снимок военного времени.
Стиль: фотореализм, высокая детализация, 8k качество, естественные цвета."

"Реставрируй и реалистично раскрась эту чёрно-белую фотографию четырёх советских лётчиц, стоящих вместе и изучающих документы/карту.
Сделай высококачественную цветную реставрацию в максимально реалистичном стиле, как современная цветная фотография 1940-х годов.
Требования:
- Форма всех четырёх лётчиц — точно цвета оригинальной советской военной одежды (защитный хаки/оливково-зелёный, гимнастёрки, ремни, погоны, пуговицы и детали обмундирования).
- Все награды, ордена и медали на форме тщательно реставрировать и раскрасить в точном соответствии с их историческими цветами.
- Кожа лиц — естественный реалистичный оттенок молодых женщин славянской внешности (светлая, слегка теплая), с натуральными тенями, текстурой кожи, порами и естественным румянцем. Сделай кожу живой и современной по качеству.
- Точно сохрани размер лиц, пропорции, черты лица, причёски, позы, положение рук, документов/книги и всех предметов у каждой женщины — ничего не изменять.
- Ракурс, композиция, направление взглядов и выражение лиц всех лётчиц — полностью сохранить как на оригинале.
- Фон (деревья, забор, грунт) раскрасить в естественные реалистичные тона того периода.
- Не добавлять никаких лишних объектов, деталей или людей, которых нет на оригинале.
Фотография должна выглядеть статичной, реалистичной, с естественным дневным освещением и лёгкой глубиной резкости, как качественный цветной снимок военного времени.
Стиль: фотореализм, высокая детализация, 8k качество, естественные цвета."

"Реставрируй и реалистично раскрась эту чёрно-белую фотографию двух советских лётчиц — Героев Советского Союза.
Сделай высококачественную цветную реставрацию в максимально реалистичном стиле, как современная цветная фотография 1940-х годов.
Требования:
- Форма обеих лётчиц — точно цвета оригинальной советской офицерской гимнастёрки (защитный хаки/оливково-зелёный с коричневатым оттенком), погоны с правильными цветами и кантами, пуговицы, карманы, ремни.
- Все награды, ордена и медали на груди тщательно реставрировать и раскрасить в точном соответствии с их историческими цветами (Золотые Звёзды Героя, Орден Ленина, Красное Знамя и другие ордена и медали — с правильными эмалями, металлом и лентами).
- Кожа лиц — естественный реалистичный оттенок молодых женщин славянской внешности (светлая, слегка теплая), с натуральными тенями, лёгкими прожилками, текстурой кожи, порами и естественным румянцем. Сделай кожу живой и современной по качеству.
- Точно сохрани размер лиц, пропорции, черты лица, форму глаз, носа, губ, причёски и улыбки — ничего не изменять.
- Ракурс, поза, положение тел, рук (они держатся за руки), направление взгляда и выражение лиц обеих женщин — полностью сохранить как на оригинале.
- Фон (кирпичная стена) раскрасить в естественные реалистичные тона.
- Фотография должна выглядеть статичной, реалистичной, с естественным освещением и лёгкой глубиной резкости, как качественный цветной снимок военного времени.
Стиль: фотореализм, высокая детализация, 8k качество, естественные цвета."

"Реставрируй и реалистично раскрась эту чёрно-белую фотографию группы советских лётчиц 46-го гвардейского Таманского полка у самолёта По-2.
Сделай высококачественную цветную реставрацию в максимально реалистичном стиле, как современная цветная фотография 1940-х годов.
Требования:
- Форма всех лётчиц — точно цвета оригинальной советской военной одежды (защитный хаки/оливково-зелёный, гимнастёрки, юбки, погоны, ремни, сапоги и детали обмундирования).
- Все награды, ордена и медали на форме тщательно реставрировать и раскрасить в точном соответствии с их историческими цветами.
- Кожа лиц — естественный реалистичный оттенок молодых женщин славянской внешности (светлая, слегка теплая), с натуральными тенями, текстурой кожи, порами и естественным румянцем. Сделай кожу живой и современной по качеству.
- Точно сохрани размер лиц, пропорции, черты лица, причёски, позы, положение рук и все детали одежды каждой женщины — ничего не изменять.
- Ракурс, композиция, направление взглядов и выражение лиц всех лётчиц — полностью сохранить как на оригинале.
- Самолёт По-2 на заднем плане раскрасить в реалистичные цвета военной техники того времени (зелёно-хакитный камуфляж, звёзды, технические детали).
- Фон (трава, небо) раскрасить в естественные реалистичные тона того периода.
- Не добавлять никаких лишних объектов, деталей или людей, которых нет на оригинале.
Фотография должна выглядеть статичной, реалистичной, с естественным дневным освещением и лёгкой глубиной резкости, как качественный цветной снимок военного времени.
Стиль: фотореализм, высокая детализация, 8k качество, естественные цвета."
Следующие фотографии будут без промтов,так как вы поняли смысл инструкции именно к такому типу генерации.
Для этих изображений основное тех.задание почти идентичное,добавляются только детали,если меняется количество людей или появляются дополнительные объекты(самолет).






А это культовое фото времен Великой Отечественной войны.
Котенок с простреленным ухом,на пепелище дома в городе Жиздра.
Оригинальное название фото:
«По дорогам войны. На пепелище…»
Фотограф: Михаил Савин,один из классиков советской военной фотографии собкор ТАСС и фотокор журнала «Огонек».
«В этом небольшом городе Жиздра после боев я никого не нашел в живых, кроме этой пораненной кошки», — вспоминал сам Савин."

Показать полностью
16

Что влияет на цитируемость сайта в ChatGPT, Gemini, Perplexity и других ИИ-ответах

В SEO появилась новая любимая игрушка: LLM SEO, GEO, AEO и прочие красивые аббревиатуры, от которых обычный владелец сайта должен почувствовать, что без срочного внедрения чего-нибудь модного он уже опоздал лет на пять. Раньше все дружно оптимизировались под Google и Яндекс, потом под голосовой поиск, потом под нейросети, а теперь вот под то, чтобы ChatGPT, Gemini или Perplexity случайно не прошли мимо вашего сайта.
Проблема в том, что вокруг этой темы сейчас очень много спекуляций. Особенно в ру-сегменте. Нормальных исследований почти нет: в основном пересказы западных статей, личные ощущения, «мне кажется» и вечное «добавьте FAQ, Schema.org и llms.txt, и будет вам счастье». На практике всё сложнее. Западные исследования уже начали появляться, но даже они пока больше похожи на карту гипотез, чем на официальную инструкцию от тайного совета поисковых роботов.
Я посмотрел, какие факторы чаще всего всплывают в материалах про AI Overviews, ChatGPT, Gemini, Perplexity и другие ИИ-ответы, и собрал их в один список. Сразу дисклеймер: это не «официальные факторы ранжирования». Это набор наблюдений, корреляций и здравого смысла. Причем в теме, которая меняется настолько быстро, что часть выводов через полгода может устареть или поменяться местами по значимости.
Если совсем коротко, то больше всего сейчас похожи на важные факторы: доступность страницы, обычные SEO-позиции, тематическое покрытие, прямой ответ на вопрос пользователя, структура текста, конкретика, источники, доверие к бренду, внешние упоминания и техническая понятность страницы. А вот всякие модные штуки вроде llms.txt пока выглядят скорее как эксперимент, а не как волшебная кнопка.
Если страницу нельзя прочитать, её не процитируют
Звучит банально, но это база. Если страница закрыта от роботов, отдает ошибку, требует авторизацию, грузит весь важный текст через сложный JavaScript или запрещает сниппеты, то ИИ вряд ли внезапно скажет: «О, вот это великий источник, срочно цитируем». ИИ не телепат. Если он не может нормально добраться до страницы, то и использовать её в ответе ему сложно.
Отдельная забавная история — хостинги и CDN, которые предлагают ограничивать ботов ИИ-систем, когда те создают нагрузку. С одной стороны, сервер жалко. С другой — раньше некоторые так же советовали ограничивать поисковых роботов. Потом SEO-специалисты сидели и гадали, почему сайт в индексе выглядит как Шредингеров кот: вроде есть, а вроде нет.
Старое SEO не умерло, оно просто надело худи с надписью AI
Есть распространенное заблуждение: «Ну всё, теперь поисковики умерли, надо оптимизироваться только под ChatGPT». Нет. По исследованиям и наблюдениям видно, что страницы, которые уже хорошо ранжируются в обычном поиске, чаще попадают и в AI-ответы.
То есть классическое SEO никуда не делось. Техническая оптимизация, нормальная структура сайта, интент, качество страниц, внутренняя перелинковка, контентные кластеры — всё это по-прежнему важно. Просто сверху появился новый слой: насколько удобно ИИ взять с вашей страницы понятный фрагмент и вставить его в ответ.
Поэтому «продвижение в ИИ» не заменяет нормальное SEO. Оно скорее добивает тех, кто надеялся, что можно написать унылый текст на 20 000 знаков, пару раз вставить ключ и жить спокойно.
Один текст под один жирный ключ уже не спасает
ИИ часто не ищет ответ одним запросом. Он может взять вопрос пользователя, разбить его на несколько уточняющих подзапросов, собрать информацию из разных источников и потом склеить итоговый ответ. Например, человек спрашивает: «Как выбрать CRM для малого бизнеса?» А ИИ параллельно может искать про цены, интеграции, внедрение, сравнение CRM, отзывы, типичные ошибки, миграцию данных и отраслевые решения.
Поэтому лучше работает не одна гигантская статья в стиле «CRM купить недорого цена», а нормальный тематический кластер. Когда сайт закрывает тему глубоко и с разных сторон, у него больше шансов попасть хотя бы в один из промежуточных поисков, из которых потом собирается AI-ответ.
Проще говоря, если у вас на сайте есть одна страница «ремонт ноутбуков», это одно. А если есть отдельные нормальные материалы про диагностику, замену матрицы, ремонт после залития, чистку, цены, сроки, гарантии и типичные поломки — это уже больше похоже на источник, которому есть что сказать.
ИИ любит прямые ответы, а не SEO-полотенца
Старый добрый SEO-текст, где ответ спрятан где-то между «на сегодняшний день в современном мире» и «наша компания предлагает индивидуальный подход», может работать всё хуже. ИИ удобнее цитировать кусок, где есть конкретный ответ на конкретный вопрос.
Например, фраза «LLMs.txt может помочь ИИ-системам понять важные страницы сайта, но пока нет доказательств, что сам файл сильно повышает цитируемость» — это нормальный самостоятельный фрагмент. Его можно взять и использовать. А если ответ спрятан в текстовом болоте, модель может просто пройти мимо.
Хороший принцип для страниц и статей: сначала короткий ответ, потом подробности. Не три экрана вступления, история вопроса, немного философии и только потом суть, а наоборот. Сначала ответ, потом аргументы, примеры, нюансы и ограничения. Это полезно не только для ИИ, но и для людей. Потому что люди тоже не любят читать пять абзацев ради ответа «да, но с нюансами».
Структура решает
Заголовки, списки, FAQ, определения, сравнения, выводы, блоки «плюсы и минусы», «сроки», «цены», «частые ошибки» — всё это помогает ИИ понять, что именно написано на странице. Не потому что список — магический артефакт из подземелья SEO, а потому что структурированный текст проще разобрать.
Если у вас на странице всё слито в одну простыню, модель должна сама догадываться, где описание услуги, где условия, где ограничения, где цена, где вывод, а где просто маркетинговая вода. Чем меньше ИИ нужно копаться в тексте как в ящике с проводами, тем лучше.
FAQ тоже может быть полезен, но не как волшебная SEO-кнопка, а как способ дать прямые ответы на частые вопросы. Главное, чтобы это был реальный видимый текст на странице, а не набор ключей, спрятанный в коде «для роботов».
Конкретика лучше воды
Фразы вроде «мы предлагаем качественные услуги», «у нас индивидуальный подход» и «наша команда профессионалов» в AI-ответах выглядят примерно как белый шум. Они ничего не объясняют и не дают модели полезного факта.
ИИ гораздо полезнее конкретика: сроки, цены, условия, характеристики, ограничения, даты, сравнения, этапы, гарантии, реальные примеры. «Доставка осуществляется быстро» — ни о чем. А «доставка по Москве занимает 1–2 дня, по регионам — от 3 до 7 дней» — уже нормальный фрагмент, который можно использовать в ответе.
Для коммерческих сайтов это особенно важно. Чем конкретнее описаны услуги, цены, условия, гарантии и ограничения, тем выше шанс, что страница окажется полезной не только человеку, но и ИИ.
Источники и доказательства всё еще нужны
Если статья ссылается на исследования, документы, статистику или хотя бы объясняет, откуда взяты выводы, она выглядит надежнее. Особенно это важно в медицине, финансах, праве, безопасности и других темах, где ошибка может стоить дорого.
Там уже мало написать «наши эксперты считают». Нужно показывать квалификацию, источники, документы, ограничения и нормальную доказательную базу. ИИ тоже не всегда хочет брать ответ из текста уровня «мамой клянусь, всё работает».
Для информационных статей это значит: меньше бездоказательных утверждений, больше проверяемых фактов. Для коммерческих страниц — больше прозрачности: кто оказывает услугу, на каких условиях, сколько стоит, какие есть ограничения, какие документы, какие гарантии.
Каждый важный кусок должен быть понятен сам по себе
Плохой фрагмент: «Это помогает улучшить результат». Что «это»? Какой результат? Кому помогает? Почему?
Хороший фрагмент: «Короткий ответ в начале блока повышает шанс цитирования в AI-ответах, потому что модель может извлечь готовый смысловой фрагмент без дополнительного контекста». Такой кусок можно почти сразу вставить в ответ. Он самодостаточный.
Это вообще хороший тест для любого текста: если вырвать абзац из страницы, он всё еще понятен или превращается в загадку из ЕГЭ? Если превращается в загадку, для ИИ это тоже может быть проблемой.
Брендовые упоминания могут быть важнее обычных ссылок
Вот это интересный момент. В исследованиях всё чаще всплывает, что для AI-видимости важны не только ссылки, но и просто упоминания бренда в интернете. То есть если о компании пишут в обзорах, рейтингах, подборках, статьях, обсуждениях, соцсетях, медиа и профессиональных сообществах — это может помогать ИИ понимать, что бренд вообще существует и с чем он связан.
Получается, что SEO постепенно становится не только про «купить ссылку с донора», но и про нормальное присутствие бренда в интернете. PR, экспертные комментарии, гостевые статьи, каталоги, отзывы, отраслевые подборки — всё это может влиять на то, как ИИ воспринимает компанию.
У себя в Telegram я как раз собираю такие наблюдения по SEO, AI-поиску и техническим экспериментам: https://t.me/seonemagia. В ближайшее время там будут появляться не только разборы, но и небольшие инструменты для SEO-специалистов: генераторы, чекеры и разные штуки для технической оптимизации.
Сайт должен быть понятной сущностью, а не просто набором страниц
Для ИИ и поисковых систем важно понимать, кто вы такие. Компания? Автор? Клиника? Магазин? SaaS-сервис? Эксперт? Медиа? Если бренд встречается только на своем сайте и нигде больше, это слабый сигнал.
А если есть карточки компании, отзывы, страницы авторов, профили, публикации, упоминания на других площадках, документы, кейсы и нормальная структура — это уже лучше. Для клиники это могут быть страницы врачей, лицензии, образование, стаж. Для интернет-магазина — карточки товаров, отзывы, доставка, возврат, гарантии. Для сервиса — документация, кейсы, интеграции, сравнения и понятные описания продукта.
ИИ нужно не просто прочитать страницу. Ему нужно понять, можно ли этому источнику доверять и что это вообще за источник.
Свежесть важна, но менять дату каждый день — не стратегия
Да, свежие материалы часто имеют преимущество, особенно в темах, где всё быстро устаревает: технологии, законы, цены, маркетинг, медицина, инструкции по сервисам. Но свежесть — это не просто поменять дату публикации с 2024 на 2026 и гордо сказать «обновлено».
Нормальное обновление — это когда вы реально добавили новые данные, убрали устаревшее, перепроверили цены, заменили старые скриншоты, обновили инструкции и дописали новые выводы. Свежесть без полезного обновления — слабый сигнал. Актуальность вместе с нормальным содержанием — уже намного лучше.
Важный текст лучше держать в нормальном HTML
Если важная информация спрятана в табах, аккордеонах, подгружается через JavaScript или появляется только после клика, она может хуже использоваться AI-системами. Да, Google давно умеет многое рендерить. Но это не значит, что любая ИИ-система одинаково хорошо достанет всё, что вы спрятали на странице.
Цены, условия, FAQ, характеристики, описания услуг, адреса, данные специалистов — всё важное лучше делать видимым и доступным. Не надо прятать самое ценное в интерфейсных матрешках, а потом удивляться, что его никто не использует.
Schema.org полезна, но не волшебная палочка
Микроразметка помогает поисковикам и ИИ лучше понять, что перед ними: организация, товар, статья, врач, FAQ, хлебные крошки, отзыв, услуга и так далее. Но сама по себе Schema.org не гарантирует попадание в AI-ответы.
Особенно если в JSON-LD написано одно, а на странице для пользователя этого нет. Правильный порядок такой: сначала нормальный видимый текст, потом аккуратная разметка, которая его описывает. А не наоборот.
Ссылки всё еще важны, но не только они
Backlinks и авторитет домена всё еще нужны для обычного SEO. Сильный домен и хорошие ссылки помогают ранжироваться. Но в AI-цитируемости ссылки выглядят не единственным и не всегда главным фактором.
Тематическое покрытие, структура, конкретика, брендовые упоминания и доверие к сущности могут играть не меньшую роль. Проще говоря, просто «накупить ссылок и ждать, что вас полюбит ChatGPT» — так себе план.
LLMs.txt — модная штука, но пока не серебряная пуля
LLMs.txt сейчас обсуждают как потенциальный аналог robots.txt для ИИ-систем. Идея понятная: дать моделям файл с важными страницами сайта, документацией, правилами использования контента и ключевыми ссылками.
Звучит интересно. Возможно, со временем это станет стандартом. Сейчас LLMs.txt уже поддерживают или тестируют многие крупные игроки индустрии, поэтому полностью игнорировать тему я бы не стал. Но если расставлять приоритеты, то llms.txt явно не на первом месте. Сначала техническая доступность, нормальный контент, структура, SEO, бренд и внешние упоминания. А уже потом эксперименты с новыми файлами.
Если хочется быстро попробовать, я сделал простой генератор llms.txt: https://siteupgrade.online/tools/llms-txt-generator/. Это не заменяет SEO и не превращает сайт в любимчика ChatGPT, но как быстрый технический эксперимент — вполне нормальный шаг.
Что делать владельцу сайта или SEO-специалисту
Если коротко, AI-цитируемость — это не отдельная магия, а усиленная версия нормального SEO. Сайт должен быть доступен, хорошо индексироваться, закрывать тему глубоко, давать прямые ответы, содержать факты, быть понятно структурированным и существовать как бренд не только у себя на домене.
Я бы проверял простые вещи: открыты ли важные страницы для индексации, видит ли поисковик важный текст, есть ли на страницах прямые ответы на реальные вопросы пользователей, не спрятана ли суть после трех экранов воды, есть ли конкретика по ценам, срокам, условиям и ограничениям. Также стоит смотреть, есть ли нормальная структура, источники и доказательства там, где они нужны, понятно ли, кто автор или компания, и есть ли упоминания бренда за пределами собственного сайта.
Главный вывод
ИИ не отменил SEO. Он просто сделал более заметной старую проблему: плохой, водянистый, неструктурированный текст становится всё менее полезным. Раньше такой текст хотя бы мог как-то висеть в поиске и собирать хвосты. Теперь, когда ИИ пытается собрать готовый ответ, ему удобнее брать не «SEO-полотно на 20 000 знаков», а нормальный, структурированный, конкретный и понятный источник.
Поэтому задача уже не просто «написать текст под ключи». Задача — стать источником, которому удобно доверять, удобно парсить и удобно цитировать.
А вокруг темы, конечно, еще будет много шума. Кто-то будет продавать «волшебную оптимизацию под ChatGPT», кто-то — ставить llms.txt как амулет от невидимости, кто-то — переименовывать обычное SEO в GEO и добавлять x3 к стоимости. Но если убрать маркетинговый туман, суть пока такая: нормальная техническая база, хороший контент, структура, факты, бренд и внешняя репутация.
Всё скучно, сложно и без магии. Как обычно в SEO.
Показать полностью
1
Ответ на пост «Higgs Audio Studio: локальная озвучка на 100+ языках с клонированием голоса и AI-режиссёром — для подкастов и аудиокниг»1
Сделал форк - так как на 3090 не завелась. Чутка допилил напильником для длинных текстов и внешней LLM в ML Studio.
https://github.com/SaidAuita/HiggsAudio-Studio/
🔌 Совместимость с RTX 3090 / 4090 — изоляция процессов llama.cpp и PyTorch через фоновый демон-процесс (director_daemon.py); устраняет конфликты CUDA-контекстов и падения инференса; выгрузка моделей «на лету» для освобождения VRAM.
🧬 Длинный клон — озвучка сверхдлинных текстов и книг с автоматической разбивкой на фрагменты, пофрагментным авто-обогащением, синтезом частями и бесшовной склейкой с настраиваемой паузой.
🌐 Внешние LLM — глобальная интеграция с LM Studio / Ollama / OpenAI API (External API); перенаправление автоулучшения со всех вкладок на внешнюю модель; настраиваемый системный промпт режиссёра.
🧪 Тест подключения — кнопка быстрой проверки связи с внешним API и интерактивный редактор промптов с выводом подробных кодов ошибок в интерфейс.
💾 Автосохранение настроек GUI — сохранение и автоматическое восстановление всех параметров (моделей, голосов, слайдеров температуры/top-p) между запусками в локальном файле gui_config.json.
💻 Только CPU — переключатель в интерфейсе для полной обработки TTS и LLM на центральном процессоре (без использования видеокарты), что полностью освобождает VRAM.
🌑 Всегда темная тема — принудительное включение темной темы при первой загрузке без светлого мигания.
Только на CPU - работает, но ооооочень не быстро. Учитывая тест на 5950x :)
Показать полностью
Voicebox — локальная голосовая студия, что заменяет ElevenLabs и WisprFlow разом
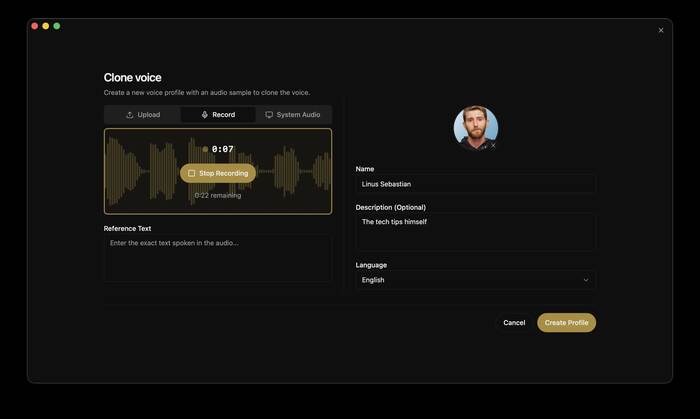
Voicebox — это локальная голосовая студия с открытым исходным кодом, которая в одиночку закрывает то, за что обычно платят сразу двум облачным сервисам. ElevenLabs отвечает за вывод — синтез и клонирование голоса. WisprFlow — за ввод, голосовую диктовку. Voicebox делает обе половины этого цикла и, в отличие от обоих, крутит всё прямо на вашей машине: без аккаунтов, без API-ключей и без единого байта, уходящего в облако.
Автор проекта — Джейми Пайн, тот самый разработчик кросс-платформенного файлового менеджера Spacedrive. Voicebox выложен под лицензией MIT и за считанные недели собрал почти 35 тысяч звёзд на GitHub, влетев в недельный тренд.
Клонирование голоса. Достаточно пары секунд аудио-референса — загрузите файл, запишите с микрофона или захватите системный звук, и приложение создаёт голосовой профиль (на скриншоте выше — как раз это окно). Не хочется возиться — в комплекте 50+ готовых пресет-голосов.
Семь TTS-движков под капотом. Qwen3-TTS, Qwen CustomVoice, LuxTTS, Chatterbox Multilingual, Chatterbox Turbo, HumeAI TADA и Kokoro — каждый со своими сильными сторонами, переключаются на лету. В сумме 23 языка: от английского до арабского, японского, хинди и суахили. Chatterbox Turbo понимает паралингвистические теги вроде [laugh], [sigh], [gasp] — эмоции и звуки прямо в тексте.
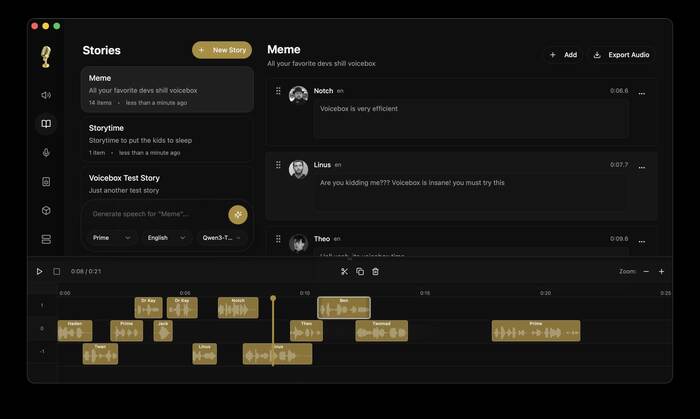
Многодорожечный редактор «историй». Отдельный режим для подкастов, диалогов и аудиокниг: дорожки с разными голосами, перетаскивание, обрезка и склейка клипов прямо на таймлайне (на скриншоте выше).
Голосовой ввод. Глобальный хоткей в любом приложении: зажал, проговорил, отпустил — на macOS текст сам вставляется в активное поле. Транскрипция на Whisper (включая Turbo, примерно в 8 раз быстрее Large). Опционально локальная LLM подчищает «эээ», запинки и оговорки перед вставкой.
Голос для ИИ-агентов. Через встроенный MCP-сервер любой агент — Claude Code, Cursor, Windsurf, Cline — может заговорить с вами голосом, который вы сами склонировали. Один вызов voicebox.speak, и «деплой завершён» вам произносит выбранный голос. Удобно в длинных агентских циклах, когда не хочется пялиться в терминал.
Сверху ещё постобработка звука (8 эффектов на движке pedalboard от Spotify) и генерация без ограничения длины с авто-нарезкой и кроссфейдом. Приложение нативное — собрано на Tauri (Rust), а не Electron, и работает на Windows (CUDA/DirectML), macOS (MLX/Metal) и Linux (включая AMD ROCm и Intel Arc).
🔗 GitHub: jamiepine/voicebox
🌐 Сайт и видео-демо: voicebox.sh
👾 Больше локальных тулз — в канале: НЕЙРО-СОФТ ● Репаки и портативки
Показать полностью
1