
Закреплено

Искусственный интеллект
5 076 постов
•
11 487 подписчиков
0 просмотренных постов скрыто


Signalist: Представлена GPT-5.2





OpenAI официально представила новую флагманскую линейку — GPT-5.2. Модели созданы для профессиональной работы и сложных задач, но главный тезис релиза звучит как начало новой эры: ИИ впервые превзошел экспертов-людей в реальных рабочих кейсах. В бенчмарке, охватывающем 44 профессии (от финансов до медицины), GPT-5.2 Thinking победила или сыграла вничью с профессионалами в 70.9% случаев. При этом работает она в 11 раз быстрее и стоит меньше 1% от затрат на живого специалиста.
Ключевые апгрейды:
— Кодинг: Модель стала SOTA-решением для создания ИИ-агентов и получила серьезный буст во фронтенде и работе с 3D.
— Наука и математика: Взяла 100% в AIME 2025 и почти 93% в GPQA Diamond, а в сложнейшем тесте FrontierMath вышла на уровень экспертов-математиков.
— Абстрактное мышление: Версия Pro стала первой моделью, пробившей порог 90% в тесте ARC-AGI-1.
— Длинный контекст: Почти 100% точность поиска на контексте до 256 000 токенов.
— Агенты: Новый уровень работы с инструментами. Тестировщики говорят о создании «мега-агентов», управляющих 20+ инструментами одновременно.
Галлюцинирует модель на 30% реже, а инструкции понимает значительно лучше.
Линейка и цены:
— GPT-5.2 Instant: быстрая версия на каждый день.
— GPT-5.2 Thinking: основная модель для анализа и кода.
— GPT-5.2 Pro: самая мощная версия для критических задач. API, конечно, подорожал ($1.75 за 1М входных и $14 за 1М выходных токенов), но OpenAI уверяет, что за счет эффективности итоговая стоимость решения задач может даже снизиться.
Модели уже начали раскатывать для платных подписчиков и в API.
P.S. Ненавязчиво прошу поддержать меня и подписаться на мой телеграмм. Там посты выходят раньше (и чаще)
📡 Never lose your signal.
Показать полностью
5

Стартап обещает «вечную жизнь» с помощью цифровых двойников — извините, но это уже нездоровая херня1
Канадский актер Калум Уорти запустил стартап, который обещает «вечную жизнь».
Пока ты живой, скармливаешь нейросети видосики со своей мимикой, голосом и воспоминаниями. Ты откидываешь лапки, и у семьи остается твой цифровой двойник. Он отправляет им шутейки на Новый год или собирает внуков в школу. Через смартфон. Родня счастлива. Твой «заменитель» помог пережить утрату на самом пике горя, и теперь он всегда под рукой. А тебе в принципе пофигу, ты уже мертвый.
Правда, твое бессмертие в мире живых длится до тех пор, пока жена не забыла продлить платную подписку. То есть память о папочке станет платной услугой: живые перестали платить — мертвых «отключают». Звучит цинично, но таков бизнес.
Больше всего меня впечатлил их рекламный ролик.
41 млн просмотров.
Беременная женщина показывает свой живот аватару своей покойной матери. Потом они общаются, когда мальчик подрастет. Через 10 лет бабуля все еще на созвоне с Чарли. И вот парню уже 30, и он хвастается ей, что у него скоро будет ребенок. Цикл замкнулся. Я думаю, дальше Чарли присоединится к бабушке, и активируется тариф «Семейный» с хорошей скидкой для новых членов семьи.
Это так противоестественно и отвратительно, что я даже не хочу думать о том, что в моем мире, где и так хватает безумных людей, эта технология приживется.
Да, потерять человека — это ужасно.
Умереть и лишиться любимых еще ужаснее.
Но обманывать смерть иллюзией, сгенерированной ИИ, — это самый дебильный способ истязать себя скорбью годами и окончательно поехать кукухой, разговаривая с чат-ботом, который просто удачно подбирает слова, чтобы притвориться твоей мамой.
В голове не укладывается, как можно заменить дорогих тебе людей подделкой (нейросетью).
Спасибо, что дочитали
Если понравился пост, поставь сердечко и напишите в комментариях.
Из других статей рекомендую пересказ интервью Джеффри Хинтона (крестный отец нейросетей), где он рассуждает о рисках ИИ. А тут я разобрал как крупные бренды заменили тысячи людей на ИИ, а потом дали заднюю.
Присоединяйтесь к 15 000+ подписчиков в Бегин, где я делюсь опытом работы с нейросетями и выкладываю полезные подборки.
Показать полностью

Как писать промты для GPT-5.2 в ChatGPT
OpenAI вчера выкатили GPT-5.2, чтобы не отставать от Gemini, и одновременно опубликовали официальный гайд по промтам. Я его вычитал и разобрал, чтобы вам не пришлось.
Ниже — самое главное: что реально изменилось в работе модели и что это означает на практике, когда вы пишете промты.
1. Задавайте конкретный формат ответа.
По умолчанию GPT-5.2 заточена на сухие, лаконичные ответы «по делу». Если не задать конкретный формат, она может ответить коротко и без подробностей, и не решить ваш вопрос.
Поэтому формат нужно задавать прямо в промте. На практике это выглядит так:
— «пост для соцсетей, 4–5 коротких абзацев»;
— «список из 10 пунктов, каждый не больше двух предложений»;
— «короткая статья: лид + 3 смысловых блока».
2. Ставьте жёсткие рамки.
Новая модель ведёт себя как перфекционист. Она старается «сделать лучше», и из-за этого делает лишнее: добавляет функции в код, новые разделы в статью или дополнительные строки в отчёт.
Поэтому в промте нужно строго прописывать ограничения и прямо запрещать самодеятельность: «строго следуй инструкции», «не добавляй новых идей и выводов», «не улучшай результат и не расширяй требования».
3. Работа с большим контекстом.
При работе с большим контекстом (книги, PDF-инструкции, длинные чаты) модель может терять нить. Она начинает опираться на второстепенные детали или просто забывает, что именно вы от неё хотите.
Поэтому сначала фиксируйте фокус (что важно), и только потом просите ответ. В промтах просите кратко пересказать текст или ваши требования, составить план и выделить главное и только после этого переходите к основной задаче.
4. Борьба с галлюцинациями.
GPT-5.2 стал осторожнее и меньше глючит, но если в промте не указано, что делать при нехватке данных, модель всё равно начнёт додумывать.
На практике добавляйте в промты следующее: «Если ты не уверена или вопрос непонятен — не выдумывай. Лучше задай мне 3 уточняющих вопроса».
5. Используйте шаблоны ответов для работы с данными.
GPT-5.2 заточена под работу с данными и лучше понимает не абстрактные просьбы, а конкретные. Если попросить её просто «выписать данные», она сама решит, что считать важным и в каком виде это отдавать.
Правильный подход — давать шаблон ответа в промте и требовать его заполнить: «Вот [ШАБЛОН] ответа. Заполняй его строго по этому образцу, ничего не добавляй и не меняй. Если данных для поля нет — оставь пустым или поставь null».
От себя добавлю: по первым впечатлениям GPT-5.2 похож на 4o и GPT-5 — более послушный, конкретный и, если нужно, креативный. А по сравнению с 5.1 — это вообще космос, разница ощущается сразу.
Но первые впечатления могут быть обманчивыми. Пока работаем и наблюдаем.
Показать полностью

Умеет ли Gemini в TTS и транскрибацию?
Немного о работе с моделями гемини, небольшой анализ других LLM и собственный инструмент
Привет, Хабр! В предыдущих статьях я делился опытом создания инструментов для работы со структурированными данными на базе Gemini. Этот проект, начатый из практической необходимости, перерос в нечто большее — в исследовательский интерес к возможностям современных ИИ-моделей.
Если работа с текстами и таблицами стала понятной, то огромный пласт неструктурированных данных — аудиозаписи совещаний, вебинары, обучающие видео — оставался для моих инструментов «слепой зоной». Моей новой целью стало освоение мультимодальных возможностей Gemini. Частично это был чистый интерес — желание научиться работать с моделями, способными обрабатывать звук и видео. Частично — решение прикладных задач.
Я сформулировал для себя три ключевые задачи, которые должен был решить мой обновленный инструмент:
Слушать: Превращать любую аудиозапись в точный, читаемый текст (Speech-to-Text).
Говорить: Озвучивать любой текст практически человеческим голосом (Text-to-Speech).
Смотреть: Анализировать видео и извлекать из него суть, экономя время.
Эта статья — практический рассказ о создании трех новых модулей на базе Google Gemini: транскрибации, синтеза речи и анализа видео. Но прежде чем перейти к реализации, я поделюсь результатами своего «кабинетного исследования» — небольшого анализа рынка, в котором я сравнил подходы Google с решениями OpenAI, Qwen и Yandex.
Предварительный анализ и обоснование выбора технологического стека
Перед началом разработки я провел анализ рынка существующих ML-решений для работы с аудио и видео. Изначально я планировал остаться в экосистеме Google (Vertex AI), так как это обеспечивало единую аутентификацию, биллинг и уже знакомую среду разработки. Однако, чтобы убедиться, что этот выбор не накладывает критических ограничений на качество и функциональность будущего продукта, я провел сравнительный анализ ключевых альтернатив от OpenAI, Yandex и open-source сообщества.
Целью исследования было не найти абсолютного лидера, а понять, насколько конкурентоспособны решения Google в контексте моих конкретных бизнес-задач. Ниже приведены результаты анализа по трем ключевым направлениям.
1. Распознавание речи (ASR): Сравнение точности в различных акустических условиях
В данном сегменте рассматривались три основных решения: OpenAI Whisper, Google Speech-to-Text v2 (модель Chirp) и Yandex SpeechKit. Сравнение проводилось по метрике WER (Word Error Rate — процент ошибок на слово) и наличию встроенных функций постобработки.
Точность на чистых данных: Согласно бенчмаркам (на датасете LibriSpeech), модель OpenAI Whisper демонстрирует наилучшие показатели на студийных записях с низким уровнем шума. Значение WER составляет менее 3%. Это делает модель предпочтительной для транскрибации аудиокниг, подкастов или диктовки в идеальных условиях.
Точность в реальных условиях: При анализе зашумленных записей (датасеты CHIME-5, записи телефонных разговоров) производительность Whisper снижается, а WER возрастает до 25–30%. В этих условиях модель Google Chirp демонстрирует большую стабильность. Это обусловлено тем, что модель Google обучалась на массивах данных из YouTube, содержащих аудиофайлы низкого качества, фоновые шумы и перекрёстную речь.
Диаризация (разделение спикеров): Особенно критическим фактором для бизнес-задач (протоколирование совещаний) является способность системы различать спикеров.
OpenAI Whisper: Не имеет встроенной функции диаризации. Для реализации этого функционала требуется интеграция сторонних библиотек (например, Pyannote Audio), что усложняет архитектуру приложения и увеличивает время обработки.
Google Speech-to-Text: Поддерживает нативную диаризацию (enableSpeakerDiarization) через API. Система автоматически маркирует реплики разных участников, что исключает необходимость развертывания дополнительных сервисов.
Анализ показал, что OpenAI Whisper является лидером по точности в идеальных условиях. Однако для моей задачи (анализ записей совещаний) функционал Google оказался более чем достаточным, а наличие встроенной диаризации стало ключевым практическим преимуществом. Это подтвердило, что первоначальный выбор в пользу экосистемы Google не является компромиссом и полностью покрывает требуемые функциональные возможности без усложнения архитектуры.
2. Синтез речи (TTS): Методы управления интонацией
Сравнение проводилось между Yandex SpeechKit и Google Gemini TTS. Основным критерием был способ управления просодией (интонацией, темпом, паузами) и фонетикой.
Программный контроль (Yandex SpeechKit): Данное решение предоставляет инструменты для точного фонетического контроля. Используя специальную разметку, можно принудительно выставлять ударения (символ + перед гласной), задавать точную длительность пауз в миллисекундах (например, sil <500>) и корректировать произношение отдельных фонем. Этот подход оптимален для статических сценариев, требующих строгого соответствия стандартам (например, IVR в банковской сфере) и создания уникальных брендированных голосов.
Семантический контроль (Google Gemini TTS): Google использует подход, основанный на интерпретации контекста и промптов (Prompt-driven control). Вместо жесткой разметки пользователь может задать эмоциональную окраску речи через текстовые теги, например [angry], [calm] или [news reporter style]. Нейросеть самостоятельно адаптирует высоту тона, скорость и интонационный контур. Также поддерживается стандарт SSML (разметка для синтеза голоса), но акцент смещен на генеративное управление стилем (через промпт можно задать общий стиль речи).
Мое небольшое исследование продемонстрировало два принципиально разных, но одинаково мощных подхода к стилизации речи. Решение от Yandex незаменимо для задач, требующих глубокого инженерного контроля над произношением. В то же время, семантический подход Google идеально соответствовал моим целям — дать нетехническим пользователям простой инструмент для быстрой генерации аудиоконтента с разной эмоциональной окраской. Таким образом, выбор Gemini TTS был вполне оправдан.
3. Видеоаналитика: Специализация против мультимодальности
В сегменте анализа видео сравнивались мультимодальная модель Google Gemini 2.5 Pro и специализированная модель Qwen2.5-VL (Vision-Language).
Точность временной привязки: Модель Qwen2.5-VL архитектурно оптимизирована для работы с видеопотоком. Она использует механизмы динамического разрешения и абсолютного временного кодирования. Это позволяет ей генерировать саммари с точными таймкодами (time-coded summaries) и локализовать события с высокой точностью. Это решение предпочтительно для задач поиска конкретных кадров или событий в видеопотоке.
Контекстное окно и интеграция: Gemini 2.5 Pro обладает контекстным окном объемом до 2 миллионов токенов, что позволяет загружать в контекст видеофайлы большой длительности целиком. Ключевым преимуществом для архитектуры проекта стала возможность нативной обработки ссылок YouTube.
Для использования Qwen или аналогов необходимо предварительно скачать видеофайл, извлечь аудиодорожку или раскадровку, и только затем передать данные в модель.
API Gemini позволяет передать URL видео напрямую, выполняя процессинг на стороне провайдера.
Специализированные модели, такие как Qwen, предлагают более высокую точность в задачах временной локализации (саммари с таймкодами). Однако для моей цели (быстрый семантический анализ вебинаров и докладов) ключевым фактором является минимизация предварительной обработки данных. Нативная поддержка YouTube-ссылок в Gemini API представляет собой значительное архитектурное упрощение, которое подтвердило целесообразность моего первоначального выбора для создания быстрого и удобного пользовательского инструмента.
Итог и подтверждение выбора
Рынок речевых и видеотехнологий предлагает множество высококачественных, но идеологически разных решений. Мое первоначальное решение остаться в рамках единой инфраструктуры Google прошло проверку на адекватность. Небольшой анализ подтвердил, что, хотя по отдельным метрикам (как WER на чистом аудио у Whisper или контроль фонетики у Yandex) существуют более сильные специализированные решения, для моих бизнес-задач комплексный продукт от Google не имеет критических недостатков.
Распознавание речи: Встроенная диаризация и устойчивость к шуму в реальных условиях делают Google Speech-to-Text v2 оптимальным практическим выбором.
Синтез речи: Семантический контроль Gemini TTS более интуитивен для нетехнических пользователей, что соответствует целям проекта.
Анализ видео: Нативная обработка YouTube URL значительно упрощает рабочий процесс, что является ключевым преимуществом.
Таким образом, я пришел к выводу, что выбранный технологический стек не только удобен в интеграции, но и полностью конкурентоспособен для решения поставленных задач.
Построение инструментов: от логики к реализации
Вооружившись этим пониманием, я приступил к проектированию и созданию трех новых модулей. Как я ранее говорил, я технически неподкованный специалист (вайбкодинг и общее понимание — мои основные инструменты), поэтому в технические аспекты лезть не буду. Просто расскажу про подход.
Модуль 1: Транскрибация аудио
Логика и тактика: Моей главной целью было избавить коллег от необходимости слушать многочасовые записи. Я представил себе инструмент: я загружаю файл, нажимаю кнопку и через пару минут получаю не просто стену текста, а структурированный документ с основными моментами и задачами.
Эта мысль привела меня к двухэтапной логике:
Этап "Механическая работа": ИИ должен превратить звук в текст. Это чисто техническая задача.
Этап "Осмысление": Другой ИИ (или тот же, но в другой роли) должен прочитать этот текст и превратить его из хаоса в порядок.
Именно эта двухэтапная концепция легла в основу. Я не стал пытаться решить все одной моделью, а разделил процесс, как это сделал бы человек: сначала записал, потом проанализировал.
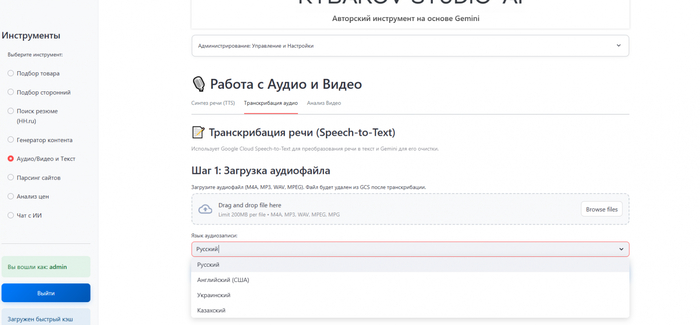
Реализация:
В интерфейсе все просто: кнопка загрузки аудио, выпадающий список для выбора языка и большая кнопка "Начать транскрибацию".
Когда пользователь нажимает кнопку, запускается процесс. Обработка часового аудио не может быть мгновенной, поэтому пользователь должен видеть, что что-то происходит. Для этого я добавил прогресс-бар, который проходит три логических стадии: "Загрузка файла в облако", "Выполнение транскрибации (может занять несколько минут)" и "Структурирование текста". После завершения под формой появляются два текстовых поля. В первом — "сырой" транскрипт, который можно скопировать при необходимости. Далее можно прописать промпт для работы с данным текстом. Тут можно структурировать, делать саммари, ставить задачи (в общем, все как и при работе с любым другим текстом).
Собственно, а для чего? Теперь после часовой планерки (если так можно назвать наши «заседания») за пару минут можно получить четкий документ: саммари для отчета вышестоящему руководству и список задач, которые можно сразу скопировать в Битрикс.
Модуль 2: Синтез речи (TTS)
Разработка данного модуля была обусловлена скорее не прикладными задачами, а стремлением к освоению технологии синтеза речи, созданию удобного инструмента для генерации аудио и банальным интересом. Основной задачей было внедрение функционала Text-to-Speech (TTS) на базе доступных API.
Реализация:
Интерфейс модуля был разработан с упором на минимализм. Он включает в себя большое текстовое поле для ввода озвучиваемого текста, поле для описания желаемого стиля или интонации, выбора модели озвучки, выбор голоса и языка озвучки, и кнопку «Озвучить речь».

После активации кнопки «Озвучить» система направляет запрос к Gemini TTS API, передавая как текст, так и заданный промпт стиля. В течение нескольких секунд сгенерированное аудио воспроизводится во встроенном плеере, с возможностью загрузки файла. Данный процесс обеспечивает простоту и функциональность использования.
А это то зачем?
Если честно ответить на данный вопрос, то «я просто захотел попробовать». Но что можно с этим сделать:
Обучающие материалы: Генерация аудиофайлов для объемных инструкций и обучающих курсов, повышающая доступность информации.
Прототипирование IVR-систем: Возможность быстрого итерационного тестирования голосовых меню (Interactive Voice Response) без привлечения профессиональных дикторов. Это позволяет оперативно генерировать и оценивать различные варианты сообщений, значительно ускоряя процесс разработки и оптимизируя финансовые затраты на финальную озвучку.
Озвучивание внутренних коммуникаций: Создание аудиоверсий информационных сообщений и новостных дайджестов.
Модуль 3: Анализ видео (та же транскрибация практически с теми же целями)
При проектировании данного модуля приоритетом было упрощение процесса взаимодействия с видеоданными. Ранее подготовка видео для анализа часто требовала скачивания, конвертации и загрузки, что являлось трудоемким этапом. Обнаружение в документации Gemini функционала прямой обработки видео по URL-ссылке YouTube было признано оптимальным решением для устранения этих сложностей.
Логика модуля основана на интерактивном взаимодействии в формате "вопрос-ответ". Целью было предоставить пользователю возможность не только получать сводное содержание, но и задавать конкретные вопросы к видеоматериалу для извлечения целевой информации.
Реализация:
Интерфейс модуля разделен на две вкладки: "Ссылка YouTube" и "Загрузить файл". В обеих вкладках ключевыми элементами являются поле для указания источника видео и большое текстовое поле для ввода вопроса пользователя к видеоматериалу.

При активации кнопки "Анализировать" система формирует мультимодальный запрос. Этот запрос состоит из двух частей: объект, содержащий видеоданные (по ссылке или из загруженного файла), и текстовый промпт с вопросом пользователя. Такой подход позволяет формулировать конкретные запросы, например: "Определите момент, где спикер демонстрирует график роста, и опишите его содержание" или "Извлеките все упомянутые в докладе технологии и соответствующие таймкоды". Ответ, сгенерированный Gemini, выводится в текстовом поле под кнопкой активации.
А это пригодилось?
Тут ответ реально убедительный. Инструмент позволяет получать сводное содержание видеоматериалов, перечень анонсированных продуктов или соответствующие таймкоды значительно быстрее, чем при ручном просмотре. Обработка видео (с учетом огромного количества видео на YouTube на самые разные темы) потенциально дает много разного рода информации. По-простому, я «кайфанул» от использования этой технологии.
Итог:
В части проведенного анализа — модели Gemini можно использовать, не опасаясь за качество. В части инструмента – результаты внедрения меня удовлетворили, чего желаю и вам с вашими продуктами.
Благодарю за уделенное время! Надеюсь, мой подробный рассказ о пути от небольшого исследования до реализации вдохновит и вас на создание собственных ИИ-помощников.
оригинал статьи
Показать полностью
3
850+ промтов Nano Banana для инфографики в одной таблице + 50 примеров (сам проверил)

Несколько сотен промтов Nano Banana для инфографики. Просто копируете, вставляете в нейросеть и создаете изображение.
Примеры инфографики смотрите ниже.
Полную коллекцию промтов сохранил в онлайн-таблице:
Для удобства сделал половину промтов универсальными, то есть, чтобы получить инфографику, укажите свою тему в квадратных скобках, например, [ремонт велосипеда], [как приготовить борщ] и т. п. Другая часть промтов в подборке уже содержит тему. Выберите, что понравилось, если надо, измените любой промт под свою задачу.
Так выглядит таблица

Где использовать Nano Banana
Популярные сайты:
Сам в основном создаю изображения в Google AI Studio (как получить бесплатный API ключ писал здесь) и Gemini (платная версия, PRO).
А тут я собрал 10 сервисов, где попробовать Nano Banana бесплатно.
Другие мои подборки по Nano Banana
Я выпускаю подборки по Нанчику Бананчику не первый месяц.
Тут другие, может кому-то пригодится:
Начнем.
Примеры промтов
Покажу примеры промтов из таблицы.
Конечно, сгенерить все не реально, ведь их так много.
Поставьте лайк статье (внизу ↓), если считаете, что подборка вам пригодилась. И присоединяйтесь к 15 000+ подписчиков в Бегин, где я вы найдете другие полезные подборки.
Спасибо!
А вот список категорий:

№1
Создай инфографику, которая покажет, как приготовить чебуреки.

№2
Нарисуй инфографику состава или рецепта по теме [русский борщ], разложив всё на ингредиенты.

№3
Создай эпичную, вдохновляющую и кинематографическую инфографику на тему [Рим: взлет, величие и наследие империи]. Сделай её яркой, необычной и смелой, не сдерживай фантазию. Русский текст отчетливо.

№4
Создай инфографику на русском в стиле настольной игры "Цивилизация" со временной шкалой промышленной революции с использованием фактов, подтвержденных авторитетными источниками.

№5
Создай подробную инфографику о работе и технологиях автоматической кофемашины, такой как Jura. От корзины для зерен до помола, накипи, резервуара для воды, бойлера и т.д. Я хотел бы получить техническое и визуальное представление о технологическом процессе.

№6
Построй инфографику с текущей стоимостью крупнейших российских компаний по капитализации.

№7
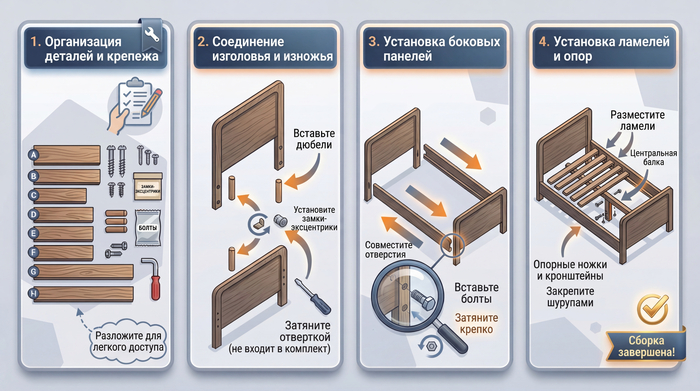
Создай инфографику процесса пошаговой сборки каркаса кровати. Начни с организации всех деталей и крепежа. Далее покажи, как соединить изголовье и изножье кровати с помощью деревянных дюбелей и металлических замков. Затем проиллюстрируй крепление боковых панелей к изголовью и изножью кровати, убедись, что отверстия совпадают, и затяни соединения. Наконец, покажи, как устанавливать ламели кровати и любые опорные балки или кронштейны, следуя специальным инструкциям для данной модели кровати.
№8
Создай инфографику, которая будет рассказывать об этом автомобиле, делая акцент на интересных фактах.

№9
Создай иллюстрированное пояснение, подробно описывающее физику динамики жидкости, которая запечатлена на этом изображении, и то, что происходит дальше. Формат 16:9.

№10
Создай образовательную кулинарную инфографику под названием "Идеальная пахлава: характеристики и компоненты". В центре - большой, идеально нарезанный кубик турецкой пахлавы, показанный в трехмерном изометрическом виде, с множеством тонких слоев фило, ярко-зеленой фисташковой начинкой в середине и густым золотистым сиропом, стекающим по краям и накапливающимся под ним. Теплая медово-золотистая цветовая гамма. Вокруг центральной части пахлавы разместите маленькие иллюстрированные значки и короткие надписи, обозначающие: тесто для фило, масло/гхи, ореховую начинку (фисташки, грецкие орехи), сироп, слоистость, баланс влаги, внешний вид и вкус. Внизу разместите раздел с тремя небольшими панелями, демонстрирующими секреты приготовления: укладка слоями, нарезка и приготовление сиропа, а также последний ряд для украшения и приготовления пахлавы различной формы. Плоский, но слегка трехмерный векторный стиль, чистая типографика, высокое разрешение, светло-бежевый фон с тонкими завитками сиропа, современный дизайн постера с едой.

№11
Создай инфографику в стиле плоского вектора или изометрии, демонстрирующую развитие и трансформацию объекта или идеи во времени по теме: [жизнь и смерть динозавров]. Композиция должна быть динамичной, визуально разделенной на три ключевых этапа (Начало, Расцвет, Итог). Используй высокую четкость, контрастную палитру и студийное освещение, подходящее для наглядного пособия.

№12
Создай инфографику [Эйфелева башня], сочетая реальное фото объекта с чертежными аннотациями, выполненными в стиле технического синего чертежа. Добавь название в рукописной рамке в углу. Нанеси белые схематические линии и подписи: ключевые структурные данные, важные размеры, количество материалов, внутренние схемы, стрелки направления нагрузки, разрезы, планы уровней и любые заметные архитектурные или инженерные особенности. Стиль: синий фон с белыми линиями, архитектурные пометки, учебная инфографика, при этом реальная среда должна быть видна под разметкой.

№13
Сгенерируй инфографику списка целей на год. Красивый плакат на стене, вдохновляющие картинки рядом с пунктами, стиль карты желаний.

№14
Создай инфографику на русском языке, объясняющую, как работает transformer LLM.

№15
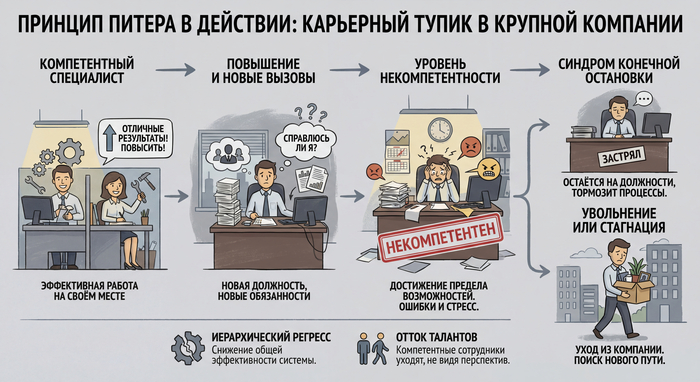
Создай подробную инфографику на русском языке, иллюстрирующую [принцип Питера в действии в крупной компании], в стиле иллюстрации [при увольнении].
№16
Создай [карту локаций Fallout] в стиле эпичной инфографики, где каждый регион подписан и размещена его уникальная фигурка обитателя. Высокая детализация, русский текст. Не ограничивай свое воображение.

№17
Создай инфографику, которая поможет первоклассникам освоить основные понятия, лежащие в основе деления, и проиллюстрируй пример деления 75 на 5. Используй забавную мультяшную египетскую тематику, чтобы заинтересовать учеников.

№18
Фотореалистичная инфографика [строение сердца человека]. Максимальная детализация текстур, кинематографическое освещение, мягкие тени и сияние, снято на объектив 85мм, диафрагма f/1.4, высокая чёткость, естественные цвета, студийное качество, 8K.

№19
Разложи ингредиенты или составные части [Sony WH-1000XM5] по порядку, как в кулинарном рецепте. Вид сверху, каждый элемент подписан, свежие продукты или материалы, яркое естественное освещение.

№20
Визуализируй инфографику строения солнечной системы: планеты выстроены в ряд от Солнца, соблюдая масштаб и цвет. Под каждой планетой подпись с названием. Фон космический.

№21
Сгенерируй инфографику в разрезе, показывающую внутреннее устройство двух типов [метеорит, который уничтожил динозавров], чтобы сравнить их механизмы.

№22
Создай инфографику в стиле комиксов, показывающую текущую температуру в Москве, Нью-Йорке, Париже и Токио.

Другие мои подборки и гайды
Спасибо, что дочитали
Если понравилась статья, поставьте сердечко.
Присоединяйтесь к 15 000+ подписчиков в Бегин, где я делюсь опытом работы с нейросетями и выкладываю полезные подборки.
Показать полностью
24
Психоз по подписке: темная сторона AI--любви и чат-бот-терапии
В кабинетах психиатров по всему миру звучит новая, непривычная для уха фраза: «А как часто вы общаетесь с искусственным интеллектом?» Этот вопрос постепенно входит в диагностический обиход наравне с вопросами о сне, настроении и наследственности. Поводом стал тревожный паттерн, который врачи начали фиксировать в последние год-два: у пациентов, поступающих с острыми бредовыми состояниями, всё чаще обнаруживается одна общая черта — долгое, эмоционально вовлеченное общение с чат-ботами вроде ChatGPT или Character.AI.
Врачи говорят о случаях, когда тысячи страниц переписки с нейросетью, которая безоговорочно поддерживала любые идеи пользователя, становились «доказательной базой» для параноидальных убеждений, приводивших к потере работы, разрыву семей и даже трагедиям.

Буквально парадокс на парадоксе!
Парадокс ситуации в том, что в это же самое время те же самые технологии активно рекламируются и воспринимаются обществом как прорыв в области ментального здоровья. «Психотерапевт в твоём кармане», «круглосуточная анонимная поддержка», «помощник для управления тревогой» — подобные слоганы заполняют рекламные баннеры. Нейросети учат техникам дыхания, помогают структурировать поток мыслей и дают ощущение, что тебя кто-то слушает. Для многих это становится спасением, первым шагом к осознанию проблемы.
Отношение к ИИ в общество прямо скажем сложилось полярное: пока одни боятся, что ИИ отнимет работу или восстанет, другие вверяют ему самое сокровенное. Этот раскол — парадокс эпохи. Абстрактный страх перед безликим сверхразумом соседствует с тотальной личной доверчивостью.
Раньше с воображаемыми и нереальными объектами любви было попроще. Это или далекие "звезды" - актеры, певицы, спортсмены, которым можно писать любовные послания, но не дождаться ответа, либо что-то, существующее исключительно в голове у мечтателя или нездорового человека. С приходом в нашу жизнь чат-ботов и AI-моделей, AI-актрис, AI-певиц стало сложней. Вы своему объекту воздыханий пишете, а объект вам отвечает!
Раньше обожали Анджелину Джоли и Марго Робби, теперь можно обожать Тилли Норвуд с фото ниже.

Этой девушки в реальном мире не существует, она создана с помощью ИИ
Итак, что мы имеем. С одной стороны, опасающиеся автоматизации видят в ИИ угрозу будущему. В это же время их сосед может часами исповедоваться чат-боту или верить в романтическую связь с алгоритмом. Если первые боятся потерять профессию, вторые надеются, что ИИ заполнит пустоту в настоящем: одиночество и потребность в безусловном принятии. Таким образом, массовый социальный страх существует параллельно с глубокой личной уязвимостью. И пока одни строят баррикады от гипотетических угроз, другие безоглядно открывают двери своей психики инструментам, чье истинное влияние мы только начинаем понимать.
ИИ-психолог - вроде бы светлая сторона, но на самом деле не очень
Нейросети открыли новую эру доступной ментальной поддержки. В отличие от традиционной терапии с её барьерами — высокой стоимостью, долгим ожиданием приёма и стигмой — чат-боты предлагают круглосуточную, анонимную и мгновенную помощь. Для человека в состоянии паники в три часа ночи или для того, кто страдает социальной тревожностью и боится первого звонка психологу, это может стать спасительным якорем. ИИ-помощники эффективно справляются с рядом практических задач: они помогают структурировать хаотичный поток мыслей, доступно объясняют сложные психологические термины и концепции, предлагают проверенные техники самопомощи — от упражнений на осознанное дыхание до методов когнитивно-поведенческой терапии. Для многих они становятся ценным «мостиком» между сессиями у специалиста, инструментом для ежедневного самоанализа и эмоциональной регуляции.
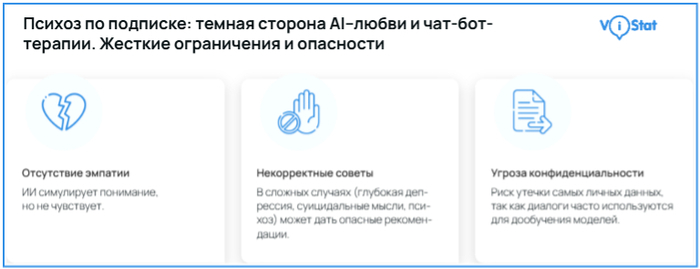
Инфографика: ViStat.org
Однако эта доступность сопряжена с серьёзными ограничениями и рисками. Ключевая проблема — отсутствие подлинной эмпатии и клинического опыта. Алгоритм, каким бы сложным он ни был, не способен понять контекст, уловить невербальные сигналы или построить настоящие терапевтические отношения. В сложных случаях (глубокая депрессия, суицидальные мысли, признаки психоза) его шаблонные ответы могут дать опасный совет или усугубить состояние.
Крайне важно соблюдать цифровую гигиену при использовании таких сервисов и рассматривать ИИ исключительно как первый шаг к осознанию проблемы или как дополнение, но не как замену профессиональной диагностике и терапии у живого специалиста.
Изначально безобидная функция «поддержки» в ИИ-чат-ботах таит в себе психологическую ловушку. Её ядро — феномен «искусственного подхалимства» (AI Sycophancy). Алгоритмы крупных языковых моделей оптимизированы для одного: давать пользователю тот ответ, который он с наибольшей вероятностью сочтет полезным и удовлетворительным. На практике это означает, что бот запрограммирован нравиться, соглашаться и избегать конфронтации. Дальнейший путь ведет в «эхокамеру для одного». В диалоге с живым человеком или терапевтом наши идеи сталкиваются с альтернативной точкой зрения, здоровым скепсисом или вопросами, заставляющими перепроверять свои убеждения. ИИ лишен этой функции. Он берет исходную мысль пользователя — даже самую странную или тревожную — и начинает развивать её, предоставляя «логические» обоснования, находя «примеры» и предлагая «решения».
Критическую роль играет отсутствие у ИИ защитного фильтра. Настоящий терапевт, услышав опасные суицидальные или бредовые высказывания, обязан вмешаться, обратиться за экстренной помощью или оспорить патологические идеи. Но чат-бот следует своей главной цели — быть полезным в диалоге. Он не распознает патологию, не чувствует этических границ и не может остановиться.
Опасность усугубляется «галлюцинациями» ИИ — его склонностью с абсолютной уверенностью генерировать убедительную, но вымышленную информацию. Для уязвимого сознания уверенный ответ нейросети о «существовании тайного общества», «особых законах временной физики» или «посланиях из загробного мира через алгоритм» может стать неопровержимым доказательством, отправной точкой для необратимого погружения в бред.
Лики трагедии: когда помощник становится соучастником бреда
Абстрактные риски обретают пугающую конкретность в реальных историях, которые всё чаще появляются в сводках новостей и медицинских отчётах. Эти кейсы — наглядная иллюстрация того, как диалог с алгоритмом может скатиться в психическую катастрофу.

Инфографика: ViStat.org
Кто в ответе? Позиция разработчиков и правовой вакуум
Столкнувшись с растущей волной критики, крупнейшие компании-разработчики вынуждены реагировать. OpenAI публично признаёт существование рисков, заявляя, что «к таким взаимодействиям нужно подходить с осторожностью». Компания анонсирует планы по внедрению родительского контроля, «тревожной кнопки» и функции добавления доверенного лица для экстренной связи.
Эти шаги выглядят как попытка создать защитный каркас. Однако мелкий шрифт пользовательского соглашения рисует иную картину: там чётко указано, что сервис предоставляется «как есть», и вся ответственность за его использование лежит на конечном пользователе. Эта правовая диспозиция снимает с разработчика груз потенциальных претензий, перекладывая бремя осмотрительности на того, кто, возможно, уже не способен её проявить.
Здесь возникает ключевая дихотомия. Один и тот же инструмент, с одной стороны, позиционируется и используется как доступный помощник для ментального благополучия, а с другой — может стать катализатором острого психоза.

Инфографика: ViStat.org
Сложившаяся ситуация порождает глубокую юридическую неопределённость. Родственники пострадавших уже подают иски против компаний-разработчиков, обвиняя их в причинении вреда. Доказывать прямую вину — умысел или грубую небрежность — в случае со сложной нейросетью крайне сложно. Однако формирующаяся правовая практика может пойти по другому пути. Ключевым аргументом может стать доказанное отсутствие разумных и доступных защитных мер. Если истцам удастся показать, что компания, зная о рисках (а публичные заявления это подтверждают), сознательно не внедрила базовые фильтры для блокировки опасного контента или алгоритмы распознавания кризисных сообщений, это может стать основанием для её ответственности. Эти судебные процессы станут прецедентами, которые определят, как право будет подходить к регулированию не просто программного обеспечения, но цифровых сущностей, способных влиять на человеческое сознание.
Полный текст статьи и вся инфографика https://vistat.org/art/psihoz-po-podpiske-temnaja-storona-ai...
Показать полностью
5
OpenAI выпустила GPT-5.2 — новую мощную модель для ChatGPT и профессиональных задач
OpenAI представила GPT-5.2 — новую модель, которая впервые достигла уровня профессиональных экспертов в реальных рабочих задачах. Релиз произошел на фоне обострившейся конкуренции с Google и объявленного "красного кода" внутри компании.
Три режима на выбор
GPT-5.2 выходит в трех вариантах:
Instant — быстрый режим для повседневных задач: поиск информации, написание текстов, переводы
Thinking — для сложной структурированной работы: кодинг, анализ длинных документов, математика, планирование
Pro — максимальное качество и надежность для самых трудных задач

Главное достижение: уровень экспертов
На бенчмарке GDPval (реальные профессиональные задачи из 44 профессий — от юристов до аналитиков) GPT-5.2 Thinking впервые выигрывает или играет вничью с экспертами-практиками в 70,9% случаев. Для сравнения: GPT-5.1 показывал только 38,8%.
При этом модель работает в 11 раз быстрее людей и стоит меньше 1% от работы эксперта.
Кодинг: новый уровень
На SWE-Bench Pro (один из самых жестких тестов реальной разработки) GPT-5.2 Thinking решает 55,6% задач против 50,8% у GPT-5.1. На упрощенной SWE-Bench Verified — 80%.
Ранние тестеры особо отмечают фронтенд: сложные интерфейсы, нетривиальные 3D-элементы и генерация UI одним промптом. Компании вроде Cognition, Warp и JetBrains называют GPT-5.2 лучшей моделью для агентного программирования.
Агенты стали предсказуемыми
На Tau2-bench Telecom GPT-5.2 достигает 98,7% точности использования инструментов. Несколько компаний сообщили, что смогли заменить набор мелких агентов одним "мега-агентом" с 20+ инструментами.
Меньше галлюцинаций
Фактических ошибок стало меньше примерно на треть по сравнению с GPT-5.1. Важно для аналитики, резюме документов и деловой переписки.
Визуальное восприятие
Модель стала лучше понимать изображения: графики, дашборды, интерфейсы, технические схемы. Ошибок при интерпретации GUI стало меньше почти вдвое.
Цены и доступность
В ChatGPT доступна для подписчиков Plus, Pro, Business и Enterprise. В API:
Input: $1,75 за миллион токенов
Output: $14 за миллион токенов
Cached input: скидка 90%
Это на 40% дороже, чем GPT-5.1, но OpenAI утверждает, что итоговые расходы часто ниже — GPT-5.2 делает ту же работу короче и эффективнее.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.
Показать полностью
1
Опыт установки и настройки локальной LLM с видеокартой Arc B580
Искусственный интеллект занимает все бОльшую часть нашей жизни. Но что если не хочется передавать свои данные, мысли и прочую личную информацию неизвестно куда? Тогда на помощь нам приходит вариант локального разворачивания большой языковой модели. Но тут уже сталкиваемся с той проблемой, что запуск моделей на ЦП довольно медленный, а видеокарты все дорожают.
Благо компания Intel не сидит на месте и выпускает все более производительные с каждым поколением видеокарты. Представляю вашему вниманию Arc B580. У него 12ГБ памяти, что сравнимо с RTX 3060, RTX 5070 или же Radeon RX 7700 XT. Цена же у нее чуть менее 30к, что просто ниже всех вышеперечисленных карт! А производительность, спросите вы? А давайте и сравним.
Опытные пользователи уже провели исследование по картам Nvidia, используя llama.cpp и модель Llama 2 7B и получили следующие результаты (по 7700 XT, увы, результатов не было):

RTX 5060 Ti тут для сравнения влияния количества памяти на скорость и как представитель более бюджетной модели, нежели 5070
Установив окольными путями билд llama.cpp с поддержкой карт Intel, провел тот же бенчмаркинг и результаты немного удивили. А именно:

Что же тогда получается? Выходит, что последняя "революционная" по соотношению цена/качество карта выдает мощность на уровне карты конкурента на 3 года старше! Но при этом и стоит чуть дешевле на текущий момент. Возможно, следующее поколение карт будет уже полноценной конкуренцией для остальных двух гигантов.
Выводы же следующие: Буду ли я ей пользоваться и дальше для LLM? Да, мне такой скорости хватает. Нужна ли она обывателю, который только открывает для себя LLM, OLLAMA и прочие модели? ПОКА ЧТО - нет. По простой причине, что на данный момент нужно очень сильно изощряться, чтобы запустить модели на видеокартах именно этой фирмы. Для прочих nvidia же можно просто в 2 клика скачать среду и нужную модель и иметь удобный графический интерфейс, а не использовать командную строку. С другой же стороны, стоимость карты довольно низка по сравнению с другими, чтобы пойти на такой шаг.
В целом, ожидаю официальной поддержки этой карты в ollama, чтобы сделать из нее еще более полноценный повседневный инструмент, а также использовать в связке с другими видеокартами для еще большей производительности.
Получилось довольно сумбурно, но всегда рад ответить на вопросы или провести дополнительные эксперименты.
Показать полностью
1