
Закреплено

Искусственный интеллект
5 075 постов
•
11 487 подписчиков
0 просмотренных постов скрыто


ИИ-реклама нового поколения
Вот, кажется, выдумываешь что-то специально фантасмагоричное и нереалистичное, сознательно преувеличиваешь действительность и думаешь: ничего такого в жизни точно не будет. А потом приходит новость, что в результате проведённого xAI Хакатона победил проект, который создаёт с помощью ИИ видеорекламу прямо в фильме или сериале, делая её частью сцены, где персонажи рекламируют нужный продукт, радостно держа его в руках или делают вид, что используют его. А затем сюжет просто продолжается, как будто ничего не случилось.
Помню, как при просмотре 4 сезона "Настоящего детектива" (самый худший из всех) помимо многочисленных недостатков самого серила какие-то гении русской озвучки решили сделать так, что персонажи иногда, вместо реальных диалогов из оригинала советуют друг другу, какой доставкой лучше воспользоваться, так ещё по быстрому описывают её преимущества, как будто это такой дружеский совет. А им в ответ: "Да, спасибо, именно так и сделаю в следующий раз". Первый раз, когда это произошло, я думал, что сошёл с ума и мне показалось, а потом это просто стало раздражать и о, даже минимальном, погружении можно было забыть.
Я надеюсь они одумаются и после первого же использования и реакции пользователей забудут об этой идеи.
Я сейчас пересмотрел их видео, и у меня закралась мысль, что они сами относятся к своей идеи с юмором. Вначале быстрым монтажом нам пытаются донести мысль, что классическая реклама - это отстой, и для этого показывают как бы ситуацию, когда человек хочет посмотреть видео о том, как сделать сердечно-легочную реанимацию, но перед этим ему показывают рекламу на 15 секунд. Ну вы поняли, поняли же? Человек умирает, каждая секунда на счету, но, извини, рекламку то нужно посмотреть.
Но они же должны осознавать, что если их вид рекламы добавят не только в фильмы и сериалы, а ещё и в YouTube, то вместо "плохой старой" рекламы человек, которому нужно узнать, как быстро помочь нуждающемуся, увидит что-то типа:
"... в случае, если он так и не приходит в сознание, нужно как можно быстрее и без промедления начать..."
*и тут автор видео встаёт, как и человек, на котором он показывал, что нужно делать, и оба поочерёдно говорят*
А знаете, в жизни всегда нужно найти время на паузу и перерыв.
В ту самую минуту, когда дел становится слишком много, а мысли спешат быстрее вас, просто отодвиньте всё в сторону.
Налейте себе чашку кофе - тёплого, крепкого, собранного из зёрен, которые знают цену хорошему мгновению.
Почувствуйте, как возвращается ясность, как будто мир вдруг сбавил скорость ради вашего глотка.
Сделайте вдох.
Сделайте глоток.
Верните себе своё время.
И пусть весь мир подождёт."
Показать полностью

Как я сравнил нейросеть в MAX и Nano Banana
В мессенджере MAX оказывается, есть встроенная нейросеть, которая умеет генерировать картинки. Решил вот поэкспериментировать с генерацией изображений в разных нейросетях. В качестве исходника использовал одну и ту же фотографию и давал одинаковые задания. Сравнивал нейросеть встроенную в мессенджер MAX, и нейросеть nano banana в телеграм-боте. Было очень забавно — зацените сами.
Загрузил обычную фотографию

🔹 Задание №1
«Помести на эту фотографию персонажей из мультфильма "Зверополис"»
MAX выдал довольно неожиданное творческое прочтение задачи — результат получился специфический, в любом случае интересный 🤣

Nano banana, наоборот, обработал фото аккуратнее и ближе к заданной стилистике.

🔹 Задание №2
«Помести на эту картинку персонажей из советских мультфильмов: "Ну, погоди!" и "Простоквашино"»
Тут я предположил, что российская нейросеть должна уверенно разбираться в отечественной мультипликации!
MAX на этот раз удивил ещё сильнее — интерпретация получилась довольно свободная 🤣

А вот nano banana смог выдать заметно более узнаваемых персонажей.

🔹 Задание №3
«Помести на эту картинку шаолиньских животных ушу: тигра, дракона, змею, журавля, леопарда»
Тут результат оказался похожим на первую попытку: MAX сгенерировал весьма своеобразные варианты 😄

а nano banana.

Выводы делать не буду — всё и так ясно. Просто делюсь опытом. Интересно наблюдать, насколько по-разному разные нейросети интерпретируют одни и те же задачи.😄
Кто хочет поэкспериментиовать, можете попробовать Nana Banana в Телеграмм. Ну а как попробовать через MAX, все и так знают 🤣
Показать полностью
7

Вопрос
Это фотография или эту картинку сгенерировал ИИ? Посмотрите внимательно. Я просто не понимаю.

Показать полностью
1



Модель адаптивного Роя в задаче Консенсуса плотности
Как рой агентов находит истину без главного? 2500 простых программных единиц достигают 100% консенсуса, используя только локальные сплетни!
Вы когда-нибудь задумывались, как стая птиц или муравьиная колония принимают коллективные решения без единого лидера?
В этом видео мы погрузимся в мир распределенных систем и смоделируем, как рой агентов, видящих только своих ближайших соседей, может решить задачу консенсуса. Мы откажемся от градиентных спусков и вместо этого применим принципы, вдохновленные нейрофизиологией — Обучение Хебба.
Вы этом выпуске:
Механика "Роя": Как бинарные агенты (Черный/Белый) принимают решения, основываясь на взвешенном мнении соседей.
Самообучение: Увидите, как агенты динамически меняют "доверие" (веса) к другим, усиливая связи с теми, кто прав, и игнорируя "шум".
Фазовый переход: Наблюдайте в реальном времени, как хаос (51% консенсуса) превращается в абсолютный порядок (100%) через лавинообразный процесс.
Устойчивость: Почему децентрализованные системы самоисцеляются и как они справляются с "дефектными" агентами, чего не всегда удается добиться в централизованных моделях.
Здесь не только теория — но и запуск симуляции на сетке 50x50, где мы проследим хронологию победы коллективного разума. Если вам интересно, как простые локальные правила порождают сложное, адаптивное и устойчивое поведение - смотрите видео.
Код модели можно посмотреть здесь
В том же каталоге текстовая затравка (spec.txt) для генерации кода анимации и сам сгенерированный код анимации.
Показать полностью

Активируем ChatGPT GO на 12 месяцев бесплатно (ну почти бесплатно)!
ВНИМАНИЕ!
IP Индии нужен только один раз для оформления пробной версии на 12 месяцев! После получения подписки, он больше не нужен!
Закончилась у меня подписка на ChatGPT Plus и я озаботился продлением и тут выясняется, что для наших индийских друзей ChatGPT выкатил новый тариф ChatGPT Go. Мало того, даёт возможность поюзать его бесплатно на год.
Напоминаю - в РФ ChatGPT работает только через обход!
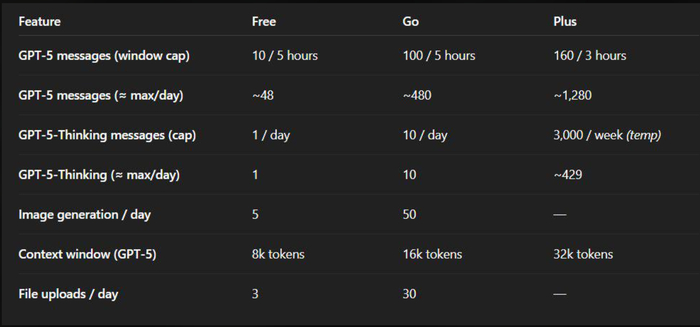
Сравнение тарифов
Начал изучать вопрос и представляю вам способ получения годовой подписки ChatGPT Go, практически бесплатно.
Что нам понадобится?
1. IP Индии.
2. Зарегистрируйте аккаунт через Gmail или Outlook. Почтовые адреса с доменом .ru использовать нельзя. Я выбрал последний, так как не нужен номер телефона и можно сразу указать страну.
3. Инструкция ниже.
Если у вас есть возможность зайти через IP Индии, то супер. Если нет, то ищите возможность через пробные версии. У меня вышло 10 рублей за сутки. К сожалению, данная тема запрещена к обсуждению и я не могу расписать подробно процесс получения.
Считаем что вы уже под IP Индии.
Я буду делать в Opera.
Переходим в приватный режим, чтобы повысить наши шансы на успех (Ctrl+Shift+N).
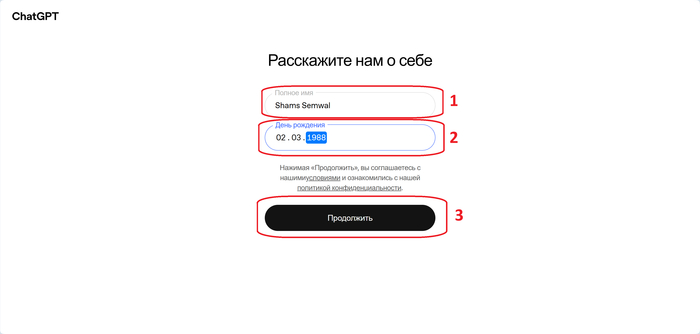
Далее, регистрируем нашу почту.
Генерируем любое индийское имя. Вкладку не закрываем, пригодится:



Регистрация
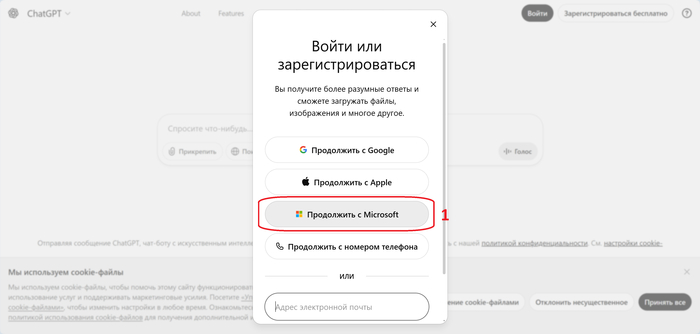
Переходим в ChatGPT:
И нам сразу предлагают попробовать тариф GO.

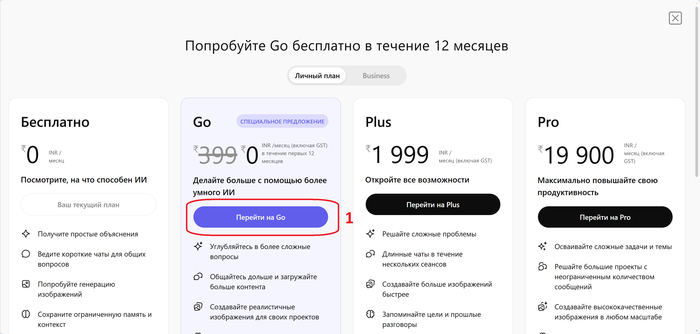
Тариф GO
Переходим по итогу к оформлению триальной версии.
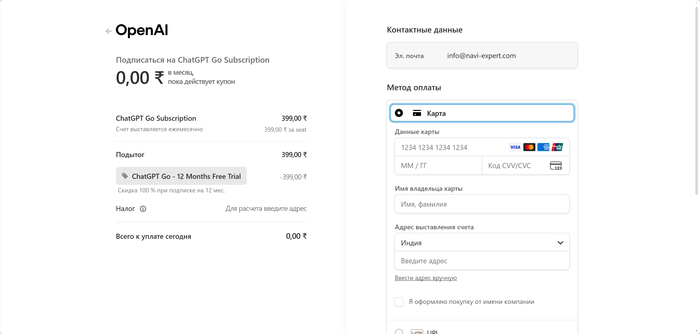
Оформление
Тут нам понадобится ввести данные карты.
Для этого используем генератор по ссылке ниже:
Для оплаты понадобится тестовая карта. Сгенерируйте её на сайте
Используйте BIN 551827706 (остальные цифры подставятся автоматически).
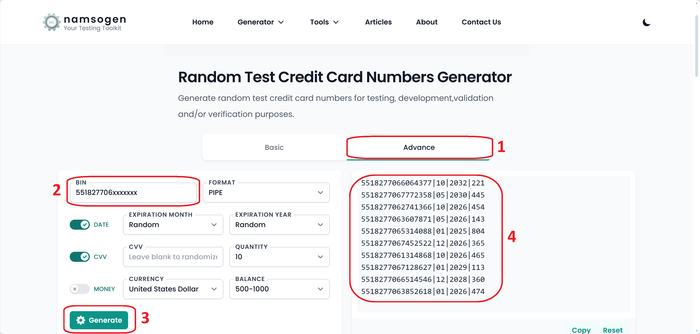
Генератор карт
Укажите любое имя на английском, имя и фамилию берём из генератора выше.
Реальный индийский адрес (можно взять тут):
Вводим все данные и оформляем триал.
Проходим капчу и...
С первого раза не получилось и карту не приняло.
📌 Важно: Если вылезет ошибка — попробуйте сменить VPN, сгенерировать новую карту или выбрать другой адрес.
Вводим другой номер и повторяем процесс.
Карта принята и на почту прилетает письмо, что ChatGPT Go активирован на год.
Поздравляю — вы превосходный хакер!
У меня вышло на траты ровно 10 рублей, а ушлые торгаши уже продают на Авито подписку за 1300-1500 рублей.

Затраты
Пользуясь случаем, не рекламирую свой телеграмм канал, а рекламирую серию своих постов по избавлению от подписок:
Показать полностью
14

Ответ на пост «Самая редкая профессия и искусственный интеллект»1
Удивительно насколько люди парадоксально (недо)?оценивают всю "мощь и нищету" ИИ.
С одной стороны конструкту, который сейчас вставляют и в хвост и в гриву в каждой первой прикладной отрасли и задаче от силы (как считать) до полутора лет в обед. Человеческие джуны на таком сроке ещё в памперсы сикают.
С другой стороны трудно не поддаться очарованию таких, казалось бы, недюжинных когнитивных способностей от сравнительно небольшого и сравнительно простого куска серверного софта.
Человечество не в первый раз впадает в такую эйфорию от новой технологии. Когда машины научились считать быстрее и точнее людей, им (людям пока, конечно же) казалось, что вот оно, машины скоро захватят мир и свергнут человечество. До сих пор так считать могли только хомосапиенсы, а тут машина! сама! СЧИТАЕТ!
Потом таких волн было много. Сложные механические автоматы, вязальные и швейные машины, станки, часовые механизмы внушили Человечеству, что вот-вот роботы захватят мир. Эту волну с удовольствием и энтузиастом подхватили фантасты, а мы получили от них глубокие и интересные экзистенциальные рассуждения о законах робототехники, о том, чем биологические "машины" отличаются от технических...
Шли годы, а "проблемы" с роботами, для усмирения которых понадобилось бы как-то применять законы Азимова", всё не вставали ребром. Однако у Человечества время от времени возникали рецидивы ощущения, что ИИ (а может быть и сильный ИИ) уже близко.
Таков был период, когда начали появляться экспертные системы, а информационные технологии дошли до того, что появилась потребность и техническая возможность работать со знаниями в более-менее формализованной форме. Этот период, как я понимаю сейчас, был очередным ренессансом мысли о скором приходе и резком развитии Искусственного Интеллекта.
Но годы снова шли, компьютеры мощнели, о том, что нам всегда хватит 640кБ памяти вспоминали всё с большей издёвкой, а хайп на тему искусственного интеллекта по поводу каждого мало-мальски заметного технического прорыва был с каждым разом всё тише и скромнее. Вспоминается как в первый раз АйБиЭмовский суперкомпьютер обыграл Каспарова (тогдашнего чемпиона мира) в шахматы.
Я тогда был уже старшеклассником и сильно увлекался всем, что связано с компьютерами. И даже мне - едва освоившему в те годы Q-Basic и посматривающему на Pascal - было удивительно почему люди связывают эту сугубо узкую переборную, чуть ли не брутфорсную задачу с Интеллектом.
Потом, когда компьютер обыграл Ли Седоля в Го, искусственно интеллектуальный хайп уже слабо выглядывал из под уровня прочего техногенно-новостного шума, хотя, надо сказать, в этот раз уже было гораздо больше поводов как-то притянуть за уши разговоры об интеллекте. AlphaGo опирался уже в значительной степени на машинное обучение, а не на логику, комбинаторику и оптимизированные классические алгоритмы.
Это был 2016 год. Я уже 12 лет как после института работаю программистом. Все эти годы не сказать что ничего не происходило, но ярких каких-то событий, связанных с машинным обучением, в медийном поле не вспоминается. Ну то есть вот как мы на 4 (или каком там я не помню уже) курсе делали лабораторку с обучением небольшой нейросетки распознавать рукописные буквы, так ничего прям так уж сильно не менялось, чтоб аж до хайпа, до того, чтобы снова вспомнить Азимова с его законами. Фантасты, конечно, старались, там витало много интересных идей, но всё на уровне шума.
Да, я отлично помню, как появлялись зачатки механизмов распознавания голоса. Куда-то это потом делось, но я отчетливо помню как на кнопочных звонилках вполне можно было голосом выбрать из телефонной книжки контакт и позвонить не нажимая кнопок. Помню как купил на где-то развалах диск с подборкой софта для синтеза и распознавания речи. В частности там был и Dragon Dictation (или что-то в этом роде). Да, эта штука даже как-то поддерживала русский язык, но качеством распознавания разочаровывала, а корявый синтез резал уши даже на английском.
Думал ли я тогда, гадал ли, что спустя некоторое время у нас будет Алиса, так здорово говорящая и замечательно понимающая даже шепот? Я отчетливо помню как появился сервис Яндекса, способный по шаблону набуровить какой-то под пьяную лавочку похожий на нормальный текст, а по факту связный, но бессмысленный набор слов.
Если оглядываться в прошлое, то это уже был перегиб экспоненты развития технологии. С этого момента машинное обучение добивалось всё новых свершений. Болталки, изображающие трёп в чате, появились давно, но о прохождении ими теста Тьюринга говорили только в шутку, от неграмотности, или инфантильного энтузиазма.
И вот мы здесь. За какие-то пару лет у нас ценой каких-то чудовищных вычислительных затрат и усилий по подготовке датасетов были обучены первые по-настоящему большие модели (LLM). Они начали удивлять. Оказалось, что раздутый до неимоверных масштабов "Т9" способен оперировать с языковыми конструктами, а это, в свою очередь, оказалось похожим на рассуждения.
Наверно это не было сюрпризом абсолютно для всех, однако удивляться тут есть чему. Оказалось, что когнитивные задачи можно решать эдаким черным ящиком, обученным на эпических количествах текстов. Да, поначалу это было глючно и странно. Галлюцинации и неуправляемость удалось побеждать разными уловками от манипуляцией с обучающей выборкой до хитрых системных промптов и итерационной многослойной обработки (думание).
Надо ли говорить, что сейчас генеративные модели и всё вот это вот, что называют Искусственным Интеллектом не просто перегретый инвестициями мыльный пузырь, а вполне себе уже приносящая пользу в куче отраслей технология? Думаю не надо.
На наших глазах случился очередной технологический фазовый переход, который меняет ландшафт и прогнозируемое будущее нашей цивилизации.
Что дальше-то? А дальше огромный простор применения и развития новой технологии. Она даже новорождённая и сырая поражает небывалыми новыми доступными возможностями. Теперь, даже если предположить, что новых текстов для обучения человечеству взять уже не откуда, есть ещё необъятные просторы для развития.
Нейросети могут брать информацию для обучения напрямую из окружающего мира, как это всегда делали люди. Да, это будет требовать гигантских энергетических и материальных затрат на вычисления, а значит мы переработаем огромное количества песка в кремний для чипов. Посмотрите что творится с рынком видеокарт, памяти, и всего, что можно использовать для растущей новой индустрии. Но этот ящик Пандоры уже не закрыть.
Но не только экстенсивные пути есть для развития. Сейчас мы уже применяем графовые БД для поиска в пространстве понятий и смыслов. Может быть мы вспомним такой замечательный язык как Пролог, чтобы "протезировать" механизм обработки формальной логики для нейросетей. В конце концов генеративные модели в чатах и рассуждениях во всю используют написание скриптов для алгоритмических вычислений. В эту "игру" можно играть по всему фронту развития ИИ.
Если кому-то кажется, что мы "упёрлись" и начнётся стагнация, то готов спорить, что это не так.
Да... к сему это я всё. Мне тут напомнили в оригинальном посте про старый добрый Lisp, а он меня в голове лежит рядышком с ещё более недооценённым на мой взгляд языком для применения в контексте ИИ - Прологом.
Помяните моё слово, его ещё вспомнят не раз в контексте оптимизации логического вывода для LLM.
Ну а чтобы два раза не вставать, жахну тут футурологический прогноз на ближайшее будущее.
На дальнюю перспективу легко прогнозировать, всё равно никто не вспомнит и не припомнит, если ошибёшься. А вот на ближнюю...
Итак, побуду капитаном:
- Будет развиваться внеконтекстная память агентов. Всевозможные векторные БД - это только начало, уже есть графовые БД, которые хранят не просто куски текста, но целые взаимосвязи понятий. До сих пор мы в основном имели "знания", спрятанные в черном ящике весов и связей нейронной сети. Это, вроде бы, тот самый путь, которым пользуются люди в своей голове, но давайте вспомним самолёты. Они хоть чем-то и похожи на птиц, однако крыльями они не машут, зато летают очень быстро и таскают много груза. Также и здесь. Мы будем оставлять за "черным ящиком" нейросети базовые "мыслительные" функции, а информацию будем вытаскивать в формализованные структуры специализированных баз данных.
- Развитие когнитивных ассистентов. Мы уже начали и продолжим учить наших ассистентов держать в формализованном векторном контексте (см предыдущий пункт) кучу совершенно разной информации о личной (цифровой и не только) жизни. Наши ассистенты будут "знать" всё о нашем творчестве, об интересах, о вкусах, о закладках в браузере, о планах на лето или выходные, об анализах из поликлиники, о покупках, о наших автомобилях начиная от расходников до поломок и ТО, о наших бытовых вопросах от содержимого холодильника до коммунальных платежей... Многие настолько будут доверять своим ИИ-ассистентам, что будут хранить в их контексте все свои личные переписки. Это неизбежно приведёт к когнитивной аугументации, когда наши ИИ-ассистенты станут своеобразной частью нашего "Я", а мы будем на них сваливать всю когнитивную рутину, которую раньше делали самостоятельно своей биологической нейросетью. И среди этого будет много парадоксальных моментов: порой мы будем склонны отдавать нейросети даже "рутину" общения с родными и знакомыми, внешние "когнитивные протезы" в лице ИИ-ассистентов будут назначать встречи, обсуждать организационные вопросы, вежливо поддерживать так называемые "small talks". Зато наша биологическая нейросеть будет, зачастую, с упоением зависать в, казалось бы, рутинных, но таких дофаминовых гриндилках, как современные казуальные компьютерные игры.
Если кому ещё интересны прогнозы на ближайшее будущее, то пинайте, а то мне кажется я тут в своём графоманском угаре генерю своей биологической языковой моделью обременительно много букофф.
Показать полностью

10 сайтов где попробовать Nano Banana бесплатно + подборки промтов GitHub + гугловские гайды

Может кому-то пригодится. Мне кажется, проще купить платную подписку Gemini или какой-нибудь мультимодальной платформы вроде Kling AI или Leonardo AI, где есть Nano Banana, чем маяться с бесплатными аккаунтами. Первая продается что-то вроде тысячи-двух рублей на маркетплейсах вроде Ggsel, Playerok, Плати Маркет или даже на Яндекс.Маркет, Ozon и Вайлдберриз.
Сам пользуюсь Gemini (платно) и Google AI Studio (бесплатно).
Где использовать Nano Banana бесплатно:
gemini.google.com — где-то 2–3 генерации в режиме «Думающий», затем откатывается на обычный, где доступно 30–70 простеньких картинок в день.
aistudio.google.com — по моим наблюдениям дает до 30 генераций в день. Есть жирный минус: нужно привязать зарубежную карту (деньги не списываются), как это сделать написал здесь
lmarena.ai - вроде безлимит, но у них тестовая форма генерации, то есть надо ввести промт, выбрать одну из двух картинок, а потом ты узнаешь какую из них сделала Nano Banana
felo.ai - 200 кредитов в день, после регистрации дают 300 (итого 500 на старте), одна картинка примерно полтинник кредитов
www.nano-banana.ai - 5 кредитов в день, на две картинки (не Pro версия)
nanobanana-pro.com/ru - 8 кредитов в день, на одну Pro и две обычные картинки
www.lovart.ai - 100 кредитов в день, 4 картинки
www.genspark.ai - 100 кредитов в день, 2-3 картинки
imageeditor.online - я так и не понял что по лимитам, но все работает
visualgpt.io - 25 кредитов, 2-3 картинки
И на десерт.
Тут прикольные подборки промтов, которые репостят в соцсети всего мира (часть из них, наверное, уже кто-то видел в телеграм-каналах):
Еще посмотрите мои подборки промтов с примерами:
Гугловские гайды по Нанчику Бананчику (там есть прикольные примеры):
Другие мои подборки и гайды
***
Спасибо, что дочитали
Поставь сердечко и напиши в комментариях.
Присоединяйся к 15 000+ подписчиков в Бегин, где я делюсь опытом работы с нейросетями и выкладываю полезные подборки.
Показать полностью