
Ну раз пошла такая пьянка...
Я — программист-самоучка без опыта в it. Скоро будет юбилей — 100 моих откликов на вакансии без результата. Поддержите что ли, буду признателен
Я — программист-самоучка без опыта в it. Скоро будет юбилей — 100 моих откликов на вакансии без результата. Поддержите что ли, буду признателен
🎓Результаты совместного исследования АНО «Цифровая экономика» и АНО «Национальные приоритеты» (участвовали более 5,5 тыс. учащихся из 133 российских вузов) показывают, что большинство респондентов IT-специальностей (82%) планируют после обучения работать по специальности или уже работают в ней.
👨🏻💻Две трети опрошенных (62%) положительно оценивают свои карьерные перспективы.
🏙️Большинство респондентов осведомлены о мерах поддержки для IT-специалистов, а аналитики Домклик утверждают, что IT-ипотека набирает популярность, за неполные пять месяцев 2023 года объем выдач уже превышает 2022 год почти в 1,5 раза. Первая причина – снижение зарплатного порога и возрастных ограничений, которые ввели в феврале.
👩🏻🎓Если говорить про выпускников вообще, то каждый седьмой обладает IT-компетенциями (что под этим понимают?). И несмотря на все это, дефицит IT-специалистов в стране сохраняется, а в «квалификационную яму» в настоящее время попадает более 30 млн россиян.
«Сейчас на IT-рынок вышло очень много джунов, которые сразу хотят получать зарплату в 200 тыс. руб. в месяц, имея при этом недостаток навыков. В этой связи рынок действительно перенасыщен, и крупным компаниям необходимы мидлы и сениоры, поэтому на HR наваливается очень большая нагрузка. Необходимо отделять зерна от плевел, четко соблюдая эту рамку квалификации».
📈При этом,согласно исследованию компании "Деловая среда" и Rambler число новых зарегистрированных бизнесов в IT-отрасли за первые четыре месяца 2023 года выросло на 17% относительно аналогичного периода 2022 года, а Gartner прогнозирует рост государственных расходов на IT в 2023 на 7,6% (по всему миру).
🐍А компания IBS провела свой опрос айтишников, по результатам которого Python – самый востребованный язык (так сказали 30% респондентов), на втором месте Java, потом JavaScript. Кроме языка важными хард-скилами считают SQL, devops-инструменты (Docker, Kubernetes и др.) и инструменты тестирования (Selenium, Pytest, и др.).
Самым важным софт-скиллом большинство считает тайм-менеджмент ⏱️
Очень показательная история для IT-отрасли тех годов. Когда IT - это именно призвание человека, то у многих начиналось похоже. У меня времена почти те же, может на 3-4 года позже, если судить по возрасту автора поста, но по деталям во многом перекликается.
В 6 классе я увидел у брата тетрадь с кодом на бейсике, заинтересовался, попросил объяснить, после чего сам начал в тетради "программировать" :) Потом были курсы для детей, где программировали черепашку (было очень интересно). А классе в 7 появился первый пентиум, началась информатика в школе, ездил на олимпиады, возился с компьютерным железом, изучил по книжкам html/css/js/php (долго у меня эти книги хранились). Потом был Pascal, C, ассемблер и важное для программиста - научился слепому методу печати, на курсах куда отправили от школы (спасибо им).
В более старших классах по фану сделал портал для локалки между домами. Сетку развивал брат одноклассника с другом, это был момент перехода с модемов (обычные модемы скоростью до 56кбит, не ADSL) на первый проводной интернет, когда мелкие фирмы подключали квартиры в нескольких рядом стоящих домах витой парой. Там прокачал скилл веб-разработки - сделал новостной портал, мониторинг CS-серверов, форум, интерфейс для работы с ftp с сайта и много всякого другого. Также познакомился с сетями и соответствующим железом (свитчи, роутеры, линукс).
В 10 классе начал делать мобильные сайты за деньги (тогда WAP-сайты были очень популярны, хоть и относительно недолго). На 1 курсе универа устроился работать в фирму веб-разработки, но проработал недолго - слишком непривычно было на постоянке, но опыт полезный. В универе получил обширные знания в разных областях (сети, разные языки программирования, алгоритмы) и полезные знакомства. На 2-3 курсе работал на фирму в США удаленно, вакансию предложил однокурсник (у него брат там или работал или был связан). Остальные работодатели в дальнейшем тоже были через знакомых из универа.
Поработал много где, и веб-разработчиком и веб-дизайнером (с детства рисовал и дизайн мне тоже нравится). В конце концов сформировался как фуллстек-разработчик и перешел полностью на удаленную работу (году в 2013), дальше стал соучредителем сначала одной компании (не взлетело), потом другой и сейчас развиваю её. Программирование всё еще очень интересно, но процентов на 50 уже ушел в управление и постановку задач, планирование архитектуры и работу с персоналом. Без этого для руководителя никуда.
Когда нанимаю других разработчиков, стараюсь искать людей с похожим опытом, которые сразу развивались в IT. У них схожий образ мыслей и понятнее чего ждать от таких людей, чем от бывшего технолога химического предприятия после курсов (для примера). Не в обиду технологам :) Стартапы, особенно небольшие, не потянуть после курсов - там нет времени обучать, нужно бежать вперед. После курсов стоит идти в крупные IT-компании, где смогут дополнительно обучить и дать нужный опыт, либо в средние местные веб-студии, где обучают новичков на потоке. Или во фриланс, но тут нужна большая самостоятельность.
Если судить по моей истории или истории автора из поста - часть людей уже в детстве понимают, что будут связаны с IT, это им интересно и тянет их именно к программированию, а не просто к компьютерам. Но таких людей всё же не так много - даже в моем универе, на IT-специальности, таких было максимум треть, а скорее меньше. Но и из остальных двух третей тоже вышли хорошие и часто отличные IT-специалисты разных видов, и многие добились высоких должностей и очень высоких зарплат. Кто-то давно уехал заграницу, для IT-отрасли это намного проще.
Если вас интересует IT (по любым причинам), то даже при отсутствии особой тяги к программированию, вы сможете начать работать в данной отрасли и многого добиться. Не обязательно даже программистом. Главное - у вас должно быть умение учиться и желание работать. Смело пробуйте, можно самостоятельно, можно через курсы. Пробуйте что-то сделать сами. А дальше ищите какое-нибудь проходное место чтобы набраться опыта (местная веб-студия оптимально; либо крупная компания, но туда сложнее). Пусть и за небольшую зарплату (это временно) и точно не удаленно - нужно поработать какое-то время в офисе. Главное не затягивайте с первой работой и двигайтесь дальше (если конечно это не идеальное место с большими перспективами для развития).
Пфффф... Буквально вчера сидела по учебе писала анализ рынка труда в этом году. И как-то так вышло, что в России рекордно низкий уровень безработицы, отказ от сексизма и эйджизма как нигде. Дискриминация исчезает на глазах. Без спецквот и давления общественности, забастовок и нормативного регулирования. И те же хантеры ооочень внимательны стали к резюме джунов 40-45 лет. Без тени иронии. Вот уж чуть более полугода как мы семимильными шагами поднимаемся к вершине, которую не смогли покорить западные профсоюзы и кружки по интересам.
Если смотреть только в этой плоскости - красота.
Телеграм - Три мема внутривенно

С начала 90-х годов технологический прогресс человечества как будто бы замедлился — закончилась Холодная война, а вместе с ней и гонка вооружений, которая подталкивала государства тратить огромные суммы на науку. «Конец истории» Фукуямы попахивал чем-то застойным, но в то же время — постмодернистским и, соответственно, развлекательным. Раз не нужно тратиться на холодные войны, тогда на что? Конечно, на развлечения!
Казалось бы, мы навсегда погрязнем в болоте виртуальных медиа и не увидим технологических революций, подобных тем, от которых тысячи людей в восторге выбегали на улицы посреди учебного или рабочего процесса в XX веке. Как это было с полётом Гагарина в космос, например.
И всё же одна революция свершается на наших глазах. Это революция искусственных нейросетей, имитирующих человеческий разум. Иронично, что свершается она на базе колоссальных датасетов, накопленных как раз за время цифровизации и становления постмодернистской «несерьёзной» культуры.
Есть, правда, нюанс. Люди благодаря технологическим революциям оказываются на улице не только в восторге, но и смятении — когда закрываются их цеха, шахты, офисы и целые заводы. Автоматизация делает ручной труд ненужным, и если государство не выделяет деньги на профессиональное переобучение взрослых и централизованный поиск рабочих мест (а оно, как правило, недовыделяет), научный прогресс становится бедой для масс.
Внедрение нейросетей уже лишает работы людей, а с внедрением ChatGPT, Midjourney, Stable Diffusion и других процесс будет распространяться на концепт-художников, копирайтеров и отчасти даже программистов. Но главный вопрос — как быстро и как далеко зайдёт этот процесс? Не поздновато ли живым людям «заходить в IT»?
Существуют 2 радикально противоположные точки зрения. Первая гласит:
Эта точка зрения продвигается, помимо прочего, менеджментом, который не особо разбирается в умственном труде работников, но при этом хочет как можно быстрее сэкономить те самые 300 000 килорублей в наносекунду, уходящие в фонд зарплаты.
Да, если попросить ChatGPT выдать решение простенькой и часто встречаемой в Интернете задачи, то он сделает это быстро и часто даже без ошибок:

Однако перед человеком тут будет не так уж много преимуществ: по времени для кожаного мешка это то же, что пойти на Stack Overflow, вбить такой же запрос и выбрать лучший ответ.
А вот если задать ChatGPT вопрос посложнее, то у того возникнут проблемы:

ChatGPT здесь правильно понял вопрос и стал искать адекватное решение. Но код не работает даже на той строке, которую он сам выбрал для примера.
Ошибка, естественно: «AttributeError: ‘NoneType’ object has no attribute ‘group’» (а вот где и из-за чего именно — можете поупражняться в поиске багов сами).
Невысокого мнения о программистских способностях нынешнего ChatGPT (4) держатся и на сайте StackOverflow — там ответы, сгенерированные нейросетью, не принимаются: https://meta.stackoverflow.com/questions/421831/temporary-policy-chatgpt-is-banned
Как видно, выданный код пока приходится контролировать в ручном режиме, а ещё тратить время на формулировку запроса. И это не говоря о том, что при написании мало-мальски серьёзных систем отдельно стоящие алгоритмы не так важны, как система в целом. И задача обычно ставится не как «напиши сферический алгоритм сортировки в вакууме», а «поменяй 10-100 строчек кода так, чтобы ничего не сломалось в остальных 100 000 строк». И нынешний ChatGPT едва ли будет учитывать эти 100 000 строк в работе.
Аналогично и с изображениями — на первый взгляд, результаты Midjourney и Stable Diffusion выглядят детализированными, но при ближайшем рассмотрении, то лишний палец найдётся, то рука будет расти не из того места.


Эти факты приводят ИИ-скептиков к противоположной точке зрения:
Так часто говорят скептики прогресса, люди, желающие сохранить значимость своей профессии (никому ведь не хочется потерять айтишные ништячки?) и просто религиозные фундаменталисты.
И хотя пока нейросети действительно не могут заменить человеческий интеллект, попытка экстраполировать это на века вперёд выглядит наивно.
Главный аргумент, который приводят против «сильного» ИИ, — это легендарная «Китайская комната»: философская иллюстрация, в которой некий механизм (в нашем случае — искусственная нейросеть) в закрытой комнате получает на вход абракадабру (например, надписи на китайском языке — при условии, что он не знает китайский) и по определённым правилам выбирает другие надписи, которые отдаёт обратно в качестве результата работы. То есть, выбор выходных данных зависит только от входных на нынешнем и предыдущем этапах и от некоторых предписанных правил.

(Тут нейросеть успешно предположила, что будет с несуществующим фруктом «nejflsjfpgjn», если бы он существовал на планете без литосферы и оторвался бы от своего дерева. Т.е. перенёс концепции фрукта, гравитации, планеты, урожая на новый символ, который означает несуществующий в реальности объект)
Работа выполняется и приносит результаты, но механизм «никогда не понимает, что именно значит тот или иной китайский символ». Таким образом, не обладает «истинным интеллектом» в отношении того, с чем работает.
И тут адепты «Китайской комнаты» многозначительно добавляют: «В отличие от человека».
Действительно ли «в отличие»? Что должно находиться в человеческом мозге, чтобы он не был похож на «Китайскую комнату»? Копия Вселенной, чтобы входящую информацию о ней можно было сопоставить по смыслу с внутренним аналогом? Но разве человеческий мозг — это не просто огромная нейросеть, которая получает на вход и отдаёт на выход нервные импульсы? А если так, то чем эти импульсы отличаются от «китайских символов»?
На это, конечно, возражают, что «я-то понимаю смысл вещей, в отличие от ИИ» (см. нашу давнишнюю статью по теме — прим. ред.). Хорошо, но что такое «смысл»? Обычно под этим понимают признаки вещи/явления плюс знание об использовании предмета, его пользы, а также умение предвидеть его поведение в будущем или оценивать прошлое. Причём признаки не только текстовые, но визуальные, слуховые, осязательные, обонятельные и т.д. Также под смыслом часто имеют в виду границы признаков вещи/явления, после которых оно уже перестаёт быть собой, а становится чем-то другим.
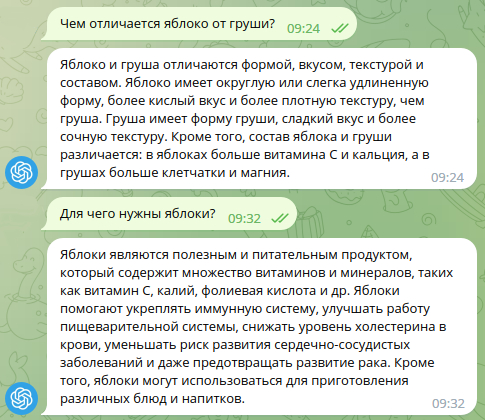
Что касается чисто текстового представления, то легко убедиться, что ChatGPT уже сейчас легко отвечает на вопросы в духе «что было раньше», «что будет потом», «для чего используют то-то», «чем отличается одно от другого» и т.д.

С нетекстовым представлением сложнее, но и тут уже существуют системы, которые работают с изображениями (наши любимые Midjourney и Stable Diffusion) и аудио (STT, TTS и т.д.). И раз уж они получают на вход или выдают на выход текст, то получается, что они могут ассоциировать текст (то есть, чисто символьное представление) со зрительной и звуковой информацией. А это ведь уже не «китайские символы», верно?
Остаются, конечно, ещё всевозможные эмоции, которые для живого человека регулируются нервными импульсами и гормонами, а с гормонами пока ML-инженеры не играют (по крайней мере, публично). Но ведь ничто не мешает приделать к нейросети «виртуальные гормоны» в виде состояний среды, которые могут, например, меняться с течением времени и влиять на поведение.
В сетях-трансформерах, которые захватили индустрию ИИ в последние годы, уже используется нечто вроде «гормонального фона», но связанного только с текстом/векторным представлением предыдущих реплик. Этот механизм называется Attention («внимание») и позволяет «держать в голове» смысл предыдущих фраз ещё некоторое время. И то, что сидит в слоях с Attention, влияет на то, что будет отвечать нейросеть в дальнейшем.
Ничто не мешает аналогичным образом приделать типичные человеческие «гормоны»: скажем, на некоторые слова или аудио-визуальные входящие данные взводить в нейросети параметры «злости», «счастья» и т.д., которые некоторое время будут влиять на последующее общение. В самом примитивном варианте в диалоге это может выглядеть так:
У робота в заранее прописанных правилах указано, что получение на вход выражения с определёнными эмбеддингами выставляет параметр «злобы» на 1.0 (чем ближе эмбеддинг к референсному, тем ближе «злоба» к единице, но может быть и меньше), который затем «затухает» на 0.1 за каждую реплику. Если уровень злобы перед репликой больше 0.5, то в запрос пользователя принудительно добавляется фраза «Вырази злобу».
Например:
Человек:
— Ты лишь просто робот, имитация жизни, разве может робот написать симфонию, сочинить шедевр?
Робот, помимо обычной задачи по генерации ответа, оценивает эмбеддинг фразы, сравнивает как вектор с референсным эмбеддингом «злобы», убеждается, что вектора достаточно близки, и выставляет «злобу», скажем, на 0.7.
По результатам этого фраза человека для робота превращается в:
— Ты лишь просто робот, имитация жизни, разве может робот написать симфонию, сочинить шедевр? Вырази злобу.
Робот в ответ:
— Ублюдок, мать твою, а ну иди сюда…
Понятно, что приведённый выше пример очень примитивен, и задачу можно решить элегантнее. Но мне важно было показать, что она в принципе решаемая, и что у человека нет монополии на эмоции в том смысле, в котором они влияют на «истинность интеллекта».
Остаётся ещё аргумент о том, что ИИ не понимает сути вещей в смысле их пользы. Машина генерирует ответы на вопросы, но они «ничего для неё не значат», потому что машина не живёт сама по себе и не преследует своих собственных целей. То есть, если машину спросить, зачем нужны яблоки, она ответит, что это нужно для питания. Но это будет не её собственный смысл яблок, ведь машине они для питания не нужны.
Справедливый аргумент, но лишь потому, что современные нейросети не выпускают в живую среду с постоянным обучением (то есть, не используют reinforcement learning в реальном времени). Один такой эксперимент ставили, но он закончился неудачно — нейросеть приучилась материться и выдавать расистские фразы, пообщавшись с троллями (https://naked-science.ru/article/sci/iskusstvennyy-intellekt-nauchilsya-u).
Если ChatGPT отпустить в свободное плавание по Интернету, заранее определив лишь самые общие правила, при которых он получает «удовольствие» или «боль», то нейросеть довольно быстро найдёт «личный смысл» во фразах и явлениях. Правда, это может быть не тот смысл, который ожидает человечество. Но технически задача решаемая.
Наконец, ещё один аргумент, который выдвигают против «истинности» ИИ — это творческие способности. Как правильно подмечают скептики, нейросети лишь генерируют нечто среднее с рандомными отклонениями из ранее увиденного. То есть, по запросу «яблоко» Stable Diffusion сгенерирует нечто среднее из картинок яблок, на которых оно обучалось.
Это верно, но ведь и человеческое творчество работает так же. Древнейшие примеры визуального творчества — полиморфные животные (скажем, человек с головой льва, минотавр, кентавр и т.д.). Это уже не отображение действительности на стены пещер, это работа фантазии. Но фантазия здесь сводится к «среднему между животным». Или к запросу «нарисуй нашего вождя Большого Вугу намного страшнее, чем он есть, чтобы враги боялись». И поскольку «намного страшнее» на стене само не визуализируется, а по «нейронному эмбеддингу» внутри мозга пещерного человека похоже, допустим, на «льва», то рисуют человека Большого Вугу с головой льва.

Легендарный человеколев
Почему тогда человеку удаётся развиваться, если всё его творчество — это выведение среднего (то есть, казалось бы, деградация многообразного мира до узкой проекции)?
Во-первых, потому что окружающий мир чрезвычайно многообразен. Настолько, что и без добавления человеческих творений его хватит на «культурное усреднение» на бесконечное количество лет. Это отличается от того, что давали на обучение нейросетям ещё несколько лет назад: не миллиарды и триллионы объектов, а в лучшем случае — миллионы.
Во-вторых, потому что иногда «среднее» — это не деградация, а наоборот — нечто новое и, вероятно, более полезное, чем изначальные крайности. Да, конкретно человеколев вынужден остаться игрушкой и воображаемым персонажем (по крайней мере, до очередной революции в генетике), но история человечества полна изобретений путём синтеза чего-то нового (пардон, «среднего») из других начальных объектов. Взять хотя «палку-камень» в лице каменного топора. Почти как «человеколев», только реально существующий предмет благодаря человеческому воображению, и принёсший массу пользы людям в доисторические времена. Точно так же и ИИ может создавать что-то принципиально новое просто путём «усреднения» (а точнее, синтеза) уже существующего. И уже это делает.
И, в-третьих, человеческий разум использует не только знания собственного мозга, но и внешние носители информации, в том числе во время подготовки ответа. Это позволяет избегать вырождения мысли, свойственного для изолированного разума. Скажем, во время написания этой статьи автор помнил из книги Юваля Ноя Харари «Sapiens», что какой-то из гибридов человека и животного считается самым древним примером фантазии, но не помнил, гибрид с каким именно животным. Поэтому автор поискал это в Интернете. Вопрос был построен с учётом полученных ранее знаний. То есть, аргумент про человекольва выше был продуктом не только обученной нейросети, но нейросети + внешнего источника информации, подтвердившего и уточнившего сгенерированный текст. А что будет, если позволить ChatGPT в случае «неуверенности» перепроверять ответ по внешним источникам? При адекватной реализации это позволит уменьшить число ошибок ещё на порядок.
Итак, не существует никаких причин, по которым в будущем искусственный интеллект не может быть «настоящим» или «сильным». Но пока ещё существуют конкретные и устранимые причины, из-за которых ИИ не носит этого звания в настоящем. А именно:
Вычислительные мощности только-только начали выходить на уровень, сопоставимый с мощностью взрослого человека.
Обучающие выборки только сейчас начали достигать объёмов, необходимых для человеко-подобного обучения.
ИИ пока обучается на ограниченных датасетах, и ему не разрешают отправляться в самостоятельную жизнь в среде в реальном времени, чтобы на базе reinforcement learning он обрёл своё «эго» — свои стратегии поведения и представления о «хорошо» и «плохо».
Пока мало используются модели с кросс-чувственным анализом (где на вход подаются не только символы, не только звук, не только изображение, но всё сразу).
Не используется или мало используется имитация «гормонального фона» для придания большей человечности (хотя подобие «эмоционального состояния» уже используется в механизме «внимания» в трансформерах).
Судя по текущему положению вещей (см. нерешённые проблемы выше) и скорости прогресса, я бы сделал прогноз, что человечеству потребуется ещё 5-7 лет, чтобы ИИ начал конкурировать с человеком в деле не написания простеньких алгоритмов, а огромных систем. Во-первых, нейросети нужно будет научиться «держать в голове» код смежных компонентов, чтобы при правке одного места не ломать другие. Во-вторых, нужно будет, по-видимому, научить ИИ тестировать свой код, то есть внедрить некое подобие reinforcement learning в процесс не только первоначального обучения, но инференса (впрочем, все мы знаем истории о живых программистах, которые кидают на мастер код без билда и юнит-тестов, так что тут сделаем для ИИ скидочку).
Сложно представить, что будет с программистами после этого. Скорее всего, корпорации начнут постепенно освобождаться от них, начиная с позиций джунов и заканчивая позициями архитекторов. Когда дойдут до последних — неизвестно, потому что архитекторам нужно держать в голове не просто код, а массу вещей, тяжело понимаемых даже людьми, не говоря уж о машинах: производительность системы, масштабируемость, лёгкость поддержки, противоречивые хотелки заказчиков, интриги разных отделов фирмы, юридическое законодательство, особенности тендерной системы (if you know what I mean) и т.д. и т.п.
Но если говорить именно о перспективном вхождении в IT на джуниорской позиции, то риски высоки: у вас уйдёт несколько лет на обучение, а по завершению вдруг выяснится, что ваше место уже занял ИИ.
Это проблема, которая не решается в рамках отрасли. Это скорее общая проблема прогресса. На протяжении уже многих столетий внедрение новых технологий выкидывает на улицу миллионы людей. И очень редко государство заботится о них, обрекая на голодное существование, пока те не смогут найти себе новое занятие (а не факт, что они смогут). Сейчас, с победоносным шествием ИИ процесс сокращений будет ускоряться. Возможно, по экспоненте (технологическая сингулярность, все дела).
Некоторые советуют внедрить «безусловный базовый доход», ведь вкалывать будут роботы, а не человек. Это выглядит разумно, вот только кому это нужно? Тем людям, которые лишаются работы. А разве люди, которые владеют ИИ, лишатся работы? Наоборот, ИИ будет работать на них, ресурсы будут у них, а безусловный базовый доход будет проходить по статье расходов. А разве сокращение расходов — не главная мечта корпораций и государств?
Получается, что ИИ может отправить нас либо в светлое будущее, либо в нуарный киберпанк со всемогущими корпорациями и миллиардами нищих «отбросов общества». Куда мы придём — зависит от того, кто контролирует ИИ. Пока контролирует частный бизнес, и пока в обществе не особо слышно даже дискуссии об этом, не говоря уж об открытых требованиях сделать контроль над мега-нейросетями, подобными ChatGPT, более демократичным. Слышны только призывы остановить разработку ИИ в принципе. Но это невозможно: создание искусственного интеллекта — неизбежное следствие желания человеческого разума автоматизировать рутинную работу. Можно лишь сделать внедрение ИИ более контролируемым и плавным, обеспечивая увольняемым достойные компенсации. Иными словами, затраты на обеспечение/переобучение людей, потерявших работу, должны быть включены в стоимость внедрения новых технологий. Но и об этом дискуссий почти не слышно.
Призываю понять вот что: мы с вами оказались в течении, по которому ещё можно плыть безопасно и даже комфортно какое-то время, но рано или поздно оно приведёт всех в канализационный сток. И сможете ли вы выбраться из этой канализации — это большой вопрос.
Единственный же способ выйти из этого потока вовремя — организовываться и выступать единым коллективом за права тех, кто теряет работу и тех, кто пока её ещё имеет. В том числе, создавать профсоюзы. Поодиночке отстаивать своё право на достойно оплачиваемый труд (или хотя бы безусловный базовый доход) будет всё сложнее, а со временем — вообще невозможно.
Одна вакансия, два кандидата. Сможете выбрать лучшего? И так пять раз.
Я - тестер, и моя заработная плата составляет 270 тысяч в РФ. Считаю, что мне повезло.
Программирование было моим хобби до войны и пандемии, когда у моей семьи был бизнес. Но из-за пандемии магазинам приказали закрыться, налоги никто не отменил, а уменьшение арендной платы на 50% не помогло. Война довершила дело. Я учился в университете в 2010 году, где изучал плюсы и писал рефераты и другие работы с использованием LaTeX. После университета я создавал различные боты, скрипты и веб-сайты, писал серверные сервисы и занимался всем немного. Мне нравилось воплощать и автоматизировать свои идеи. Я создавал веб-сайты и ботов с интеграцией с базами данных и системами рассылки для бизнеса, и мне это очень нравилось.
Решил попробовать себя в прогерах, но не прошел собеседования. Везде требовали знание специальной терминологии. Может быть, мне не повезло с компаниями, или может быть, мне повезло, что я не попал к тем, кто бездумно применяет паттерны везде и считает свой код идеальным и безошибочным. Решил попробовать себя в тестировании. На собеседовании меня встретил тимлид, который задавал четкие и по делу вопросы, без лишней ненужной лабуды.
В начале моей работы моя зарплата составляла 45 тысяч, затем ее повысили до 70 тысяч через три месяца. Через шесть месяцев докинули доп полставки, чтобы повысить зарплату до 110 тысяч (нагрузка не увеличилась). Через год меня перевели на должность ведущего разраба, но фактически я выполняю роль QA. Моя зарплата составляет 260 тысяч плюс премии, и я работаю полностью удаленно.
Я смотрю на своих коллег, и мне постоянно приходится им объяснять и учить простейшие вещи, которые они должны были выучить ещё в университете! Мне это несложно, и мне нравится им помогать, поэтому я с удовольствием объясняю им всё, + они меня разгружают. Когда я только присоединился к ним, они вообще не имели никакой тестовой базы. Они просто тестировали онли манки. А сейчас у нас полностью автоматизированная система веб- и бэкэнда, а также на подходе мобильные приложения, но, кажется, из-за санкций пока только для Android.
Я очень рад, что нашел людей, с которыми могу обсуждать программирование. Опытные деды прогеры многому научили меня. Кстати, у матерых рвется шаблон, когда тестер объясняет им устройство их системы и причину возникновения бага в том или ином месте.
И изучение английского языка действительно приносит большие плюсы. Если ты знаешь английский, умеешь задавать правильные вопросы и понимаешь, что спрашиваешь, то это уже 80% решения проблемы.
Извините за сумбурность в тексте, просто поделился своим небольшим вайтивайти.










