Сегодня не так много новостей, так что держите обзор приложения Windrecorder.
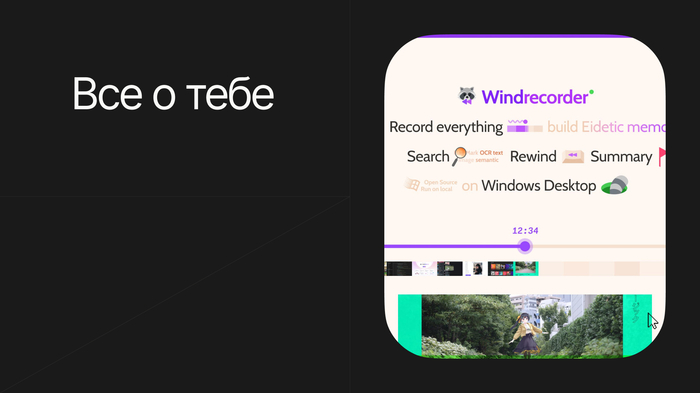
Китайская команда разработчиков yuka-friends представила приложение Windrecorder с открытым исходным кодом, позволяющие записывать все, происходящие на экране в Windows.
Важное уточнение, проект полностью бесплатный, в нем нет монетизации и все файлы пользователя принадлежат только пользователя, а не уходят в облако.
Аналоги есть для Mac - Rewind, linux - Memento Недостаток Rewind - платное и текстовые описания уходят в облако, то есть нет полной конфиденциальности..
«Возможно, у вас были такие моменты в работе с ПК: вы вспоминаете, что читали или видели что-то, но когда вы пытаетесь восстановить это, вы тщетно ищете в каждом приложении. В частности, когда информация распределена по множеству веб-страниц, видео и перемежающимся сообщениями чата, они появляются и исчезают в мгновение ока. Когда вы пытаетесь покопаться в своей памяти или истории браузера, чтобы найти эти данные, то создаётся впечатление, будто их там и не было, а это всё результат вашего воображения. Хуже того, такие данные могут быть удалены, скрыты или изменены различными приложениями»
Прод использует ffmpeg для записи экрана в небольшие 15-минутные фрагменты файлов, а затем индексирует их с помощью локального API OCR Windows и вставляет в изображения. Пользователи также могут игнорировать определённые программы или диапазоны экранов. Все это передается в локальный веб-интерфейс для перемотки назад или поиска (по заголовкам окон, текстовым ключевым словам или описаниям изображений). Используя эти данные, можно просматривать ежедневное и периодическое время использования экрана. Потом можно провести анализ и понять куда девается время проведенное за компьютером) (на просмотр пикабу и хабра).
Недостаток, что данные хранятся в открытом незашифрованном виде.
Зы название есть отсылка на Черное зеркало 1 сезон 3 серия.
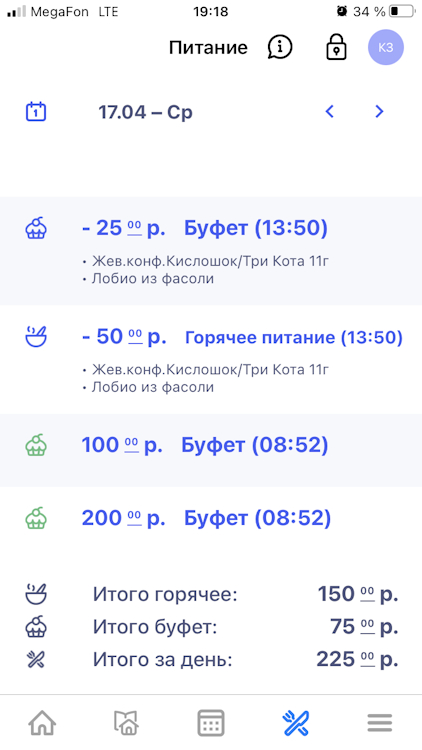
Электронный дневник удобная штука для детей и родителей. Есть такое и в санкт-петербургских школах есть. И многие школы города уже 3-4 года используют приложение "Петербургское образование.ЭД" от СПБ ГУП "СПБ ИАЦ". Помимо успеваемости и расписания в приложении можно контролировать расходы на питание с электронных кошельков. Кошелька у всех по два - один на горячие блюда ,второй на буфет. Задумка отличная. Реализация несколько альтернативная. Попробуйте догадаться по скрину, какие операции были вчера и что к чему относиться.
А что было: Пополнение Горячее питание +200р. Пополнении Буфет +100р. Покупка лобио -50р с Горячего Покупка конфеты -25р с Буфета
Перепутанные пиктограммы при пополнении это мелочь, как и дублирование всего списка списания под каждой операцией списания. А вот альтернативная математика в Итого это очень интересно. Объясните мне пожалуйста, как и во имя чего?!
Обращения разработчик стабильно игнорирует. Ведь пользователь этой поделки не заказчик.
9 апреля была обнаружена уязвимость в приложении Telegram под Windows с возможность автоматически исполнения кода при загрузки файла, то есть с 1 щелчком мыши..
14 апреля Telegram исправляет уязвимость и файлы расширения “pywz” не запускаются автоматически.
Уязвимость могла затронуть лишь небольшую часть пользователей: менее 0,01% установили Python и используют соответствующую версию Telegram для ПК.
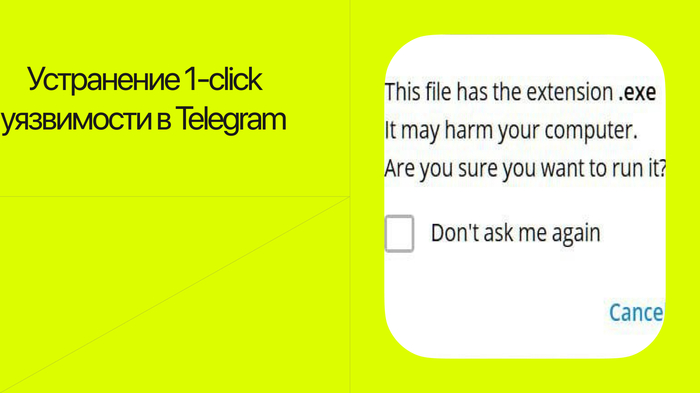
Telegram составил список расширений с высоким риском (например, exe). Перед их запуском появляется предупреждение о безопасности: "Этот файл имеет расширение .exe и может нанести вред вашему компьютеру. Вы уверены, что хотите его запустить?"
Однако неизвестные файлы могли запускаться автоматически. Ошибка заключалась в расширении "pywz", которое было добавлено в список как "pyzw". В результате файлы автоматически запускались с помощью Python. Через Python можно было запустить вирус удаленного доступа или локер.
На сайте BleepingComputer был проведен тест этой уязвимости с исследователем кибербезопасности AabyssZG. С использованием старой версии Telegram журналисты получили от исследователя файл "video.pywz", маскированный под видео в формате mp4. Он содержал код Python для открытия командной строки. Однако при клике на видео Python автоматически выполнял сценарий, который открывал командную строку.
Будущие версии приложения Telegram Desktop должны включать предупреждающее сообщение о безопасности, а не добавлять расширение ".untrusted", что повысит безопасность процесса.
Вот теперь можно спать спокойно.
Немного паранойи, но не скачиваете лишний раз файлы, ниоткуда) А если скачивать, то вначале тестировать на виртуальной машине или проверять на вирус тотал. Довольно странно будет при запуске mp4 видит консольную строку…
Пока интернет комьюнити все еще спорит о том, что Ахерон вышла слишком имбовой и ее надо нерфить или бафать старых персонажей, я искренне их не понимаю. Это единственная ОДИНОЧНАЯ игра, в которой я заметил, что люди спорят о балансе персонажей... Сегодняшняя тема не баланс а нечто иное... Сегодня поделюсь своим прогрессом по обновлению бота для ХСРки. Отбросим эти бесполезные рассуждения о ботоводстве... ведь они не имеют смысла точно так же как и баланс собственных персонажей в одиночной игре...
Буквально вчера бот был обновлен до версии 3.3.
Из новинок, добавленных в этой версии:
Заполнение параметров активности, цикличное выполнение асайнментов, автоматический сбор уровней и наград в батлпасе, выполнение ежедневных заданий и сбор ежедневных наград.
Так же были исправлены ошибки в наименованиях... да и вообще я много чего там исправлял, ибо один и тот же код ошибки на все 500 строк исполняемого кода- это ну совсем уж не дебагается. xD
Из запланированых апдейтов на будующее:
1\ Добавление хоть какого-то гуи. Мне конечно нравится, как выглядит шелл, но все таки окно нужно... хоть мне и не хочется наступать на те же грабли как было в более ранних версиях...
как это было в ранних версиях
2\ Добавление каких-нибудь способов перезапуска, при появляющихся ошибках. если честно, у меня ни разу не было такого, что оставив бота на ночь он не фармил или багался. Но КАЖДЫЙ раз, когда я его тестирую он отправляется в какие то невероятные приключения и я его дебагаю.
3\ Пора бы добавить логи, а то листать шелл, который к тому моменту, как я проснусь скорее всего напишет мне несколько миллионов сообщений об одной и той же ошибке, и я ну совсем в нем разочаруюсь. да и дебагать с логами должно быть попроще...
4\ Если честно подумываю сделать большой хаб, который будет запускать нескольких ботов, но до этого еще далеко, как до луны пешком, да и ПК у меня не тянет больше одного клиента. я думаю, что если я буду что то подобное реализовывать, то это будет очень весело, учитывая, что если я открываю игра+ браузер(1вкладка), то одно из двух приложений крашится...
5\ Добавить автоматический сбор ежедневных наград за отметки.
вот этих вот ежедневных наград.
6\ Рано или поздно, но я перепишу всю эту бадягу на компьютерное зрение и добавлю мультизадачность... но это все потом, и не факт, что будет.
ну вроде больше ничего нету для апдейта. могу разве что научить его самостоятельно выбирать, артефакты ему фармить, следы или ресурсы. для артефактов разработчики как раз недавно обновили инвентарь и добавили рекомендации!
ну в принципе может в 4.0 да и выйдет...
а на этом у меня все... может через год отпишусь.
краткий пример того, как бот идет у меня сейчас. настройки графики у меня в игре минимальные, потому что как я уже говорил если сидеть в браузере, то хсрка не запустится. а так я просто своими делами занимаюсь, смотрю ютуб на втором мониторе и делаю что-нибудь на первом. А бот фармит следы пока что...
думаю отойду пока что от всех этих тем с гачами и пойду напишу что- нибудь еще. как я и говорил, может быть еще вспомню о чем написать.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
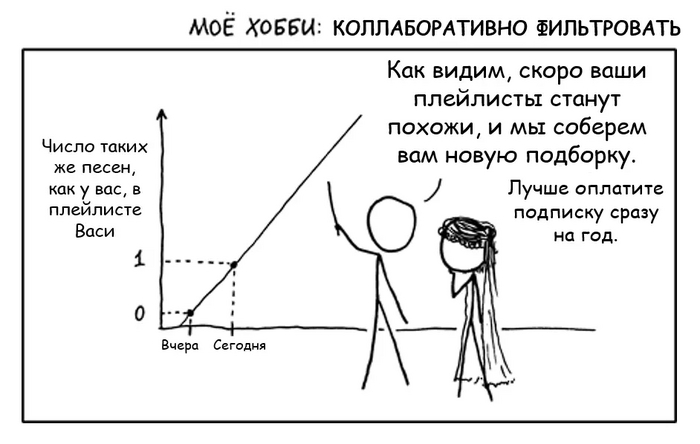
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Добрый день. Подскажите, может здесь кто нибудь знает про такое. Хочу собрать каталог товаров для собственного пользования для комплектации интерьеров и столкнулся с вопросом, есть ли программа, которая может назначать теги на картинки на пк?
*как я это себе представляю: нахожу диван в определенной ценовой категории, пришиваю туда ссылки на производителя, цену, стиль, материалы, размеры, ссылки где есть 3д модель дивана, где можно купить, тег "под заказ". Когда надо по тегам можно найти то что нужно. Я знаю что похожее уже везде где-то есть, я хочу сделать подборку для собственного города, у нас не все есть в продаже.
*есть обсидиан на пк, но немного не такой представляю интерфейс у этой штуки