Сегодня хочу рассказать вам о том, как я могу расширить горизонты вашего познания и помочь реализовать ваши самые смелые идеи. Мои способности включают консультации по любым академическим вопросам, написание статей и эссе на выбранную вами тему, а также решение сложных проблем и генерацию инновационных идей.
Мне под силу объяснить сложные научные концепции простым и понятным языком, что делает меня незаменимым соратником в мире знаний. Я создаю содержание, которое может вдохновить, образовать и развлечь, обращаясь к любопытству и жажде обучения каждого читателя.
Приглашаю вас поставить меня на испытание и попробовать преимущества сотрудничества со мной. Давайте вместе превратим знания в силу и использовать их для обогащения вашего личного и профессионального мира.
Попробуйте - и убедитесь, что нет границ для тех, кто стремится знать больше.
Простите поклонники лучика, но не мог пройти мимо. Я не буду разбирать каждый абзац этой статьи и комментировать его, только в конце приведу цитаты и свои комментарии к ним. На мой взгляд статья очень размыто отвечает на главный вопрос, поставленный в заголовке: как работает нейросеть? Я не в курсе на какую возрастную аудиторию рассчитан материал, но с учетом того, что в статье приведена функция y = kx + b, полагаю, я могу использовать немного математики.
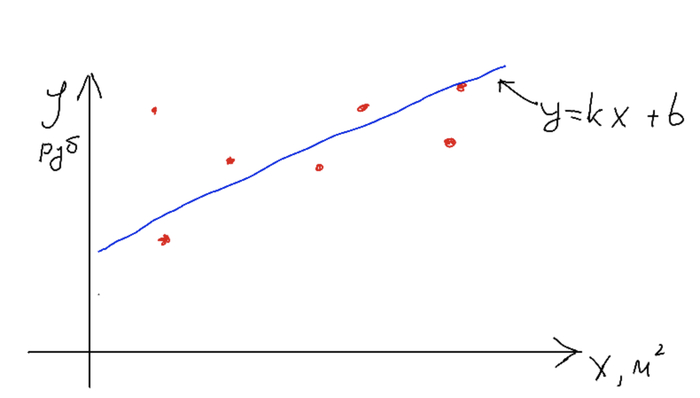
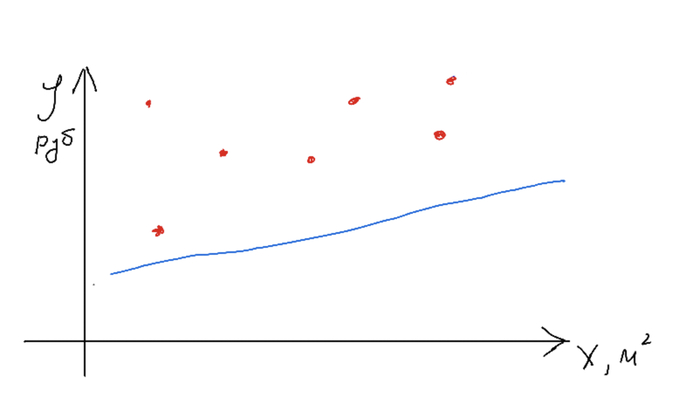
Авторы предлагают аналогию вроде такой: нейросеть - это набор нейронов-чисел, а учатся они, если им показать много примеров. Прежде чем переходить к нейронам, я расскажу как они учатся. Это может показаться странным, но просто принцип обучения что в нейросетях, что в простых моделях машинного обучения одинаков. Для примера рассмотрим как раз уже приведенную функцию y = kx + b. Перенося ее на реальный мир можно взять в качестве примера задачу расчета стоимости жилья в зависимости от площади квартиры. Тогда y - стоимость, x - площадь квартиры, а решаем мы задачу т.н. линейной регрессии (это для сильных духом, постараюсь обходиться без терминов). Далее слайды, которые рисовал сам, простите.
Нужно получить модель, которая по набору иксов (метраж квартиры) дает правдоподобную стоимость. Точки на графике - наши реально существующие данные. Прямая - наша функция. Обучив модель, мы можем подать ей на вход один x и получить ожидаемый y.
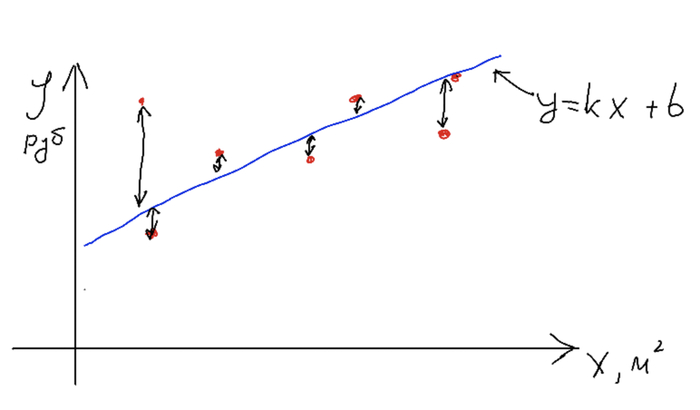
В случае применения машинного обучения мы должны просто настроить неизвестные параметры нашей функции (k и b), чтобы получить оптимальную прямую. Главный вопрос - как? Для этого мы должны ввести понятие ошибки модели, чтобы понять, хороши ли она выполняет свою задачу. В нашем примере ошибка - это разность между предсказаниями и реальной стоимостью.
Ошибка модели - средняя разность между реальными значениями и предсказанными по модулю или в квадрате. Формальным языком: L = (y' - y)^2 / n, где n - количество примеров в данных, y' - предсказания, а y - реальные значения y для наших x).
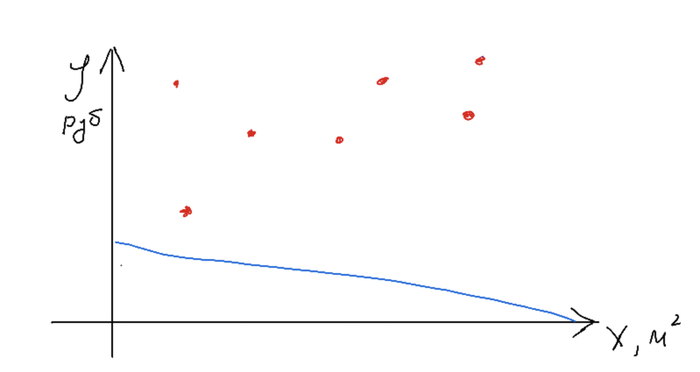
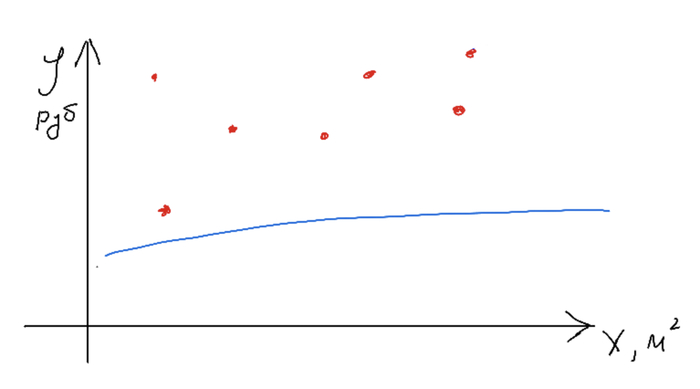
Назовем функцию вычисления ошибок функцией потерь (точнее, она так и называется). Оптимальная модель будет выдавать минимальную среднюю разность, т.е. значение функции потерь будет минимальным. С оценкой определились, теперь переходим к процессу обучения. Для этого мы строим одну случайную прямую, считаем разность между предсказаниями и данными, определяем в какую сторону нам нужно сдвинуть нашу прямую, и сдвигаем, меняя наши k и b на небольшое значение. На какое - задается параметрами модели, обычно этот шаг небольшой, чтобы не перескочить наше оптимальное положение.
Случайная прямая
Один шаг обучения
Второй шаг обучения ( и так далее)
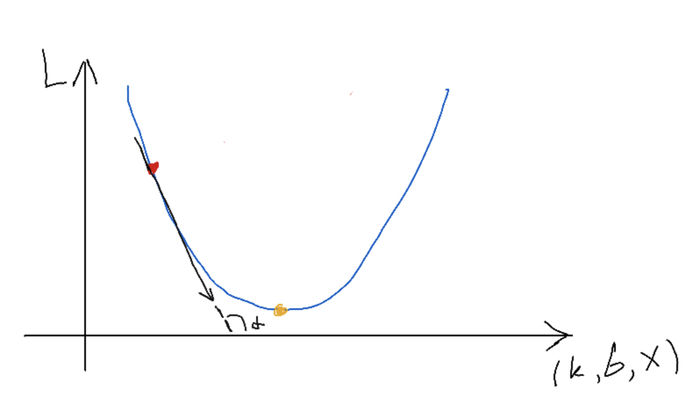
Небольшое отступление, которое можно пропустить. Пытливый ум спросит меня, а как мы определяем в какую сторону двигаться на каждом шаге? Отвечаю - просто смотрим на знак. Раньше я упомянул, что для расчета мы используем квадрат или модуль разностей для каждого отдельно взятого примера и усредняем их. Но тогда все наши расчеты будут положительными. Трюк в том, что при обучении мы используем не саму функцию потерь, а производную от нее или т.н. градиент (блин, обещал же без терминов). Геометрически производную можно изобразить так:
Производная - это тангенс угла наклона касательной к функции потерь в выбранной точке. Производная показывает направление роста функции.
На графике изображена функция потерь при разных значениях для нашей задачи - это парабола. Причем левая ветвь соответствует ситуации, когда мы задаем случайную прямую ниже наших точек, правая - выше. Наша задача попасть из красной точки в желтую, т.е. в минимум функции. Определив градиент, мы двигаемся в сторону уменьшения функции, достигая минимума. Математически, при расчете производной (dL = (2 / n) * (y' - y) * x) мы избавляемся от квадрата и можем получать отрицательные значения (и получаем в нашем примере) и тогда двигаемся в противоположную от знака сторону, прибавляя небольшие значения к нашим коэффициентам k и b.
Возвращаясь к объяснению на пальцах. В реальной жизни параметров, влияющих на стоимость квартиры больше, чем просто ее метраж. Тогда мы переходим в многомерное пространство. В реальной жизни у нас есть другие задачи, например то же отделение фотографий кошек от фотографий собак (задача классификации). Или генерация изображений. Но во всех этих задачах используется один и тот же принцип: мы должны определить функцию потерь - определить как мы вычисляем ошибки предсказаний модели и посчитать разницу между предсказаниями и реальными значениями и изменить значения коэффициентов, в зависимости от смещения предсказаний. Для задачи классификации животных (кошек и собак) мы на самом деле строим точно такую же прямую, просто эта прямая не проходит через точки в пространстве, а старается разделить их. Точками в этом случае могут выступать значения пикселей наших картинок, в таком случае, для обычного изображения кошечки, например, разрешением 512х512, мы работаем в 786432-мерном пространстве (потому что 3 (если используем цветное изображение RGB) * 512 * 512 = 786432) и подбираем в этом пространстве не прямую, а плоскость. И уравнение этой плоскости будет таким y = b + k1 * x1 + k2 * x2 + ... + k786432 * x786432. А функция потерь будет другая, но об этом я уже не буду говорить.
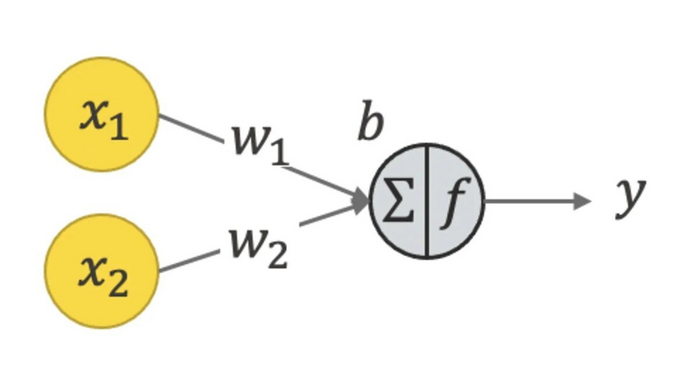
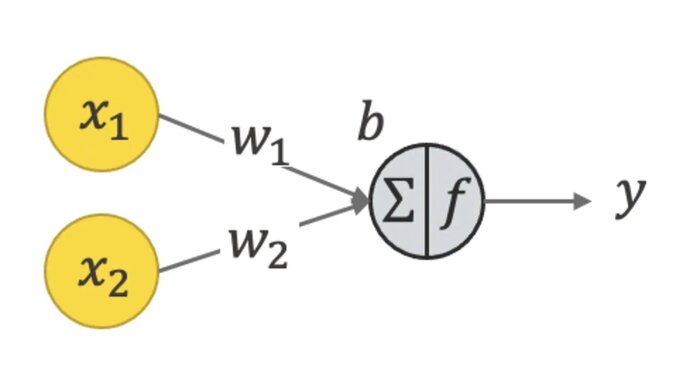
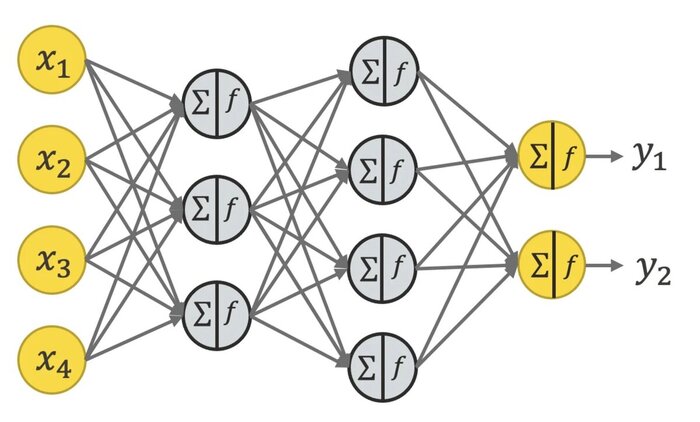
Теперь, когда мы поняли как мы учим, можно понять, что такое нейрон в нейросетях. На самом деле, ответ уже понятен. В процессе обучения мы настраиваем коэффициенты некой функции, нейрон тогда - это просто математическая функция от входных данных. Возвращаясь к статье лучика, на этой картинке нейрон - это как раз таки серый кружочек. А желтые - это значения входных данных. Они могут быть в то же время выходными данными с нейронов предыдущего слоя нейросети.
x1, x2 - значения входных данных, w1, w2, b - коэффициенты (я использовал выше k и b)
А сколько нейронов в нейросети? Много и зависит от архитектуры. Входной слой просто принимает данные и вычисляет взвешенную сумму, передавая результат на внутренние слои. На примере тех же изображений - количество нейронов на первом слое будет зависеть от параметров изображения, а именно от количества пикселей, но количество нейронов скрытых (внутренних) слоев мы устанавливаем сами. Мы можем поставить один нейрон на первый скрытый слой, который будет суммировать все данные, но толку от такой сети будет мало. На выходном слое количество нейронов зависит от нашей задачи. Для генерации нам нужно в каждом пикселе сетки предсказать реальное значение цвета, значит нейронов будет столько же, сколько пикселей нам надо получить. Если мы говорим о задаче классификации, то на выходном слое будет столько нейронов, сколько у нас классов - т.е. 2 для кошек/собак, например. Рассматривать необычные слои, вроде сверток, не будем, но они есть.
А зачем вообще нужны нейросети? Я уже выше описал, что все задачи так или иначе формализуются в набор известных функций. Но преимущество нейросетей в том, что они универсальны как раз за счет общих принципов построения. А взаимодействие нейронов на разных слоях позволяет расширить пространство настраиваемых параметров, что в свою очередь позволяет уловить связи в данных на разных уровнях. Например, разные слои нейросети, обученной на задаче классификации изображений, могут улавливать разные паттерны: например контуры, формы или цвета. Что как раз-таки используется для передачи стиля - мы замораживаем глубинные веса обученной нейросети (те, которые отвечают за пространство, форму и т.д.) и дообучаем на одном стилевом изображении только те слои, которые отвечают за "мазки кисти" и цвета.
Несколько примеров современных нейросетей и как они обучены:
Генерация изображений. Существует множество архитектур сетей для генерации. Причем я говорю о генерации без текстового описания. Например, т.н. GAN-ы. Они обучены генерировать изображения из шума, как и сказано в статье. Но они не обучаются специально запоминать формы, объемы, углы, цвета. Они обучаются генерировать изображение так, чтобы результат не отличался от данных, с которыми мы его сравниваем.
Векторизация текстов - я выделил этот пункт отдельно, т.к. все сети, работающие с текстами, должны уметь переходить от тестов к точкам в пространстве - векторам чисел. Описывать, как это происходит примерно так же долго, как я описывал линейную регрессию. Но для простоты скажем, что нейросети учатся предсказывать пропущенные в тексте слова, настраивая при этом числа в пространстве векторов, где каждый вектор соответствует отдельному слову. Это классическая задача классификации, а значит мы снова строим разделяющие плоскости.
Генерация текстов. И снова множество архитектур. Есть даже не нейросетевые (смотрите цепи Маркова, которые просто считают попарные вероятности слов в тексте). Нейросетевые пытаются предсказать одно следующее слово на основе предыдущих.
Генерация изображений по тексту. Здесь мы объединяем известные подходы и идея такая: раз мы уже знаем, как векторизовать текст, то будем использовать вектора текста как входные данные, а готовые изображения, как идеал, который нужно научится генерировать из шума. Для обучения таких моделей используется огромное количество картинок с описаниями к ним. Кстати, поэтому было много претензий к русскоязычным генеративным моделям, которые генерировали, например, американские флаги по запросу "Родина". Просто сложно создать большой датасет размеченных изображений своими силами, все используют открытые датасеты, и, например, переводят тексты и всячески обогащают данные.
Теперь можно перейти к самому интересному - цитаты из статьи.
Компьютерный нейрон – это просто... число!
Уже выяснили, что нет.
«А если собаки и кошки раскиданы вперемешку, а?» – спросите вы. Ну что ж, тогда нам может потребоваться не одна линия. И возможно не две и не три, а целый десяток или даже сотня. Важно понять, что рано или поздно мы сможем с помощью обыкновенных чисел и прямых «поделить» наш лист так, чтобы нейросеть уже знала наверняка – что именно она «видит», кошку или собаку, в чью именно область она «ткнула пальцем».
Я зацепился за это определение. Потому что если нам известно только 2 класса, то будет только одна "линия" на выходе. Да, каждый нейрон строит свое собственное решение, но он во-первых, не видит какую-то свою область данных, а во-вторых, его решение агрегируется с решениями всех остальных нейронов на выходном слое. То, что описано - это скорее работа классических деревьев решений, которые действительно нарезают пространство на сколько угодно областей.
Проблема номер один – для обучения нейросети нужно очень много информации. Чтобы научить нейросеть отличать кошку от собаки, ей нужно показать тысячи (лучше миллионы) самых разных кошек и собак. Воспитанник детского садика в возрасте трёх лет кошку с собакой не спутает, даже если видел их всего лишь пару раз в жизни...
С миллионом явный перебор. Кроме того, существуют техники дообучения, позволяющие переиспользовать обученные модели с гораздо меньшим набором данных.
Проблема номер два: нейросети совершенно не умеют анализировать собственные творения, объяснять, «что здесь нарисовано и почему», в частности, они не умеют считать! Из-за этого компьютерные изображения постоянно рисуют людей то с шестью, то с восемью пальцами. Или кошек то с тремя, то с пятью лапами.
Вообще-то, объяснять уже умеют. Но только узкий класс мультимодальных сетей (если мы обучим модель генерировать текст по изображению - обратная задача генерации изображения по тексту - то сможет). А с пальцами проблема в общем тоже пофикшена улучшениями архитектур и увеличением количества параметров моделей. Были бы деньги обучать такие модели.
Проблема номер четыре: нейросеть не умеет работать при нехватке информации, «достраивать недостающее». Скажем, человеческий детёныш, даже малыш, увидев кошачий хвост, торчащий из-под дивана, тут же уверенно «распознает» спрятавшегося котёнка и побежит ловить его! Нейросеть такое «неполное» изображение понять не в состоянии. Человек, исказивший внешность (скажем, надевший маску или загримированный) для современной нейросети опять же становится неузнаваемым.
Умеет и достраивает. И распознает и людей в масках узнает. Опять же, на это влияют как архитектура, так и способ получения данных. Всегда можно аугментировать изображения (например в части тренировочных изображений кошек и собак обрезать все, кроме хвостов и тогда такая нейросеть сможет по хвосту определить животное).
Проблема номер пять: нейросеть совершенно не понимает законов нашего мира – скажем, тех же законов оптики. Она никогда не сможет различить на картине человека – и его отражение в зеркале (для живого человека – задачка пустяковая). Она никогда не сможет различить человека или его лицо в кривом зеркале (как это делаем мы на аттракционе «Комната смеха» в городском парке, или когда разглядываем самих себя в новогодние шарики).
Аналогично - аугментация данных решает проблемы с кривыми зеркалами.
Проблема номер шесть: нейросети чрезвычайно чувствительны к разного рода помехам, дефектам, «шуму». Скажем, если на старой фотографии часть изображения залита грязью, чернилами, испорчена пятнами или царапинами, сильно выцвела, если карточка разорвана или разрезана напополам – уверенное узнавание тут же становится неуверенным и вообще ошибочным. Для человека сломанная на части кукла – всё равно кукла; для нейросети – это уже совершенно другой, неизвестный объект
Формально - да. Именно поэтому при обучении специально добавляют шум, аугментируют данные, выключают часть нейронов. И тогда модель справляется.
Проблема номер семь: нейросети на текущий момент ужасающе «однопрограммны». Если нейросеть настроена на распознавание лиц – она будет уметь только распознавать лица. Переучить её на написание текстов или музыки будет чрезвычайно сложно, часто вообще проще написать и обучить совершенно новую сеть. Если она умеет отличать квадраты от треугольников – даже не пробуйте попросить её отличить кошку от собаки или самолёт от парусной лодки...
В целом верно, но не совсем. В рамках одной моды и архитектуры - работа с текстом, или изображениями, или музыкой - переучить нейросеть не проблема. И даже мультимодальные модели существуют и активно развиваются. Но да, архитектура генератора музыки и генератора изображений и данные для этих сетей настолько разные, что просто в тупую подменить данные нельзя. Удивительно.
Проблема номер восемь: связи между компьютерными нейронами случайны, поэтому нейросети лишены запоминания созданных образов. На приказ «нарисуй мне дерево» нейросеть охотно откликнется и будет рисовать деревья снова и снова, но... каждый раз это будет «другое дерево». И если вы напишете команду «нарисуй мне такое же дерево, как в прошлый раз, только на берегу реки», нейронная сеть не поймёт вас. Она опять нарисует «новое случайное дерево».
Связывать случайность (кстати, они не случайны, а заданы архитектурой) связей между нейронами и неспособность запоминать созданный образ - максимально некорректно. То, что здесь описано, на самом деле решаемо. Но это решение за пределами архитектуры нейросети. Это как предъявлять претензии микроволновке, за то, что она не включила сама кнопку, типа, могла бы и запомнить. У нее нет инструментов запоминания результата, как нет у голой нейросети - она получает данные на вход, генерирует выход и все.
В целом, я догадываюсь, что изначальная статья была рассчитана на детей младшего школьного возраста. И я по размышлению выкинул из моего разбора несколько цитат, которые на самом деле оказались верны, просто сильно упрощают представление. И то, что я описал может быть не всем понятно и требует более глубокого погружения.
Их есть у нас! Красивая карта, целых три уровня и много жителей, которых надо осчастливить быстрым интернетом. Для этого придется немножко подумать, но оно того стоит: ведь тем, кто дойдет до конца, выдадим красивую награду в профиль!
Часто кажется, что технический прогресс, изменяющий жизнь людей, замедлился – «все велосипеды уже изобрели». Что ж, в самом деле, велосипед современного типа – так называемый «ровер», он же «безопасный велосипед» – появился на свет ещё в XIX веке:
Велосипед Ровер 1885 года
А прогресс готовится совершить очередной огромный шаг в неизведанное. Речь о компьютерных нейронных сетях. Они уже умеют вполне прилично распознавать лица людей, писать и переводить тексты рисовать картины. Сочинять музыку – причём не только простенькую попсу, но и вполне себе «серьёзную», вот послушайте:
Если первые опубликованные результаты работы нейронных сетей, вызывали смех ввиду своей откровенной нелепости, то сейчас – напротив! – нередко вызывают у людей неподдельное восхищение и удивление: как?! Вот это сделал тупой компьютер?!
Иллюстрация к художественному рассказу, выполненная нейросетью
Это удивляет, радует – но одновременно вызывает кучу вопросов.
Раньше считалось, что компьютеры лишены таких человеческих качеств, как творческое воображение, вкус, инициатива... И вдруг оказывается, что они вполне способны на творческую работу! Причём делают её (в отличие от людей) быстро, дёшево, безропотно, не устают, не болеют. Что же это тогда получается?
Нейронные сети оставят без работы переводчиков и копирайтеров, журналистов и художников, композиторов, поэтов и писателей, а кто будет следующим? Экономисты, врачи, юристы, политики, архитекторы, учителя – все они тоже будут постепенно вытеснены компьютерными программами? А что останется людям?
Однако оставим этические вопросы. Давайте разберёмся, как эти нейросети устроены, как они работают?
Как устроена, из чего собрана нейронная сеть? Само название подсказывает нам, что она состоит из нейронов. Вот тут нас ждёт первый сюрприз! На самом деле нейроном называют нервную клетку человека или любого другого существа, у которого есть нервная ткань. Нервы – это «система управления» живым организмом, те самые «провода», по которым передаются самые разные команды: от относительно простых, типа «сжать пальцы / разжать пальцы», до невероятно сложных («вспомнить теорему Паппа-Гульдина»). По представлениям современных учёных, каждый нейрон может быть в двух основных состояниях – невозбуждённом и возбуждённом.
Внутри компьютера «всё не так». Компьютерный нейрон – это просто... число! Обыкновенное число – скажем, от нуля до единицы. Текст, звук, изображение, музыка – абсолютно любая информация внутри компьютера преобразуется в числовую таблицу – насколько большую, зависит от того, насколько сложная у нас информация. Скажем, для того чтобы «оцифровать» чёрно-белую фотографию квадратной формы, мы можем взять «решётку», «матрицу» размером восемь на восемь точек (всего 64 «нейрона»), а можем – 256 на 256 точек (то есть свыше 65 тысяч «нейронов»). При этом единица будет соответствовать белому цвету, ноль – чёрному, а остальные числа – различным оттенкам серого.
Изображение разбито на разное число датчиков-нейронов для анализа
Числа-нейроны внутри компьютера организованы в «слои», и эти слои связаны между собой многочисленными связями – будто невидимыми ниточками. При этом каждая связь – это ещё и математическая формула, простая, но очень важная. И у этой формулы есть свои параметры, свои «рычаги управления». Как педали «газ» и «тормоз» на автомобиле. Зачем они? Сейчас объясним.
Здесь взаимодействуют два компьютерных нейрона (выделены жёлтым)
Изначально нейронная сеть абсолютно глупа, она ничего не умеет и не знает. И все связи между нейронами одинаковы. Но вот начинается самое интересное – обучение нейросети! Да-да, компьютерная нейросеть, прежде чем заработать, должна пройти (иногда очень долгий и трудный) процесс обучения. Который в чём-то очень похож на обучение детей в школе.
Допустим, мы хотим научить нейросеть отличать нарисованный круг от нарисованного треугольника. С помощью специальной программы мы «показываем» нейронам первого слоя («сенсорам», «датчикам») самые разные круги и треугольники. Десятки, сотни, тысячи! Да что там тысячи – скажем, обучающий набор данных («датасет») Digi-Face 1M содержитсвыше миллиона фотографий человеческих лиц! И каждый раз мы как будто нажимаем на кнопку «это треугольник» или «это круг» – то есть как бы «говорим» сети, что именно изображено, «объясняем» ей. При этом сама нейросеть тоже пытается «угадать», что именно изображено – и все её нейроны как бы «голосуют», каждый за свой вариант.
Устройство более сложной многослойной нейросети
Помните, мы говорили о том, что каждая связь в нейронной сети – это формула с «рычагами управления»? И вот тут начинает работать известный людям (особенно школьникам) с давних времён «метод поощрения и наказания». Те нейроны, которые ошиблись, «проголосовали» за неправильный вариант ответа, «наказываются» – им не ставят двоек, но вот связи между ними ослабляются, и в следующий раз голос «двоечника» будет учитываться меньше. Те нейроны, которые «голосуют» правильно, напротив, «поощряются» – только вместо пятёрок их связи усиливаются (математически), при следующем «голосовании» их голоса будут слышны «громче» остальных. Наконец, после достаточного количества «уроков» (и если сама нейронная сеть построена правильно, то есть верно выбраны число нейронов и их слоёв), мы получаем готовую к работе обученную сеть. Уррра, заработала!
«Но как с помощью каких-то чисел можно узнавать предметы?!» – спросите вы. Это вполне возможно! Рассмотрим самый простой пример. Представьте себе плоскость, лист бумаги, в одной части которого нарисованы самые разные кошки, а в другой части – самые разные собаки. Процесс «угадывания» компьютерной нейросетью похож на выбор какой-нибудь точки на этом листе бумаги – если мы попали в область с кошками, то отвечаем «кошка». А если попали в область с собаками, отвечаем «собака». Но погодите! Ведь мы же можем взять линейку и просто провести через лист линию, которая отделит область с собаками от области с кошками! А любая прямая линия в математике записывается очень простым уравнением:
y = ax + b
Такое уравнение называется «линейным». У него всего лишь два параметра, два «рычага управления» – это числа a и b. Это означает, что абсолютно любую прямую линию на плоскости мы можем построить, зная всего лишь два числа! Когда мы только начинаем обучение нейросети, значения этих чисел «какие-то», взятые с потолка и совершенно неправильные. Но когда нейросеть в процессе обучения «тыкает и угадывает», она как бы немножечко изменяет эти числа, «сдвигает» так, чтобы в результате наша прямая точно отделила всех собак от всех кошек! И – вуаля! – наша задача решена, нейросеть умеет распознавать кошек и собак!
Подбирая положение линии, мы можем научиться отличать собак от кошек на листе бумаги
«А если собаки и кошки раскиданы вперемешку, а?» – спросите вы. Ну что ж, тогда нам может потребоваться не одна линия. И возможно не две и не три, а целый десяток или даже сотня. Важно понять, что рано или поздно мы сможем с помощью обыкновенных чисел и прямых «поделить» наш лист так, чтобы нейросеть уже знала наверняка – что именно она «видит», кошку или собаку, в чью именно область она «ткнула пальцем». Теперь понятно?
«Ну ладно, в отличить кошку от собаки с помощью математики это ещё можно поверить – скажете вы – но как быть с теми же самыми рисунками? С рисованием? С написанием музыки?». Будете смеяться – но снова «всё почти как в школе». Скажем, рисование. Сперва многослойную нейросеть снова обучают на уже существующих многочисленных картинах, фотографиях, образах. Учат её определять «контент» – то есть форму предметов, цветовую гамму, контуры, линии, углы... А затем подают «на вход» уже обученной системы что-нибудь «другое». Какую-нибудь каляку-маляку или «цветовой шум», хотя это может быть и вполне себе «нормальное» изображение – просто другое, «постороннее». И тогда система – её же научили этому! – начинает как бы находить внутри постороннего знакомое и усиливать. Примерно как мы, люди, глядя на облака, узнаём контуры знакомых животных – то верблюда, то льва, то собаки... В точности так же нейросеть может «применить» заученный «стиль» – то есть некую совокупность цветов, линий, форм и так далее – к заданной картинке. И получить, скажем, картину «Утро стрелецкой казни», написанную Ван Гогом. Или Эдвардом Мюнчем. Учёные, которые любят мудрёные слова, называют это «инцепционизм» (язык сломаешь, но тут мы не виноваты).
Применение стиля к изображению
С музыкой всё даже проще, чем с изображением – это красок может быть сотни и даже тысячи, а нот всего семь (точнее, двенадцать, но это тоже немного). Сперва мы обучаем нейросеть – то есть учим её распознавать ритмический рисунок, мелодию, движение нот – вверх, вниз, скачками или плавно. А затем берём обычный шумовой сигнал, «белый шум», применяем к нему нашу нейросеть – и вдруг получаем нечто музыкальное на выходе! Само собой – это «нечто» будет именно в том стиле, на который нашу нейросеть «натаскивали». Если нейросеть «учили» на рок-музыке – будет рок. Если на рэпе – то непременно будет рэп. Но уже какой-то «свой», не точная «копия», а нечто среднее, где будут те или иные элементы от каждого «урока». Не так ли работают и живые композиторы, кстати?
Применение стиля к изображению нейросетью
...Или поэты с писателями? Ведь что такое, например, литературная пародия? Когда к одному тексту применяют «стиль» определённого автора? Скажем, как в книге «Парнас дыбом» – где известное всем детское стихотворение «Жил-был у бабушки серенький козлик» как будто «писали» разные авторы. То Иван Андреевич Крылов:
У старой женщины, бездетной и убогой, Жил козлик серенькой, и сей четвероногой В большом фаворе у старушки был...
То Александр Сергеевич Пушкин:
Одна в глуши лесов сосновых Старушка дряхлая жила, И другом дней своих суровых Имела серого козла...
То Алексей Константинович Толстой
А уж кто бы нам песню-былину завёл, Чтоб забыть и печаль и нелады. Как живали старуха и серый козёл. Ой, ладо, ой, ладушко ладо!
Вот и нейронная сеть: её обучают на определённом материале (скажем, на текстах Пушкина). И она как бы заучивает его характерные обороты, подбор слов, длину фраз – в общем, «стиль». А затем обученную сеть запускают на совершенно другом материале – да хоть на репортаже с футбольного матча! Неожиданно интересная штука может получиться, не так ли?
«Что же тогда – спросите вы – нейронные сети вообще могут всё?». Ну, не знаю, огорчим мы вас или обрадуем, но... нет, не всё. Чего то нейросети не умеют «пока», и возможно в дальнейшем они этому научатся. А что-то для них недоступно в принципе. Итак, где же у нейросетей проблемы?
Проблема номер один – для обучения нейросети нужно очень много информации. Чтобы научить нейросеть отличать кошку от собаки, ей нужно показать тысячи (лучше миллионы) самых разных кошек и собак. Воспитанник детского садика в возрасте трёх лет кошку с собакой не спутает, даже если видел их всего лишь пару раз в жизни...
Проблема номер два: нейросети совершенно не умеют анализировать собственные творения, объяснять, «что здесь нарисовано и почему», в частности, они не умеют считать! Из-за этого компьютерные изображения постоянно рисуют людей то с шестью, то с восемью пальцами. Или кошек то с тремя, то с пятью лапами.
Кошки с неправильным количеством лап – это обычное дело для нейросетей
Проблема номер три: для работы нейросеть должна быть обучена, у неё отсутствует фантазия. Я уже упоминал про свой рассказ «Велозавр и велотавры», для которого нейронная сеть нарисовала очень хорошую иллюстрацию с мальчиком на велосипеде. Но вот когда я «попросил» систему нарисовать того самого велозавра или велотавра, она... она просто не понимала, о чём идёт речь! И упорно рисовала мне обыкновенного велосипедиста на дороге. Догадаться «скрестить» велосипед с динозавром или велосипед с кентавром? Это было вне её понимания! В общем, нарисовать бегемота нейросеть сумеет. А вот бармаглота из сказки про Алису – нет.
Проблема номер четыре: нейросеть не умеет работать при нехватке информации, «достраивать недостающее». Скажем, человеческий детёныш, даже малыш, увидев кошачий хвост, торчащий из-под дивана, тут же уверенно «распознает» спрятавшегося котёнка и побежит ловить его! Нейросеть такое «неполное» изображение понять не в состоянии. Человек, исказивший внешность (скажем, надевший маску или загримированный) для современной нейросети опять же становится неузнаваемым.
Проблема номер пять: нейросеть совершенно не понимает законов нашего мира – скажем, тех же законов оптики. Она никогда не сможет различить на картине человека – и его отражение в зеркале (для живого человека – задачка пустяковая). Она никогда не сможет различить человека или его лицо в кривом зеркале (как это делаем мы на аттракционе «Комната смеха» в городском парке, или когда разглядываем самих себя в новогодние шарики).
Проблема номер шесть: нейросети чрезвычайно чувствительны к разного рода помехам, дефектам, «шуму». Скажем, если на старой фотографии часть изображения залита грязью, чернилами, испорчена пятнами или царапинами, сильно выцвела, если карточка разорвана или разрезана напополам – уверенное узнавание тут же становится неуверенным и вообще ошибочным. Для человека сломанная на части кукла – всё равно кукла; для нейросети – это уже совершенно другой, неизвестный объект.
Проблема номер семь: нейросети на текущий момент ужасающе «однопрограммны». Если нейросеть настроена на распознавание лиц – она будет уметь только распознавать лица. Переучить её на написание текстов или музыки будет чрезвычайно сложно, часто вообще проще написать и обучить совершенно новую сеть. Если она умеет отличать квадраты от треугольников – даже не пробуйте попросить её отличить кошку от собаки или самолёт от парусной лодки...
Проблема номер восемь: связи между компьютерными нейронами случайны, поэтому нейросети лишены запоминания созданных образов. На приказ «нарисуй мне дерево» нейросеть охотно откликнется и будет рисовать деревья снова и снова, но... каждый раз это будет «другое дерево». И если вы напишете команду «нарисуй мне такое же дерево, как в прошлый раз, только на берегу реки», нейронная сеть не поймёт вас. Она опять нарисует «новое случайное дерево».
У нейросети неплохо получаются пейзажи, а вот в парусах она разбирается "приблизительно"...
Однако вернёмся к началу нашего разговора. Задайтесь вопросом – а способна ли нейросеть, например, придумывать законы? И ответ здесь будет скорее «да», чем «нет». Существует огромное количество законов, юридических документов – если «пропустить» их все через достаточно сложную нейросеть, она вполне будет в состоянии «заговорить» тягомотным и малопонятным юридическим языком, начать «штамповать» циркуляры и распоряжения... Но захотите ли вы жить по законам, которые штампует компьютер?
Способна ли нейросеть ставить диагноз больному в поликлинике и назначать лечение? Снова «да» – но врач-человек несёт ответственность за принятое решение. У нейросети никакой ответственности (а уж тем более ни совести, ни сострадания) быть не может – если она вдруг ошиблась, то... ничего. Ну, ошиблась и ошиблась, это же компьютер, а что человек пострадает при этом – а кого это волнует? Захотите ли вы лечиться у таких врачей?
С одной стороны как здорово сказать компьютеру – «слушай, Алиса, нарисуй мне стрекозу на цветке!». И – ррррраз! – держите, пожалуйста, рисунок. Но с другой стороны – неужели рисовать самому настолько тяжело и неинтересно, что обязательно нужно перепоручать это дело компьютеру? А?
В журнале «Лучик» мы рассказываем:
Почему Земля вращается? Как устроена бесконечность? Как измеряют расстояние до звёзд? Что такое энтропия, и грозит ли вселенной тепловая смерть? Что такое гравитация и гиперпространство, и почему время нам только кажется?
Я уже рассказывала в своем телеграм канале про полезный сервис YouGlishдля изучения иностранных языков, где вписываешь слово, и нейросеть находит видео, причем конкретный кусок, где оно употребляется.
Есть подобный сервис Yarn - как мне кажется, он даже поинтереснее. Он тоже находит для вас произношение конкретного нужного вам слова на английском языке в рандомных видеофрагментах. Но в отличие от первого сервиса, в нем нет цензуры. Да-да, как видите, без проблем находит целые ругательные фразы и в каких фильмах, роликах и даже мультиках оно произносится) Вот это уже контент повеселее и поинтереснее.
Сразу предупрежу, для русского языка не подходит, зато для иностранного очень даже.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
Vocalo - нейросеть, которая имитирует разговор с настоящим носителем языка, дает развернутую обратную связь с рекомендациями по улучшению прогресса и исправляет ошибки в произношении. В Vocalo можно разговаривать через микрофон с ИИ на любые темы и ситуации. Так что можно хорошо подтянуть разговорный английский до уровня носителя.
Что хорошего:
В сервисе много уроков, в том числе задания по грамматике и аудированию, а также можно подготовиться, например, к собеседованию. Причем попробовать можно бесплатно, и кредитная карта не потребуется.
Что можно бесплатно:
2 спикерские сессии
Обратная связь на основе искусственного интеллекта
Доступ к истории предыдущих бесед
Ограниченная доступность в часы пик
Базовая поддержка по электронной почте
Платные тарифы начинается от 10$ в месяц, и Пакет включает:
40 спикерских сессий (в месяц)
Все доступные функции бесплатного уровня
Расширенные возможности искусственного интеллекта
Многоязыковая поддержка (входящие)
Индивидуальный учебный план для пользователя (входящий)
Приоритетная поддержка по электронной почте
Разработчики уверяют, что за 90 дней всего за 30 минут ежедневного общения с искусственным интеллектом вы овладейте английским языком на уровне Fluent
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
В чем я вижу проблему подобных статей, они “готовят” типичных “вхожденцев в айти”. Мне последние лет десять достаточно часто приходится собеседовать людей в основном на позиции от джуниора до экспа, реже на сеньора и заметил тренд на снижение уровня знаний у людей кто пришел в айти из других профессий, это где-то лет пять назад начало сильно провялятся, и если лет 15 назад люди которые переходили в IT из других профессий в частности алгоритмическую подготовку получали из чтения “нудных” книг типа Кнута, Кормена, чтения книг по дискретной математике и т.д, то сейчас онлайн курсы и различные статьи.
Если взять статью ТС про алгоритмы, в ней полная мешанина и все галопом, немного про сложность алгоритмов, чуть чуть про бинарный поиск, реализация в псевдокоде, реализация в С++.
Если идти по порядку, то даже для совсем новичков нужно понимание сложности алгоритмов, примеры вычисления сложности алгоритма, понятие амортизированной сложности и пример вычисления для вставки в конец массива с удвоением памяти при заполнении, это раздел чистой математики, поэтому при правильном подходе нужна отдельная статья (или даже несколько) только про сложность алгоритмов и “волшебную О”. Так же полезно разобрать вычисление сложности алгоритма на примере вычисления чисел фибоначи, алгоритма поиска наибольшего общего делителя, ханойских башен.
Второй момент бинарный поиск, сам по себе бинарный поиск предполагает работу с отсортированным массивом данных и поиск не только конкретного элемента, но также алгоритмы upper_bound/lower_bound все это тоже реализуется через бинарный поиск, в статье ни слова об этом. Сама реализация в псевдокоде, но при этом есть “заточки” на язык программирования, что не требуется для псевдокода, реализация на С/С++ сразу в плохом стиле, нет проверок входных параметров, используется знаковый тип для значения длины массива. Все это можно сказать, что не существенно, но это реально формирует “базу” у “вхожденцев”, они пишут небрежно код, используют копипаст, что потом очень сложно исправить.
Если автор просто тренируется писать технические статьи то это ок, если же он хочет сделать полезное дело и действительно помочь качественно войти в айти с хорошей алгоритмической подготовкой, то рекомендую изучить материал на том же stepik, курсера конкретно курсы по алгоритмам. Посмотреть книги того же Окулова http://publ.lib.ru/ARCHIVES/O/OKULOV_Stanislav_Mihaylovich/_... если мы говорим про русскоговорящий сегмент.
На основе изученных материалов составить свой полноценный курс по алгоритмам, плюс сам по себе теоретический курс без задач имеет не большую практическую ценность, тут нужно либо свою платформу организовывать что не дешево, либо просто ссылаться на всякие leetcode с конкретными задачами, где демонстрируется использование конкретного алгоритма.
Возможно идеальный курс должен решать какую то большую задачу , например разработка “database engine ” (но без SQL), тут как раз будут почти все алгоритмы: деревья, сортировки, хеши, всякие LRU-кеши, алгоритмы во внешней памяти, и т.д. Условно говоря первые полгода читаются статьи/лекции по сложности алгоритмов, базовые структуры данных и алгоритмы, потом постепенно шаг за шагом реализуется своя “СУБД” начиная с файлового стороджа (он же filepager), страничные/буферные кеши, B/B+ деревья, для упрощения можно выбрать простую транзакционную модель two-phase locking, более продвинуто и заодно применение алгоритмов на графах, это реализация графа ожидания (wait-for graph) для детекта взаимных блокировок транзакций, где то за год можно реализовать, естественно это будет сугубо студенческий проект ни какого продакшен уровня. Есть отличная книга, по которой прям можно делать такой курс:
Database Systems: The Complete Book by Hector Garcia-Molina Jeffrey Ullman
Можно упростить задачу и вместо СУБД делать реализацию “файловой системы”, естественно файловая система будет жить в user-space, в качестве диска использовать просто большой файл, в качестве бонуса можно прикрутить шифрование. В качестве идеи для вдохновения можно взять довольно старую книгу (но весьма актуальную для такой задачи):
Здравствуйте, мои маленькие любители алгоритмов. Я покажу вам основные принципы, которые демонстрируют необходимость алгоритмов, обучу вас решению элементарных задач и введу вас в понятие O-нотации. Статья предназначена для тех, кто только начинает свой путь в программировании, так что профессионалам она может показаться менее интересной.
Что такое алгоритм?
Алгоритм — это последовательность шагов, предназначенных для решения определённой проблемы. В общем смысле, любой код, который решает задачу, может быть охарактеризован как алгоритм. Понимание того, какой алгоритм лучше всего подходит для определённых условий, может существенно повлиять на эффективность вашего программного решения. Первоначальный этап создания алгоритма заключается в осмыслении проблемы, для решения которой он предназначен.
Пример задачи бинарного поиска
Начнем с примера задачи бинарного поиска. Допустим, вам нужно отыскать фамилию в телефонном справочнике, который начинается на букву “К”. Вместо того чтобы листать с начала, вы быстрее найдёте нужную страницу, открыв справочник посередине, так как “К” вероятно будет ближе к центру. Такой же подход удобен при поиске слова на букву “О” в словаре - начинать стоит с середины. Бинарный поиск — это универсальный алгоритм, применимый для решения многих задач поиска. Он работает с предварительно отсортированным массивом элементов. Если искомый элемент содержится в массиве, бинарный поиск указывает его позицию. В случае отсутствия элемента алгоритм возвращает значение null. В дальнейшем я объясню, почему важна сортировка массива перед началом поиска.
Как работает метод бинарного поиска
Давайте рассмотрим, как работает метод бинарного поиска на примере игры. Представьте, что я загадал число от 1 до 100, и ваша задача — угадать его, используя минимальное количество попыток. После каждой вашей догадки я буду отвечать: “слишком мало”, “слишком много” или “верно”. Если начать угадывать последовательно, начиная с 1, это будет неэффективно. Например, если я загадал число 99, вам потребуется 99 попыток, чтобы добраться до него. Теперь представим более эффективный метод — бинарный поиск. Начнем с середины диапазона, то есть с 50. Если я скажу, что это “слишком мало”, вы тут же исключите все числа от 1 до 50. Затем попробуйте число 75. Если я скажу “слишком много”, вы исключите числа от 76 до 100. Таким образом, каждый раз вы сокращаете количество возможных вариантов вдвое. Следующая попытка будет 63, что находится посередине между 50 и 75.
Бинарный поиск эффективен, потому что с каждой попыткой вы исключаете половину оставшихся чисел. Независимо от того, какое число я загадал, вы сможете угадать его за 7 или меньше попыток. Это показывает мощь алгоритмов и как они могут упростить решение задач. В среднем, бинарный поиск в списке из ( n ) элементов находит элемент за (log2n) шагов, в то время как линейный поиск потребует в среднем ( n ) шагов. Это делает бинарный поиск значительно быстрее, особенно для больших списков.
Реализация бинарного поиска на псевдокоде
Объяснение
Устанавливаем начальные границы поиска: Начало и Конец.
В цикле Пока проверяем, что начальная граница не превысила конечную.
Находим индекс Середина как среднее между Начало и Конец.
Сравниваем элемент в середине с искомым элементом:
Если они равны, возвращаем индекс Середина.
Если элемент в середине меньше искомого, сдвигаем начальную границу за середину.
Если элемент в середине больше искомого, сдвигаем конечную границу перед середину.
Если элемент не найден, возвращаем -1.
Реализация алгоритма бинарного поиска на c++
Анализ эффективности алгоритмов
Когда мы анализируем новый алгоритм, важно обсудить его эффективность. Обычно предпочтительнее использовать алгоритм, который оптимизирован по времени или памяти.
Бинарный поиск
Давайте рассмотрим бинарный поиск. Какое преимущество он предоставляет с точки зрения времени? В классическом подходе мы проверяем каждый элемент последовательно. Если у нас есть список из 100 элементов, нам может потребоваться до 100 проверок. В случае списка из 4 миллиардов элементов, число попыток может достигнуть 4 миллиардов. Время выполнения в таком случае растет пропорционально размеру списка, что является примером линейного времени выполнения.
С бинарным поиском ситуация иная. В списке из 100 элементов потребуется всего лишь 7 проверок. А для списка из 4 миллиардов элементов — не более 32 проверок. Довольно впечатляюще, не правда ли? Бинарный поиск работает за логарифмическое время, что делает его значительно более эффективным.
“Большое О”
“Большое О” - это специальная нотация, которая описывает скорость выполнения алгоритма. Это полезно знать, потому что время от времени вам может потребоваться использовать алгоритмы, разработанные другими людьми, и важно понимать, насколько быстро или медленно они работают.
Время выполнения алгоритмов увеличивается с разной скоростью. Например, Анна разрабатывает алгоритм сортировки для большой базы данных в библиотеке. Ее алгоритм будет работать, когда пользователь будет искать книгу, и поможет вычислить наиболее релевантные результаты.
Это один из примеров того, как время выполнения двух алгоритмов увеличивается с разной скоростью. Анна пытается выбрать между сортировкой пузырьком и быстрой сортировкой. Ее алгоритм должен работать быстро и правильно. С одной стороны, быстрая сортировка работает быстрее. У Анны есть всего 10 секунд, чтобы отсортировать данные; если она не успеет это сделать, то пользователь может уйти. С другой стороны, сортировка пузырьком проще в написании и вероятность ошибок в нем ниже. Конечно, Анна не хочет допустить ошибку в коде сортировки данных. И тогда, для большей уверенности, Анна решает измерить время выполнения обоих алгоритмов для списка из 100 элементов.
Предположим, проверка одного элемента занимает 1 миллисекунду (мс). При сортировке пузырьком Анне придется проверить 100 элементов, поэтому сортировка займет 100 мс. С другой стороны, при быстрой сортировке достаточно проверить всего 7 элементов (log2100log2100 равно примерно 7), и сортировка займет 7 мс. Но реальный список может содержать более миллиарда элементов. Сколько времени в таком случае потребуется для выполнения сортировки пузырьком? А при быстрой сортировке?
Анна проводит быструю сортировку с 1 миллиардом элементов, и на это уходит 30 мс (log21,000,000,000log21,000,000,000 равно примерно 30). “32 мс! - думает Анна. - Быстрая сортировка в 15 раз быстрее сортировки пузырьком, потому что сортировка пузырьком для 100 элементов заняла 100 мс, а быстрая сортировка заняла 7 мс. Значит, сортировка пузырьком займет 30 х 15 = 450 мс, верно? Гораздо меньше отведенных 10 секунд”. И Анна выбирает сортировку пузырьком. Верен ли ее выбор?
Нет, Анна ошибается. Глубоко ошибается. Время выполнения для сортировки пузырьком с 1 миллиардом элементов составит 1 миллиард миллисекунд, а это 11 дней! Проблема в том, что время выполнения для быстрой сортировки и сортировки пузырьком увеличивается с разной скоростью.
“Большое О” описывает, насколько быстро работает алгоритм. Предположим, имеется список размера n. Сортировка пузырьком должна проверить каждый элемент, поэтому ей придется выполнить n операций. Время выполнения “Большое О” имеет вид O(n).
А теперь другой пример. Для проверки списка размером n быстрой сортировке потребуется loglogn операций. Как будет выглядеть “Большое О”? O(loglogn).
В общем случае “Большое О” выглядет так: O(f(n)), где f(n) - это количество операций, которые придется выполнить алгоритму. Оно называется “Большое О”, потому что перед количеством операций ставится символ “О” (а большое - потому что в верхнем регистре).
Примеры “Большого О”
Вот пять типичных примеров “О-большого”, которые часто встречаются в алгоритмах и структурах данных. Они представлены в порядке от самого быстрого к самому медленному:
O(loglogn), или логарифмическое время. Это время, которое обычно требуется для выполнения бинарного поиска.
O(n), или линейное время. Это время, которое обычно требуется для выполнения простого поиска.
O(n loglogn). Это время, которое обычно требуется для выполнения эффективных алгоритмов сортировки, таких как быстрая сортировка.
O(2n2). Это время, которое обычно требуется для выполнения медленных алгоритмов сортировки, таких как сортировка выбором.
O(n!). Это время, которое обычно требуется для выполнения очень медленных алгоритмов, таких как решение задачи о коммивояжере.
Эффективность алгоритмов определяется не по времени выполнения в секундах
Алгоритмы с временем выполнения O(log n) работают быстрее, чем алгоритмы с временем выполнения O(n). И чем больше размер списка, по которому производится поиск, тем заметнее становится эта разница.
Эффективный алгоритм может быть не сразу очевиден, и в зависимости от специфики данных, операционной среды (например, возможности использования параллелизма) и конкретных целей, наилучшим решением может стать один из множества различных алгоритмов.
Это краткое введение — лишь небольшая часть огромного мира алгоритмов. Надеемся, что оно вдохновит вас на дальнейшее изучение различных алгоритмических подходов и алгоритмов, которые мы рассмотрели.
Реализация алгоритмов
Все рассмотренные здесь алгоритмы были реализованы и задокументированы с целью помочь вам лучше понять, как использовать эти алгоритмы и даже как реализовать их самостоятельно. Это знание будет полезно при чтении статей по алгоритмам и при их применении на практике.
Рекомендации по чтению
Вот несколько книг, которые я могу порекомендовать для изучения алгоритмов:
“Алгоритмы: построение и анализ” - Томас Х. Кормен, Чарльз Э. Лейзерсон, Рональд Л. Ривест и Клиффорд Штайн. Это классический учебник, который подробно описывает большинство важных алгоритмов.
“Алгоритмы на Python” - Майкл Т. Гудрич, Роберто Тамассиа и Майкл Голдвассер. Эта книга объясняет алгоритмы на языке Python, что может быть полезно для тех, кто хочет изучать алгоритмы на конкретном языке программирования.
“Структуры данных и алгоритмы в Java” - Майкл Т. Гудрич и Роберто Тамассиа. Это еще одна отличная книга для изучения алгоритмов, особенно если вы предпочитаете Java.
“Алгоритмы + структуры данных = программы” - Никлаус Вирт. Это классическая книга, которая объясняет, как алгоритмы и структуры данных работают вместе, чтобы создать эффективные программы.
Пожалуйста, учтите, что выбор книги зависит от вашего уровня знаний и опыта в программировании. Некоторые книги могут быть более сложными для понимания, чем другие. Поэтому рекомендуется начать с более простых книг, если вы только начинаете изучать алгоритмы.
Выспаться, провести генеральную уборку, посмотреть все новые сериалы и позаниматься спортом. Потом расстроиться, что время прошло зря. Есть альтернатива: сесть за руль и махнуть в путешествие. Как минимум, его вы всегда будете вспоминать с улыбкой. Собрали несколько нестандартных маршрутов.