Второй эпизод «сериала» про ИИ-стартапы. Поговорили, как создать стартап на технологии превращения аудио или видео файлов в текст: как собрать сильную команду, привлечь инвестора на стадии MVP, найти клиентов и получить грант от государства.
Сегодня мы вместе раскроем секреты рынка искусственного интеллекта, который применяется для расшифровки аудио и видео-файлов в текст.
⚡Получите конспекты всех интервью и доступ к чату с гостями в базе знаний спец-сезона – startupsecrets.ru/ai
Разобраться в теме со всех сторон я позвал трех основателей, которые уже успели на троих получить 12 млн рублей грантами от государства и привлечь 4,5 млн рублей инвестициями от ангелов:
Федор Жилкин – со-основатель, технический и генеральный директор проекта mymeet.ai, ИИ-ассистента для онлайн-встреч, который позволяет транскрибировать звонки, делать их краткую выжимку и быстро назначать задачи присутствующим. Команда недавно привлекла свой первый раунд в 3 млн рублей.
Ася Семенова – основательница проекта ViSaver, который позволяет мгновенно искать информацию внутри видео файлов по текстовому запросу. Команда на старте получила 1,5 млн рублей от частного инвестора и еще 2 млн рублей в виде грантов от ФСИ.
Виктория Кондрашук – основательница стартапа «Сибирские нейросети», компании-разработчика open source системы для анализа интервью. Стартап получил 10 млн рублей от ФСИ на свою разработку.
Всем привет! Как насчет того чтоб перенять мой опыт?
Сегодня я хочу затронуть две темы, о одной из них мало информации в открытых источниках. Первое - это как я реализовал защиту в Telegram на REST API. Второе - это какие дыры есть в Mini App Telegram.
Вводные данные
Я разрабатываю Mini App в Telegram, это такая штука открывающаяся внутри бота и есть внутрение приложение Telegram.
Стояла задача разработать приложение с админкой, тратить время на развертывание сервера, налаживание и его защиту не было времени. Нужна оперативная работа.
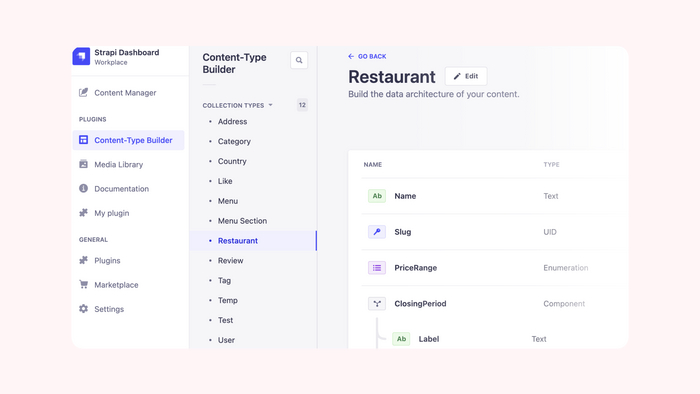
Изучив возможные варианты, выбрал Strapi - это OpenSource проект написанный на Node.js. Развернуть можно как в облаке так и локально. Имеет поддержку русского языка.
Так выглядит админка Strapi
Если в общем, то мой стек используемых инструментов выглядит следующим образом:
Telegram App ( Библиотека )
Strapi ( Админ панель + REST API )
PostgreSQL ( База данных )
Next.js ( Само приложение )
Стек технологий
Решение с защитой что я предлагаю подойдет каждому. Главное понять его принцип.
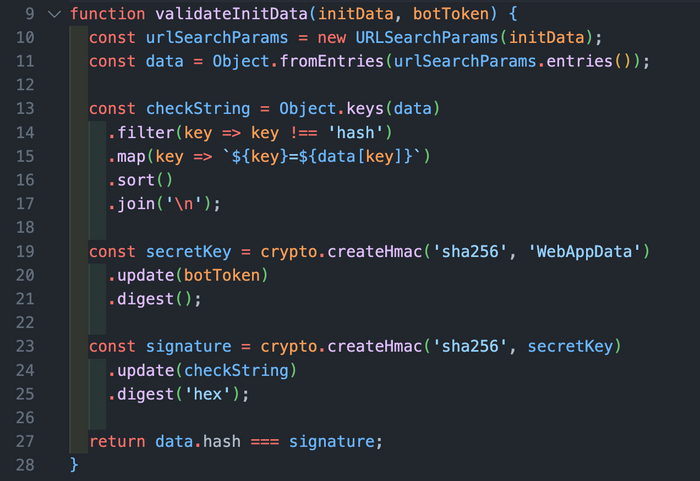
Как я защищал REST API? Валидация данных
Когда пользователь открывает веб-приложение через Telegram, ваше приложение получает начальные данные от самого Telegram, такие как идентификатор пользователя и его имя. Чтобы убедиться, что эти данные подлинные и не были изменены, используется специальный процесс проверки.
Преобразование данных: Приложение преобразует начальные данные в удобный формат.
Создание строки для проверки: Из всех параметров (кроме специального hash) создается отсортированная строка.
Создание секретного ключа: С помощью токена вашего бота создается секретный ключ.
Создание цифровой подписи: Используя секретный ключ и строку параметров, создается цифровая подпись.
Сравнение подписей: Приложение сравнивает созданную подпись с полученной от Telegram. Если они совпадают, данные подлинные.
Этот процесс помогает убедиться, что данные, полученные от Telegram, не были изменены, обеспечивая безопасность вашего приложения и его пользователей.
После успешной валидации я генерировал JWT токен для пользователя и он становился полноценным пользователем в моей системе.
Далее можно с ним делать что угодно 😏 - ну допустим заблокировать его, дать права админа и т.д.
А сам пользователь имеет полный доступ к возможностям приложения. Но вне телеграма он ничего не сделает.
Какие дыры есть в приложениях и почему?
Не буду показывать на конкретном примере, но большинство разработчиков не умеют или не хотят защищать свои приложения, а чисто привязывают все к Telegram ID ( ID вашего аккаунта ) и так и живут.
Telegram ID состоит из цифр и перебрать его методом подбора не составит труда и получить доступ к аккаунту в Mini App.
Зачастую этим грешат новые приложения или не опытные разработчики, например в Telegram Apps Store ваше приложение проверяют на наличие этой защиты.
Кроме того нужно учесть что само приложение не должно никоем образом отображаться в поисковиках, если все взаимодействие выстроено на основе телегерама. Приложения же имеют свой адрес и могут индексироваться, не забывайте выключать!
Кроме всего этого можно запретить вне телеграма заходить в ваше приложение тем же способом что описан выше.
Как же защитить приложение и пользователей?
Не важно на каком языке вы пишите, телеграм уже сделал для вас подсказку, осталось ей воспользоваться.
Я надеюсь эта статья поможет тем кто хочет или уже занимается разработкой WebApp на Telegram. Если все еще осталось что-то не понятно, то пишите смело - будем вместе разбираться:)
Если у вас так же останутся вопросы или предложения или вы просто захотите поделиться своим приложением, то пишите! Всегда рад пообщаться с читателями 😁
TikTok знают все. ByteDance - тоже, ведь эта компания сделала TikTok. Но мало кто знает, что первый выстреливший продукт ByteDance - отнюдь не приложение с вирусными клипами, а нейроагрегатор новостей Toutiao. Именно в недрах Toutiao возник TikTok и его знаменитый алгоритм, за право над которым китайцы сейчас воюют американцами.
Знакомьтесь, основатель ByteDance Чжан Имин. Именно он отобрал свободное время сначала у миллионов китацев, а потом и у всего мира.
Как только закон о запрете Тиктока в США вступил в силу, сразу начался цирк с конями. Сначала глава ByteDance выступил с обращением, где призвал американцев “встать на защиту свободы слова”, а еще заявил, что “компания не смирится и будет бороться”. Потом СМИ писали, что китайцы хотят продать Тикток американцам без алгоритма (ага, больно он кому-то нужен без алгоритма...). А совсем недавно технологические медиа начали пробрасывать версию, что ByteDance разработает отдельный алгоритм для ускользающей из рук ByteDance (и КПК) американской версии Тиктока. Видимо, чтобы можно было скинуть отжатый актив без особенных мук китайской совести.
Рискну предположить, что стороны будут еще долго бодаться на счет алгоритма. Неудивительно, ведь рекомендательный движок можно смело назвать главным бриллиантом китайского приложения. Эксперты зачастую называют алгоритм Тиктока настоящим произведением искусства, а техноэнтузиасты регулярно пытаются разобраться в его внутреннем мире.
Многие в курсе, что Тикток - это брат-близнец китайского сервиса Douyin (прямо-таки однояйцевый). В 2016 года хитрые китайцы запустили у себя Douyin, а потом “клонировали” его для западной аудитории. Еще чуть позже ByteDance купил платформу musical.ly, объединил её с Тиктоком, влил мегатонны юаней в маркетинг, и вот мы здесь.
Кстати, ставьте лайк, если вас тоже до чёртиков бесила реклама Musical.ly в 2018 году. Репост, если попались на неё и скачали приложение.
Раздражала она не меньше Азино три топора и Джойказино. Кстати, вот эти ребята на картинке (это актеры из основной рекламы Musical.ly в РФ) так много мелькали, что даже стали звездами мелкого пошиба.
Из этой истории хочется сделать вывод, что Тикток просто взял алгоритм у Douyin. И это верно. Однако, у Douyin он возник не из космического китайского вакуума.
В России мало кто знает, что у ByteDance есть еще один сервис, самый первый - новостная платформа Toutiao. И очень зря, потому что это крайне интересная штука. Именно она является мамой Douyin и бабушкой Тиктока (ну или папой и дедушкой, не суть).
Итак, по порядку:
"Человек-рекомендация", или краткая история одного из главных инноваторов Китая
Год назад я делал большую статью про Ван Сина - китайского предпринимателя, скопировавшего целых три американские компании. Последняя из трех - экосистема Meituan - сделала его одним из богатейших людей Китая. Самая первая - Xiaonei (копия цукерберговской соцсети) тоже неплохо выстрелила и работает до сих пор под названием RenRen. А вот между ними была попытка скопировать Twitter.
Тот проект назывался Fanfou, и он оказался не слишком удачным. Но сегодня он нам интересен по другой причине - в нем успел поработать разработчик по имени Чжан Имин.
Чжан Имин в молодые годы. Надеюсь, что это он, с молодыми фотками китайцев всегда непросто (но вроде похож).
До Fanfou Чжан успел немного потрудиться в Microsoft, а еще раньше - в тревел-агрегаторе Kuxun (который, кстати, до сих пор неплохо держится в своей индустрии). Позже, в 2009 г., Чжан основал свой первый стартап - 99fang. Это платформа для поиска объектов недвижимости, что-то вроде нашего ЦИАНа. На нем можно была искать недвижку, фильтровать выдачу и связываться с агентами для сделок. 99fang неплохо выстрелил, и тоже прекрасно себя чувствует по сей день.
Почему я вообще рассказываю про места работы нашего героя? Потому что из них становится отчётливо видно, что Чжан Имин всю свою карьеру плотно работал с рекомендательными сервисам. Он отлично изучил эту область айти и плавал в ней не менее уверенно, чем баоцзы в соевом соусе. Так что, вполне логично, что именно на алгоритмы рекомендаций он сделает ставку в своём главном детище.
Итак, чувак круто шарил в рекомендательных алгоритмах и в целом был весьма толковым айтишным руководителем (на тот момент уже дорос до топ-уровня). Однако, все его пересечения с алгоритмами были… как бы сказать… слегка местечковыми. То недвижка, то билеты на транспорт какие-то.
Чжан Имин хотел большего. И однажды он поставил себе действительно взрослую задачу:
Запихнуть весь китайский интернет в рекомендательный движок.
С виду - китайский BuzzFeed. Но есть нюанс
В 2012 г. Чжан Имин создает Beijing ByteDance Technology Co., более известную как просто ByteDance. Однако до Тиктока еще было далеко.
Первым продуктом компании стал сервис Toutiao.
Слово “Toutiao” можно перевести на русский как “Заголовки”. Китайцы вообще очень щепетильно подходят к неймингу, и этот случай - не исключение. В нем вся суть. В 2010-х в Китае уже был довольно развитый интернет-сектор. А значит среднестатистический китаец уже тогда легко мог получить уйму самого разного контента (а текста - так вообще вагон и маленькую тележку). Следовательно, диапазон внимания становился более узким, развивалась контентная слепота.
В такой ситуации формулировки в заголовках выходят во главу угла. Человек смотрит на заголовок и по нему принимает решение - открывать ему статью, пост или видео, или серфить по сети дальше. Весьма несложный процесс, не правда ли? Почти рутинный.
Вот и Чжан Имин так подумал. Он решил, что людям в этом аспекте можно здорово помочь. Для этого Toutiao разработал алгоритм, умеющий:
Анализировать заголовки. Для этого используется комбинация из обработки текстов на естественном языке (Natural Language Processing, NLP) и машинного зрения.
Агрегировать контент. Если один и тот же инфоповод мелькает в разных закоулках китайнета, то сервис выбирает самые важные, вирусные и просто интересные части и собирает из них единую сущность.
Профилировать пользователя. Тут понятно - учет предыдущих действий пользователя, анализ его предпочтений и взаимодействий и многое другое. Проще говоря - понять, что конкретно зацепит внимание 40-летнего инженера Ли или 20-летнюю студентку Сянь (пасхалочка детектед).
В технические дебри залезать не буду, там много всего используется. В частности, глубокое машинное обучение, свёрточные нейронные сети (convolutional neural network), коллаборативная фильтрация и много других традиционных (и не очень) методик, применяемых любым адекватным рекомендательным движком.
Интерфейс Toutiao - 2017 (слева) vs 2022 (справа). Не зря все-таки Чжан Имин работал в китайском аналоге Твиттера.
Лучше отмечу три продуктово-технических фичи, благодаря которым Toutiao так полюбился миллионам китайцев:
Фича первая. Toutiao не просто агрегирует контент из китайской сети, но и умеет его менять. Например, сервис может чуть подшлифовать формулировку заголовка, чтобы сделать его более цепляющим, вирусным и вкусным.
Фича вторая. Она связана с первой. Раз Toutiao умеет хорошо докручить агрегированный контент до товарного вида, то увеличивается кликабельность. А чем больше кликов делают пользователи (как один конкретный пользователь, так и все в совокупности), тем точнее становятся дальнейшие рекомендации. Вообще, так умеют делать большинство нормальных алгоритмических лент (например, тот же экс-Твиттер или запрещенные в РФ соцсети Цукерберга), но в те годы действительно хорошо владели этим навыком не только лишь все. Taotiao владел им хорошо, очень хорошо.
Наконец, фича третья. Сервис научился неплохо отстреливать фейковые новости и мусорные инфоповоды. Зачастую он делал это гораздо лучше первоисточника, потому что у него было unfair advantage в виде мощного алгоритмического нейрофильтра. Так что, для китайцев Toutiao стал дополнительным фильтром мозга от всякого мусора (ох, если бы они только знали, какой другой сервис в 2016 г. выкатит ByteDance…).
В последнем пункте еще можно предположить (не настаиваю), что алгоритм Toutiao умел вычищать не только явные фейк-ньюс, но и работать с более тонкими материями. Тут сами продолжите мысль, держа в голове, что речь идет не о случайной стране, а о Китае.
В итоге Чжан Имин смог:
Взять китайский интернет, выбрать из него самое интересное, превратить это интересное в готовый цепляющий контент и выплюнуть его тем, кому он будет наиболее актуален. При этом отцепляя от состава фейки и (возможно) кое-какую лишнюю информацию.
Отличный рецепт. Для Китая начала 2010-х самое то!
На первый взгляд может показаться, что еще один ушлый китаец скопировал очередной американский сервис (на этот раз - BuzzFeed), а автор этой статьи с восхищением копается в очередной китайской подделке. Но это не так:
BuzzFeed начинал как платформа, подкидывающая юзеру наиболее вирусный контент на разные темы. Однако, в погоне за вирусностью BuzzFeed, во-первых, серьезно менял и адаптировал контент из третьих источников, а во-вторых, сам создавал оригинальный контент. И для этого у него была своя команда редакторов (настоящих, кожаных). Нет, понятно, что сейчас у BuzzFeed в почете нейросети, перехватившие львиную долю работы. Однако, в начале было не так.
А вот у Toutiao людей-редакторов отродясь не водилось. Китайский сервис осмелился поставить полный all-in на алгоритмы и машинное обучение. Напомню, на дворе был 2012 г. Только-только набирала обороты предыдущая волна искусственного интеллекта, Cэм Альтман недавно присоединился к Y Combinator, а OpenAI еще и в помине не было.
Кстати, показательно, что Toutiao иногда называют “китайским BuzzFeed с мозгами”. Заметьте, не наоборот! Возможно, эту метафору придумала какая-нибудь честолюбивая нейросетка, кто знает.
Рост, проблемы и решения
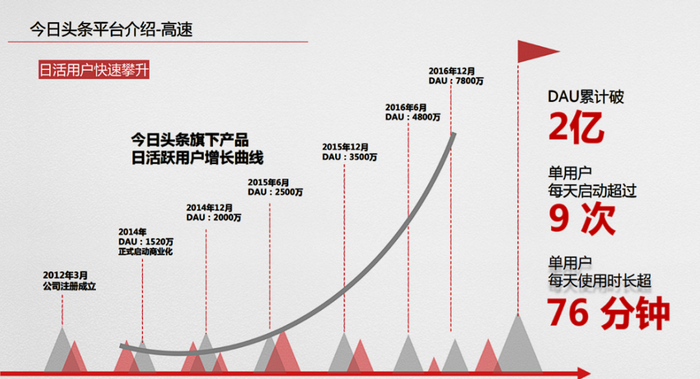
Уже в 2014 году у сервиса было 20 миллионов активных пользователей. Для Китая это не предел мечтаний, но за два года - вполне достойный результат. К 2016 г. набралось почти 80 миллионов, а в 2018 г. сервисом пользовались 200 миллионов уникальных китайцев. Вот это уже серьёзные цифры даже для Поднебесной!
Насколько я понял (лол), на графике показано ежедневное число активных юзеров Toutiao по годам. Да, при всём моём интересе к китайскому tech, я терпеть не могу собирать инфу о нём…
Однако, у сервиса была и темная сторона - проблемы с авторским правом. Конечно, далеко не весь интернет защищен копирайтом, и Toutiao вполне хватило бы и свободного контента, чтобы разгуляться. Однако, для пущего сетевого эффекта хотелось охватывать всё.
Изначально Toutiao практически не сотрудничал с издательствами и новостными порталами. Агрегатор просто брал из интернета всё, что не приколочено намертво. За счет этого Чжан Имин довольно быстро перетянул у СМИ серьезную долю интернет-трафика и стал монетизировать её через рекламу.
С одной стороны, это вполне закономерно бесило всю китайскую медийку. Но с другой, они понимали, что воевать в открытую нельзя - в таком случае ByteDance просто испортит им конкурентную позицию и лишит трафика, отключив от своей агрегации. Проще говоря, они прозевали момент, когда Toutiao был маленький и беззубый.
Решение нашлось. Постепенно Toutiao стал заключать партнерства с новостными площадками. У одних (в основном, самых крупных) просто покупали доступ к контенту - Toutiao мог брать их контент, а взамен отчислял процент от своей рекламной выручки, либо же просто платил определенный тариф. Другие стали делать для Toutiao специальные секции. Иногда в них был другой формат, но сильно борзеть было нельзя, иначе ByteDance мог разозлиться и прекратить сотрудничество. Некоторые журналисты, авторы и небольшие издания сразу шли на Toutiao - либо полностью, либо вели на нём рубрики. Взамен получали халявные охваты (примерно как твиттерские блогеры, т.е. вполне обычная интернет-история).
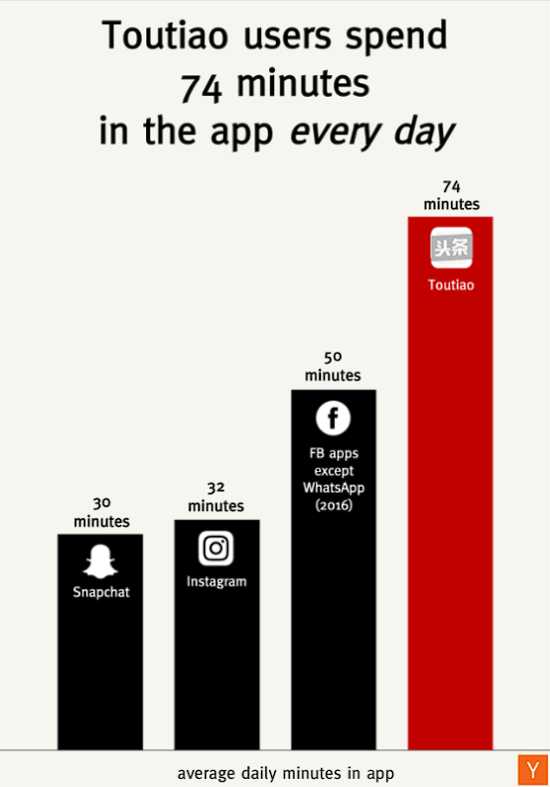
Toutiao действительно плотно проник в жизнь китайцев. Один из пруфов - число ежедневных минут в приложении в сравнении с западными сервисами (на графике данные за 1 квартал 2016 года). *Instagram и FB запрещены в РФ
Нужно сказать, что одна из главных суперсил Toutiao - оперативность подачи релевантной информации. За счет этого периодически удавалось красиво хакнуть рост.
Например, очень круто помогли большие спортивные турниры. Когда в 2014 году в Бразилии проходил футбольный чемпионат мира, Toutiao стал для китайцев лучшим способом получать самые быстрые апдейты. Когда кто-то забивал гол, то оповещение в Toutiao было тут как тут. Не удивлюсь, если китайские любители футбола узнали об унижении бразильцев от немцев на несколько минут раньше, чем весь остальной мир.
Похожий фокус провернули и на Олимпиаде в Рио в 2016 году. Тогда Toutiao запустил социальный проект - “цифрового журналиста”, пишущего короткие заметки о спортивных событиях еще за несколько минут до его окончания. Художественными изысками они не отличались, но зато били все рекорды скорости.
Получается, оба раза китайскому цифровому сервису помогли крупные турниры в Бразилии.
Так вот как, оказывается, работает БРИКС!
Toutiao (точнее весь ByteDance, но до Douyin/Тиктока Toutiao был его главным продуктом) активно привлекал инвестиции. Вложиться успели несколько китайских корпораций, включая “главный аналог Твиттера” Поднебесной под названием Sina Weibo, а также Sequoia Capital, структуры Юрия Мильнера и много кто ещё. Когда Тикток начал разрывать мир и привлекать еще более серьезные суммы, Toutiao тоже перепадало хорошее финансирование.
Как появился Тикток
В 2015 г. на Toutiao появился собственный раздел с видео. Пользователи могли загружать короткие видосы, после чего продвинутые алгоритмы платформы раскидывали их нужным зрителям.
В 2016 г. видеораздел Toutiao собирал более 1 миллиарда просмотров в день, что делало плошадку сервисом коротких видео №1 во всём Китае. Здесь важно, что именно коротких видео! В сегменте длинных были и более зубастые драконы.
В сентябре 2016 года Чжан Имин решил поменять название для видео-секции Toutiao. В итоге выбрали слово, которое на русский можно перевести примерно как “завлекать” или “соблазнять” (на просмотр видео, само собой, про онлифансы в Китае тогда речи не шло). А по-китайски это слово звучит не иначе как “Douyin”.
Уже в декабре этого же года ByteDance понял, что создал нечто колоссальное и монструозное, и отпочковал Douyin в отдельный сервис.
Как вы понимаете, всё самое лучшее для рекомендательного алгоритма нового приложения взяли у Toutiao. Еще через год ByteDance выпускает глобальную версию Douyin под названием TikTok. А дальше - история.
На данном фото уважаемый китайский IT-предприниматель Чжан Имин что-то объясняет какому-то случайному лаоваю.
Toutiao же успешно работает до сих пор, снабжая вирусным контентом и актуальными новостями более 350 миллионов китайцев.
В завершение хотел бы отметить два момента:
Момент первый. Из моей статьи может показаться, что вот был такой китайский интернет-контент, потом пришел Чжан Имин на белом коне, агрегировал весь контент через Toutiao и умчался в закат (точнее, в Тикток). Конечно, в реальности всё было гораздо сложнее. В 2010-х в Китае была жуткая грызня за индустрии, и иногда бойня в tech-секторе выходила за всякие рамки. Погуглите, например, “Войну тысячи Групонов” или как Tencent расправлялся с конкурентами. Так что, ByteDance развивал свой продукт в условиях дичайшего соперничества.
Момент второй. Из истории видно, что китайские стартаперы создали прорывной и очень сильный ИИ-продукты во времена, когда ИИ был совсем не тем, что нынче. Хотя сейчас в ИИ-гонке вроде бы лидирует США со своими OpenAI, Microsoft, Google и Nvidia, кто знает, что там готовят сумрачные китайские гении. На эту тему крайне рекомендую почитать книгу “Сверхдержавы искусственного интеллекта” за авторством Кай Фу Ли (про конфликты китайских предпринимателей там тоже есть, кстати).
Вот теперь the end.
***
Если вам зашло, то подпишитесь на мой тг-канал Дизраптор. Там много подобных материалов - не только про Китай и ByteDance, а вообще. Разборы крутых компаний, инноваций, продуктов и чего только не. Каждый день туда пишу большие содержательные посты, а еще анонсирую все статьи, которые выходят регулярно. Также есть второй канал Фичизм, где я разбираю интересные и яркие фичи. Тоже заходите.
Родился 2 (14) ноября 1864 года в семье служащего. В 1885 году окончил 3-ю московскую гимназию. В 1889 году, окончив естественное отделение физико-математического факультета Московского университета, он стал преподавать в средних учебных заведениях (1892—1893 — в Муромском реальном училище). С 1893 года работал лаборантом в термохимической лаборатории профессора В. Ф. Лугинина. В 1896 году он сделал здесь своё первое выдающееся открытие — уравнение кинетики растворения кристаллов, позже названное его именем (уравнение Нернста—Щукарёва). После защиты в 1906 году магистерской диссертации «Исследования внутренней энергии газообразных и жидких тел» и, продолжая работать в лаборатории, стал приват-доцентом московского университета.
В 1909 году, после защиты докторской диссертации «Свойства растворов при критической температуре смещения», был избран на должность экстраординарного профессора общей химии Екатеринославского высшего горного училища, а в 1911 году стал профессором Харьковского технологического института, в котором преподавал вплоть до времени ухода на пенсию в 1931 году. В 1935 году А. Н. Щукарёв вновь был приглашен на кафедру физической химии для руководства исследовательскими работами и для чтения аспирантам курса химической термодинамики.
В 1905—1907 годы, в Москве и Харькове, А. Н. Щукарёв выступал с публичными лекциями по вопросам логики мышления, на основе которых была написана книга «Проблемы теории познания в их приложениях к вопросам естествознания и в разработке его методами» (Одесса: Mathesis, 1913. — 138 с.; переиздана: М.: URSS, 2007).
В 1909 году Щукарёв сконструировал логарифмический счётный цилиндр со спиральной шкалой. Стремясь к возможно большей простоте, он применил новый для того времени материал — целлулоид. Модель, сделанная самим учёным, в 1980 году была приобретена у его дочери Л. А. Щукарёвой Политехническим музеем.
Работая в Екатеринославе, он обнаружил и описал явление химической поляризации и магнито-химический эффект, который изучал в последующие годы.
В Харькове им была восстановлена логическая машина Джевонса, сконструированная в конце 1890-х годов П. Д. Хрущовым. По выражению А. Н. Щукарёва, логическую машину он «получил в наследство». Затем Щукарёв изготовил усовершенствованный вариант логической машины Джевонса, лаконичное описание которого содержится в его программной статье «Механизация мышления (Логическая машина Джевонса)», опубликованной спустя 12 лет:
Я сделал попытку построить несколько видоизменённый экземпляр, вводя в конструкцию Джевонса некоторые усовершенствования. Усовершенствования эти, впрочем, не носили принципиального характера. Я просто придал инструменту несколько меньшие размеры, сделал его весь из металла и устранил кое-какие конструктивные дефекты, которых в приборе Джевонса, надо сознаться, было довольно порядочно. Некоторым дальнейшим шагом вперёд было присоединение к инструменту особого светового экрана, на который передаётся работа машины и на котором результаты «мышления» появляются не в условно-буквенной форме, как на самой машине Джевонса, а в обыкновенной словесной форме
Машина логического мышления
В апреле 1914 года, за четыре месяца до начала Первой мировой войны, профессор Харьковского технологического института Александр Николаевич Щукарев по просьбе Московского Политехнического музея приехал в Москву и прочитал лекцию «Познание и мышление». Лекция сопровождалась демонстрацией созданной А. Н. Щукаревым «машины логического мышления», способной механически осуществлять простые логические выводы на основе исходных смысловых посылок.
Например, при исходных посылках:
серебро есть металл;
металлы есть проводники;
проводники имеют свободные электроны;
свободные электроны под действием электрического поля создают ток.
Получаем логические выводы:
серебро есть проводник, оно имеет свободные электроны, которые под действием электрического поля создают ток;
не серебро, но металл (например, медь) есть проводник, имеет свободные электроны, которые под действием электрического поля создают ток;
не серебро, не металл, но проводник (например, уголь), имеет свободные электроны, которые под действием электрического поля создают ток;
не серебро, не металл, не проводник (например, сера) не имеет свободных электронов и не проводит электрический ток.
Лекция имела большой резонанс. Присутствовавший на ней профессор А. Н. Соков откликнулся статьей с провидческим названием «Мыслительная машина» (журнал «Вокруг света», №18, 1914 г.), в которой написал:
«Если мы имеем арифмометры, складывающие, вычитающие, умножающие миллионные числа поворотом рычага, то, очевидно, время требует иметь логическую машину, способную делать логические выводы и умозаключения одним нажиманием соответствующих клавиш. Это сохранит массу времени, оставив человеку область творчества, гипотез, фантазии, вдохновения – душу жизни.».
Напомним, что в 1914 году, когда была опубликована статья, Алану Метисону Тьюрингу, гениальному английскому математику, опубликовавшему в 1947 г. нашумевшую статью «Думающая машина. Еретическая теория», а в 1950 г. вторую: «Может ли машина мыслить?», шел второй год!
«Машина логического мышления» А. Н. Щукарева представляла собой ящик высотой 40 см, длиной 25 и шириной 25 см. В машине имелись 16 штанг, приводимых в движение нажатием кнопок, расположенных на панели ввода исходных данных (смысловых посылок). Кнопки воздействовали на штанги, т.е. на световое табло, где высвечивался (словами) конечный результат (логические выводы из заданных смысловых посылок).
Приезд в Харьков сыграл большую роль в жизни Щукарева. Дело в том, что в Харьковском университете много лет работал хорошо известный в то время в России профессор Павел Дмитриевич Хрущев (1849–1909). По специальности он также был химиком и также, как Щукарев, был увлечен проблемой мышления и методологией науки. Еще в 1897 г. он прочитал для профессорско-преподавательского состава Харьковского университета курс лекций по теории мышления и элементам логики. Вероятно в это время у него возникла мысль повторить (воспроизвести) «логическое пианино» – машину, изобретенную в 1870 г. английским ученым математиком Вильямом Стенли Джевансом (1835-1882), профессором Манчестерского университета, книга которого «Основы науки» была переведена на русский язык в 1881 г. и, очевидно была известна П.Д.Хрущеву. К тому же по материалам книги профессором математики Одесского университета И. В. Слешинским в 1893 г. была опубликована статья «Логическая машина Джевонса» («Вестник опытной физики и элементарной математики», семестр XV, №7). Джевонс не придавал своему изобретению практического значения. «Логическое пианино» трактовалось и использовалось только как учебное пособие при преподавании курса логики. Судя по всему, профессор П. Д. Хрущев, воссоздавший машину Джевонса, (в начале 1900-х годов или несколько ранее) намеревался использовать ее подобно Джевонсу как учебное пособие во время своих лекций по логике и мышлению.
После смерти П. Д. Хрущева в 1909г. его вдова передала машину Харьковскому университету, где он долгое время работал.
Каким образом А. Н. Щукарев отыскал машину, сконструированную П. Д. Хрущевым, – неизвестно. Сам А. Н. Щукарев в статье «Механизация мышления» (1925 г.) пишет, что она досталась ему «по наследству».
А. Н. Щукарев вел большую просветительскую работу, выступал с лекциями на тему познания и мышления во многих городах Украины, а также в Москве и Ленинграде. Первое время он демонстрировал машину, построенную Хрущевым, а затем – сконструированную им самим. В указанной выше статье он сообщает:
«Я сделал попытку построить несколько видоизмененный экземпляр, вводя в конструкцию Джевонса некоторые усовершенствования. Усовершенствования эти, впрочем, не носили принципиального характера. Я просто придал инструменту несколько меньшие размеры, сделал его весь из металла и устранил кое-какие конструктивные дефекты, которых в приборе Джевонса, надо сознаться, было довольно порядочно. Некоторым дальнейшим шагом вперед было присоединение к инструменту особого светового экрана, на который передается работа машины, и на котором результаты «мышления» появляются не в условно-буквенной форме, как на самой машине Джевонса, а в обыкновенной словесной форме.»
Однако главное, что сделал Щукарев, заключалось в том, что он, в отличие от Джевонса и Хрущева, видел в машине не просто школьное пособие, а представлял ее своим слушателям как техническое средство механизации формализуемых сторон мышления. Статью «Механизация мышления. Машина Джевонса» он начинает с упоминания истории создания технических средств для счета. Упоминает абак, суммирующую машину Паскаля, арифметический прибор Лейбница, логарифмическую линейку и аналоговые дифференцирующие машины для решения уравнений. Механизация формализуемых логических процессов рассматривается им как следующий шаг в развитии подобных устройств, оказывающих существенную помощь человеку в умственной работе. В качестве примера в статье приводится решение задачи прогнозирования электрических свойств водных растворов окислов химических элементов. С помощью машины были найдены восемь вариантов растворов электролитов и неэлектролитов.
«Все эти выводы совершенно правильны», – пишет ученый, – «однако мысль человеческая сильно путалась в этих выводах».
Как и в наше время, когда в Советском Союзе кибернетику посчитали вначале лженаукой, так и в 20-е годы воззрения А. Н. Щукарева, помимо доброжелательного отношения, оценивались рядом ученых резко отрицательно.
Профессор И. Е. Орлов в 1926г. на страницах журнала «Под знаменем марксизма» написал: «...Претензии профессора Щукарева, представляющего школьное пособие Джевонса в качестве «мыслящего» аппарата, а также наивное изумление его слушателей, – все это не лишено некоторого комизма. ...Нас хотят убедить в формальном характере мышления, в возможности его механизации» (Орлов И. «О механизации умственного труда». Журн. №12, 1926 г.). К чести журнала – его редакция не согласилась со взглядами автора статьи.
Последнюю лекцию А. Н. Щукарев прочитал в Харькове в конце 20-х годов. Свою машину он передал Харьковскому университету, на кафедру математики. В дальнейшем след ее потерялся. В истории развития информационных технологий в Украине и в бывшем Советском Союзе имя А. Н. Щукарева связано с важным шагом в области средств обработки информации – пониманием и активной пропагандой важности и возможности механизации (в дальнейшем автоматизации) формализуемых сторон логического мышления.
Привет, Пикабу! Меня зовут Александр Троицкий, я автор канала AI для чайников, и в этой статье я расскажу про разные способы векторизации текстов.
Всем привет! Вдохновившись прикольной и понятной статьей на английском языке, и не найдя сходу чего-то похожего в русскоязычном сегменте интернета, решил написать о том, как обрабатывается текст перед тем, как на нем начинают применять разные модели ИИ. Эту статью я напишу нетехническим языком, потому что сам не технарь и не математик. Надеюсь, что она поможет узнать о NLP тем, кто не сталкивается с AI в продуктах на ежедневной основе.
О чем эта статья:
Что такое векторизация текста и как она развивалась
Зачем она нужна и где применяется
Какие бывают методы векторизации и какие у них преимущества и недостатки
Что такое векторизация (и немного истории)
Векторизация текста — это процесс преобразования текста в числовой формат, который могут понимать и обрабатывать алгоритмы машинного обучения. Текстовые данные по своей природе являются категориальными и неструктурированными, из-за этого обучать модели ИИ прямо на тексте - нельзя, их надо векторизовать.
Векторизация текста как концепция начала развиваться после Второй Мировой войны и использовалась в основном для поиска информации и перевода текста.
Один из ключевых моментов в развитии технологии векторизации текста — создание модели векторного пространства (vector space model, VSM) в 1970-х годах, которая позволяла представлять текстовые документы как векторы в многомерном пространстве. Эта модель стала основой для многих методов информационного поиска и начала использоваться для анализа и сравнения документов.
С появлением интернета и увеличением доступных текстовых данных в 1990-х и 2000-х годах, интерес к векторизации текста и развитию методов NLP значительно вырос. Это привело к разработке более продвинутых методов, таких как TF-IDF (Term Frequency-Inverse Document Frequency), который позволяет лучше учитывать контекст и семантическое значение слов.
Почти все современные векторайзеры текста были изобретены внутри компании Google - это Word2Vec и BERT. Они умеют преобразовывать слова в цифры, которые отлично описывают значения и контекст использования этих слов.
Где применяются векторайзеры?
Ответ простой - почти везде, где текст встречается с ИИ. У всех текстовых моделей есть так называемые "тело" и "голова". Если говорить очень упрощённо, то тело - это векторизация, а голова - это обучение какой-то модели на результатах тела.
Именно поэтому векторайзеры очень важны - чем лучше вы передадите суть слова в числовом выражении, тем лучше потом обучится модель.
Если говорить о бизнес применении, то вот небольшой список из примеров где используется NLP, а значит и векторизация:
Анализ настроений и обработка отзывов клиентов: Компании анализируют отзывы и комментарии клиентов в социальных сетях, на форумах и сайтах отзывов для понимания их настроений по отношению к продуктам, услугам или бренду. Это помогает улучшить качество обслуживания и адаптировать продукты под нужды потребителей.
Системы рекомендаций: Векторизация текста используется для анализа предпочтений пользователей и их интересов на основе их поисковых запросов, просмотренного контента и написанных отзывов. Это позволяет создавать персонализированные рекомендации, например, в онлайн-ритейле или на стриминговых сервисах.
Классификация и сортировка документов: Векторизация текста применяется для автоматизации классификации и сортировки больших объемов документов, таких как электронные письма, договоры или резюме.
Поисковые системы и SEO: Поисковые алгоритмы используют векторизацию текста для улучшения релевантности и точности результатов поиска.
Чат-боты и виртуальные ассистенты: Векторизация текста лежит в основе разработки чат-ботов и виртуальных ассистентов, которые используются в обслуживании клиентов, автоматизации ответов на частые вопросы и в ведении персонализированных диалогов.
Анализ рынка и конкурентной среды: Компании используют векторизацию для мониторинга новостей, публикаций и отчетов конкурентов для получения ценной информации о рыночных тенденциях и стратегиях конкурентов.
Предотвращение мошенничества и безопасность: Векторизация текста используется в алгоритмах для распознавания подозрительных сообщений, фишинговых писем или недобросовестной рекламы, что помогает защитить бизнес и клиентов от мошенничества.
Разбираемся в том какие бывают методы векторизации текста
Давайте попробуем на примерах разобраться в том, как работают разные методы векторизации на примере двух предложений:
Лодка села на мель
Девушка села на стул
One-hot encoding
Самый просто и примитивный метод, результатом которого является матрица с единицами и нулями внутри. 1 говорит о том, что какой-то текстовый элемент встречается в предложении (или документе). 0 говорит о том, что элемент не встречается в предложении. Давайте разберемся на примере двух предложений выше:
Сначала нужно получить список всех слов, встречаемых в наших предложениях. В нашем случае это ['Лодка', 'Девушка', 'села', 'на', 'мель', 'стул']
Составляем матрицы для каждого предложения.
Собственно эти матрицы - это и есть векторизованное значение этих предложений. Как вы видите, чтобы описать всего 4 слова, у нас получились довольно большие и разряженные матрицы (разряженные значит, что внутри больше нулей, чем единиц). Каждая такая матрица занимает много места, поэтому для больших текстов этот метод становится неэффективным.
Кроме того, метод не описывает:
Как часто встречается слово.
Контекст этого слова.
Bag of words
По сути это тот же самый one-hot encoding, но тут матрицы схлопываются и каждое предложение будет представлять из себя одну строку, а не большую матрицу. Таким образом Bag of words имеет те же минусы, что one-hot encoding, но занимает меньше места. Чтобы получить Bag of words можно сложить столбики каждой матрицы из one-hot encoding в одну строку, получится:
TF-IDF
TF-IDF - это уже более сложная штука, чем bag of words или one-hot encoding, но всё еще относится к тому, что можно описать простой экселькой. Состоит этот метод векторизации из двух компонентов: Term Frequency (частотность слова в документе) и Inverse Document Frequency (инверсия частоты документа). В TF-IDF редкие слова и слова, которые встречаются в большинстве документов (в нашем случае предложений), несут мало информации, а значит им дается небольшой вес внутри вектора.
TF-IDF = TF * IDF
TF = количество раз когда слово встретилось в предложении или документе / количество слов (токенов) в предложении или документе
IDF = натуральный логарифм от количества документов деленное на количество документов с каким-то словом.
Давайте разберем пример с нашими двумя предложениями:
И в итоге получаем векторы у каждого предложения. В данном примере метод посчитал слова "Лодка", "мель" значимыми в первом предложении, и слова "Девушка", "стул" значимыми во втором преложении. Словам "села", "на" был присвоен нулевой вес, потому что они встречались в обоих предложениях.
Как я писал ранее, этот метод векторизации всё ещё считается относительно простым. Применять его можно как baseline при решении какой-то NLP задачи, а также для простых задач бинарной классификации. Например, он вполне может подойти для поиска негатива в отзывах. Также у TF-IDF есть настраиваемые параметры длины анализируемой части предложения и вместо слов "Девушка" и "села" можно сразу искать в тексте словосочетание "Девушка села", тогда TF-IDF будет худо-бедно воспринимать контекст. Но все равно базово он воспринимает контекст хуже, чем методы векторизации, о которых мы будем говорить далее.
Word Embeddings (Word2Vec)
Word2Vec - это изобретение компании Google, которое представили широкой публике в 2013 году. Суть его заключается в том, что нейронная сетка переваривает большое количество текста и на основании него создает векторы для каждого слова. Эти векторы - это на самом деле веса обученной нейронной сетки, которая либо берет на вход какое-то слово и пытается предсказать ближайшие окружающие его слова (это называется Skip-Gram), либо наоборот: берет на вход окружающие слова, а на выходе предсказывает загаданное слово.
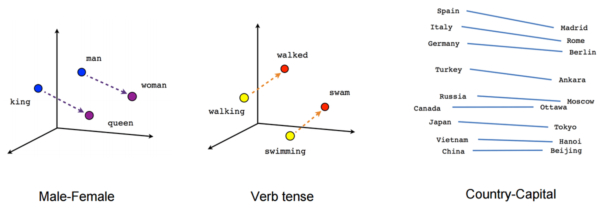
Если взять веса этой нейронки, привести в двухмерное пространство и разместить на графике разные рандомные слова, то окажется, что "пёс" и "собака" будут стоять рядом. А кошка будет ближе ко льву. То же самое с глаголами.
На выходе у Word2Vec каждое слово имеет какой-то длинный вектор чисел, что-то типа [0.12, -0.54, 0.84, ...*ещё 200 чисел*..., 0.99]. Вектор чисел каждого слова не зависит от контекста этого слова - вектор фиксирован. Именно это недоразумение исправили исследовали Google через 5 лет после обнародования Word2Vec, когда опубликовали...
BERT
На самом деле BERT, как и Word2Vec, это лишь один из методов векторизации текста за счет нейронных сетей. Все вместе эти методы называются трансформерами, и их довольно много.
Суть BERTa та же, что у Word2Vec, однако он намного сложнее и более гибкий относительно контекста, в котором употребляется слово. Нейронная сетка BERTа состоит из множества слоёв, в отличие от классического Word2Vec с одним слоем, поэтому BERT долго и сложно обучается на очень большом количестве данных.
Особенно интересен последний пункт про контекст. Давайте рассмотрим его на примере двух предложений:
Он взял лук и пошел на охоту
Он добавил нарезанный лук в картошку
Несмотря на то, что в обоих предложениях мы употребляем слово "лук", его смысл абсолютно разный и отображает разные предметы. Именно тут BERT поймет разницу между двумя луками, а Word2Vec - нет, и даст один и тот же вектор для двух луков.
Изначальный BERT обучался на большом датасете из примерно 3 млрд слов (англоязычная Википедия и Toronto Book Corpus). Впоследствии большая часть дата саенс сообщества либо использует уже готовый BERT, либо переобучает последние слои этой нейронки, чтобы она лучше учитывала контекст какой-то конкретной ситуации, для этого не требуется очень много вычислительных мощностей или данных.
Заключение
Мы ответили на основные вопросы о том, что такое векторизация, как и где она применяется и чем различаются её основные методы. Если вам интересно знать про ИИ и машинное обучение больше, чем рядовой человек, но меньше, чем data scientist, то подписывайтесь на мой канал в Телеграм. Я пишу редко, но по делу: AI для чайников. Подписывайтесь!
Telegram представил свою собственную внутриигровую валюту под названием Stars для использования в мини-приложениях. Эти "Звезды" можно приобрести через App Store или Google Play или через специального бота.
Хотя Apple и Google взимают с пользователей комиссию в размере 30% за покупку Stars, Telegram компенсирует эту комиссию за счет рекламы, что делает ее практически нулевой. Создатели мини-приложений могут обменять полученные Stars на криптовалюту Toncoin через платформу Fragment.
В будущих обновлениях Telegram валюта Stars получит дополнительную функциональность, включая возможность отправлять вознаграждения создателям контента и приобретать цифровые товары и услуги в мини-приложениях.
Проблема. Комп написал, что мало места на диске С. Освободил гигов 17. Через часа 2 свободно 136Мб. Освободил ещё. Через 40 минут свободно меньше 100мб. Выскакивает часто какая-то ошибка про Java script. Блок питания начал трещать, но это думаю вентилятор. В чем может быть проблема?
С 4 по 7 июня в Новокузнецке проходит выставка Майнинг Уголь 2024. Мы решили привезти систему речевой аналитики производственного процесса, по сути, знакомое многим распознавание речи, но на входе не смартфон, а цифровая производственная радиосвязь. Слушаем эфир, и при признаках опасности информируем диспетчера.
Начали проверять журнал, что шахтеры говорили в рацию. У одного бедолаги обнаружили постоянно действующий вредный и опасный фактор в виде жены.