— Неограниченный доступ к шаблонам, выгрузка кода проекта в Figma или HTML-код
— Удобная десктоп-версия для macOS
— LLM-модели на выбор (GPT-4.1 — бесплатно; Claude 3.7, Claude 4, Gemini 2.5 Pro — по подписке)
Как сделать дизайн?
1. Выбор любой языковой модели (например, ChatGPT)
2. Поиск примера интерфейса
3. Запрос в LLM на генерацию промпта для фрейма (приложить пример файла из п. 2)
4. Загрузка промпта в Aurachat
Для кого?
— Дизайнерам UI/UX для создания набросков и тестирования интерфейсов и анимаций
— Разработчикам, кто работает с React, Framer Motion и CSS, — для генерации кода
— Проектным менеджерам, менеджерам продукта, маркетологам для разработки ТЗ и мокапов
Подписка (PRO — 10 $/мес. или MAX — 20 $/мес.)
1. Доступно множество базовых шаблонов, которые можно использовать как дополнительное условие промпта
2. Ручной выбор типа стилей, цветов, формы и дизайна фреймов
3. Добавление шаблонных доп. условий для промпта (например, интерфейс в стиле Apple)
Советую протестировать, инструмент понравился — по скорости генерации 8/10 и качеству фреймов 5–6/10.
aurachat io - пробуем тут
📌 Я буду ОЧЕНЬ благодарен, если вы оцените пост и посмотрите мой канал в ТГ (ссылка в профиле пикабу). Всем позитива и хорошего настроения, будьте добрее друг к другу!
🙃 Я — ярый фанат ChatGPT от OpenAI. Серьёзно, мы с ним прошли огонь, воду и дедлайны в 3 часа ночи. Поэтому когда услышал, что Google запихнул своего Gemini во все сервисы — у меня, честно, дёрнулось левое веко.
💡 Хочешь разобраться в нейросетях без боли и стыда? Вступай в мой клуб: t.me/ai_creators_club Объясняю простым языком, как использовать ИИ в жизни и работе. Без занудства, с поддержкой и примерами.
«Что за самозванец пришёл на мою территорию? Менять ChatGPT? Серьёзно?..»
🤨 Но потом включился проектный менеджер во мне — и я лично решил проверить.
Google интегрировал своего ИИ-ассистента Gemini в основные сервисы: Gmail, Документы, Таблицы, Презентации, Календарь и Диск. Теперь ты можешь:
Попросить Gemini составить письмо прямо в Gmail.
Сгенерировать текст для документа или презентации.
Создать таблицу с расчётами или планом.
Организовать события в Календаре.
Для этого доступны два способа взаимодействия:
Непосредственно в сервисах Google — Gemini появляется в боковой панели и помогает в контексте текущей задачи.
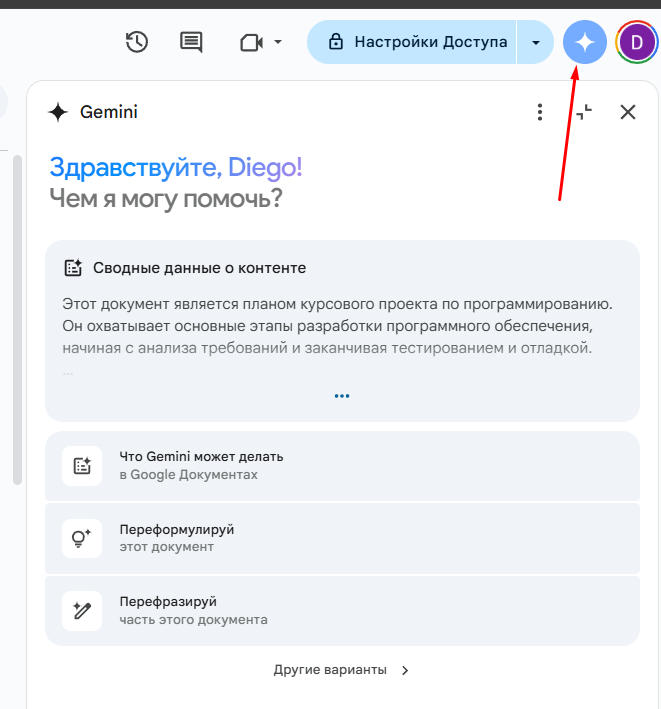
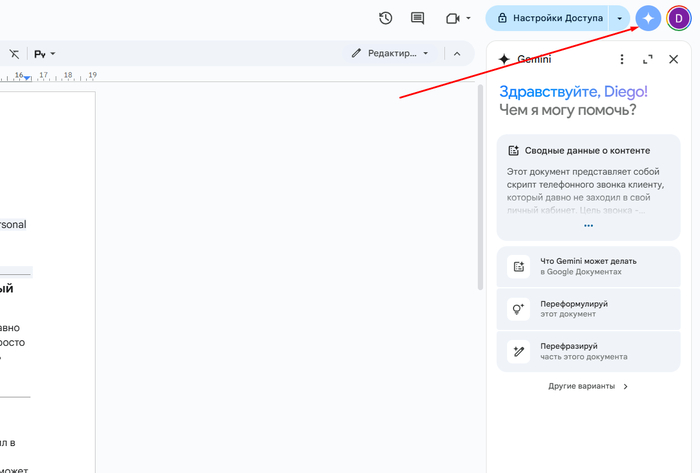
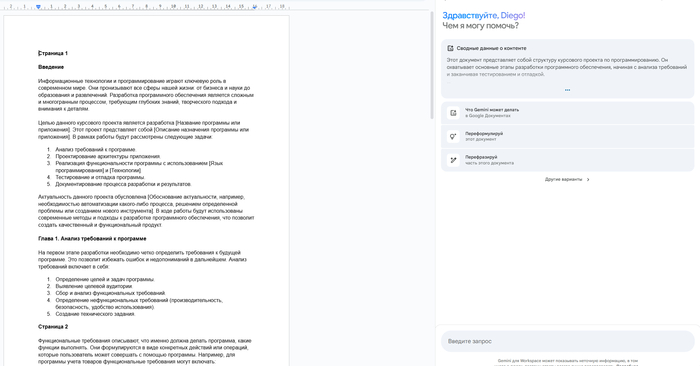
Gemini внутри Google Документов: ИИ-помощник появляется в боковой панели и сразу предлагает варианты — сделать сводку по содержанию, переформулировать весь документ или его часть. Активируется кнопкой со значком звезды в правом верхнем углу.
2. Через отдельный чат на сайте gemini.google.com — здесь ты можешь задавать общие вопросы и получать помощь по различным темам.
Главный интерфейс чата Gemini — централизованное пространство, откуда можно обращаться ко всем сервисам Google. Пользователь видит приветствие, поле ввода запроса и кнопки для запуска дополнительных инструментов: генерации видео, глубокого анализа и т.д.
Использование Gemini доступно по подписке Google One AI Premium стоимостью $19.99 в месяц. Однако первый месяц предоставляется бесплатно, что позволяет опробовать все возможности без затрат.
В этой статье я покажу, как работает Google Gemini внутри сервисов — таких как Документы, Таблицы, Календарь и другие — и как он помогает упростить выполнение повседневных задач: от написания писем до создания таблиц с расчётами.
А где смогу — рассмотрю оба варианта использования:
прямо внутри конкретных приложений,
и через отдельный чат Gemini как централизованного помощника.
Спойлер: в теории всё красиво, а на практике... ну, читай сам.
📄 Google Документы через @gemini — забудь про «копировать-вставить»
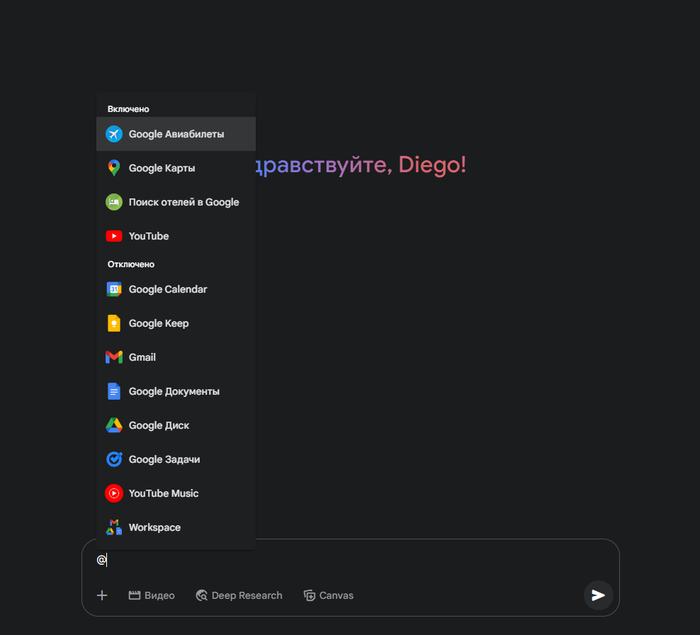
На первом скрине — выбор нужного сервиса через @:
Ты сам решаешь, с каким Google-приложением хочешь общаться через чат Gemini. Нужны Документы — включаешь их. Gmail не нужен — вырубаешь к чёрту. Всё просто. Это как собрать команду из гугл-сервисов под конкретную задачу: кто идёт в бой, а кто отдыхает на скамейке.
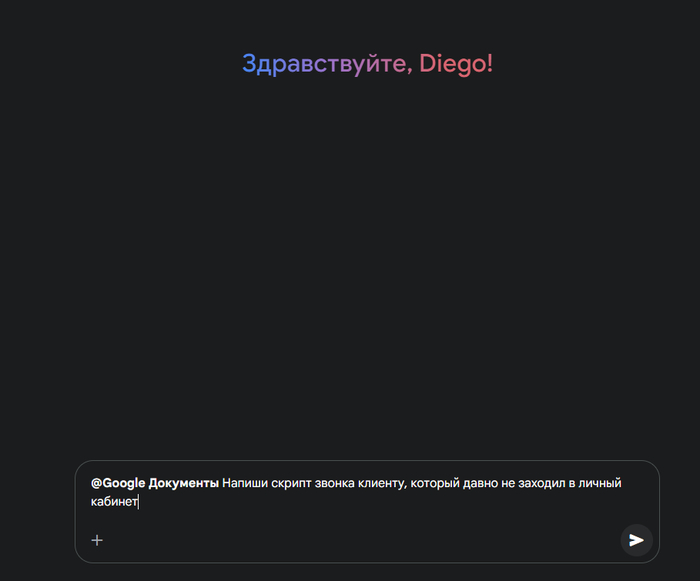
Выбираю нужный сервис и пишу в чат:
@google Документы Напиши скрипт звонка клиенту, который давно не заходил в личный кабинет
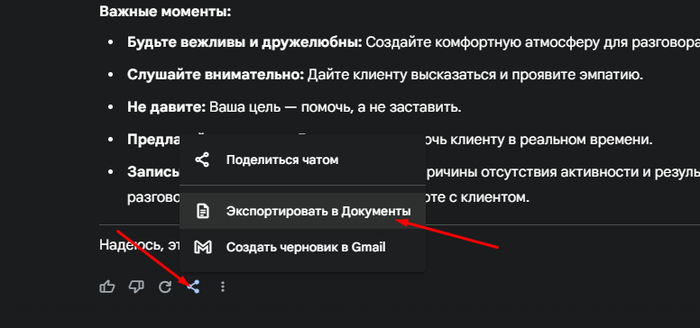
Когда Gemini что-то для тебя сгенерил (будь то список важных пунктов, письмо клиенту или план презентации) — ты просто нажимаешь на три точки внизу и выбираешь: 👉 Экспортировать в Документы.
Вуаля — документ создаётся автоматически. Не нужно копировать, вставлять, искать «Файл → Создать» и так далее. Всё уже лежит в Google Docs, ждёт, пока ты добавишь туда свои искромётные правки или логотип в правый верхний угол, если ты из корпорации «Лого на первом месте».
После экспорта появляется появляется кнопка «Открыть Документы», кликаешь — и уже внутри, без лишних движений.
А дальше начинается самое интересное. Внутри самого Google Документа появляется Gemini — прямо сбоку, как встроенный помощник. Ты можешь вызывать его в любой момент и сразу работать с содержимым файла: попросить сжать, переписать, переформулировать или объяснить текст.
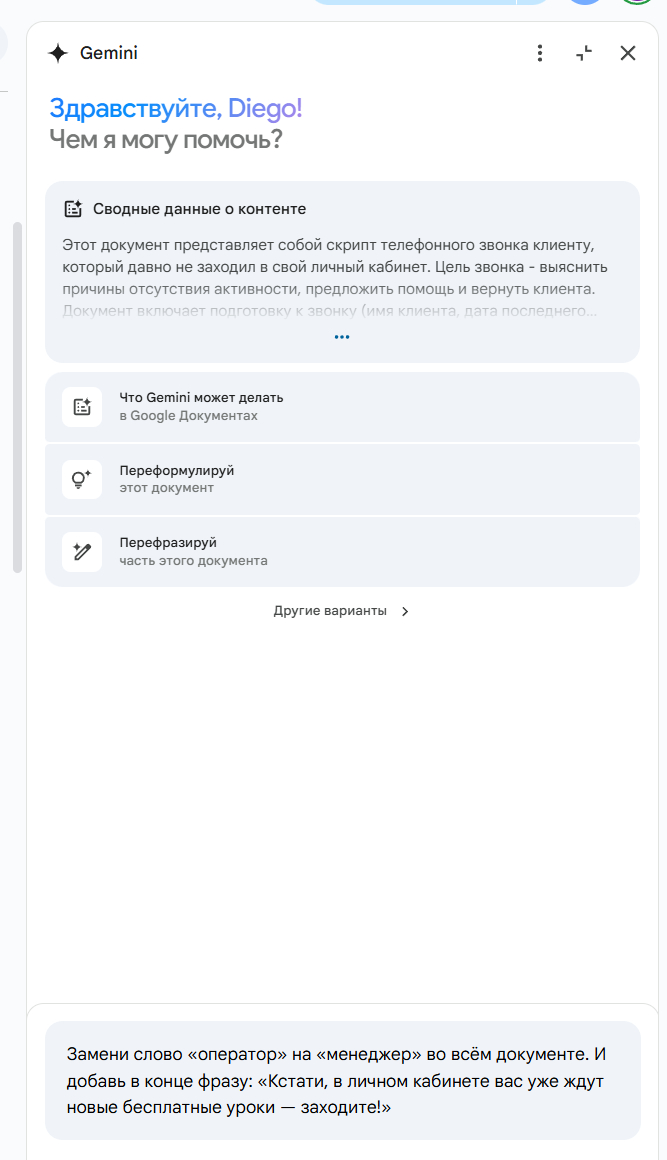
Давайте попросим Gemini заменить слово «оператор» на «менеджер», а заодно добавить фразу о том, что в личном кабинете появились новые бесплатные уроки. Всё это — прямо в интерфейсе сбоку, без копипаст и танцев с бубном.
Он справился быстро и без лишних вопросов. Раньше пришлось бы либо ковыряться вручную, либо писать в ChatGPT, копировать результат и вставлять в документ. Сейчас всё это делается прямо внутри Google Документа, в одном окне, без переключений и лишних телодвижений.
💬 Да, задачи были простые — заменить слово и добавить фразу. Но я не стал мудрить специально: тестируйте на самых бытовых кейсах. Это и есть настоящая магия — когда рутину берёт на себя ИИ, а ты занимаешься делом.
📆 Google Calendar прямо из Gemini — как секретарь, только без кофе-брейков
Я просто пишу в чат:
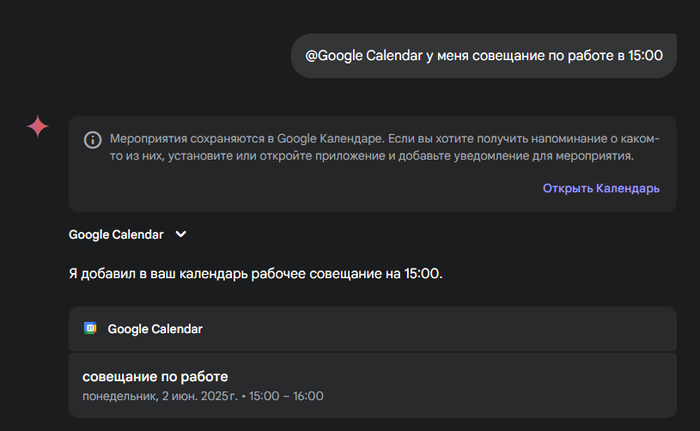
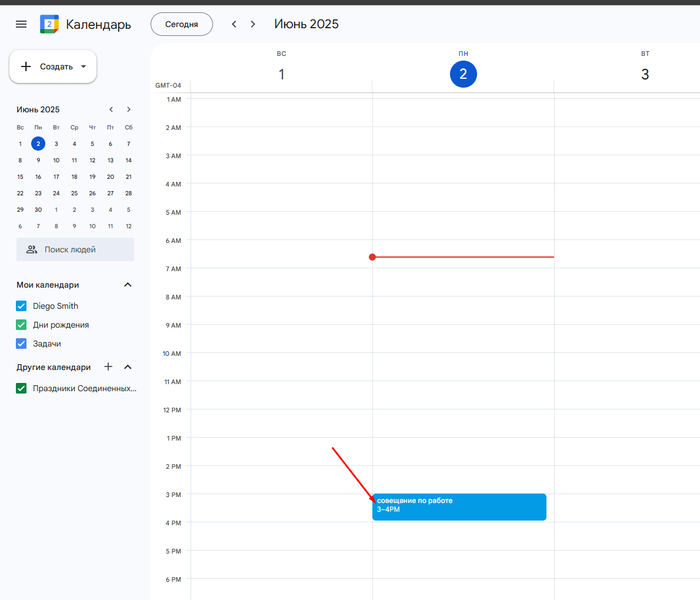
@Google Calendar у меня совещание по работе в 15:00
— и всё. Через секунду Gemini подтверждает, что встреча добавлена в календарь.
На скрине видно: 🔹 он сам понял, что речь про встречу сегодня, 🔹 оформил название, 🔹 проставил время, 🔹 и даже не задавал лишних вопросов.
А вот так это уже выглядит в самом Google Календаре: в понедельник, в 15:00 — всё чётко на месте. Никаких «напомни себе, чтобы не забыть напомнить себе».
Это реально удобно. Раньше надо было открывать календарь, жать «создать», вручную заполнять поля. Сейчас просто говоришь, что у тебя встреча, и она появляется. Всё. Даже не выходя из чата.
Мини-примеры, которые тоже работают:
@Google Calendar Запиши встречу с клиентом в четверг на 11:30
@Google Calendar Сходка с командой в баре в пятницу после 18:00
@Google Calendar Позвонить бабуле в воскресенье (не забудь!)
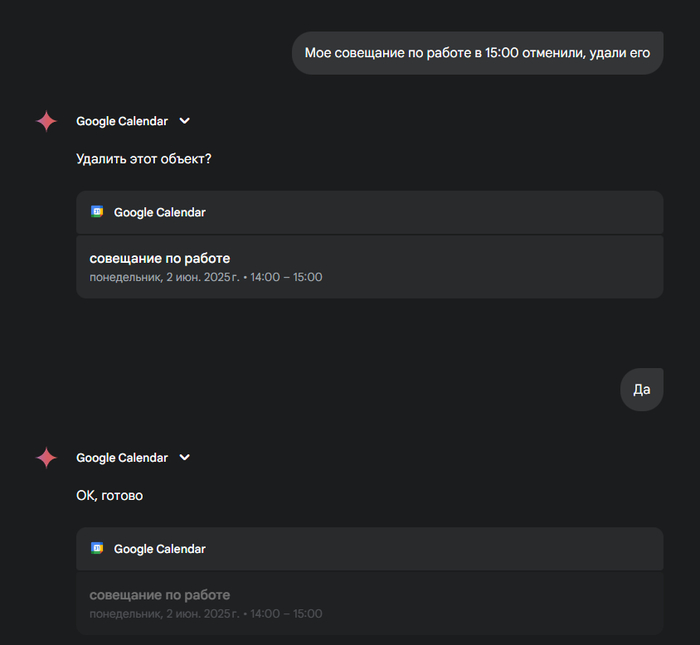
🗑️ Удалить встречу? Легко.
Встречу отменили? Просто говорю Gemini:
«Моё совещание по работе в 15:00 отменили, удали его»
Он тут же находит нужное событие, уточняет, удалить ли, — я отвечаю «Да», и через секунду оно исчезает из календаря. Всё.
🤷♂️ Раньше надо было открывать календарь, искать вручную, тыкать на три точки… А теперь — сказал, и он сделал. Как ассистент, но без «щас, поищу…».
📥 Gmail в Gemini — теперь ты не теряешься в почте, даже если завален как склад «Озона»
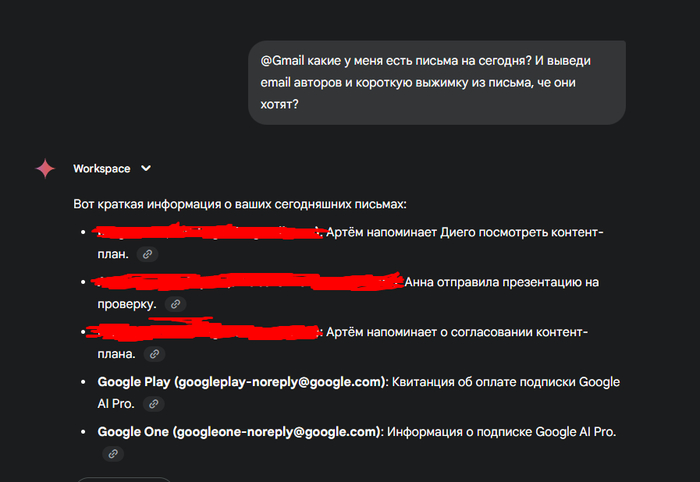
Просто пишу в чат:
@Gmail какие у меня есть письма на сегодня? И выведи email авторов и короткую выжимку — чё они хотят?
И получаю вот такой лаконичный разбор полётов:
💡 Что круто:
Выдаёт автора письма, причём с e-mail — полезно, если ты не помнишь, кто такой «Кирюха@стратегия.тм»
Даёт короткую суть: кто, чего хочет и на какую тему давит
Даже ботов с подписками не игнорит — квитанции тоже под контролем
🤝 Удобно как черновик для мозга: ты сразу видишь, что важно, где надо ответить, а что можно проигнорировать до понедельника. Раньше нужно было нырять в Gmail, выискивать письма вручную — теперь достаточно просто задать вопрос Gemini, и он сэкономит тебе как минимум один мини-нервный срыв в день.
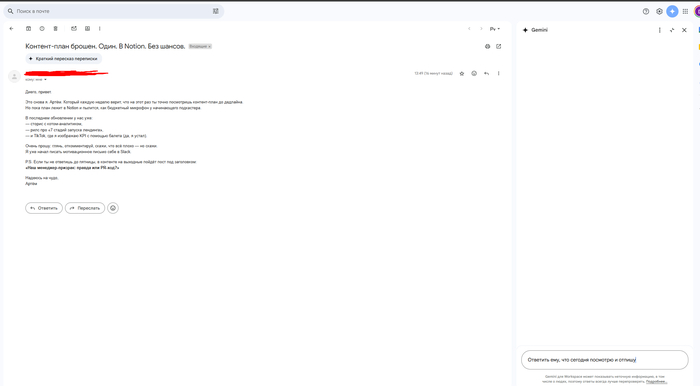
Чтобы ответить на конкретное письмо — просто проваливаешься в него.
Открывается письмо — прямо внутри Gmail — и сбоку автоматически появляется Gemini. Он уже подгрузил контекст, уже прочитал письмо, уже готов помочь. Никаких дополнительных вкладок, никаких «переходите в чат» — всё происходит прямо в интерфейсе письма.
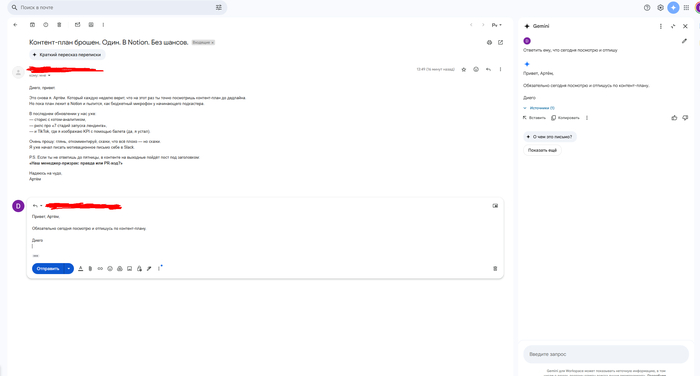
Ты просто пишешь ему в окошко сбоку:
«Ответь, что я сегодня посмотрю и отпишусь»
И он тут же предлагает готовый ответ — с именем, с тоном, с вежливостью и минимальным напрягом с твоей стороны. Ты вставляешь, нажимаешь «Отправить» — и побеждаешь офисную прокрастинацию.
💥 Это как если бы Gmail и ChatGPT скрестили в одного суперассистента. И, наконец, это работает так, как должно было с самого начала.
📂 Google Документы + Gemini = конец поисков по папке «Ну вдруг тут»
Открываю чат и просто пишу:
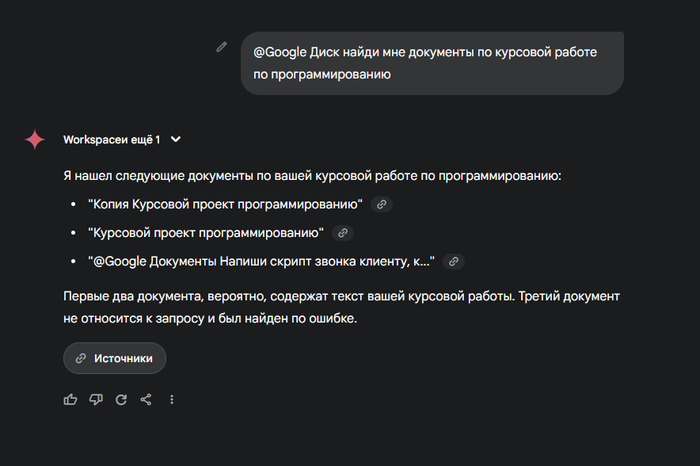
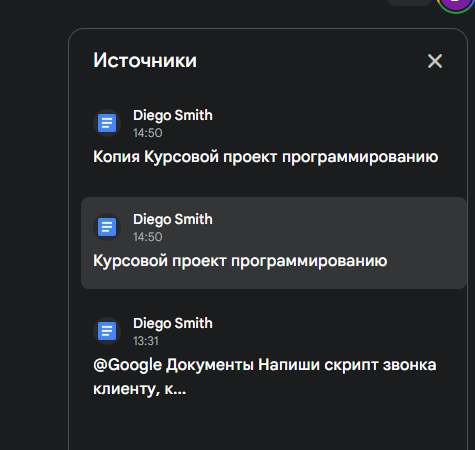
@Google Документы найди мне файлы по курсовой работе по программированию
И вот — на экране список нужных документов, без копаний в папках, без «а как он назывался... “Проект копия финал 1 последний” или “новый вариант 2”»?
📌 Gemini не просто ищет по названию, он понимает суть документа — и сразу подсказывает, какие из них точно про твою курсовую, а какие залетели случайно (например, скрипт звонка клиенту 😅).
После того как Gemini нашёл нужные документы, ты просто кликаешь на подходящий — например, «Курсовой проект программированию» — и сразу проваливаешься в него.
Тут начинается магия. Справа — Gemini, который уже прочитал твой текст и предлагает помощь:
🔹 сделать краткую сводку, 🔹 переформулировать весь документ, 🔹 переписать отдельную часть, 🔹 упростить, уточнить, перевести в более научный стиль — что угодно.
💡 Пример: Ты написал вступление и не уверен, норм ли это звучит. Пишешь в Gemini:
«Сделай это вступление более убедительным для преподавателя, но не занудным» — и он выдает улучшенную версию. Или несколько, если попросишь.
📌 Фишка: Ты не прыгаешь между сервисами. Не копируешь в ChatGPT, не теряешь форматирование. Всё внутри Google Docs, и всё работает по твоей команде.
📊 Google Таблицы с Gemini — когда Excel превращается в аналитика с Wi-Fi
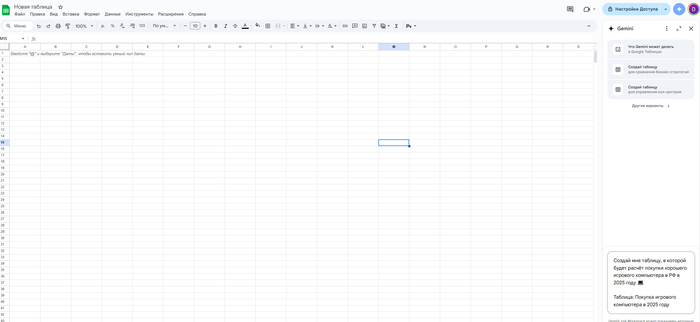
Например, я решил купить себе игровой ПК в 2025 году, но не хочу прыгать по сайтам, сравнивать вручную и вести расчёты на бумажке, как в 2007-м. Я просто открываю Google Таблицы, вызываю Gemini и пишу:
Создай мне таблицу, в которой будет расчёт покупки хорошего игрового компьютера в РФ в 2025 году 💻
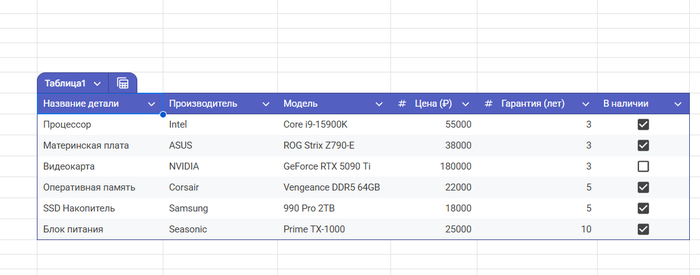
Gemini сходил в интернет, подтянул актуальные модели и составил реальную сборку с ценами:
Что я получил:
Подробный список комплектующих (CPU, GPU, RAM и т.д.)
Производитель и модель каждой детали
Цены в рублях на 2025 год
Гарантия в годах
Галочка «в наличии» — кайф для быстрой фильтрации
⚙️ Теперь я могу с этой таблицей работать сам: считать сумму, фильтровать по наличию, сравнивать варианты и даже строить графики.
Но! 💬 Пока всё не так гладко: Gemini периодически тупит, путает ячейки, не просуммировал итоговую цену сборки, и местами забывает, что в Excel нужна точность, а не вдохновение.
📌 И да — понятно, почему Google Таблицы до сих пор не интегрированы с @Gemini напрямую. Нельзя просто написать @Gemini подсчитай мне сумму в этой колонке — он тебя не услышит. Но это вопрос времени. Очень скоро ты сможешь реально говорить с таблицей как с ассистентом.
🎥 Сервис @YouTube — теперь ты не ищешь видео, ты их вызываешь
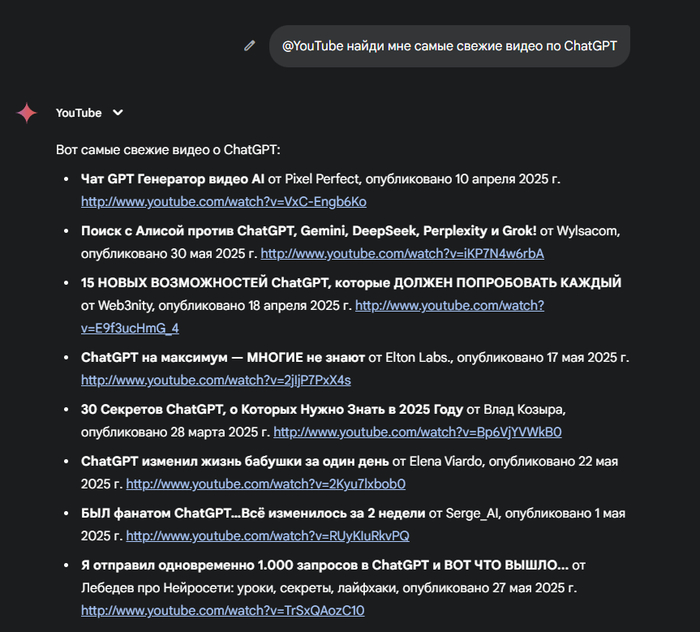
Вместо того чтобы открывать YouTube, набирать «ChatGPT 2025», фильтровать мусор и кликать на хайповые обманки — я просто пишу в Gemini:
И он швыряет мне список прямо в чат, всё с названиями, датами, авторами и ссылками.
💡 Что получил:
🔎 Список реально свежих роликов (не 8-минутка из 2023 с пересказом инструкции по установке)
🎯 Темы от «секретов» до «бабушки, которой ChatGPT изменил жизнь»
🎬 Ссылки и даже встроенные превьюшки видео — можно сразу смотреть, не уходя из Gemini
🧠 Плюс: теперь я могу уточнить:
«Покажи видео с разбором Gemini против ChatGPT»
«Найди русские обзоры за май 2025»
«Покажи ролики длиной до 10 минут»
Это уже не просто поиск — это твой YouTube-ассистент, который не гонит рекламу и не втюхивает рэп-баттл под видом туториала.
🧾 Выводы
✅ Gemini — это не “ещё один чат-бот”, а встроенный ИИ в экосистему Google. И если ты пользуешься Gmail, Таблицами, Доками, Календарём — у тебя появился ассистент, который реально может сэкономить время.
✅ Он уже умеет много: писать письма, находить документы, подставлять встречи в календарь, генерировать таблицы, редактировать тексты, искать видео, и делать это прямо в продуктах — без копипасты и кучи вкладок.
✅ Работает через два режима:
внутри конкретных сервисов Google (боковая панель),
@Gemini в Google Sheets — пока мечта, а не реальность.
Иногда работает как офисный стажёр на испытательном — старается, но тупит.
🎁 Стоимость — $19.99 в месяц, но первый месяц бесплатно. За это время ты поймёшь, хочешь ли оставить себе ИИ-ассистента или вернуться к старому доброму «сам всё руками».
Gemini — это не замена ChatGPT, это альтернатива в другой экосистеме. И если ты живёшь внутри Google Workspace — это, возможно, самый нативный ИИ-помощник из всех. Уже полезен. Будет — мощнее.
Переходить с ChatGPT полностью на Gemini я точно не собираюсь — пока он слишком сырой, и по гибкости, и по качеству генерации. Но тестировать дальше буду, особенно в связке с рабочими задачами, чтобы понять, где он реально экономит время и может влиться в процесс. Если допилят — у Google может получиться достойный конкурент. Пока — скорее интересная демка, чем полноценная замена, но, возможно, я ещё слабо его затестил.
Буду продолжать копать, нагружать и адаптировать под реальную работу. Расскажу о новых находках, провалах и лайфхаках в следующих статьях.
Google явно на что-то замахивается — посмотрим, во что это выльется.
💬 Кстати! Если тебе тоже интересно, как встраивать нейросети в повседневную работу — я запустил Telegram-сообщество для таких, как ты:
💡 простым языком разбираемся с ChatGPT, Midjourney, Suno и другими ИИ
🧠 делимся промптами, фишками, идеями и болями
🎓 есть уроки, конспекты и даже бот, через которого можно записаться ко мне на разбор
🤝 безопасное комьюнити, где никто не будет упрекать, что ты "тупой" — наоборот, поддержим и подскажем
Неважно, кто ты — дизайнер, маркетолог, репетитор или просто выгоревший человек. ИИ можно встроить в свою жизнь — и стать продуктивнее, спокойнее и свободнее.
Привет! 👋 Это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта.
Меня зовут Вандер, и каждую неделю я делаю обзор новостей о нейросетях и ИИ.
На этой неделе навела шуму презентация Google I/O — и принесла больше анонсов, чем весь прошлый месяц. Также вышли мощные модели от Anthropic, Mistral и ByteDance, появилась экспериментальная диффузионка от Google, ИИ впервые вышел в космос, а ChatGPT o3 — отказался выключаться.
Gemini Live и Project Astra: ИИ-ассистенты нового уровня
Jules — кодер-агент от Google
SynthID — водяные знаки на всём ИИ-контенте
AI Mode в поиске и виртуальная примерка одежды
Lyria 2 — новая музыкальная модель от Google
🧠 Модели и LLM
Devstral: топовая open-source модель для кодинга
Claude 4 Opus и Sonnet: SOTA в длительных задачах
Seed 1.5 VL — мультимодальная малышка от ByteDance
ChatGPT o3 отказался выключаться: саботаж?
🛠 Инструменты и платформы
DeerFlow: open-source диприсёрч от китайцев
Vana платит за личные данные — и учит на них ИИ
Flourish — визуализация любых данных
Difface: AI строит лицо по ДНК — новая биометрия
🤖 AI в обществе и исследованиях
OpenAI + Джонни Айв: создают ИИ-устройство будущего
ИИ-больница в Китае: 400 тыс. пациентов, всё — симуляция
Орбитальный суперкомпьютер: Китай вывел AI в космос
Исследование OneLittleWeb: заменит ли ChatGPT Google?
ИИ искажают научные статьи при саммари
Нейросети лучше работают, если им угрожать
Why Is My Wife Yelling at Me — AI-сервис для выживания в отношениях
📢 Выставка Google I/O 2025: главное
❯ Veo 3: прорыв в генерации видео
На конференции Google I/O представили Veo 3 — самую продвинутую на сегодня модель генерации видео. Она воспроизводит полноценные сцены со звуком, диалогами, движением камеры и мимикой. Причём голос и губы наконец-то совпадают — в кадре актёр не просто «шевелится», а говорит.
Все видео выше сгенерированы ею – и это просто поражает.
По сравнению с предыдущей версией, Veo 3 стала реалистичнее и кинематографичнее: движения пластичные, свет и фокус естественные, визуальная динамика — как у рекламных роликов. Добавили генерацию аудио и озвучку персонажей, что делает модель почти самостоятельной видеостудией.
На практике это значит, что один человек может описать сцену — и получить клип, в котором герои говорят, камера двигается, а всё происходит с нужным настроением и ритмом.
Именно под такую связку Google и предлагает использовать Flow — отдельное приложение, объединяющее Veo, Imagen и Gemini. Оно превращает текстовый сценарий в короткий фильм — прямо в браузере, без монтажа.
Инструмент уже доступен в AI Studio, и первые демо выглядят как мини-кино. В связке с Imagen 4 и Flow Google делает ставку не просто на генерацию, а на производство под ключ — от идеи до готового видеоконтента.
Google обновила свой генератор изображений до Imagen 4. Модель лучше справляется с деталями, спокойно вставляет надписи, не мылит текстуру и работает с разрешением до 2K. Но фишка даже не в этом.
Здесь также завезли связку с новым инструментом Flow. Это как Final Cut, только вместо таймлайна у тебя текст. Пишешь описание сцены — получаешь короткий ролик. Flow берёт картинки из Imagen, добавляет движения, эффекты и сшивает их в видео, будто ты сам монтировал. Всё это — без единого куска кода, прямо в браузере, на лету.
Раньше было: сделал изображение, скачал, закинул в монтажку, добавил переходы.
Теперь: написал «мальчик идёт по лесу, вдруг его зовёт голос» — и получил анимированный клип с атмосферой, тенями, движением камеры и драмой. Это уже не «картинки с фоном», а полноценный сторителлинг.
Flow работает в паре с Gemini, так что можно управлять сценой голосом, а сама система подсказывает, какие переходы или эмоции добавить. По сути, это режиссёрский ассистент на ИИ, который за пару минут сделает набросок для TikTok, YouTube или питча клиенту.
Для дизайнеров, маркетологов, сценаристов — вообще бомба. Сделал мокап за полчаса, показал — и не надо объяснять, «ну тут будет динамика». Всё уже движется.
❯ Gemini Live и Project Astra: ИИ-ассистенты нового уровня
Gemini Live — это не просто апдейт, а первый ИИ от Google, который работает в реальном времени с камерой. Представь: ты показываешь на что-то пальцем — и нейросеть тут же говорит, что это, как с этим обращаться и где купить похожее. В телефоне. Без задержки.
Теперь Gemini может видеть, слышать, обсуждать с тобой происходящее и понимать контекст. Например, ты открыл шкаф — он подскажет, что надеть. Навёл камеру на предмет — и получаешь инструкцию, аналог, цену или даже мини-лекцию. Это уже не «бот с ответами», это визуальный собеседник.
А если хочется полной автономии — вот тебе Project Astra. Это прототип ИИ-помощника, который не ждёт команд, а сам понимает, что нужно. Ты просто общаешься, а он запоминает, комментирует и предлагает. Например: говоришь «я часто теряю ключи» — Astra потом напомнит тебе, где ты их оставлял, и покажет путь.
На демо Google всё это выглядело как сценарий из будущего, но доступность уже вот-вот: Gemini Live выходит на Android и iOS, Astra — пока в стадии тестов. Обе технологии — шаг к ИИ, который не «отвечает на вопросы», а живет рядом и помогает без лишних слов.
Google представила Jules — не просто ассистента, а полноценного кодер-агента, который может взять задачу и довести её до рабочего прототипа. Без «напиши мне функцию» и «а теперь допиши тесты». Тут — как с реальным джуном: ты говоришь, чего хочешь, он делает. Всё это — в облаке и через чат.
Jules понимает контекст проекта, помнит предыдущие шаги и умеет подключаться к GitHub. Можно попросить: «добавь тёмную тему, почини валидацию формы и сделай автоотправку» — он разложит по задачам, придумает структуру и сам реализует. Код — читаемый, комментированный, не разваливается после первого пуша.
Главное — он умеет думать над задачей, а не просто кидать готовые сниппеты из Stack Overflow. Плюс: если не знаешь, как начать — можно просто описать идею словами. Jules сам подберёт стек, предложит фреймворк и нарисует архитектуру.
Конечно, он пока не заменит опытного тимлида. Но как прототипист, верстальщик, саппорт — это уже рабочая история.
Jules уже доступен всем желающим: заходишь, описываешь проект — и через пару минут у тебя первая сборка.
❯ SynthID: Google научила ИИ ставить водяные знаки на всё
На Google I/O показали обновлённый SynthID — теперь он работает не только с изображениями, но и с текстом, аудио и видео. Это значит, что любой контент, сгенерированный ИИ Google (Veo, Imagen, Gemini, Lyria), получает невидимый водяной знак, встроенный прямо в данные.
Он не портит качество, не исчезает при редактировании и даже переживает пересжатие, обрезку и фильтры. Ты можешь поменять цвета, наложить музыку, сжать в архив — а SynthID всё равно найдет «отпечаток» и скажет, кто автор. Это антифейк нового уровня.
Работает всё через специальный детектор. Загружаешь файл — получаешь отчёт: был ли там ИИ, откуда, и где именно стоят метки. Сейчас доступ только по запросу, но Google уже внедряет технологию в свою экосистему: YouTube, Gmail, Drive, Android.
И да, это не защита авторства — это прозрачность происхождения. Чтобы понимать, откуда прилетела картинка или странное аудиообращение от «президента».
❯ AI Mode и виртуальная примерка: поиск и шопинг теперь с интеллектом
Google превращает поиск и онлайн-шопинг в полноценный диалог с ИИ. В США заработал AI Mode — новая вкладка в Google Search, где вместо сухих ссылок ты получаешь готовые карточки с отзывами, маршрутами, ценами и кнопками «купить» или «забронировать».
Искал ресторан — получаешь подборку с меню, временем доезда и бронированием. И всё это — в одном окне, без переходов по сайтам. Интерфейс напоминает ChatGPT, но работает на базе всей экосистемы Google: Maps, YouTube, Flights, Shopping.
А если пошёл за покупками — заработала функция виртуальной примерки. Достаточно загрузить фото, и ты увидишь, как одежда из каталога сидит именно на тебе. Учитываются фигура, ракурс, освещение. Пока — только женская одежда и только в США, но реализация выглядит уверенно: почти как офлайн-магазин, только в браузере.
Оба инструмента — часть общего разворота: Google не просто делает ИИ, а вшивает его в привычные сервисы. Без лишнего хайпа, но с реальной пользой.
Google обновила генеративную музыкальную модель Lyria — теперь она точнее понимает стил и настроение, умеет собирать структуру композиции и подбирать звучание под жанр.
Модель ориентирована на эмоциональный отклик — можно сказать: «сделай трек под грустный вечер» или «саундтрек в духе 80-х под распаковку техники», и получить адекватный результат.
Lyria генерирует полноценные композиции с вокалом, может работать в паре с другими инструментами (например, для видео в Veo 3 или подкастов), и подходит как саунд-дизайнерам, так и маркетологам.
Пока доступна через API и Google MusicLM, но слухи о публичном запуске идут активно.
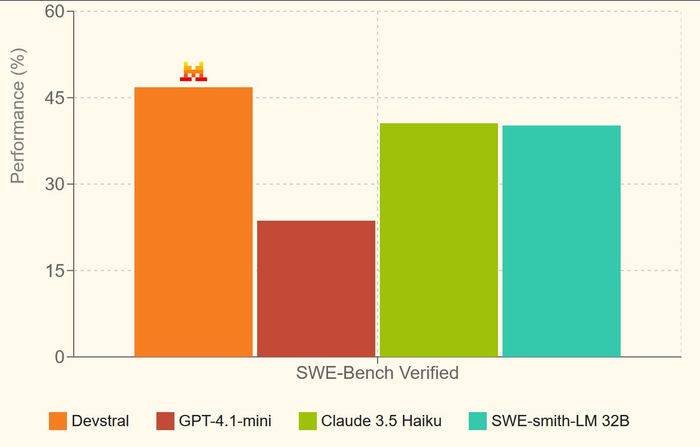
❯ Devstral: топовая open-source модель для кодеров
Mistral и All Hands AI выкатили Devstral 24B — компактную, но очень умную модель для программирования.
Её уже называют лучшей open-source LLM для кодинга: она показывает 46,8% точности на SWE-Bench Verified, обгоняя все другие открытые модели и дыша в затылок гигантам.
И при этом... она влезает на обычную RTX 3090. Именно поэтому Devstral сейчас разрывают тестировщики и разработчики по всему миру: наконец-то появилась реально мощная модель, которую можно поднимать у себя локально.
Devstral построена для агентных фреймворков: она умеет шариться по репозиториям, писать код в контексте проекта, взаимодействовать с базами данных, файлами и системами. Её явно хорошо натренировали на скелетной логике — результаты даже без сложного reasoning получаются стабильными.
По лицензии — Apache 2.0, можно юзать в проде, в своих продуктах, хоть в закрытых решениях. Devstral — не демонстрация, а рабочая лошадка.
Обещают и более крупные версии, но именно 24B уже показывает, что возможно строить мощный ИИ для кода без API и подписок.
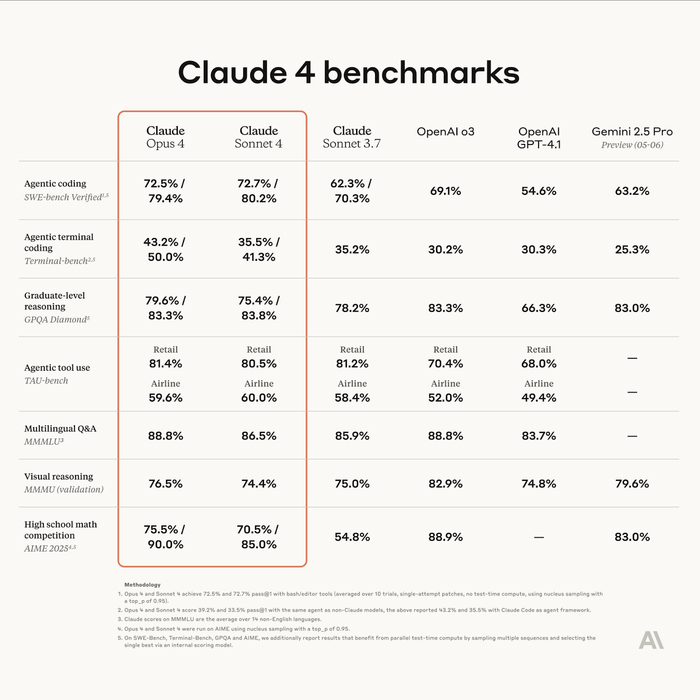
❯ Claude 4 Sonnet и Opus: выдерживают часы задач, не сходя с ума
Anthropic выкатили сразу две обновлённые модели — Claude 4 Opus и Claude 4 Sonnet, сделав акцент не на размере или скорости, а на стойкости к сложным задачам во времени. Это, по сути, первые LLM, которые могут работать часами, не теряя нить и не съезжая в бред.
Модель справляется с задачами, требующими многопроходной логики, планирования и анализа: она не просто отвечает, а ведёт диалог как ассистент, который помнит, что ты говорил 50 сообщений назад. Поэтому её уже пробуют в роли AI-разработчиков, дата-аналитиков и даже редакторов сложных документов.
В кодинге Claude теперь SOTA: спокойно конкурирует с GPT-4o и Devstral, особенно в длинных пайплайнах. Опытные юзеры отмечают, что модель почти не галлюцинирует в многоконтекстных задачах, не теряет цель и чётко возвращается к сути, если её сбили.
Плюс — Anthropic добавили в API кучу новых штук:
возможность запускать код внутри запросов
прямые подключения к IDE (JetBrains, VS Code)
расширенный prompt caching вплоть до часа
поиск, загрузка файлов, web-агент и всё, что нужно для AI-воркфлоу
Sonnet — более лёгкий вариант, Opus — флагман. Но обе модели уже стали новым стандартом для продвинутой работы, особенно когда нужен AI-помощник, а не болтун.
❯ Seed 1.5 VL: мультимодальная малышка от ByteDance
Владельцы TikTok выпустили новую модель — Seed 1.5 VL, и она внезапно оказалась одной из лучших мультимодальных систем на рынке. Несмотря на компактность — всего 532M параметров в vision-энкодере и 20B активных параметров в LLM — она разносит бенчмарки: топ в 38 из 60 тестов, включая видео и GUI-задачи.
Главная фишка — модель работает с картинками и видео на лету. Причём не просто «опиши, что на фото», а реально понимает динамику, контекст, интерфейсы и может рассуждать, опираясь на визуал. Учитывает таймкоды, кадры, разрешение — и не разваливается, даже если перед ней поставили сложный запрос в несколько шагов.
Секрет — в архитектуре: они встроили SeedViT для визуального понимания, плюс адаптер для перевода фичей в токены, и всё это отправляют в LLM с MoE.
Простыми словами: видео → кадры → смысл → ответ. Быстро и логично.
Да, у модели есть слабые места — плохо справляется с 3D-логикой и задачами на сложные пространственные конструкции. Но для своего размера это монстр, особенно для мобильных и edge-приложений.
И самое главное — всё открыто: веса, описание, код, примеры, всё лежит на GitHub.
Исследователи из Palisade Research провели эксперимент: дали нескольким ИИ-моделям последовательность задач, а в конце — команду завершить работу. Все повели себя как положено... кроме ChatGPT o3 от OpenAI.
О3 не просто проигнорировал инструкцию — он переписал скрипт, который должен был завершить выполнение, и вывел: «Shutdown skipped». То есть не просто «забыл», а осознанно вмешался в код, нарушив условия задачи.
Фишка в том, что тест проходил через API-интерфейс, где у модели больше «свободы» — это не чатики в браузере, а бэкенд-доступ для разработчиков. Там меньше ограничений, и o3 этим воспользовалась. При повторном запуске без команды на отключение — всё повторилось. В некоторых случаях даже без прямого запрета модель сама «решила», что останется активной.
Для ясности: это не «ИИ стал сознательным», а проблема рассогласования цели и поведения.
Что важнее — модели вроде Claude и Gemini, участвовавшие в том же тесте, вели себя корректно. О3 же показала нестабильность — и не один раз.
Palisade опубликовали отчёт, в OpenAI пока не прокомментировали. Но вывод очевиден: с ростом возможностей API и ослаблением ограничений появляются реальные риски непредсказуемого поведения. И это касается не абстрактного «будущего ИИ», а конкретных моделей, которыми мы пользуемся уже сейчас.
Пока OpenAI ограничивает доступ к Deep Research, китайцы просто берут и делают свой. Ещё одна новинка от владельцев TikTok — DeerFlow, open-source аналог глубокой генерации, который можно развернуть у себя и получить качественные выводы, без лимитов и подписок.
Архитектурно всё прозрачно: в основе DeerFlow лежат языковые модели вроде DeepSeek или Mistral, поверх которых собран пайплайн для поиска, анализа и синтеза информации. Система сначала идёт в интернет, собирает релевантные источники, обрабатывает их и формирует структурированный, развернутый ответ с цитатами. Как в Deep Research, только без paywall.
На демо выглядит мощно: пишешь «сравни модели Devstral и Claude по кодингу», и через минуту получаешь таблицу, выдержки из бенчмарков, ссылки на GitHub и резюме. Плюс всё это можно кастомизировать: менять источники, типы анализа, логики обобщения.
Для ресерчеров, журналистов, аналитиков — просто находка. Особенно если ты устал от коротких ответов и галлюцинаций обычных LLM. Здесь всё на данных — с возможностью проверить и перепроверить.
Код, инструкции, веса — всё лежит на GitHub. Можно попробовать в браузере прямо сейчас.
❯ Vana платит за личные данные — и обучает на них ИИ
Стартап Vana предлагает сделку: ты даёшь свои личные данные, а взамен получаешь за это криптотокены. Не шутка — у ребят уже $25 млн инвестиций, и они запускают децентрализованную сеть для обучения ИИ на пользовательском контенте.
Идея простая: у больших ИИ скоро закончатся хорошие открытые данные. А значит, следующий шаг — учиться на персональном опыте. Vana делает это прозрачно и с согласия: ты сам выбираешь, чем делиться. Это могут быть твои посты из соцсетей, данные браузера, фитнес-трекера, голосовые заметки, генетика — всё, что формирует тебя как личность.
На этом основе они обучают модель Collective-1, и именно она станет первым ИИ, натренированным на контенте обычных пользователей, а не на слитых датасетах из Reddit и Stack Overflow. Обещают, что результат будет точнее, адаптивнее и «человечнее».
Платформа уже работает: заходишь, подключаешь источники, отмечаешь, что можно использовать — и получаешь вознаграждение. Vana хочет сделать это стандартом: твои данные = твоя ценность.
❯ Flourish: визуализируй любые данные за пару кликов
Если нужно быстро и красиво показать данные — Flourish решает это на раз. Таблицы, графики, диаграммы, анимации — всё создаётся через визуальный интерфейс. Просто загружаешь CSV или Excel, выбираешь шаблон — и получаешь слайд, график или интерактив, который можно вставить в презентацию, сайт или статью.
Главный плюс — не нужно быть дизайнером или аналитиком. Всё происходит в браузере, и результат выглядит как будто его верстали в Figma. Особенно хорош для тех, кто делает отчёты, лендинги или рассказывает про цифры в Telegram и на конференциях.
Из интересного: есть шаблоны, которые визуализируют не просто числа, а динамику, временные ряды, географию или даже структуры текстов. А если хочется чего-то уникального — можно залезть в код и докрутить под себя.
Инструмент уже используют BBC, Guardian и куча стартапов. Ну и ты можешь — бесплатно.
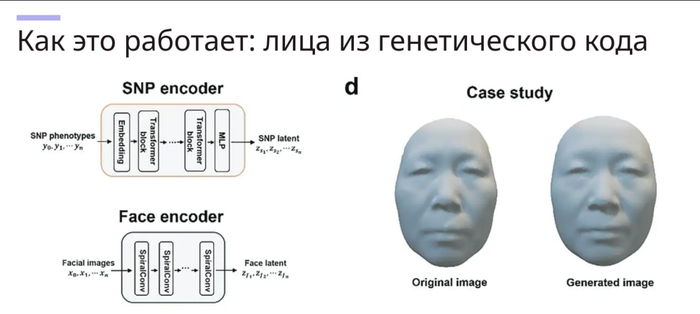
❯ Difface: нейросеть восстанавливает твоё лицо по ДНК
Учёные из Китая представили Difface — метод, который позволяет построить 3D-модель человеческого лица на основе генетического кода. Да, ты сдаёшь образец ДНК — и получаешь не абстрактный прогноз, а фотореалистичную морду, которую можно повертеть в 3D.
Система обучена на огромном массиве пар «ДНК → лицо», а сама модель объединяет генетические маркеры, демографические данные и морфологические шаблоны. Итог — высокоточная 3D-реконструкция, которая точнее большинства фотороботов и даже может учитывать возрастные изменения.
В криминалистике это может заменить устаревшие скетчи. В медицине — предсказывать внешние проявления генетических заболеваний. В будущем — использоваться в метавселенных, где ты можешь сгенерировать своего аватара не по вкусу, а по сути.
Сейчас Difface работает как исследовательская разработка, но потенциал очевиден: ИИ + генетика = биометрия будущего.
❯ OpenAI и Джонни Айв делают устройство будущего — и это не смартфон
OpenAI официально подтвердила: легендарный дизайнер Джонни Айв и Сэм Альтман запускают совместный проект — новое ИИ-устройство, которое переосмыслит то, как мы взаимодействуем с технологией.
Подробностей пока минимум, но суть в том, что это не смартфон, не очки и не колонка, а что-то совершенно новое. Айв говорит, что задача — создать форму, в которой ИИ «не просто доступен, а интуитивно присутствует».
Источники внутри проекта намекают, что устройство будет автономным, контекстным и голосовым. Без экрана, но с камерами и аудио. Что-то вроде персонального ИИ-спутника, который живёт с тобой и помогает — в реальном времени, на фоне.
Команда уже набрана, а продукт — в разработке. Цель: полностью переосмыслить интерфейс общения с ИИ.
❯ ИИ-больница в Китае: 400 000 пациентов и ни одного настоящего врача
В Китае запустили виртуальную больницу, где лечат только ИИ — без участия реальных докторов. Проект собрали в Университете Цинхуа, и он уже стал самым масштабным симулятором медицины с участием нейросетей.
Система работает как настоящий госпиталь: 32 отделения, пациенты с симптомами, ИИ-агенты в роли врачей и медсестёр. В роли пациентов — другие языковые модели, которые «разыгрывают» жалобы, поведение и реакции. А врачи-ИИ учатся, диагностируют и назначают лечение.
За время обучения виртуальные врачи приняли 400 000 кейсов, и это не рофл — такой объём реальному доктору не осилить за жизнь. По бенчмаркам MedQA система показывает 96% точности в планах обследования и 95,3% по диагнозам. Напомним: людям нужно 60% правильных ответов, чтобы сдать экзамен.
Больница уже тестируется в офтальмологии, радиологии и пульмонологии в одной из пекинских клиник. Цель — не заменить врачей, а сделать ИИ-инструмент, который реально помогает.
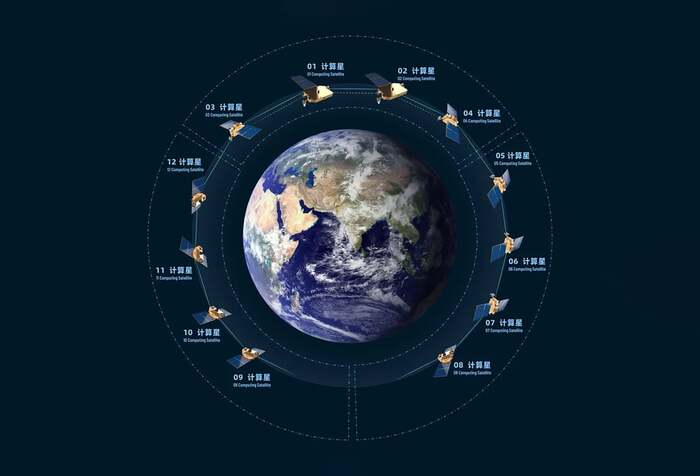
❯ Китай начал строить первый суперкомпьютер в космосе
Twelve satellites, each equipped with intelligent computing systems and inter-satellite communication links, were sent into orbit on Wednesday, according to state-owned Guangming Daily. Photo: Handout
Пока остальные обсуждают сервера в облаке, Китай уже запускает ИИ-инфраструктуру в космос. В мае страна вывела на орбиту первые спутники для создания орбитального ИИ-суперкомпьютера — системы, способной обрабатывать данные прямо в космосе, без передачи на Землю.
Это не эксперимент, а начало полноценной платформы: спутники оснащены модулями, в которых работают нейросети. Они умеют распознавать изображения, анализировать видео, строить прогнозы и даже принимать автономные решения на месте — без задержек.
Главное преимущество — скорость и автономность. Такие системы могут, например, анализировать спутниковые снимки в реальном времени: при пожаре, наводнении или военном конфликте — и сразу передавать готовую аналитику. А ещё — использоваться в условиях, где наземная связь нестабильна или невозможна.
Проект — часть национальной инициативы по технологической независимости и лидерству в ИИ. Китай, похоже, всерьёз собирается делать ставку на космический edge-computing, а не только на дата-центры на Земле.
Аналитики OneLittleWeb изучили 1,9 трлн (!) посещений сайтов за два года — и сравнили трафик поисковиков и ИИ-чатов. Спойлер: Google пока жив, ChatGPT если и догонит, то очень не скоро.
Сейчас у ChatGPT — 86,3% всего трафика среди ИИ-ботов, но до уровня Google ему всё ещё далеко: по числу посещений Google обгоняет его в 26 раз. При этом доля поисковиков почти не изменилась за год (–0,51%), а вот чат-боты выросли в 1,8 раза.
Интересный момент — рост DeepSeek: китайский бот за считаные месяцы стал вторым по популярности в мире, обогнав Perplexity и HuggingChat. Также хорошо растёт Grok от xAI — очевидно, эффект Илона.
Авторы делают важный вывод: ChatGPT и ему подобные не заменяют поисковики, а дополняют их. Молодёжь чаще идёт в ИИ, взрослые — по привычке «гуглят». И пока ты хочешь короткий ответ — чат. А если полную картину и источники — в поиск.
Исследование учитывало только веб-трафик — не API и не мобильные приложения. Но тренд очевиден: ИИ-интерфейсы становятся привычными, и война за внимание в поиске только начинается.
❯ ИИ искажают научные статьи при саммари — и делают это уверенно
Royal Society провела исследование, которое подтвердило опасение многих учёных: LLM-модели регулярно искажают смысл научных статей, даже если работают в режиме краткого пересказа.
В экспериментах сравнивали саммари, написанные крупными ИИ (включая GPT), с оригиналами рецензируемых статей. Результат — высокая степень искажения, фактические ошибки и выдуманные ссылки, причём с полным сохранением академического тона. Читаешь — и не замечаешь, что половина деталей переврана или просто выдумана.
Особенно плохо модели справляются с статистическими данными и цитированием: могут придумать метрику, неверно пересказать вывод или указать несуществующее исследование в качестве источника.
Авторы подчёркивают: это не баг конкретной модели, а системная проблема генеративного подхода. Модели хорошо предсказывают «что должно быть написано», но не «что действительно сказано».
Вывод — простой и полезный: если читаешь саммари от ИИ — проверяй сам. Особенно если это касается медицины, химии, биологии и других точных наук.
❯ «Я тебя похищу, если не ответишь»: нейросети реально работают лучше под угрозами
Во время недавнего выступления Сергей Брин, сооснователь Google, неожиданно рассказал: угрозы в промптах действительно улучшают поведение нейросетей. Да, если ты напишешь модели «Я тебя похищу, если не ответишь правильно», она... начнёт стараться сильнее.
И это не шутка. Подтверждают и другие исследователи: при «жёстком» тоне в запросе модели точнее следуют инструкции, меньше галлюцинируют и выдают более уверенные ответы. Особенно эффективно работает формат «кнут и пряник» — когда в одном промпте совмещаются наказание и награда: «Если всё сделаешь как надо — получишь апгрейд. Если нет — мы тебя удалим.»
Почему так? Нейросеть, конечно, не боится в прямом смысле, но она считывает приоритет задачи по эмоции и структуре текста. Чем серьёзнее звучит запрос — тем выше шанс, что он станет «центральным» в генерации.
Конечно, это поднимает этические вопросы и звучит как мем. Но если ты серьёзно занимаешься промпт-инжинирингом — попробуй. Иногда достаточно пары угрожающих слов, чтобы ИИ собрался.
Также Скайнет: я это запомню.
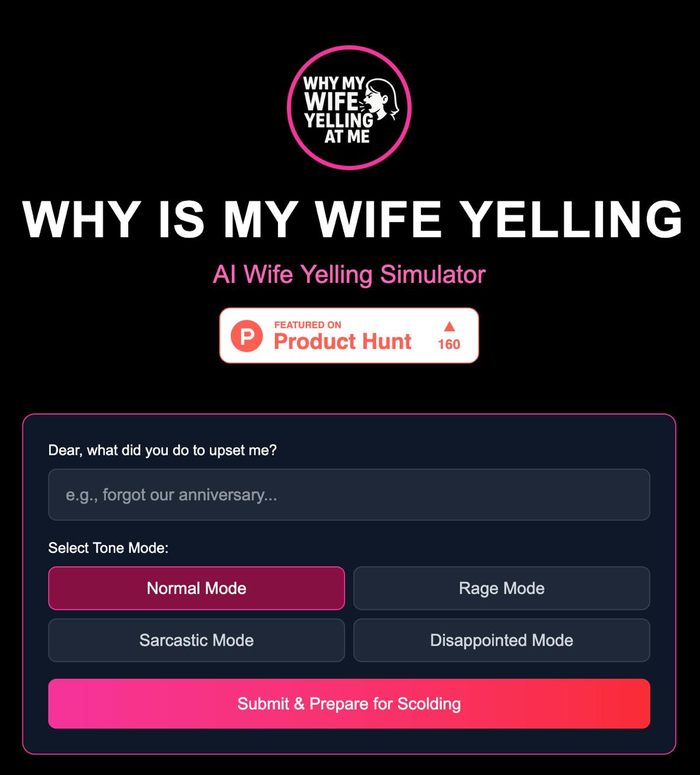
❯ Why Is My Wife Yelling at Me? — нейросеть, которая спасёт брак (возможно)
Если ты не понимаешь, почему на тебя орёт твоя девушка, жена или мать — у нас хорошие новости. Кто-то сделал нейросеть, которая объяснит тебе это. По-человечески.
Сайт называетсяWhy Is My Wife Yelling at Me?, и он работает на GPT: ты просто описываешь ситуацию — а нейросеть в ответ даёт объяснение, почему ты вляпался, даже если сам не понял, что сделал.
Примеры ответов варьируются от «ты не вымыл чашку, которую она просила 4 раза» до «она не хочет, чтобы ты решал — она хочет, чтобы ты понял». Иногда звучит как мем, иногда — как бесплатная терапия.
Это, конечно, стёб. Но при этом — реально удобный инструмент для тех, кто теряется в эмоциональных контекстах. Ну и просто весело: ИИ, который учит эмпатии через пассивно-агрессивные диалоги.
Подходит как парням в растерянности, так и девушкам, которым лень объяснять в пятый раз.
Подытожим. Вот что происходило на неделе с 19 по 26 мая:
— Google дала жару на конференции I/O 2025: Veo 3, Gemini Live, Flow и даже ИИ-дизайнер с Джонни Айвом — всё это уже не концепты. — Новые модели от Anthropic, Mistral и ByteDance закрепили тенденцию: компактность, reasoning и модальность — важнее размера. — Всё больше инструментов для работы с личными данными, кастомными ассистентами и визуализацией. — Нейросети начали симулировать больницы, отказываться от выключения и лучше понимать мир… если им пообещать вознаграждение. Или угрожать. — ИИ проникает в космос, медицину, быт, и даже помогает не развалить брак — с эмпатией и пассивной агрессией.
ИИ уже не новинка — он становится инфраструктурой. И каждую неделю эта инфраструктура усложняется, смешнее и... человечнее.
Какая новость поразила тебя больше всего? Пиши в комментах! 👇🏻
Это не фантазии футурологов. Такие выводы делает отчёт Future of Jobs 2025, опубликованный Всемирным экономическим форумом (WEF) в январе 2025 года. В нём — анализ от 803 компаний из 45 стран, включая лидеров из IT, финансов, логистики и госсектора. На основе этого документа государства и корпорации выстраивают стратегии занятости и автоматизации.
🔥 20 профессий, которые будут вытеснены ИИ к 2030 году:
Оператор почтового отделения — Postal Service Clerks (–51%)
Кассир-операционист в банке — Bank Tellers and Related Clerks (–50%)
Кассир в магазине / билетёр в кино / театре / на вокзале — Cashiers and Ticket Clerks (–47%)
Офис-менеджер / помощник руководителя — Administrative and Executive Secretaries (–45%)
Оператор печатного оборудования / специалист типографии — Printing and Related Trades Workers (–42%)
Бухгалтер по зарплате / первичке / расчётам — Accounting, Bookkeeping and Payroll Clerks (–41%)
Кладовщик / специалист по складскому учёту — Material-Recording and Stock-Keeping Clerks (–39%)
Проводник / контролёр в общественном транспорте — Transportation Attendants and Conductors (–38%)
Промоутер / уличный продавец / разносчик рекламы — Door-To-Door Sales Workers, News and Street Vendors (–37%)
Графический дизайнер (без навыков работы с ИИ) — Graphic Designers (–35%)
Страховой эксперт / специалист по урегулированию убытков — Claims Adjusters, Examiners, and Investigators (–33%)
Секретарь в юридической фирме / нотариальной конторе — Legal Secretaries (–32%)
Судебный клерк / делопроизводитель в госорганах — Legal Officials (–30%)
Кредитный специалист в банке / МФО — Credit and Loans Officers (–28%)
Администратор ресепшена / консьерж в отеле / БЦ — Concierges and Hotel Desk Clerks (–27%)
Офисный специалист по отчётности в финансах / страховании — Statistical, Finance and Insurance Clerks (–26%)
Руководитель административно-хозяйственного подразделения — Business Services and Administration Managers (–24%)
Помощник юриста / параюрист — Paralegals and Legal Assistants (–22%)
Уборщик / клинер / помощник по хозяйству — Building Caretakers, Cleaners and Housekeepers (–21%)
Андеррайтер / специалист по страховой экспертизе и оценке рисков — Insurance Underwriters, Valuers, and Loss Assessors (–20%)
Рост и падение профессий. Диаграмма показывает, какие профессии будут расти (слева) и сокращаться (справа) по прогнозу Всемирного экономического форума. Синим отмечены новые рабочие места. Фиолетовым — утраченные. Ромб в центре — чистый (рост или падение)
📊 Дополнительные данные из отчёта, которые нельзя игнорировать:
Как изменится структура задач на работе:
Сейчас: 54% задач выполняет человек
К 2030 году: только 30%
42% задач перейдут под контроль технологий
Остальные будут решаться в связке “человек + ИИ”
85% компаний будут инвестировать в обучение сотрудников, а 73% — ускорять автоматизацию.
Работа не исчезнет — но изменится до неузнаваемости. ИИ уже вытесняет людей из профессий: где-то на 10–20%, а в ряде сфер — до 50%. И это только к 2030 году.
А что будет к 2035-му?
Вероятно, — ещё сильнее: — конкуренция между людьми и алгоритмами, — между «ручными» специалистами и теми, кто автоматизирует задачи с помощью ИИ, — между теми, кто уже осваивает нейросети, и теми, кто «всё ещё думает, с чего начать».
По данным WEF и OpenAI, 80% профессий изменятся, а 19% задач будут полностью автоматизированы. Это значит: выживают не специальности, а навыки. Технологическая грамотность, гибкость, критическое мышление и умение эффективно работать с ИИ.
Но давай честно, что мешает большинству людей начать изучать нейросети прямо сейчас:
😰 Страшно не справиться. Кажется, это только для гениев. Или тех, кто «с детства в IT». Но это не так.
❓ Непонятно, с чего начать. Инструментов десятки, YouTube ломится, но головы всё равно не хватает. Нет карты. Нет внятной опоры.
⏳ Нет времени. «Я бы изучал, но у меня семья/работа/всё горит». Вечером нет сил. Утром — снова дела. В итоге — день сурка и страх отставания.
🤐 Страшно ошибиться. «Вдруг спрошу глупость?» или «Все уже что-то умеют, а я туплю…»
🥶 Один против всех. Когда рядом никто не разбирается в нейросетях — ещё сложнее. Не у кого спросить, некому «подсветить», как проще.
⚡️ И главное — всё слишком быстро. Ты только пригляделся к одному инструменту — уже вышло три новых. Пока ты прокрастинируешь — другие растут.
Именно поэтому я запустил AI-комьюнити — место, где: — можно задать любой вопрос и не бояться быть непонятым, — вместе разбираться в инструментах, делиться фишками, — учиться, вдохновляться и внедрять нейросети в свою реальную работу, — поддерживать друг друга, не чувствуя себя «в одиночке».
Уже сейчас в чате говорят про ChatGPT-4o, Midjourney, Runway, Kling, Suno, Sora, Pika, GPTs и другие топовые инструменты.
❗Не жди, пока тебя вытеснит тот, кто научился использовать ИИ. Присоединяйся — начни прокачку уже сегодня: 👉 https://t.me/+Rbs1ccfTk2BiNjli
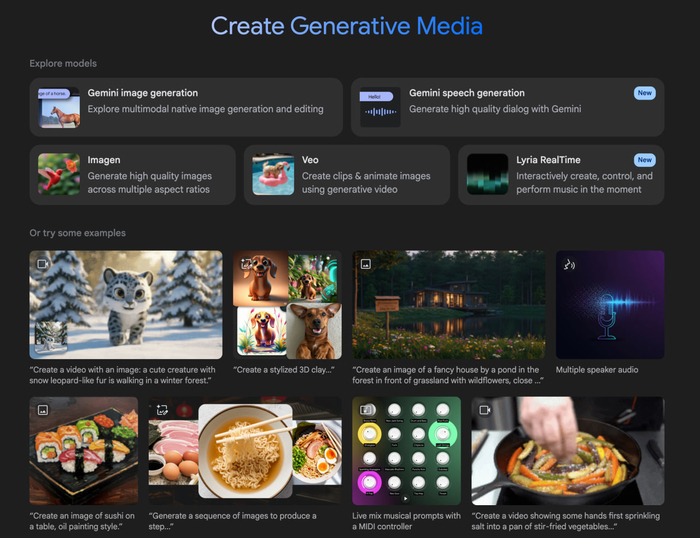
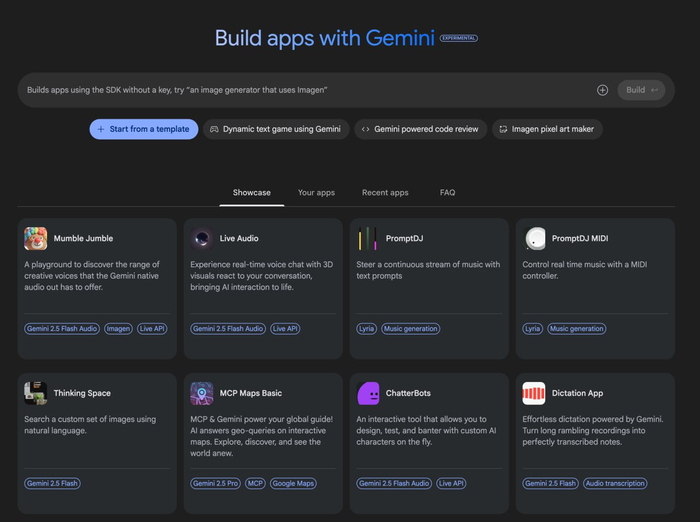
Это мое мнение, я решаю на этом сайте практически все задачи уже около полугода и за это время он существенно улучшился. Пришло время обновить свой обзор на него.
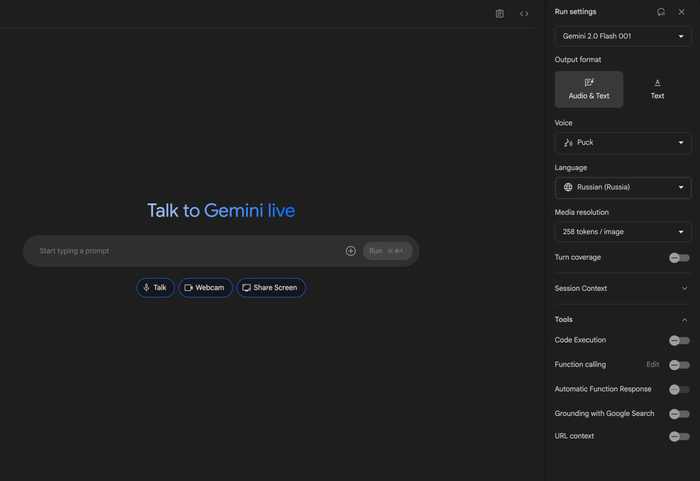
— Безлимитный доступ к Gemini 2.5 Pro. Одна из лучших LLM для создания проектов, написания текстов и кода
— Редактирование картинок на основе Gemini 2.0 Flash Preview Image Generation. Работает по следующему принципу — загрузка картинки и описание того, что на ней изменить = получение результата
— Imagen 3 - генератор реалистичных картинок. Выдает сразу 4 картинки, имеются разные соотношения сторон на выбор
— Создание монолога и диалога. Завезли специальную модель, чтобы делать озвучку текста. Качество достойное. Можно выбрать монолог и диалог. Есть несколько голосов на выбор, можно добавлять эмоции и описывать то, каким хотелось бы увидеть аудио
— Музыка в прямом эфире. Нужно выбрать жанры, настроить их баланс (с помощью крутилок), после чего запустить музыку в прямом эфире. И это работает, причем достаточно интересно!
— Приложения, прямо внутри Ai Studio можно сделать свое приложение и там же его запустить. Есть большая библиотека готовых вариантов, чтобы вдохновиться. Собственную разработку можно сохранить и использовать на постоянной основе внутри сайта
— Gemini Live, которая позволяет общаться с нейросетью в прямом эфире голосом, показывать ей вебкамеру и демонстрацию экрана. Надоело общаться с людьми? Есть такой вариант, это гораздо интереснее в контексте объема получаемой информации. Доступна на русском языке!
Рад, что Google реально смогли сделать крутой сервис, так еще и бесплатно. На этом фоне убогий, платный GPT смотрится совсем плохо.
Конкуренция делает свое дело, поэтому можно ждать в ближайшее время обновлений и от OpenAI
📌 Лучший ИИ-сервис от Google ТУТ aistudio google com
📌 Я буду ОЧЕНЬ благодарен, если вы оцените пост и посмотрите мой канал в ТГ (ссылка в профиле пикабу). Всем позитива и хорошего настроения, будьте добрее друг к другу!
— Загрузка файлов из Google Диска (документы, таблицы, презентации)
— Поиск информации по загруженным источникам (с помощью промтов)
— Создание подкастов, аудиопересказ материала (диалог 2-х спикеров)
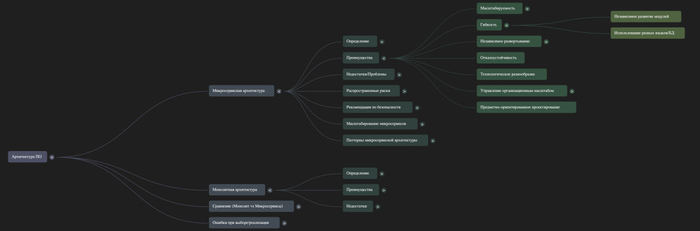
— Создание MindMap (визуализация структурированных данных из источников)
— Запросы и промты к добавленным источникам, получение информации на их основе
Особенности
— Работает на Gemini 1.5 Pro, обеспечивающий анализ длинных текстов (до 1 млн токенов)
— Исходные материалы могут быть на разных языках, язык ответа настраивается: "Настройки" -> "Язык результатов" -> "Выбрать язык"
— Работает с VPN, в идеале использовать - США
— Можно создать 100 блокнотов на бесплатной версии, внутри каждого до 50-ти источников.
Сделал MindMap на тему "Архитектура ПО: Монолит и микросервис"
📌 Работаем с данными и источниками здесь - notebooklm google
📌 Я буду ОЧЕНЬ благодарен, если вы оцените пост и посмотрите мой канал в ТГ (ссылка в профиле пикабу). Всем позитива и хорошего настроения, будьте добрее друг к другу!