


Двемерская надпись (Dwemer inscription)

Кое-кому, похоже, так и не удалось ее разобрать. Даже словарь не помог.
Кое-кому, похоже, так и не удалось ее разобрать. Даже словарь не помог.
На первый взгляд, вопрос из заголовка звучит абсурдно, ведь обе буквы выглядят совершенно идентично. Однако транслит в адресной строке подсказывает: первая Х – кириллическая, а вторая X – латинская.

Мы знаем, что как кириллический, так и латинский алфавиты являются потомками греческого. Соответственно, наша буква Х (ха) и латинская X (икс) – это греческая Χ (хи) в практически неизменном начертании. Но если мы произносим эту букву так же, как греки – /х/, то откуда взялось латинское прочтение /кс/?
Чтобы понять это, следует начать с того, что греки позаимствовали свою письменность у финикийцев. В случае, когда финикийский и греческий звуки были идентичны, греки сохранили функцию буквы неизменной:
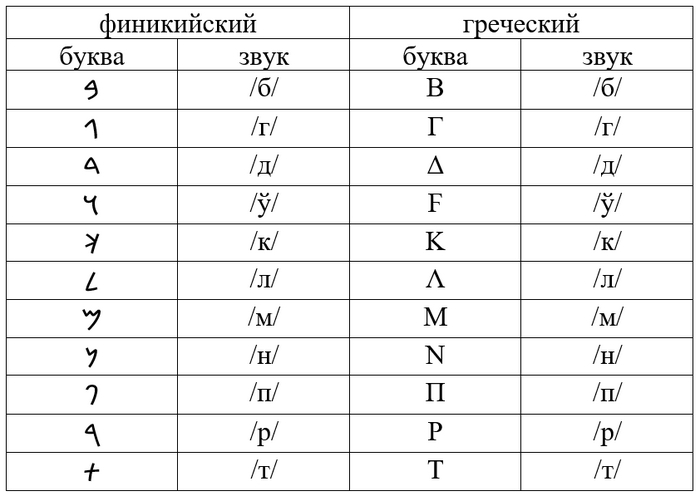
В финикийском алфавите были буквы только для согласных, так же, как и в родственных еврейской и арабской письменностях. Благодаря особой структуре семитских языков, читающий всё равно мог понять, о чём идёт речь. Для греческого языка такой принцип подходил плохо, слишком велика в нём была роль гласных. Зато в финикийском языке было куда больше согласных, чем в греческом, то есть, имелись «лишние» буквы, которым греки нашли применение.
В принципе, первый шаг сделали уже сами финикийцы: буквы йод и вав стали со временем использоваться для записи не только согласных /й/ и /ў/, но и долгих гласных /ии/ и /уу/. Греки взяли ещё четыре буквы, обозначавших согласные, которых не было в греческом и начали записывать ими гласные:

Комментарий к таблице: /’/ (В Международном фонетическом алфавите – ʔ) – это звук, который можно услышать между гласными в русском не-а; h – как в английском hat; /х/ и /‘/ в финикийском были глухим и звонким фарингальными (МФА /ħ/ и /ʕ/), то есть, произносились в гортани.
Ещё одну букву, Ω /оо/, греки создали на основе Ο. По какой-то причине придумывать отдельные буквы для долгих /аа/, /уу/ и /ии/ они не стали.
Кроме того, в финикийском были аффрикаты /ц/ и /дз/, которые отсутствовали в греческом. Греки могли буквы для этих звуков смело выкинуть или использовать для обозначения каких-то других звуков, но, по-видимому, /ц/ и /дз/ они воспринимали не как слитные звуки, а как сочетание двух, и идея записывать сочетание «согласный + с» им понравилась, так что они сохранили финикийские буквы и нашли применение для них, обозначая одной буквой сочетания /зд/ и /кс/, которые аффрикатами не являются. Более того, придумали новую букву для /пс/, но об этом ниже.
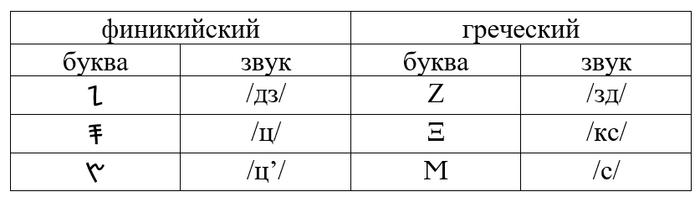
Комментарий к таблице: знак ’ здесь и ниже обозначает фарингализацию.
Некоторые другие финикийские буквы тоже получили в греческом новую функцию:

Как я рассказывал раньше, в греческом было три придыхательных согласных: /пˣ/, /тˣ/, /кˣ/. И только один из них, /тˣ/, сразу получил свою финикийскую букву. Для /пˣ/ греки придумали букву Φ, вероятно на основе лишней коппы (Ϙ), которая в греческом быстро вышла из употребления (но зато дала латинскую Q).
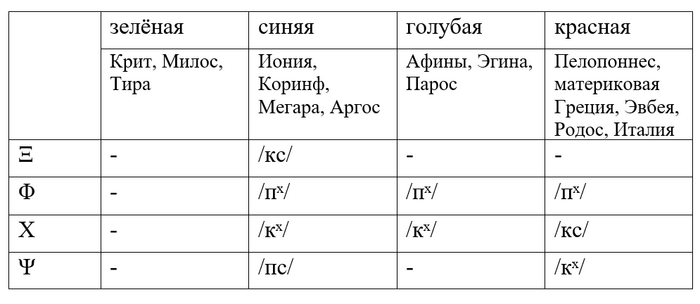
Сложнее была история /кˣ/. Греки придумали две новых буквы, Χ и Ψ, но использовали их по-разному в зависимости от региона. На западе Χ читалась как /кс/, а Ψ – /кˣ/. На востоке иначе: Χ – /кˣ/, а Ψ – /пс/.
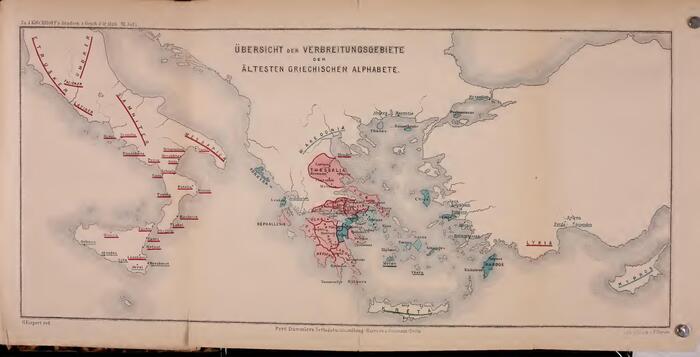
Ещё в XIX веке немецкий учёный А. Кирхгоф выделил четыре группы вариантов древнегреческой письменности:
На карте:
«Синий» вариант используется в современном греческом с поправкой на то, что /пˣ/ и /кˣ/ стали со временем произноситься как /ф/ и /х/. Когда славяне заимствовали греческий алфавит, буква Χ читалась уже как /х/, поэтому наша Х произносится именно так. А вот римляне заимствовали свой алфавит из греческого в «красном» варианте. По этой причине латинская буква X читалась как /кс/, но, как я уже писал раньше, благодаря забавному выверту исторической фонетики, в современном испанском это /х/, как в русском.
Литература:
Kirchhoff A. Studien zur Geschichte des griechischen Alphabets. Berlin, 1877.
Matthaiou A.P. Local Scripts // Encyclopedia of Ancient Greek Language and Linguistics. Vol. 2. Leiden, Boston, 2014. Pp. 379–385.
Swift N. The Origin of the Greek Alphabet // Encyclopedia of Ancient Greek Language and Linguistics. Vol. 1. Leiden, Boston, 2014. Pp. 94–100.
Что такое клинопись? Когда и где она появилась, и кем использовалась? Какие материалы использовались для её написания? К какому периоду относятся самые древние клинописи, найденные археологами?
Ольга Попова, лингвист, кандидат филологических наук, научный сотрудник Института языкознания РАН рассказывает об истории клинописи, о том, какую информацию записывали этим письмом, как преобразовывалась шумерская клинопись на протяжении времён и почему этот вид письменности был вытеснен арамейскими и греческими видами письма.
ВКонтакте: https://vk.com/video-190320587_456240116
Для всех поклонников футбола Hisense подготовил крутой конкурс в соцсетях. Попытайте удачу, чтобы получить классный мерч и технику от глобального партнера чемпионата.
А если не любите полагаться на случай и сразу отправляетесь за техникой Hisense, не прячьте далеко чек. Загрузите на сайт и получите подписку на Wink на 3 месяца в подарок.

Реклама ООО «Горенье БТ», ИНН: 7704722037
Откуда произошли буквы?
Да, все знают, что кириллица была создана на основе греческого, а латиница, со всей очевидностью, происходит от латинского. Эти алфавиты, в общем-то похожи, и действительно являются родственниками.
Но откуда взялись они?
Дело в том, что когда-то очень давно, примерно на территории современного Ливана жили финикийцы.
Именно они основали города Кадис и Малагу в Испании, Палермо в Италии, Триполи в Ливии, Карфаген в Тунисе.
Финикийцы изобрели простую письменность, где знак соответствовал не слову, а звуку, что, по сравнению, с иероглифическим письмом, сокращало количество знаков в несколько тысяч раз.
Кстати, неподалеку от финикийцев жили египтяне с кучей симпатичных иероглифов, и некоторые древнеегипетские иероглифы были частично взяты за основу в финикийском алфавите (а значит в каком-то виде дошли и до нашего).
Таким образом, первым фонетическим письмом считается именно финикийский алфавит (15в до н.э.), и эту идею подхватили во всём мире, ни больше, ни меньше (кроме, разве что, Кореи, Китая и Японии).
Успех финикийского алфавита был обусловлен простотой запоминания и написания, а также универсальностью (с небольшими изменениями его оказалось легко приспособить практически к любому языку).
Сравните, что вас пугает меньше, выучить несколько тысяч иероглифов, сотню слоговых знаков или пару десятков букв?
В одну сторону, на запад, пошли греческий и латынь, а на восток - арамейское письмо, произошедшее от финикийского, и давшее начало алфавитам Монголии, Таиланда, Индии, Израиля и арабских стран. Да, сложно поверить, но все эти на первый взгляд непохожие знаки, как и наш алфавит, происходят от финикийских букв.
Переходим к практике.
А - греч. А "альфа" - финик. "алеф" ("бык"). У финикийцев эта буква означала гортанную смычку (как та, что мы все говорим в слове "не-а"). Форма буквы восходит к египетскому иероглифу, обозначающему быка. Если перевернуть букву А, она становится похожа на быка анфас.
В - греч. Β "бета" - финик. "бет" ("дом"). Эта буква тоже происходит от египетского иероглифа с значением "дом". Древнегреческое чтение "б" было унаследовано западной цивилизацией, а вот славянский алфавит создавался во времена Византии, когда эта греческая буква из "беты" стала "витой". Поэтому мы унаследовали чтение "в", а для создания "б" немного модифицировали эту же самую букву. Так что "Б" и "В" у нас родственники.
По этой же причине разной хронологии на западе говорят "alphabet", а у нас "алфавит", через "в". Кстати, с финикийского, оказывается, это слово переводится как "быкодом".
Г - греч. Г "гамма" - финик. "гамл" ("верблюд"). А вот в латинице это стало буквами "C" и "G". Как? Дело в том, что прежде, чем попасть к римлянам, греческий алфавит был немного потрёпан этрусками. Там, где звуки не отличались, ничего страшного не произошло. Но вот звук "г" этрускам оказался не нужен, поэтому они стали так обозначать "к" - это раз. И они стали изображать этот знак более сглаженно ("С") - это два. Это дело досталось римлянам (то есть буква "С" со звуком "К"). Но звук "Г" им тоже оказался нужен. Взять оригинал уже было неоткуда, поэтому они добавили к этой букве хвостик, и получили "G". Такие дела.
П.С. Узнали английского верблюда - "camel"? Он притопал оттуда же.
Д - греч. Δ "дельта" - финик. "далет" ("дверь"). Тут каждый вертел как хотел, и у нас получилось "Д", а в латинице "D".
Е - греч. Е "эпсилон" - финик. "хе" ("молитва", "выдох"). У нас тут тоже сделали "кручу-верчу", и получились и "Е", и "Э". А потом ещё и "Ё".
З - греч. Ζ "зета" - финик. "зайн" ("оружие, меч") - наша буква стала просто более сглаженным вариантом оригинала. А в латинице её поставили в конце алфавита, потому что сначала её не взяли (из-за отсутствия звука), а потом оказалось, что греческие слова с этим звуком тоже надо как-то записывать. Пришлось букву вернуть, но чтобы не нарушать строй (на место "Z" уже поставили "G", как мы помним), засунули её в самый конец.
i - греч. Ι "йота" - финик. "йод" ("рука"). В латинице к XVI веку из этой буквы получается ещё и "J", а у нас, хоть она и была упразднена после революции, как элемент сохранилась в буквах "Ы" и "Ю".
К - греч. Κ "каппа" - финик. "каф" ("ладонь"). Как мы помним, римляне уже запутались из-за этрусков с буквой "Г", сделав из неё "С" (которая читалась как "К"), поэтому "К" им уже была не нужна. Но позже всё равно пришлось её усвоить, опять же, для написания греческих слов. В современных романских языках эта буква так и осталась не в чести, её по-прежнему используют только для иностранных имён и названий.
Л - греч. Λ "лямда" - финик. "ламед" ("посох"). Эту букву тоже повертели, и получились разные варианты, от "Л" до "L".
М - греч. Μ "мю" - финик. "мем" ("вода"). Ещё одна буква, которая точно произошла от египетского иероглифа. И сегодня она напоминает волны.
Н - греч. Ν "ню" - финик. "нун" ("угорь", "змея"). На самом деле в кириллице тоже сначала писалось "N". А потом палочка немного съехала.
О - греч. Ο "омикрон" - финик. "айн" ("глаз"). Это, наверное, самая точно сохранившаяся буква.
С - греч. Σ "сигма" - финик. "шин" ("зуб"). Сначала эта буква попала в латиницу, потеряла угловатость и стала выглядеть как "S". А в славянский алфавит попал её "лунообразный вариант" - "ς". Возможно, это связано с тем, что у нас были некоторые дополнительные звуки, которые надо было тоже как-то обозначать, и основной (но развёрнутый) вариант сигмы пошёл на них - это "Ш" и "Щ".
Т - греч. Τ "тау" - финик. "тав" ("крест"). Тоже сохранилась у всех.
У - греч. Υ "ипсилон" - финик. "уау" ("колышек"). На самом деле этот звук был не совсем как "у", а скорее как английское "w". Не всем он был нужен, и некоторые вот сделали из этой буквы немного другую, "F", для звука "ф". У этрусков ипсилон потерял хвостик и превратился в "V", в этом виде его забрали римляне (позже опять-таки забрали у греков и "Y" для заимствованных слов, обозвали "греческой и" - "и грек"). А когда снова понадобился звук "w", то сдвоили "v", и сделали ещё одну специальную букву.
И - греч. Н "эта" - финик. "хет" ("забор"). Помните, у "N" палочка спустилась, и стала "Н"? Вот у "Н" она тогда же спустилась, и стала "И".
П - греч. Π "пи" - финик. "пей" ("рот"). Тут так вышло, что наша буква произошла от строчной, а латинская - от старого курсива, больше похожего на финикийский вариант. Правая ножка у греческой "пи" была короче левой, и постепенно начала загибаться, превратившись в итоге в "Р".
Р - греч. Ρ "ро" - финик. "рош" ("голова"). Опять в кириллицу всё попало как в греческом, а в латыни пришлось добавлять диагональную черту, чтобы не путать с "Р". Получилось "R".
Ф - греч. Φ "фи" - финик. "коф" ("игольное ушко"). Так вышло, что у нас сохранилось вот такое написание, и звук "ф", а в латинице черточка уменьшилась и съехала, и получилась буква "Q", сохранившая звук "к". У них, при этом, уже были "С" и "К" для этого звука, а всё было мало.
Ц, Ч - греч. \нет\ - финик. "сьяде" ("удочка"). Для таких редких славянских звуков пришлось доставать из погреба финикийскую букву, которая исчезла уже в греческом. Зато её потомки существуют в арабском и в иврите.


Четыре года назад я совершил один из самых безрассудных поступков в своей жизни: начал учить японский язык. Разумеется, прежде чем решиться на такое приключение, я тщательно все продумал и провел подробное исследование на тему. Т.е. погуглил, что другие люди думают об этом экзотическом языке. Отзывы меня весьма приободрили. В них говорилось, что нужны годы и годы тяжелого учения. Люди писали, что, если тебе кажется, что язык очень тяжелый, то ты все еще недооцениваешь опасность раз в десять. Интернет пестрит предупреждениями, что тебе это не нужно; что это тяжело; что "не лезь оно тебя сожрет".
Но меня было не остановить. У меня был положительной опыт изучения английского, немецкого и испанского. Я был окрылен уверенностью и не думал, что японский так ужасен, как его малюют. Так вот. Я был не прав. Японский - страшно тяжелый язык, требующий в разы больше времени, чем любой романский или германский язык. Собственно, об этом и хочу вам сегодня рассказать: что именно в японском представляет наибольшую сложность.
В этой статье начну с самого очевидного препятствия на пути изучающего: письменности.
Краткий экскурс в виды японской письменности
Японская письменность состоит из трех основных частей: 2 слоговые азбуки (хирагана и катакана) и иероглифы (кандзи).
Со слоговыми азбуками все достаточно просто. Каждая из них состоит из 46 знаков, и они обе позволяют передавать одни и те же звуки. В первой табличке катакана, во второй - хирагана:


Кандзи, в свою очередь, - это тысячи и тысячи иероглифов, которые попадаются в текстах с разной частотой. Вот, например, список из 80 базовых кандзи, которые японские школьники изучают в первом классе:

Эти три вида вида письменности используются вместе. Например, вот типичное предложение из вики: マーモット類は日本ではなじみの薄い動物である. В начале предложения идет катакана (простые угловатые символы) для того, чтобы написать слово "сурок" (マーモット, ma-motto), которое в японский позаимствовано из английского. Затем идет лапша из кандзи (сложные символы) и хираганы (простые округлые символы), чтобы сказать, что для Японии сурки не характерны.
Как катакана, хирагана и кандзи уживаются вместе? На самом деле, достаточно хаотично. Катакана обычно используется для написания слов, заимствованных из европейских языков. Например: ヘリコプター (herikoputa-, вертолет). Хирагана преимущественно применяется для написания служебных слов (предлоги и т.д.). Например: に (ni) - это "в", から (kara) - это "из". Плюс с помощью хираганы происходит словообразование, изменение глаголов по временам и т.д. Например, в слове 高くなかった часть "くなかった" обозначает, что в прошлом свойство "高" (высокий или дорогой) отсутствовало. И, наконец, кандзи используются как корни слов.
Но из этих правил столько исключений, что называть это правилами даже как-то неловко. Некоторые глаголы почти всегда пишутся хираганой. Например: もらう (morau, получать). Но для многих из них существует и вариант с кандзи. Для того же もらう есть аналог, который выглядит так: 貰う (тоже morau, получать). Огромное количество слов, которые традиционно записывают именно хираганой, имеют вариант с использованием кандзи. Например, обычно слово "почти" пишется как ほとんど, но периодически встречается и 殆ど, которое читается и обозначает абсолютно то же самое.
Похожая история и с катаканой. Имена животных часто записывают просто катаканой: カマキリ (kamakiri, богомол), カラス (karasu, ворона). Но для многих этих животных есть и вариант с кандзи, который тоже весьма распространен: 蟷螂 (kamakiri, богомол), 烏 (karasu, ворона).
Наконец, использование кандзи, катаканы, хираганы может быть художественным приемом. Если автор хочет изобразить странный (магический, неземной, очень громкий и т.д.) голос, то он может написать предложение целиком катаканой. Речь ребенка может быть записана полностью хираганой, т.к. дети знают мало кандзи. И, наоборот, если хочется нагнать напыщенности или подчеркнуть заумность говорящего, предложение может использовать избыточное количество кандзи, в том числе очень редких и в местах, где хирагана/катакана подошли бы лучше.
У того, кто всю эту японскую красоту видит в первый раз, может возникнуть резонный вопрос: а можно ли забить на всю эту сложность и просто писать все катаканой или хираганой? Нет, нельзя. В японском языке не ставятся пробелы между словами. Максимум из доступного: это точка и запятая. Все остальное сплошняком. Поэтому без кандзи будет проблематично (но не невозможно) разобрать написанное. При всем при этом, если не могут вспомнить подходящий кандзи, то пишут хираганой. Дети, которые знают мало кандзи, тоже пишут тексты хираганой.
Изучение хираганы и катаканы займут у вас пару вечеров. После этого вы сможете без проблем искать в словарях слова, написанные катаканой. С хираганой чуть сложней. Японский - это агглютинативный язык. К концу слов может приклеиваться большое количество разных суффиксов и поначалу (т.е. первые пару лет обучения), когда подряд идет много хираганы, сложно понять, где кончаются суффиксы для слова, что из этого предлог, где начинается следующее слово. В поисках примера я открыл первую попавшуюся под руки книгу и в первом же абзаце была эта красота: できることはあるのだろうか (できる + こと + は + ある + の + だろう + か). Парой предложений далее написано следующее: 実に退屈きわまりないものだということだった (実 + に + 退屈 + きわまり + ない + もの + だ + という + こと + だった). Конкретно эти примеры не требуют знания продвинутой грамматики, но иллюстрируют проблему, с которой сталкивается учащийся при попытке начать потреблять японскую литературу. В первые несколько лет сложно читать японские тексты. Если вы не знаете испанский, то вы все равно можете прямо сейчас открыть испанскую книгу и, пользуясь онлайн словарем, будете потихоньку продвигаться. С японским такое едва ли прокатит. Чтобы пробраться через потоки хираганы, вам будет необходимо целенаправленно изучать грамматику. Ну или смириться с тем, что от вас будет ускользать довольно большой пласт смысла написанного.
Слоговые азбуки - это самое простое, что есть в японской письменности, поэтому к ним больше возвращаться в статье не будем. То, что было выше, это вообще цветочки. Мясо начинается только сейчас. Итак, что же такое сложного в кандзи?
Их очень, очень много
Начнем с очевидного. Иероглифы вселяют ужас уже одним своим количеством и буквально устраивают зерг-раш при первых робких попытках молодого падавана прикоснуться к азиатской культуре.
Я не могу точно сказать, сколько вам понадобится кандзи для чтения книги и газет, но могу вместе с вами прикинуть. Но сначала немного о видах кандзи.
Кандзи делятся на три группы: jouyoukanji (常用漢字, обычно используемые кандзи), jinmeiyoukanji (人名用漢字, кандзи для использования в личных именах) и hyougaiji (表外字, знаки вне списка).
Jouyoukanji (обычно используемые кандзи) - это те кандзи, которыми министерство образования Японии "рекомендует" ограничиваться в повседневном употреблении. Их 2136. Они изучаются в начальной и средней японских школах (12 классов в сумме) и это тот минимум, которым вам необходимо овладеть как можно скорее.
Jinmeiyoukanji (кандзи для использования в личных именах) - это другая большая группа иероглифов. Она состоит из 863 кандзи. Только эти иероглифы и иероглифы из jouyoukanji можно использовать для имен и фамилий. Часть этих кандзи, как подсказывает имя группы, вы увидите исключительно в именах. Например, кандзи 櫻 в женском имени 櫻子 (sakurako). Однако, сотни иероглифов, которые именуются "кандзи для использования в личных именах", вполне себе используются в повседневной жизни совсем не для имен. Например: 厨 в 厨房 (chuubou, кухня). В целом, я не считаю рациональным пытаться специально заучивать иероглифы из этой группы, пока они вам не встретятся в статьях/газетах/книгах. У jinmeiyoukanji бывает множество возможных произношений, и сами японцы очень часто не знают, как прочитать ту или иную фамилию. Комедийный троп с неправильным/комичным произношением фамилии регулярно используется в японской поп-культуре. Визитные карточки японцев часто содержат расшифровку имени. Ученики, попадая в новый класс, записывают свое имя на доске и объясняют, как его произнести.
И, наконец, третья группа: hyougaiji (знаки вне списка). Это все остальные кандзи. Тысячи их. На английском их называют uncommon kanji. Но пусть вас не вводит это название в заблуждение. Некоторые из этих "uncommon kanji" встречаются на порядки чаще, чем иные common kanji. Например: такие "uncommon" кандзи, как 蟻 (ari, муравей), 罠 (wana, ловушка), оба кандзи в сочетании 彷彿 (houfutsu, иметь сходство), - встречаются гораздо чаще чем "common" кандзи 旗 (hata, флаг) или 桑 (kuwa, тутовое дерево).
По моим прикидкам, чтобы потреблять не очень сложную литературу, необходимо знать все обычные кандзи (2136), штук 300 кандзи для имен и около 500 "нестандартных" кандзи. Итого, 3000 иероглифов. С этим багажом вы будете узнавать почти все встречаемые символы в художественной литературе, но словарь все равно убирать далеко не надо. Со знанием всего лишь 3000 кандзи незнакомые иероглифы вам будут попадаться приблизительно каждые страниц 10. И это я, конечно, говорю про идеальный мир, где вы безупречно помните все, что выучили. На практике, разумеется, редко используемые кандзи и, к сожалению, даже довольно популярные кандзи, все равно вылетают из головы.
Кандзи много, действительно много. Но если вы думаете, что понимание японских текстов сводится только к заучиванию трех тысяч символов, то троекратное ха! Самое интересное еще впереди.
У каждого кандзи множество произношений
Нельзя просто взять и выучить 3000 кандзи, даже если у вас очень хорошая память и вам доставляет удовольствие заучивание списков без контекста. У каждого иероглифа может быть несколько произношений. Какое произношение выбрать зависит от того, какое слово он образует. Например, возьмем кандзи 厳. Это достаточно популярный иероглиф, который используется для образования десятков слов. В слове 厳しい он произносится как kibi, в 厳めしい - как ika, в 厳か - как ogoso, в 厳重 как gen, а в слове 荘厳 - как gon. Все эти слова часто употребляемые, и вы их легко встретите в тексте.
В теории у абсолютного большинства кандзи есть два основных вида произношения: 訓読み (kun'yomi), родное японское произношение, и 音読み (on'yomi), заимствованное из китайского (часто с искажениями). В учебниках обычно указывают, что японское произношение преимущественно используется, когда кандзи стоит в гордом одиночестве, а китайское произношение - когда кандзи соединяется с другим кандзи, чтобы образовать слово (熟語, kanji compound).
На практике, однако, все намного сложнее, поскольку обучение все равно сводится к тому, что мы заучиваем, как и в каком контексте звучит тот или иной иероглиф. Например, знание того, что у кандзи 厳 есть kun чтения kibi, ika, ogoso и on чтения gen и gon вам слабо поможет, поскольку этого недостаточно, чтобы понять, как читать новое слово, которое вы встретили. Все равно надо лезть в словарь. Даже если кандзи стоит в одном и том же положении (например, в начале или конце слова), то оно все равно может читаться по-разному. К примеру, кандзи 木 (дерево) читается как "moku" в 木片 и как "ki" в 木戸. Или, вот еще кандзи 性. Слово 性質 читается, как "seibetsu", а 性分, как "shoubun". Таких примеров можно привести тысячи.
Директива "японское чтение для односложных слов, китайское - для составных" имеет невероятное количество исключений. Чуть выше мы видели, как кандзи 木 использует японское чтение при образовании сочетания 木片. Кандзи 本, напротив, почти всегда читается как hon, используя произношение, пришедшее из китайского языка, даже когда этот иероглиф стоит совершенно отдельно. Или вот интересное слово: 道順 (michijun, маршрут). Первый кандзи использует kun произношение, а второй - on произношение.
В общем, для меня, как любителя, остается абсолютной загадкой, зачем в японских школах и во многих учебниках заставляют заучивать, какие чтения kun, а какие - on. В итоге все сводится к тому, что необходимо запоминать звучание для каждого конкретного случая. Может быть, я что-то упускаю из виду, и вы сможете просветить меня в комментариях!
Как вы, наверное, уже заметили, количество кандзи и количество произносимых слогов могут сильно не совпадать. Некоторые кандзи имеют варианты произношения из одного слога, как, например, 語 (go, язык). Есть кандзи с произношением из двух (雲, kumo, облако), трех (光, hikari, свет), четырех (古, inishie, древность) или пяти (承る, uketamawaru, получать) слогов.
Таким образом, 3 тысячи иероглифов, о которых мы говорили в предыдущем разделе, превращаются в десятки тысяч вариантов произношения. Но и это еще не все, поскольку
Каждый кандзи может образовывать огромное количество разных слов
Из предыдущей части вы, вероятно, уже поняли, что кандзи не равно слово. Слово может состоять из одного (猫, neko, кот), двух (先生, sensei, учитель), трех (拾得物, shuutokubutsu, находка), четырех (下位互換, kaigokan, обратная совместимость) или более кандзи. Некоторые иероглифы могут образовывать только одно, два слова. Например, кандзи 隕 всегда (или почти всегда) используется только в слове 隕石 (метеорит). Другие кандзи способны образовывать десятки и сотни слов. Например, можете посмотреть в вики на сотни слов, образованных с помощью 性.
Некоторые слова интересны тем, что в них можно поменять местами кандзи и получится новое слово. Например, 運命 (unmei) и 命運 (meiun) оба переводятся как "судьба". При этом произношение обоих иероглифов не меняется, когда они меняются местами. 運 продолжает звучать как un, 命 - как mei. В следующей паре, 腹切 (harakiri) и 切腹 (seppuku), значение опять же не меняется, но произношение различается кардинально: в одном слове используется on произношение, а в другом - kun. Или вот: 置物 (okimono) и 物置 (monooki). Как видите, в этом случае произношение для иероглифов не меняется в отличие от предыдущего примера, но кардинально меняется смысл. Первое слово - это "орнамент". Второе - "кладовка".
Мозг отчаянно пытается искать логику и паттерны, но японская письменность лишь смеется над такими вульгарными и приземленными материями и продолжает радовать своей непредсказуемостью. Ибо что нам консистентность и предсказуемость? Язык - он трансцендентен, он жив и он об искусстве, чувствах и традициях, а не об этом вашем логическом мышлении. Фи.
Многие кандзи и слова очень похожи друг на друга
Это не совсем честный пункт, поскольку он, в отличие от всего остального в статье, может быть применен к абсолютно любому другому языку, но я все равно решил его включить.
Не удивительно, что среди часто употребляемых тысяч кандзи найдется множество весьма похожих. Как вам, например, 懇, 墾, 墜, 堕? Они даже формируют похожие на вид слова: 堕落 (daraku, деградация), 墜落 (tsuiraku, авиакатастрофа). Или 概 и 慨 (которые, кстати, оба часто одинаково произносятся, как gai). Да тысячи их, на самом деле: 超 и 越 (каждый из которых образует глагол с произношением koeru), 因 и 困, 他 и 池, 噴 и 憤 с 寛, 紛 и 粉, 既 и 厩, 喧伝 и 宣伝, и т.д. и т.п.
К тому же, в предыдущем разделе мы уже обсуждали, что в некоторых словах можно менять местами кандзи и получаются совершенно новые слова с совершенно другим значением: 客観 (объективный) и 観客 (зритель), 現実 (реальность) и 実現 (осуществление).
Выше мы уже разобрали, что у одних и тех же кандзи может быть разное произношение, но могут ли, наоборот, использоваться разные кандзи, чтобы написать одно и то же? Я рад, что вы спросили! Это подводит нас к следующему пункту!
Одни и те же слова, записанные разными кандзи
Вместо привычного 万 (man, десять тысяч) вам может встретиться 萬 (такое же произношение и значение). 厩 и 馬屋 - это одно и то же. Означает "конюшня" и произносится как umaya. 涸びる и 乾びる, 取り得 и 取柄, продолжать можно долго. И это, не говоря о том, что, как мы обсуждали ранее, часть слов вместо кандзи иногда пишется хираганой. まっとう, 真っ当 и 全う - это все одно и то же слово, которое означает "порядочный".
Окей. Классно. Много вариантов написания одного и того же. Очень удобно. Как насчет того, чтобы одни и те же слова имели несколько разных вариантов произношения?
Одни и те же слова можно читать по-разному
Вы, наверное, уже не удивитесь, но такого в японском тоже навалом. Вот вам 身代 (имущество), который читается как shindai. А вот вам 身代金 (выкуп). В конце добавили kin (золото, деньги). Будет ли новое слово читаться как shindaikin? Конечно нет, глупый гайдзин! Новое слово читается как minoshirokin. Чтобы подсказать об этом читателю часто (но далеко не всегда) используется альтернативное написание 身の代金.
Или вот вам 音声 (голос). Это слово можно прочитать, как onsei, а можно, как onjou. Как хотите, так и читайте. На смысл не повлияет.
У нашего следующего гостя тоже два произношения, но они несут разный смысл. Если вы прочитаете 細々 как hosoboso, то это означает "очень бедный", а если как komagoma, то это означает "крошечный". Здорово, правда?
Итак. Тысячи кандзи, у каждого множество значений и произношений, каждое образует множество разных слов. Количество произносимых слогов с количеством символов не коррелирует. Слова состоят из одного и более кандзи. При этом, одни и те же слова могут быть записаны разными способами и иметь разные варианты прочтения, которые различаются или нет по смыслу. Неплохо, неплохо. Удивит ли нас еще японская письменность? С чем еще она заставит нас столкнуться?
Атэдзи (当て字)
Атэдзи - это, без сомнения, мои любимые слова в японском языке. У японцев не было кандзи для некоторых слов, но вместо того, чтобы использовать хирагану или катакану, они решили: "А почему бы просто не заюзать рандомные иероглифы, у которых одно из произношений нам подходит?" Идея отличная, сказано - сделано. Так у нас появились 西班牙 (supein, Испания), который состоит из кандзи "запад", "группа людей" и "клык"; 洒落 (share, модный), который состоит из кандзи, похожего на саке, но не имеющего своего собственного общеизвестного значения, и иероглифа "падать"; и сотни других слов, значение которых не связано с иероглифами, которые используются.
Но, если случаи, когда значение и кандзи не связаны, то должны же быть слова, где не связаны кандзи и произношение?
Гикун (義訓)
И такое тут есть. Например, 海象 (seiuchi) состоит из кандзи "море" и "слон" и означает "морж", но произношение никак не связано с написанием, и позаимствовано от русского "сивуч".
Окей. Слова, где кандзи не влияют на смысл. Check. Слова, где кандзи не влияют на произношение. Check. Как насчет слов, где кандзи не влияют ни на смысл, ни на произношение?
Серьезно?
На самом деле, нет. Формально такой категории слов не существует. Но есть слова, где используется какое-то совсем редкое и неизвестное чтение кандзи и/или значение слова так далеко от значений составляющих его кандзи, что увидеть эту связь можно только, если целенаправленно прочитать об этом.
Например, 百合 (yuri, лилия). Кандзи 百 и 合 никак не подсказывают, как произнести слово. Казалось бы, и смысловой связи никакой нет, поскольку 百 означает "сто", а 合 означает "смешивать". Но словарь подсказывает, что выбор этих двух кандзи был не случаен и он символизирует то, что луковицы лилии сплетаются друг с другом в больших количествах. Так что номинально используемые кандзи отражают смысл слова. На практике же, пока в словарь не заглянешь, в жизни не догадаешься, о чем речь.
Кошмар какой! А есть ли вообще шанс угадать произношение и значение впервые встреченного сочетания кандзи?
Вообще, да. Например, встретив слово 優越感 (yuuetsukan, комплекс превосходства) в первый раз, вы сможете и произношение, и значение понять сразу, поскольку у этих трех кандзи возможных чтений совсем мало, а значение достаточно очевидно из значений отдельных иероглифов (感 - "чувство", 優 и 越 - оба означают "превосходить"). Проще всего с научными и медицинскими терминами. Там кандзи комбинируются в интуитивно понятные слова. Разумеется, интуитивно понятными они будут только в том случае, если вы уже до этого потратили сотни или тысячи часов на японский язык.
Другая проблема заключается в том, что, даже если кажется, что вроде понял и прочитал новое слово правильно, потом может оказаться, что конкретно здесь использовалось какое-то уникальное произношение или что смысл оказался не совсем тем, который ожидал. Как провести ту грань, где можно положиться на интуицию, а где лучше проверить в словаре, - вопрос открытый.
Более того, иногда даже удается угадать произношение кандзи, который видишь первый раз в жизни. Дело в том, что кандзи состоят из элементарных частей, которые называются радикалами (или ключами). Всего радикалов 214 штук. Довольно часто слова, использующие один и тот же радикал, имеют одинаковое звучание. Например, зная, что 河 и 可 могут произноситься как "ka", вы, встретив 珂, можете предположить, что этот кандзи тоже имеет одним из своих произношений "ka". Это ускорит то, с какой скоростью вы сможете посмотреть этот иероглиф в словаре. Не скажу, чтобы мне это прям очень помогало, но порой упрощает жизнь.
Заключение
Японский язык объективно очень тяжелый. Тяжел он не только для нас, иностранцев, но и для самих японцев. На протяжении всей программы обязательного образования юные азиаты тратят кучу времени на заучивание того, как и что пишется, как произносится. Японская письменность - это настоящее испытание. Несмотря на это, японский язык я люблю и почти ни разу не пожалел, что вложил в него тысячи часов своего времени. Я по-новому взглянул на то, как работает человеческий язык. Какие-то вещи, которые казались мне совершенно очевидными в парадигме европейских языков, функционируют в японском совершенно по-другому. Кроме того, знание японского открыло для меня дверцу в волшебный и гигантский мир богатой японской истории и культуры. Дверцу, которую я использую практически исключительно для чтения примитивных визуальных новелл. Ну и статью вот накатал.

На этом про письменность - все. Планируется еще две статьи на тему: про лексику и грамматику японского. Ну, и, конечно, я помню, что 80% моих подписчиков подписались ради английского языка. Про английский статьи тоже будут :-)
Здравствуйте! Меня зовут Ваган, мне 17, живу в городе Варна в Болгарии. Моё призвание в жизни- анимация, но не рисование мультиков, а создание глубокого и сложного повествовательного искусства. Помимо этого, я увлекаюсь лингвистикой, конструированием языков, историей, феминизмом и вообще всем, что имеет отношение к искусству.
Я ищу общительную (т. е. не стеснительную и не молчаливую) девушку лет 16-18 или старше. Подчёркиваю, что мне нужна только дружба и я не стремлюсь к романтическим отношениям.
У меня есть Мессенджер, Инстаграм, Телеграмм и ВатсАпп. Мой номер +359 98 880 5514
«Чат на чат» — новое развлекательное шоу RUTUBE. В нем два известных гостя соревнуются, у кого смешнее друзья. Звезды создают групповые чаты с близкими людьми и в каждом раунде присылают им забавные челленджи и задания. Команда, которая окажется креативнее, побеждает.
Реклама ООО «РУФОРМ», ИНН: 7714886605
В древней русской письменности чуть ли не каждое слово, каждая форма могли писаться по-разному. Неужто не было никаких правил и «каждый писал, как хотел»? Отнюдь нет!
Из видео вы узнаете:
• чем представления о правописной норме в Средневековье отличаются от современных
• как на Руси сосуществовали две орфографии
• правда ли кириллица была хорошо приспособлена под славянское произношение
• как славянская азбука с самого начала создавала почву для грядущей вариативности написаний
• как ранняя русская орфография была определена тогдашней культурой, обществом и системой обучения грамоте.











