Слушайте трейлер первого тематического сезона «Стартап-секретов» и готовьтесь к выходу первого эпизода.
Весь этот месяц я провожу по три интервью в неделю, чтобы создать самую подробную картину жизни стартапов на нейросетях. Какие деньги зарабатывают. Какие проблемы испытывают. Где находят финансирование.
Я отошел от стандартного формата 1 выпуск = 1 гость. Теперь за 1,5 часа можно услышать истории трех основателей в одной нише, но с разными продуктами, успехами и трудностями.
Вас ждут 30 интервью, собранных в 10 тематических выпусков с основателями стартапов из всех областей: от транскрибаторов и генераторов картинок до медицинских стартапов с ИИ.
Как вы понимаете, это сложнее, но и более информативно.
А еще я превращаю полные интервью и невошедшие в подкаст материалы в конспекты, на основе которых создаю базу знаний по ИИ-стартапам. Ранний доступ к ней можно получить на сайте подкаста.
Поддерживает спец-сезон Yandex Cloud, за что им большое спасибо!
Надеюсь, вы оцените мой труд и примените эти знания для ваших проектов 🌚
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
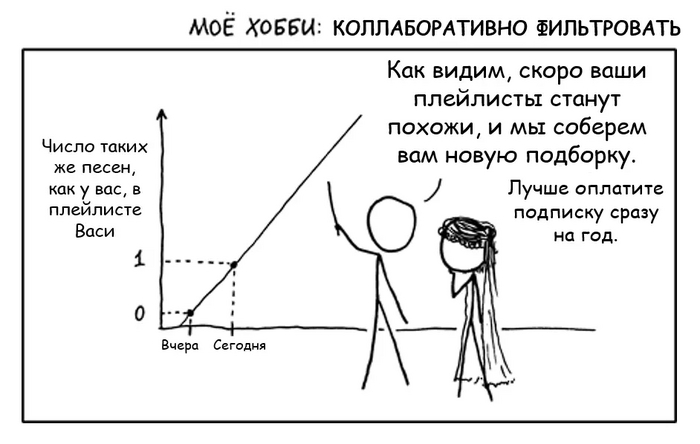
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Никогда еще моё переводческое сердце не заходилось так сильно, как в последнее время, когда перспектива потерять профессию разливается кровавыми огнями заката под натиском искусственного интеллекта.
Не успели мы, преданные псы Иеронима, слететь с ног в 2022-м и, долго и мучительно отдыхиваясь, крутить по канувшему в бездну рынку головой, не веря смоим глазам, понять, что да, больше работы не будет, как теперь пришла новая смена. AI теперь пишет дипломные работы студентам, отвечает на вопросы школьникам, переводит прозу и стихи за считанные секунды. Наступило время кошмаров, прозорливо предсказанных экшнами 90-х.
Удивительно, что ВУЗам еще выделяют бюджетные места на переводческие отделения, еще более удивительно, что на эту профессию еще кто-то поступает. На что-то ведь они надеются, хочется верить, что не все абитуриенты туда приходят просто "ну потому что что куда ж еще, я совсем не определился, посижу пока тут". Страшно мне и горько, потому что я долго на это училась сама и долго вкладывала азы в подрастающее поколение...
Неужели не одухотворить нам больше ничьих страниц воспоминаний, не расшифровать на спор жутких договорных сокращений и не разложить по секундам субтитров...Так же, наверное, обидно было ненужным этой меняющейся планете тяжелым динозаврам. Эхехе- вздыхали они поди, пафосно восклицая: а точно лучше нас переведут? Ничего не упустят? А в Африку тоже поедут? Прямо в каске на стройку? Ну хоть сурдо-динозавры-то останутся?? (Недавно сходили на концерт симфонической музыки...со сцены работал переводчик, показывая на руках жестами события в сказке, по которой через минуту прозвучит музыка...Она очень старалась, я пришла в восхищение от ее экспрессии! А потом представила себя на месте глухих детей...Вот они посмотрели на нее, а потом оркестр начал играть...а они сидеть в тишине...какую музыку они сейчас себе представляют в голове по мотивам ее жестикуляции, интересно...)
Как же тоскливо смотреть на этот закат...И тот факт, что намечающиеся тенденции наверняка не пощадят представителей других профессий, меня лично не очень утешает.
Я так ни разу и не попробовала AI, ни в какой роли.. А вы?
НейросетьRiff позволяет генерировать музыку в формате HD, которые потом можно использовать на YouTube, Tik Tok, подкастах и другое. Достаточно просто описать, для чего нужна музыка и выбрать длительность. Если творческий кризис настолько одалел, что даже не описать, чего хочется, есть аудио для вдохновения и можно добавить видео - за это снимут 5 кредитов.
Бесплатно доступно:
10 бесплатных риффов в месяц
15 секунд создания HD-музыки
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
Есть еще один крутой сервис, который удаляет шумы, но при этом звук не будет как роботизированный, как в Adobe Podcast.
CrystalSoundобеспечивает чистый звук, прекрасно удаляет шум, другие голоса, только еще можно изменить голос и настроить тональность, отлично убирает эхо и можно улучшить качество дорожки.
Кроме того, есть двунаправленное шумоподавление, эта функция доступна в бесплатном тарифе, как и улучшение аудиофайла
Тарифы
Бесплатный
В бесплатном тарифе, помимо лучшего в своем классе двунаправленного шумоподавления и улучшения аудиофайла, доступно:
- 90 минут в день можно обработать БЕСПЛАТНО. Причем их можно продлить, приглашая друзей.
- Стереоголос высокой четкости (48 кГц, 2 канала)
- Низкое потребление процессора
- Удаление эха в помещении
- Акустическое эхоподавление
- Забавные голосовые эффекты
- Уровень шумоподавления динамика
- Низкое искажение речи
Платный
За 12 $ в месяц (или 8 при годовой подписке) будет доступно все тоже самое, что и в бесплатном тарифе, плюс:
- Функция «Только мой голос» для подавления голосов других людей
Хотите быть в курсе полезных ии сервисов для работы, учебы и облегчения жизни? Подпишитесь на мой канал в Telegram НейроProfit, там я рассказываю о том, как зарабатывать с помощью нейросетей и использовать ии-сервисы для бизнеса 😉
Каждый основатель хочет, чтобы бизнес быстро рос. Но слишком быстрые проекты страдают большим списком врожденных болячек, о которых стоит знать заранее, прежде чем ввязываться в «стартапьи бега».
🎧 Подкаст «Стартап-секреты»: Сезон 3, выпуск 2
Я вообще за за технологичность во всем. Очень люблю разные инновационные штуки, стараюсь пробовать все новое и современное. И это любопытство, наверное, одно из из тех чувств, которые меня подтолкнули к инвестированию.
Специальный гость: Женя Чебатков – стендапер, комик, участник шоу «Стендап» на ТНТ и по совместительству инвестор Fabula AI.
Fabula AI – мульти-платформенное приложение для создания и редактирования изображений при помощи нейросетей.
Первая версия сервиса появилась в марте 2023 года и представляла из себя Telegram-бота с функцией создания стилизованных портретов на основе пользовательских селфи и портретных снимков.
Благодаря фримиум бизнес-модели и реферальной системе проекту удалось обеспечить быстрый виральный рост базы пользователей. За первый месяц без маркетингового бюджета телегам-ботом воспользовалось 5000 людей.
Сумма инвестиций от Евгения Чебаткова в компанию Fabula AI на Preseed-раунде составила 5 млн рублей, сделка прошла в августе 2023 года.
В подкасте Али и Родион рассказали:
как им удалось ускорить команду и побороть болячки «хайповых» продуктов
чему они научились на своих ошибках при запуске MVP в формате телеграм-бота
зачем они сделали бесплатный тариф, хотя у конкурентов его не было
что сделали, чтобы достичь 1,7 млн активаций продукта на разных площадках
как они доросли с нуля до оценки в $25’000’000 всего за год и чем в этом помогло новое B2B-направление.
Женя поделился историей о том, как он стал инвестором в российские технологические проекты и чего ожидает от них.
Тайм-коды на YouTube со ссылками:
0:00 Вступление и знакомство с Али и Родионом, которые привлекли 1,7 млн пользователей в свой ИИ-продукт меньше, чем за год
6:43 Женя Чебатков о том, почему и как начал инвестировать в российские стартапы
10:37 Как российскому стартапу поднять денег. Ожидания-реальность
16:23 Особенности телеграм-ботов в качестве MVP продукта
20:40 Стоимость первой версии Fabula AI и почему Али взял на запуск три кредитки
На сайте подкаста «Стартап-секреты» вы найдете все выпуски с возможностью фильтровать по интересующей вас теме, например, «Запуск стартапа», «B2B-проекты», «Инвестиции» или «Глобальные рынки».
Сразу скажу, что ссылки будут полезны как заказчикам, так и исполнителям такого рода услуг.
Даже профессионалы с большим опытом могут для себя здесь что-то новое найти.
50 самых посещаемых нейросетевых инструментов
Здесь всё очень подробно для хорошего погружения.
Авторы исследования изучили более 3000 инструментов искусственного интеллекта, собрав данные из различных каталогов, в которых перечислены инструменты искусственного интеллекта. Из них они выделили 50 самых посещаемых инструментов, которые отражают более 80% трафика индустрии искусственного интеллекта за исследуемый период (с сентября 2022 по август 2023).
Если нужно, что-то попроще, то посмотрите на Топ 26 самых посещаемых ИИ-инструментов в 2023 году. Здесь информация представлена ёмко, со ссылками и кратким описанием. Есть как бесплатные, так и платные инструменты. Тестируйте, чего еще не тестировали.
Что почитать
У меня есть убеждение, основанное на содержании прочитанных мной книг. Заключается оно в том, что не так уж и редко в работах отдельных российских авторов ты натыкаешься на краткий пересказ более содержательных и глубоких произведений их зарубежных коллег. Поэтому в подборке исключительно иностранные авторы.
Люди, которые давно в коммуникациях, скорее всего, не откроют для себя чего-то нового в этом коротком списке (но это не точно). А тем, кто хочет почитать что-то на уровне "стратегии", он может пригодиться.
Здесь список из восьми "толстых", но чертовски полезных книг, и девятая идет бонусом.
На какие каналы можно подписаться
Автор этой подборки мало того, что профессионал в сфере PR, так еще и подписан на ≈100 авторских Telegram-каналов про PR, дизайн, маркетинг и др.
Работая в коммуникациях, он решил собрать в одной статье максимальное число качественных Телеграм-каналов про пиар и смежные сферы: маркетинг, копирайтинг, работу в индустрии и т.д.
Получилось больше 70 штук: авторские каналы про PR, авторские каналы про смежные сферы и корпоративные/общественные каналы на те же темы.
Что можно посмотреть про SMM
Выпуск может быть полезен как предпринимателям, так и SMM-специалистам, а также специалистам из смежных сфер. Мне подкаст показался очень полезным.
В нем про типичные косяки в SMM. О том, как их исправить. Также о SMM-стратегии и тактике. О целях, роли. О том, как строить стратегию. Про отработку негатива. Про SMM для маленьких, средних и больших компаний. Нет инфоцыганских штук про успешный успех. Исключительно разговор практиков.
Что послушать в 2024 году предпринимателю, который развивает свой ИТ-проект, ну или будущему стартаперу?
Зачем слушать подкасты про развитие IT-бизнеса
Любители аудио-контента знают о существовании отличных подкастов о бизнесе, вроде «Несладкий бизнес», «Заварили бизнес», «Бизнес, роботы, мечты». Но за долгие годы существования подкастов в России появились нишевые шоу про IT-бизнес, которые регулярно балуют новыми выпусками.
Идеи, практический опыт, знания о разных рынках и проектах, а еще актуальные направления для развития своего дела – все это вы найдете в свежих подкастах из подборки.
Часто информация, которой делятся участники выпусков, больше нигде не освещается.
Вы можете слушать подкасты в дороге, за рулем, во время занятия домашними делами или на тренировке. Проводите время с пользой в компании интересных людей!
Собрал для вас самые заметные и активные подкасты по теме развития стартапа и предпринимательства в технологической сфере. Слушайте!
Подборка интересных подкастов о стартапах
1. Стартап-секреты с Дмитрием Беговатовым
Длительность выпусков: 60–90 минут
Ведущий: Дмитрий Беговатов, основатель Product Radar – площадки для лучших стартапов и продуктов из России.
Подкаст для тех, кто развивает свой ИТ-бизнес. Большой, маленький, микроскопический – не важно. Ну и для тех, кто пока только мечтает о запуске стартапа. Участники подкаста – предприниматели, инвесторы, партнеры фондов и эксперты по темам развития ИТ-бизнеса: от юридических вопросов, до репутации в интернете и продаж в B2B SaaS.
Гости: Дмитрий Калаев (сооснователь и директор «Акселератора ФРИИ»), Кирилл Куликов (сооснователь beau), Александр Панов (основатель биотех-лаборатории Neiry), Иван Шкиря (основатель Callibri и Гудок), Вадик Михалев (сооснователь Zerocoder и Orchestra), Радик Юсупов (основатель Radist.Online) и другие.
Ведущие: Денис Кутергин (YouDo) и Эдуард Гуринович (CarPrice)
Основатели — это подкаст и видеошоу о бизнесе в России. Ведущие — известные предприниматели, которые сами прошли путь создания бизнеса, Денис Кутергин (YouDo) и Эдуард Гуринович (CarPrice). Мы говорим на одном языке с состоявшимися предпринимателями и знаем всё о построении крупного бизнеса в России.
Гости: Иван Хохлов (сооснователь бренда одежды 12 STOREEZ), Владимир Седов (основал компанию по производству матрасов «Аскона»), Сергей Иванов (сооснователь частной аэрокосмической компании Даурия), Марк Саневич (сооснователь медицинской технологической компании BestDoctor) и другие.
Ведущий: Дмитрий Калаев (Акселератор ФРИИ, фонд ФРИИ)
В гостях у Димы Калаева — IT-предприниматели, инвесторы, топ-менеджеры корпораций и другие эксперты, которые «причиняют пользу» рынку и всей отрасли. Можно и нужно забирать инсайты и внедрять в свой бизнес!
Гости (пока вышла пара выпусков): Максим Спиридонов, основатель бизнес-клуба Reforma, экосистемы Wonder Family, проектов Нетология и Фоксфорд, а также Антон Зиновьев, основатель финтех-сервиса CarMoney и FinTech/AdTech стартапа 7 TECH.
Подкаст студии Red Barn. В каждом выпуске гости из инновационных проектов в разных областях рассказывают о том, как запускаются и живут технологичные стартапы в России.
Гости: Роман Талалаев (сервис по тестированию товаров), Михаил Шперлинг (стартапер-вундеркинд), Илья Бердыш (искусство запуска стартапов на AI) и другие.
Подкаст от ведущего агентства по продаже IT-бизнесов – IT Бизнес Брокер: как покупать, развивать и продавать it-компании.
Мы собираем самые заметные сделки на рынке и общаемся с теми, кто имеет реальный опыт покупки и продажи интернет-магазинов, онлайн-сервисов и мобильных приложений.
Мы вникаем в детали и обсуждаем зачем предприниматели продают и покупают бизнесы, где искать покупателей и инвесторов, как оценивать активы и зарабатывать на сделках больше.
Гости: Михаил Шперлинг (16-тилетний со-основатель Ai Disraeli), Денис Ларионов (владелец холдинга Modesco, приобрел телеграм-сервис fleep.bot), Евгений Боровков (серийный it-предприниматель, основатель первого российского конструктора прототипа сайтов – WebMaster), Дмитрий Грин (действующий предприниматель в it-сегменте) и другие.
Каждую неделю Анастасия Жигач обсуждает с профильными специалистами самые актуальные темы для бизнеса — релокацию, международную экспансию, изменения в законодательстве и многое другое.
Гости: Мария Баталова (основательница сети глэмпингов «Хюгге Кэмп»), Александр Горный (сооснователь United Investors), Денис Ефремов (принципал венчурного фонда Fort Ross Ventures), Дмитрий Курин (директор МТС по инновациям и инвестициям) и другие.
Подкаст от команды «Контура» для тех, кто строит свой бизнес и проверяет гипотезы.
Гости: Антон Езуб (серийный предприниматель, у которого за спиной бренд арахисовой пасты Hey, nut, школа дополнительного образования для детей, веб-студия), Иван Зайченко (создатель франшиз «Жизньмарт» и «Сушкоф и Дельпесто»), Сергей Негодяев (управляющий партнер и кофаундер Prospective Technologies Venture Capital), Ринат Шамсиев (кофаундер Звонобота) и другие.
В подкасте издания «Правила жизни» Сергей Мезенцев разбирается, каково это — развивать технологический стартап до большой и мощной IT-компании в России 2023 года. Как привлечь инвестиции? Как убедить клиентов в том, что за вашей технологией — будущее и оно уже наступило? Как упаковать новаторскую идею в B2B и B2C продукт? Как быть с импортозамещением? Эти и другие вопросы Сергей обсуждает с руководителями стартапов, занимающихся всем, что только можно вообразить — от дополненной реальности до кибербезопасности.
Гости: Александр Серебряков (CEO TextBack), Евгений Костюшов (CEO MedVR). Дмитрий Яшин (CEO Easyteka).
В подкасте обсуждаем, как, действуя нестандартно, добиваться успеха. Разбираем кейсы, подсматриваем лучшие ходы, полируем фишечки. С кайфом говорим о лайфхаках в маркетинге, бизнесе, стартапах и технологиях.
Гости: Иван Чирков (руководитель группы бренда Нетология), Кристина Дмитриева (дизайнер и основательница школы дизайна для девушек «Brand design wellness»), Варвара Лялягина (предпринимательница, руководительница Start Blog Up и сообщества Студия), Алексей Черняк (сооснователем Darberry, экс-гендиректором Групон Россия, сооснователем синдиката инвесторов United Investors) и другие.
Подкаст о стартапах, которые смогли преодолеть гравитацию старта и взлетели 🚀Здесь мы общаемся с основателями стартапов, узнаём, что у них получилось и не получилось, а также делимся опытом в реализации проектов.
Гости: Михаил Чернов (CEO & Founder Refin Online), Мария Конопелько и Антон Волков (co-founders в Solvery), Игорь Поваразднюк (генеральный директор бренда "Атом"), Кевин Ханда (сооснователь маркетплейса KazanExpress) и другие.
Если вы знаете еще интересные подкасты на тему IT-бизнеса, пишите в комментариях!
Лайк подборки в поддержку хороших подкастов – приветсвтуются. А еще не забывайте оценивать подкасты в Apple Podcasts и на других площадках – авторам это очень приятно! 🌚