
Быстрая адаптация для масштабирования изображений в диффузионных моделях
Автор: Денис Аветисян
Новый подход позволяет значительно ускорить процесс получения высококачественных изображений из диффузионных моделей, сохраняя при этом сопоставимое качество.

Адаптер повышения разрешения на основе скрытых пространств (LUA) интегрируется в существующие диффузионные конвейеры без переобучения генератора/декодера и дополнительных этапов диффузии, обеспечивая повышение разрешения скрытого представления в два или четыре раза (64 × 64 до 128 × 128 или 256 × 256) с последующим однократным декодированием до разрешения 1024 × 1024 или 2048 × 2048, что добавляет всего +0.42 с (1K) или +2.21 с (2K) на GPU NVIDIA L40S, превосходя многоэтапные конвейеры повышения разрешения и достигая эффективности, сравнимой с повышением разрешения в пиксельном пространстве, при сопоставимом перцептивном качестве.
Представлен LUA – легковесный адаптер, эффективно масштабирующий латентные представления в диффузионных моделях с использованием трансфера Cross-VAE и однопроходного масштабирования.
Диффузионные модели, несмотря на впечатляющие результаты, сталкиваются с ограничениями масштабируемости при генерации изображений высокого разрешения. В работе, озаглавленной 'One Small Step in Latent, One Giant Leap for Pixels: Fast Latent Upscale Adapter for Your Diffusion Models', представлен адаптер LUA – легковесный модуль, выполняющий суперразрешение непосредственно в латентном пространстве. Это позволяет значительно ускорить процесс генерации изображений высокого разрешения без потери качества, избегая затратных операций постобработки. Не откроет ли данное решение путь к созданию более эффективных и масштабируемых генеративных моделей будущего?
Преодолевая Границы Высокодетализированной Синтезации Изображений
Создание изображений высокого разрешения представляет собой серьезную вычислительную задачу, требующую значительных ресурсов и времени обработки. Традиционные методы супер-разрешения, работающие непосредственно с пикселями, хотя и демонстрируют эффективность, зачастую приводят к появлению артефактов и остаются ресурсоемкими. Существующие подходы, использующие многоступенчатые диффузионные пайплайны, страдают от увеличения задержки, что препятствует их применению в задачах, требующих обработки в реальном времени. Таким образом, поиск новых, эффективных и быстрых методов синтеза высокодетализированных изображений остается актуальной научной проблемой, ограничивающей возможности широкого применения таких технологий.

Наш метод (SDXL+LUA) обеспечивает минимальную задержку и создает чистые, стабильные текстуры без артефактов и шумов, характерных для прямого высококачественного сэмплирования или методов повышения разрешения в пиксельном пространстве, что демонстрируется на сравнении изображений, сгенерированных из базовых SDXL-изображений.
Скрытая диффузия и новый подход: LUA
Для решения вычислительных задач, связанных с диффузионными моделями, активно исследуются методы работы в сжатом латентном пространстве. В рамках данного подхода представлена Latent Upscaler Adapter (LUA) – легковесный модуль, предназначенный для эффективного увеличения разрешения латентных представлений. Интегрируясь между генератором и декодером VAE, LUA позволяет повысить детализацию генерируемых изображений без необходимости переобучения модели или добавления дополнительных этапов диффузии, обеспечивая тем самым значительное ускорение процесса и снижение вычислительных затрат.
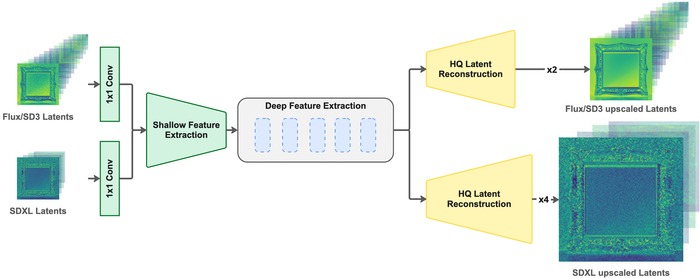
Архитектура Latent Upscaler Adapter (LUA) использует общую основу SwinIR для различных масштабов, адаптируя ширину латентного пространства VAE и обеспечивая масштабирование латентов в ×2 или ×4 с помощью специализированных pixel-shuffle голов.
Архитектура LUA и стратегия обучения
В основе LUA лежит архитектура SwinIR, использующая механизм оконного самовнимания и Swin Transformer для эффективной экстракции признаков в латентном пространстве. Для оптимизации производительности системы применена многоэтапная стратегия обучения, постепенно повышающая сложность задач и улучшающая конечные результаты. Обучение и оценка LUA проводились с использованием датасета OpenImages, представляющего собой обширный ресурс для исследований в области синтеза изображений и обеспечивающего надежную основу для оценки эффективности предложенного подхода.

Метод LUA обеспечивает наилучшее качество масштабирования изображений за счет сохранения деталей и минимального уровня шума при незначительных затратах времени, превосходя bicubic и SwinIR в плане стабильности и четкости деталей.
Превосходство и Эффективность Latent Upscaling
Исследования демонстрируют, что Latent Upscaling (LUA) обеспечивает значительное снижение вычислительных затрат и задержки по сравнению с традиционными методами, такими как LIIF и увеличение разрешения в пиксельном пространстве. Оценка качества с использованием метрик, включая FID Score, KID Score и CLIP Score, подтверждает способность LUA генерировать высококачественные изображения, сохраняя их семантическую согласованность. Работа в латентном пространстве позволяет LUA минимизировать артефакты и обеспечивать визуально превосходные результаты. В частности, достигнут передовой показатель FID в 176.90 при разрешении 4096x4096 и pFID в 61.80 при том же разрешении. При разрешении 2048x2048 LUA демонстрирует FID в 180.80 и pFID в 97.90. Время обработки изображений 4096x4096 составляет 6.87 секунды, а для изображений 2048x2048 – 3.52 секунды, что свидетельствует о высокой производительности метода.

Поэтапное обучение позволило улучшить качество реконструкции и детализацию декодированного изображения за счет постепенного увеличения разрешения и концентрации высокочастотной энергии вокруг ключевых элементов.
В основе представленной работы лежит стремление к предельной эффективности и точности. Авторы демонстрируют, что без четкого определения задачи масштабирования скрытых представлений в диффузионных моделях, любое решение будет лишь шумом. Предложенный LUA-адаптер, легкий и эффективный, позволяет достичь высокого разрешения изображений с минимальными вычислительными затратами. Это подтверждает, что элегантность алгоритма проявляется в его математической чистоте и доказуемости. Как заметила Фэй-Фэй Ли: «Искусственный интеллект должен служить людям, а не наоборот». Эта работа демонстрирует, как ИИ может быть разработан для более эффективного и доступного создания визуального контента, служа тем самым этой цели.
Что Дальше?
Представленная работа, безусловно, демонстрирует элегантность решения в области масштабирования скрытых представлений. Однако, не стоит обманываться кажущейся простотой. Оптимизация без анализа – это самообман и ловушка для неосторожного разработчика. Вопрос не в том, насколько быстро можно получить результат, а в том, насколько корректно он отражает истинную структуру данных. Необходимо тщательно исследовать влияние адаптера на генеративные возможности модели, избегая случайных артефактов и потери разнообразия.
Очевидным направлением для будущих исследований представляется формальная верификация свойств адаптера. Доказательство сходимости и стабильности алгоритма – задача нетривиальная, но необходимая. Кроме того, следует обратить внимание на возможность обобщения подхода на другие типы скрытых пространств и генеративных моделей. Успешное решение этих задач позволит создать действительно универсальный инструмент для высококачественной генерации изображений.
Наконец, представляется важным оценить вычислительную стоимость адаптера в контексте реальных приложений. Ускорение процесса генерации должно быть значительным, чтобы оправдать дополнительные затраты на обучение и внедрение. В противном случае, мы рискуем получить лишь очередное красивое решение, не имеющее практической ценности.
Оригинал статьи: denisavetisyan.com/malenkij-shag-v-skrytom-prostranstve-ogromnyj-skachok-dlya-izobrazheniya
Связаться с автором: linkedin.com/in/avetisyan








