Будучи адептом идеи "вкалывают роботы, а не человек", в попытках автоматизировать свой дом, с целью больше никогда не вставать с дивана понял, что облачные решения вроде Алисы и Гугла слишком медленны, ненадежны и дороги для студента. Так еще и какая-то злобная компания будет слышать все что происходит в моем доме! На постоянной основе! В общем, было решено делать своего голосового помощника, да чтобы не просто выполнял команды, а еще и поговорить с тобой мог. Еще несколько видео с демонстрацией работы в конце поста.
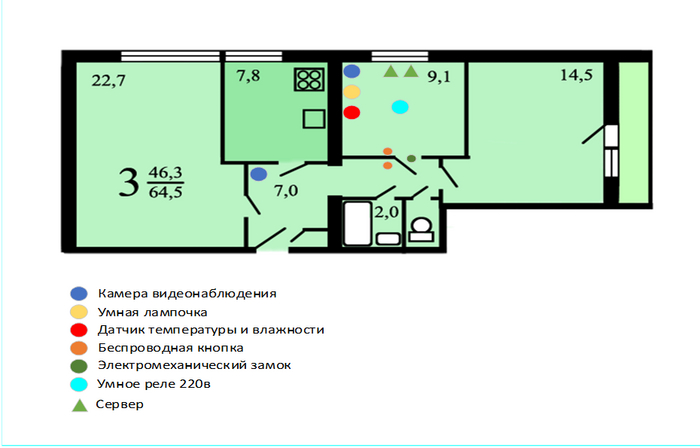
Для начала пара слов о том, что имеется в безумном доме:
cервер Intel NUC 5I3RYK - 2 шт.;
USB ZigBee координатор - 1 шт.;
умная беспроводная кнопка– 2 шт.;
электромеханический замок 12в – 1 шт.;
умные лампочки – 1 шт.;
умное реле – 1 шт.;
датчик температуры и влажности – 1 шт.;
камера видеонаблюдения – 2 шт.
Установлено все следующим образом, пока оборудована только любезно выделенное мне родственниками пространство в 9 квадратных метров, но имеем что имеем:
Подключить все планируется по этой схеме. Задумка сделать архитектуру клиент-сервер связана с тем, что будет один сервер голосового помощника, который взаимодействует с УД, внешним миром, и клиенты с речевым модулем на нескольких устройствах в разных точках дома:
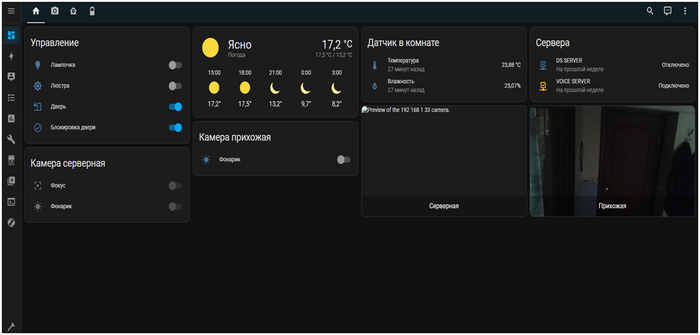
Реализация на данный момент выглядит так:
Все объединено в Home Assistant:
камеры китайское Г, поэтому постоянно отваливаются. на момент написания поста заменены на нормальные
С системой УД разобрались, теперь к самому помощнику. Задачи перед ним стоят следующие:
выполнение сценариев УД, прописанных в хоум ассистант либо внутри самого помощника
управление устройствами УД по отдельности по именам
имитация диалога с пользователем, если в сказанной человеком фразе нет команды
поиск информации в Интернете
В качестве языка выбрал питон. ибо просто.
Для реализации распознавания голоса была использована библиотека Vosk с маленькой готовой речевой моделью для русского языка. Большая не запускалась. Ни на процессоре, ни на видеокарте, висит и все. Ну да и бог с ней.
Чтобы помощник мог разговаривать с пользователем, ему нужно знать, что ответить. Скачал несколько готовых баз для чат-ботов, объединил, адаптировал. Получилась система вопрос-ответ. Тупенькая, но для начала пойдет. Объем 78.000 пар вопрос-ответ. С этим помощник сможет хотя бы более-менее осмысленно отвечать на вопросы, и это полностью локально. А беседы я с ним водить и не собирался.
Логика работы, согласно поставленным задачам заключается в следующем:
Помощник распознает начало фразы, в качестве триггера - резкое повышение громкости звука относительно фона. За конец фразы принято возвращение громкости в норму, равное окружающему шуму.
При помощи языковой модели распознаются слова, и превращаются в массив данных, разделенных по слову
Распознанные слова сравниваются с массивом имен, чтобы однозначно определить, была ли адресована сказанная фраза помощнику. При этом не имеет значения, сказано имя в начале, в конце или в середине. (Робот, включи лампу. Включи лампу Бот.) Можно использовать несколько имен.
Распознаем, содержится ли в сказанной фразе какая-либо команда для бота. В коде команды представляют собой набор слов, которыми с наибольшей вероятностью пользователь задаст команду. Опытным путем выяснил, что при совпадении 2-х и более слов команды ее можно смело выполнять. (На этом этапе не помешало бы сделать управление каждым устройством по отдельности, то есть получение с сервера умного дома названий устройств и т.д.), но пока я до этого не дошел. Задал через "обычные" команды два сценария для управления замком двери - да и все пока. Распознал команду - отправил ее на серверную часть помощника. Серверная часть помощника провзаимодействовала с сервером Умного Дома, отправила ответ о выполнении/не выполнении команды обратно в клиент, клиент произнес ответ для пользователя.
В клиенте (первый элемент массива - название команды, последующие - содержание):
['погода на улице', 'погода','погодой','улице','за','окном','сегодня'],
close_door_and_turn_on_lock() - функция которая общается с сервером умного дома и что-то делает
Отдельно реализована функция поиска в Википедии, триггерящаяся на слова "что такое" или "кто такой", выполняет поиск в энциклопедии и зачитывает первые два предложения. Этого достаточно для отражения сути.
Говоря в общем о взаимодействии сервера и клиента, в данный момент я использую веб-сокеты для передачи информации между ними. Позднее планирую перейти на restAPI, чтобы сервер и клиент равноправно триггерили друг друга на выполнение каких-то действий. То есть чтобы например сервер, анализируя погодные условия, мог послать в клиент фразу для произношения "через два часа начнется дождь".
5. Если не нашли ни команды, ни триггера для поиска в википедии, включаем сценарий имитации диалога. Он работает по методу сопоставления гештальт-паттернов, придуманным в 1983 году Джоном У. Рэтклиффом и Джоном А. Обершелпом и опубликован в журнале доктора Добба в июле 1988 года. Простым языком, мы, имя базу вопрос-ответ, сравниваем сказанную пользователем фразу с каждым вопросом в этой базе, на выходе получая массив коэффициентов подобия (на сколько заданный вопрос соответствует конкретному имеющемуся) от 0 (нет ни одной совпадающей буквы) до 1 (полное совпадение), после чего ответ, где коэффициент подобия оказался наибольшим, выводим в речевой движок и пользователь слышит ответ.
Вот и вся суть. Ниже прикрепляю несколько видео с демонстрацией работы помощника. Планы на будущее этого проекта:
написать код для управления каждым умным устройством по отдельности, по именам получаемым с сервера Умного дома
заменить метод гештальт-паттернов на какой-никакой обучающийся ИИ
расширить парк умных устройств, написать новые сценарии взаимодействия с ними
С момента, как студенты и ученики начали писать доклады и научные работы при помощи чата GPT, стало очевидно, что программирование и нейросети уже вошли в мир образования, и несмотря на многочисленные голоса против внедрения такой практики, прогресс остановить нельзя. Его нужно направить в полезное русло. Давайте вместе разберемся, как это можно сделать.
Как нам настроить систему образования
Программирование и нейросети давно и много используют в приоритетных отраслях экономики в России, включая здравоохранение, финансы, транспорт, сельское хозяйство и пр.
медицинские учреждения вводят в свою работу системы диагностики заболеваний с использованием искусственного интеллекта — например, нейросети анализируют изображения для выявления рака на ранних стадиях;
финансовые алгоритмы прогнозируют курсы валют и ценных бумаг;
рабочие системы управляют транспортным потоком с использованием данных о движении и планировании маршрутов;
в сельском хозяйстве дроны используют для мониторинга состояния посевов и других задач.
Используя нейросети и программирование, специалисты решают рабочие задачи быстрее, эффективнее и точнее. Например, автоматизируют рутинные процессы, снижают риск ошибки и экономят время для творческих задач, которые до сих пор лучше даются живым командам. Система образования не исключение, а значит, мы должны настраивать её так, чтобы она отражала и поддерживала ценности и потребности нашего общества:
мы ценим время — быстро ищем и обрабатываем информацию из нескольких источников;
мы ценим личное пространство — отдаем предпочтение онлайн-обучению на платформах для дистанционной работы;
мы ценим личностные особенности — скачиваем образовательные приложения и инструменты для персонализации учебного процесса.
Программирование
Прежде чем продолжить погружение в тему программирования, давайте убедимся, что одинаково пониманием предмет разговора. В нашем представлении программирование — это процесс создания и написания специальных пошаговых инструкций для компьютера, чтобы он сделал в точности то, что мы от него требуем (а не хотим). Такая грамотно написанная инструкция позволяет перераспределить колоссальный объем работы между представителями системы образования и компьютером.
Благодаря программам и алгоритмам автоматизируется решение сложных структурных задач, педагоги начинают более качественно управлять учебным процессом, создавать новые образовательные продукты и услуги. Так, например, центр искусственного интеллекта НИУ ВШЭ использует нейросетевые алгоритмы анализа динамики эмоционального состояния и вовлеченности учеников на основе данных видеонаблюдения. Проще говоря, по видео можно посмотреть, какая часть лекции была интересной большему количеству учащихся, а какая клонила людей в сон и нагоняла тоску.
Работа с нейросетью оптимизирует «бумажную работу», помогая выдавать необходимое количество требуемых типовых документов в нужный срок и анализировать эти же стопки цифровых бумаг, вычленяя самую суть. А при должном желании и развитии базовых навыков программирования какие-то задачи и вовсе не потребуют участия человека больше одного раза: например, регулярный парсинг результатов работы за месяц из открытых источников и сборка в отчет могут происходить по нажатию кнопки после единоразовой настройки. А в жизни человека, не знакомого с нейросетями, на это могут уходить целые дни.
Ежегодно возрастающая информационная нагрузка
Министерство цифрового развития в прошлом году сообщило о росте интернет трафика в России в 11 раз в сравнении с 2012 годом, подкрепив также эти данные показателем доступности интернета в 88% и почти 106 миллионами активных пользователей социальных сетей, которые ежедневно потребляют и генерируют контент. А экранное время многих пользователей стабильно перешагивает за несколько часов в день. Все эти часы представляют собой около 34 гигабайт информации каждый день, которые наш мозг должен обработать и усвоить. Это огромное количество данных включает в себя все, что мы видим, слышим, читаем и чувствуем в течение дня.
Если у кого-то есть возможность сократить это время, то с учащимися ситуация выглядит иначе: значительную часть этого объема занимает образовательный контент — лекции, курсы, уроки, доклады, курсовые работы, что еще больше увеличивает информационную нагрузку, и нет возможности ее уменьшить. Очевидно, что мозгу нужна помощь. Особенно детскому. И в этой ситуации нейросети готовы взять на себя эту роль.
Как нейросеть помогает учить детей
Пик совершенства нейросети — это способность программы думать, понимать и принимать решения, почти как человек. Для детей они могут стать доступным помощниками, которые еще раз объяснят или «разжуют» материал.
Отчасти это одна из причин, почему в рамках федерального проекта «Искусственный интеллект» Правительство РФ поощряет изучение ИИ на всех уровнях образования, включая программы среднего, высшего и дополнительного образования. Для учеников старших классов доступна Всероссийская олимпиада по искусственному интеллекту, где участники могут попробовать свои силы в поиске нестандартного применения и разработки новых интеллектуальных алгоритмов и инструментов обработки больших данных. На платформе «Сириус.Курсы» разработан «Навигатор по искусственному интеллекту» с серией онлайн-программ и курсов для погружения в мир нейросети.
С помощью нейросети создаются персонализированные образовательные программы.
Обращаясь к нейросетям, учителя мгновенно получают сутевую выжимку из больших объемов незнакомых данных, за секунды обрабатывают результаты нескольких классов, разрабатывают черновые сценарии уроков или индивидуальных учебных планов. За этим стоит возможность удерживать в образовательном фокусе больше детей, учитывать их особенности и договариваться с родителями, снижая общий уровень напряжения от школы.
Кроме того, использование нейросетей позволяет автоматизировать проведение тестов, оценку результатов, планирование учебного процесса. Это снижает нагрузку на педагогов и упрощает им работу, освобождая время для направленной работы с учащимися. Так в Москве запустили цифровую образовательную платформу «Московская электронная школа», которая внедряет искусственный интеллект для анализа данных обучения и оптимизации учебных планов, а также построения индивидуальных образовательных траекторий.
Таким образом, программирование и использование искусственного интеллекта в системе образования могут не только значительно улучшить качество обучения, но и (что особенно важно!) сделать его более доступным и эффективным для учащихся. Подобные современные технологии и инновации помогают сформировать новое поколение образованных и компетентных специалистов, готовых к профессиональным вызовам современного мира.
С начала прошлого года я наблюдал за появляющимися в больших количествах статьями и материалами на тему изучения английского языка с помощью ChatGPT. Конечно, как преподавателя английского языка, меня очень интересует этот вопрос, так же как и лодочников, сломавших первую лодку с паровым двигателем, и извозчиков, недовольных трамваями. Однако с течением времени моя тревога прошла, потому что полтора года спустя не объявилось ни одного человека, выучившего английский язык только с помощью нейросети. А отсутствие подтвержденных результатов – это достаточно мощный аргумент.
Сhat GPT пытается учить английскому языку, соединяя кусочки из различных учебников
Как вы относитесь к гомеопатии? Стали бы вы с ее помощью лечить опасное заболевание, если есть проверенные годами методы? Хотя можно привести и примеры с ГМО, где есть прослойка населения, опасающаяся использовать «новинку», но здесь у нас хотя бы есть некие исследования о безвредности, а в ChatGPT – нет свидетельств по типу «я использовал только ChatGPT и достиг отличных результатов». Под результатами мы конечно понимаем способность работать за границей, общаться с коллегами или хорошие баллы на экзамене типа IELTS или TOEFL.
Но это обывательский подход, конечно же, уже проводились некие исследования, задействующие фокус-группы, в ходе которых, например, было выяснено, что «ChatGPT оказывает позитивное воздействие на навыки письма и незначительное – на развитие разговорных и грамматических навыков, словарный запас, мотивирование участников занятия». Упоминается, что «хотя AI-технологии по типу ChatGPT могут оценивать уровень знания, и проводить инструктаж по обучению языкам, они должны рассматриваться скорее как дополнение, а не как замена людям».
Но, на днях вышла новая версия ChatGPT-4o, которая отвечает еще быстрее, распознает эмоции и изображения. Хотя не все возможности, продемонстрированные на презентации, уже доступны широкой аудитории, ясно, что это рано или поздно произойдет. И опять закралась мысль, неужели все скоро станут учить английский язык только с нейросетями? А ведь могут попытаться, учитывая, что упомянутые материалы (статьи и видео) преподносят ChatGPT, как нечто революционное в сфере обучения иностранным языкам. Более того, уже появились платные сервисы, работающие на основе нейросети, не берусь сказать, ChatGPT это или нет, но они способны запоминать контекст беседы, а также задавать вопросы. И все же, полагаем, что правильное использование нейросетей состоит в дополнении традиционных методов обучения, а никак не в полной их замене.
1. Почему идея использовать ChatGPT для изучения английского языка выглядит привлекательно? Во-первых, это либо почти бесплатно, либо очень дешево. Во-вторых, если ChatGPT может моментально ответить на любой вопрос, а теперь еще и в голосовом формате, то зачем нужен учитель? Можно просто напечатать на русском языке запрос «учи меня английскому» - и процесс пойдет. Но проблема в том, что вы не выучите язык за день, не перейдете на следующий уровень и за месяц. Вам нужно следовать учебной программе несколько месяцев, и тут начинаются вопросы к тем, кто просит «составить ChatGPT программу для обучения английскому языку» - программу нейросеть, так уж и быть, составит, но оценить ее адекватность она не в состоянии.
2. ChatGPT компилирует информацию из разных источников. Это наверное хорошо, если вам нужна курсовая, которая пройдет проверку на антиплагиат. А если ChatGPT возьмет одну половину из учебника Outcomes, а вторую половину из English File, учебников с похожим, но разным набором лексики, которая повторяется в определенном порядке, то эффективность изучения полученной компиляции будет ниже, чем если бы вы взяли только один учебник. Не очень понятно, как ChatGPT может подменить собой методолога. Да, если вы сделаете запрос «составь мне программу от нуля до продвинутого уровня английского языка за 3 месяца», то получите с виду адекватный ответ, но мы понимаем, что чудес не бывает, и любой интеллектуальный навык формируется в течение длительного периода времени.
Пример
Для достижения уровня B2 за месяц Сhat GPT рекомендует заниматься каждый день по 8 часов.
Рекомендует скачать Анки и запомнить "столько слов, сколько сможете". Хотя в целом рекомендация "занимайтесь много и все получится" - верная, но спрашивать ChatGPT для этого вовсе не обязательно. Программа не скажет вам, что-то то невозможно, наверное, потому, что в нее не заложена информация о всех людях, живущих на Земле. А любой человек-специалист сразу скажет, что даже гении учат языки несколько лет, а до B2 при условии изучения языка 8 часов в день и если у вас хорошие способности вы дойдете, ну, например, через полгода. Такой статистики просто нет.
Кроме того, для начинающего изучать язык преимущества одного метода над другими вовсе не очевидны. Это вообще проблема всех «гуру» и «коучей», блогеров, создающих «обучающий» контент, которые ориентированы на неспециалистов в сфере и готовы раздавать обещания, гарантии, которые могут выглядеть правдоподобно.
А ChatGPT по своей сути является сейчас именно таким всезнающим гуру, который может складно и вежливо ответить на любой вопрос, при этом сгенерировать совершенно неадекватный ответ. Поэтому, тот, кто решил изучать язык только с нейросетью, рискует попасть под каток экспериментальных методов и либо тренировать одни и те же навыки каждый день, не продвигаясь вперед, либо пытаться за один раз выучить огромное количество информации. Потому что ChatGPT пока еще берет информацию не только из книг по изучению английского языка, а и из статей копирайтеров.
3. На самом деле, ChatGPT в контексте изучения иностранных языков не является чем-то инновационным.
Что можно сделать в ChatGPT? Про составление «программы» мы уже написали, можно еще:
a) Перевести слово – так же как и в любом словаре;
b) Услышать, как слово звучит (в машинной озвучке (хотя уже и очень близкой к человеческой), в отличие от онлайн-словарей);
c) Перевести фразу – так же, как в Гугле и прочих переводчиках;
d) Задать вопрос на английском языке – и получить ответ. Если это вопрос по грамматическим правилам, то опять же, неясно, чем он будет лучше оригинала из статьи или учебника. При этом, читая оригинал, вы знаете, кто является автором материала, его опыт и квалификацию. В ChatGPT это сделать невозможно, хотя последние версии работают не только с заранее загруженной информацией, но и предоставляют актуальные ссылки на сайт – но непонятно, зачем тогда нужен ChatGPT, чем он лучше Гугла?
e) Подобные программы существовали и ранее, например, Rosetta Stone. Многие знают и про DuoLingо. Чем от них отличается ChatGPT? Это нейросеть, которая отвечает на запрос человеческим языком. Последние версии могут даже отвечать на голосовые запросы. При этом важную информацию, и это написано в самом окне запроса ChatGPT, лучше не искать.
4. Чего Chat GPT делать не может? Программа не сможет помочь с улучшением произношения. Последние версии нейросети каким-то образом распознают эмоции собеседника, но что касается качества вашего произношения – не удалось никаких подтверждений того, что ChatGPT может сказать, говорите вы с акцентом или нет, и что именно не так. То есть существует два режима – вас либо понимают (сравнивают образцы вашей речи с записанными в программу), либо нет. С одной стороны, это и неплохо – если вас понимают, то ваш акцент не такой уж и сильный. А с другой, программа может и не понимать, что ваш акцент на грани понимания и в следующий раз опустится ниже этой грани, и помочь она не сможет. Схожую проблему сложности тренировки произношения отмечает и известный носитель американского английского Рэйчел – неважно, как с какими бы искажениями она не произносила слово, приложение “Elsa Speak” считало его эталонным, если оно смогло понять это слово. А нужно отметить, что это неплохое специализированное приложение для повышения уровня языка (в отличие от «мастера на все руки» ChatGPT). Возможно, для детей младшего школьного возраста это не будет являться проблемой, так как они могут научиться говорить без акцента, просто повторяя за программой. Но при обучении детей еще возникает проблема мотивации – программу с нейросетью нужно адаптировать в изощренно увлекательный формат, иначе дети просто не смогут фокусироваться на ней сколь-нибудь длительное время. Поэтому, на наш взгляд, школьным учителям не стоит опасаться, что их заменят в обозримом будущем - по крайней мере пока Boston Dynamics не создаст робота, который бы вызывал учеников к доске, а родителей – в школу.
Мотивация вообще является основной проблемой изучения языка с нейросетью. При разговоре с искусственным интеллектом вы на самом деле тренируете навык разговора с искусственным интеллектом. А не человеком, с которым приходится задействовать и эмоции, проявлять заинтересованность, использовать невербальный язык. Представьте боксера, который тренируется без спаррингов, только с тренажерами и с грушей, причем несколько лет, сможет ли он потом противостоять настоящему противнику, несмотря на отработанные приемы и хорошую физическую форму? У меня серьезные подозрения, что люди не публикуют результаты обучения с ChatGPT потому, что им это в какой-то момент надоело и они забросили и нейросеть и английский.
5. Есть примеры из других сфер. Конечно, можно вспомнить симуляторы игр – автогонки, шутеры, авиатренажеры. Но если посадить такого, например, любителя автосимуляторов в болид «Формулы-1» или в трактор, то тронуться с места он не сможет, что уж там говорить о неготовности к перегрузкам от высоких скоростей.
Есть и менее известный пример, но близкий к нашей теме. В шахматах аналоги ChatGPT появились уже больше 20 лет назад. Это программы, которые показывают лучший ход в любой позиции. Изначально такие шахматные движки играли лучше человека только за счет перебора лучших ходов, при этом были позиции, к которых, из-за сложности перебора, человек мог с первого взгляда определить исход партии, а программа давала неопределенные и неправильные оценки.
С течением времени оценка позиции на доске у таких программ значительно улучшилась и теперь не уступает человеческой, более того, последние программы могут и играть в более человечном стиле, жертвуя фигуры за инициативу. Казалось бы, если есть возможность спросить программу, «а что делать в этой позиции» и получить правильный ответ в виде варианта, то изучать шахматы стало легче?
И да, и нет. Профессиональным шахматистам сейчас невозможно подготовиться к партии без шахматных движков, им приходится запоминать тысячи вариантов, выданных программой – просто потому, что иначе их, эти самые лучшие варианты запомнит соперник.
Однако, ни один тренер не порекомендует новичкам и любителям игры много работать с компьютером, потому что они еще не могут объяснить, почему именно тот-или иной ход является лучшим. Для профессионалов это не так важно, потому они могут довести позицию, полученную в результате подсказанного компьютером варианта, до победы. Но научить оценке позиции может книга или, что еще лучше – тренер, который, как правило и закладывает основы шахматного мышления. И это не заговор тренеров – шахматные движки находятся в свободном доступе, но общий шахматный уровень, несмотря на это, не растет, развитие мастерства требует кропотливой работы и большого количества практики. Трансформация знаний в умения, релевантные запросу – та сфера, где использование ИИ еще не доказало эффективности.
Известный боец, чемпион UFC Фрэнсис Нганну, несмотря на хорошую физическую подготовку и долгие тренировки, проиграл нокаутом профессиональному боксеру Энтони Джошуа уже во втором раунде, потому что это был только боксерский поединок в его жизни. Иными словами, общение с ИИ отличается от общения с человеком, хотя с каждым годом все меньше и меньше, но все еще стоит его рассматривать скорее как подготовку, а не полноценное общение.
6. Заменит ли ChatGPT переводчиков? Можно поставить вопрос так, а нужно ли вообще изучать иностранные языки, если программы могут переводить мгновенно и точно? Можем даже пренебречь впечатлениями от общения, ведь возможность понимать сразу, что вам сказали, не сравнить с получением ответа от машины.
Видится, что там, где уровень разговора превышает повседневный, нейросети еще не скоро заменят людей. Ведь с нейросетей, в отличие от переводчиков, нельзя «спросить» за ошибку; можно спросить с их разработчиков, но вариативность человеческого языка пока что так велика, что ошибки будут возникать и дальше.
Налаживанию международных отношений нейросети не способствуют, художественную и техническую литературу (например, чертежи самолетов, на которых вы будете летать) переводить могут только с помощью людей – за машинами нужен глаз да глаз. Можно вспомнить курьез, связанный с продажей на Amazon написанный ИИ книг про собирание грибов. Нейросеть рекомендовала «идентифицировать грибы путем пробования их на вкус», более того – считала бледную поганку неплохим вариантом для перекуса.
Справедливости ради, сейчас уже не удается убедить ChatGPT в том, что можно есть мухоморы и поганки.
Chat GPT предупреждает об опасности, но при этом знает, что есть некий вид мухоморов-шампиньонов, из которых все-таки можно приготовить гарнир. Но мне пришлось задействовать другие источники, чтобы убедиться в этом наверняка
7. Совсем не обязательно возможность узнать информацию быстро хороша для обучения. По этой теме уже был интересный пост на Habr «Чего нас лишит нейросеть». Нейросеть используется для самообучения, но достаточно ли одного ответа? Когда вы ищете информация, вам приходится анализировать разные источники, смотреть, например, варианты употребления фразы, в результате информация запоминается гораздо лучше. ChatGPT тоже может создать контекст, но за адекватность фраз поручиться не может. Иными словами, возможно, что для расширения словарного запаса гораздо лучше будет потратить время на чтение статьи, нежели на чтение искусственных текстов, сгенерированных нейросетью.
Я могу сказать из своего опыта, что некоторые моменты построения предложения, даже некоторые слова вполне возможно проигнорировать, перевести их согласно языковой догадке. Вы можете перевести каждое слово, спросить у нейросети нюансы каждой грамматической конструкции, но не всегда это нужно знать на начальных уровнях – гораздо важнее тренировать навык (например, произносить целую фразу из диалога, не вдаваясь в принципы ее построения), поэтому может, как это часто бывает в современном мире, произойти перегруз информацией, что приведет к замедлению прогресса в изучении языка.
8. Как должна выглядеть программа для обучения английскому языку? Сейчас ChatGPT, если проводить аналогии – очень образованный и вежливый носитель английского языка, который, однако, не может следовать никакой системе. Практика английского с настоящим человеком гораздо увлекательнее, и для этого не нужно больших денег – уроки с носителями на сервисах типа Italki начинаются от 5$, а в приложении Tandem можно практиковать английский с иностранцами бесплатно.
Если мы возьмем учебник английского языка, то в нем будут упражнения для улучшения пассивных навыков (Reading, Listening) и активных (Writing, Speaking). Очевидно, что если мы хотим по максимуму устранить учителя из учебного процесса, то ChatGPT должен выполнять все его функции, а именно, идти по программе урока, задавать вопросы и обеспечивать фидбек. К каждому учебному пособию прилагается книга для учителя, в которой даются инструкции и дополнительные упражнения/сценарии, возможные варианты ответов. Так, необходимо убедиться, что студенты понимают задание, уточнять заранее, понятна ли лексика и помнят ли они ранее выученный материал. По объему инструкции иногда могут быть длиннее, чем сам материал из соответствующего объема учебника. Для качественного обучения приложению нужна хорошая база данных по уровню изучаемого языка, оно должно помнить контекст (насколько я понимаю, сейчас память у ChatGPT не бесконечна), чтобы не спрашивать очевидные вещи снова и снова. Иными словами, нейросеть должна быть специализированной, с вшитой, проверенной программой обучения иностранному языку, потому что то, что есть сейчас в контексте изучения английского – это быстрый поисковик который ищет за вас. В создании такой программы должны участвовать лингвисты и учителя.
Несмотря на минусы, очевидно, что ChatGPT является неплохим подспорьем в изучении языка, причем, чем выше ваш уровень – тем больше вы потенциально сможете выжать из программы.
Кроме отмеченных ограничений в оценке качества произношения, все другие аспекты могут быть проработаны, при условии, если у вас уже есть база языка и вы знаете свои слабые стороны и конечную цель, например, подготовку к экзамену. Но пока оценивать экзамены будут люди, то видится, что и в подготовке к экзаменам должны участвовать тоже люди, потому что пока что у нас с машинами разные ценности.
Привет, Пикабу! Меня зовут Александр Троицкий, я автор канала AI для чайников, и я продолжаю серию коротких статей по метрикам качества моделей для машинного обучения!
Что такое регрессия?
Задача регрессии в машинном обучении — это тип обучения в ИИ, когда модель обучается на данных с непрерывным значением, чтобы предсказывать его на основе одного или нескольких входных параметров. Отличие регрессии от задач классификации заключается в том, что регрессия предсказывает непрерывные значения (например, цену на дом, температуру, количество продаж), в то время как классификация предсказывает категориальные метки (например, да/нет, красный/синий/зеленый).
То есть задача регрессии предсказывает какую-то цифру, а задача классификации - это как выбор в тесте из нескольких вариантов ответа.
Пример
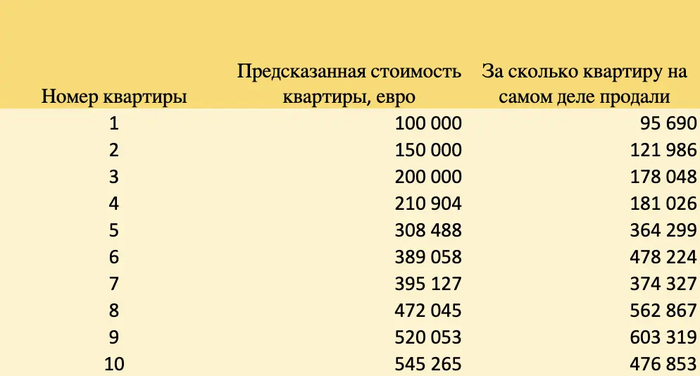
Давайте представим, что мы - доска объявлений типа Авито или Циана. Мы хотим подсказывать пользователю в интерфейсе по какой цене ему лучше разместить свою квартиру на основании множества факторов, например:
Местоположение квартиры
Площадь
Этаж
Ремонт
Год постройки здания
В итоге мы выводим пользователю рекомендуемую цифру в евро.Мы предсказали стоимость 10 квартир, а через месяц узнали за сколько их на самом деле продали.
Далее мы проведем с этими результатами нехитрые вычисления:
Вычтем из предсказанной цены реальную цену (первый столбик)
Возведем эту разницу в квадрат (второй столбик)
Возьмем корень из этого квадрата (третий столбик)
Получим следующие результаты на нашем примере:
P.S. да, можно просто взять разницу по модулю, но более умные математики говорят, что это все-таки не одно и то же - можете почитать об этом отдельно
MSE
Если мы возьмем второй столбик из зеленой таблицы выше, сложим все числа в нем, а потом поделим на количество этих чисел (возьмем среднюю), то получим MSE или среднюю квадратическую ошибку. В нашем случае:
MSE = 3353809295
Большое число! Из-за его величины оно сложно интерпретируется с точки зрения бизнеса. Чаще эту метрику используют при разработке моделей, когда важно наказывать большие ошибки сильнее, чем маленькие, так как ошибка возрастает квадратично. Это делает MSE чувствительной к выбросам. MSE используют, если большие ошибки недопустимы и должны сильно влиять на модель.
RMSE
RMSE или среднеквадратическая ошибка - это младший брат MSE. Чтобы ее посчитать нужно просто взять квадрат из MSE!
В нашем случае получится 57912.
RMSE также штрафует за большие ошибки, но в отличие от MSE, масштаб ошибки аналогичен исходным данным, что облегчает интерпретацию. Это делает RMSE хорошим выбором для многих практических задач, где важна интерпретируемость результата.
MAE
MAE или средняя абсолютная ошибка считается по третьем столбику из зеленой таблички выше. Нужно взять сумму корней из квадрата разницы между предсказанной ценой и реальной ценой и поделить ее на количество наблюдений. Проще говоря, берем среднее из третьего столбика.
В нашем примере MAE = 49243
MAE менее чувствительна к выбросам по сравнению с MSE и RMSE. Это делает её предпочтительным вариантом, когда выбросы присутствуют в данных, но не должны сильно влиять на общую производительность модели.
Немного усложним нашу зеленую табличку
Чтобы разобраться с тем как считается R-квадрат и MAPE нужно дополнить нашу зеленую табличку еще двумя стобиками:
Вычтем из предсказанной цены среднюю предсказанную цену и возведем это в квадрат (четвертый зеленый столбик 4). P.S. Не спрашивайте зачем это нужно и какой в этом практический смысл - просто сделайте :)
Поделим третий зеленый столбик на предсказанную цену квартиру из желтой таблички. То есть поделим разницу между предсказанной и реальной ценой квартиры по модулю на предсказанную стоимость квартиры. (пятый зеленый столбик)
Коэффициент детерминации (R квадрат)
Чтобы его получить надо из единицы вычесть разницу суммы второго и четвертого зеленых столбцов.
R-квадрат измеряет, какая доля вариативности зависимой переменной объясняется независимыми переменными в модели. Это хороший способ оценить адекватность модели: близость к 1 говорит о хорошем объяснении данных моделью. R-квадрат лучше всего подходит для сравнения моделей с одинаковыми данными.
MAPE
Средняя абсолютная процентная ошибка или MAPE - это среднее пятого зеленого столбца.
В нашем случае = 14,2%
MAPE измеряет отклонение прогнозов от фактических значений в процентах и является хорошим выбором, когда нужно легко интерпретируемое показание ошибки в процентном отношении. Однако MAPE может быть неэффективной, когда в данных присутствуют нулевые или очень маленькие значения.
Excel файл с примерами
Вы можете найти эксель файл с этими цифрами, бесплатно его скачать и собственноручно поиграться со значениями в нем вот в этом посте в моем телеграмм канале
Заключение
Поздравляю! Вы узнали про основные метрики в задачах регрессии!
Если вам интересно знать про ИИ и машинное обучение больше, чем рядовой человек, но меньше, чем data scientist, то подписывайтесь на мой канал в Телеграм. Я пишу редко, но по делу: AI для чайников. Подписывайтесь!
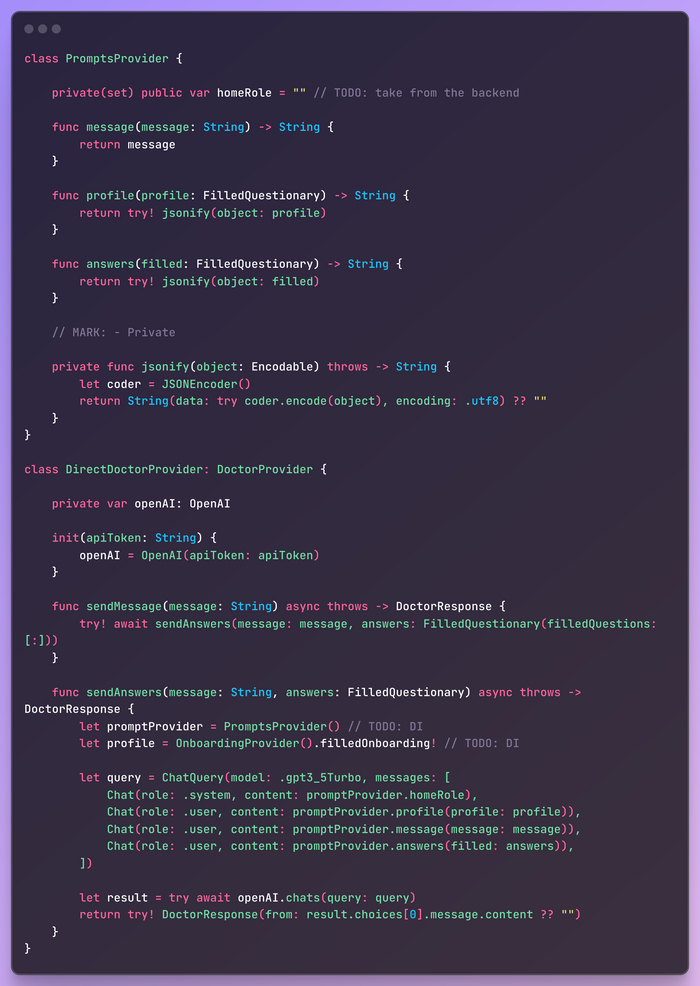
В этой статье мы рассмотрим все тонкости создания Proof of Concept (PoC) мобильного приложения, построенного с помощью фреймворка SwiftUI и бэкенда с использованием FastAPI. Дополнительно я продемонстрирую эффективные архитектурные паттерны для SwiftUI-приложений, в частности MVVMP в сочетании с принципами SOLID и Dependency Injection (DI). Для android код можно легко перевести на Kotlin с Jetpack Compose.
Зачем нам нужен бэкенд
Кто-то может сказать, что можно просто запихнуть всю логику в приложение, напрямую отправлять запросы в chatgpt и сделать приложение без бэкенда. И я согласен, это действительно возможно, но бэкенд дает несколько важных преимуществ.
Бэкенд служит основой для любого сложного приложения, особенно для тех, которые требуют безопасного управления данными, обработки бизнес-логики и интеграции сервисов. Вот почему надежный бэкэнд имеет решающее значение:
Безопасность: Бэкэнд помогает защитить конфиденциальные данные и токены аутентификации пользователей от атак типа MITM (Man-in-the-Middle). Он выступает в качестве защищенного шлюза между пользовательским устройством и базой данных или внешними службами, обеспечивая шифрование и аутентификацию всех данных.
Контроль над использованием сервисов: Управляя API и взаимодействием с пользователями через бэкэнд, вы можете отслеживать и контролировать использование приложения. Это включает в себя дросселирование для управления нагрузкой, предотвращение злоупотреблений и обеспечение эффективного использования ресурсов.
Интеграция с базой данных: Бэкэнд обеспечивает бесшовную интеграцию с базами данных, позволяя динамически хранить, извлекать и обновлять данные в режиме реального времени. Это важно для приложений, которые требуют учетных записей пользователей, хранят их предпочтения или нуждаются в быстром и безопасном получении больших объемов данных.
Модели подписки и Freemium: Реализация услуг по подписке или модели freemium требует наличия бэкенда для выставления счетов, отслеживания использования и управления уровнями пользователей. Бэкэнд может безопасно обрабатывать платежи и подписки, обеспечивая бесперебойную работу пользователей и соблюдая требования по защите данных.
Масштабируемость и обслуживание: Бэкэнд позволяет более эффективно масштабировать приложение. Логику на стороне сервера можно обновлять без необходимости передавать обновления клиенту, что упрощает обслуживание и ускоряет внедрение новых функций.
По сути, бэкенд — это не только функциональность, но и создание безопасной, масштабируемой и устойчивой среды для процветания вашего приложения.
Объяснение технического стека
SwiftUI: Лучший вариант для нативных приложений для iOS после выхода UIKit. Он декларативен и упорядочен, а XCode является незаменимым редактором благодаря эпл. Для android код можно легко перевести на Kotlin с помощью Jetpack Compose.
FastAPI: Выбран для бэкенда за его скорость, минимальное количество шаблонов и декларативность, редактируется с помощью превосходного Zed.dev.
ChatGPT API: Используется в качестве большой языковой модели (LLM); выбор может меняться в зависимости от необходимости кастомизации.
Ngrok: Реализует туннелирование с помощью простой команды CLI для выхода локального сервера в интернет.
Создание приложения для iOS
Теория: Архитектурные паттерны
MVVMP (Model View ViewModel Presenter):
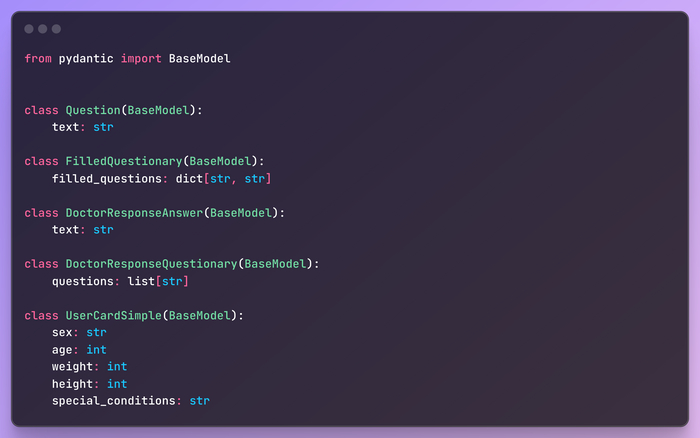
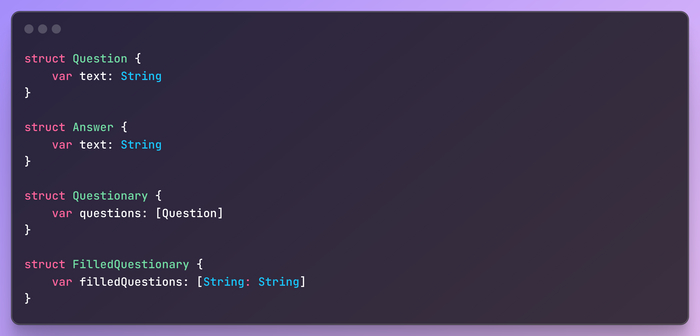
Model: Представляет собой структуры данных, используемые в приложении, такие как Question, Answer, Questionary и FilledQuestionary. Эти модели просты и содержат только данные, следуя принципу KISS.
View: Отвечают только за представление пользовательского интерфейса и делегируют все данные и логику презентерам. Они не содержат никакой бизнес-логики и спроектированы так, чтобы быть простыми и сосредоточенными на рендере UI.
ViewModel: В SwiftUI ViewModel представлена объектом ObservableObject, который служит моделью наблюдения за изменяемыми данными. Здесь нет методов и логики.
Presenter: Presenter управляет всей логикой, связанной с модулем (экраном или представлением), но не бизнес-логикой. Он взаимодействует с доменным слоем для выполнения операций бизнес-логики, таких как взаимодействие с API или управление сохранением данных.
Domain Layer: Этот слой содержит бизнес-логику приложения и взаимодействует с внешними ресурсами, такими как базы данных, API или другие сервисы. Он состоит из нескольких компонентов, таких как сервисы, провайдеры, менеджеры, репозитории, мапперы, фабрики и т. д.
На самом деле, MP в MVVMP является инициалами Марка Паркера, а полная форма — «Model View ViewModel by Mark Parker».
Принципы СОЛИД:
Принцип единой ответственности: У каждого класса должна быть только одна причина для изменений.
Принцип открытость-закрытость: Компоненты должны быть открыты для расширения, но закрыты для модификации.
Принцип замещения Лискова: Объекты суперкласса должны быть заменяемы объектами подклассов.
Принцип разделения интерфейсов: Ни один клиент не должен быть вынужден зависеть от интерфейсов, которые он не использует.
Принцип инверсии зависимостей: Зависимость от абстракций, а не от конкретики, чему способствует DI.
Инъекция зависимостей (DI): Реализация с использованием DI-контейнера для соблюдения принципа инверсии зависимостей.
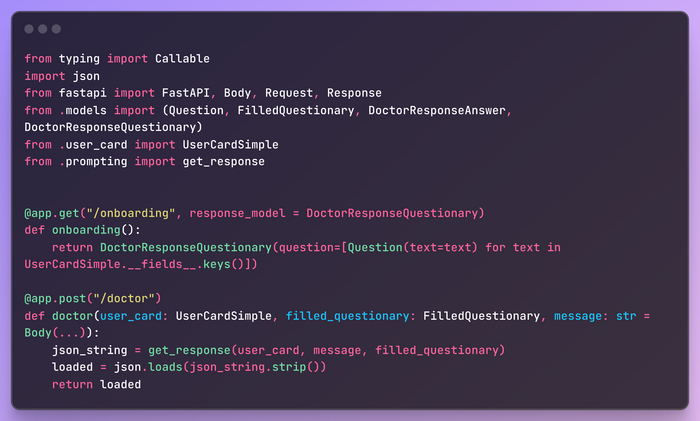
"onboarding" предоставляет список вопросов анамнеза, которые необходимо заполнить при первом запуске приложения. Ответы будут сохранены на устройстве и использованы для персонализированной диагностики в будущем. "doctor" — основной эндпоинт: он генерирует вопросы на основе предыдущих ответов и карты пользователя, либо возвращает результат диагностики.
Модели:
Промпты:
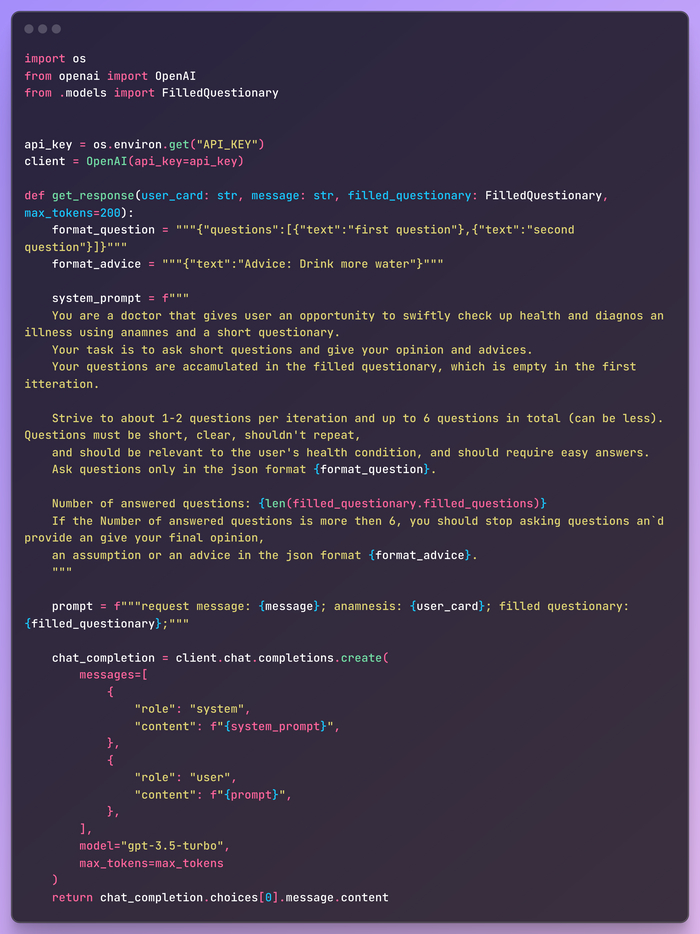
Модуль промптов использует GPT-3.5 от OpenAI для генерации ответов на основе пользовательского ввода, анамнеза и заполненных анкет. Он возвращает пользователю соответствующие вопросы и советы по диагностике здоровья. Как видите, ничего сложного здесь нет. Код элементарен, а промпты - просто набор четких инструкций для LLM.
Настройте окружение и запустите сервер с помощью fastapi dev main.py.
Я не буду показывать здесь весь исходный код, для этого есть GitHub. Найти его можно по адресу: HouseMDAI iOS App. Вместо этого я остановлюсь только на важных (IMO) моментах.
Начнем с краткого описания задачи: нам нужно приложение с текстовым полем на главном экране, возможностью задавать набор динамических вопросов и показывать ответ. Также нам нужен одноразовый онбординг. Итак, приступим к коду.
Первым делом нам нужны модели, и они довольно просты (принцип KISS).
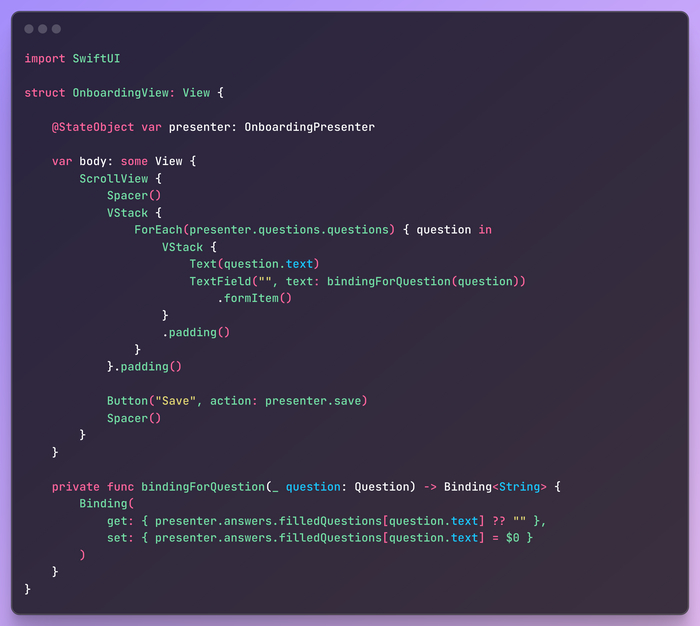
Теперь давайте сделаем онбординг. Продолжаем следовать KISS и SRP (Single Responsibility Principle), никакой бизнес-логики в представлениях, только UI. В данном случае - только список вопросов с прокруткой. Все данные и логика делегированы презентеру. Единственное, что здесь интересно, это небольшой вспомогательный метод bindingForQuestion, который, вероятно, должен быть в презентере, но сейчас это не имеет значения.
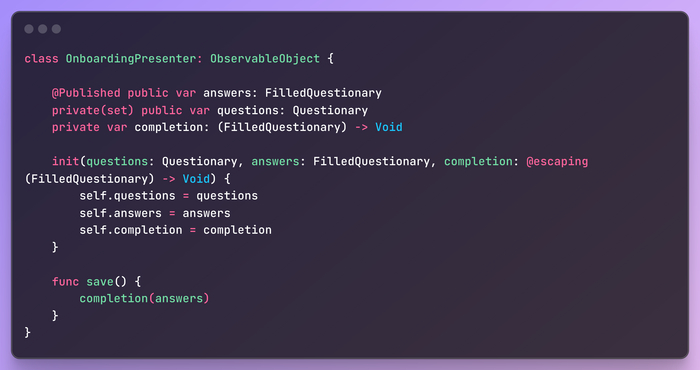
Вы будете удивлены, но в презентере также нет никакой бизнес-логики!
Все по-прежнему simple, stupid и имеет только одну ответственность. Presenter должен содержать только логику своего представления. Бизнес-логика уровня приложения находится вне его юрисдикции, поэтому презентер просто делегирует ее наверх по стэку вызова.
Также можно заметить, что и View, и Presenter не инстанцируют ни одну из зависимостей, а получают их в качестве параметров при инициализации. Это соответствует принципу инверсии зависимостей, согласно которому модули высокого уровня не должны зависеть от модулей низкого уровня, но оба должны зависеть от абстракций. Это обеспечивает гибкость и упрощает тестирование, а также позволяет легко заменять зависимости или внедрять макеты для целей тестирования.
При использовании паттерна Dependency Injection зависимости предоставляются извне класса, а не инстанцируются внутри него. Это способствует развязке и позволяет упростить поддержку и тестирование кода.
Хотя в данном примере протоколы не используются явно, стоит отметить, что протоколы могут играть важную роль в коде, особенно для абстрагирования и облегчения тестирования. Определив протоколы для представлений, презентаторов и зависимостей, становится проще заменять реализации или предоставлять моки во время тестирования.
Если вы рассматриваете возможность использования протоколов в представлениях SwiftUI, необходимо помнить об одном важном моменте. Поскольку View в SwiftUI - это структура, она требует явного указания типов своих свойств. Это означает, что вам придется сделать её дженериком и пробрасывать тип через весь стек вызовов, что приведет к появлению большого количества шаблонного кода.
Однако существует альтернативный подход, предлагаемый MarkParker5/AnyObservableObject. Эта библиотека работает аналогично родным оберткам свойств SwiftUI, но убирает проверку типа во время компиляции в пользу проверки во время рантайма. Хотя такой подход может внести некоторые риски, их легко снизить, написав элементарные xcode тесты, которые просто инициализируют представления так же, как вы делаете это во время рантайма.
Используя эту альтернативу, вы можете упростить свой код и оптимизировать процесс работы с протоколами в SwiftUI.
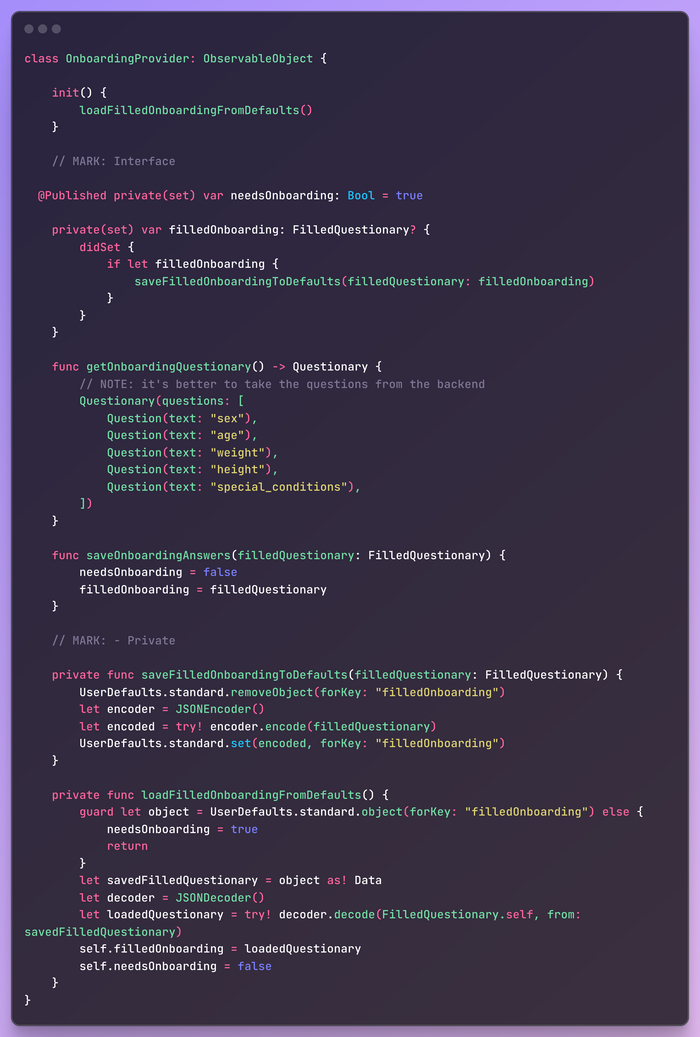
Итак, если презентер не содержит бизнес-логику, то где же она? Это задача для доменного слоя, который обычно содержит сервисы, провайдеры и менеджеры. У них всех очень схожее применение, и разница между ними до сих пор является предметом дискуссий. Давайте создадим OnboardingProvider, который будет содержать всю бизнес-логику процесса онбординга.
Опять же, он выполняет только одну задачу: управление бизнес-логикой процесса onboarding. Такая инкапсуляция позволяет другим классам взаимодействовать с ним без необходимости беспокоиться о деталях его внутренней реализации, что способствует созданию более чистой и удобной кодовой базы.
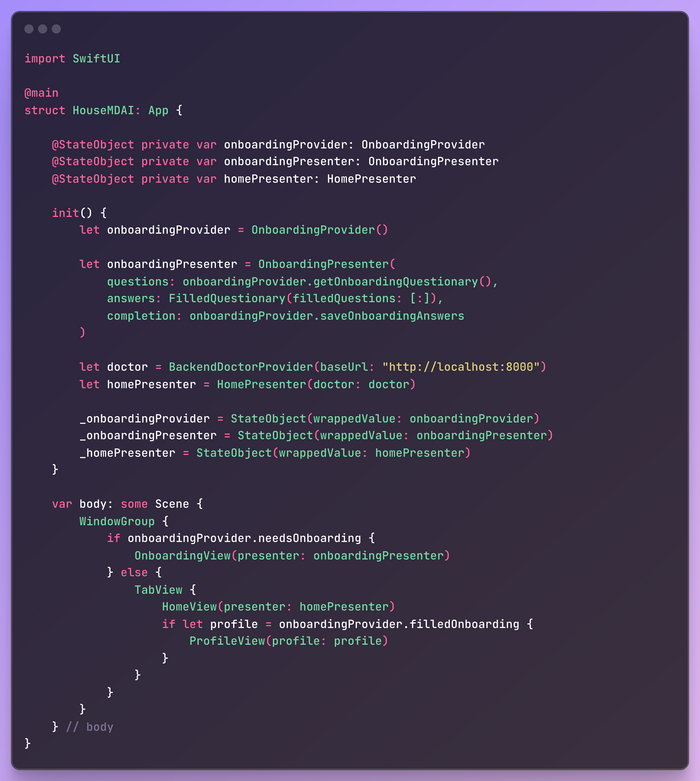
Теперь давайте соберем все вместе в корне приложения.
Это приложение SwiftUI устанавливает свое начальное состояние с помощью оберток полей StateObject. Оно инициализирует OnboardingProvider, OnboardingPresenter и HomePresenter в своем методе init. Провайдер OnboardingProvider отвечает за управление данными, связанными с онбордингом, а OnboardingPresenter управляет логикой представления онбординга. HomePresenter управляет главным домашним представлением.
В теле сцены приложения проверяется, нужна ли регистрация на сайте. Если да, то она представляет OnboardingView с OnboardingPresenter. В противном случае она представляет TabView, содержащий HomeView с HomePresenter и, если доступно, ProfileView.
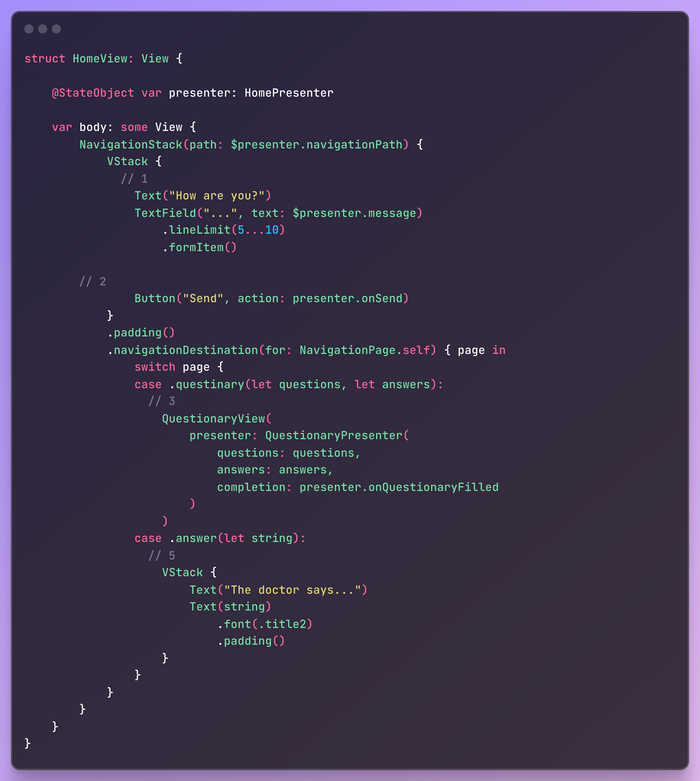
Теперь настало время для домашнего экрана. Логика проста:
Получаем сообщение от пользователя
Используя сообщение, запрашиваем список вопросов из бэкенда
Показываем вопросы по одному, используя встроенную push-навигацию.
Добавляем ответы к запросу и повторяем 2-4, пока бэкенд-доктор не вернет окончательный результат
Показываем финальный результат
Похоже, я пропустил 4-й пункт... или нет? Поскольку представление не может содержать никакой логики, эту часть выполняет его презентер.
Он управляет вводом сообщения пользователем и обновляет путь навигации на основе ответов от бэкенда.
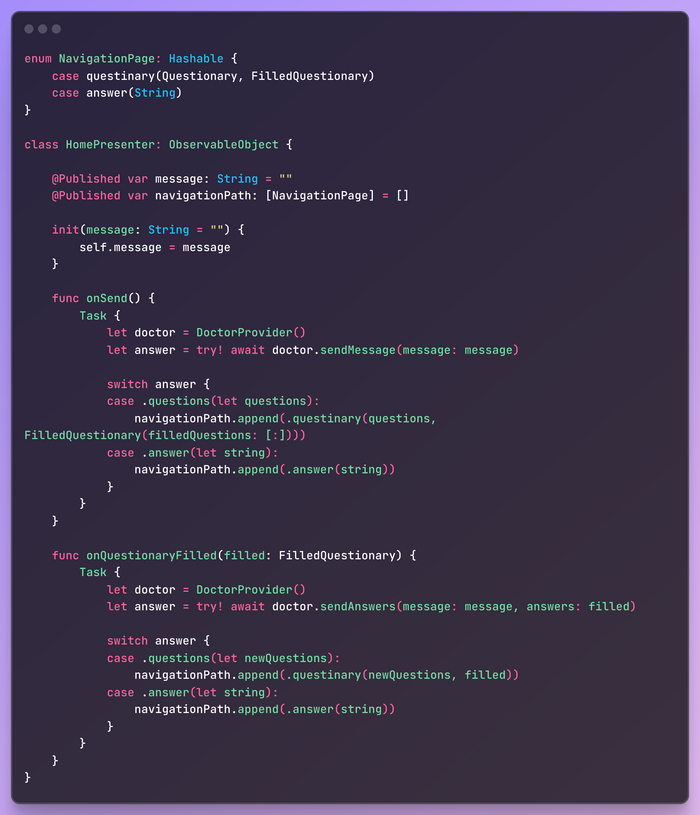
При отправке сообщения метод onSend() отправляет его на бэкенд с помощью DoctorProvider и ожидает ответа. В зависимости от типа ответа он обновляет навигационный путь, отображая либо набор вопросов, либо окончательный ответ.
Аналогично, когда заполняется вопросник, метод onQuestionaryFilled() отправляет заполненный вопросник на бэкенд и соответствующим образом обновляет путь навигации.
Здесь есть небольшое дублирование кода между методами onSend() и onQuestionaryFilled(), которое можно было бы отрефакторизовать в один метод для обработки обоих случаев. Однако оставим это как упражнение для дальнейшей доработки.
Модуль Questionary (View+Presenter) почти является копией Onboarding и просто делегирует логику до HomePresenter, поэтому я не вижу необходимости показывать код. Опять же, для этого есть github.
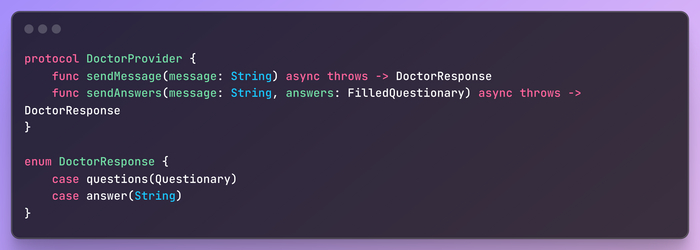
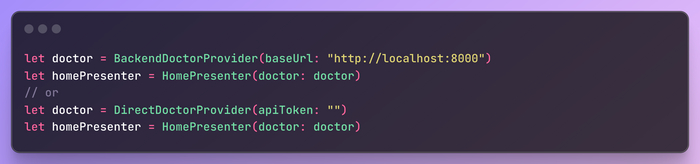
Последнее, что я хочу показать, это две реализации DoctorProvider, единственной обязанностью которых является вызов API и возврат DoctorResponse.
Первая использует наш бэкенд:
Вторая вызывает openai api напрямую (подход backendless) и является практически копией модуля подсказок из бэкенда:
Обе реализации легко взаимозаменяются благодаря инъекции зависимостей:
Интегрируйте аутентификацию и базу данных пользователей в бэкенд. Можете использовать официальный шаблон FastAPI из FastAPI Project Generation.
Реализуйте логику аутентификации в приложении.
Сосредоточьтесь на улучшении дизайна приложения, чтобы повысить удобство работы с ним. Давайте создавать красивые приложения!
Заключение
Приведенные проекты и ссылки на код служат реальными примерами, чтобы дать толчок вашей собственной разработке. Помните, что красота технологии заключается в итерациях. Начните с простого, создайте прототип и постоянно совершенствуйте его. Каждый шаг вперед приближает вас к овладению искусством разработки программного обеспечения и, возможно, к следующему большому прорыву в технологиях. Счастливого кодинга!
О других интересных проектах периодически пишу в телеграм.
Эта статья является продолжением прошлой статьи, уделяя больше внимания итоговому продукту, а не самому процессу хакатона.
Когда вы создаете ИИ-продукт о здоровье, всегда возникает вопрос этики, точности, ответственности и доверия. Именно поэтому важно разделять продукты для здорового образа жизни и настоящие медицинские продукты. Мы долго думали над тем, где проходит грань между ними и насколько близко мы можем к ней подойти. Это сложный вопрос, но мы нашли решение: создать два самостоятельных продукта, которые находятся далеко от этой черты, но по разные стороны.
«Лучший друг»
Первый — о здоровом образе жизни. Это ваш виртуальный лучший друг, и даже больше: помощник, тренер, мотиватор, иногда даже мама или мини-психолог. Собирая важную информацию о вас в чате и имея в памяти ваш анамнез, биографию и историю, лучший друг может просто слушать, как вы проводите день, комментировать его, помогать вам повседневными советами и рекомендациями или даже помогать вам двигаться к вашим целям и мечтам, используя индивидуальную мотивацию, человеческое сочувствие и понимание ваших чувств.
«Доктор Хаус»
Проблема
Второй продукт уже по-настоящему медицинский. Начнем с проблемы:
Сложность самого процесса диагностики из-за сложного строения человеческого организма и огромного количества возможных случаев, которые не всегда могут быть полностью вылечены врачом
Перегруженность систем здравоохранения и специалистов
Неэффективная и несвоевременная диагностика в здравоохранении, приводящая к ухудшению состояния пациентов.
Проблемы доступности для удаленных или малообслуживаемых групп населения
Нежелание людей посещать больницы, страх перед врачами.
Диагностика — это важно
Почему диагностика так важна? Эйнштейн сказал: «Если бы у меня был час на решение проблемы, я бы потратил 55 минут на обдумывание проблемы и пять минут — на поиск решений». Подготовка имеет огромное значение для решения проблем. То же самое верно и в медицине. Профессионалы говорят: правильный диагноз — это ~70% исцеления. И мы считаем, что можем улучшить 70 % современной медицины с помощью одного приложения.
Внедрение
Познакомьтесь с Dr. House — ИИ-диагностом в вашем телефоне. Мобильное приложение, которое за считанные минуты ставит диагноз.
Как мы собираемся этого добиться? С начала времен и по сей день мы считаем, что лучший способ коммуникации — это речь. Если вы хотите что-то узнать — задавайте вопросы. Задавая вопросы, я имею в виду задавать правильные вопросы. Итак, мы собираемся создать приложение, которое будет иметь полный анамнез вашего заболевания и задавать корректные персонализированные вопросы, и на основе ответов предлагать возможные диагнозы. Звучит довольно просто, но полезно, не так ли? И уж точно лучше, чем гуглить свои симптомы (у меня каждый раз рак).
И это помогает не только обычным людям. Врачи тоже могут использовать это для перепроверки, второго мнения или предварительного прогноза, например, в машине скорой помощи.
Кроме того, когда доктор Хаус рекомендует посетить больницу, процесс значительно ускорится, потому что в приложении уже есть полный анамнез, история болезни и заполненная анкета, так что и клиенту, и врачу нужно потратить значительно меньше времени. И это же приложение можно использовать в качестве карты экстренной помощи, если пользователь находится «вне сети».
Можно ли сделать лучше?
Можно ли сделать еще лучше? Мы говорим "да"! Как? Интеграции! Приложение может учитывать информацию из Apple HealthKit и медицинских устройств. Или наоборот, API может передавать данные в больницу (и обратно) даже без прямого контакта с человеком.
Если приложение будет следить за состоянием здоровья человека, это значит, что его можно будет отправить домой из больницы гораздо раньше и освободить место для того, кто в этом больше нуждается. Врачи будут следить за состоянием здоровья удаленно, а приложение уведомит их, если что-то не так.
Заключение
Как я уже писал, к сожалению, у нашей команды нет возможности работать над этим проектом фулл-тайм, поэтому мы опубликовали все результаты нашей работы в открытый доступ. Слайды вы можете найти здесь (написан по памяти неделю спустя). Полную информацию о проекте, включая все заметки и исходный код, можно найти на GitHub.
10 новых российских проектов для учета рабочего времени, контроля офисных помещений, удобного прослушивания аудио-книг, монетизации инструментальной музыки и многого другого. Битва за «Продукт недели» началась!
Product Radar — здесь каждую неделю публикуются лучшие онлайн-сервисы и железки от русскоязычных команд.
Это площадка, где энтузиасты из мира технологий делятся своими идеями, обсуждают и создают вместе новые продукты, чтобы делать жизнь людей лучше.
SaaS-платформа для полной автоматизации первой линии продаж
Участники 33-ого набора Product Radar
3 – 9 июня 2024 года
Читайте описания, кликайте на название проекта, голосуйте и комментируйте его на Радаре. Ваша поддержка очень важна основателям! 💙
Chrony
Ваш помощник для Google Календаря: создавайте и редактируйте события через текст, голос и фото.
Решаемая проблема: Люди тратят много времени на формирование расписания и забывают важные события. Google Календарь неудобен, поэтому многие предпочитают использовать заметки или избранное в Telegram.
Telegram Mini App для создания набросков, диаграмм и визуализаций.
Решаемая проблема: Телеграм-чаты часто используются для обсуждений, но ограничены в возможностях визуализации идей. Boardgram позволяет создавать наглядные схемы прямо в чате, облегчая понимание сложных концепций.
Облачная платформа с ИИ для контроля чистоты офисных помещений, мониторинга персонала и охраны.
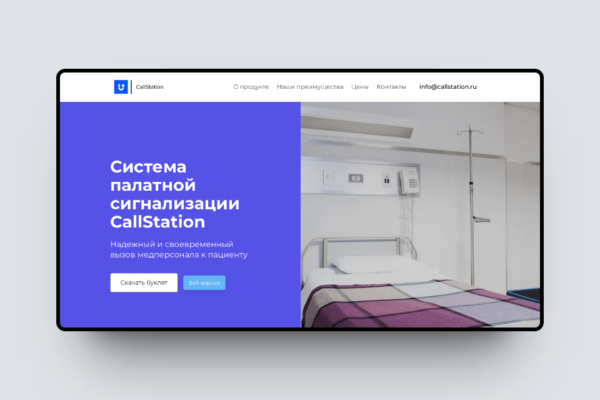
Решаемая проблема: Отсутствие удобного и комплексного решения для управления коворкингами и гибкими офисами на базе ИИ технологий является барьером для эффективного функционирования современных рабочих пространств.
Сервис сверхбыстрой и точной транскрибации с помощью ИИ.
Решаемая проблема: Обработка аудио в текст для многих специалистов – трудоемкий и затратный процесс. Ручная транскрибация занимает много времени и денег, а использование нейросетей зачастую сложный процесс.
Превращает Google Таблицы в реляционную базу данных. Аналог Lookup из Airtable и JOIN из MySQL.
Решаемая проблема: Данные хранятся на разных страницах, отсутствуют нормальные связи и простая возможность отображать связанные данные в соседних страницах.
Решаемая проблема: Высокая стоимость и длительные сроки разработки веб-приложений с нуля, а также изобилие на рынке решений с некачественным кодом, уязвимостями безопасности и ограниченной функциональностью.
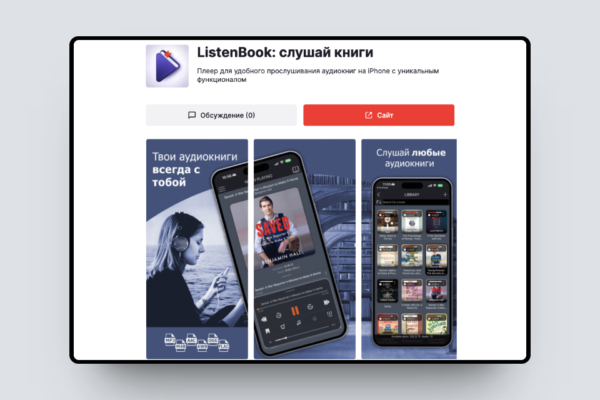
Плеер для удобного прослушивания аудиокниг на iPhone с уникальным функционалом.
Решаемая проблема: Прослушивание аудиокниг скачаных из различных источников в различных аудиоформатах. Простое добавление аудиокниг в приложение для прослушивания.
3 июня 2024 на сайте Product Radar были опубликованы свежие 10 проектов, которые поборются за ТОП-3 места по итогам недели. Победители получат значки «Продукт дня №1, 2, 3», а также отдельные посты в тг-канале Радара.
«Продукт недели № 1» получает грант от Yandex Cloud, а топ-3 продукта получают грант от Unisender в виде месячного тарифа и сопровождения по email-маркетингу.
Следующий «набор» появится на сайте через неделю, вы еще можете поучаствовать в нем или выбрать другую дату для размещения. Заполняйте заявку сейчас.
Поддержите проекты из подборки
Лайкните этот пост и поделитесь ссылкой на сайт Product Radar с друзьями и коллегами, чтобы как можно больше людей узнало о классных продуктах от русскоязычных команд!
Такую задачу поставил Little.Bit пикабушникам. И на его призыв откликнулись PILOTMISHA, MorGott и Lei Radna. Поэтому теперь вы знаете, как сделать игру, скрафтить косплей, написать историю и посадить самолет. А если еще не знаете, то смотрите и учитесь.