Когда читаешь новости о выпуске очередного чипсета для мобильного телефона, обязательно видишь описание его возможности работы с нейросетевыми алгоритмами. В чипсетах создают специальные вычислительные блоки, которые эффективно способны работать именно с алгоритмами ИИ.
Но когда покупаешь телефон, в котором стоит чип, который умеет работать с алгоритмами ИИ, далеко не всегда видишь результат этой работы.
Зачастую в это вносят вклад маркетологи. Учитывая большое количество моделей, которое выпускает Xiaomi под своим брендом, а также под суббрендами Redmi и POCO не удивительно, что они искусственно отключают встроенные возможности, которые можно отнести к более дорогим моделям в более доступных.
Сегодня я покажу, как легко и непринуждённо вернуть 3 настройки обработки фото и видео на смартфонах Xiaomi, Redmi или POCO, которые работают на базе ИИ, но отключены во многих моделях.
Внимание: возможность включить алгоритмы ИИ определяется аппаратной возможностью чипсета вашего телефона. Если он не поддерживает эти функции, включить их не получится.
Как вернуть 3 настройки обработки фото и видео с помощью ИИ
Текстовая инструкция:
Установите приложение "Activity Launcher". Раньше оно было доступно в Google Play, сейчас его то ли удалили, то ли переименовали, не знаю. Я выложил его в ТГ - Activity Launcher в виде APK. Проверил, ни вирусов, ни другой ерунды в нём нет.
Запускаете приложение, в строке поиска вводите слово "Display".
Листаете поисковую выдачу вниз до раздела "Настройки".
Теперь ищите строки: "HDR-улучшение с ИИ", "MEMC" и "Улучшение изображений с ИИ". Если чипсет вашего смартфона поддерживает эти технологии, их возможно включить. Если этих настроек нет, значит ваш телефон эти технологии не поддерживает.
Надеюсь, использовать смартфон с дополнительными ИИ-алгоритмами стало приятнее.
Если по необычайному стечению обстоятельств вам стало любопытно, есть ли ещё подобные лайфхаки для смартфонов Xiaomi - добро пожаловать на MetaMi.
Для кого-то это умение колонки Алисы выбирать любимую музыку, для других — способность чата GPT помочь в написании курсовых работ, а для третьих — персонажи и боты в видеоиграх.
Тем не менее, современные технологии искусственного интеллекта (ИИ) активно внедряются в повседневную жизнь, в офисах и на производстве. Например, американская компания Amazon применяет искусственный интеллект для улучшения работы своих роботизированных складов, оптимизации процесса доставки заказов, персонализации рекомендаций покупателям и других задач.
Мы с подругой из Высшей школы экономики решили провести исследование по этой теме с целью улучшения рабочего процесса сотрудников.
Наш подход основан на опроснике, содержащем вопросы об использовании ИИ и уровне удовлетворенности сотрудников, чтобы выявить возможные взаимосвязи. Заполнение опросника займет всего 5 минут, и мы будем рады вашему участию)
Всё больше в жизнь проникают нейросети, как в виде чат-ботов, так и в виде алгоритмов, которые работают в привычных нам приложениях.
Не всегда мы можем повлиять на то, как используются данные, которые обрабатываются нейросетями.
Некоторые работают локально, но очень много людей используют облачные сервисы, основанные на Ai.
Особенность нейросетей заключается в том, что для того, чтобы они оставались конкурентоспособными их должны постоянно тренировать и дообучать. Иначе они очень быстро отстанут от конкурентов.
Легче всего брать данные для дообучения из результатов беседы нейросети с людьми.
Уверен, не все люди горят желанием отдавать свои личные данные крупным корпорациям, да ещё бесплатно.
Ладно ещё, если вы спрашивали у ChatGPT какой-то рецепт блюда, или как заменить масло в двигателе автомобиля. Но не забывайте, что ChatGPT способен анализировать фото, видео и текстовые документы. Поэтому эту нейросеть часто используют в компаниях для работы, "скармливая" Ai информацию, которая вообще не должна быть общедоступной.
Для того, чтобы данные пользователя не использовались для дальнейшего обучения ChatGPT, а также для гарантированного их удаления с серверов, есть два режима у этого чат-бота. И я покажу, как их включить.
Как включить режим инкогнито при работе с ChatGPT
Для тех, кто не хочет смотреть видео, оставлю текстовую инструкцию:
Откройте интерфейс ChatGPT в браузере
Нажмите на название "ChatGPT" в верхней части экрана
Появится меню, в котором увидите переключатель "Временный чат". Включив его вы добьётесь двух целей: беседа будет гарантированна удалена через 30 дней и данные не будут использованы для обучения алгоритмов.
Есть ещё один метод: войдите в настройки аккаунта, найдите вкладку "Элементы управления данными" и в нём отключите пункт "Улучшить модель для всех". Эта опция отвечает за разрешение использовать данных, которые вы предоставили ChatGPT для анализа, а также вашу беседу с ботом для дальнейшего обучения.
Надеюсь, вам были полезны эти знания. Теперь вы можете быть спокойны - ChatGPT не будут использовать вашу информацию для дообучения бота.
Конечно, это всё по заявлению компании OpenAI. Как дела обстоят на самом деле мы не знаем.
Если по необычайному стечению обстоятельств вам стало любопытно, есть ли ещё подобные лайфхаки для смартфонов Xiaomi - добро пожаловать на MetaMi.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
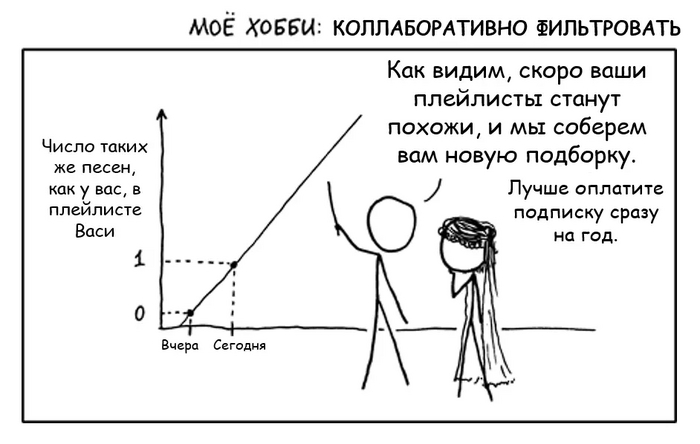
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Продолжая цикл разъяснения параметров нашей любимой нейронной сети Stable Diffusion я решил в этот раз остановиться именно на Denoising Strength, ибо он каждый раз взрывал мне бошку. В прошлый раз я разбирал CFG Scale.
На данный момент шум могут декодировать VAE (вариационные автоэнкодеры), DPM (диффузионные вероятностные модели) и Сэмплеры (специализированные решатели высокого порядка для диффузионных уравнений).
Их задача сводится к тому, чтобы за определенное количество шагов генерации или Sampling steps из полного шума достать четкое изображение, к тому же сформированное по текстовой или визуальной подсказке (другой картинке).
В 2022 году был изобретен и адаптирован под диффузионные нейронные сети сэмплер DPM Solver, который значительно ускорил процесс декодирования шума. С момента его появления начали появляться, DPM Solver++, DPM ++ SDE Karras, DPM++ 2M Karras и другие, которые отличаются лишь методом решения дифференциальных уравнений (ими и убирается шум).
По итогу: чем быстрее вы решаете уравнение, тем меньше времени требуется для денойзинга картинки. И тут приходится балансировать между точностью и скоростью.
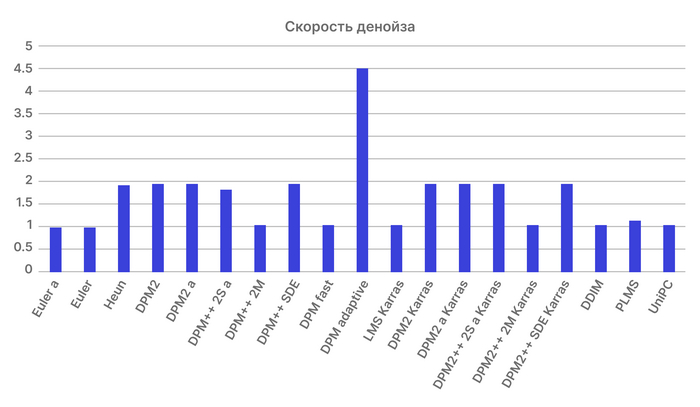
На картинке выше вы можете посмотреть скорость работы различных сэмплеров. DPM Adaptive вышел в топы по медлительности потому, что сам определяет количество шагов генерации, что значительно повышает его точность в зависимости от конкретного запроса.
Как работает параметр Denoising strength?
Если нужна научная статья со всей математикой, то рекомендую прочитать данный материал.
Этот параметр мы будем рассматривать в режиме работы img2img, где он нужен для того, чтобы определять, насколько будет преобразовано исходное изображение во что-то новое.
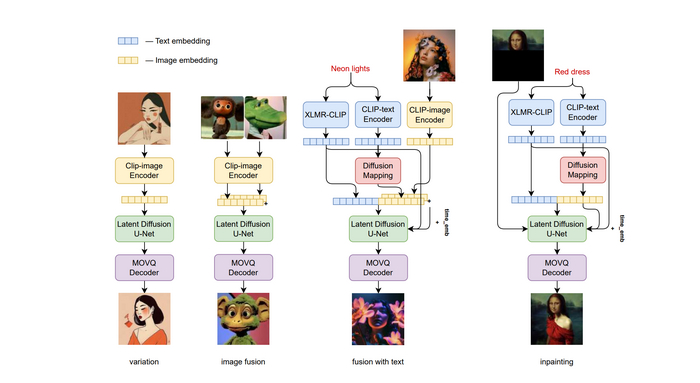
Сейчас коротко залезем в изнанку того, за счет чего вообще происходит генерация img2img и Inpaint.
Обратите внимание на самую правую колонку с Мона Лизой, разберем ее. Во-первых, для создания изображения используется не только текстовые эмбеддинги (зашифрованный текст), но и визуальные эмбеддинги (зашифрованные картинки), плюс учитывается исходник (Мона Лиза).
Т.е. нейросеть не просто накладывает поверх изображения шум и рисует что-то поверх, а полностью с нуля генерирует изображение, предварительно размазывая его с заданной силой.
И чем больше Denoising strength, тем с большей силой нейросеть может опираться не на исходник, а на внутренние эмбеддинги (зашифрованные в ней текст и картинки). А понижением денойза мы обрубаем эти эмбеддинги и не позволяем нейронке работать с шумом.
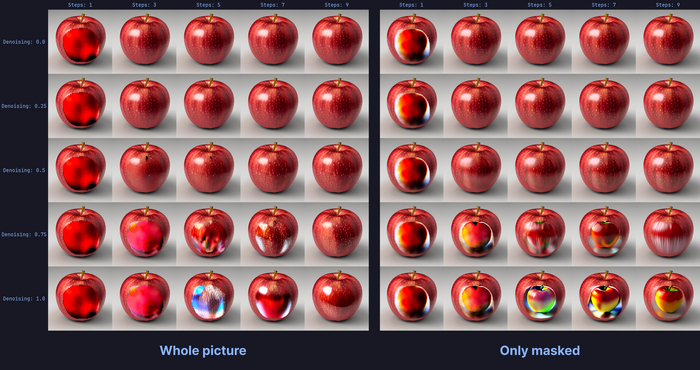
Выше представлено наглядное доказательство того, что модель Stable Diffusion учитывает исходник и генерирует разный шум в зависимости от контекста.
Слева учитывается контекст всей картинки с яблоком, а справа только определенная область в центре. Шум, сгенерированный на первом шаге, отличается: слева это целая область, а справа второе яблоко внутри первого.
Для закрепления: если Denoising strength небольшой, то шумом ка бы является исходное яблоко, которое уже без шума (его не надо пересоздавать). А если Denoising strength большой, то нейронка подавляет уже новосозданный шум и получает другой результат.
Если сложно, то посмотрим на это дело с другой стороны: представьте, что у вас в руках лупа. Более точная фокусировка эквивалентна низкому denoising strength: все уже сфокусировано, менять ничего не нужно. Ну, а если произошла расфокусировка, то нам срочно нужно это исправить и навести фокус: а пока мы это делаем — происходит генерация.
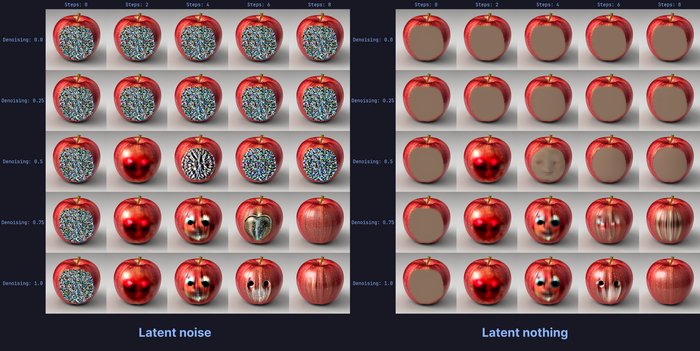
Разбираем больше примеров генерации шума
К примеру, у нас есть яблоко, и мы хотим его изменить на другое яблоко. Закидываем картинку в img2img, выставляем Denoising strength и жмем Generate.
На нулевом шаге генерации мы имеем наш исходник, который затем размывается и зашумляется. Как вы можете видеть, шум не похож на тот, который появляется при сбоях связи на телевизоре: он не заготовлен, а создается самой моделью. Нейронка как бы упрощает картинку донельзя и размывает ее, превращая в некую заготовку.
Даже при низком показателе Denoising strength мы получаем шум, однако на следующем шаге происходит перерасчет, и мы снова получаем исходное яблоко.
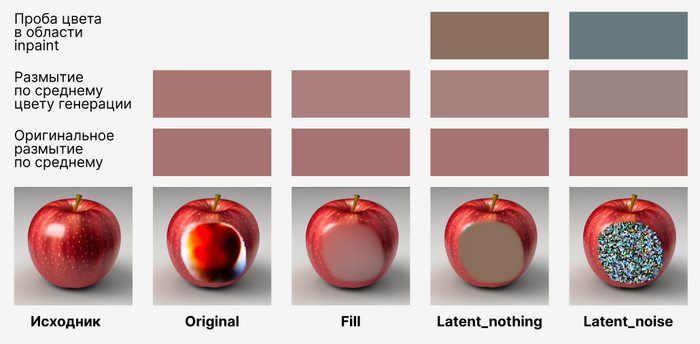
Сравнение методов генерации шума в режиме Inpaint
Далее посмотрим, как влияют на генерацию разные режимы работы генерации шума, среди которых: original, fill, latent noise, latent nothing. По мере продвижения буду комментировать и оставлять комменты для понимания, нафиг это нужно все вообще.
Тесты проводились на модели Deliberate_v2.
Метод original учитывает эмбеддинги исходника и придерживается их при генерации и декодировании шума. Хорош в том случае, если необходимо соблюдать контекст, цвета или формы.
Fill отлично подходит тогда, когда нужно убрать объект с фона или предмета. Этот метод размывает замаскированную область под маской, тем самым создавая пустое пространство.
Latent noise по сути создает случайный шум и затем его декодирует. С помощью данного метода можно как сгенерировать что-то новое в кадре, так и переделать часть объекта с нуля.
Latent nothing всегда создает определенный цвет, поверх которого затем происходит генерация.
Еще я заметил, что разные методики наложения шума по-разному меняют цветовую палитру. Для проведения этого эксперимента и размыл исходник в Photoshop в режиме Средняя, после чего проделал ту же операцию с картинками, на которых есть наложенный шум.
Чем правее стоит пример, тем больше он подвержен изменениям, и тем больше цвет отличается от исходника.
Отличие Inpaint модели от обычной
Inpaint-версия создает шум немного иначе, нежели обычная модель. Я привел данный пример, чтобы еще раз доказать, что шум — это многоэтапный и сложный процесс, который комбинируется с разными эмбеддингами и исходными данными.
Использовал в тестах Reliberate-inpaint. Такого рода модели обучаются дополнительно на масках и контентом под ним, а следование подсказке остается не в приоритете.
Шум Inpaint-модели максимально схож с оригинальной палитрой, а денойз стремится ближе к исходнику, т.е. эмбеддинги изображения явно перевешивают текстовые.
Вот еще примеры — и все также следование исходнику.
Congratulations, вы выжили!
Теперь вы разбираетесь в том, что такое Denoising strength в нейросетях. А если еще нет, то спамьте вопросами. Буду рад обратной связи и вашим комментариям, а также приглашаю в свой телеграм чат, где отвечу на все вопросы касаемо SD.
Буду рад видеть вас в телеграм-канале, где я собираю лучшие гайды по Stable Diffusion. А если не найду, то пишу сам.
Друзья, если Вы интересуетесь темой Искусственного Интеллекта, представляю Вашему вниманию ролик моего друга, который давно и всерьёз работает в этой области. Это скорее лекция - нежели контент, но мы 2 месяца старались сделать его смотрибельным, прошу оценить по всей строгости:
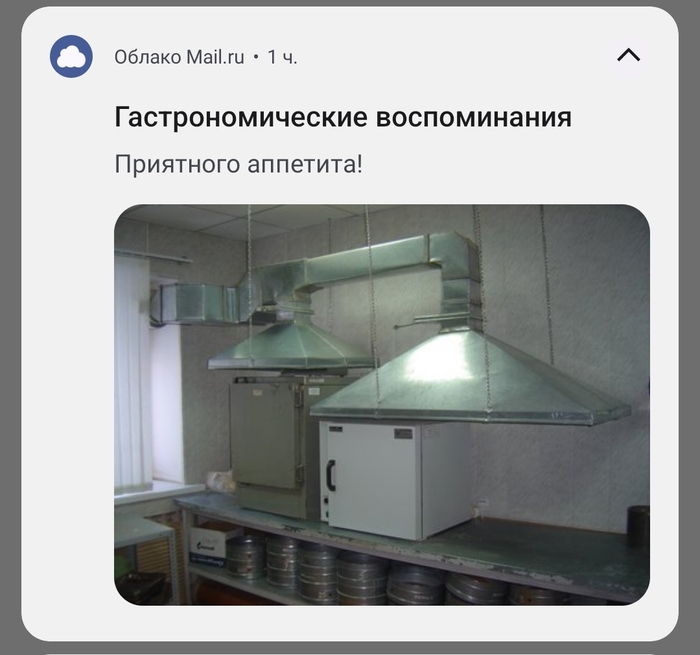
Приложение облака выдало вот такое сообщение. Надо им сказать что не всё что с вытяжными зонтами - это горячий цех общественного питания. На фото - лаборатория испытания битума.