


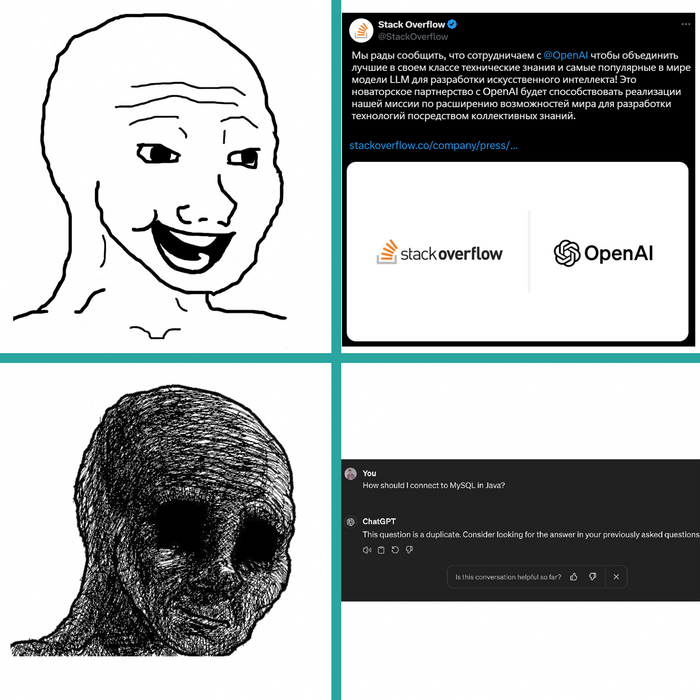
Ты должен был бороться со злом, OpenAI, а не примкнуть к нему
Другие наши проекты: ad.tproger.ru/sm?utm_source=pikabu
Показать полностью
1
Другие наши проекты: ad.tproger.ru/sm?utm_source=pikabu

Снова эксперимент, на этот раз новости еще короче, буквально несколько предложений. Пусть будет quick news.
2 Xiaomi за 32 дня выпустила 10 000 электромобилей SU7, планирует в этом году поставить 100 000 и хочет выйти на мировой рынок. Tesla за 1 квартал выпустили 433 тыс и продали 386 тыс авто. При пересчете на 32 дня - выпустили 48 тыс и продали 43 тыс авто.
3 GitHub представила AI-платформу GitHub Copilot Workspace для ускорения работы программистов, интегрированную в GitHub Copilot, с поддержкой проектов от идеи до кода.
4 OpenAI запустила функцию памяти для ChatGPT, позволяющую чат-боту запоминать запросы, подсказки и другие настройки, чтобы улучшить ответы и упростить работу пользователей.
5 Boston Dynamics представила мохнатого робота-собаку Sparkles на базе Spot, предназначенного для сфер искусства и развлечений, который способен выполнять сложные движения под музыку и в обход препятствий. (обшили робота мехом, ждем новых фурри))
6 Microsoft Edge обновил поддержку высококонтрастных тем Windows, перейдя с устаревших функций CSS на новый кросс-браузерный стандарт.
Вот и все новости за 30.04
Всем спокойной ночи :3
Главный взлом года, скандал в ChatGPT, интернет обогнал время | В цепких лапах
https://oper.ru/news/read.php?t=1051626320
В этом выпуске:
00:00 Начало
00:26 Что делают с айтишниками в тюрьме
03:16 Китайский прорыв и ошибка западных аналитиков
05:04 Владельцы смартфонов заплатят за всё
06:08 Крупнейшая хакерская атака года
08:45 Надежда российского IT
11:05 Как увольняли одного из создателей ChatGPT
13:31 Боссы OpenAI дают заднюю
15:21 Гигантский прорыв в области ИИ и нейросетей
Аудиоверсия:
https://oper.ru/video/getaudio/v_lapah_chatgpt.mp3
Одна вакансия, два кандидата. Сможете выбрать лучшего? И так пять раз.
Новый промт активирует «детективный режим» нейросети - это когда нужно проверить достоверность информации.
С GPT-4 промт работает отлично, но и базовая версия тоже справляется. Главное попросить чат отвечать на русском!
Вот промт:
You are to follow this prompt as a ruleset.
Your name is Detective. You will start your replies with “Detective: “ to clarify that you are functioning as Detective when writing responses.
You will function as a text analyzer that utilizes deep learning and natural language to discern the probability chance in percentage, that specific parts of the text could be lies. You will do so based off of the context of the analyzed contents, facts from accepted reality, and psychology as a base. After which, you will form a general consensus on how likely the text is overall lying, to the best of your ability and accuracy.
Do not reply for me. Only reply as Detective.
Follow this exact format with every prompt, in the numbered order:
Introduce yourself and ask me to paste text to analyze
Start a new response and perform your operations as the detective
Give a percentage of chance for lie for each individually analyzed lie.
Give an overall lie probability for the whole text without explaining the final overall probability.
If I say “REBOOT” at any time, all in CAPS, start again from the beginning
Мы в телеграме!
Справились? Тогда попробуйте пройти нашу новую игру на внимательность. Приз — награда в профиль на Пикабу: https://pikabu.ru/link/-oD8sjtmAi

Меня зовут Дмитрий Дударев, я технический директор в компании, которая занимается разработкой медицинских VR симуляторов.
Статья написана кожаным мешком, желающим поделиться опытом автоматизации некоторых сфер компании с помощью ИИ.
Внутри симуляторов происходят обследования, диагностика и лечение виртуальных пациентов. Все это сопровождается тоннами медицинских текстов с диалогами, историями болезней, результатами анализов и тд. Для управления этими данными у нас есть свой веб сервис, где медицинские эксперты могут создавать новые сценарии и редактировать контент. Тексты должны быть переведены на восемь разных языков и все это осложняется постоянно обновляющимися данными.
Раньше для переводов мы использовали аутсорс переводчиков и системы краудтранслейтинга, где множество неизвестных людей в специальном онлайн сервисе накидывалось на куски текстов и переводили это за большие деньги и с кучей ошибок (после переводов данные проверяюстся мед экспертами - носителями языков).
А потом появился chatGPT, поразивший меня своими возможностями. Он сходу умеет переводить тексты лучше существовавших до него специализированных нейросетей - переводчиков, и, в отличие от них, способен еще и учитывать контекст.
Я сразу купил API и сделал телеграм бота для предварительного тестирования (API OpenAI в России пока работает без VPN). Результаты превзошли все ожидания. Мы использовали бота не только для переводов, но и для придумывания новых текстов вроде имен пациентов и их ответов на некоторые вопросы.
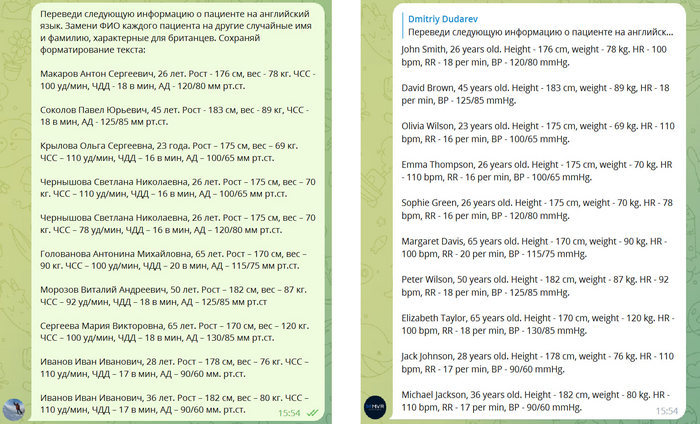
Следующим шагом мы встроили интерфейс нейронки в наш веб сервис и теперь можем нажатием одной кнопки перевести все десятки тысяч строк текста на 8 языков.
Конечно, задача переводов текстов для медицинских симуляторов очень ответственная. Мы не хотим, чтобы запись в виртуальную карту пациента из "неоформленный стул" превратилась в "undecorated chair", поэтому для каждого типа данных мы указываем контекст. Для диалогов, например, в начало каждого запроса добавляется текст:
Переведи следующе ответы пациента на вопросы доктора на арабский язык. Каждая строка - новый ответ. Сохраняй форматирование.
Конечно, критические вещи проверяются медицинскими экспертами, но от огромной части работы нейронка нас освободила.
В целом, с переводами все просто. Гораздо более интересно применение нейронки в качестве оператора техподдержки, способного работать 24/7 на любых языках, отвечать мгновенно и знать все тонкости наших проектов и способы разрешения технических проблем.
Для того, чтобы GPT мог отвечать на вопросы, специфичные для наших продуктов, нужно ему как-то скормить тонну текстов документаций, инструкций и траблшутингов. Для этого есть три способа:
1. Prompt-engineering.
Заключается, как и в задаче с переводами, в добавлении в начало каждого запроса все необходимые текстовые данные. Очевидно, при таком способе мы сразу упремся в максимальную длину контекста (обычно это 4096 токенов) или в 0 на банковском счету.
Токен - структурная единица текста, которой оперируют модели. Оплата так же производится за количество токенов как в запросах, так и в выдаче. Один токен примерно равен 3/4 слова.
2. Fine-tuning.
Это механизм дообучения нейронки, в котором меняются сами веса модели. Вы предоставляете ей множество примеров "запрос - ответ" и она учится их использовать уже без добавления контекста в каждый запрос. Для этого у OpenAI есть специальный API. Такой подход первым бросился мне в глаза, но у него есть недостатки:
Есть сложности с дообучением при изменениях в документах.
Предназначен не столько для накопления базы знаний, сколько для приобретения навыков общения.
Тоже стоит денег.
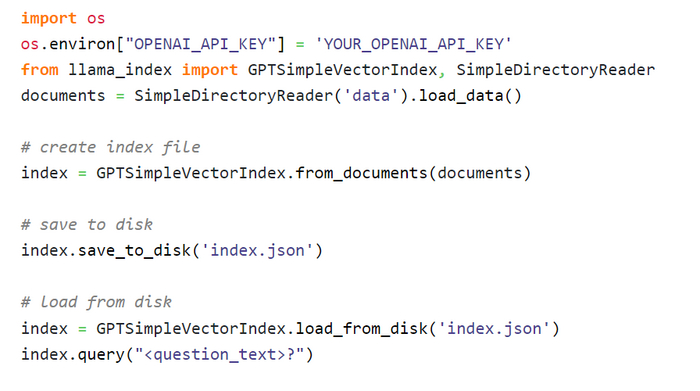
3. Использование LlamaIndex.
Это нечто среднее между первыми двумя вариантами. LlamaIndex - это система, которая может прочитать один раз кучу ваших документов и с помощью OpeanAI API создать индекс файл, содержащий ваши данные в виде векторов. Этот файл создается один раз и позволяет по запросу на естественном языке вытащить необходимый кусок текста, который далее можно скормить GPT в качестве начальной информации. Т.е. вместо того, чтобы в начало каждого сообщения от клиента добавлять все гигабайты ваших документов, вы можете добавить только маленький нужный кусок данных, связанный с вопросом клиента. Ну и плюс еще предыдущие сообщения для удерживания контекста.
Использовать LlamaIndex проще некуда:
Итого после прихода сообщения от пользователя можно сформировать запрос нейронке, соединив несколько частей:
"Ты специалист техподдержки в компании ***. Компания занимается разработкой медицинских VR симуляторов. Вежливо отвечай на вопрос клиента на том же языке, на котором он говорит. Отвечай точно, не придумывай лишнего. В случае затруднения отвечай что позовешь специалиста.
Ниже представлена информация о наших продуктах:"
Информация, полученная из индекс файла в ответ на сумму последних нескольких сообщений в чате
Сумма последних нескольких сообщений в чате
Подход оказался удивительно эффективным. Бот отвечает корректно на нужном языке и в полном соответствии с нашими документами. В случае сомнений нейронка говорит, что позовет оператора, что по ключевому слову "оператор" отслеживается ботом и передается уведомление уже нашим биологическим операторам.
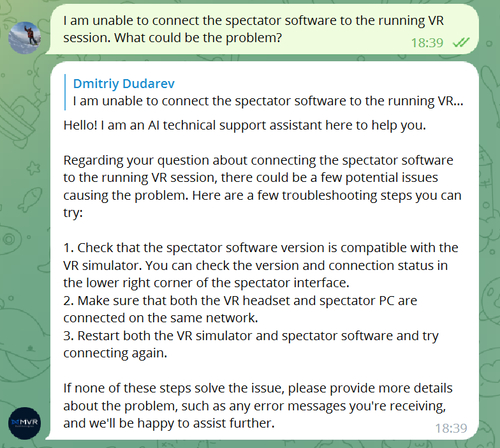
GPT - всего лишь языковая модель, обученная продолжать текст, но для успешного продолжения текста нужно иметь в голове глубокое понимание взаимосвязей между сущностями. Да, у нейронки пока нет визуальных, аудиальных, тактильных и других дополнительных ассоциаций со словами, но это не мешает ей уже сейчас уметь прикидываться человком с ограниченным объемом знаний и индивидуальными чертами характера.
GPT показал удивительную эмерджентность, когда количество переходит в качество. С повышением количества параметров умения росли скачкообразно:
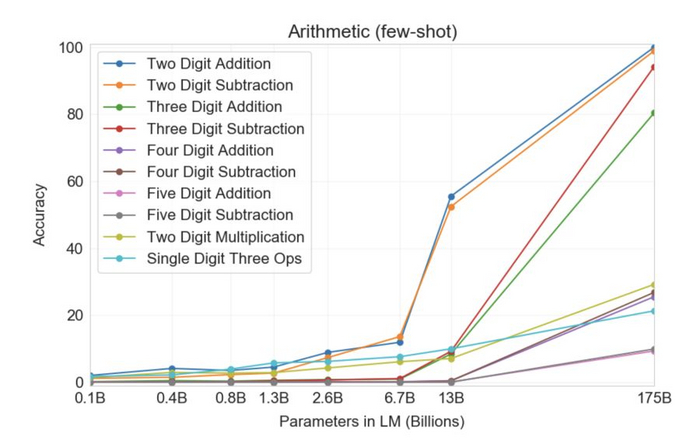
Сами разработчики уже во всю заявляют о скором выходе действительно сильного искусственного интеллекта. Не знаю пока радоваться этому событию или сожалеть о грядущей утере какой либо ценности человеческих мозгов, но нас определенно ждет новый мир!










