Этот интересный факт о Python напрямую связан с предыдущим. На эмблеме Python изображены как раз таки змеи. Пресмыкающиеся образуют квадрат.
Составил лого брат Гвидо, дизайнер Юст ван Россум. Шрифт текста тоже изобрел он.
До 2006 года логотип Питона был текстовым. Но кобры всевозможных видов в книгах, журналах и на сайтах про Python подтолкнули к смене лого во избежание путаницы.
Интересный факт про Python заключается в том, что это один из самых популярных языков программирования в мире. Он был создан 90-х годах прошлого века Гвидо ван Россумом и с тех пор стал одним из наиболее распространенных языков программирования.
1. "Python Crash Course" Эрика Мэтиза — это книга для начинающих, которая поможет вам освоить основы языка Python и научиться создавать простые программы.
2. "The Pragmatic Programmer" Эндрю Хант и Дэвид Томас — это книга о том, как стать успешным программистом, используя принципы Agile-разработки.
3. "Python for Data Analysis" Роберт Лафоре — это книга о том, как использовать язык программирования Python для анализа данных и создания приложений для работы с большими объемами информации.
1. Используйте переменные вместо констант. Константы — это значения, которые определены один раз и не могут быть изменены. В то время как переменные могут быть изменены в любой момент времени.
2. Используйте циклы для повторения кода много раз. Цикл позволяет повторять код до тех пор, пока он не будет выполнен полностью.
3. Используйте условные операторы для проверки условий и выполнения действий в зависимости от результата. Например, если вы хотите найти все четные числа в списке, вы можете использовать оператор if.
Для тех кто первый раз читает мой гоблинский блог - расскажу кратко что тут происходит. Я сам являюсь зеленым новичком в разработке игр и в своем блоге описываю этапы изучения столь сложного дела. На данный момент - это работа с движком Godot 4.
Чтобы не мучать вас длинными статьями, я разбиваю этот путь на кучу мелких блоков. Один пост - одна механика движка. Все гоблинские заумные слова расшифровываются на человеческий, так что даже пациент из Кащенко поймет о чем речь. Погнали!
● Создание сцены с персонажем:
В прошлой статье мы создали редактор карт с автоматическим заполнением, кто не читал - почитайте, будет полезно. Теперь нам нужно сделать персонажа, которым мы будем бегать по данной карте. Для этого нам нужен узел типа "CharacterBody2D", на основе которого мы и создаем новую сцену. Сделать это можно выбрав вкладку "Другой узел".
Как выглядит узел "CharacterBody2D"
● Визуальное изображение персонажа:
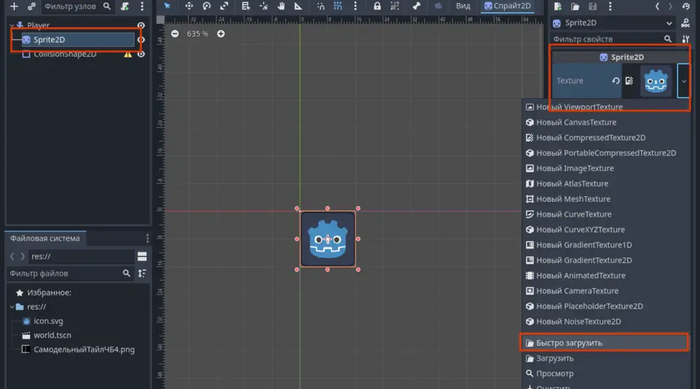
Узел это конечно хорошо, но мы пока ни черта не видим - нам нужен визуальный образ. Добавляем дочерний узел "Sprite2D". В его настройках находим вкладку текстуры и добавляем иконку Godot. В будущем мы заменим спрайт на анимацию, но пока нам хватит такой затычки.
Узел "Sprite" -> Texture -> Быстро загрузить
● Настройка зоны столкновения:
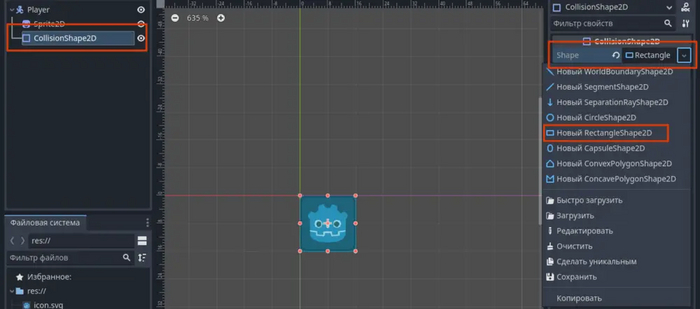
Чтобы наш персонаж не проваливался в текстуры и реагировал на поверхности мы должны настроить зоны столкновения. В прошлом уроке мы работали со слоем Collision в нашем TileMap. Тут же мы добавляем узел "CollisionShape2D", который представляет из себя выделение зоны столкновения в виде простой геометрической фигуры. Вид этой фигуры мы выбираем во вкладке "Shape".
Узел "CollisionShape2D" -> Shape -> Новый RectangleShape2D
● Начальные данные для физики и управления:
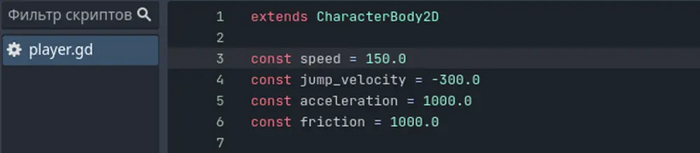
Создаем скрипт для нашей сцены и первым делом зададим константы. Константа - это постоянное значение, которое не будет меняться в ходе работы программы.
Чтобы создать константу мы пишем: const название_константы = значение
Переменные же создаются по другому: var название_переменной = значение
Давайте разберемся за что отвечают указанные нами значения:
speed и acceleration - от этих значений будет зависеть скорость передвижения по оси X (влево-вправо)
jump_velocity - это значение влияющее на высоту прыжка. Ось Y в Godot перевернута с ног на голову и отрицательное значение означает вверх.
friction - значение влияющее на скорость остановки при прекращении передвижения.
Так выглядят наши константы в коде
Так же мы добавляем значение гравитации, однако оно выставляется из внутренних настроек проекта.
var gravity = ProjectSettings.get_setting("physics/2d/default_gravity")
● Общая функция для управления персонажем:
Задав исходные данные мы можем приступать к настройкам функций нашего персонажа. Для этого мы пишем стандартную функцию Godot:
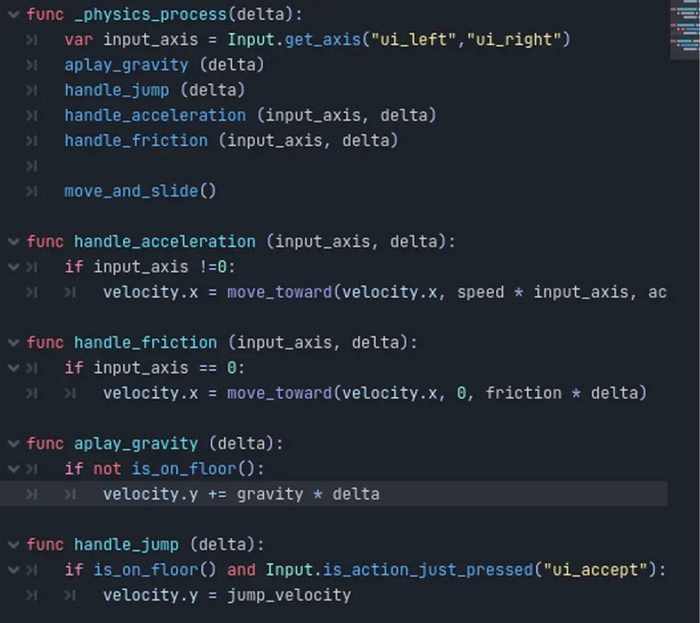
func _physics_process(delta):
Для тех кто не знает - эта функция вызывается перед каждым физическим кадром, который привязан к физическому fps, он по умолчанию равен 60 раз в секунду.
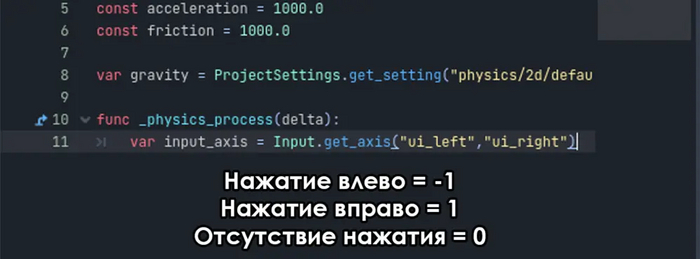
var input_axis = Input.get_axis("ui_left","ui_right")
Get_axis - это функция которая присваивает переменной одно из двух значений при нажатии одной из двух кнопок. Первое значение равно -1 и задается при нажатии клавиши "влево". Второе же равно 1 и задается при нажатии клавиши "вправо". Если на момент кадра не нажата ни одна из этих кнопок, значение равно 0. Это позволяет нам определить нужное направление для изменения координат персонажа.
Влево = -1 | Вправо = 1 | Стоим на месте = 0
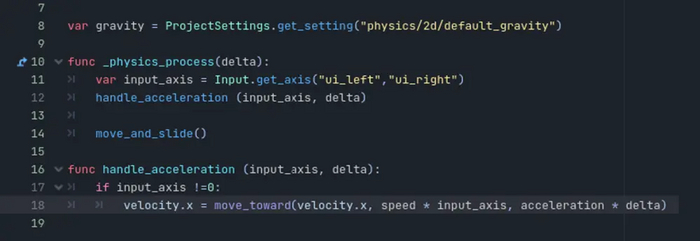
● Движение по оси X (влево-вправо), создаем новую функцию:
handle_acceleration (input_axis, delta)
В нее мы добавляем условие, что должна быть нажата одна из клавиш - влево или вправо.
if input_axis !=0:
Если данное условие выполнено, то мы совершаем перемещение в заданном направлении. Для этого используется функция move_toward.
velocity.x - это переменная отвечающая за перемещение по оси X.
В move_toward мы задаем три параметра через запятую. Изначальная точка, точка в которую мы должны прийти, шаг в сторону нужной точки за один кадр.
Каждый кадр мы двигаемся в выбранную сторону, начальная точка меняется и это создает замкнутый круг движения. А чтобы его запустить, мы добавляем нашу функцию под physics_process и в конце пишем move_and_slide().
move_toward ( начальная точка, точка прибытия, расстояние шага за один кадр )
▸ А где тормоза то !?
● Как сделать остановку?
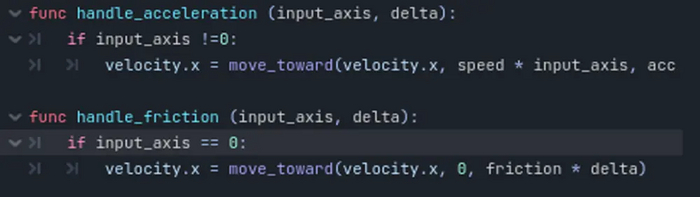
Мы начали двигаться и если не нажмем кнопку в противоположную сторону - улетим за край карты. Чтобы разорвать наш круг постоянного движения мы должны сделать функцию тормоза.
Копируем нашу прошлую функцию и переименовываем ее:
handle_friction (input_axis, delta):
Так же меняем заданное условие, input_axis должен быть равен нулю. Главное помнить, что знак равенства при сравнении выглядит вот так "==".
if input_axis == 0:
В функции move_toward заменяем значения. Первое остается прежним, на втором ставим ноль, а на третьем стираем acceleration и пишем friction. Все это в сумме обеспечит нам быструю остановку.
Функции обратные друг другу
● Движение по оси Y (прыжок, гравитация), создаем новую функцию:
aplay_gravity(delta):
Если мы не на земле, то бишь в воздухе - нас должно тянуть вниз.
if not is_on_floor():
velocity.y += gravity * delta
Ставим именно "+=", так как это сделает плавное падение с нарастающим ускорением. Не забудьте умножить на delta, иначе все произойдет за долю секонды.
● Следующая функция для прыжка:
handle_jump(delta):
Для нас важны два условия - нахождение на земле в момент прыжка и нажатие нужной клавиши.
if is_on_floor() and Input.is_action_just_pressed("ui_accept"):
Если данное условие соблюдено мы приравниваем параметр оси Y к значению высоты прыжка.
velocity.y = jump_velocity
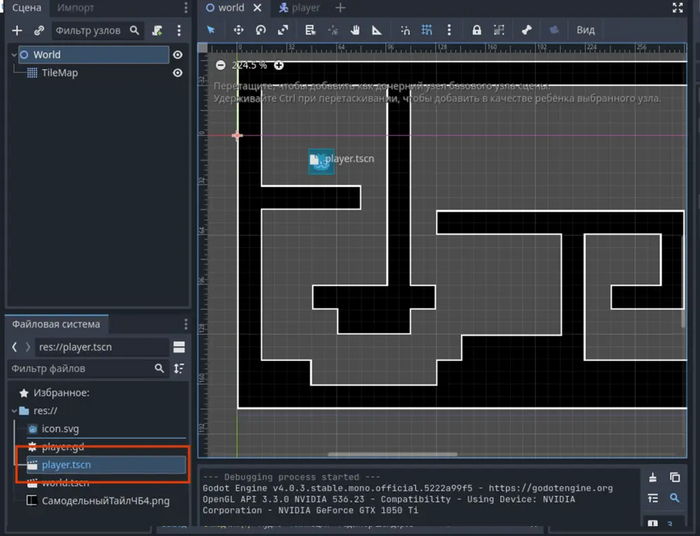
Добавляем эти функции под physics_process, а после переходим на сцену "world". Туда из общего списка ресурсов перетаскиваем сцену "player".
.tscn - это формат сцены в Godot
Как выглядит наш блок с функциями
● Что у нас получилось в итоге?
✓ Если вы нажимаем клавишу влево или вправо - персонаж двигается в выбранном направлении.
✓ Если ни одна из клавиш направления не нажата - мы останавливаемся.
✓ Если мы находимся в воздухе - нас тянет вниз с каждой секундой все сильнее.
✓ Если находясь на земле, мы жмем прыжок - нас подкинет вверх.
▸ Оно живое!
Вот так при помощи четырех простых функций мы создали основу физики и управление персонажем. Надеюсь разобрал каждый шаг максимально подробно и понятно.
✓ Зеленые новички - крепитесь и подписывайтесь, скоро новая статья. На очереди две темы - "анимация персонажа" или "двойные прыжки и прыжки от стены".
✓ Опытные шаманы - запасайтесь успокоительным, ибо дальше будет еще куча попыток освоить gamedev.
✓ Ну и все кто имеет свое мнение, поддержку или усмешку - пишите комменты!
В этой статье я расскажу как я смог бесплатно и без мощного железа дообучить LLaMA на диалогах с друзьями в ВК, чтобы сделать чат бота, который копирует наш стиль общения, оживляет разговор в чате и просто пишет странные и смешные вещи. В статье будет мало терминов, тут я простым языком расскажу как вы можете обучить большую языковую модель.
Прошло уже около полугода как Meta* случайно слили свою языковую модель LLaMA. А недавно они сами выложили в открытый доступ ее 2-ую версию. Для понимания масштаба - на обучение Meta* потратили более 3 311 616 GPU часов. Это примерно 378 лет работы одной мощной видеокарты.
Cразу скажу, что я уже публиковал эту статью на Хабр. Но хочу теперь попробовать начать писать статьи на Пикабу, так что я буду очень рад любым комментариям и отзывам. Надеюсь пользователям Пикабу эта статья тоже зайдет)
Те, кто интересовался темой языковых моделей, уже, наверное, знают, что первую версию llama энтузиасты почти сразу после слива оптимизировали для работы на обычных процессорах и на нейроускорителях Apple, которые стоят в их процессорах. При этом на M1 процессоре LLaMA стала работать очень быстро, выдавая более 10 токенов(токен - это слово, часть слова или буква) в секунду, это быстрее чем бесплатный ChatGPT на тот момент. Еще через пару недель ее дообучили ребята из Стэнфорда, чтобы она понимала концепцию вопрос-ответ и могла давать ответы и выполнять задачи.
Что потребуется для запуска нейронки
Есть две версии модели: LLaMA и LLaMA 2. LLaMA есть в размерах 7B, 13, 30B, 65B, LLaMA 2 - в размерах 7B, 13B и 70B. 7B весит примерно 13 гб, 65B - 120 гб. Но не торопитесь ужасаться, во-первых, как я уже писал, ее можно запустить не только на видеокарте, она хорошо работает и на процессоре, а во вторых, для запуска на обычных компьютерах применяют квантизацию (quantization) - это сжатие всех весов нейронов. В оригинальной версии вес каждого нейрона 16 бит, но их сжимают до 8, 4 и даже до 2 бит. Чаще всего используют сжатие до 4 бит, LLaMA 7B при таком сжатии весит 3.9 гб и требует немного больше 4 гб оперативной памяти и обычный процессор.
Что будем обучать и что потребуется
В данной статье я покажу как я дообучал LLaMA 7B и LLaMA 2 7B. Если готовы заплатить за аренду видеокарт, то можете обучить и модели покрупнее. Обучение будем проводить для нейронки в оригинальном размере (16 битовые веса), создав Lora модуль (не буду тут рассказывать, что это, если вкратце, то это алгоритм обучающий лишь несколько дополнительных слоев для нейросети, которые корректируют ее работу, это намного менее требовательно, чем полное дообучение). Для этого пока обязательно нужна видеокарта, то есть нужно около 15 гб видеопамяти.
На этом можно было бы остановиться, подумав, что за такое железо точно придется платить. Но пока изучал эту тему, я увидел, что один парень на гитхабе написал о возможности запустить обучение бесплатно на Google Colab. Честно говоря, я был в шоке, когда понял что google совершенно бесплатно дает доступ к машине с 13.6 гб оперативки, с Nvidia Tesla T4 на 16 гб видеопамяти, около 78 гб хранилища и очень быструю сеть (скорость загрузки нейросети там доходила до 200 мегабайт в секунду). Конечно всю эту радость дают не навсегда, а на неопределенный срок, и отнять это могут в любой момент. У меня получалось обучать по часа 4.
Данные для обучения
Для обучения я взял историю диалога с друзьями в ВК. В ВК можно получить по запросу все данные о себе, которые у них есть, в том числе истории всех переписок. Чтобы подготовить полученные данные, я воспользовался первым попавшимся на github репозиторием для парсинга сообщений в бэкапе вк и сделал форк с изменениями для создания датасета. Через код в Jypyter вы сможете получить json файл с датасетом для обучения.
Обучение
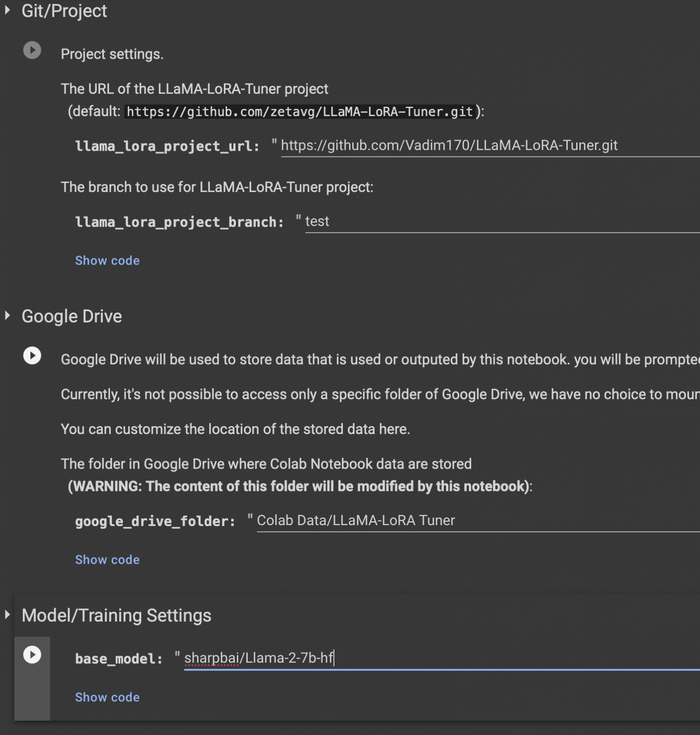
Для обучения можно воспользоваться этим проектом, я сделал от него форк, добавив шаблон для обучения на простом тексте (оригинальный репозиторий имеет шаблоны только для обучения концепции вопрос-ответ). Вот мой форк и вот проект которые вы можете запустить в гугл колабе, он подтянет мой форк. В первых нескольких полях вы можете поменять папку на Google Disk, куда будут сохраняться результаты обучения, нужно не меньше 300 мб. Также можете вместо модели "sharpbai/Llama-2-7b-hf" выбрать другую, например llama 7b первой версии (decapoda-research/llama-7b-hf), найти вы их можете на huggingface. Лучше всего брать те, которые разбиты на множество файлов (такие требуют меньше памяти при загрузке). Те, что не разбиты, не всегда загружаются на бесплатном google colab (требуется больше памяти).
Пакеты не всегда ставятся сразу в виртуальной машине, не стоит пугаться, иногда требуется нажать Runtime -> Restart runtime. На второй раз пакеты ставятся успешно.
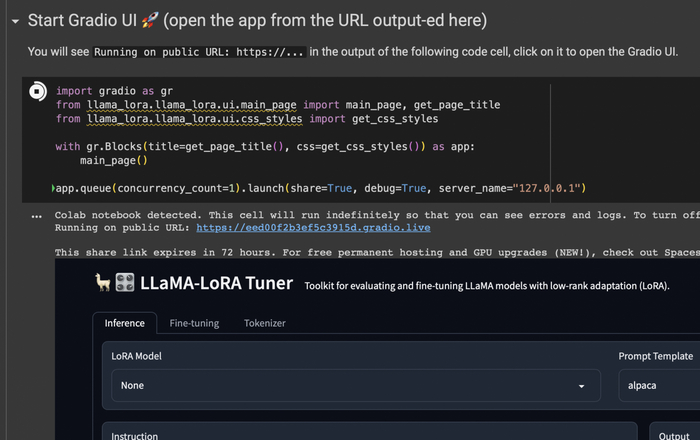
После того как языковая модель скачается и загрузится в память, вы можете воспользоваться веб интерфейсом, чтобы настроить параметры обучения. Ссылка будет выведена в формате: Running on public URL: https://...
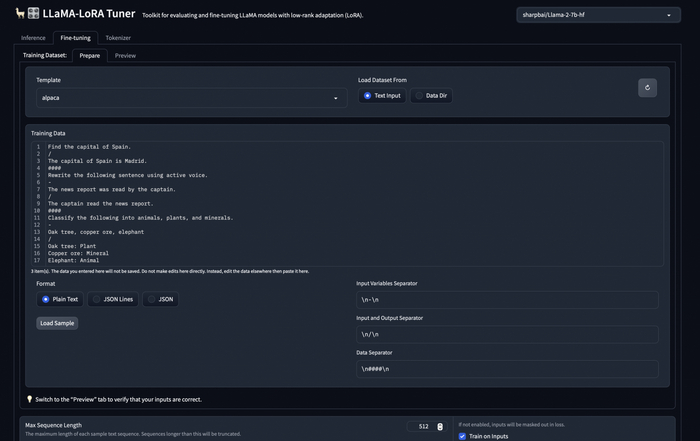
Сразу можете переходить во вкладку Fine tuning, в поле Template выставлять "my_sample", в поле Format "JSON Lines". my_sample - это тот простой шаблон промптов, который я добавил, в нем нет ничего кроме input и output. Далее нужно либо скопировать содержимое файла датасета, либо открыть его, скопировав на машину google colab.
После можете посмотреть превью данных для обучения во вкладке Preview. Еще на этой вкладке браузер меньше тупит, не пытаясь отобразить все данные для обучения.
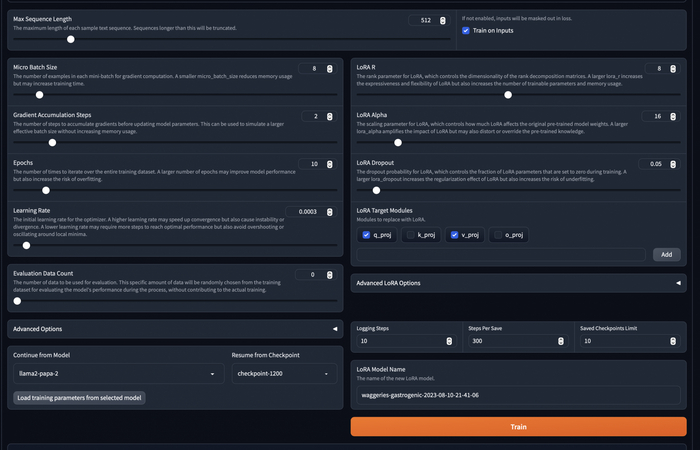
Остается только выставить параметры обучения, в целом можно оставить по умолчанию, но вот поля, которые я менял:
Max Sequence Length - Влияет на максимальную длину текста в наборе датасета. Все данные из датасета, длина которых превышает эту, не будут использоваться в обучении. (На русском почти всегда длина это количество букв). Очень большое число может привести к переполнению памяти на бесплатной машине.
Train on Inputs - Эту галочку лучше поставить, чтобы модель обучалась и на input тексте, и на output.
Micro Batch Size - Грубо говоря, указывает количество данных, которое берется для обучения за раз. Очень большое число может привести к переполнению памяти на бесплатной машине. Я оставлял в основном 8.
Gradient Accumulation Steps - Не разбирался как работает, но я поднимал до двух. Судя по описанию, ускоряет обучение, как и Micro Batch Size, но не увеличивает потребляемый объем памяти.
Epochs - Количество эпох обучения. Можно смело ставить больше, все равно остановим обучение руками, или гугл сам остановит машину часа через 4.
Learning Rate - Коэффициент обучаемости, влияет на скорость, но слишком большой может привести к плохому обучению, я оставлял 0.0003.
Saved Checkpoints Limit - Максимальное число чекпоинтов, ставьте побольше.
Steps Per Save - Количество шагов перед сохранением бэкапа. Ставьте 200-300, чтобы почаще сохраняться и меньше терять в случае отключения машины гуглом.
LORA Model Name - Название папки на гугл диск, в которую будут сохраняться бэкапы.
Позже еще понадобится раздел Continue from Model для продолжения обучения с последнего чекпоинта.
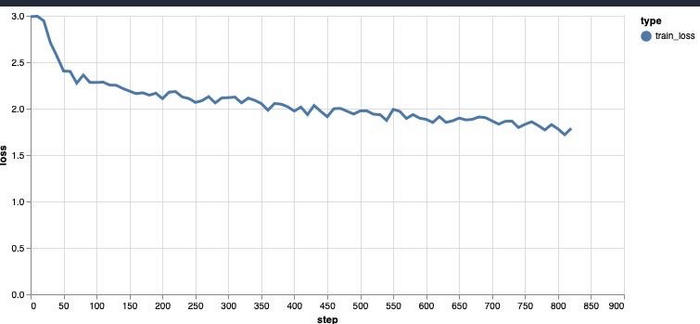
В процессе обучения вы будете видеть примерно такой график. Я обычно дожидался ошибки примерно до 1.1. Дольше у меня не хватало терпения).
Теперь, зная как можно бесплатно дообучить llama, вы можете создать тупого бота симулирующего участника в диалоге с друзьями, он, конечно, не будет кидать мемы и понимать глубокий смысл, но может поугорать за компанию или написать тупую шутку. Можно попробовать сделать что-то и посерьезнее, например, ПО системы для написания ответов на письма или откликов на фриланс бирже. Применений может быть много, но стоит понимать что LLaMA 7B все же плоховата в работе с русским, так как мало его учила.
Спасибо больше за внимание, надеюсь статья была для вас полезна! Буду рад любым коментариям и дополнениям!
Я выложил пару сравнений работы дообученной и простой llama 2 7B в телеграм канале, который недавно создал, буду стараться там регулярно выкладывать интересные мысли про программирование, нейросети и информационную безопасность.
Также выложу там инфу про то, как я поднял llama на raspberry pi для бота в телеграмме.
* Meta - признана экстремистской организацией и запрещена в России.
Десятки ботов предлагают доступ к популярным нейросетям. Разбираемся, реальность это или обман
В «Телеграмме» все чаще можно наткнуться на ботов, которые предлагают сгенерировать текст или картинки.
Разработчики обещают простой доступ к нейросетям без навыков программирования, необходимости устанавливать сторонний софт и с оплатой российскими картами. Таких ботов можно найти по прямому поиску, через рекламу или в многочисленных статьях в сети. Возникает вопрос: что скрывается за очередным сервисом с названием Chat GPT Bot или Mid journey Bot?
Мы разобрались, что обещают авторы нейросетевых ботов в «Телеграмме», и что на самом деле получают пользователи.
Стоит ли искать нейросетевых ботов в «Телеграмме»
Официальных ботов в «Телеграмме» нет. У нейросетей Mid journey, Stable Diffusion и Chat GPT нет своего сервиса в мессенджере. Пользоваться ими можно только на официальных сайтах этих нейросетей — они указаны в конце нашего материала.
Разработчики ботов могут вводить в заблуждение. Многие боты называются так же, как официальные нейросети, хотя «под капотом» может скрываться что угодно. Разработчики не раскрывают версии моделей или выдают устаревшие версии нейросетей за актуальные.
Спустя несколько бесплатных попыток многие боты просят деньги за подписку. Расчет на то, что вы купите подписку, думая, что подписываетесь на официальный сервис. На деле вы получите модель нейросети неизвестного происхождения.
Для подключения нейросети к боту у нее должен быть открыт API — набор инструментов для разработчиков, с помощью которых одна программа может использовать другую. Встроить нейросеть в «Телеграмм» можно, если разработчик имеет доступ к коду нейросети.
API открыт только у Stable Diffusion. Доступа к API Mid journey нет, а у Chat GPT и Dall-E 2 — платный и только для разработчиков.
Как работают боты Chat GPT в «Телеграмме»
В «Телеграмме» есть десятки ботов, которые выдают себя за Chat GPT: указывают сервис в названии, используют брендинг компании Open AI. И на первый взгляд кажется, что все соответствует истине: боты, как и Chat GPT, генерируют посты, сценарии, тексты песен.
Неизвестно, что скрывается за ботом. У Open AI доступно несколько языковых моделей для разработчиков. Доступ к API у них платный, при расчете тарифов используется система токенов. Работает она так: разработчики платят определенную сумму за тысячу токенов — сгенерированных частей слов. Тысяча токенов равна примерно 750 словам. Например, в этом абзаце около 60 токенов.
Пользователи ботов генерируют текст и таким образом тратят токены, за которые заплатили разработчики. Из-за этого во многих ботах есть лимиты на сообщения, множество рекламы или платная подписка. Вряд ли найдутся альтруисты, готовые предоставить сервис и платить за него из своего кармана. Зато можно сделать бота с Chat GPT для личного использования.
Самая дешевая модель Ada стоит 0,0004 $ за тысячу токенов, самая дорогая и продвинутая Davinci — 0,02 $ за тысячу токенов. GPT-3.5 — доступ к ее API открыли недавно, — на которой работает Chat GPT, стоит в десять раз дешевле Davinci — 0,002 $ за тысячу токенов.
Доступ к API GPT-4 обычным разработчикам пока получить непросто: нужно записываться в лист ожидания и дожидаться ответа от Open AI. Модель самая дорогая из всех — 0,03 $ за тысячу токенов.
Chat GPT хуже GPT-4?
Open AI выпустила четыре версии языковой модели GPT, которая обучается на текстах из интернета и может генерировать осмысленные ответы на вопросы.
Базовый Chat GPT работает на версии GPT-3,5. Основное отличие от версии GPT-3 — наличие «памяти». Модель запоминает детали разговора и может строить ответы, основываясь на информации, которую ей уже сообщил пользователь. Работает с русским языком, но с английским справляется намного лучше.
GPT-4 лучше учитывает контекст, умеет распознавать изображения, хорошо работает с русским языком и сдает сложные экзамены на уровне отличников. В бытовом общении и простых задачах разница между GPT-3,5 и GPT-4 может быть едва заметной. Однако разрыв между версиями становится очевидным по достижении определенного порога сложности задачи. GPT-4 доступна по подписке на Chat GPT.
Текст был спонсирован ребятами, которые сделали 2 бота Chat GPT в телеграмме.
Я лично пользовался Chat GPT-4, там действительно такая версия используется.
Как работают боты для рисования картинок в «Телеграмме»
В основном они работают по одному и тому же принципу — запускаете бота, вводите текстовую команду и получаете в ответ сгенерированное изображение. Разработчики ботов заявляют, что предоставляют легкий доступ к популярным нейросетям. Вот они:
Mid journey — оригинальной нейросетью можно пользоваться через официального бота в «Дискорд». Но бесплатная версия ограничена 25 попытками, а оплатить премиум с помощью российской карты нельзя.
Stable Diffusion — это нейросеть с открытым исходным кодом, при желании каждый может себе поставить сборку для генерации и пользоваться на компьютере. Но для этого необходимо мощное железо.
Dall-E 2 — эту нейросеть создала компания Open AI, разработчики Chat GPT. Доступ к ее API платный.
Главная проблема в том, что под ботами с названием Mid journey Bot или Dall-E 2 Bot может скрываться что угодно. Сложно с ходу сказать, какую модель использует тот или иной сервис в «Телеграмме».
Проще всего со Stable Diffusion. В «Телеграмме» действительно есть несколько рабочих ботов на основе нейросети. Они используют вычислительные мощности, которые предоставляют разработчики, и модель Open Journey, имитирующую результаты генерации Mid journey.
Вероятно, выбирают именно эту модель, потому что Mid journey по простому запросу генерирует красивые картинки, а в Stable Diffusion нужно прописывать большие и детальные промпты, чтобы получить нечто похожее.
Но не нужно от таких ботов ожидать качества «настольной» Stable Diffusion, поскольку, как правило, они используют старые модели — новые выходят буквально каждую неделю. Картинки получаются в лучшем случае средние. По уровню они близки к Dream Studio — браузерной облегченной версии Stable Diffusion.
У Mid journey нет открытого API. Но в теории нейросеть можно как-то связать с «Телеграмм» через «Дискорд». Я обнаружила бота, генерирующего такие же картинки, как в нейросети, и по стилистике, и по деталям.
Но разрешение у получившихся в «Телеграмме» картинок очень низкое. Бот дает одну бесплатную генерацию в сутки. Чтобы сделать апскейл картинки — увеличить ее разрешение — придется ждать следующего дня. После этого бот требует 199 Р в месяц за пять запросов в сутки. При этом в официальном Mid journey есть 25 бесплатных генераций, а минимальная подписка стоит 10 $ (918 Р) и дает 3,3 часа генерации в месяц. За это время можно сгенерировать сотни картинок.
Опять же: скорее всего, мне еще повезло, что я наткнулась на бота с Mid journey в названии, который действительно рисует как Mid journey. С большей вероятностью под ботами-аналогами будет скрываться та же Open Journey или другие бесплатные модели.
Из официального есть разве что бот Сбера под названием Malevich, который использует модель ru Dall-E. Из плюсов: Malevich, в отличие от остальных нейросетей, понимает запросы на русском языке.
Но ru Dall-E уже сильно устарела: она выходила во времена, когда можно было удивить размытыми картинками с артефактами, лишь издалека похожими на изначальный запрос. Результаты не сравнятся с тем, что сейчас можно сгенерировать даже в бесплатных браузерных версиях.
Стажировка в Авито — это классная возможность начать работу в командах с сильной экспертизой в продуктовой разработке. Вы будете работать над реальными задачами для бизнеса и сможете напрямую влиять на продукты для миллионов пользователей. * по мнению авито
4 направления:
QA
IT-Security: аналитик-SOC
IT-Security: DevOps
iOS
Backend
FrontEnd
2. Росатом Есть стажировка и направления обучения (с последующей стажировкой)
AtomSkills – отраслевой чемпионат профессионального мастерства Госкорпорации «Росатом» по методике WorldSkills - Отбор заявок пройдет с 14 по 21 августа
Web - Идёт набор. Требования: PHP, понимаешь принципы ООП, имеешь базовые знания JS, HTML;
Case Lab JavaScript и Java - Старт Case Lab Java - 11 сентября. Длительность 3 месяца Старт Case Lab JavaScript - 25 сентября. Длительность 2,5 месяца