Всем привет! В сегодняшней статье посмотрим на новую нейросеть под названием Udio. По результатам, кажется, она превосходит последнюю версию Suno.
Взглянем детально на функционал и её способности, ну и покажу, как можно дорабатывать результаты из Udio так, чтобы получались неплохие(!) коммерческие треки, которые можно будет выпустить на площадках. Да, вы всё верно прочитали: вся музыка, сгенерированная в Udio, полностью принадлежит вам, а уж тем более после доработки. Если вы всегда мечтали создать свой трек, не вставая с кресла или кровати, то это оно вот самое. Приступим.
Всего на сайте три доступных вкладки:
Discover — или так называемая главная страница. Здесь самые залайканные работы пользователей за определенный период
My Creations — в этой вкладке хранятся ваши сакральные наработки
Liked Songs — соответственно, лайкнутые работы
Так же доступны и плейлисты. Давайте перейдём к самому главному - генерации музыки.
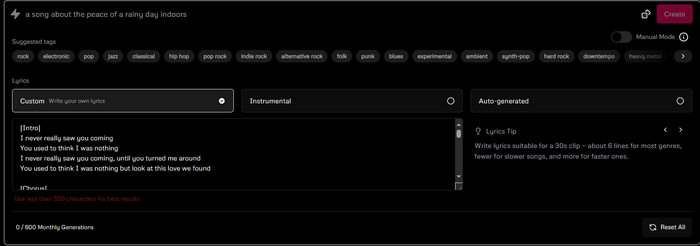
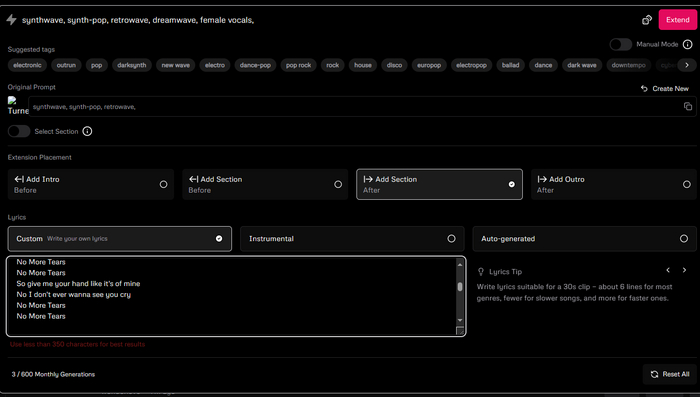
Чтобы приступить к созданию трека, жмём сверху слева розовую "Create". Далее видим следующее окно.
Сразу видим следующее: в месяц доступно 600 генераций(что достаточно много) и рекомендация по количеству символов: не более 350 для лучших результатов. Ну и Udio сам генерирует вам обложку к треку, причём очень неплохо.
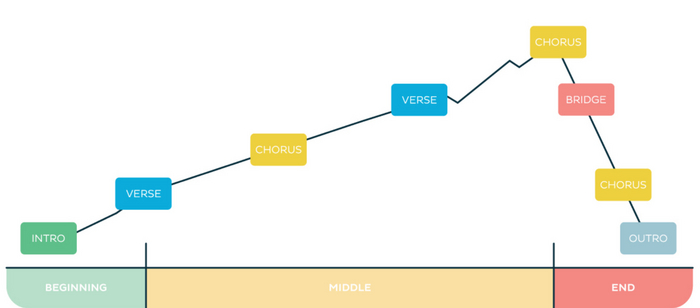
Так же разработчики сделали шпаргалку, чтобы правильно написать текст к песне и рулить промптом. Детально останавливаться не будем, скажу лишь, что рекомендуется использовать разделители аранжировки, а именно припев, куплет, бридж и всё такое. Если, конечно, музыка со словами. Так же доступны несколько языков, эмоции, дикторские голоса, инструменты и пол вокалиста, читка или пение, всё это и много чего ещё можно регулировать. Удивительно.
Ну и помимо текста есть основной промпт трека
Тут есть куча тегов с жанрами музыки и автоматический поиск, вводите и сразу видите результаты. Давайте попробуем создать лиричный синт-поп ретровейв трек с красивым женским вокалом, текст взял из одного похожего по стилю трека.
Ещё замечу, что Udio создает 30-секундные демки, которые вы можете по выбору сделать полноценными по длительности(Extend Track), а так же скачать демку, удалить её, сделать ремикс или зарепортить. Чтобы доделать трек до полноценного, здесь есть редактор, который добавили буквально на днях.
Итак, у меня получилось несколько вариантов, но мне приглянулся один, там почти не слышно голоса из-за затяжного интро, но мне с первых нот понравилось. Далее я нажимаю Extend, чтобы сделать полноценную версию
Здесь мы видим редактор Udio. Тут можно добавить части трека, такие как интро, аутро и т.п. И само собой текст. Дублирую его и генерирую ещё раз.
Немного подождав, вот какой результат получился, а точнее два:
На самом деле, мне этого уже достаточно, и можно закидывать всё это в DAW и далее дособирать, но я покажу функционал до конца, доделаем вокальную часть, и если будет много плюсов, покажу, как доделать профэссионално
Мне очень нравится две вещи: что создаётся по два отрывка, и можно выбрать, который лучше. И второе, что можно добавлять инструментальные аутро и интро, и что в целом редактор удобный. Мне не нравится, что я не могу выбрать темп трека, это пока единственное, что меня огорчило, потому что темп очень сильно решает, будет ли трек танцевальным, или медленным и текучим, а ещё скорее всего темп может повлиять и на настроение, которое задаст нейронка. Но есть костыли, можно добавить темп в текст песни.
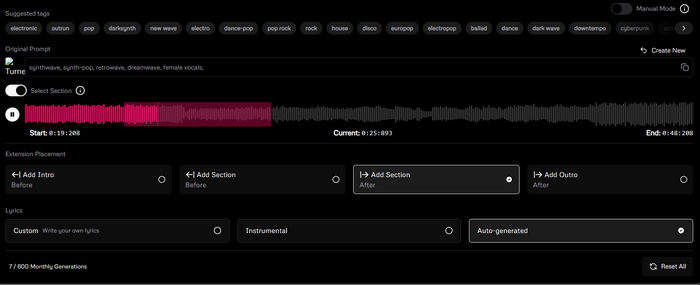
В этом окне так же есть очень немаловажная функция, это Select Section
Выбираем любой кусок, неудобно, что нет разделения по тактам, чтобы выбрать отрезок ровно, надеюсь, что это добавят в будущем. Так же выбираем, добавить часть до или после выбранного отрезка, и нажимаем Extend. Теперь нейронка будет отталкиваться от выбранного вами отрезка
Только что закончилась генерация, и чёрт возьми, это очень крутое аутро. Это нереально крутое и вайбовое аутро с саксом, просто послушайте. Трек вышел на 2:10
Интерфейс довольно простой и понятный, что тоже мне понравилось.
В общем, очень крутая штука, в ней действительно можно убить часы и получить невероятные эмоции.
Давайте сделаем костыльныйонлайн мастеринг, это лучше, чем ничего. Если будет много плюсов, то покажу, как делать некостыльный
Так же есть несколько режимов, но советую выбирать инструментальный. Всё же лучше чем ничего. Такое уже не стыдно выложить и на цифровые площадки по типу Яндекс.Музыки.
Приглашаем вас делиться своими работами в нашем сообществе Нейро-Музыкана Пикабу.
Если вам интересна тематика генерации музыки, добро пожаловать в Нейро-Звук🔉. Ну и загляните в моё сообщество музыкантов в Telegram, если вам понравилась статья, до новых встреч!
Вот такие прикольные клипы я получила из песен, которые сгенерировала в Suno и Udio:
Здесь мне песня напомнила любую песню Тейлор Свифт, поэтому я просто сгенерировала клип для Тейлор Свифт)
Noisee — бесплатная нейросеть, которая создаст музыкальный клип на основе трека.
Можно использовать ссылку на песню из Suno, Youtube, Udio, Stable Audio и Soundcloud. Можно так же загрузить свой mp3-файл. Работает пока только через платформу Discord.
Для примера, я сгенерировала треки в Suno и Udio, и затем вставила ссылку на каждый в Noisee, прописала, что должно быть в клипе, при желании можно добавить референсы в виде изображений. Нейросеть довольно быстро генерирует.
Заодно сами сможете сравнить, кто из генераторов музыки лучше справился с изначальной текстовой подсказкой.
Что крутого в нейросети Noisee?
Если в видео что-то не понравилось, его можно отредактировать. Просто нажимаете Edit и вас переносит на сайт Noisee, где можно ПОКАДРОВО отредактировать, изменить автоматически сгенерированный промпт для КАЖДОЙ картинки.
Ограничения:
Использовать можно 3 раза за 3 часа
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? В своем телеграм канале НейроProfit я рассказываю, как можно использовать нейросети для бизнеса
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
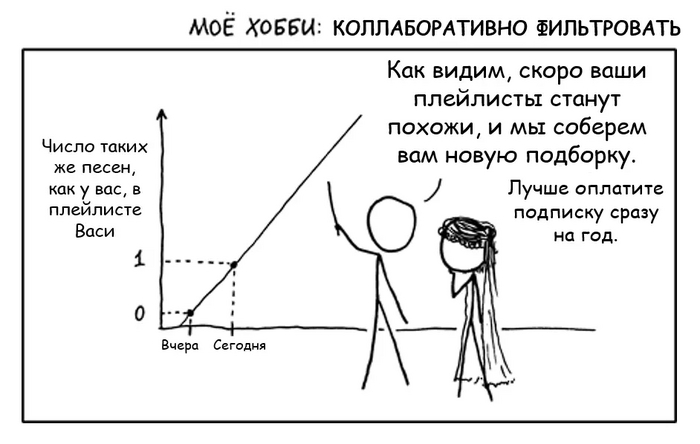
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Теперь можем делать готовые музыкальные композиции с прекрасным (любым) вокалом, сложными оркестровками и абсолютно чистыми авторскими правами, то есть неограниченное использовагние во всех каналах. Это идеальное решение для рилз, рекламы, корпоративных гимнов, поздравлений, чего угодно!
В эпоху искусственного интеллекта и технологических инноваций мир маркетинга стремительно меняется. Одним из новейших трендов становится генерация готовых песен с помощью обученных нейросетей. Эта технология открывает невиданные ранее возможности для брендов, желающих запомниться своей аудитории.
Песни всегда были мощным инструментом воздействия на эмоции людей. Мелодия и слова глубоко западают в память, формируя прочные ассоциации с продуктом или компанией. Однако написание качественных песен - процесс трудоемкий и дорогостоящий. Генерация песен с помощью ИИ предлагает быстрое и бюджетное решение этой задачи.
По мнению аналитиков, технология генерации песен с помощью ИИ имеет колоссальный потенциал в области маркетинга. Она позволяет брендам моментально создавать запоминающиеся и отвечающие духу времени музыкальные промо-материалы. При этом себестоимость создания песен на заказ значительно ниже по сравнению с традиционными методами.
Эксперты прогнозируют, что в ближайшие годы многие компании начнут активно осваивать данную технологию. Интеграция ИИ в процесс музыкального производства для маркетинговых целей, скорее всего, станет новой нормой.
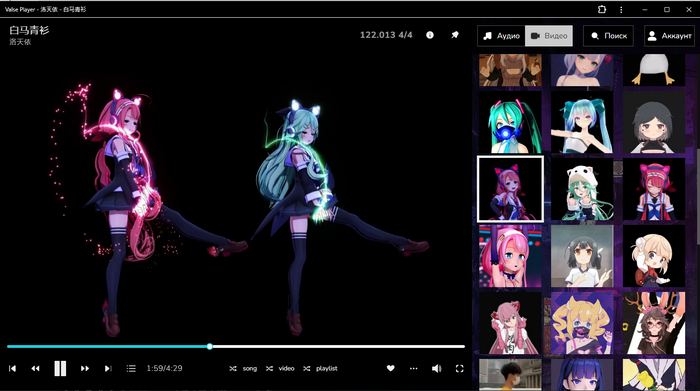
Всем привет. Прошел почти год с того момента как я выкладывал пост про аниме девочек танцующих под музыку. Тема многим понравилась и некоторые добрые люди даже помогли с редизайном. Проект не умер и всё это время развивался.
Итак встречайте новую версию:
Основные нововведения:
1) новый дизайн в котором есть обложки альбомов
2) много новой музыки: 28к альбомов, 357к треков большая часть из которой во flac
3) возможность лайкать треки, создавать плейлисты (для этого потребуется зарегистрироваться)
4) Поиск теперь работает через специальный поисковый движок и работает очень быстро
5) волна по треку (бесконечный плейлист который создаёт нейросеть похожий на какой-то опорный трек)
6) улучшены алгоритмы которые размечают треки
7) повышено качество видосов
8) мультиязычность интерфейса (в настройках английский русский)
9) Плавный переход треков
10) Динамическая смена цветовой схемы в режиме обложки. Если выбрана обложка, плеер берёт цвета из обложки и на основе них окрашивает свой интерфейс
11) Появились прямые урлы на треки. Когда играет трек, в строке URL меняется ссылка на него. Если эту ссылку скопировать и отправить другу - от откроет этот трек в плеере (в качестве плейлиста подгрузится альбом этого трека)
12) Обложки альбома были оптимизированы в миниатюры и теперь списки грузятся очень быстро
13) скачивание треков
14) Сделана интеграция плейлистов со сторонним андроид плеером, теперь можно слушать музыку нативно в телефоне, машине. Для этого в разделе аккаунт нужно взять ссылку "Liked M3U8 URL:" которую можно вставлять как m3u8 плейлист в любой плеер который поддерживает .m3u8 плейлисты. В этом плейлисте будут лайкнутые вами треки (лайки доступны после регистрации)
Если в поиске вы не нашли свою песню, не расстраивайтесь. Поисковые запросы сохраняются и потом когда будет происходить следующая выгрузка, ваша песня будет выгружена и добавлена в плеер)
И просто немного скриншотов:
Некоторые штуки не доделаны (например лайки для альбомов, более функциональная работа с плейлистами) и будут постепенно дорабатываться.
Бывала у вас когда-нибудь такая ситуация, что кто то, что-то сказал, а ты об этом забыл? Или на пример у вас есть какой-нибудь друг, который говорит что-либо, но уже через минуту переобувается и доказать ему что-либо в дружеском споре почти невозможно?
Могу отметить, что это весьма печальная ситуация, и долгое время я жил примерно так же печально. Но с возрастом меня стали посещать «умные мысли» (да да) …
И так, в чем вся суть ситуации? Еще в то время, когда я играл во всякие игры, я любил записывать некоторые фрагменты своего геймплея, думаю сейчас это все куда более популярно чем сейчас, ведь даже в windows появился свой аналог, о существовании которого я не знал ровно до тех пор, пока не перешел с Nvidia на AMD.
Возможность сохранить последние несколько минут видеозаписи для меня казалась потрясающей и весьма удивительной. Но время шло, и в игры я играть перестал. Однако в один день, будучи опять обманутым постоянно переобувающимся собеседником я все больше и больше стал задумываться: «а нет ли приложения для отложенной записи аудио?». сразу я его не нашел, а писать его самостоятельно мне было лень... Но поискав чуть-чуть получше, я нашел одно такое приложение!
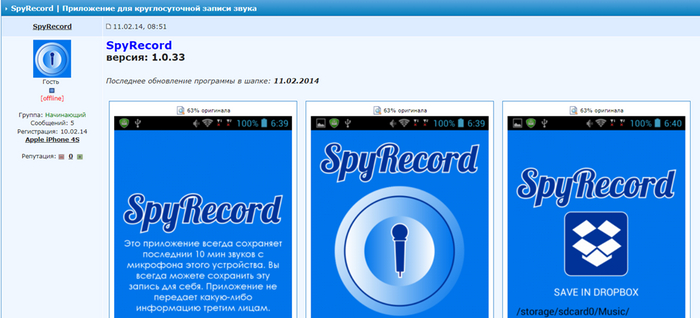
Знакомьтесь! Приложение SpyRecord!
Еще в давние годы я вскрывал приложение и смотрел, как оно работает и мне если честно все понравилось.
Отзыв с 4PDA_wernow:
Удобная минималистичная программа. Пишет в wav, двенадцатисекундными кусками. По достижению 10 минутного интервала, начинает циклично удалять по одному старые (по времени) фрагменты, заменяя их на свежезаписанные.
Записи кладёт на sdcard. Максимально занимаемый объём порядка 60 мегабайт (это если без сохранения). Программа становится в автозагрузку (но это ей можно и запретить) и пишет до тех пор пока вы её не сами не закроете.
Её применение полезно, когда вы целенаправленно не собираетесь ничего писать, не ждёте события/разговора/случайной встречи, но оно вдруг происходит. Вам не придётся кусать локти что не успели это зафиксировать, запомнить.
Склейка фрагментов при сохранении (и соответственно объединения в один файл) пока грешит шовностью, проглатыванием фрагментов, и несколько раз даже перепутало последовательность... Настроек качества записи нет.
Как можно заметить отзыв хороший и программа сама по себе не плоха, но вот только на новых версиях Андроид программа так или иначе полностью перестает работать в фоне и следственно свою основную функцию не выполняет…
Таким образом я вернулся в скучную реальность, но длилось это не долго, ведь буквально вчера я, решившись на конец переделать старый добрый SpyRecord для работы на своей Harmony OS3, наткнулся на решение, которое оставило меня полностью довольным…
Представляю вам Rewind!
Rewind, как описывает его трешбокс: Reverse Voice Recorder, что весьма точно ее характеризует. Сильно радует то, что работает приложение лишь с доступом к работе в фоновом режиме и микрофону. Приложение отображается в строке уведомлений и им можно управлять прямо оттуда.
Да, я сейчас рассказываю про артефакт семилетней давности, однако ничего более свежего я так и не нашел… если вы знаете что-то посвежее, то напишите пожалуйста, что это за приложение такое, а то я нашел только 2 таких из которых одному из них уже больше 10ти лет...
Выбирать время сохраняемой записи можно прямо перед самой записью и после ее начала смело закрывать приложение, оставив его в покое… должен сказать, что я не ожидал, что на моей третьей гармони заработает такое редкое приложение, но вот оно как-то так…
настройки очень простые и работает оно очень просто.
опять же порадовало то, что AppGuard не залочил мне его установку(стандартная функция защиты приложений на Harmony блокирует установку сторонних апк, что порядком надоедает, но Rewind я скачал и он не ругался).
На конец могу отметить, что теперь-то я уж точно… да кого я обманываю, все равно ведь особо ничего не изменится… доброй ночи вам господа. Пойду, займусь чем-нибудь…
Я говорю о качельке громкости на телефоне. Вот она бедолага, туда сюда, туда сюда. Какое видео не включи - у каждого свой уровень громкости. Неужели всех это устраивает? Неужели нет программистов, которые могли бы сделать прогу автоматического уровня громкости? А ещё лучше вшить в ОС изначально? Надеюсь что есть ;)
> ПОЛУЧИТЬ | 34 700₽ 💁🏻♂️ Ableton Live 11 Lite — это урезанная версия со всеми необходимыми рабочими процессами, инструментами и эффектами, но с ограниченным количеством дорожек, но данной версии будет с головой достаточно для начинающих музыкантов или людей заинтересованных в обработке звука.
↘️ Особенности Ableton Live 11 Lite:
– Мощный секвенсор: Создавайте и исполняйте свои музыкальные идеи с помощью интуитивно понятного интерфейса и передовых инструментов для работы с MIDI и аудио.
– Встроенные эффекты и инструменты: Пользуйтесь широким спектром эффектов и инструментов прямо из коробки, чтобы улучшить качество ваших треков и выступлений.
– Поддержка VST и AU плагинов: Расширьте возможности вашего секвенсора с помощью тысяч доступных плагинов, чтобы создать уникальные звуки и обработки.
– Интеграция с популярными DAW: Ableton Live 11 Lite легко интегрируется с другими популярными цифровыми рабочими станциями, что позволяет вам легко обмениваться файлами и сотрудничать с другими музыкантами.
↘️ Обзор возможностей на YouTube:
↘️ ИНСТРУКЦИЯ: 1. Переходим по этой ссылке. ╚ Теперь вводим свою почту 2. Готово, ожидаем сообщение. ╚ Копируем код для активации
2. Теперь загружаем программу. ╚ Создаем аккаунт и вводим код 3. Готово, пользуемся всю жизнь. ╚ Если вас не интересует данная программа, то вы можете получить код на временную почту и поделиться им в комментариях, чтобы сэкономить время Пикабушникам.
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.