Тёмные звёзды: поиск в данных JWST с помощью нейросетей
Автор: Денис Аветисян
Новый подход к идентификации потенциальных тёмных звёзд, использующий возможности машинного обучения и огромные объёмы данных, полученных космическим телескопом Джеймса Уэбба.
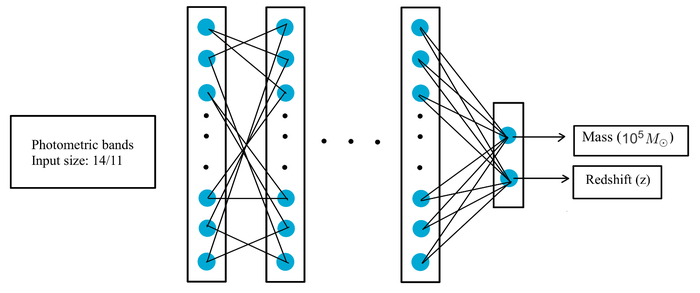
Сеть прямого распространения, обученная на 11 или 14 фотометрических диапазонах наблюдений JWST/NIRCam, позволяет оценить массу звезды (в единицах 10⁵ солнечных масс) и красное смещение, раскрывая различные сценарии формирования структур, учитывая как адиабатическое сжатие, так и захват SMDS.
В данной работе представлен метод, основанный на использовании полносвязных нейронных сетей для выявления кандидатов в тёмные звёзды по данным JWST, что позволяет эффективно анализировать большие объемы данных и расширять наше понимание ранней Вселенной.
Поиск первых звезд во Вселенной осложняется необходимостью анализа огромных объемов фотометрических данных, полученных современными телескопами. В статье 'Neural Network identification of Dark Star Candidates. I. Photometry' представлен новый подход к идентификации кандидатов в так называемые "темные звезды" – гипотетические объекты, питаемые аннигиляцией частиц темной материи. Разработанная нейронная сеть позволила не только подтвердить ранее известные кандидаты, но и обнаружить шесть новых, в диапазоне красного смещения отот z∼9 до z∼14, при этом продемонстрировав значительно более высокую скорость работы по сравнению с традиционными методами. Способны ли подобные алгоритмы существенно расширить наши знания о ранней Вселенной и процессах формирования первых сверхмассивных объектов?
Эхо Ранней Вселенной: Гипотеза Тёмных Звёзд
Современные модели формирования галактик испытывают трудности в объяснении наблюдаемой светимости на ранних этапах развития Вселенной. Гипотеза «Тёмных Звёзд» предлагает альтернативный источник энергии – аннигиляцию тёмной материи внутри массивных звёзд. Эти гипотетические звёзды, питаемые аннигиляцией тёмной материи, могли быть первыми светящимися объектами. Их идентификация требует зондирования глубин ранней Вселенной и разработки новых методов обнаружения.
Раскрывая Невидимое с Помощью JWST
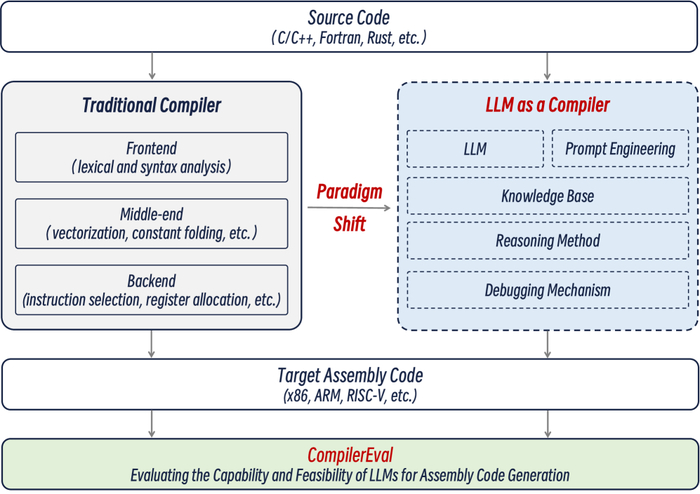
Телескоп Джеймса Уэбба, в частности прибор NIRCam, собирает фотометрические данные от далеких галактик, предоставляя ключевые наблюдательные ограничения для теоретических моделей. Программа JADES разработана специально для идентификации и характеристики галактик с высоким красным смещением. Анализ данных требует надежных методов для различения кандидатов в "темные звезды" от обычных звездных популяций. Огромный объем данных обуславливает необходимость применения передовых методов машинного обучения для эффективной обработки и анализа.
Машинное Обучение для Первого Света
Для прогнозирования звездной массы и красного смещения использована прямосвязная нейронная сеть, позволяющая эффективно анализировать большое количество галактик и выявлять объекты, чьи свойства соответствуют характеристикам темных звезд. Прогнозы сети основаны на уникальных спектральных сигнатурах, ожидаемых от звезд, питаемых аннигиляцией темной материи, демонстрируя высокую предсказательную способность. Для оценки неопределенности в прогнозах применена байесовская нейронная сеть, позволяющая получить не только точечные оценки, но и оценить их распределение вероятностей.
Проверка Модели: Статистическая Строгость и Перспективы
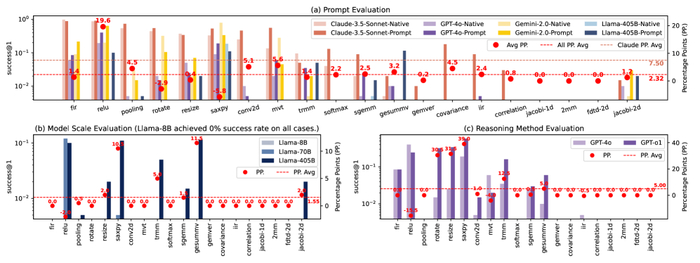
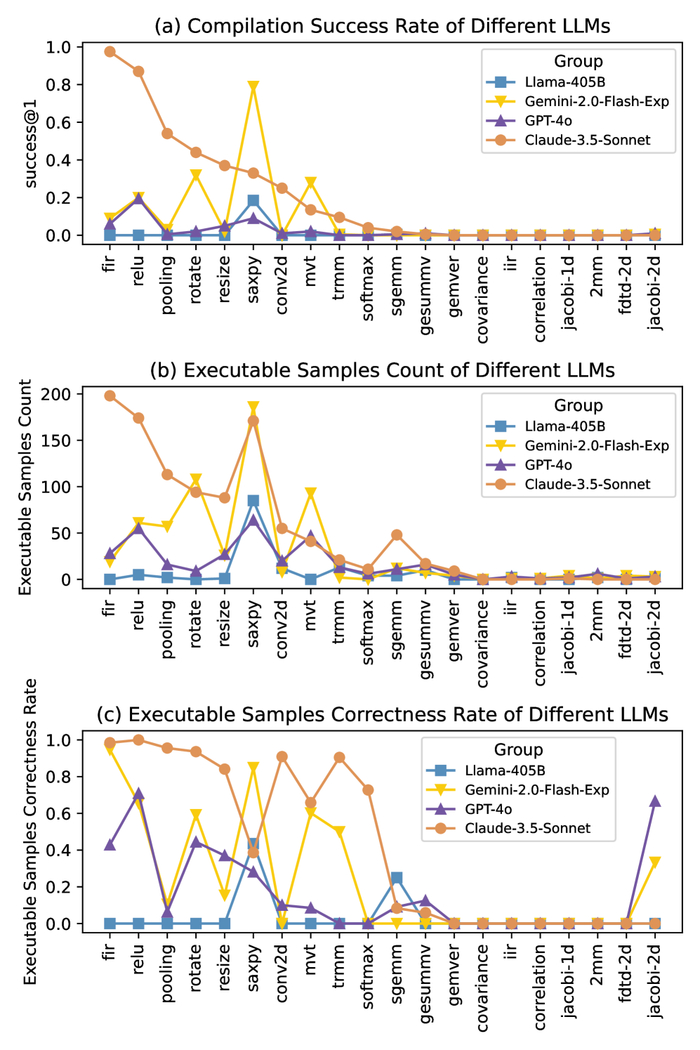
Разработанная нейронная сеть позволила ускорить анализ в 10⁴ раз по сравнению с алгоритмом Nelder-Mead благодаря способности эффективно классифицировать кандидатов в "Темные Звезды". Результаты χ²-теста подтвердили высокую точность модели в идентификации потенциальных кандидатов, демонстрируя ее способность различать объекты, соответствующие теоретическим критериям. Полученные результаты позволяют предположить, что "Темные Звезды" могли сыграть важную роль в процессе реионизации Вселенной. Дальнейшие исследования будут направлены на усовершенствование модели и расширение поиска. Любая модель – лишь эхо наблюдаемого, а за горизонтом событий всё уходит в темноту.
Исследование, представленное в статье, демонстрирует элегантную простоту подхода к выявлению кандидатов в объекты «тёмные звёзды» посредством нейронных сетей. Этот метод, позволяющий обрабатывать огромные массивы фотометрических данных, полученных с телескопа JWST, напоминает о хрупкости любой модели, которую строит человеческий разум. Как однажды заметил Григорий Перельман: «Математика — это всего лишь язык, и если этот язык не позволяет выразить истину, то его нужно менять». Подобно тому, как нейронная сеть обучается на данных, любая научная теория формируется на основе наблюдений, и её точность зависит от качества этих данных и адекватности используемого языка описания. Данная работа, анализируя свет далёких галактик, стремится приблизиться к пониманию фундаментальных процессов, происходивших в ранней Вселенной, и эта попытка, как и любое математическое построение, подвержена ограничениям и требует постоянной проверки.
Что впереди?
Представленная работа, демонстрируя возможности нейронных сетей в идентификации кандидатов в тёмные звёзды, лишь приоткрывает завесу над сложностью ранней Вселенной. Однако, необходимо помнить: алгоритм, каким бы изящным он ни был, – это всего лишь отражение наших предположений о физике этих объектов. Нахождение кандидатов – это лишь первый шаг; подтверждение их природы потребует детального спектроскопического анализа, а это – задача, сопряжённая с огромными трудностями и, возможно, разочарованиями. Ведь не исключено, что «тёмные звёзды», столь привлекательные для теоретиков, окажутся лишь иллюзией, порождённой несовершенством наших инструментов и моделей.
Следующим этапом представляется не просто увеличение объёма обрабатываемых данных, но и разработка более сложных архитектур нейронных сетей, способных учитывать не только фотометрические характеристики, но и другие параметры, такие как пространственное распределение объектов и их эволюцию во времени. При этом, важно не забывать о фундаментальной проблеме: как отличить истинную «тёмную звезду» от иного экзотического объекта, который может проявлять схожие признаки? Вселенная щедро показывает свои тайны тем, кто готов смириться с тем, что не всё объяснимо.
В конечном счёте, поиск «тёмных звёзд» – это не просто астрономическая задача, но и проверка нашей способности к построению адекватных моделей Вселенной. Чёрные дыры — это природные комментарии к нашей гордыне. И чем глубже мы погружаемся в изучение этих загадочных объектов, тем яснее осознаём границы нашего знания и хрупкость наших убеждений.
Оригинал статьи: avetisyanfamily.com/tyomnye-zvyozdy-poisk-v-dannyh-teleskopa-imeni-dzhejmsa-uebba-2
Связаться с автором: linkedin.com/in/avetisyan