0 просмотренных постов скрыто



Что выпускает Яндекс под собственным брендом? Топ-25
Умная колонка Яндекс Станция Лайт с Алисой на YaGPT, 5Вт
Это яркая и компактная умная колонка, которой можно управлять голосом и сенсорными кнопками. Она отлично подойдёт для учёбы и развлечения детей. Внутри живёт виртуальный ассистент Алиса, которая ответит на вопросы маленьких почемучек, поможет решить пример или объяснит сложное правило. А ещё с ней можно поиграть в интересные игры, просто поболтать и даже сочинить собственную сказку.
Теперь Алиса работает с нейросетью YandexGPT, которая позволила улучшить сценарии работы виртуального ассистента №1*.
Помогает вам придумывать идеи, объясняет сложное простыми словами, общается как интересный собеседник - теперь Алиса лучше удерживает контекст разговора и задаёт вопросы, когда хочет что-то уточнить.
Помимо этого, умная колонка украсит интерьер. Матовый корпус приятно держать в руках, а расцветка порадует глаз. У Алисы в Станции Лайт — свой характер, который зависит от цвета устройства. Чтобы пользоваться Станцией Лайт, нужно подключиться к интернету по Wi-Fi и иметь аккаунт на Яндексе. Ссылка на колонку

Яндекс Станция Лайт 2 — новая умная колонка для детей и тех, кто не перестаёт ими быть. Внутри живёт более эмоциональная и функциональная Алиса, с которой никогда не бывает скучно: с ней можно веселиться, делиться секретами, играть и общаться дни напролёт — она найдет ответы на миллионы вопросов, придумает идеи, предложит классные игры, включит любимую музыку. Теперь виртуальный ассистент №1 подстраивает интонацию под ваше настроение и показывает свои эмоции с помощью глазок на LED-экране Станции. В наборе — классные стикеры и маски, чтобы у ребёнка было пространство для творчества. Ссылка на неё

Яндекс Станция Мини 3 — новое поколение самой популярной умной колонки с Алисой, которая поможет продуктивно работать, вести домашние дела и классно отдыхать. Впервые виртуальный ассистент №1* научился понимать и выполнять сразу две команды. Устанавливать и редактировать напоминания или будильники на Станции теперь можно через приложение в телефоне. Корпус умной колонки стал гармоничнее, дизайн часов на LED-экране — современнее, а с новым динамиком музыка звучит сочно и громко. Ссылка на неё

ТВ Станция Бейсик (YNDX-00076) — устройство «два в одном»: умный телевизор с голосовым управлением без пульта и музыкальная Станция с AI-ассистентом Алисой. Диагональ экрана 55 дюймов (139 см).
Технология Farfield обеспечивает распознавание голоса, которое работает на расстоянии. Алиса включит, что попросите: сериал, видео блогера или спортивную трансляцию. ссылка на телевизор
Умная портативная колонка "Яндекс Станция Стрит" с Алисой - это современное и функциональное устройство, которое станет незаменимым помощником в любом месте.
"Станция Стрит" оснащена мощным аккумулятором емкостью 3300 мАч, что обеспечивает до 12 часов автономной работы. Это позволяет использовать колонку в качестве будильника, радио или музыкального плеера без необходимости постоянного подключения к электросети.
Благодаря поддержке Bluetooth 5.0 и Wi-Fi, колонка легко подключается к различным устройствам, включая смартфоны, планшеты и компьютеры. Также поддерживается AirPlay, что позволяет синхронизировать колонки и наслаждаться качественным звуком. ссылка на колонку

Умная колонка Яндекс Станция Макс с виртуальным ассистентом Алисой, мощным звучанием и встроенным хабом управления Zigbee, мощностью звучания 65 Вт, встроенным хабом управления Zigbee, беспроводной связью Wi-Fi (2,4–5 ГГц) и Bluetooth 5.0, с возможностью встраивания в экосистему умного дома — от официального поставщика с гарантией от производителя.
Теперь Алиса работает с нейросетью YandexGPT, которая позволила улучшить сценарии работы виртуального ассистента №1. Ссылка на колонку
Яндекс Станция Дуо Макс — флагманская умная колонка с AI-ассистентом Алисой, операционной системой YaOS X, большим поворотным Full HD touch-экраном с камерой, мощными динамиками и сабвуфером. Смотрите и слушайте что любите, делегируйте домашние и рабочие задачи¹, управляйте умным домом² голосом или касаниями. ссылка на станцию

Базовые удлинённые носки на каждый день. Однотонные, эластичные, из качественного трикотажа. А ещё очень универсальные — подойдут под разные случаи. В них везде комфортно и приятно.
У носков лаконичный дизайн с вышитым логотипом Яндекса. Манжета мягкая и не давит на голень. Есть поддерживающая резинка для свода стопы, которая снижает нагрузку на мышцы. Мы позаботились о том, чтобы носки были удобны как для дома, работы и учёбы, так и для спорта и активного отдыха. Размерная сетка единая для неё и для него. Ссылка на них

Брелок-клавиша с логотипом Яндекса и жёлтой подсветкой, которая загорается при нажатии. Эстетичный и приятный фиджет — антистресс-аксессуар, который поможет расслабиться и украсит ключи, сумку или рюкзак.
Внутри клавиши синий свитч: механический переключатель с тактильной отдачей и кликающим звуком. Кейкап-колпачок съёмный — его можно надевать на другой похожий брелок или использовать прямо в клавиатуре. Основание кнопки полупрозрачное, усиливает эффект свечения при клике. У брелка есть кольцо на цепочке, чтобы прицепить его и носить всегда с собой.
Размеры: 2 × 3 × 9 см. ссылка на него

Кажется, этот робот привёз вам несколько отличных идей и вдохновение для их воплощения: скорее открывайте блокнот и творите!
Если быстро листать страницы, можно увидеть анимацию с роботом-доставщиком. В блокноте можно рисовать и делать наброски, записывать идеи и планы, оставлять любимые цитаты или впечатления дня.
В серию роботов-доставщиков входят магниты, стикерпак, значки, брелоки и даже одежда.
Обложка блокнота сделана из гибкого картона, формат страниц — A5. С легкостью помещается в любой рюкзак, сумку или шопер. Ссылка на него

Коллекция с роботом-доставщиком — то, что поднимет настроение даже в пасмурную погоду. Брелоки с роботами-курьерами спешат украсить ключи, одежду, сумку или рюкзак.
В серию роботов-доставщиков входят магниты, стикерпак, значки, брелоки и даже одежда.
Брелоки сделаны из мягкого и лёгкого синтетического материала, устойчивого к царапинам и влаге. Миниатюрный робот крепко держится на металлической цепочке с кольцом.
Два робота-доставщика на выбор: радостный и влюблённый. Выберите того, кто больше подходит вам или соберите всю коллекцию. Ссылка на брелок

Металлический значок с международным логотипом Яндекса. Крепится на застёжку-бабочку, поэтому никуда не денется и будет держаться ровно. Сделан из латуни и алюминия — не потеряет вид и прослужит долго.
Поверхность значка глянцевая. Для основания выбрали неброский цвет шампань, чтобы не отвлекал от главного и сочетался со всем. Пин будет отлично смотреться на толстовке и худи, футболке и рубашке, даже на пиджаке.
Этот значок — атрибут инноваций и технологий. С ним вы сможете носить частичку Яндекса всегда с собой. Ссылка на него

Этот миниатюрный робот-курьер Яндекса спешит доставить радость вам и окружающим. Он украсит любую одежду, сумку или рюкзак и будет напоминать о современных технологиях.
Робот-доставщик отличный компаньон, поэтому сочетается с другими значками из коллекции Яндекса и не только. Но если вы решите носить его одного, он не расстроится: ведь у него будете вы.
Сделан из металла и холодной эмали. Значок крепко держится на ткани. Возьмите для себя или в подарок тому, кого обрадует собственный робот-курьер. Ссылка на него
Стикерпак из серии «Я на работе». В наборе 12 наклеек: восемь шутливых и знаковых фраз от сотрудников больших компаний и четыре Я, чтобы собирать комбинации. Наклейки помогут привлечь внимание, прояснить рабочие моменты и найти общий язык с коллегами.
Стикеры объёмные, глянцевые и прочные, сделаны из полиуретановой смолы. Основание из клейкого полиэстера, поэтому наклейки надёжно держатся на гладкой поверхности. Стикеры можно приклеить на обложку блокнота или ежедневника, на крышку ноутбука и чехол планшета. Они подойдут для разных случаев корпоративной жизни и не только. ссылка на них

Умная лампочка Яндекс YNDX-00551 - модель светодиодного типа на 806 Лм, которая работает в экосистеме Умный дом Яндекс и управляется Алисой. Режим свечения - сменный. Корпус произведен из прочного, износостойкого пластика. Форма - груша.
• Цоколь - Е27
Подходит для большинства светильников и люстр.
• Цветовая температура - от 2700 до 6500 К
Обеспечивает выдачу естественно белого освещения.
• Низкое энергопотребление
При потребляемой мощности 9 Вт срок службы лампы составляет 15000 часов.
Быстрое подключение к умному дому производится по технологии Matter over посредством Wi-Fi с поддержкой стандартов IEEE 802.11b/g/n. Возможно управление со смартфона посредством голосовых команд. Ссылка на лампу

«Город в деталях» — это набор конструктора, знакомые истории о сервисах Яндекса, только в мини-формате.
Набор про Такси посвящён поездке в аэропорт, с которой начинается путешествие. Всё по-настоящему: узнаваемая жёлтая машина с фирменными виниловыми наклейками, открывающийся багажник, а в качестве героев — водитель и пассажир. А ещё — небольшая сумка: чтобы взять в поездку всё самое необходимое.
В конструкторе — 218 деталей из прочного и безопасного пластика, которые надёжно скрепляются между собой.
Игрушечный набор подходит и для мальчиков, и для девочек. И даже для тех, кто постарше: это интересный и оригинальный подарок для коллекционеров и любителей игрушек. «Город в деталях» совместим с конструкторами других брендов: можно создать целый город с множеством персонажей и разными историями. ссылка на набор

Складной картхолдер для четырёх визиток или карт — банковских, проездных, скидочных. Сделан из удобной и приятной экокожи. Закрывается на магнитную кнопку, чтобы точно ничего не потерять.
Защитит от износа, повреждений и грязи. На сгибе есть углубления, чтобы картхолдер лучше складывался и прослужил дольше. На лицевой стороне вытеснен логотип Яндекса. Картхолдер тонкий и компактный — помещается в карман одежды, сумки или рюкзака. Подойдёт для ежедневного использования, деловых поездок и путешествий. Ссылка на него

Умная лампочка Яндекс YNDX-00558 на 806 Лм - модель светодиодного типа в форме груши со стандартным цоколем Е27, что делает ее универсальной для большинства светильников и люстр. Управление светом можно осуществлять посредством мобильного приложения, голосовых команд, помощника Алиса или сценариев.
• Регулировка цвета свечения в диапазоне RGB и температуры света от 2700 до 6500 К
Дает возможность создать максимально комфортное освещение, подходящее для разных нужд - теплый свет для отдыха или холодный для сосредоточенной работы.
• Показатель мощности 9 Вт и яркость в 806 лм
Позволяет освещать пространства с внушительной площадью или использовать в люстрах, рассчитанных на одну лампу.
Лампа функционирует на протоколе Matter over Wi-Fi, что дает возможность при необходимости работать без интернета. Срок службы модели составляет 15000 часов. Ссылка на неё

Эта бутылка сделана из прочного пластика и вмещает до 500 мл жидкости. С ней вы будете чаще вспоминать о том, как важно пить воду.
Она лёгкая и компактная, поместится в боковой карман большинства рюкзаков, в шопер или спортивную сумку. Берите её с собой на тренировки, в офис или на прогулки.
Прозрачный корпус и крышка, доступная в пяти цветах: белом, жёлтом, красном, сером и чёрном. Вы можете наливать в бутылку не только воду, но и другие напитки: смузи, морс, холодный чай или спортивные смеси. Станет отличным подарком тому, кто старается сохранять водный баланс организма. Ссылка на неё
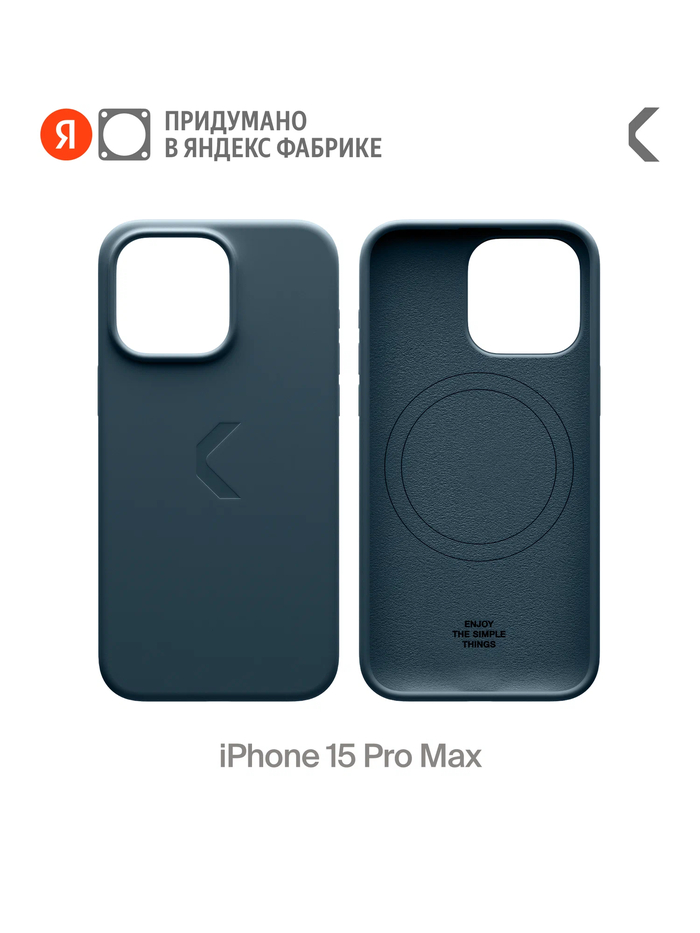
Commo — это бренд аксессуаров для мобильной электроники, придуманный в Яндексе. Shield Case от COMMO — это силиконовый чехол для iPhone 15 Pro Max с поддержкой беспроводной зарядки. Он создан из высококачественного силикона, поэтому приятен на ощупь и обеспечивает комфортное использование. Благодаря своей текстуре чехол не скользит в руках, надёжно фиксируется и при этом не выглядит громоздким — сохраняет стильный вид смартфона. Его легко снимать и мыть, что обеспечивает удобство в уходе.
Для каждой модели представлена фирменная палитра цветов, позволяющая подобрать чехол по вкусу. Shield Case надёжно защищает смартфон от царапин и лёгких ударов, сохраняя его внешний вид. Поддержка беспроводной зарядки позволяет использовать все возможности вашего iPhone, не снимая чехол. ссылка на него

Умный сенсорный Wi-Fi выключатель позволяет управлять световыми приборами с помощью мобильного приложения или голосовым помощником Яндекс Алиса.
Мощность нагрузки - 1000 Вт!
• Выключатель двойного действия - его можно подключить как без нуля с конденсатором (идет в комплекте), так и С нулем или заземлением если они у вас есть (подойдет либо земля либо ноль, без разницы!)
• Выключатель прекрасно работает с Алисой через связку Яндекс и любым из приложений Tuya Smart / Digma Smart / Smart Life.
• Свет можно включать нажатием на круглую сенсорную кнопку с подсветкой, либо голосом. Алиса управляет каждой группами света отдельно, можно называть их как угодно и добавлять в сценарии. Также можно делать из них переключатели через сценарии в приложении Tuya.
• Размер стандартный - 86х86мм, встаёт в обычный круглый подрозетник, глубина посадочного места 25мм, диаметр 50мм, подключение элементарное, вместо вашего выключателя (нужно всего 2 провода - фаза от щитка и фаза на светильник, и ноль \ земля если есть)
• При варианте подключения без нейтрального провода необходима установка конденсатора. Он идёт в комплекте с выключателем! Ссылка на него
Умная лампочка Яндекс YNDX-00556 (RGB, Matter over) на 806 Лм - модель светодиодного типа с цоколем GX53, который совместим с большинством светильников, рассчитанных для фиксации в подвесные и натяжные потолки. Цвет свечения - многоцветный. Корпус плоской формы выполнен из прочного, износостойкого пластика.
• Цветовая температура, варьирующуюся в пределах от 2700 до 6500 К
Дает возможность организовать теплое освещение или холодный свет для выполнения важных дел.
• Потребляемая мощность - 9 Вт
Лампа отличается долгим сроком службы - до 15000 часов.
Возможна интеграция с системой Умный дом. Быстрое подключение производится посредством Wi-Fi. Возможно управление лампой через мобильное приложение, посредством голосовых команд или создания сценариев с Алисой. ссылка на лампы

Умная лампочка Яндекс YNDX-00557, работающая с Алисой, позволяет расширить систему умного дома. Модель представлена в пластиковом корпусе в форме свечи. Показатель мощности 6 Вт и световой поток 520 лм гарантируют высокую степень яркости для освещения помещений с небольшой площадью (прикроватной и рабочей зоны).
• Цоколь Е14
Дает возможность осуществлять вкручивание в разные светильники.
• Возможность изменения цвета свечения в RGB-диапазоне
Помогает создать разные атмосферные условия для настроения: фиолетовое - для детской комнаты, синее - для проведения досуга, режим Вечеринка - для времяпрепровождения с друзьями.
• Настройка цветовой температуры от 2700 до 6500 К и яркости
Позволяет установить теплое освещение для отдыха или холодное для сосредоточенной работы.
Управление лампой может производиться несколькими способами: голосовые команды, мобильное приложение, специальные сценарии. Устройство функционирует с протоколом Matter over Wi-Fi, что позволяет интегрировать его в умный дом и использовать настроенные параметры при отсутствии сети. Ссылка на неё

Умная лампочка Яндекс YNDX-00559 (RGB, Matter over Wi-Fi) обеспечивает комфортное управление светом в помещении посредством системы Умный дом. Модель отличается рефлекторной колбой, на внутренней стороне которой нанесено светоотражающее покрытие.
• Цоколь GU10
Рассчитан для потолочных, настенных светильников и интерьерной подсветки.
• Подключение к умным девайсам
Дает возможность создавать сценарии.
• Экономная эксплуатация
Срок службы лампы достигает 15000 часов при мощности 4,9 Вт.
• Световой поток 520 лм
Свидетельствует о том, что ламп излучает яркий свет.
Модель можно настраивать на разные цвета свечения от 2700 до 6500 К. Управление параметрами настройки осуществляется через приложение Дом с Алисой или Яндекс Станцию. ссылка на лампочку
Игрушечный робот-доставщик Яндекса — теперь радиоуправляемый, с радиусом перемещения до 25 метров. Маневрирует во все стороны, умеет светить фарами и открывать багажник, чтобы доставлять радости.
Робот предназначен для помещений, но готов ездить и на улице, если погода хорошая, а поверхность ровная. Управляется стиком на пульте управления: удобно держать одной рукой, есть крепление на запястье. Багажник открывается и закрывается отдельными кнопками.
Особенности игрушки:
• работает от аккумуляторов, они уже установлены
• заряжается через провод
• одной зарядки хватает на 1,5 часа
• полностью заряжается за 3 часа. ссылка на игрушку
Показать полностью
20
4

В машинах Lada решили сделать автозапуск и открытие багажника голосом

Именно так я себе это представляю
Систему удаленного запуска двигателя предполагается интегрировать в приложение Lada Connect, которое презентовали вместе с новинкой Lada Iskra. На данный момент автозапуск находится в высокой степени готовности и «идет доводка систем», отметил представитель предприятия.
Помимо этого, АвтоВАЗ работает над тем, чтобы расширить функционал голосового управления, например, для того, чтобы можно было использовать голос для открытия багажника или включения света.
Подробнее
Показать полностью

Как голосовой робот увеличил посещаемость вебинара на 30%: кейс Unibell
Разберём, почему звонок эффективнее письма, как голос влияет на решение участвовать и как повторить этот результат в вашем бизнесе.
🎯 Проблема: интерес есть, участия нет
Компания-клиент регулярно проводила вебинары. База — 5500 контактов, знакомых с брендом, но регистрация не достигала даже половины базы, а фактическая посещаемость была ниже прогнозов.
💡 Решение: голос вместо текста
Unibell предложила использовать голосового робота с распознаванием речи.
Как это работало:
📞 Сценарий звонка:
«Привет, звоню пригласить тебя на вебинар "Как создать и эффективно развивать партнерскую сеть". Чтобы зарегистрироваться, скажи «да». Ждём всех! Приведи друга – получите по 10% скидки.»
Скорость обзвона: 5000 номеров в час.
Интеграция с CRM для учёта откликов в реальном времени.
Логика обработки ответов «да», «нет», «позже» с маршрутизацией на регистрацию или повторный контакт.
📊 Результат
Рост посещаемости на 30% всего за три часа после старта обзвона.
🔹 63 человека зарегистрировались сразу после звонка, без дополнительных писем и напоминаний.
🔹 Средняя стоимость регистрации снизилась почти вдвое благодаря высокой конверсии автообзвона.
🔍 Почему голос эффективнее текста
Персонализация в моменте.
Голос создаёт эффект диалога. Даже понимая, что звонит робот, человек слышит обращение по имени и живую речь, что сильнее вовлекает, чем текст.Мгновенное действие.
Для регистрации достаточно сказать «да» во время звонка. Без ссылок, форм и переходов — минимальный порог входа превращает сомневающегося в участника за секунды.Триггер скидки за друга.
Фраза «Приведи друга – получите по 10% скидки» одновременно повышает ценность участия и запускает микроэффект сарафанного радио.Автоматизация без потери человечности.
Обзвон 5000 контактов за час невозможен силами менеджеров. Робот сделал это мгновенно, сохранив персональный подход и разгрузив отдел маркетинга.
💡 Как применить в вашем бизнесе
🔹 Приглашайте на мероприятия голосом — это повышает конверсию.
🔹 Используйте call-to-action без лишних действий (например, «Скажите «да» для регистрации»).
🔹 Встраивайте мотивацию: скидка за друга, подарок за участие, доступ к эксклюзивным материалам.
🔹 Интегрируйте автообзвон с CRM, чтобы сразу видеть результат и планировать дальнейшие коммуникации.
В мире, перегруженном текстом, голос становится редким и ценным каналом коммуникации.
Подумайте:
Где именно в вашей воронке продаж «живое» приглашение заменит текст?
– При подтверждении встреч?
– При приглашении на закрытые распродажи?
– При возврате «тёплых» лидов, которые перестали отвечать?
Как показал кейс Unibell, голос не только напоминает — он мотивирует действовать.
Показать полностью
Олеса
Субботним утром еле тащимся в пробке по трассе к северу от СПб. Перекидываемся отдельными фразами с женой... Навигатор на её телефоне показывает, что эта бадяга растянулась на 5 километров... Тоска! Проползаем мимо какой-то автомастерской, машинально читаю вслух название вывески с отвалившейся заглавной буквой "к": "..олеса". Продолжаем неспешный разговор... Совершенно неожиданно в кабине, раздается приятный женский голос:
- Я собственно не понимаю о чём вопрос?
Я: ??! Да, собственно ни о чём. Просто с женой разговариваю!
- А как зовут ваши жену?
Я (предвкушая возможность развлечься в пробке): Забыл!
- В следующий раз записывайте на бумажке!
Я: Спасибо за совет! Я в следующий раз, когда буду жениться, запишу имя в паспорт!
- Очень рада, что смогла Вам помощь!
Я: А уж как рад я возможности пообщаться с приятной собеседницей!!
Диалог решительно прерывает моя жена, она выключает телефон и объясняет, что это на произнесённое мой "...олеса", в её телефоне активизировался голосовой помощник...
Я: А ведь ты меня к ней приревновала!
...ползём дальше, но уже в немного приподнятом настроении
Показать полностью

Как я телефонным мошенникам давление поднял (Новый способ мошенничества?)
Сегодня, пока я работал, на мой телефон поступил звонок по WhatsApp с незнакомого номера. По работе у меня это случается часто - звонят коллеги с других филиалов, что-то запрашивают или советуются - в общем, рутина. Но, подняв трубку, я услышал:
- Рамирес Кунович, здравствуйте! - сказала девушка на чистом русском
- Здравствуйте...
- Звоню из сортировочного центра Почты России, на ваше имя отправлено письмо из Федеральной Налоговой Службы, но нет конечного адреса - нужно его указать. Пользуетесь приложением почты России?
Я слегка опешил, но чуйка сработала не сразу - мне действительно некоторое время назад приходило письмо от ФНС неизвестного содержания, которое я не успел забрать с почты, и его утилизировали. Стыд за мою гражданскую безответственность снова вызвал у меня смешанные чувства.
- Ну да... Есть, сейчас я зайду...
- Да, заходите в приложение, я сейчас отправлю уведомление и вас "проведу" чтобы вы указали адрес.
Однако, в этот момент я начал что-то понимать, и очень кстати забарахлила связь - рабочий вайфай снова отвалился, и звонок, превратившись в сперва в молчание и гудки, оборвался.
Я понял: "Походу, мне звонили мошенники. Кто ещё будет по ватсапу звонить и объяснять куда заходить в приложении?"
Я загуглил и убедился, что какие-то разводы с Почтой России и правда существуют.
Кроме шуток, хоть какого-нибудь звонка от мошенников я ждал давно, потому что мне нравится пробовать над ними глумиться - но тонко это ни разу не получалось. Вопросы про Крым и украинский акцент уже как-то приелись всем) Да и украинского акцента в этот раз не было.
Но... она мне позвонила снова!
- Извините, оборвалась связь. У вас получилось посмотреть отправление в приложении?
- Ну, я так и не зашёл...
- Заходите, посмотрите, есть ли там уведомление.
Я ради интереса зашёл - ничего там не было.
- Ничего нет...
- Попробуйте закрыть приложение, сбросить его свайпом, зайти снова. Такое бывает, что информация не сразу подгружается.
- Нет, всё равно ничего не появилось.
Ничего и правда не было. Удивительно?
- К сожалению, такое бывает. Значит, вы можете посмотреть информацию и указать данные через нашего официального бота. Это удобно, он работает в Телеграм. Готовы?
- Ну... Давайте. Что за бот?
И она продиктовала бота, предложила объяснить, как его найти, но я уже нашел - в Гугле. Первой ссылкой была статья о новом виде мошенничества. Тут у меня сложился не только паззл, но и стопроцентная уверенность, что меня пытаются развести. Значит, надо провести "профилактику".
- Получилось?
- Да... Девушка, а вы знаете, что голос каждого человека уникален?
- Что вы имеете в виду? Кажется, вас плохо слышно...
- Ну смотрите. Голос каждого человека уникален, как отпечаток пальцев - и ни помехи, ни разные технические средства - разные микрофоны, например - не мешают голос определить. У каждого голоса своя неповторимая цифровая сигнатура.
- К чему вы это мне говорите? - Она пыталась сохранить лицо, не выдавая напряжение
- Ну смотрите. Мы с вами вот говорим сейчас. А по вашему голосу формируется цифровой векторный эмбеддинг. Он будет в базу внесён. Это приложение такое специальное. А в ближайшие год-полтора каждый, кому вы будете звонить, будет видеть и слышать, что говорит с мошенником, откуда бы вы и с какого бы номера ни звонили.
...
*Пять секунд тишины*
- Зачем вы это всё говорите?! - теперь она уже еле сдерживалась, и визжащие нотки в её голосе были с явным трудом подавлены
- Да просто так. Спасибо вам за звонок.
Трубку эта курица бросила сама.
P. S.
Я покопался в сети, спросил всем известную нейросеть и оказалось, что технологии, которыми я устрашал неизвестную мошенницу, уже есть: голос каждого человека действительно уникален, его можно с высокой точностью распознать, и этим уже пользуются крупные банки, Яндекс.Алиса и много кто ещё.
Но нет такого приложения, которое по голосу определяло бы, что "с вероятностью 96% с вами говорит мошенник" и уведомляло об этом. А жаль.
Показать полностью

