Меня зовут Алексей, и я создатель нового сервиса под названием CyberEducate. Хочу рассказать вам об этом проекте от первого лица.
Многие из вас наверняка хотели изучить какую-либо тему или нишу, чтобы получить новые знания и навыки. Однако зачастую вас останавливали не сложность самого процесса или нехватка времени, а дикие ценники от так называемых "бизнес-инфлюенсеров". Не все, но большинство этих товарищей втридорога продают публичную информацию, которую можно легко найти в открытых источниках.
Разве нормально платить бешеные деньги за то, что и так доступно каждому? Я считаю, что знания должны быть доступны для всех без исключения, независимо от размера кошелька. Именно поэтому я создал CyberEducate - платформу, которая избавит вас от необходимости переплачивать инфобизнесменам, онлайн-школам и т.д.
Сервис создан на базе ChatGPT, способен автоматически создавать достаточно качественные обучающие курсы по любой тематике на основе публичных данных. Причем делает это быстро, эффективно и за смешные деньги по сравнению с ценниками инфоцыган. Пока достигнуты следующие результаты - Программа курса генерируется в зависимости от темы курса и нагрузки на текущий момент - от 10 сек до 30 секунд. На генерацию каждого урока уходит от 30 сек до 1 минуты. Есть идеи как еще ускорить генерацию, пока в процессе.
Именно этим я и руководствовался, когда придумывал концепцию CyberEducate.
Это сервис, который позволяет создавать полноценные онлайн-курсы с нуля в кратчайшие сроки и с минимальными усилиями.
ИИ конечно еще далеко не идеален, иногда пытается генерировать всякую чушь, но в целом уже сейчас работает не плохо.
Курсы реально можно генерировать по любой тематике - от вязания, кулинарии и техники знакомств, до квантовой физики, программирования и тактике игры в CS2 ))))
Как "оно" работает:
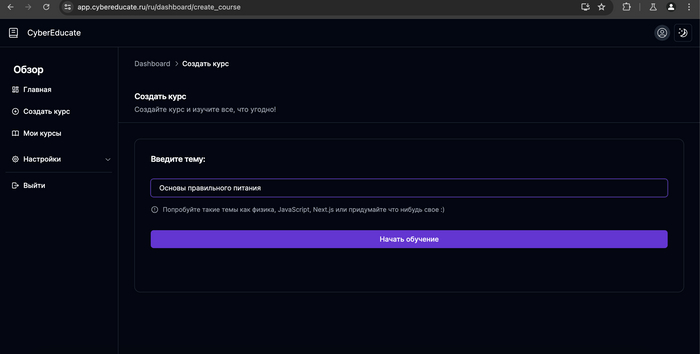
Вбиваем интересующую Вас тему, например - Основы правильного питания
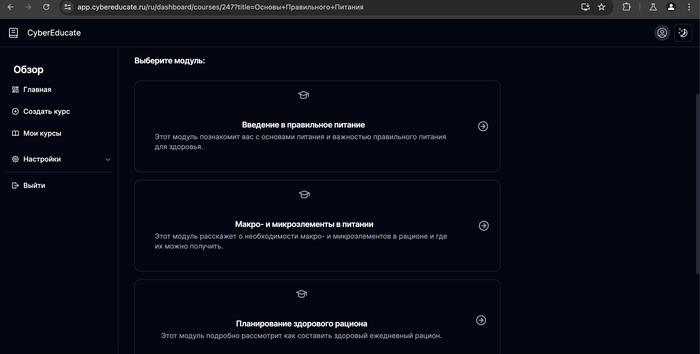
Получаем программу курса из 4 модулей
По 5 уроков в каждом из модулей
Генерируем урок и впитываем знания))
Более того, в планах добавить массу дополнительных возможностей по кастомизации курса, адаптации его под разные уровни сложности, добавлению мультимедийных материалов, тестовых занятий, и прочее
Сейчас, когда проект находится на начальной стадии, у меня есть уникальный шанс напрямую пообщаться с первыми пользователями и услышать их обратную связь.
Буду рад конструктивной и не очень критике, замечаниям, пожеланиям.
И да, это мой первый самостоятельно написанный проект и сделан в одно лицо на коленке с помощью Chatgpt и огромного количества кофе, но и при этом он как то работает)))) Так что я криворукий мудак-самоучка, цены-конь, и прочее - я в принципе и сам знаю, но не смогу отказать Вам себя порадовать этим, так что даже с такой критикой - велком!
Поэтому я призываю вас не стесняться и активно делиться своими впечатлениями, идеями по улучшению и пожеланиями.
После регистрации доступно создание 1 курса бесплатно, так что каждый может попробовать.
Поговаривают, что в некоторых компаниях сотрудники уже не понимают, что происходит в коде проекта. Де-факто для коллективной работы картография проекта — необходимость, нежели привилегия...
Составление пояснений и комментариев к обширным ИИ-системам — трудоемкая задача, но под небольшие опен-сорс/продакшн проекты есть решение.
AutoDocstring — инструмент, который автоматически создает документацию к коду на основе структуры и комментариев. Экономия времени, согласованность стиля, адекватная читаемость и повышенную точность документации — плюсы этого тула. Выделил нужный блок кода, прожал ctrl+shift+2 — готово.
Просматривать строки документации можно во вкладках, выбирать типы форматов строк, выводить типы параметров через подсказки типов pep484, значения и имена переменных. Внутри поддержка args, kwargs, декораторов, ошибок и типов параметров.
Теперь в утилиту можно добавлять "кастомные" документации. Чтобы использовать собственный шаблон, создайте файл .mustache и укажите путь к нему с помощью конфигурации customTemplatePath.
Сгенерированная документация содержит структурированные описания функций, методов и классов. Однако AutoDocstring не всегда правильно интерпретирует комментарии в коде или не учитывает особенности некоторых языков программирования.
А еще записи могут не соответствовать стандартам или требованиям проекта.
Поэтому редактировать и редактировать. Но для создания костяка описаний инструмент — идеально. AutoDocstring сократит время, затрачиваемое на написание документации, на 30-50%. А еще неплохо так снизит число ошибок в тексте.
Несмотря на капризы погоды, лето неумолимо приближается. Значит, занятия в спортивном зале или домашние тренировки получится заменить на активности под открытым небом. Собрали для вас товары, которые сделают уличные воркауты интереснее, увлекательнее и полезнее.
Мегамаркет дарит пикабушникам промокод килобайт. Он дает скидку 2 000 рублей на первую покупку от 4 000 рублей и действует до 31 мая. Полные правила здесь.
В компактную поясную сумку поместятся телефон, ключи, кошелек или другие нужные мелочи. Во время тренировки все это не гремит и не мешает, но всегда находится под рукой. Материал сумки прочный и влагонепроницаемый, вещи в ней защищены от повреждений, царапин или пота.
С фитнес-резинкой можно тренировать все группы мышц: руки, ноги, кор, ягодицы. А еще она облегчает подтягивания и помогает мягко растягиваться. В сети можно найти огромное количество роликов с упражнениями разной степени сложности. Нагрузка легко дозируется: новичкам подойдет резинка с сопротивлением до 23 кг, опытным атлетам — до 57 кг. При этом оборудование максимально компактно и поместится даже в небольшую сумку.
Для тех, кому надоели обычные тренировки. Слэклайн — это стропа шириной 50 мм, с помощью которой осваивают хождение по канату. Тренажер учит сохранять баланс, прокачивает координацию и концентрацию, а еще дает отличную нагрузку на спину, руки и ноги.
Настольный теннис — простой в освоении вид спорта, который отлично помогает размяться и тренирует скорость реакции. В комплект входят две ракетки, три мяча, сетка, накладка и чехол — все, что нужно, чтобы поиграть вечером во дворе с другом или устроить небольшие соревнования. Этот недорогой набор подойдет именно для развлечения и веселья, устанавливается почти на любой стол.
Еще один вид спорта, которым можно заниматься, даже не имея серьезной подготовки — бадминтон. С набором от Wish Steeltec вы сможете потренировать силу удара, побегать и просто хорошо провести время. Детали яркие, так что их трудно потерять даже на природе. Леска натянута прочно, ресурса ракеток должно хватить не на один сезон.
Фрисби воспринимается как простое пляжное развлечение. Тем не менее перекидывание друг другу тарелки задействует все группы мышц и развивает скорость реакции. Эта тарелка летит далеко и по понятной траектории — отличный снаряд для начала. Кстати, фрисби — это еще и ряд спортивных дисциплин со своими правилами и техническими сложностями, так что игра с друзьями может перерасти в серьезное увлечение.
Стильный мяч из износостойкой резины отлично подходит для уличных тренировок. Вы сможете поиграть компанией в баскетбол или стритбол или просто отработать броски. При производстве используется технология сбалансированного сцепления: это значит, что снаряд не сбежит от вас и будет двигаться по стабильной траектории.
Футбол — один из самых популярных в России видов спорта. Играя, можно отлично побегать, потренировать меткость и отработать взаимодействие в команде. Футбольный мяч Torres Striker выполнен из качественного полиуретана и резины и выдержит не один десяток матчей, не потеряв упругости. Отличная балансировка и оптимальный размер делают его подходящим как для взрослых, так и для подростков. Он достаточно тяжелый, почти как в профессиональном спорте, так что совсем малышам не понравится.
Пляжный или обычный волейбол? А может быть, пионербол, как в детском лагере? Мяч TORRES SIMPLE COLOR подойдет для любой из этих игр. Камера отлично держит давление, поэтому вам не придется постоянно подкачивать его, а качественные материалы (полиуретан и бутил) сохраняют все характеристики даже при интенсивном использовании.
Многоскоростной велосипед с рамой 19-го размера подойдет как мужчинам, так и женщинам. Это отличный вариант для новичков: модель доступная, удобная. Поможет понять, нравится ли вам велоспорт. Конструкция велосипеда позволяет ездить по дорогам разных типов, поэтому вы сможете перемещаться по городу или отправиться в поход. Есть складной механизм — велосипед с ним легко возить в машине, на электричке и просто хранить в кладовке.
Более продвинутая модель для тех, кто уже оценил прелесть движения на двух колесах. Геометрия велосипеда предполагает вертикальную посадку. Это обеспечивает более удобное положение тела, чем на других байках. В конструкции предусмотрены детали для комфорта и безопасности: пружинная вилка с ходом 100 мм, сервисная подводка тросов и дисковые гидравлические тормоза.
Если вы не фанат велоспорта, но хотите получить свою дозу физической нагрузки, перемещаясь по городу, выбирайте самокат. В модели PLANK Magic 200 есть регулировка руля по высоте, надежные тормоза и прочная увеличенная дека из алюминия. Когда вы катаетесь на самокате, работают мышцы ног, ягодиц, спины и живота, а заодно добираетесь, куда нужно. Если вы решите сделать паузу в тренировках, самокат легко складывается для хранения.
Любая активность на свежем воздухе требует хорошей обуви, специально сделанной для занятий спортом. Яркие кроссовки Hoka RINCON 3 с облегченным весом амортизируют, снижают нагрузку на суставы. Выраженный рельеф подошвы обеспечивает сцепление с поверхностью вне зависимости от того, где проходит тренировка: на специальной площадке, асфальте или грунте.
Легкие женские кроссовки из линейки Clifton подходят для занятий на твердых покрытиях. Дышащий сетчатый верх поддерживает вентиляцию стоп, чтобы можно было тренироваться даже в жару. Подошва из легкой пены EVA гасит силу ударов. Кроссовки беговые, подходят для тренировок на длинных дистанциях.
Во время занятий на свежем воздухе важно защитить голову от перегрева. С этим отлично справится легкая и светлая бейсболка — например, от GLHF. Она удобно сидит на голове, не сваливается и не отвлекает от занятий, благодаря сетке голова меньше потеет. Козырек жесткий и не мнется.
Не забудьте защитить кожу от солнца — чтобы не было мучительно больно на следующий день после тренировки под открытым небом. В этом поможет крем против пигментных пятен с сильной защитой от ультрафиолета SPF50. Водостойкая текстура легко наносится и быстро впитывается, действует два часа — потом крем нужно обновить.
Удобные и стильные солнцезащитные очки защищают глаза благодаря фильтру UV400, который поглощает до 99.99% ультрафиолета. Они выполнены из легких материалов и плотно прилегают к голове. Ударопрочные поликарбонатные линзы с антибликовым покрытием подходят для разных видов спорта.
Используйте промокод килобайт на Мегамаркете.Он дает скидку 2 000 рублей на первую покупку от 4 000 рублей и действует до 31 мая. Полные правила здесь.
Реклама ООО «МАРКЕТПЛЕЙС» (агрегатор) (ОГРН: 1167746803180, ИНН: 9701048328), юридический адрес: 105082, г. Москва, ул. Спартаковская площадь, д. 16/15, стр. 6
Современные навыки хакеров превосходят все и вся. Вирусы в картинках, взломы баз данных пользователей, прозвоны, фишинг, ботнеты, программы - вымогатели и многое другое.
Наша цель заключается в том, чтобы достичь безопасного хранения данных на вашем компьютере или телефоне. Наверняка вы слышали, что пароли не стоит хранить в телефоне или в компьютере, так как в том случае, если злоумышленники получат доступ к вашим устройствам, то они спокойно смогут войти в ваше соц. сети, а если у вас еще и ко всем аккаунтам на разных платформах одинаковые пароли, то тут даже без комментариев о том, что может быть..
Перейдем к сути.
Существует много способ для безопасного хранения и передачи информации.
Их можно разделить на две категории: 1) криптография 2) стеганография
Каждая из этих категорий имеет подкатегории: 1.1 симметричное шифрование 1.2 асимметричное шифрование 1.3 хеширование (одностороннее шифрование без возможности дешифрования. Эта подкатегория нам не подходит) 1.4 гибридное шифрование 2.1 классическая стеганография 2.2 компьютерная стеганография 2.3 цифровоя стеганография Данные подкатегории делятся еще на подкатегории, но это уже тема для отдельной статьи.
Сегодня мы будем разбирать раздел криптографии и асимметричное шифрование.
Раскрытие категории:
Криптография - наука изучающая методы шифрования информации и их использование. Асимметричное шифрование (RSA - Rivest, Shamir, Adleman) - шифрование данных с помощью двух ключей, один из которых - открытый, а другой - закрытый.
Весь процесс шифрования и дешифрования происходит на основе математических формул и чисел. Пугаться не нужно, ничего сложно в этом нет.
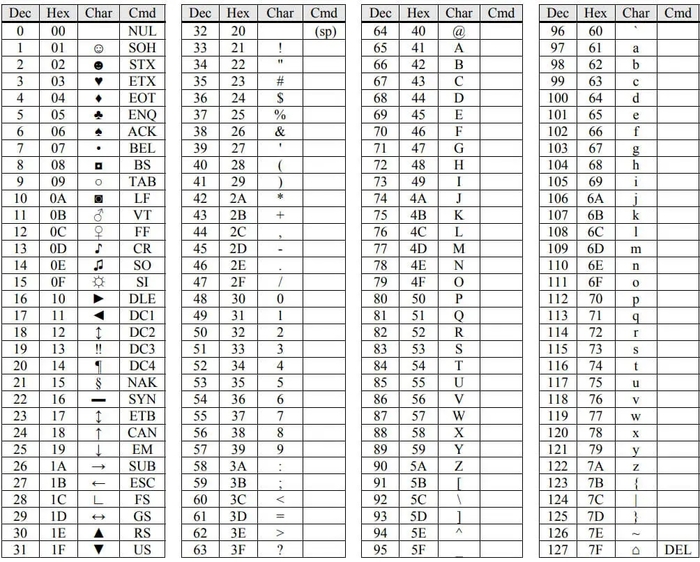
Алгоритм: 1) Генерация двух простых чисел p и q. 2) Вычисление значения n, где n = pq. 3) Вычисление функции Эйлера. F = (p-1)(q-1). 4) Генерация экспоненты e, являющийся взаимно простым с F. (Наибольший общий делитель двух чисел равен 1) 5) Вычисление значения d, такое что (d*e) % F = 1. (% - остаток от деления) Совокупность e и n является открытым ключом, а совокупность d и n – закрытым ключом. Для шифрования информации необходимо преобразовать символы в числа удобным вам способом. Можно воспользоваться таблицей символов ASCII (смотреть скришот ниже) и использовать числовые значения для букв в столбике "DEC". Более простым способом является создание своих числовых значений для букв(A-1, B-2, C-3 и т. д.)
После преобразование всех символов в числовые значения начинаем их шифровать с помощью алгоритма написанного выше. *Для удобства, числовое значение каждой буквы можно раделять точкой. *
Для шифрования сообщения:C = m**e%n Для дешифрования сообщения:m = C**d%n m - числовое значение символа Пример: Возьмём слово "шифр". Алфавит: ш-12; и-18; ф-23; р-54 p = 3 q = 5 n = 3 * 5 = 15 F = (3-1) * (5-1) = 8 e = 7 (*gcd(7, 8) = 1) d = 7 ((7*7) % 8 = 1) *gcd - функция проверки того, что два числа являются взаимно простыми Процесс шифрования: Шифруем каждое числовое значение символа: 12 -> 12^7%15 = 3 18 -> 18^7%15 = 12 23 -> 23^7%15 = 2 54 -> 54^7%15 = 9 Зашифрованное сообщение: 3.12.2.9 Процесс дешифрования: Дешифруем зашифрованные числовые значения букв: 3 -> 3^7%15 = 12 12 -> 12^7%15 = 18 2 -> 2^7%15 = 23 9 -> 9^7%15 = 9 Сопоставляем буквы в соответствии с кодами из алфавита (ш-12; и-18; ф-23; р-54) и получаем слово "шифр"
Важно соблюдать порядок зашифрованных кодов букв, иначе при дешифровке сообщение будет просто набор символов.
@tehnoin
Уже занимаюсь разработкой по внедрению данного алгоритма в телеграмм бота, который будет в абсолютно открытом доступе.
Всем привет) сегодня напишем программу для нахождения первых n чисел Фибоначчи и увидим одну из примечательных особенностей специального символа end. Приступим)
Первоначально пройдемся по теории. Числа Фибоначчи — это последовательность чисел, которые задаются по определённому правилу. Оно звучит так: каждое следующее число равно сумме двух предыдущих. Первые два числа заданы сразу и равны 0 и 1.
На Python существует несколько разновидностей реализации алгоритма нахождения, но мы рассмотрим в рамках этой статьи самый простой. Начнем наш ряд с единицы. Если вы захотите поделиться своей версией алгоритма то можете опубликовать в комментариях)
Приступим к реализации, для начала создадим 2 переменные fib1, fib2 и присвоим им первоначальные значения, обе будут равны единице:
fib1 = fib2 = 1 # первоначальные значения fib1 и fib2
Далее спрашиваем у пользователя сколько чисел необходимо вывести, записываем в переменную n как тип данных int.
fib1 = fib2 = 1 # первоначальные значения fib1 и fib2
n = int(input("Введите количество выводимых чисел: ")) # присваиваем пременной n значение количества выводимых цифр
Выводим первоначальные числа которые записаны в переменные fib1 и fib2, заметим что в конце используем символ end, в данном случае он вставляет пробел между строками и предоставляет нам возможность продолжить дополнять текст в одну строку.
fib1 = fib2 = 1 # первоначальные значения fib1 и fib2
n = int(input("Введите количество выводимых чисел: ")) # присваиваем пременной n значение количества выводимых цифр
print(fib1, fib2, end = " ") # выводим первые 2 числа
Создаем цикл для поиска остальных чисел от 2 (так как 2 первых значения уже есть) до n (количество выводимых чисел, не забываем про ошибку на еденицу)
fib1 = fib2 = 1 # первоначальные значения fib1 и fib2
n = int(input("Введите количество выводимых чисел: ")) # присваиваем пременной n значение количества выводимых цифр
print(fib1, fib2, end = " ") # выводим первые 2 числа
for i in range (2, n): # и так как первоначальные значения уже вывели продолжим с двух
Теперь подходим к самому главному выражению в цикле, присваиваем fib1 будет равно fib2 а fib2 = fib1 + fib2 таким образом при каждой итерации цикла fib2 будет равняться предыдущее число + текущее. Отступы в цикле обозначил как " > > "
fib1 = fib2 = 1 # первоначальные значения fib1 и fib2
n = int(input("Введите количество выводимых чисел: ")) # присваиваем пременной n значение количества выводимых цифр
print(fib1, fib2, end = " ") # выводим первые 2 числа
for i in range (2, n): # и так как первоначальные значения уже вывели продолжим с двух
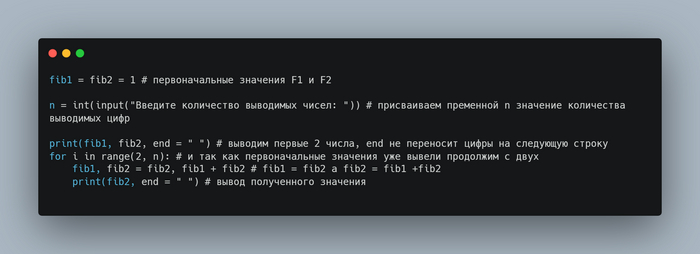
> > print(fib2, end = " ") # вывод полученного значения
Запускаем код и любуемся результатом:
Все наша программа готова! Знаю что можно написать ее другими способами (рекурсией) но решил объяснить через циклы так как для новичков это проще. Ниже опубликовал картинку с кодом.
Картинка с кодом
Также можно поиграться с кодом в онлайн интерпретаторе - тык
Получение адреса по координатам, довольно полезная функция, которую можно использовать в различных целях. Например, вам скинули геолокацию. Можно сделать телеграм-бота, отправить ему полученные данные и в ответ получить адрес. Данный функционал можно реализовать на Python. Давайте посмотрим, как это можно сделать.
Для получения адреса по геолокации будем использовать библиотеку geopy. В ней реализованы классы для работы с сервисами геокодирования, такими как OpenStreetMap Nominatim, Google Geocoding API (V3) и многими другими. В нашем коде мы будем использовать OpenStreetMap, так как его использование бесплатно и не требует получения дополнительных ключей.
Установка библиотеки
Для установки библиотеки пишем в терминале команду:
pip install geopy
Импорт модулей в скрипт
После того, как библиотека будет установлена, необходимо импортировать модули для работы с ней в скрипт. Пишем следующий код:
Получаем адрес по координатам. Обратное геокодирование
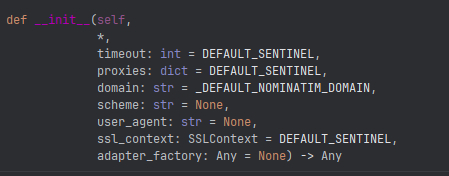
Создадим функцию get_addr(location: list) -> str, которая на входе получаем широту и долготу в виде списка, а возвращает адрес в виде строки. В случае ошибки будет возвращен текст «Unknown».
После этого инициализируем класс Nominatim и передаем в него user_agent. Здесь использование какого-то специализированного агента не принципиально и можно просто передать «GetLoc». Если мы заглянем в параметры данного класса, то увидим, что в него, кроме user_agent можно передать таймаут, прокси и еще множество других параметров, которые в данном случае не принципиальны.
Обратимся к инициализированному классу и его методу reverse, в который передадим координаты в виде списка с широтой и долготой. В ответ мы получим адрес, который и возвратим из функции, обратившись к методу address.
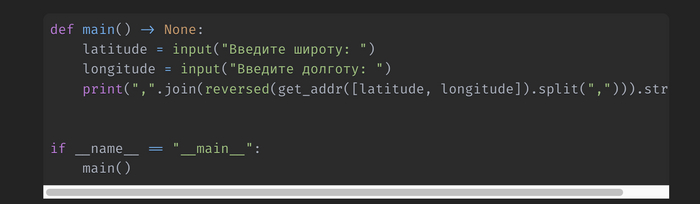
Запрос координат у пользователя. Вывод полученного адреса в терминал
Создадим функцию main(), в которой будем запрашивать широту и долготу у пользователя. После передадим их в функцию get_addr и выведем полученный результат в терминал. Здесь необходимо немного обработать полученные данные, так как они возвращаются в обратном порядке, начиная с номера дома и заканчивая страной. Поэтому, добавлена обратная сортировка, разбиение строки по запятой в список и обратное его объединение.
Тестирование функции
Протестируем написанный код. Возьмем произвольные координаты объекта с Яндекс.Карты и введем в запросе скрипта. В ответе мы видим полученный адрес, который совпадает с тем, что указан на Картах.
Итог:
Как видим, с помощью использования сторонней библиотеки получить адрес по координатам не такая уж сложная задача. К слову, возникновение исключений, когда адрес не был найден, происходит достаточно редко. В большинстве случаев все отрабатывает корректно.
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.
Стандарт Open Document стал де-факто уже давно. И если раньше формат документов Microsoft Office был проприетарным, то теперь он представляет собой «.zip»-файл в котором храниться множество «.xml», а также изображения и прочие файлы. Конечно же, самым простым способом извлечь документы является изменение расширения документа на «.zip» и последующее извлечение файлов любым архиватором. Но, если вам нужно сделать это не с одним документом, это может быть достаточно продолжительно по времени. Поэтому, давайте рассмотрим несколько способов, с помощью которых можно извлечь изображения из файлов формата ".docx", ".xlsx", ".pptx", ".odp", ".ods", ".odt".
Способ №1: используем стандартные библиотеки python
Для данного способа не требуется установка сторонних библиотек. Достаточно тех, что поставляются в комплекте с самим интерпретатором.
Импортируем нужные нам в процессе работы библиотеки:
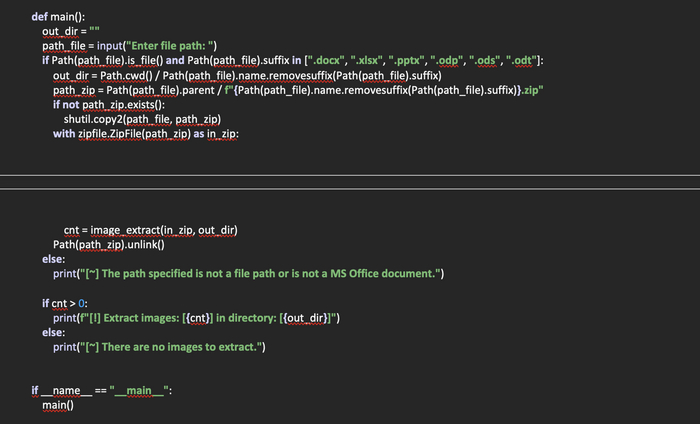
Создадим функцию image_extract(in_zip: zipfile, out_dir: Path), в которую будем передавать zip-файл, а также путь к директории в которую будут распакованы изображения. В данном случае путь у пользователя запрашиваться не будет.
Объявим переменную cnt, которая будет счетчиком распакованных изображений. Затем в цикле пробежимся по списку содержимого архива. Проверим расширения файлов в архиве. И если они совпадают с расширениями из списка, будем читать текущий файл с изображением и сохранять в байтовом режиме в директорию, которая передается в функцию. Также, данная директория создается автоматически и называется именем исходного документа. После того, как все изображения будут сохранены, возвращаем из функции наш счетчик.
Осталось дело за малым, запросить у пользователя путь к файлу, проверить, является ли он файлом и имеет ли нужный формат. После чего скопировать файл с расширением «.zip», открыть с помощью zipfile и передать в функцию для поиска изображений и их распаковки. Ну и напоследок удалить скопированный zip-файл.
После окончания извлечения изображений вывести сообщение пользователю о том, сколько файлов было извлечено и в какую директорию.
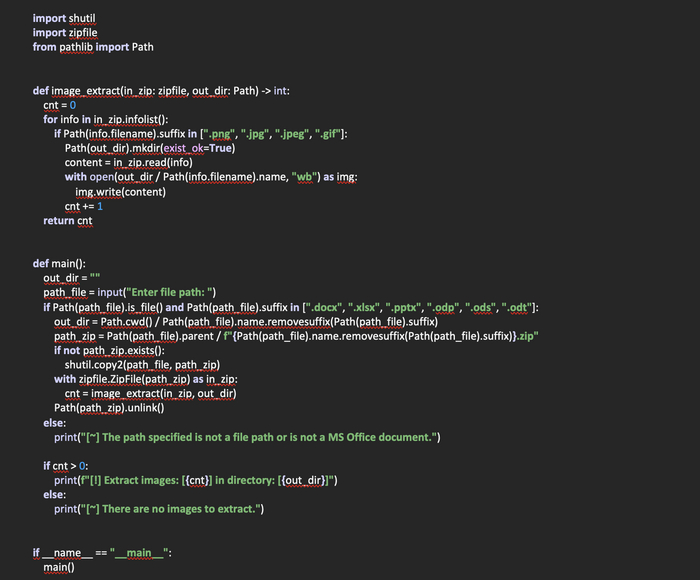
Полный код скрипта:
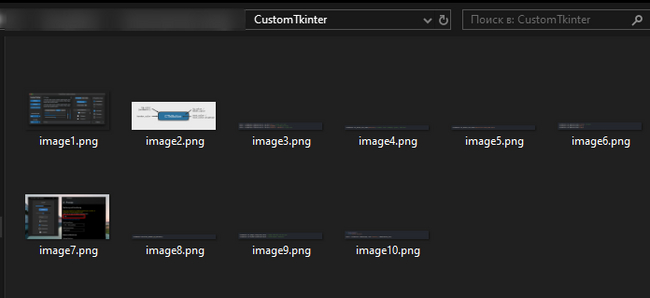
Протестируем созданный скрипт. У нас есть, для примера документ «CustomTkinter.docx». В нем содержаться несколько изображений. Вот их мы и попробуем извлечь.
Запускаем скрипт, указываем путь к документу и получаем папку с названием документа, в которой содержаться изображения.
Способ №2: используем библиотеку docx2txt
Создадим файл docx2im.py. В данном случае мы будем использовать стороннюю библиотеку docx2txt. Для ее установки пишем в терминале или командной строке:
Теперь импортируем нужные библиотеки в скрипт.
В данном случае нам не понадобиться создавать дополнительных функций. Сделаем все в одной. Хотя, в теории, можно было бы разделить извлечение изображений и текста. Да, дополнительным бонусом, при том, что извлекаются изображения только из документов «.docx», является извлечение текста.
Для начала запросим у пользователя путь к документу и путь к папке для извлечения изображений. Проверим, является ли переданный параметр путем к документу и является ли расширение данного документа «.docx». Затем проверим, существует ли директория для извлечения изображений. Если нет, создадим ее, так как docx2txt ее самостоятельно не создает.
Теперь передаем путь к документу и путь для извлечения изображений в функцию process данной библиотеки. Из нее будет возвращен текст документа. Проверим, содержится ли в переменной text что-нибудь. Для этого обрежем пробелы и знаки переноса каретки, так как, если в документе нет текста, но есть пустая строка, переменна text не будет пуста.
Затем открываем текстовый документ на запись и записываем в него полученный текст.
Этот способ достаточно простой, но, как вы уже поняли, извлекать изображения из других форматов документов он не умеет.
Думаю, что вышеприведенных скриптов будет достаточно. Можно использовать также библиотеку aspose-words, которая устанавливается с помощью команды:
pip install aspose-words
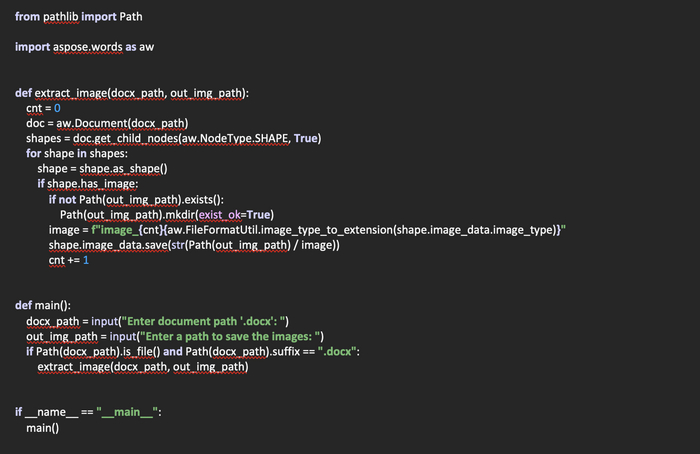
Однако, способ извлечения с ее помощью изображений не особо отличается от предыдущих. Создадим файл aspose_extract.py. Вот для примера код:
Выбирать, что использовать вам и в каком виде, конечно же, вам. Здесь описаны только несколько способов, с помощью которых можно проделать данную операцию. Скорее всего, если поискать более тщательно, найдется еще множество библиотек, с помощью которых можно извлечь изображения из документов.