Одним из первых подробный материал о новой гарнитуре выпустило издание The Verge. Как описал продукт редактор Нилай Патель, Vision Pro — это первая попытка Apple создать компьютер, который работает в пространстве вокруг пользователя.
Внешний вид.
Vision Pro впечатляет по сравнению с другими VR-гарнитурами, которые, в основном, сделаны из пластика и часто выглядят глупо. Vision Pro, изготовленная из углеродного волокна в алюминиевом корпусе, кажется естественным продолжением знакомого дизайна Apple. Выглядят меньше, особенно по сравнению с некоторыми огромными VR-шлемами.
2. EyeSight — очень странная штука.
Передний дисплей Vision Pro оснащён технологией EyeSight, которая демонстрирует окружающим видео ваших глаз, чтобы им было комфортно разговаривать с вами, пока вы носите гарнитуру. На самом деле глаза не всегда видно. Передний дисплей — OLED с низким разрешением и двояковыпуклой панелью перед ним, которая обеспечивает лёгкий 3D-эффект. Он очень тусклый, а защитное стекло очень хорошо отражает, так что видео глаз трудно заметить при ярком освещении.
3. Вес
Весь вес Vision Pro (650 гр.), внутри корпуса скрывается огромное количество камер и датчиков, процессор M2, сопроцессор Apple R1, вентиляторы и динамики. И через какое-то время ношения вы заметите вес всего этого. У Vision Pro весь вес сосредоточен на лицевой части головы. Не как на других крупных гарнитурах, таких на пример как Quest Pro (722 гр.) которые сложными оснащены оголовьями, которые позволяют сбалансировать вес.
4. Настройка.
Настройка Vision Pro предельно проста: регулировка оголовья — единственное, что нужно сделать вручную. Всё остальное автоматизировано и управляется датчиками. Если у вас есть iPhone, вы можете поднести его к Vision Pro и передать все свои настройки. Если iPhone нет, вам придётся ввести пароли вручную, но после гарнитура будет работать нормально.
5. Дисплеи.
Изображение с камер передаётся на внутренний дисплей MicroOLED (23 млн пикселей по 7,5 мкм). Apple утверждает, что задержка между тем, что видят камеры, и тем, что отображается на дисплее, не превышает всего 12 мс. Однако у дисплеев есть одно важное ограничение: их поле зрения невелико. Apple не назвала точную цифру, но поле зрения Vision Pro определённо меньше, чем 110 градусов по горизонтали у Quest 3. Это создаёт большие чёрные рамки вокруг всего, что вы видите, как будто вы смотрите в бинокль. Не смотря что на дисплее хорошее изображение, Vision Pro это всё таки VR-гарнитура, которая маскируется под гарнитуру AR. Хотя Apple презентовала Vision Pro как гарнитуру дополненной реальности. Проблема в том, что технологии создания настоящего AR-дисплея, который смог бы заменить обычный компьютер, пока не существует.
6. Система отслеживания движений глаз и рук.
Одна вещь, которой Apple очень гордится. Ваши глаза — это мышь, а пальцы — это кнопка, и вы сводите их вместе, чтобы кликнуть на что-то. Многочисленные датчики чётко отслеживают, куда смотрит пользователь устройства и какие жесты он выполняет.
Но со временем вы понимаете, что необходимость постоянно смотреть на то, с чем работаешь, это сильно отвлекает. Для сравнения, при работе за обычным компьютером, пользователю не нужно постоянно переводить свой взгляд с дисплея на мышь — управление куда более удобнее, интуитивнее и быстрее.
Для выполнения жестов при помощи пальцев, руки не нужно держать прямо перед Vision Pro, поскольку камеры отслеживают относительно широкую область перед гарнитурой. Однако обозреватели отметили, что у них нередко было так, что датчики не распознавали жесты, поскольку руки не попадали в область работы камер. А вот виртуальная клавиатура в Vision Pro совершенно неудобная. По словам обозревателей, она подходит «только для того, чтобы ввести пароль от Wi-Fi». В остальном же лучше использовать физическую клавиатуру или голосовой ввод.
7. Аватары.
Аватары, или персоны Vision Pro, впечатляют, но в то же время они очень плохи. Функция пока в бета-тестировании, но работает неплохо. Суть предельно проста: камеры TrueDepth в гарнитуре сканируют ваше лицо и создают виртуального аватара, который выглядит почти так же, как вы. Если ваша «персона» вам не понравится, её можно кастомизировать — добавить аксессуары вроде очков, изменить тон кожи, цвет глаз и другие параметры. Аватар повторяет движения губ, повороты головы и даже движения рук. Это, в теории, выводит видеосвязь на новый уровень. И на практике, как отмечают работает неплохо.
8. Фото и видео.
Не рекомендовали снимать фотографии на Vision Pro, если в этом нет особой необходимости. 6,5-мегапиксельные сенсорной камеры, оптимизированной для видео, выглядят они плохо. С видео дела обстоит по лучше: Vision Pro снимает квадратные видеоролики размером 2200 x 2200 со скоростью 30 кадров в секунду. Они выглядят приятнее, чем фотографии.
9. VisionOS
Vision Pro работает под управлением VisionOS, которая основана на iPadOS. Благодаря этому гарнитура начинает с полного набора зрелых функций iPadOS и существенной части огромной библиотеки приложений для iPad. Основная разница между VisionOS и iPadOS заключается в том, что в iPadOS существует множество вариантов упорядочивания приложений, а VisionOS — это полный хаос свободно плавающих окон. Вы можете открыть столько приложений, сколько захотите, и разместить их в любом месте. Вы можете открыть окна на кухне, уйти и открыть ещё несколько в гостиной, а затем вернуться на кухню и обнаружить, что вас ждут все ваши старые окна.
10. Vision Pro для работы и фильмов.
VisionOS Позволяет запускать множество приложений и располагать их окна рядом друг с другом. Управлять программами удобно, но операционной системе VisionOS пока не хватает инструментов для многозадачности. Сильнее всего Vision Pro раскрывается при совместной работе с Mac. Синхронизация между устройствами происходит моментально. Пользователь может перетащить окно из компьютера Mac в своё виртуальное пространство в Vision Pro и продолжить полноценную работу уже там. При этом у него останутся все возможности, которые были доступны на Mac.
Vision Pro отлично подходит для просмотра 3D-фильмов, обеспечивая высокий уровень погружения. У пользователей есть возможность размещать видео на различных фонах, в том числе живописных, например, на фоне гор или океана. Единственный недостаток при просмотре фильмов или другого контента в Vision Pro - это приходится делать в одиночку.
11. Время работы и зарядка.
Обычное использование — 2 часа 26 минут
Просмотр 3D-видео — 3 часа 9 минут
Полная зарядка — 1 час 30 минут
30 минут зарядки — с 0 до 37%
Vision Pro работает от внешний аккумулятор, который подключается к гарнитуре по кабелю. По словам обозревателей кабель иногда мешается, но в целом не доставляет большого дискомфорта, особенно если закрепить его на поясе.
12. Выводы
Главный минус Vision Pro — цена, приблизительно $3500 (примерно 316000 р.). В России гарнитура будет стоить порядка 500000 р.
Из плюсов хорошие дисплеи, хорошая производительность, хорошая эргономика (не считая внешнего аккумулятора).
Анимация персонажей направлена на создание видеороликов с персонажами из изображений с помощью управляющих сигналов. Цветное очертание скелета, как в ControlNet, позволяет точечно задать и настроить движения объекта с фото.
В настоящее время Diffusion-модели стали основным направлением в исследованиях визуальной генерации благодаря их мощным возможностям. Чтобы сохранить согласованность сложных элементов внешнего вида с эталонным изображением, мы разрабатываем ReferenceNet для объединения деталей с помощью пространственного внимания.
Обзор процесса создания видео: последовательность поз первоначально кодируется с помощью Pose Guider и объединяется с многокадровым шумом, после чего система UNet выполняет процесс шумоподавления. Вычислительный блок системы UNet состоит из пространственного, перекрестного и временного внимания. Интеграция эталонного изображения включает в себя два аспекта. Во-первых, главные очертания извлекаются через ReferenceNet и используются для пространственного внимания. Во-вторых, остальные детали извлекаются с помощью кодера изображений клипов для перекрестного внимания. Темпоральное внимание работает во временном измерении. Наконец, декодер VAE декодирует результат в видеоклип.
Друзья, всем привет, в прошлой статье Fooocus v2 — бесплатный Midjourney у вас на компьютере, вы познакомились с рисующей нейросетью которая вполне способна заменить Midjourney, узнали как её установить, как пользоваться, за что отвечают все настройки и как работают режимы, как писать запросы, чтобы нейросеть вас понимала.
Из этой части вы узнаете как с помощью нейросети Fooocus можно дорисовать любое изображение выйдя за его границы, изменить любую деталь на изображении, узнаете как добавить на свою генерацию текст, наложить свое лицо или как создать изображение по вашему референсу. Сегодня я расскажу про раздел Input Image.
Вкладка Upscale or Variation
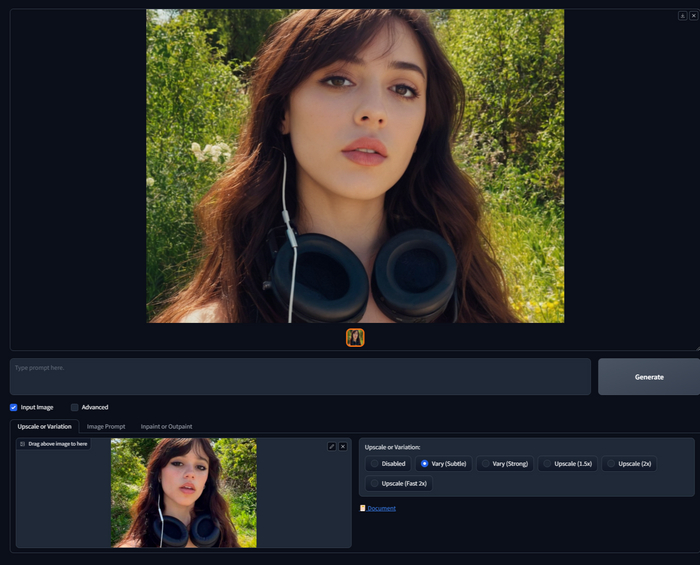
Ставим галочку на Input Image и попадаем в мир роскоши и комфорта, на вкладку где вы можете либо создать вариации уже существующего изображения, либо увеличить изображение. Это может быть как то, что вы сгенерировали, так и ваша фотография. Чтобы что-то заработало нам надо загрузить изображение, я для примера возьму фотографию Джены Ортеги, которая играла Уенсдей в одноименном сериале от Нетфликс.
Variation - Вариации
Допустим нам нельзя использовать фотографию Джены, например в коммерческой публикации, но она идеально соответствует нашей задаче, для рекламы наушников например. Выбираем в таком случае Vary (Subtle), чтобы получить то же самое, что изображенона загруженном изображении, в нашем случае девушку в лесу в наушниках, нам даже запрос писать не нужно, нейросеть сама поймет что нужно сделать. Если будем использовать Vary (Strong), то такого сходства с загруженным изображением уже не получим, оно будет просто "на тему", режим Vary (Strong) лучше работает для того, чтобы сделать вариацию генерации, где используется запрос.
Вариации отличный и простой способ получить собственную версию любого изображения, но что делать, если изображение нужно использовать, например для печати, как увеличить его разрешение?
Upscale - Увеличение
A picture of a beautiful girl with headphones around her neck walking in the woods
В положении Upscale происходит увеличение изображения, можно выбрать увеличение в 1.5 или 2 раза, есть еще 2x Fast, но он делает ощутимо хуже. Важно понимать, что новые детали таким образом не появятся, изображение просто будет увеличено с некоторым количеством едва заметных артефактов. Если необходимо вы можете несколько раз по кругу закидывать полученное изображение в апскейл, для этого просто перетащите его сверху в форму ниже. А мы переходим дальше, к самому мощному инструменту.
Вкладка Image Prompt
close-up female portrait. road, retrowave colors
Вкладка Image Prompt позволяет вам использовать в качестве подсказки изображение, и сделать это большим количеством способов, используя различные модели ControlNet. Комбинируя разные способы вы можете получить совершенно любое изображение. Вот в примере выше я взял фотку Джены, текст на прозрачном фоне, пейзажик и ретро фотографию жигулей. С первой картинки я получил надпись, со второй позу, расположение и эмоцию девушки, с третьей часть фона и с четвертой часть палитры. Невероятный результат, по очень простому запросу. Ниже я расскажу как работает каждый из режимов, чтобы увидеть эти дополнительные настройки нажмите на галочку Advanced.
ImagePrompt - Стиль и содержимое
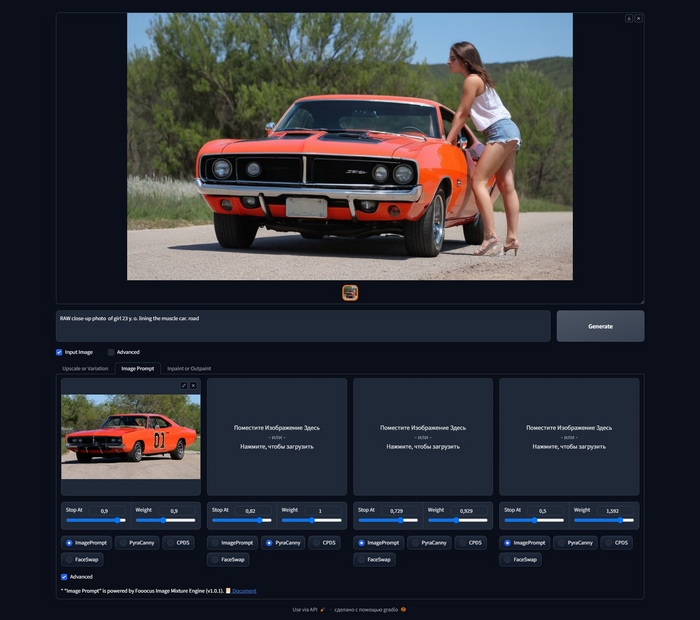
Режим Image Prompt он же СontrolNet IP adapter создан для того, чтобы вы могли использовать в качестве запроса изображение, при том забирает с референсного изображения Image Prompt не только стиль, но и содержимое, т.е. улавливает контекст. Покажу на простом примере. Загружаем фотографию ретро автомобиля, пишем простой запрос RAW close-up photo of girl 23 y. o. lining the muscle car. road, я не пишу в запросе ни модель машины ни цвет, но получаю фотографию девушки рядом с очень похожей машиной, на ту что я загрузил в качестве референса.
RAW close-up photo of girl 23 y. o. lining the muscle car. road
Таким же образом можно взять стиль с любого изображения. Еще пример: я нашел классную картинку с разрушенным городом на PromptHero, это сайт где можно найти интересные примеры и запросы для нейросетей. Картинка атмосферная, мне нравится, но она сделана в миджорни и её запрос мне не поможет. К тому же мне нужна такая же только с перламутровыми пуговицами горизонтальная и с плюшевым медведем. Задачка кажется сложной.
Чтобы получить похожую картинку только по запросу придется постараться. Можно поступить проще, загружаю это изображение в Image Prompt, пишу запрос Photo of a gloomy ruined city, close-up of a teddy bear, и получаю сразу же отличный результат, ровно такой, каким я себе представлял. Драматичная темная картинка с плюшевым мишкой который героически идет к светящемуся зданию, сразу хочется узнать что будет дальше.
Photo of a gloomy ruined city, close-up of a teddy bear
Но что делать, если результат не устраивает, всегда можно подкрутить Stop At, он отвечает за то, когда нейросеть перестанет смотреть на то изображение которое вы загрузили. По умолчанию стоит на 0.5. т.е. половину всей генерации фокус придерживается загруженного изображения, а потом уже генерирует как хочет. Часто бывает полезно увеличить или наоборот уменьшить это значение.
Увеличивать стоит если вы хотите хорошо перенести визуальный стиль. А уменьшить, если вам достаточно лишь общей композиции, так вы дадите нейросети больше свободы. Кроме того можно увеличить влияние изображения, с помощью ползунка Weight, чем больше вес, тем сильнее влияние на генерацию, выше интенсивность влияния, но одновременно с этим уменьшается и креативность нейросети, поэтому находите баланс.
Когда использовать Image Prompt? Когда надо скопировать стиль, атмосферу, освещение, а при высоком Weight и композицию изображения.
PyraCanny - Контуры
Canny создает так называемую карту, того, что изображено на картинке которую вы загружаете. Это карта состоит только из ключевых контуров, на ней отсутствует информация о цвете или стиле. Эти контуры лягут в основу вашей будущей генерации.
Например я сгенерировал милого кролика, но мне хочется сделать кролика в другом стиле, при этом я хочу полностью сохранить его пропорции. Загружаю кролика в Image Prompt, выбираю PyraCanny, ставлю Stop At на 0.9 или даже на 1, чтобы сохранить пропорции до конца генерации. И просто по промпту Bunny начинаю переключать различные встроенные в фокус стили, пока не найду то, что мне нравится. Про стили подробно рассказывал в первой части. Вот такой получается результат у меня.
Bunny + стили
Очень полезный инструмент, чтобы сделать вариации персонажей, иконок в разных стилях. Кстати вам не обязательно загружать готовое изображение, вы можете загрузить и контурный набросок сделанный от руки и Фокус попытается сгенерировать по нему изображение.
Еще PyraCanny отлично подходит чтобы стилизовать текст. Все что вам нужно, это сделать PNG изображение текста, на прозрачном фоне, для этого подойдет любой редактор, онлайн могу посоветовать photopea.com он удобный и бесплатный. Я предпочитаю делать обводку тексту, так обычно интереснее стилизуется. Чтобы текст был читаемым и не прыгал стоит поставить Stop At на 1 и Weight на 1.2, а иногда и выше, если текст искажается или недостаточно виден.
Когда использовать PyraCanny? Когда надо скопировать содержимое изображения, персонажа, архитектуру, черты лица или композицию, или добавить текст.
CPDS - Глубина и контрастность
confused Keanu Reeves as John Wick in the desert, holding a gun
CPDS создает карту на основе резкости и контрастности загруженного изображения. После обесцвечивая изображения, остается только информация о силуэте, очертаниях и резкости и глубине. Это позволяет перенести в вашу генерацию любую сложную сцену или позу, не ограничиваясь при этом строгими контурами как это делает Canny.
Для примера я взял знаменитую сцену с Траволтой из фильма Криминальное чтиво и воссоздал с участием других персонажей: Гомера Симпсона, Гэндальфа, Джона Уика, Дарта Вейдера и еще нескольких.
Получилось отлично, а главное достаточно просто, запросы были в духе confused Homer Simpson.
Когда использовать CPDS? Когда нужно перенести силуэты и глубину, воссоздать сложные сцены, позы, глубину в пространстве.
FaceSwap - Замена лица
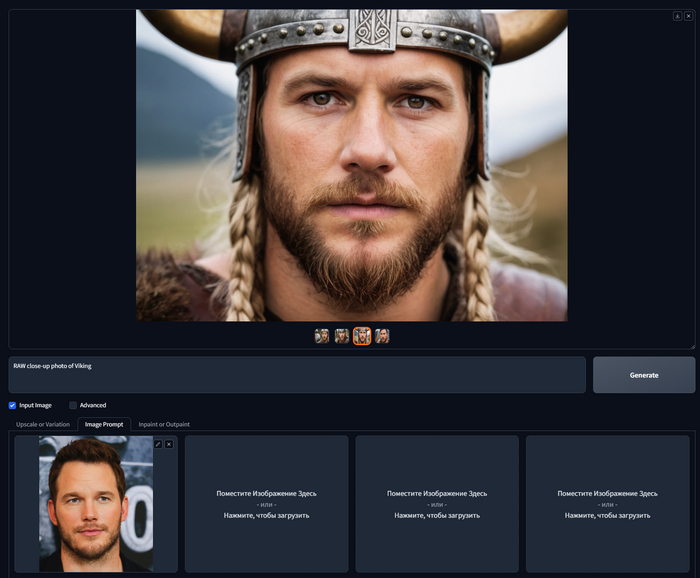
Вот мы добрались и до единственной ложки дегтя, то, что разработчик называет FaceSwap, на самом деле никакой не FaceSwap, а просто IP Adapter, как и Image Prompt, но обученный на лицах, он их вырезает и пытается встроить в генерацию. Но, честно говоря, это работает плохо. Такое ощущение, что пьяный друг кому-то рассказал как вы выглядите, и генерация это результат по мотивам такого описания. Определенно есть какое-то сходство, но есть и различие , которое пугает эффектом зловещей долины. Как я не крутил настройки так и не смог заставить этот режим работать хорошо. Разве узнаете вы на этой фотке Криса Пратта, Звездного лорда из Стражей галактики? Я нет.
RAW close-up photo of Viking
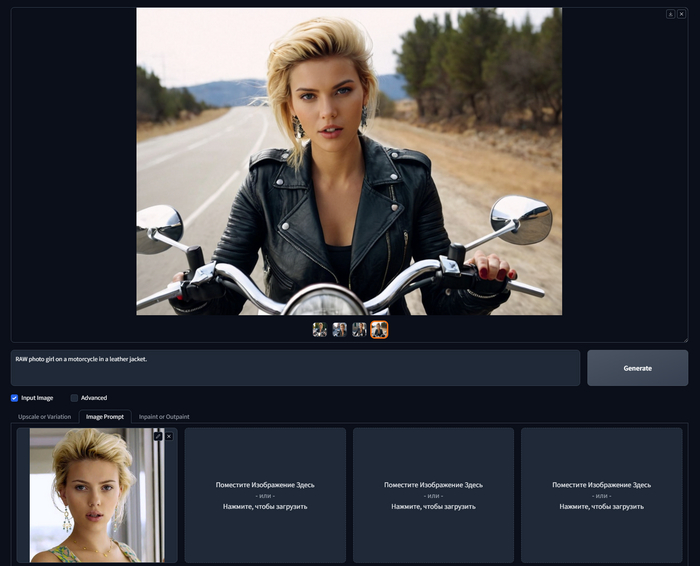
Хотел бы я сказать, что с женщинами получается лучше, но нет, вместо Скарлетт Йоханссон на мотоцикле, у меня получается её троюродная сестра, видимо.
RAW photo girl on a motorcycle in a leather jacket
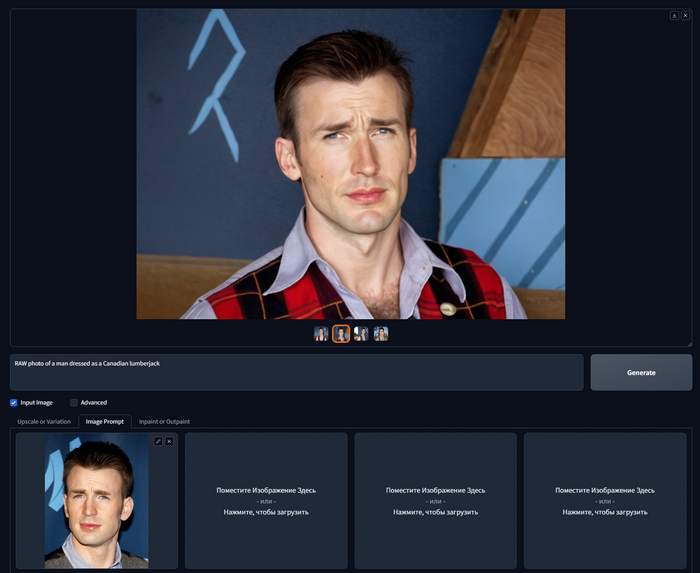
Если вы думаете что получится просто поднять Weight, то и тут вас ждет разочарование, если его поднять, то композиция, ракурс и цвета будет наследоваться с загруженного изображения, а то что вы пишите в запросе практически не будет учитываться. Для примера я загрузил фотку Криса Эванса, и выкрутил вес до 1.4, да так лицо действительно чуть больше похоже, это уже не родственник, а конкурс двойников. Но теперь все время пролезает кусок фона с референса, а ракурс лица невозможно изменить.
RAW photo of a man dressed as a Canadian lumberjack
Настоящий же FaceSwap очень аккуратно и тщательно смешивает черты лица с оригинала с загруженным лицом и практически всегда дает отличный результат, я об этом рассказывал в статьеСтань героем мемов! Делаем гифки со своим лицом с помощью нейросетей, посмотрите, очень интересная.
Я не могу назвать реализацию замены лиц в фокусе действительно работающей. Будем надеяться что в будущем разработчики либо улучшат этот редим, либо сделают тот классический FaceSwap который мы знаем по другим приложениям.
Когда использовать FaceSwap? Когда вы хотите чтобы у всех ваших персонажей было похожее лицо или типаж, либо готовите базовую картинку для замены лица в другом приложении, например в ReActor.
Различные комбинации
Самое классное, что вы можете комбинировать возможности Image Prompt как угодно, загружайте разные изображения, добавляйте текст, стили, и конечно управляйте запросом. Вот еще несколько классных примеров, которые были бы сложно получить только по текстовому описанию.
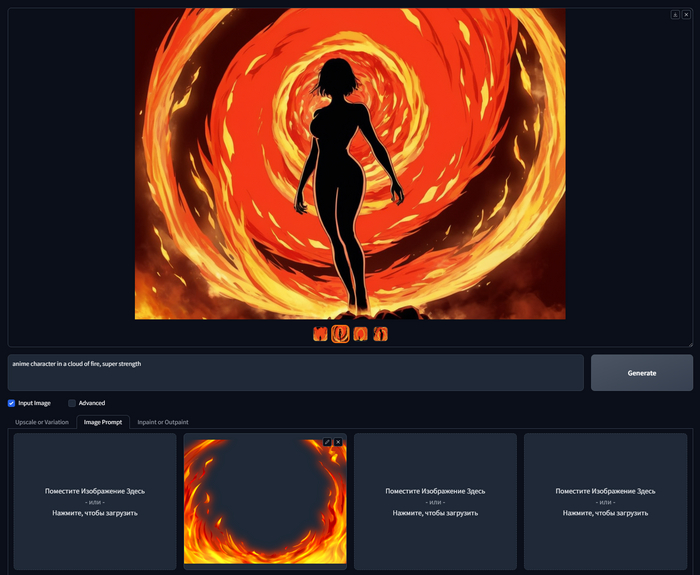
anime character in a cloud of fire, super strength
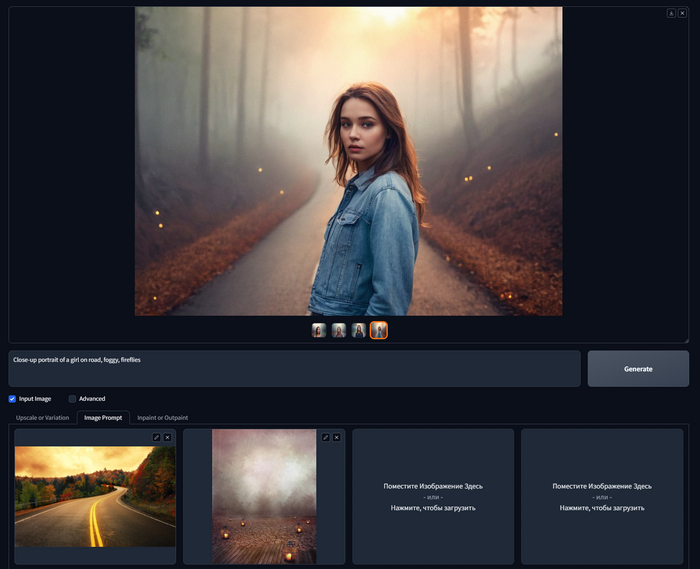
Close-up portrait of a girl on road, foggy, fireflies
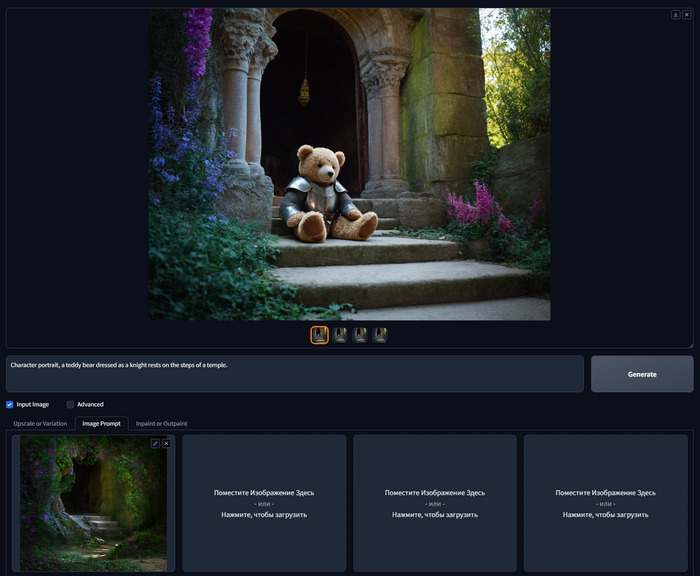
Character portrait, a teddy bear dressed as a knight rests on the steps of a temple.
Специально для моих подписчиков на Бусти я собрал пак из 1 800 необычных и интересных изображений - референсов, для использования в Image Prompt. В этом материале многие изображения как раз оттуда. Теперь добавить необычный эффект, сделать интересный фон или стиль можно в пару кликов и без сложных запросов. Подпишитесь на Бусти и вы, там много полезных материалов, записи обучающих стримов и доступ в наш закрытый чат. Только поддержка подписчиков позволяет мне писать такие подробные гайды и инструкции для вас друзья. А мы двигаемся к двум оставшимся, но не менее крутым функциям, впереди Inpaint и Outpaint.
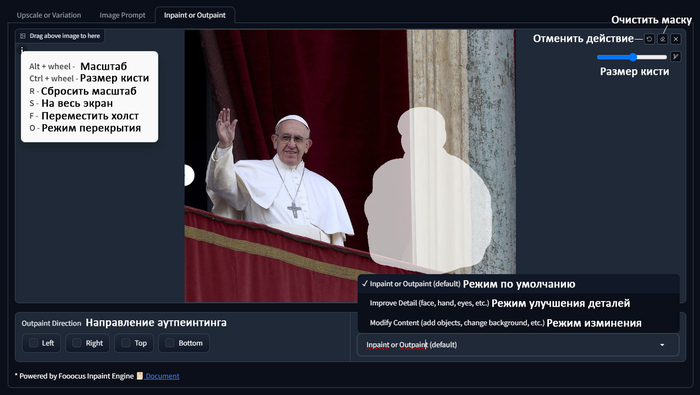
Вкладка Inpaint or Outpaint
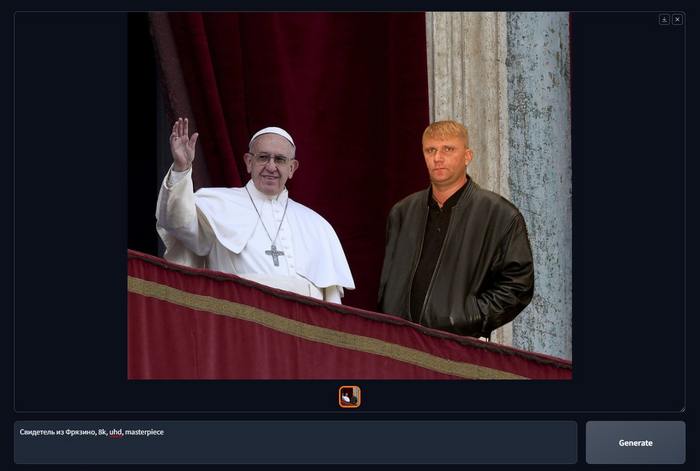
Конечно Свидетель из Фрязино уже был на этом фото c Папой Франциском, когда я его нашел, сгенерировать его не получится, но на этом примере я могу показать как можно изменить реальное изображение, прежде чем мы приступим к аутпеинтингу.
Inpaint - Изменяем изображение
Шпаргалка по быстрым клавишам и основным функциям
Как часто бывает, что на хорошей фотографии есть что-то, чего там быть не должно, раньше исправить такое фото было сложно. Теперь же есть инпеинтинг, простая механика - закрашиваем то, что нам не нравится маской, пишем что хотим вместо того, что под маской и получаем отличный результат. При том использовать запрос не обязательно. У инпеинтинга есть три режима:
Inpaint or Outpaint (default) - режим включенный по умолчанию, он же используется на аутпеинтинга. Подходит в целом для любой задачи, но разрешение в этом режиме будет ниже чем в двух других.
Improve Detail (face, hand, eyes, etc.) - режим улучшения деталей, отлично подходит для улучшения детализации лица, рук, глаз или других объектов.
Modify Content (add objects, change background, etc.) - режим изменения, в этом режиме удобно изменять или добавлять, то чего на изображении не было.
В режимах Improve и Modify появляется дополнительное поле, в котором можно указать конкретные изменения, это сделано чтобы вам не пришлось менять основной запрос, а потом вспоминать что там было.
Например, если мы хотим избавиться от персонажа на фото, то просто запустим генерацию с пустым запросом, либо с описанием той поверхности которая находится рядом, например стена или природа. Точно так же мы можем заменить персонажа на любого другого, достаточно лишь описать его. Конечно если делать это так же грубо как я на этих примерах, то будут заметны артефакты. Но если у вас есть тачпад, то вы сможете очень аккуратно нарисовать маску.
Но, этим не ограничиваются возможности инпеинтинга, еще вы можете: заменить фон, поменять одежду или прическу, улучшить лицо, добавить то, чего не хватает, удалить то что есть, возможности ограничиваются только вашей фантазией. На мой взгляд инпеинтинг самая мощная механика в работе с изображениями, а в фокусе она к тому же максимально удобно реализована.
Outpaint - Расширяем изображение
Атупеинтинг позволяет выйти за границы изображения, работает он очень просто. Вам достаточно выбрать сторону, в которую надо расширить изображение, влево, вправо, вверх, или вниз, вы конечно можете поставить сразу все 4 галочки, но так качество будет хуже, лучше делать одну сторону за раз. Вы можете как указывать запрос, так и нет. Допустимо немного изменять запрос между итерациями аутпеинтинга, чтобы добиться желаемого результата.
Вы можно делать аутпеинтинг много раз подряд, перетягивая сгенерированную картинку вниз, но важно помнить что каждый раз разрешение изображения становится больше и в какой-то момент у вас просто не хватит видеопамяти.
Аутпеинтинг прекрасная механика которая не только позволяет изменить размер кадра и соотношение сторон, заглядывая за границу несуществующего, но и отличный инструмент для создания больших детализированных изображений. Как это, его разрешение 4674х2772, но для вашего удобства я превратил его в видео. Есть конечно косячки на склейках, но их можно убрать множеством других способов.
Друзья, на этом мы закончили изучать возможности Input Image в Фокусе, поздравляю вас! Теперь вы знаете как делать вариации, увеличивать изображения или генерации, как использовать вкладку Image Prompt и все виды ControlNet, чтобы получить уникальное изображение созданное по вашему референсу, содержащее текст или даже похожее на вас. И конечно же вы теперь сможете изменить что-то в уже существующем изображении с помощью инпеинтинга или заглянуть за границы изображения с помощью аутпеинтинга.
Cinematic still of cat holding shopping bag full of vegetables with paws, shopping with smile in a market
Делитесь тем что у вас получается в нашем чате нейро-энтузиастов и увидимся на стримах, ближайший, уже 28 ноября в 20:00 на Бусти, вход как и всегда свободный, подпишитесь чтобы не пропустить начало. Разберем Фокус по косточкам, отвечу на все вопросы.
А еще я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Всех обнял.
Hotshot – это инновационный инструмент, предназначенный для создания захватывающих GIF-изображений и преобразования текстовых подсказок в динамичные анимации. Этот мощный инструмент открывает новые возможности для творчества с анимированными изображениями, предоставляя пользователям простой и удобный способ придать своему контенту анимационный характер.
Основные Характеристики Hotshot:
Простота Использования: Интерфейс Hotshot разработан с учетом удобства пользователей. Создание GIF-файлов становится легким и доступным процессом.
Текстовые Подсказки: Пользователи могут преобразовывать текстовые подсказки в анимированные изображения, добавляя креативный и персональный элемент в свой контент.
Динамичные Анимации: Hotshot предлагает широкий выбор эффектов и стилей анимации, позволяя создавать динамичные и визуально привлекательные GIF-изображения.
Платформа для Идей: Инструмент становится отличной платформой для воплощения творческих идей в анимированные картинки, подходящие для различных контекстов использования.
Расширенные Возможности: Hotshot может быть использован для разнообразных целей, включая создание анимированных объявлений, креативных подписей и даже визуальных эффектов для презентаций.
Применение Hotshot:
Социальные Сети: Идеальный инструмент для создания анимированных контентов, которые привлекают внимание на платформах социальных сетей.
Цифровой Маркетинг: Hotshot может использоваться для разработки креативных рекламных материалов, обогащенных динамичными анимациями.
Обучение и Образование: Инструмент подходит для создания интересных и визуально привлекательных материалов в учебных целях.
Кстати, мы сделали бесплатного тг-бота для генерации изображений и бесплатный гайд по генерациям изображений - ПОПРОБУЙТЕ
Друзья, всем привет! Сегодня я хочу рассказать вам про самую простую и доступную для понимания нейросеть, которая создает изображения по вашему текстовому описанию. Она называется Fooocus и основана на знаменитой Stable Diffusion XL. Это идеальное решение в качестве вашей первой нейросети, и необходимый инструмент для любого дизайнера или контент мейкера.
Автор Fooocus не случайный разработчик, а сам создатель ControlNet, очень важной подсистемы для Stable Diffusion, которая изменила все в мире генерации изображений, позволив художникам и дизайнерам полностью контролировать создаваемый арт. Создатель сравнивает свой проект с Midjourney по качеству арта и удобству использования. И действительно порог входа в эту нейросеть очень низкий, а результаты отличные с первой генерации. Установим, изучим, сделаем выводы, поехали.
Что нам понадобится:
Компьютер или ноутбук с видеокартой минимум на 8GB видеопамяти.
Около 25GB свободного места на диске для одного режима и 40GB для всех трех.
Или Google аккаунт для запуска в облаке.
Fooocus пока еще не забанен в Google Colab, а это значит, что если у вас нет подходящего компьютера вы можете запустить приложение на серверах гугла совершенно бесплатно. ПК бояре могут спускаться к следующему заголовку. Поговорим про запуск в облаке.
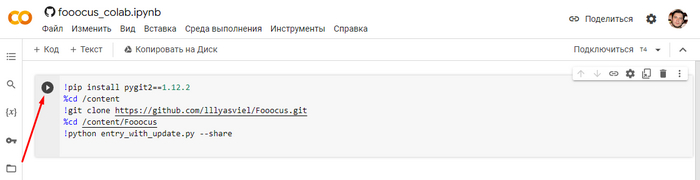
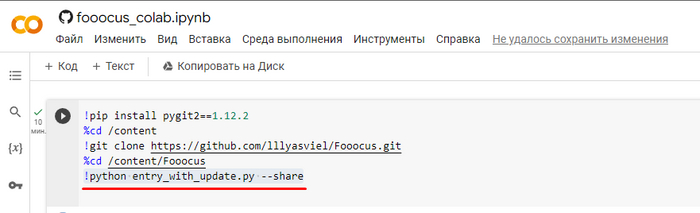
Запуск в Google Colab
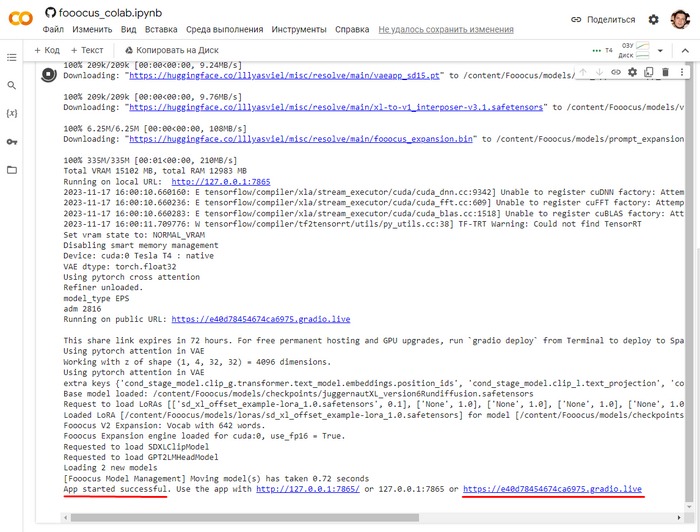
Открываем вот эту ссылку, и нажимаете на кнопку плей, соглашаетесь с гуглом и жмите кнопку Выполнить. Ждите пока произойдёт скачивание и установка на сервер Google Colab, это может занять до 10 минут.
Вы поймете что установка завершена и программа готова к работе когда внизу консоли увидите App started successful.и рядом будет ссылка вида https://какие-то-цифры.gradio.live, вот на неё и надо будет кликнуть. Программа откроется готовая к работе.
Если вы хотите запустить в режиме Realistic или в режиме Anime замените строку кода !python entry_with_update.py --shareна строку !python entry_with_update.py --preset anime --shareдля режима Аниме, или на !python entry_with_update.py --preset realistic --shareдля режима Реализма. Про режимы я еще расскажу ниже.
Помните, что Google Colab еще весной прикрыл возможность использовать свои мощности для генерации в Automatic 1111, другом интерфейсе нейросети, скорее всего скоро прикроют и этот, поэтому не рассчитывайте на него слишком сильно. Кроме того по итогам моих тестов, вижу что контейнер с фокусом вылетает если сильно грузить его, например если несколько раз подряд отправлять изображение на аутпеинтинг каждый раз с увеличением разрешения. Так, что только локальная версия вас не подведет, к ней и перейдем.
Локальная установка
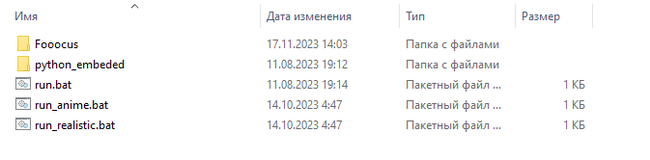
Если у вас ПК на Windows и видео карта NVidia, все что вам нужно сделать, это скачать архив с этой страницы, нажав на >>> Click here to download <<<. Архив распакуйте в любую удобную папку не содержащую в путях кириллицы.
После того как архив распакован у вас в папке будет три файла run.bat, run_anime.bat и run_realistic.bat, каждый из файлов запускает соответствующий режим, про режимы я покажу наглядно чуть ниже, а пока можете выбрать то, к чему больше душа лежит, я запущу режим по умолчанию - run.bat.
Для установки на Mac, AMD, Linux и т.д. переходите на гитхаб проекта и изучайте способы самостоятельно, поддержка заявлена, но у меня протестировать не на чем, а рассказывать о том, что я сам не протестировал я по понятным причинам не могу.
Если вы все сделали правильно, не важно локально или в гугле, то у вас уже открыт интерфейс фокуса и выглядит он примерно так, попробуем написать какой-нибудь простенький промпт и посмотрим что получится. У меня это будет "Leonardo DiCaprio as a mechanic in a garage with oil effect in a rugged style". Первая генерация будет дольше чем последующие, потому что еще скачиваются дополнительные файлы. Вот что получилось у меня.
Leonardo DiCaprio as a mechanic in a garage with oil effect in a rugged style
По моему отличный результат, кстати, если у вас так же как у меня не выбирается автоматически темная тема, просто добавьте в конце адреса в адресной строке ?__theme=dark, тогда будет установлена темная тема. Работает и локально и в гугл коллабе.
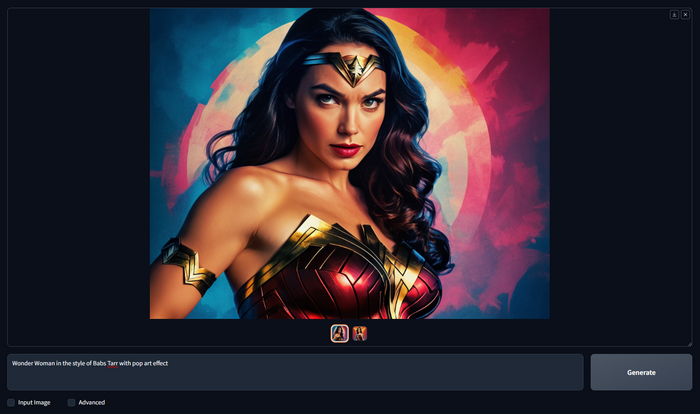
Wonder Woman in the style of Babs Tarr with pop art effect. Согласитесь, темная тема гораздо приятнее
Как писать запросы
Чтобы нейросеть вас понимала, важно научиться правильно писать запросы. В фокусе у нас работают SDXL модели, которые отлично понимают человеческий язык, а дополнительный GPT движок улучшает ваши текстовые запросы самостоятельно, поэтому каких-то особых знаний вам не понадобится. Просто опишите то что хотите видеть следуя такой структуре: Вид изображения, объект, описание внешности, дополнительные элементы, место, эффект, стиль.
Например: Фотография красивой девушки 28 лет, красные волосы заплетенные в косы, большие голубые глаза. Одета в красивое голубое платье с белыми цветами. День, лето, сидит в кафе, пьет кофе. Современная цифровая иллюстрация, рекламный постер. Затем я просто перевожу текст в любом переводчике и получаю отличный результат, который соответствует моим ожиданиям. Вот что вышло у меня.
Photo of a beautiful girl 28 years old, red hair braided in braids, big blue eyes. Dressed in a beautiful blue dress with white flowers. Day, summer, sitting in a cafe, drinking coffee. Modern digital illustration, advertising poster.
По моему отличный результат, но не расстраивайтесь, если у вас что-то не вышло сразу, написание запросов - это навык, потренируйтесь всего недельку и у вас будет получаться уже гораздо лучше.
В этом руководстве я использую готовые запросы из моего списка 100 промптов для новичков, по которым всегда получается хороший результат, подписчики могут скачать список запросов на Бусти. Подпишитесь и вы,ведь на Бусти видео выходят раньше и много эксклюзивных материалов, записи обучающий стримов, а так же доступ в наш секретный чат.Только благодаря поддержке подписчиков у меня есть возможность создавать такие исчерпывающее инструкции и все свое время посвящать изучению нейросетей, чтобы потом делиться информацией с вами друзья. А мы продолжаем изучать Fooocus и переходим к режимам.
Режимы запуска
Режимы отличаются значительно, в разных режимах используются разные модели (в моделях содержится информация обо всем что может создать нейросеть), подходящие под эти модели настройки, разные дополнительные лоры (дополнительные мини-модели) и различные стили включены по умолчанию, ниже я перечислил основные отличия и сгенерировал изображения с одинаковым сидом и запросом, но в разных режимах, чтобы вы лучше понимали разницу и смогли выбрать подходящий для себя. Но обязательно попробуйте их все. Дополнительно я указал ссылки на модели и лоры, на сайте civitai, так вы сможете самостоятельно посмотреть изображения которые на них можно создать и запросы к ним.
Режим General
Cat with a bowtie in a coffee shop with steam effect in a cozy style
Harley Quinn as a waitress in a diner with hammer effect in a playful style, photographed by Juergen Teller
Универсальный режим подойдет для всего и для арта и для реалистичных работ, хорошо следует стилям.
Стили по умолчанию: Fooocus V2, Fooocus Photograph, Fooocus Negative
Негативный запрос: unrealistic, saturated, high contrast, big nose, painting, drawing, sketch, cartoon, anime, manga, render, CG, 3d, watermark, signature, label
Режим Anime
Cat with a bowtie in a coffee shop with steam effect in a cozy style
Harley Quinn as a waitress in a diner with hammer effect in a playful style, photographed by Juergen Teller
Режим подойдет для Аниме и художественного арта. Обратите внимание, что запрос всегда начинается с 1girl, корректируйте если требуется, а то будете получать анимешных девочек.
Надеюсь теперь вы лучше понимаете на что способен Фокус в каждом из режимов и сможете сознательно выбирать режим под задачу. А я же останусь сидеть на режиме General, на мой взгляд самый универсальный.
Дополнительные настройки
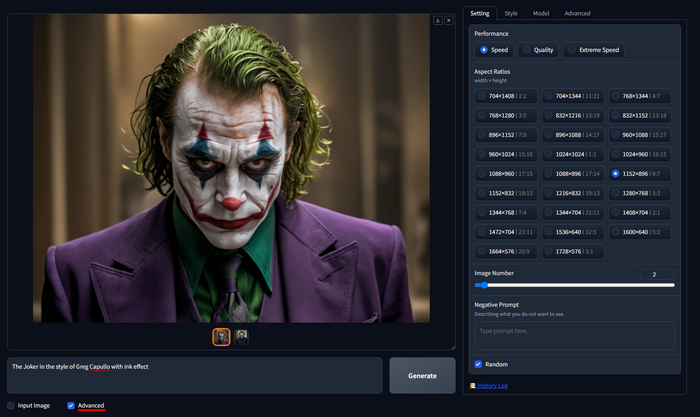
The Joker in the style of Greg Capullo with ink effect
Если вы думали, что в самом простом интерфейсе для создания изображений с помощью SDXL моделей больше нет настроек, он же простой, то вы ошибаетесь, настроек много. Скрывают их две галочки. Начнем с галочки Advanced.
Раздел Setting
В этой вкладке находится все, что непосредственно касается настроек генерации.
Performance - позволяет задать производительность, на выбор три режима Speed - 30 шагов, Quality - 60 шагов и Extreme Speed, между первыми двумя режимами вы разницу скорее всего даже не заметите, а вот последний режим появился совсем недавно, он конечно делает качество хуже, но работает невероятно быстро за счёт использования новой технологии рендеринга LCM. Меня обычно устраивает режим Speed.
Aspect Ratios - соотношение сторон, позволяет вам выбрать разрешение для вашего изображения, выбор фиксированный не случайно, тут только те разрешения на которых обучались SDXL модели, а значит вы при всем желание не сможете сделать что-то не правильно. Первая цифра это ширина, вторая высота. Для удобства рядом еще написано соотношение сторон. Можно сделать как ультра широкое изображение, например 1728×576, в стиле кино-кадров.
The Joker in the style of Greg Capullo with ink effect
Так и ультра высокое, например в 704×1408, в обоих случаях результат отличный, так что выбирайте размер под ваши задачи.
The Joker in the style of Greg Capullo with ink effect
Image Number - позволяет задать количество изображений которые нужно сгенерировать, по умолчанию 2, но вы можете указать вплоть до 32 изображений, но конечно это займет длительное время.
Negative Prompt - негативная подсказка позволяет указать то, чего на изображении быть не должно.
Seed - все изображения создаются из белого шума, как помехи в телевизоре, Seed и есть ид конкретного уникального шума, по умолчанию стоит галочка Random, задавая случайный шум для каждой генерации, но если вы её снимите, то увидите ид по которому была создана текущая картинка. Использовать один и тот же Seed бывает полезно если вы экспериментируете с запросом, или проверяете как работают разные лоры, или просто хотите воспроизвести то изображение, которое уже создавали ранее.
History Log - содержит информацию обо всем, что вы ранее создавали, тут как раз можно увидеть Seed для каждого изображения, запрос и другие настройки. В отличии от Automatic 1111, ComfyUI и прочих Фокус не хранит информацию о генерации внутри самого изображения, а значит вы не сможете воспроизвести информацию о генерации через png info. Сохраняйте лог генераций или промпты отдельно. А мы переходим на следующую вкладку.
Раздел Style
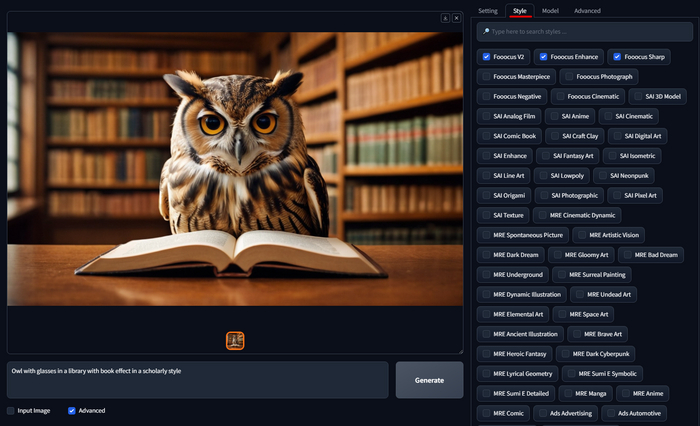
Owl with glasses in a library with book effect in a scholarly style
По умолчанию всегда включено несколько стилей, Fooocus V2, это тот самый стиль который активирует GPT модель улучшающую ваши запросы, имейте это ввиду, когда будете переключать стили. Стилей очень много, поэтому можно воспользоваться поиском. Для примера я выключу два стиля следующие за Fooocus V2, и вместо них включу Steampunk 2 и SAI Fantasy Art, не изменяя промпт и даже Seed. И получаю отличную фентези сову.
Owl with glasses in a library with book effect in a scholarly style
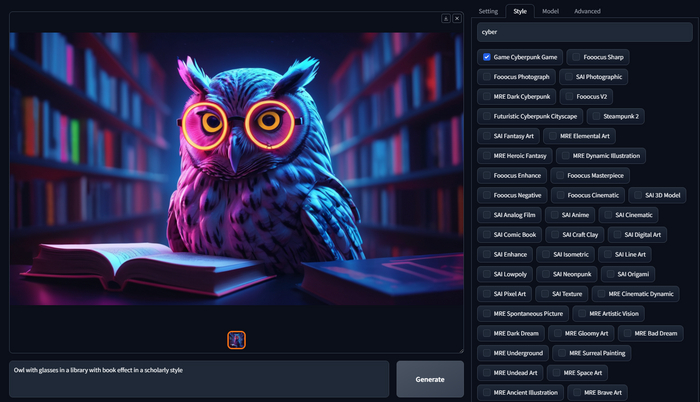
Или например мне нужна сова с книгами в Киберпанк стиле, для этого выключаете все стили и включаете Game Cyberpunk Game.
Owl with glasses in a library with book effect in a scholarly style
А возможно вам нужная черно-белая драматичная сова? Тоже не проблема, для примера ниже я выбрал стили Photo Film Noir, Dark Fantasy, Dark Moody Atmosphere и SAI Line Art. Мне результат очень нравится.
Owl with glasses in a library with book effect in a scholarly style
Экспериментируйте со стилями и комбинируйте их, в Фокусе работа со стилями улучшена по сравнению с A1111 и другими, это позволяет применять одновременно 3-5 стилей для получения отличного результата, а не парочку как в аналогах. А мы двигаемся в следующую вкладку.
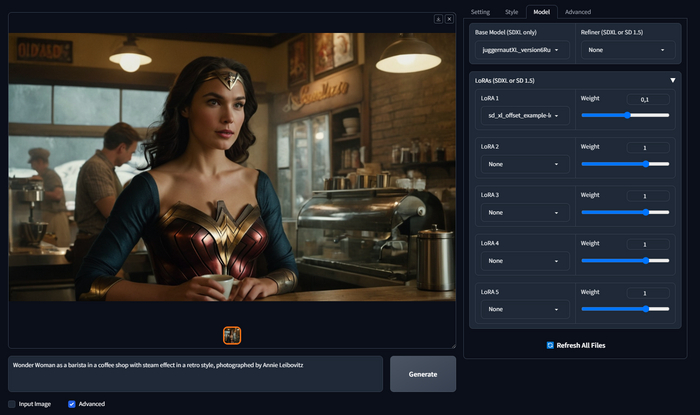
Раздел Model
Wonder Woman as a barista in a coffee shop with steam effect in a retro style, photographed by Annie Leibovitz
На вкладке Model можно переключить модель, выбрать рефайнер, или добавить дополнительные лоры. Сила лор может регулироваться от -2 до 2, в большинстве случаев оптимально ставить 0.5, всего можно добавить до пяти лор.
Скачиваем лоры и модели с https://civitai.com, лоры кладем в папку Fooocus\models\loras. Модели кладем в папку Fooocus\models\checkpoints. Какие лоры могут вам понадобиться и зачем? Смотрите в моем большом обзоре сервисных лор для SDXL на YouTube, я сравнил 12 самых популярных, рассказал что они делают и как их использовать.
Если у вас уже есть своя папка с моделями или лорами, например в A1111, то вы можете подключить её отредактировав пути до папки с моделями в файле Fooocus\config.txt, кстати, там же в конфиге можно указать и настройки по умолчанию, с которыми будет запускаться Фокус. Используйте файл config_modification_tutorial.txtв качестве пособия по возможным настройкам, он лежит рядом.
Раздел Advanced
На вкладке Advanced находится всего пара настроек, первая Sampling Sharpness отвечает за добавочный шум при создании изображения, чем больше шума, тем больше деталей будет на вашем изображении, но избыток шума может привести к артефактам и замусоренности, это отлично видно на гифке ниже. Мне обычно нравится значение 5-7.
Raccoon with a mask in a trash can with garbage effect in a mischievous style.
Guidance Scale отвечает за то, насколько сильно нейросеть должна пытаться следовать запросу, высокое значение приведет к артефактом, а на низком все будет блеклое, смотрите рекомендуемое значение CFG в описании модели, или оставляйте по умолчанию.
Developer Debug Mode открывает меню для тонкой настройки, но настройки там настолько тонкие, что покрутить их и ничего не сломать, а сделать лучше у вас вряд ли получится, так что этот раздел исследовать не будем.
Друзья, поскольку количество медиа файлов в этом руководстве уже переваливает за 20, а для рассказа про оставшуюся галочку Input Image мне нужно еще как минимум столько же, я сделаю это в следующей публикации.
Из второй части вы узнаете как в Фокусе работают вариации, чтобы создать похожее изображение на то, что вы загружаете. Узнаете как работает качественное увеличение ваших изображений. Расскажу про местную вариацию ControlNet которая позволяет скопировать и стиль и содержимое с любого изображения добавив в вашу генерацию. И про местный дипфейк, который позволяет перенести ваше лицо на создаваемое изображение. И конечно же про инпеинтинг и аутпеинтинг, с помощью которого можно расширить или изменить любое изображение как в тех роликах с фотошопом, генеративной заливкой и мемами.
close-up of baby Groot bye-bye hand shake in the space, surrounded with firefly and blue sparkles
А на сегодня у меня все, вы узнали про нейросеть Fooocus, которая создает изображения по текстовому запросу и научились в ней работать. Теперь вы знаете за что отвечает каждая из настроек и сможете осмысленно создавать красивый арт который пригодится в работе или учебе, и конечно, порадует друзей и близких. Генерация изображений с помощью нейросетей очень интересный и увлекательный процесс, делитесь своими работами в нашем чате с такими же увлеченными энтузиастами.
Я рассказываю больше про нейросети у себя на YouTube, в телеграм, на Бусти, буду рад вашей подписке и поддержке. До скорого.
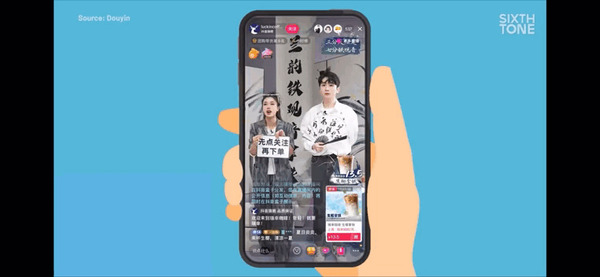
Китайские онлайн-магазины переживают настоящий бум автоматизации благодаря продавцам-клонам, созданным на основе искусственного интеллекта. Эти виртуальные «продавцы» никогда не устают и готовы трудиться 24 часа в сутки, 7 дней в неделю
Совершенно новый уровень маркетинга начинает доминировать на китайской онлайн-шопинговой сцене. Прямые трансляции считаются наиболее прибыльным маркетинговым каналом, и звезды платформ, таких как Taobao и Douyin, могут заключать мгновенные сделки. Однако эти успехи требуют огромных вложений. Стоимость подготовки онлайн-продавца высока, и она включает не только деньги, но и время. Более того, каждый ведущий неизбежно сталкивается с необходимостью отдыха. Именно тут на помощь приходят аватары на базе искусственного интеллекта...
Недавно MIT Technology Review опубликовал интересную статью о том, как искусственный интеллект завоевывает рынок китайских онлайн-продавцов. Даже поздно ночью популярные каналы на Taobao, Douyou или Kuaishou продолжают радовать своих зрителей. Однако если присмотреться внимательней, обнаруживаются некоторые особенности в поведении и речи продавцов. Это не настоящие люди, а продукт искусственного интеллекта, который прекрасно исполняет свои обязанности.
«Если компания наймет десять ведущих для прямых трансляций, у каждого из них будет свой уровень квалификации. Два или три наилучших стримера могут обеспечить большую часть продаж», - отмечает генеральный директор компании, специализирующейся на искусственном интеллекте, Чен Дан. «Виртуальный ведущий может заменить шестерых или семерых стримеров, чей вклад меньше, а показатели ROI ниже. Это значительно снижает расходы».
Несмотря на то, что лучшие онлайн-продавцы все еще опережают клонов на базе искусственного интеллекта в продажах, многие компании предпочитают автоматизацию. Создание базового клона теперь стоит около 8000 юаней (1100 долларов), что дает возможность сократить расходы, улучшить доступность услуг 24/7 и действительно повысить продажи
Тем не менее на производстве все по старому, друзья! Контроль качества, инспекция бизнес процессов. логистика, 1688 и прочее , со всем этим помогу вам. Обращайтесь
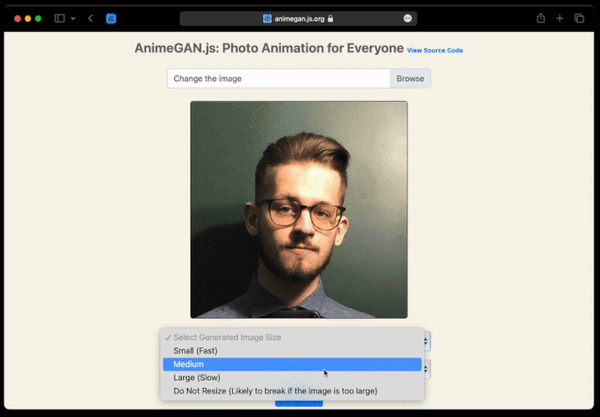
Аниме - это уникальное искусство, которое покорило сердца миллионов фанатов по всему миру. Его выразительные персонажи, яркие цвета и захватывающие истории сделали этот жанр популярным не только среди азиатских зрителей, но и за его пределами. Теперь, благодаря нейросети AnimeGAN.js, вы можете стать частью этой увлекательной вселенной и преобразовать свои обыденные фотографии в настоящее аниме-искусство.
Что такое AnimeGAN.js?
AnimeGAN.js - это веб-версия нейросети, созданной для одной потрясающей цели: превратить ваши фотографии в аниме-стиль. Ее действие так просто и захватывающе, что сложно поверить, что за этим стоит технология и искусственный интеллект. Просто загрузите вашу фотографию, и AnimeGAN.js автоматически анализирует черты лица на изображении. Затем она возвращает вам ту же фотографию, но с вдохновением аниме.
Как это работает?
AnimeGAN.js работает путем анализа черт лица на вашей фотографии и пересоздает ее в стиле аниме. Это означает, что обыденные портреты превращаются в выразительные аниме-персонажи с большими глазами, стильной прической и живописными деталями. Вы можете выбрать степень анимации, чтобы управлять тем, насколько ярко и выразительно будет ваше аниме-изображение.
Творческие возможности
AnimeGAN.js открывает перед вами бескрайние творческие возможности. Теперь вы можете создавать уникальные аниме-аватары для своих социальных медиа, обрабатывать свои фотографии и просто веселиться, превращая себя и своих друзей в аниме-героев.
Важные замечания
Помните, что использование AnimeGAN.js должно быть ответственным и с уважением к частной жизни. Если вы хотите обработать фотографии других людей, всегда получайте их разрешение. И не забывайте о правилах и ограничениях, установленных для использования таких инструментов.
AnimeGAN.js - это захватывающий инструмент для всех фанатов аниме и искусства. Он дает вам возможность погрузиться в увлекательный мир аниме и сделать ваши фотографии неповторимыми.
Кстати, не забудьте подписаться на мой канал, там много интересного. Я буду рад Вашей подписке.
Измерять время люди научились тысячи лет назад. Легко можно вспомнить изобретенные ими песчаные, солнечные, водяные часы. Позже на смену им пришли механические и атомные. В быту можно обойтись любым из этих устройств, но ученым, работающим в самых передовых областях исследований, нужно определять течение времени максимально верно. Не так давно перед ними замаячила перспектива заполучить в свое распоряжение «хронометр», который будет точнее даже атомного, дающего погрешность всего в секунду на несколько миллиардов лет. Это ядерные часы.
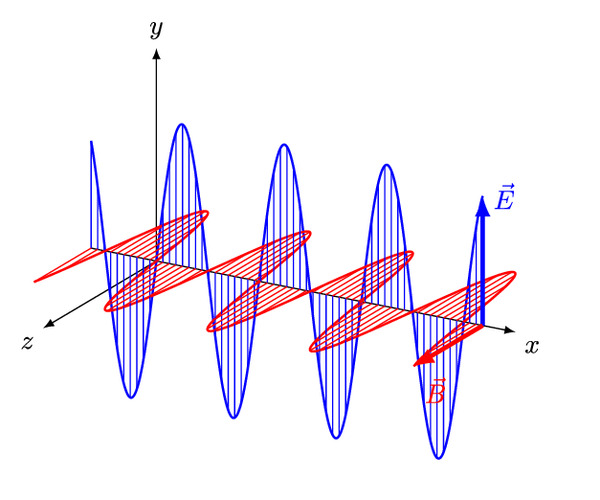
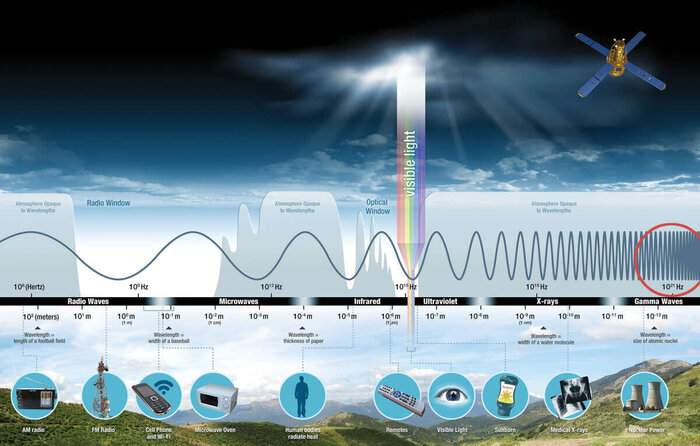
Чтобы получить часы современного типа, нужно использовать нечто такое, что ходит взад и вперед с постоянной скоростью. В науке такая система называется осциллятором, и её ключевой характеристикой считается частота, с которой совершаются колебания. Самыми точными и надежными осцилляторами являются световые волны, состоящие из электромагнитных полей, «вибрирующих» с известной частотой. Чтобы понять, как они помогают создать атомные часы, нужно ненадолго погрузиться в квантовую механику.
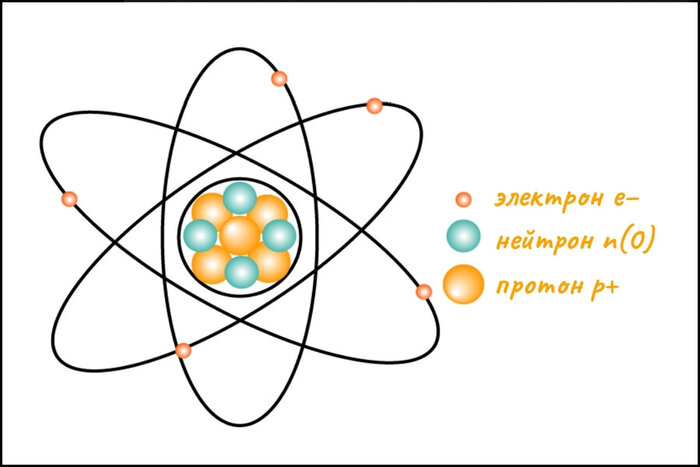
Поляризация электромагнитных волн
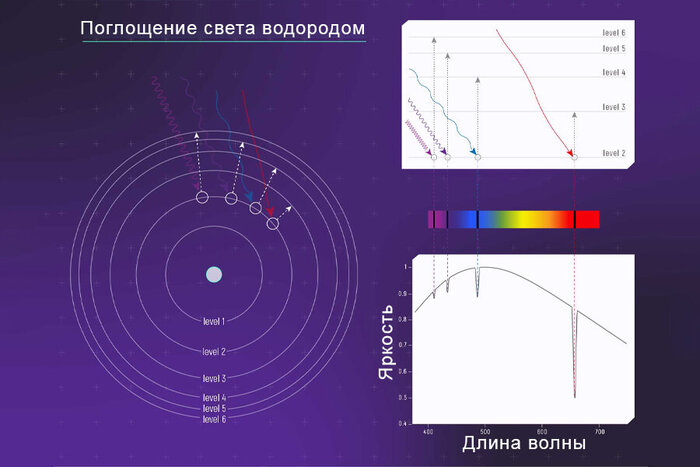
Атом состоит из ядра, окруженного электронами. Местоположение последних определяется количеством имеющейся у них энергии. Здесь будет уместно мысленно вообразить лесенку субатомного масштаба. Чтобы электрон поднялся или спустился на одну ступеньку, он должен либо получить, либо потерять определенное количество энергии. При этом свет либо поглощается, либо испускается - на строго определенной частоте, так как квантовая механика постулирует, что частота световых волн и энергия напрямую связаны. Чем ниже одна, тем меньше другая, и наоборот.
Таким образом, при создании атомных часов ученые берут группу идентичных атомов, например, цезия-133, и воздействуют на них лазером. Луч последнего имеет заданную частоту, а следовательно и энергию, которая идеально подходит для перемещения всего одного электрона каждого атома на следующую ступеньку. Перескочившие частички в конечном счете теряют лишнюю энергию и опускаются на прежнее место, а это означает излучение света. Подсчитывая частоту этих невероятно точных колебаний, ученые отмечают течение времени.
Атомные часы разрабатываются в течение десятков лет. Сегодня они активно используются в самых передовых отраслях человеческой деятельности, в том числе в космонавтике. Но лесенка электронов вокруг атома – не единственное, что может выступить в интересующем нас качестве. Такая же структура, только меньшего размера, имеется в атомном ядре, которое, подобно электронам, способно перепрыгивать с одного уровня на другой при поглощении или выделении определенного количества энергии. Ядерные часы имеют очевидные преимущества по сравнению с атомными. Хотя бы потому, что ступеньки последних на некоторых энергетических уровнях не всегда постоянны. Их положение может изменяться на ничтожно малую величину при внешних возмущениях в электрическом или магнитном поле. А если часы имеют размер в один атом, то даже самые крошечные сдвиги могут сказаться на способности следить за временем.
Планетарная модель атома Резерфорда
Тем временем, на ядро атома внешние возмущения почти не влияют, так как его протоны и нейтроны очень тесно связаны. Но тут есть другая загвоздка, а именно гораздо меньший масштаб, в котором придется работать наблюдателю. Это, в свою очередь, означает приложение энергии, количество которой в миллионы раз больше, чем нужно для функционирования атомных часов. Вспомним, что данный параметр зависит от частоты электромагнитного излучения. Обычное ядро нужно обрабатывать не микроволнами, как в традиционных цезиевых атомных часах, и не оптическими лазерами, как в более современных хронометрах, использующих другие химические элементы. Здесь нужен лазер, испускающий гамма-лучи, отличающиеся очень высокой частотой и наполненностью энергией. При нынешнем уровне развития технологий это попросту невозможно.
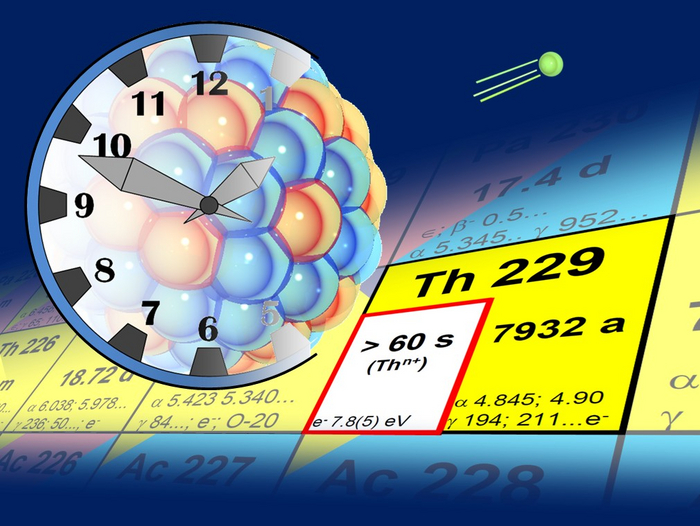
Обойти ограничения может позволить известная науке лазейка, которую предоставляет радиоактивный элемент торий-229, но тут есть небольшая проблема. Ученые знают, что его ядро возбуждается одним из видов ультрафиолетового излучения, но никто из них не может определить точное количество энергии, требующееся для этого. Серьезный прорыв в понимании данного вопроса произошел в 2023 году, когда группа исследователей из ЦЕРН решила применить нетрадиционный подход к своим экспериментам. Вместо того чтобы для выяснения неизвестных параметров обработать ядра тория лазером на различных частотах, они задействовали другой радиоактивный элемент – актиний-229. Тот превращается в торий-229, причем в возбужденный. Дождавшись окончания этого состояния у химического элемента, исследователи измерили частоту испускавшегося света. Теоретически это должно было показать параметры работы лазера в ядерных часах, использующих обычный торий.
Эксперименты оказались недостаточно точными, и выделить идеальную частоту для запуска первых в мире ядерных часов не удалось, но ученые сузили диапазон поисков для последующих исследований. Это означает, что уже сейчас можно начать просчитывать варианты потенциального применения данного хронометра. Это может быть усовершенствованная GPS и прочие виды высокоточного мониторинга. Не исключено, что ядерные часы позволят отслеживать незначительные движения тектонических плит, а это прямой путь к прогнозированию землетрясений и извержений вулканов. Астрономы могли бы продвинуться в поисках темной материи. Ну и, наконец, весьма интригующе выглядит перспектива проверки постоянства законов физики. Так, например, скорость света кажется сегодня константой, однако некоторые физики предполагают, что она меняется в космических временных масштабах, пусть и очень незначительно. В общем, будем следить за развитием событий. Технология кажется весьма заманчивой.
Спасибо за внимание! Если вам понравилась статья, то можете поддержать ее "плюсиком" или подписаться на этот канал. Также хотелось бы упомянуть, что у нас есть свой Телеграм канал. Там мы постоянно публикуем интересные посты о космосе и астрономии.
Мы искренне ценим каждого нашего читателя. Если вы захотите поддержать нас материально (по кнопке ниже), то ваше имя/никнейм будут указаны в конце следующей публикации. Это наш маленький способ сказать "спасибо" за вашу доброту и поддержку!