

По итогам происходящего сейчас с компанией "YADRO"
По итогам произошедшего считаю что я уже неплохо выступил..
Короче - я собой очень доволен.
А вы чё думаете? 🤣😂😀😉
Показать полностью
1
По итогам произошедшего считаю что я уже неплохо выступил..
Короче - я собой очень доволен.
А вы чё думаете? 🤣😂😀😉
Новые AMD к сожалению стоят очень дорого, бешенных денег, 50-100 тысяч руб не валяются на улице. Поэтому к сожалению доступно только до 5-10 тысяч руб на AM3, AM3+ сокетах, AM2, AM2+ сильно уже устарели и не подходят, ведь в них нет поддержки POPCNT и SSE 4.2 для установки Windows 11 24H2 и будущей Windows 12.

Продолжение истории процессоров AMD.

Процессоры без встроенной графики под сокет AM5 носят название Raphael. Как и в случае с предшественниками, в состав линейки входят шестиядерные Ryzen 5, восьмиядерные Ryzen 7 и топовые Ryzen 9 с 12 или 16 ядрами с поддержкой многопоточности. В двух последних сериях имеются модели с технологией 3D V-Cache. У старших моделей с двумя кристаллами CCD дополнительный кеш устанавливается лишь на один из них.

Мобильные чипы поколения Zen 4 представлены в апреле 2023 года двумя вариантами. Phoenix представляет собой наследника APU прошлых поколений с производительной графикой RDNA3 и предназначен для массового сегмента ноутбуков. До восьми ядер в монолитном кристалле сочетаются с 16 МБ кеша L3. Поддерживается память DDR5-5600 и LPDDR5X-7500. Процессоры производятся по самому передовому техпроцессу 4 нм. Они лишены поддержки PCI-E 5.0 — доступна лишь четвертая версия интерфейса. Пиковые частоты достигают 5.2 ГГц, а TDP не превышает 54 Вт.
В противовес этому, чипы Dragon Range предназначены для высокопроизводительного сегмента ноутбуков и представляют собой мобильную адаптацию чиплетных Ryzen 7000 для десктопов с аналогичными характеристиками, но ограниченными частотами и TDP — до 5.4 ГГц и 75 Вт, соответственно. Линейка содержит модели с количеством ядер от шести до 16.
Линейка процессоров на базе архитектуры Zen 4 представлена относительно недавно, и ей еще есть куда расти. В ближайший год планируется появление десктопных APU с производительной графикой. Также ожидаются младшие модели Ryzen 3, которые пока в ассортименте этого поколения отсутствуют. Ryzen Threadripper нового поколения станут намного мощнее — помимо архитектуры Zen 4, нового сокета и повышенных частот, в них будет до 96 ядер.
Архитектура Zen разработана с прицелом на модульность и доработку, вследствие чего впереди нас ждёт ещё не одно поколение процессоров Ryzen. AMD подтвердила, что первые процессоры на Zen 5 выйдут в 2024 году. Следующая за ней Zen 6 в разработке – о ней уже появляются первые утечки информации.
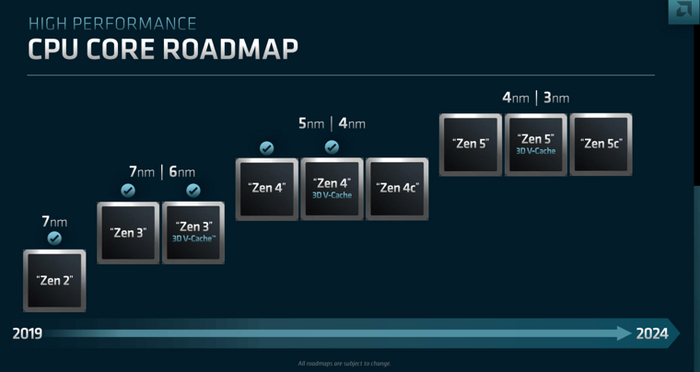
Благодаря этой архитектуре процессоры AMD «восстали из пепла» и стали равноправными конкурентами ЦП Intel. Также стоит отметить, что именно Zen спровоцировала рост производительности и количества ядер потребительских процессоров, которого до них в период «застоя» 2011-2016 годов практически не было.

С обратной стороны подложки находится множество электронных компонентов, стабилизирующих напряжения для правильной работы внутренних частей процессора. Они окружены металлическими контактами, отвечающими за подключение процессора в сокет материнской платы.
С верхней стороны чип покрывается дополнительным слоем кремния. Следом наносится припой или пластичный терм интерфейс, после которого на процессор устанавливается термо-распределительная металлическая крышка.

После того, как процессор принимает привычный для нас вид, он отправляется на последнее тестирование. По его окончании на крышку наносится название модели и номер партии. Затем процессор отправляют в упаковочный цех. Из него он попадает на склад производителя, а следом — и на полки магазинов.

Так что же такое "Центральный процессор"
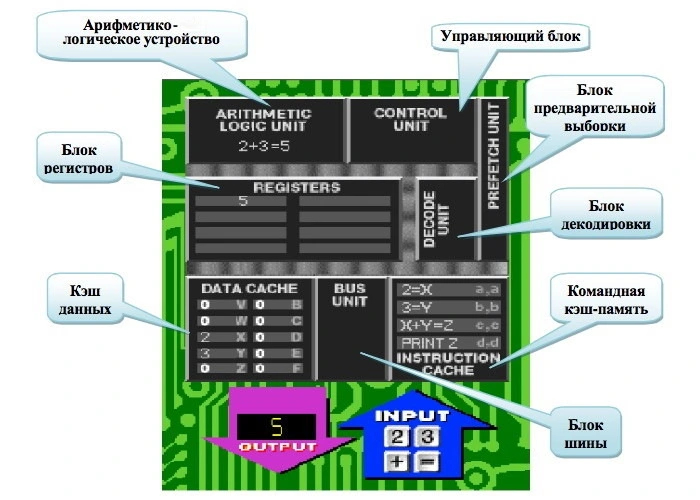
Центральный процессор — сложное электронное устройство. В его состав входят различные блоки вычислительных ядер, несколько уровней кэш-памяти, шины обмена данными, встроенная графика и прочие блоки. За счет чего же растет то самое IPC?
Инструкции, полученные процессором, поступают на исполнительный конвейер. От количества и скорости работы разнообразных исполнительных блоков, имеющихся в нем, зависит скорость исполнения инструкций. В каждом новом поколении количество таких блоков увеличивается, а также улучшается эффективность их работы. Сначала идут следующие блоки:
Предсказатели переходов (Branch Predictors). Блоки, прогнозирующие выполнение или невыполнение инструкций в программах на несколько шагов вперед.
Блоки выборки инструкций (Instruction Fetch Units, IFU). Блоки, занимающиеся выборкой инструкций для последующей передачи их декодерам.
Декодеры (Decoders). Преобразуют сложные команды x86 в простейшие микрооперации для исполнения.
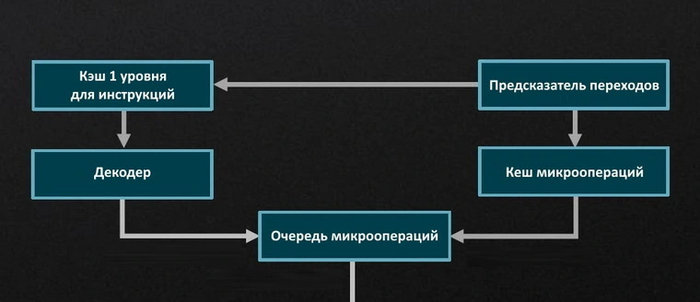
Это общая часть конвейера. Затем он разделяется на две части, каждая из которых предназначена для работы с собственным типом вычислений: целочисленную (Integer) и с плавающей запятой (Floating-Point). У каждой части имеются следующие независимые блоки:
Блок переименования регистров (Register Rename). Исполняемые инструкции ссылаются на логические регистры. Этот блок переносит ссылки на физические регистры процессора.
Планировщики исполнения (Schedulers). Выстраивают поступающие инструкции в очередь с целью максимально эффективного исполнения.
Регистровый файл (Register File). Ячейки памяти, которые хранят коды команд в период их исполнения.
Далее целочисленная часть разделяется на несколько ячеек, которые называются исполнительными портами (Execution Ports). В каждом из них может быть один из следующих блоков:
Арифметико-логическое устройство (Arithmetic Logic Unit, ALU). Занимается целочисленными вычислениями.
Блок генерации адресов (Address Generation Unit, AGU). Вычисляет адреса, используемые ядром для доступа к памяти, а также занимается их загрузкой и выгрузкой.
Блок хранения адресов (Store Data). Упрощенный вид AGU, который занимается исключительно выгрузкой адресов в память.
Блок исполнения переходов (Branch Execution Unit, BRU). Выполняет переходы и вызовы процедур на основе решений исполняемой программы.
После исполнительных портов следует блок сохранения/загрузки (Load/Store), который отвечает за загрузку данных из памяти и сохранение данных в нее.
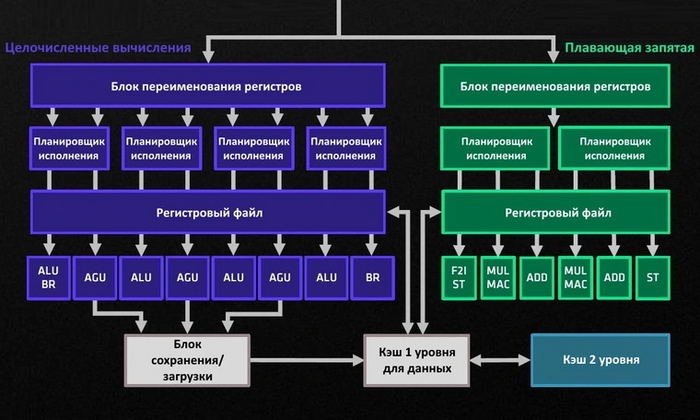
Часть вычислений с плавающей запятой называется FPU. Она работает с мультимедийными инструкциями семейств SSE, AVX, FMA и прочими. У этой части собственные порты, в которых другие блоки, отвечающие за математические операции: сложения (Add), умножения-сложения (Multiple-Add, MAD), умножения-накопления (Multiply-Accumulate, MAC), сдвига (Shift), смешивания (Shuffle).
Помимо скорости работы вычислительных блоков, на производительность влияют скорость, объем и строение кэшей. В процессоре есть несколько различных кэшей, каждый из которых предназначен для ускорения работы на определенном отрезке процесса вычислений.
Кэш инструкций (L1 Instruction Cache). Кэш, куда попадают еще не декодированные x86-инструкции.
Кэш микроопераций (L0 Cache, Micro-Ops Cache). Кэш, предназначенный для хранения декодированных микроопераций.
Кэш первого уровня для данных (L1 Data Cache). Кэш малого объема, предназначенный для данных.
Кэш второго уровня (L2 Cache). Кэш среднего объема, следующий за L1. Работает медленнее кэша первого уровня.
Кеш третьего уровня (L3 Cache). Кеш большого объема, следующий за L2. Самый медленный из всех кэшей. В отличие от других кэшей, которые у каждого ядра свои, L3 - общий для всех ядер процессора.
Буферы и очереди для работы с инструкциями (Instruction Buffers and Queue) используются для ускорения работы с инструкциями. В их число входят буфер переупорядочивания, буфер загрузки, буфер выгрузки, очередь декодированных микроопераций и очередь распределения.
Буферы ассоциативной трансляции (Translation Lookaside Buffers, TLB). Небольшие кэши, расположенные после конвейера, а также между обычными кэшами разных уровней. Используются для ускорения трансляции виртуального адреса памяти в физический.
Оперативная память (Random Access Memory, RAM). Последний уровень динамической памяти. Хотя сама память находится за пределами процессора, ее контроллер, задающий тип, число каналов и тактовую частоту, находится именно в ЦП.
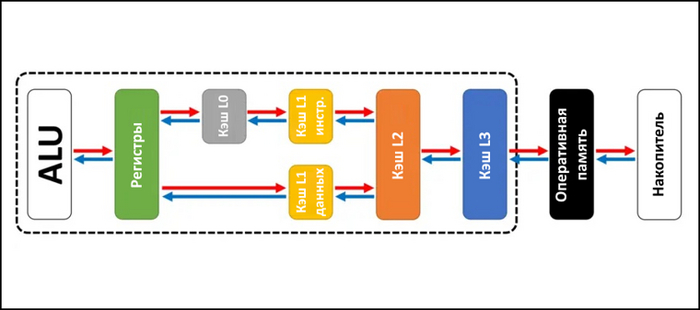
Помимо объема и их скорости, на производительность влияют и другие характеристики кэшей:
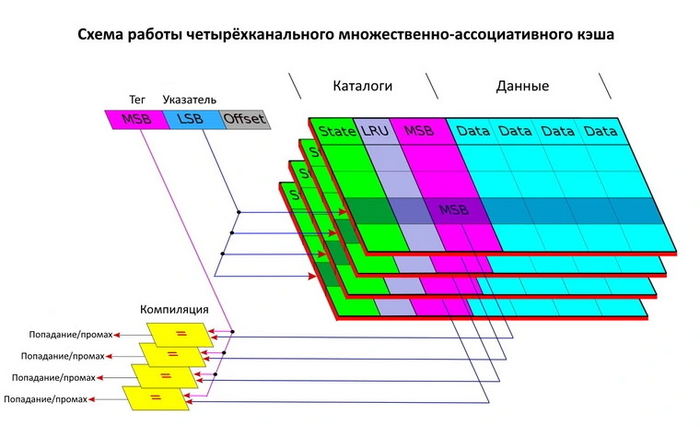
Организация. При инклюзивной организации кэша данные дублируются на различных уровнях. Это дает быстрый доступ к ним, но есть и минус — они занимают место на разных уровнях кэша. При эксклюзивной организации дублирований нет, и объем кэша используется более эффективно. Однако в случае, если нужных данных не оказалось в более быстром кэше, процессору придется тратить дополнительное время на извлечение их из более медленного уровня. Неинклюзивный кэш сочетает преимущества первых двух видов: он отслеживает данные, пытаясь спрогнозировать их необходимость на верхнем уровне кэша. При ее отсутствии алгоритмы вытесняют ненужные данные в нижний уровень кэша, экономя объем.
Сегментация. У современных процессоров кэш последнего уровня может быть как монолитным, так и состоять из нескольких сегментов.
Ассоциативность. Для ускорения работы кэша доступ к нему осуществляется по нескольким каналам. Уровень ассоциативности — это количество используемых кэшем каналов. Чем их больше, тем эффективнее работа кэша: меньше промахов при поиске данных, больше попаданий. Но с ростом числа каналов усложняется и система доступа к кэшу. Несмотря на меньшие промахи, в результате обработки большого количества каналов производительность кэша может снижаться.
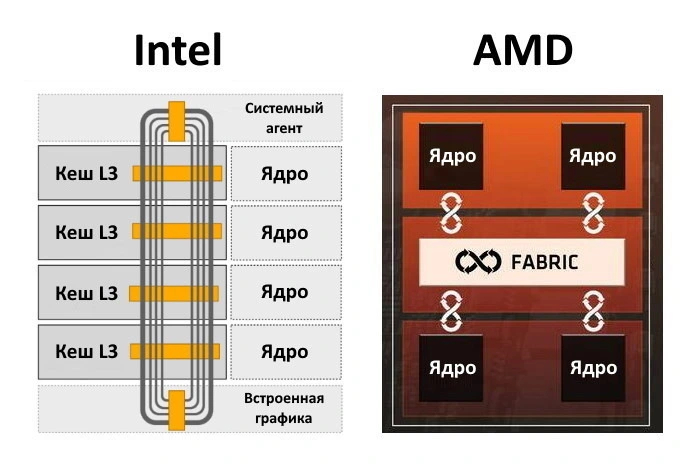
В современных многоядерных моделях важную роль играет также скорость передачи данных между внутренними компонентами процессора, в первую очередь — вычислительными ядрами. Каждая из компаний-производителей использует шину собственной разработки для соединения компонентов ЦП между собой:
Компоненты процессоров Intel соединены кольцевой шиной Ring Bus.
Компоненты процессоров AMD общаются посредством соединений шины Infinity Fabric.
На сегодняшний день процессорная архитектура, разработанная с нуля — очень редкое явление. Чаще всего новые процессорные архитектуры получаются с помощью доработки различных блоков уже существующих решений. В число таких доработок входят:
Улучшение предсказателей переходов. Доработка этих блоков помогает увеличить производительность за счет уменьшения количества промахов предсказания инструкций.
Увеличение количества декодеров. За счет этого процессор становится способен декодировать больше инструкций за такт. В теории, это должно прямо повлиять на производительность. Однако, для раскрытия потенциала большего количества декодеров необходимо одновременно «подтягивать» и другие части конвейера.
Улучшения планировщиков исполнения. Благодаря этому становится возможным более «плотно» загрузить работой исполнительные порты. Это помогает добиться их большей эффективности, повышая производительность.
Увеличение регистрового файла. Расширяет хранилище для поступающих команд. Обычно производится вместе с увеличением количества исполнительных портов – это делается для достижения их большей эффективности.
Увеличение количества исполнительных портов. Расширение конвейера с добавлением вычислительных блоков позволяет производить больше расчетов за такт и быстрее передавать их. Это прямо влияет на производительность, особенно при сложном коде.
Усовершенствования блока сохранения/загрузки. Позволяют совершать больше операций сохранения/загрузки за такт, тем самым увеличивая эффективность работы с памятью.
Улучшения блоков FPU. Увеличение количества и производительности блоков вычислений с плавающей запятой позволяет быстрее выполнять мультимедийные инструкции, а также внедрять поддержку их новых видов.
Вдобавок к улучшениям вычислительных блоков процессоры новых архитектур обычно получают и улучшения подсистемы кешей:
Увеличение размеров кэшей. Повышает количество хранящихся в них данных, вследствие чего уменьшается вероятность промаха.
Увеличение скорости кэшей. Более высокая пропускная способность кэша снижает время, необходимое для его чтения или записи.
Изменения в ассоциативности, организации или сегментации. Совокупность этих изменений обычно подбирается под прочие характеристики процессора, чтобы сделать работу кэша наиболее эффективной.
Увеличение буферов и очередей работы с инструкциями. За счет увеличения позволяют более эффективно работать вычислительным блокам процессора.
Увеличение буферов ассоциативной трансляции. Уменьшает вероятность промаха при поиске страницы памяти.
Увеличение скорости обмена по внутренним шинам. Скорость внутренней шины повышается раз в несколько поколений, чтобы успевать передавать данные с учетом роста производительности ядер и роста их количества.
Улучшения контроллера памяти. Более высокие тактовые частоты и новые типы памяти подбираются с учетом усовершенствований архитектуры, чтобы ОЗУ не стала узким местом в производительности системы.
Обратимся к примерам таких изменений. Для начала возьмем процессоры Intel. В 2021 году после шести лет «царствования» в десктопах архитектуры Skylake наконец-то вышли модели 11 поколения Core на новой архитектуре Sunny Cove.
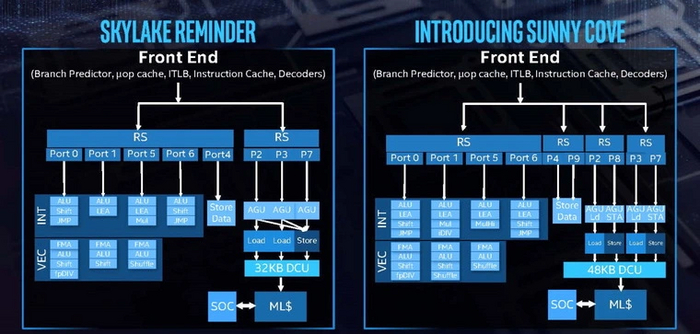
На ее основе построены десктопные процессоры Rocket Lake, которые быстрее предшественников на одной частоте примерно на 10–12%. Это стало возможным благодаря следующим улучшениям:
Пять инструкций за такт вместо четырех — заслуга расширенного декодера.
Десять исполнительных портов вместо восьми: плюс один AGU, и еще один порт для блока Store Data.
Усовершенствованный блок сохранения/загрузки, позволяющий производить одновременно две операции сохранения против одной у предшественника.
Увеличенные буферы и очереди для работы с инструкциями.
В полтора раза увеличенный кэш микроопераций и кеш L1. Последний, к тому же, был ускорен.
Кэш L2 был увеличен в два с половиной раза. Его инклюзивная организация сменилась неинклюзивной.
Производительные ядра современных процессоров Alder Lake и Raptor Lake основаны на следующей, самой современной на данный момент архитектуре Intel — Golden Cove.

По сравнению с предшественниками Rocket Lake они быстрее примерно на 15–20 %. Это достигается благодаря следующим усовершенствованиям:
В очередной раз расширенный декодер: шесть инструкций за такт против пяти
Двенадцать исполнительных портов вместо десяти: плюс один ALU и один AGU.
Увеличены буферы и очереди для работы с инструкциями.
Увеличены и ускорены кэши всех уровней.
Новый контроллер памяти, работающий с ОЗУ DDR5 наряду с DDR4.
Теперь обратим внимание на изменения в современных процессорах AMD. В конце 2020 года были представлены первые процессоры архитектуры Zen 3 — Ryzen 5000 серии.

Благодаря им впервые за много лет AMD смогла перегнать по однопоточной производительности конкурентные процессоры Intel. Рост производительности на одной частоте по сравнению с предшественниками Zen 2 составил около 20 %. Это стало возможным благодаря следующим улучшениям:
Предсказатель переходов получил улучшения для более эффективной работы.
Количество исполнительных портов было увеличено с семи до восьми. Новый порт содержит блок BRU. К тому же, теперь и один из ALU может работать в качестве BRU.
Количество планировщиков сокращено с семи до четырех. При этом каждый из переработанных планировщиков стал быстрее более, чем вдвое.
Усовершенствованный блок сохранения/загрузки позволяет производить на одно сохранение и одну загрузку больше.
Увеличены буферы и очереди для работы с инструкциями.
Усовершенствованный FPU расширился с четырех блоков до шести. Теперь у него два планировщика вместо одного.
Комплекс процессорных ядер CCX теперь содержит восемь ядер вместо четырех. Это уменьшает задержки при их общении. В связи с этим изменилась и сегментация кэша третьего уровня: теперь в каждом чипсете L3 — монолитный, объемом в 32МБ. Ранее использовались две секции по 16 МБ.
Последнее поколение процессоров AMD — серия Ryzen 7000. Они основаны на архитектуре Zen 4.
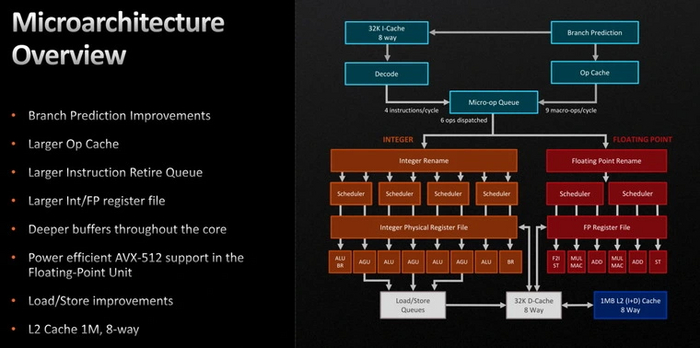
Новые процессоры быстрее предшественников примерно на 13 % на одной частоте. Архитектура Zen 4 получила следующие усовершенствования:
Предсказатель переходов в очередной раз усовершенствован.
Увеличен и ускорен кэш микроопераций.
Увеличены буферы и очереди для работы с инструкциями.
Кэш L2 вырос вдвое — с 0.5 до 1 МБ на ядро.
Увеличены размеры регистровых файлов.
Блок сохранения/загрузки теперь работает более эффективно.
Благодаря доработанному FPU добавлена поддержка инструкций AVX-512.
Новый контроллер памяти, который работает с ОЗУ DDR5 против DDR4 у предшественника.
Изменения в процессорных архитектурах разнятся из поколения в поколение. Это логично, ведь производители процессоров анализируют работу текущих поколений, и в первую очередь устраняют «узкие» места архитектур.

Рост производительности на такт (IPC) напрямую связан с блоками, в которые внесены изменения. Прирост производительности в разных видах задач может отличаться, в зависимости от внесенных в архитектуру изменений. Большинство программного обеспечения получает наибольший прирост от ускорения темпа целочисленных вычислений. Но есть и программы, которые больше чувствительны к скорости работы FPU или подсистемы кэшей.
IPC — главный показатель производительности современных ЦП, но далеко не единый. Стоит помнить, что прирост однопоточной производительности между разными поколениями процессоров дополнительно зависит от их тактовых частот, а многопоточной — еще и от количества ядер.
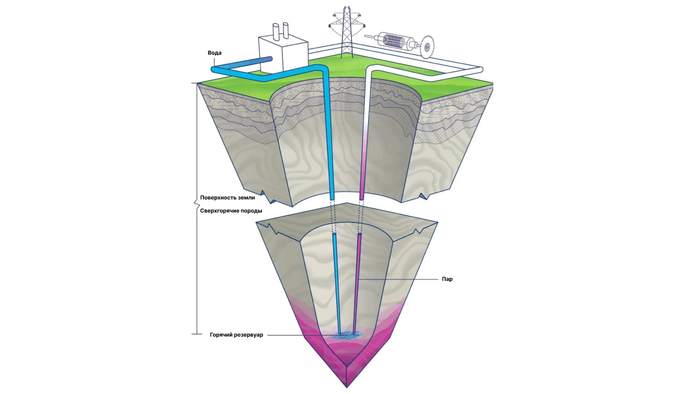
Сверхгорячие породы с температурой 374°С могут потеснить ископаемое топливо предложив чистую энергию. Типичные геотермальные электростанции используют тепло с поверхности Земли, Но ученые обратили внимание на более мощный источник: сверхгорячую горную породу, находящуюся на глубине более 10 километров.
Системы сверхгорячих пород предполагают глубокое бурение в земной коре. В эти горячие породы закачивается вода, которая нагревается, а затем возвращается на поверхность в виде пара, который может использоваться для выработки электроэнергии или получения водорода.
Американская компания Quaise Energy назвала эти сверхглубокие породы «святым Граалем геотермальной энергетики». Она планирует использовать эту колоссальную энергию путем разработки инновационных технологий бурения.
Больше интересных новостей из мира энергии и энергетики в телеграм-канале ЭнергетикУм
Россиян отлучили от разработки ядра Linux — Линус Торвальдс заявил, что отмены решения не будет
24.10.2024
Основатель проекта Linux Линус Торвальдс (Linus Torvalds) в крайне резкой манере прокомментировал исключение российских разработчиков из официального файла MAINTAINERS, в котором перечисляются те, кто сделал вклад в написание драйверов и подсистем.
Источник изображения: OpenClipart-Vectors / pixabay.com
Накануне стало известно, что из файла MAINTAINERS исчезли упоминания разработчиков, которые пользуются электронной почтой с российскими адресами и предположительно являются россиянами. Руководство проекта не дало внятных пояснений по поводу инцидента, и некоторые участники проекта выступили с призывом отменить это решение. Ответственный за поддержку стабильной ветки ядра Грег Кроа-Хартман (Greg Kroah-Hartman) заявил, что решение может быть отменено, если будут предоставлены некие документы, но основатель проекта Линус Торвальдс категорически заявил, что этого не будет.
Торвальдс пояснил, что отмены решения совершенно точно не будет, а причины, по которым в файл MAINTAINERS были внесены эти изменения, «очевидны». Они связаны не только с требованиями США — создатель Linux порекомендовал «попробовать почитать новости» и крайне резко отозвался о тех, кто призвал отменить решение. «Видимо, дело не только в отсутствии реальных новостей, но и в отсутствии знания истории», — заключил он, напомнив о своих финских корнях.
Таким образом, исключение российских специалистов было одобрено Торвальдсом и останется в силе. Но остаётся неясным, будут ли в дальнейшем приниматься в основную ветку ядра исправления от удалённых из списка разработчиков, и будут ли накладываться дополнительные ограничения на участие в проекте.
Когда основателя Linux спросили, не связан ли он каким-либо соглашением о неразглашении в связи с данным инцидентом, он также дал довольно резкий ответ: «Нет, но я не юрист и не собираюсь вдаваться в подробности о том, что мне и другим разработчикам сказали юристы. Я также не собираюсь начинать обсуждать юридические вопросы со случайными людьми из интернета, которых я всерьёз подозреваю в том, что им заплатили или их спровоцировали».

На хабре отписали гораздо более приземленные причины по вопросу. Штаб квартира разработчиков этого вашего свободного ПО, как ни крути, находится в самой свободной стране, поэтому самые свободные законы приходится соблюдать:
Джеймс Боттомли (James Bottomley), один из директоров Linux Foundation, написал в списке рассылки разработчиков Linux причины удаления российских мантейнеров:
Если ваша компания находится в списках SDN OFAC США, подпадает под санкционную программу OFAC или принадлежит/контролируется компанией, которая находится в этом списке, наша возможность сотрудничать с вами будет ограничена, и вы не сможете быть в файле MAINTAINERS.
Оригинал:
If your company is on the U.S. OFAC SDN lists, subject to an OFAC sanctions program, or owned/controlled by a company on the list, our ability to collaborate with you will be subject to restrictions, and you cannot be in the MAINTAINERS file.
p/s: странно, что еще так долго думал над этим решением, вроде новых санкций давно не было, значит могли и раньше подбанить неугодных. И отчасти странно, что признать соблюдение санкций ему труднее, чем сослаться на злых русских.







